

Cześć wszystkim! Jestem programistą back-end, piszę mikrousługi w Java + Spring. Pracuję w jednym z wewnętrznych zespołów rozwoju produktów w firmie Tinkoff.

W naszym zespole często pojawia się pytanie o optymalizację zapytań w systemie DBMS. Zawsze chcesz, żeby było trochę szybciej, ale nie zawsze da się to zrobić przy użyciu przemyślanych indeksów – musisz poszukać obejść. Podczas jednej z takich wędrówek po sieci w poszukiwaniu rozsądnych optymalizacji podczas pracy z bazą danych natrafiłem na , autor książki SQL Performance Explained. To rzadki typ bloga, na którym możesz przeczytać wszystkie artykuły pod rząd.
Chciałbym przetłumaczyć dla Ciebie krótki artykuł Marcusa. Można to nazwać swego rodzaju manifestem, który ma na celu zwrócenie uwagi na stary, ale wciąż aktualny problem wydajności operacji przesunięcia według standardu SQL.
W niektórych miejscach będę uzupełniał autora wyjaśnieniami i komentarzami. Oznaczę wszystkie takie miejsca jako „uwaga”. dla większej przejrzystości
Małe wprowadzenie
Myślę, że wiele osób wie, jak problematyczna i powolna jest praca z zaznaczaniem stron za pomocą przesunięcia. Czy wiesz, że można go z łatwością zastąpić bardziej wydajną konstrukcją?
Zatem słowo kluczowe offset nakazuje bazie danych pominąć pierwsze n rekordów w zapytaniu. Jednak baza danych musi nadal odczytać te pierwsze n rekordów z dysku w określonej kolejności (uwaga: zastosuj sortowanie, jeśli określono inaczej) i dopiero wtedy będzie można zwrócić rekordy począwszy od n+1. Najciekawsze jest to, że problem nie leży w konkretnej implementacji w systemie DBMS, ale w oryginalnej definicji według standardu:
…wiersze są najpierw sortowane według a następnie ograniczone przez usunięcie liczby wierszy określonej w od początku…
-SQL:2016, część 2, 4.15.3 Tabele pochodne (uwaga: obecnie najczęściej używany standard)
Kluczową kwestią jest to, że przesunięcie przyjmuje jeden parametr — liczbę rekordów do pominięcia, i to wszystko. Zgodnie z tą definicją system DBMS może jedynie pobrać wszystkie rekordy i odrzucić te niepotrzebne. Oczywiste jest, że definiowanie przesunięcia w ten sposób wymaga dodatkowej pracy. I tutaj nie ma znaczenia, czy to SQL czy NoSQL.
Trochę więcej bólu
Problemy z przesunięciem na tym się nie kończą. Oto dlaczego. Co się stanie, jeżeli pomiędzy odczytaniem dwóch stron danych z dysku inna operacja wstawi nowy rekord?
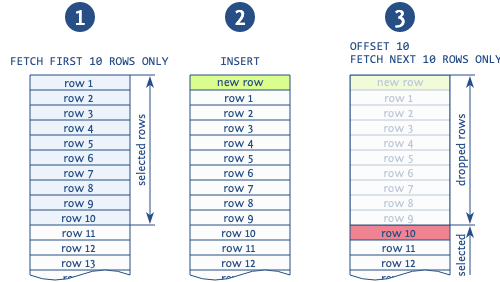
Używając offsetu do pomijania rekordów z poprzednich stron, w sytuacji, gdy nowy rekord jest dodawany pomiędzy odczytami różnych stron, najprawdopodobniej otrzymasz duplikaty (uwaga: jest to możliwe, gdy czytamy strona po stronie, używając konstrukcji order by; wówczas nowy rekord może pojawić się w środku naszego wyjścia).
Rysunek wyraźnie przedstawia tę sytuację. Baza danych odczytuje pierwsze 10 rekordów, po czym wstawiany jest nowy rekord, który przesuwa wszystkie odczytane rekordy o 1. Następnie baza danych bierze nową stronę z następnych 10 rekordów i zaczyna nie od 11., jak powinna, lecz od 10., duplikując ten rekord. Istnieją inne anomalie związane ze stosowaniem tego wyrażenia, ale ta jest najczęstsza.
Jak już ustaliliśmy, nie są to problemy konkretnego systemu DBMS ani jego implementacji. Problem leży w definicji paginacji zgodnie ze standardem SQL. Informujemy system DBMS, którą stronę pobrać lub ile rekordów pominąć. Baza danych po prostu nie jest w stanie zoptymalizować takiego zapytania, gdyż nie dysponuje zbyt dużą ilością informacji.
Warto również wyjaśnić, że problem nie dotyczy konkretnego słowa kluczowego, lecz semantyki zapytania. Istnieje kilka innych składni, które są identyczne pod względem problematyki:
- Jak wspomniano wcześniej, kluczowym słowem jest offset.
- Konstrukcja dwóch słów kluczowych limit [offset] (choć samo limit nie jest takie złe).
- Filtrowanie według dolnych granic na podstawie numeracji wierszy (np. row_number(), rownum itp.).
Wszystkie te wyrażenia mówią jedynie, ile linijek należy pominąć, nie podają żadnych dodatkowych informacji ani kontekstu.
