

Witam wszystkich, przyjaciele!
* Ten artykuł opiera się na otwartych warsztatach REBRAIN i Yandex.Cloud, jeśli wolisz obejrzeć wideo, znajdziesz je pod tym linkiem -
Niedawno mieliśmy okazję wypróbować Yandex.Cloud na żywo. Ponieważ chcieliśmy sondować długo i intensywnie, od razu porzuciliśmy pomysł uruchomienia prostego bloga na Wordpressie z bazą w chmurze – było to zbyt nudne. Po namyśle zdecydowaliśmy się wdrożyć coś podobnego do architektury usług produkcyjnych do odbierania i analizowania zdarzeń w trybie zbliżonym do czasu rzeczywistego.
Jestem absolutnie pewien, że zdecydowana większość biznesów internetowych (i nie tylko) w jakiś sposób gromadzi góry informacji o swoich użytkownikach i ich działaniach. Jest to przynajmniej niezbędne do podjęcia określonych decyzji – np. jeśli zarządzasz grą online, możesz zajrzeć do statystyk, na którym poziomie użytkownicy najczęściej utykają i usuwają Twoją zabawkę. Albo dlaczego użytkownicy opuszczają Twoją witrynę, nic nie kupując (witaj, Yandex.Metrica).
A więc nasza historia: jak napisaliśmy aplikację w golangu, przetestowaliśmy kafkę vs królikmq vs yqs, zapisaliśmy strumieniowanie danych w klastrze Clickhouse i wizualizowaliśmy dane za pomocą Yandex Datalens. Oczywiście wszystko to zostało doprawione rozkoszami infrastruktury w postaci dockera, terraforma, gitlab ci i oczywiście prometheusa. Chodźmy!
Od razu zastrzegam, że nie uda nam się skonfigurować wszystkiego za jednym posiedzeniem – do tego będzie nam potrzebnych kilka artykułów z serii. Trochę o konstrukcji:
Część 1 (czytasz). Ustalimy specyfikację i architekturę rozwiązania, a także napiszemy aplikację w języku golang.
Część 2. Wypuszczamy naszą aplikację do produkcji, zapewniamy jej skalowalność i testujemy obciążenie.
Część 3. Spróbujmy dowiedzieć się, dlaczego musimy przechowywać wiadomości w buforze, a nie w plikach, a także porównajmy usługę kolejki kafka, królikmq i Yandex.
Część 4 Wdrożymy klaster Clickhouse, napiszemy usługę przesyłania strumieniowego do przesyłania danych z znajdującego się w nim bufora oraz skonfigurujemy wizualizację w datalens.
Część 5 Doprowadźmy całą infrastrukturę do odpowiedniego stanu - skonfiguruj ci/cd za pomocą gitlab ci, połącz monitorowanie i odkrywanie usług za pomocą Prometheus i consul.
TK
Na początek sformułujmy zakres zadań – co dokładnie chcemy w efekcie uzyskać.
- Chcemy mieć punkt końcowy taki jak Events.kis.im (kis.im to domena testowa, której będziemy używać we wszystkich artykułach), który powinien odbierać zdarzenia za pomocą protokołu HTTPS.
- Zdarzenia to prosty plik json, taki jak: {„event”: „view”, „os”: „linux”, „browser”: „chrome”}. Na ostatnim etapie dodamy trochę więcej pól, ale nie będzie to odgrywać dużej roli. Jeśli chcesz, możesz przejść na protobuf.
- Usługa musi być w stanie przetworzyć 10 000 zdarzeń na sekundę.
- Powinno być możliwe skalowanie w poziomie poprzez proste dodawanie nowych instancji do naszego rozwiązania. I byłoby miło, gdybyśmy mogli przenieść przednią część do różnych geolokalizacji, aby zmniejszyć opóźnienia w przypadku żądań klientów.
- Tolerancja błędów. Rozwiązanie musi być wystarczająco stabilne i być w stanie przetrwać upadek dowolnych części (oczywiście do określonej liczby).
Architektura
Ogólnie rzecz biorąc, do tego typu zadań od dawna wynaleziono klasyczne architektury, które umożliwiają wydajne skalowanie. Na rysunku przedstawiono przykład naszego rozwiązania.
