

Opowiem wam dziś historię. Historia ewolucji technologii komputerowej i powstawania zdalnych miejsc pracy od czasów starożytnych do dnia dzisiejszego.
Rozwój IT
Najważniejsza rzecz, jaką można wynieść z historii IT to…

Oczywiste jest, że rozwój IT ma charakter spiralny. Te same decyzje i koncepcje, które porzucono dziesiątki lat temu, nabierają nowego znaczenia i zaczynają skutecznie działać w nowych warunkach, przy nowych zadaniach i nowych możliwościach. Pod tym względem IT niczym nie różni się od innych dziedzin ludzkiej wiedzy i historii Ziemi jako całości.

Dawno temu, kiedy komputery były duże
„Myślę, że na świecie jest rynek, który wystarczyłby na około pięć komputerów” – powiedział w 1943 roku dyrektor generalny IBM Thomas Watson.
Wczesna technologia komputerowa była ogromna. Nie, to nieprawda, wczesna technologia była potworna, cyklopowa. Cała maszyna obliczeniowa zajmowała przestrzeń porównywalną z salą gimnastyczną i kosztowała absolutnie nierealną kwotę. Przykładem komponentów jest moduł RAM na pierścieniach ferrytowych (1964).

Moduł ten ma rozmiar 11 cm * 11 cm i pojemność 512 bajtów (4096 bitów). Szafa całkowicie wypełniona tymi modułami miała pojemność zaledwie porównywalną z pojemnością starożytnej dyskietki 3,5” (1.44 MB = 2950 modułów), ale zużywała całkiem sporo energii elektrycznej i nagrzewała się jak lokomotywa parowa.
Angielska nazwa debugowania kodu programu, „debugging”, wiąże się z jego ogromnymi rozmiarami. Jedna z pierwszych programistek w historii, Grace Hopper (tak, kobieta), oficer marynarki wojennej, w 1945 r. zamieściła wpis w swoim dzienniku pokładowym po tym, jak zbadała pewien problem programistyczny.

Ponieważ ćma jest na ogół robakiem, wszystkie dalsze problemy i działania mające na celu ich rozwiązanie były zgłaszane kierownictwu przez personel jako „debugowanie”, tak więc nazwa „bug” była ściśle powiązana z awarią programu i błędem w kodzie, a debugowanie stało się debugowaniem.
W miarę rozwoju elektroniki, a w szczególności elektroniki półprzewodnikowej, rozmiary maszyn zaczęły się zmniejszać, podczas gdy moc obliczeniowa — wręcz przeciwnie — rosła. Ale nawet w tym przypadku nie było możliwe wyposażenie każdej osoby w komputer osobisty.
„Nie ma powodu, dla którego ktokolwiek chciałby trzymać komputer w domu”. — Ken Olsen, założyciel DEC, 1977.
W latach 70. pojawił się termin minikomputer. Pamiętam, że gdy wiele lat temu po raz pierwszy przeczytałem to określenie, wyobraziłem sobie coś w rodzaju netbooka, niemal palmtopa. Nie mógłbym być dalej od prawdy.

Mini jest tylko w porównaniu do ogromnych maszynowni, ale to nadal kilka szaf ze sprzętem kosztującym setki tysięcy i miliony dolarów. Jednak moc obliczeniowa komputerów wzrosła już na tyle, że nie zawsze były one w pełni wykorzystane, a jednocześnie komputery stały się dostępne dla studentów i profesorów uniwersyteckich.
I wtedy przyszedł ON!

Mało kto myśli o łacińskich korzeniach języka angielskiego, ale to właśnie ten język umożliwił nam zdalny dostęp do świata w formie, jaką znamy dzisiaj. Terminus (łac.) - koniec, granica, meta. Celem Terminatora T800 było zakończenie życia Johna Connora. Wiemy również, że stacje transportowe, gdzie pasażerowie wsiadają i wysiadają lub gdzie ładowane i rozładowywane są towary, nazywane są terminalami – końcowymi miejscami tras.
W ten sposób zrodziła się koncepcja dostępu do terminala i możemy zobaczyć najsłynniejszy terminal na świecie, który nadal żyje w naszych sercach.