W dalszej części artykułu słowo kluczowe offset używane jest jako uogólnienie dla wszystkich tych opcji.
Życie bez OFFSETU
Wyobraźmy sobie teraz, jak wyglądałby nasz świat bez tych wszystkich problemów. Okazuje się, że życie bez przesunięcia nie jest takie trudne: polecenie select pozwala wybrać tylko te wiersze, których jeszcze nie widzieliśmy (uwaga: te, których nie było na poprzedniej stronie), korzystając z warunku w poleceniu where.
W tym przypadku opieramy się na fakcie, że selekcje są wykonywane na uporządkowanym zestawie (stara dobra zasada order by). Ponieważ mamy uporządkowany zbiór, możemy użyć dość prostego filtra, aby pobrać tylko te dane, które znajdują się po ostatnim rekordzie poprzedniej strony:
SELECT ...
FROM ...
WHERE ...
AND id < ?last_seen_id
ORDER BY id DESC
FETCH FIRST 10 ROWS ONLYNa tym właśnie polega cała zasada tego podejścia. Oczywiście, wszystko staje się ciekawsze, gdy sortujemy według wielu kolumn, ale idea pozostaje ta sama. Ważne jest, aby pamiętać, że ten projekt ma zastosowanie w wielu -decyzje.
Takie podejście nazywa się metodą seek lub paginacją zestawów kluczy. Rozwiązuje problem zmiennoprzecinkowy (uwaga: sytuacja z zapisem pomiędzy odczytami stron została opisana wcześniej) i oczywiście, co wszyscy kochamy, działa szybciej i stabilniej niż klasyczny offset. Stabilność polega na tym, że czas przetwarzania zapytania nie zwiększa się proporcjonalnie do liczby żądanych tabel (uwaga: jeśli chcesz dowiedzieć się więcej o tym, jak działają różne podejścia do paginacji, możesz . Można tam również znaleźć testy porównawcze wykorzystujące różne metody).
Jeden ze slajdów , że paginacja według kluczy oczywiście nie jest wszechmocna i ma swoje ograniczenia. Najważniejszą wadą jest to, że nie potrafi czytać losowych stron (uwaga: nieregularnie). Jednak w dobie nieskończonego przewijania (uwaga: w przypadku front-endu) nie stanowi to aż takiego problemu. Określenie numeru strony, po której można kliknąć, jest w każdym razie złą decyzją projektową interfejsu użytkownika (uwaga: opinia autora artykułu).
A co z narzędziami?
Podział klawiszy na strony często nie jest odpowiedni ze względu na brak narzędzi wspierających tę metodę. Większość narzędzi programistycznych, w tym różne frameworki, nie daje możliwości wyboru sposobu, w jaki będzie wykonywana paginacja.
Sytuację pogarsza fakt, że opisana metoda wymaga kompleksowego wsparcia w wykorzystywanych technologiach - od DBMS po wykonanie żądania AJAX w przeglądarce z nieskończonym przewijaniem. Zamiast określać tylko numer strony, teraz będziesz musiał określić zestaw kluczy dla wszystkich stron jednocześnie.
Jednak liczba struktur obsługujących paginację słów kluczowych stopniowo rośnie. Oto co mamy w tej chwili:
- dla Javy;
- dla Ruby;
- и dla Django;
- dla Pythona;
- — kryteria API dla implementacji JPA;
- dla Perla;
- , mapper dla Node.js .
(Uwaga: niektóre linki zostały usunięte, ponieważ w momencie tłumaczenia niektóre biblioteki nie były aktualizowane od 2017–2018 r. Jeśli jesteś zainteresowany, możesz zapoznać się z oryginalnym źródłem.)
Właśnie tutaj potrzebujemy Twojej pomocy. Jeśli opracowujesz lub utrzymujesz strukturę, która w jakikolwiek sposób wykorzystuje paginację, to proszę, namawiam i błagam Cię o wprowadzenie natywnej obsługi paginacji słów kluczowych. Jeśli masz jakieś pytania lub potrzebujesz pomocy, chętnie pomogę (, , ) (uwaga: z mojego doświadczenia z Marcusem mogę powiedzieć, że jest on naprawdę entuzjastycznie nastawiony do propagowania tego tematu).
Jeśli korzystasz z gotowych rozwiązań, które Twoim zdaniem zasługują na obsługę paginacji kluczy, utwórz wniosek lub nawet zasugeruj gotowe rozwiązanie, jeśli to możliwe. Możesz również zamieścić odnośnik do tego artykułu.
wniosek
Powodem, dla którego tak proste i użyteczne podejście jak paginacja słów kluczowych nie jest powszechnie stosowane, nie jest jego techniczna trudność w realizacji lub to, że wymaga dużego wysiłku. Główną przyczyną jest to, że wiele osób jest przyzwyczajonych do widoku i pracy z offsetem - takie podejście narzuca sama norma.
W efekcie niewiele osób myśli o zmianie podejścia do paginacji, a w związku z tym narzędzia wspierające tę kwestię, dostępne w ramach frameworków i bibliotek, rozwijają się słabo. Jeśli więc bliska jest Ci idea i cel paginacji wolnej od offsetu, pomóż ją rozpowszechnić!
Źródło:
Autor: Markus Winand
Źródło: www.habr.com