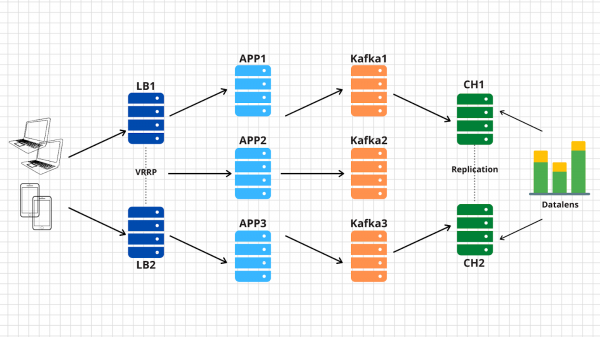
Zatem co mamy:
1. Po lewej stronie znajdują się nasze urządzenia generujące różne zdarzenia, czy to gracze kończący poziom w zabawce na smartfonie, czy też tworzący zamówienie w sklepie internetowym poprzez zwykłą przeglądarkę. Zdarzenie, jak określono w specyfikacji, to prosty plik json wysyłany do naszego punktu końcowego - events.kis.im.
2. Pierwsze dwa serwery to proste balansery, ich główne zadania to:
- Bądź stale dostępny. Można w tym celu zastosować np. keepalive, który w razie problemów będzie przełączał wirtualne IP pomiędzy węzłami.
- Zakończ TLS. Tak, zakończymy na nich protokół TLS. Po pierwsze, aby nasze rozwiązanie było zgodne ze specyfikacją techniczną, a po drugie, aby odciążyć Cię z nawiązywania szyfrowanego połączenia z naszych serwerów backendowych.
- Bilansuj żądania przychodzące do dostępnych serwerów zaplecza. Słowo klucz jest tutaj dostępne. Na tej podstawie dochodzimy do wniosku, że moduły równoważenia obciążenia muszą być w stanie monitorować nasze serwery za pomocą aplikacji i zatrzymywać równoważenie ruchu do uszkodzonych węzłów.
3. Po balanserach mamy serwery aplikacji, na których działa dość prosta aplikacja. Powinien być w stanie akceptować przychodzące żądania poprzez HTTP, weryfikować wysłany json i umieszczać dane w buforze.
4. Diagram przedstawia kafkę jako bufor, chociaż oczywiście na tym poziomie można zastosować inne podobne usługi. W trzecim artykule porównamy Kafkę, królikmq i yqs.
5. Przedostatnim punktem naszej architektury jest Clickhouse – kolumnowa baza danych, która pozwala na przechowywanie i przetwarzanie ogromnej ilości danych. Na tym poziomie musimy przenieść dane z bufora do samego systemu przechowywania (więcej na ten temat w artykule 4).
Ten projekt pozwala nam skalować każdą warstwę niezależnie w poziomie. Serwery backendowe nie dają sobie rady – dodajmy jeszcze jedno – wszak są to aplikacje bezstanowe, więc można to zrobić nawet automatycznie. Bufor w stylu Kafki nie działa — dodajmy więcej serwerów i przenieśmy do nich część partycji naszego tematu. Clickhouse sobie z tym nie radzi - to niemożliwe :) Tak naprawdę połączymy też serwery i będziemy shardować dane.
Swoją drogą, jeśli chcesz zaimplementować opcjonalną część naszych specyfikacji technicznych i skali w różnych geolokalizacjach, to nie ma nic prostszego:
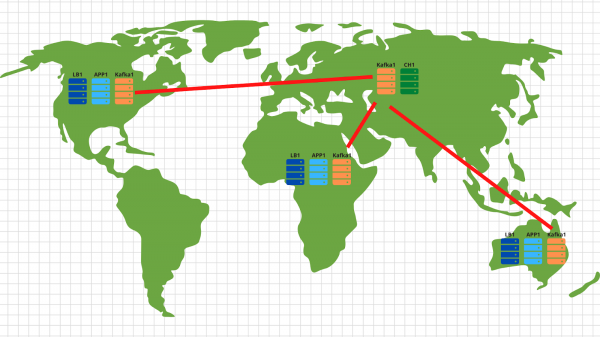
W każdej geolokalizacji wdrażamy Load Balancer wraz z aplikacją i kafką. Generalnie wystarczą 2 serwery aplikacji, 3 węzły kafka i balanser chmur np. cloudflare, który sprawdzi dostępność węzłów aplikacji i zbilansuje żądania poprzez geolokalizację na podstawie źródłowego adresu IP klienta. Tym samym dane przesłane przez amerykańskiego klienta trafią na amerykańskie serwery. A dane z Afryki są w języku afrykańskim.
Wtedy wszystko jest już dość proste – korzystamy z narzędzia lustrzanego z zestawu Kafki i kopiujemy wszystkie dane ze wszystkich lokalizacji do naszego centralnego data center zlokalizowanego w Rosji. Wewnętrznie analizujemy dane i rejestrujemy je w Clickhouse w celu późniejszej wizualizacji.
Ustaliliśmy więc architekturę - zacznijmy potrząsać Yandex.Cloud!
Pisanie aplikacji
Przed Chmurą trzeba jeszcze uzbroić się w trochę cierpliwości i napisać w miarę prostą usługę do obsługi przychodzących zdarzeń. Będziemy używać golangu, ponieważ sprawdził się on bardzo dobrze jako język do pisania aplikacji sieciowych.
Po spędzeniu godziny (może kilku godzin) otrzymujemy coś takiego: .
Jakie są główne kwestie, na które chciałbym tutaj zwrócić uwagę:
1. Podczas uruchamiania aplikacji możesz określić dwie flagi. Jeden odpowiada za port, na którym będziemy nasłuchiwać przychodzących żądań http (-addr). Drugi dotyczy adresu serwera kafka, na którym będziemy nagrywać nasze zdarzenia (-kafka):
addr = flag.String("addr", ":8080", "TCP address to listen to")
kafka = flag.String("kafka", "127.0.0.1:9092", "Kafka endpoints”)2. Aplikacja korzysta z biblioteki Sarama (), aby wysyłać komunikaty do klastra Kafka. Natychmiast ustawiamy ustawienia mające na celu maksymalną prędkość przetwarzania:
config := sarama.NewConfig()
config.Producer.RequiredAcks = sarama.WaitForLocal
config.Producer.Compression = sarama.CompressionSnappy
config.Producer.Return.Successes = true3. Nasza aplikacja posiada również wbudowanego klienta Prometheus, który zbiera różne metryki, takie jak:
- liczba żądań do naszej aplikacji;
- ilość błędów przy realizacji żądania (niemożność odczytania żądania postu, uszkodzony json, brak możliwości zapisu do Kafki);
- czas przetwarzania jednego żądania od Klienta, w tym czas na napisanie wiadomości do Kafki.
4. Trzy punkty końcowe, które przetwarza nasza aplikacja:
- /status - po prostu zwróć ok, aby pokazać, że żyjemy. Chociaż możesz dodać pewne kontrole, takie jak dostępność klastra Kafka.
- /metrics - zgodnie z tym adresem URL klient Prometheus zwróci zebrane metryki.
- /post to główny punkt końcowy, do którego będą wysyłane żądania POST zawierające json w środku. Nasza aplikacja sprawdza poprawność jsona i jeśli wszystko jest w porządku, zapisuje dane do klastra Kafki.
Zastrzegam, że kod nie jest idealny – można go (i należy!) uzupełnić. Na przykład możesz przestać używać wbudowanego net/http i przejść na szybszy fasthttp. Możesz też zyskać czas przetwarzania i zasoby procesora, przenosząc sprawdzanie poprawności JSON na późniejszy etap – kiedy dane są przesyłane z bufora do klastra Clickhouse.
Oprócz rozwojowej strony problemu, od razu pomyśleliśmy o naszej przyszłej infrastrukturze i zdecydowaliśmy się na wdrożenie naszej aplikacji za pośrednictwem okna dokowanego. Ostatecznym plikiem Dockerfile służącym do budowania aplikacji jest . Generalnie jest to dość proste, jedyny punkt na jaki chciałbym zwrócić uwagę to wieloetapowy montaż, który pozwala nam na zmniejszenie finalnego obrazu naszego kontenera.
Pierwsze kroki w chmurze
Przede wszystkim zarejestruj się . Po wypełnieniu wszystkich niezbędnych pól zostanie nam założone konto i otrzymamy grant w wysokości określonej kwoty pieniędzy, którą będziemy mogli przeznaczyć na testowanie usług chmurowych. Jeśli chcesz powtórzyć wszystkie kroki z naszego artykułu, ten grant powinien Ci wystarczyć.
Po rejestracji zostanie utworzona dla Ciebie osobna chmura oraz domyślny katalog, w którym będziesz mógł rozpocząć tworzenie zasobów chmurowych. Ogólnie w Yandex.Cloud relacja zasobów wygląda następująco:
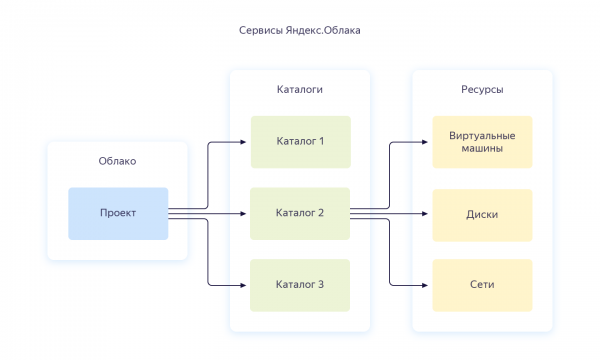
Możesz utworzyć kilka chmur dla jednego konta. A w chmurze utwórz różne katalogi dla różnych projektów firmowych. Więcej na ten temat można przeczytać w dokumentacji - . Swoją drogą, będę do tego często nawiązywać w poniższym tekście. Kiedy konfigurowałem całą infrastrukturę od podstaw, dokumentacja pomogła mi nie raz, dlatego radzę się z nią przestudiować.
Do zarządzania chmurą można użyć interfejsu internetowego lub narzędzia konsoli – yc. Instalacja odbywa się za pomocą jednego polecenia (np. Linux i Mac OS):
curl https://storage.yandexcloud.net/yandexcloud-yc/install.sh | bashJeśli Twój specjalista ds. bezpieczeństwa wewnętrznego szaleje na punkcie uruchamiania skryptów z Internetu, to po pierwsze możesz otworzyć skrypt i go przeczytać, a po drugie uruchamiamy go pod naszym użytkownikiem - bez uprawnień roota.
Jeśli chcesz zainstalować klienta dla systemu Windows, możesz skorzystać z instrukcji a następnie wykonaj yc initaby w pełni go dostosować:
vozerov@mba:~ $ yc init
Welcome! This command will take you through the configuration process.
Please go to https://oauth.yandex.ru/authorize?response_type=token&client_id= in order to obtain OAuth token.
Please enter OAuth token:
Please select cloud to use:
[1] cloud-b1gv67ihgfu3bp (id = b1gv67ihgfu3bpt24o0q)
[2] fevlake-cloud (id = b1g6bvup3toribomnh30)
Please enter your numeric choice: 2
Your current cloud has been set to 'fevlake-cloud' (id = b1g6bvup3toribomnh30).
Please choose folder to use:
[1] default (id = b1g5r6h11knotfr8vjp7)
[2] Create a new folder
Please enter your numeric choice: 1
Your current folder has been set to 'default' (id = b1g5r6h11knotfr8vjp7).
Do you want to configure a default Compute zone? [Y/n]
Which zone do you want to use as a profile default?
[1] ru-central1-a
[2] ru-central1-b
[3] ru-central1-c
[4] Don't set default zone
Please enter your numeric choice: 1
Your profile default Compute zone has been set to 'ru-central1-a'.
vozerov@mba:~ $W zasadzie proces jest prosty – najpierw trzeba zdobyć token oauth do zarządzania chmurą, wybrać chmurę i folder, z którego będziemy korzystać.
Jeśli masz kilka kont lub folderów w tej samej chmurze, możesz utworzyć dodatkowe profile z oddzielnymi ustawieniami za pomocą funkcji tworzenia profilu yc config i przełączać się między nimi.
Oprócz powyższych metod zespół Yandex.Cloud napisał bardzo dobrze do zarządzania zasobami w chmurze. Ze swojej strony przygotowałem repozytorium git, w którym opisałem wszystkie zasoby, które zostaną utworzone w ramach artykułu - . Interesuje nas gałąź master, sklonujmy ją lokalnie:
vozerov@mba:~ $ git clone https://github.com/rebrainme/yandex-cloud-events/ events
Cloning into 'events'...
remote: Enumerating objects: 100, done.
remote: Counting objects: 100% (100/100), done.
remote: Compressing objects: 100% (68/68), done.
remote: Total 100 (delta 37), reused 89 (delta 26), pack-reused 0
Receiving objects: 100% (100/100), 25.65 KiB | 168.00 KiB/s, done.
Resolving deltas: 100% (37/37), done.
vozerov@mba:~ $ cd events/terraform/Wszystkie główne zmienne używane w terraformie są zapisane w pliku main.tf. Aby rozpocząć, utwórz plik private.auto.tfvars w folderze terraform z następującą zawartością:
# Yandex Cloud Oauth token
yc_token = ""
# Yandex Cloud ID
yc_cloud_id = ""
# Yandex Cloud folder ID
yc_folder_id = ""
# Default Yandex Cloud Region
yc_region = "ru-central1-a"
# Cloudflare email
cf_email = ""
# Cloudflare token
cf_token = ""
# Cloudflare zone id
cf_zone_id = ""Wszystkie zmienne można pobrać z listy konfiguracyjnej yc, ponieważ skonfigurowaliśmy już narzędzie konsoli. Radzę od razu dodać private.auto.tfvars do .gitignore, aby przypadkowo nie opublikować prywatnych danych.
W private.auto.tfvars określiliśmy także dane z Cloudflare - w celu utworzenia rekordów DNS i proxy głównej domeny event.kis.im na nasze serwery. Jeśli nie chcesz używać cloudflare, usuń inicjalizację dostawcy cloudflare w pliku main.tf i pliku dns.tf, który jest odpowiedzialny za utworzenie niezbędnych rekordów dns.
W naszej pracy połączymy wszystkie trzy metody - interfejs WWW, narzędzie konsolowe i terraform.
Sieci wirtualne
Szczerze mówiąc, możesz pominąć ten krok, ponieważ tworząc nową chmurę, automatycznie utworzysz oddzielną sieć i 3 podsieci - po jednej dla każdej strefy dostępności. Jednak nadal chcielibyśmy stworzyć dla naszego projektu osobną sieć z własną adresacją. Ogólny schemat działania sieci w Yandex.Cloud pokazano na poniższym rysunku (uczciwie zaczerpniętym z )
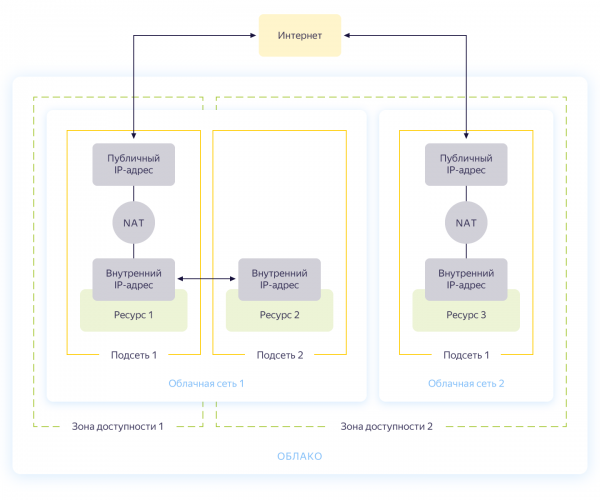
Tworzysz więc wspólną sieć, w ramach której zasoby mogą się ze sobą komunikować. Dla każdej strefy dostępności tworzona jest podsieć z własnym adresowaniem i połączona z siecią ogólną. Dzięki temu wszystkie znajdujące się w nim zasoby chmury mogą się ze sobą komunikować, nawet jeśli znajdują się w różnych strefach dostępności. Zasoby podłączone do różnych sieci chmurowych mogą się widzieć tylko poprzez adresy zewnętrzne. Swoją drogą, jak ta magia działa w środku, .
Tworzenie sieci opisano w pliku network.tf z repozytorium. Tam tworzymy jedną wspólną sieć prywatną wewnętrzną i podłączamy do niej trzy podsieci w różnych strefach dostępności - internal-a (172.16.1.0/24), internal-b (172.16.2.0/24), internal-c (172.16.3.0/24) ).
Zainicjuj terraformę i utwórz sieci:
vozerov@mba:~/events/terraform (master) $ terraform init
... skipped ..
vozerov@mba:~/events/terraform (master) $ terraform apply -target yandex_vpc_subnet.internal-a -target yandex_vpc_subnet.internal-b -target yandex_vpc_subnet.internal-c
... skipped ...
Plan: 4 to add, 0 to change, 0 to destroy.
Do you want to perform these actions?
Terraform will perform the actions described above.
Only 'yes' will be accepted to approve.
Enter a value: yes
yandex_vpc_network.internal: Creating...
yandex_vpc_network.internal: Creation complete after 3s [id=enp2g2rhile7gbqlbrkr]
yandex_vpc_subnet.internal-a: Creating...
yandex_vpc_subnet.internal-b: Creating...
yandex_vpc_subnet.internal-c: Creating...
yandex_vpc_subnet.internal-a: Creation complete after 6s [id=e9b1dad6mgoj2v4funog]
yandex_vpc_subnet.internal-b: Creation complete after 7s [id=e2liv5i4amu52p64ac9p]
yandex_vpc_subnet.internal-c: Still creating... [10s elapsed]
yandex_vpc_subnet.internal-c: Creation complete after 10s [id=b0c2qhsj2vranoc9vhcq]
Apply complete! Resources: 4 added, 0 changed, 0 destroyed.Świetnie! Stworzyliśmy naszą sieć i jesteśmy teraz gotowi na stworzenie naszych wewnętrznych usług.
Twórz maszyny wirtualne
Do przetestowania aplikacji wystarczy nam utworzenie dwóch maszyn wirtualnych – pierwszej będziemy potrzebować do zbudowania i uruchomienia aplikacji, drugiej do uruchomienia kafki, na której będziemy przechowywać przychodzące wiadomości. I stworzymy kolejną maszynę, na której skonfigurujemy Prometheusa do monitorowania aplikacji.
Maszyny wirtualne zostaną skonfigurowane przy użyciu ansible, więc przed uruchomieniem terraforma upewnij się, że masz jedną z najnowszych wersji ansible. I zainstaluj niezbędne role w Ansible Galaxy:
vozerov@mba:~/events/terraform (master) $ cd ../ansible/
vozerov@mba:~/events/ansible (master) $ ansible-galaxy install -r requirements.yml
- cloudalchemy-prometheus (master) is already installed, skipping.
- cloudalchemy-grafana (master) is already installed, skipping.
- sansible.kafka (master) is already installed, skipping.
- sansible.zookeeper (master) is already installed, skipping.
- geerlingguy.docker (master) is already installed, skipping.
vozerov@mba:~/events/ansible (master) $Wewnątrz folderu ansible znajduje się przykładowy plik konfiguracyjny .ansible.cfg, którego używam. Może się przydać.
Przed utworzeniem maszyn wirtualnych upewnij się, że masz uruchomionego agenta ssh i dodany klucz ssh, w przeciwnym razie terraform nie będzie mógł połączyć się z utworzonymi maszynami. Oczywiście natknąłem się na błąd w systemie OS X: . Aby temu zapobiec, dodaj małą zmienną do env przed uruchomieniem Terraform:
vozerov@mba:~/events/terraform (master) $ export OBJC_DISABLE_INITIALIZE_FORK_SAFETY=YESW folderze z terraformem tworzymy niezbędne zasoby:
vozerov@mba:~/events/terraform (master) $ terraform apply -target yandex_compute_instance.build -target yandex_compute_instance.monitoring -target yandex_compute_instance.kafka
yandex_vpc_network.internal: Refreshing state... [id=enp2g2rhile7gbqlbrkr]
data.yandex_compute_image.ubuntu_image: Refreshing state...
yandex_vpc_subnet.internal-a: Refreshing state... [id=e9b1dad6mgoj2v4funog]
An execution plan has been generated and is shown below.
Resource actions are indicated with the following symbols:
+ create
... skipped ...
Plan: 3 to add, 0 to change, 0 to destroy.
... skipped ...Jeśli wszystko zakończyło się pomyślnie (a tak powinno być), wówczas będziemy mieli trzy maszyny wirtualne:
- build - maszyna do testowania i budowania aplikacji. Docker został zainstalowany automatycznie przez Ansible.
- monitoring - zainstalowana na nim maszyna monitorująca - prometheus i grafana. Login/hasło standardowe: admin/admin
- kafka to mała maszyna z zainstalowaną kafką, dostępna na porcie 9092.
Upewnijmy się, że wszystkie są na swoim miejscu:
vozerov@mba:~/events (master) $ yc compute instance list
+----------------------+------------+---------------+---------+---------------+-------------+
| ID | NAME | ZONE ID | STATUS | EXTERNAL IP | INTERNAL IP |
+----------------------+------------+---------------+---------+---------------+-------------+
| fhm081u8bkbqf1pa5kgj | monitoring | ru-central1-a | RUNNING | 84.201.159.71 | 172.16.1.35 |
| fhmf37k03oobgu9jmd7p | kafka | ru-central1-a | RUNNING | 84.201.173.41 | 172.16.1.31 |
| fhmt9pl1i8sf7ga6flgp | build | ru-central1-a | RUNNING | 84.201.132.3 | 172.16.1.26 |
+----------------------+------------+---------------+---------+---------------+-------------+
Zasoby są na miejscu i stąd możemy uzyskać ich adresy IP. W dalszej części będę używać adresów IP do łączenia się przez ssh i testowania aplikacji. Jeśli masz konto Cloudflare połączone z terraformem, możesz użyć świeżo utworzonych nazw DNS.
Nawiasem mówiąc, podczas tworzenia maszyny wirtualnej podawany jest wewnętrzny adres IP i wewnętrzna nazwa DNS, dzięki czemu można uzyskać dostęp do serwerów w sieci po nazwie:
ubuntu@build:~$ ping kafka.ru-central1.internal
PING kafka.ru-central1.internal (172.16.1.31) 56(84) bytes of data.
64 bytes from kafka.ru-central1.internal (172.16.1.31): icmp_seq=1 ttl=63 time=1.23 ms
64 bytes from kafka.ru-central1.internal (172.16.1.31): icmp_seq=2 ttl=63 time=0.625 ms
^C
--- kafka.ru-central1.internal ping statistics ---
2 packets transmitted, 2 received, 0% packet loss, time 1001ms
rtt min/avg/max/mdev = 0.625/0.931/1.238/0.308 msPrzyda nam się to do wskazania aplikacji punktu końcowego za pomocą kafk.
Składanie aplikacji
Świetnie, są serwery, jest aplikacja - pozostaje ją tylko złożyć i opublikować. Do kompilacji użyjemy zwykłej kompilacji dokera, ale jako magazyn obrazów wykorzystamy usługę Yandex - rejestr kontenerów. Ale najpierw najważniejsze.
Kopiujemy aplikację na maszynę budującą, logujemy się przez ssh i montujemy obraz:
vozerov@mba:~/events/terraform (master) $ cd ..
vozerov@mba:~/events (master) $ rsync -av app/ ubuntu@84.201.132.3:app/
... skipped ...
sent 3849 bytes received 70 bytes 7838.00 bytes/sec
total size is 3644 speedup is 0.93
vozerov@mba:~/events (master) $ ssh 84.201.132.3 -l ubuntu
ubuntu@build:~$ cd app
ubuntu@build:~/app$ sudo docker build -t app .
Sending build context to Docker daemon 6.144kB
Step 1/9 : FROM golang:latest AS build
... skipped ...
Successfully built 9760afd8ef65
Successfully tagged app:latestPołowa sukcesu za nami - teraz możemy sprawdzić funkcjonalność naszej aplikacji uruchamiając ją i wysyłając do kafki:
ubuntu@build:~/app$ sudo docker run --name app -d -p 8080:8080 app /app/app -kafka=kafka.ru-central1.internal:9092</code>
С локальной машинки можно отправить тестовый event и посмотреть на ответ:
<code>vozerov@mba:~/events (master) $ curl -D - -s -X POST -d '{"key1":"data1"}' http://84.201.132.3:8080/post
HTTP/1.1 200 OK
Content-Type: application/json
Date: Mon, 13 Apr 2020 13:53:54 GMT
Content-Length: 41
{"status":"ok","partition":0,"Offset":0}
vozerov@mba:~/events (master) $Aplikacja odpowiedziała sukcesem nagrania i wskazaniem identyfikatora partycji oraz offsetu, w którym wiadomość została zawarta. Pozostało tylko utworzyć rejestr w Yandex.Cloud i wgrać tam nasz obraz (jak to zrobić za pomocą trzech linijek opisano w pliku rejestru.tf). Utwórz magazyn:
vozerov@mba:~/events/terraform (master) $ terraform apply -target yandex_container_registry.events
... skipped ...
Plan: 1 to add, 0 to change, 0 to destroy.
... skipped ...
Apply complete! Resources: 1 added, 0 changed, 0 destroyed.Istnieje kilka sposobów uwierzytelniania w rejestrze kontenerów — przy użyciu tokenu OAuth, tokenu IAM lub klucza konta usługi. Więcej szczegółów na temat tych metod można znaleźć w dokumentacji. . Będziemy używać klucza konta usługi, więc tworzymy konto:
vozerov@mba:~/events/terraform (master) $ terraform apply -target yandex_iam_service_account.docker -target yandex_resourcemanager_folder_iam_binding.puller -target yandex_resourcemanager_folder_iam_binding.pusher
... skipped ...
Apply complete! Resources: 3 added, 0 changed, 0 destroyed.Teraz pozostaje tylko zrobić do niego klucz:
vozerov@mba:~/events/terraform (master) $ yc iam key create --service-account-name docker -o key.json
id: ajej8a06kdfbehbrh91p
service_account_id: ajep6d38k895srp9osij
created_at: "2020-04-13T14:00:30Z"
key_algorithm: RSA_2048Otrzymujemy informację o identyfikatorze naszej przechowalni, przekazujemy klucz i logujemy się:
vozerov@mba:~/events/terraform (master) $ scp key.json ubuntu@84.201.132.3:
key.json 100% 2392 215.1KB/s 00:00
vozerov@mba:~/events/terraform (master) $ ssh 84.201.132.3 -l ubuntu
ubuntu@build:~$ cat key.json | sudo docker login --username json_key --password-stdin cr.yandex
WARNING! Your password will be stored unencrypted in /home/ubuntu/.docker/config.json.
Configure a credential helper to remove this warning. See
https://docs.docker.com/engine/reference/commandline/login/#credentials-store
Login Succeeded
ubuntu@build:~$Aby przesłać obraz do rejestru, potrzebujemy identyfikatora rejestru kontenerów, pobieramy go z narzędzia yc:
vozerov@mba:~ $ yc container registry get events
id: crpdgj6c9umdhgaqjfmm
folder_id:
name: events
status: ACTIVE
created_at: "2020-04-13T13:56:41.914Z"Następnie tagujemy nasz obraz nową nazwą i przesyłamy:
ubuntu@build:~$ sudo docker tag app cr.yandex/crpdgj6c9umdhgaqjfmm/events:v1
ubuntu@build:~$ sudo docker push cr.yandex/crpdgj6c9umdhgaqjfmm/events:v1
The push refers to repository [cr.yandex/crpdgj6c9umdhgaqjfmm/events]
8c286e154c6e: Pushed
477c318b05cb: Pushed
beee9f30bc1f: Pushed
v1: digest: sha256:1dd5aaa9dbdde2f60d833be0bed1c352724be3ea3158bcac3cdee41d47c5e380 size: 946Możemy sprawdzić, czy obraz został pomyślnie załadowany:
vozerov@mba:~/events/terraform (master) $ yc container repository list
+----------------------+-----------------------------+
| ID | NAME |
+----------------------+-----------------------------+
| crpe8mqtrgmuq07accvn | crpdgj6c9umdhgaqjfmm/events |
+----------------------+-----------------------------+Nawiasem mówiąc, jeśli zainstalujesz narzędzie yc na komputerze z systemem Linux, możesz użyć polecenia
yc container registry configure-dockeraby skonfigurować okno dokowane.
wniosek
Wykonaliśmy mnóstwo ciężkiej pracy i w rezultacie:
- Wymyśliliśmy architekturę naszej przyszłej usługi.
- Napisaliśmy aplikację w języku golang, która implementuje naszą logikę biznesową.
- Zebraliśmy to i wlaliśmy do prywatnego rejestru kontenerów.
W dalszej części przejdziemy do ciekawostek – wypuścimy naszą aplikację do produkcji i na koniec uruchomimy jej ładowanie. Nie przełączaj!
Ten materiał znajduje się w nagraniu wideo otwartych warsztatów REBRAIN & Yandex.Cloud: Akceptujemy 10 000 żądań na sekundę w Yandex Cloud -
Jeśli jesteś zainteresowany udziałem w tego typu wydarzeniach online i zadawaniem pytań w czasie rzeczywistym, połącz się z nami.
Chcielibyśmy szczególnie podziękować Yandex.Cloud za możliwość zorganizowania takiego wydarzenia. Link do nich -
Jeśli musisz przenieść się do chmury lub masz pytania dotyczące swojej infrastruktury, .
PS Mamy 2 bezpłatne audyty miesięcznie, być może Twój projekt będzie jednym z nich.
Źródło: www.habr.com