Urządzenie DEC VT100 nazywane jest terminalem, ponieważ kończy linię danych. Posiada praktycznie zerową moc obliczeniową, a jego jedynym zadaniem jest wyświetlanie informacji otrzymanych z maszyny głównej i przesyłanie danych wprowadzanych z klawiatury do maszyny. I choć VT100 fizycznie już dawno przestały istnieć, nadal w pełni z nich korzystamy.
Nasze dni
Zacząłbym liczyć „nasze dni” od początku lat 80., od momentu, w którym pierwsze procesory o znaczącej mocy obliczeniowej stały się powszechnie dostępne. Tradycyjnie uważa się, że głównym procesorem tamtej epoki był procesor Intel 8088 (rodzina x86), będący podstawą zwycięskiej architektury. Jaka jest zasadnicza różnica w stosunku do koncepcji lat 70.?
Po raz pierwszy pojawia się tendencja do przenoszenia przetwarzania informacji z centrum na peryferie. Nie wszystkie zadania wymagają niesamowitej (w porównaniu ze słabą architekturą x86) mocy komputera mainframe lub nawet minikomputera. Firma Intel nie zatrzymała się w miejscu, już w latach 90. wypuściła na rynek rodzinę Pentium, która stała się pierwszym prawdziwie masowo produkowanym procesorem domowym w Rosji. Te procesory potrafią już naprawdę wiele: nie tylko pisać listy, ale też obsługiwać multimedia i pracować z niewielkimi bazami danych. W rzeczywistości małe firmy w ogóle nie potrzebują serwerów — wszystko można wykonywać na urządzeniach peryferyjnych, na komputerach klienckich. Z roku na rok procesory stają się coraz wydajniejsze, a różnica między serwerami a komputerami osobistymi pod względem mocy obliczeniowej jest coraz mniejsza, często ograniczając się jedynie do redundancji zasilania, obsługi wymiany urządzeń podczas pracy i specjalnych przypadków montażu w szafach typu rack.
Jeśli porównamy nowoczesne procesory klienckie firmy Intel, które w latach 90. były „śmieszne” dla administratorów ciężkich serwerów, z superkomputerami z przeszłości, zaczniemy czuć się trochę nieswojo.
Przyjrzyjmy się starszemu mężczyźnie, który ma praktycznie tyle samo lat co ja. Cray X-MP/24 1984.

Maszyna ta należała do najlepszych superkomputerów 1984 roku, posiadała procesory 2 x 105 MHz i szczytową moc obliczeniową 400 MFlops (milionów operacji zmiennoprzecinkowych). Konkretna maszyna widoczna na zdjęciu znajdowała się w laboratorium kryptograficznym amerykańskiej NSA i była wykorzystywana do łamania kodów. Po przeliczeniu 15 milionów dolarów z 1984 roku na dolary z 2020 roku wartość ta wynosiłaby 37,4 miliona dolarów, czyli 93 500 dolarów za MFlops.

Komputer, na którym piszę ten tekst, ma procesor Core i5-7400 z 2017 roku, co wcale nie jest nowością, a nawet w roku, w którym został wydany, był to najmłodszy 4-rdzeniowy procesor do komputerów stacjonarnych średniej klasy. 4 rdzenie o częstotliwości bazowej 3.0 GHz (3.5 z Turbo Boost) i podwojenie wątków HyperThreading zapewniają od 19 do 47 GFlopsów mocy według różnych testów, przy cenie 16 tysięcy rubli za procesor. Jeśli zdecydujesz się na kompletny montaż samochodu, możesz założyć, że jego koszt wyniesie 750 USD (według cen i kursów walut z dnia 1 marca 2020 r.).
Ostatecznie otrzymujemy 50-120-krotną przewagę zupełnie przeciętnego procesora stacjonarnego nad superkomputerem z pierwszej dziesiątki z niedawnej przeszłości, a spadek jednostkowego kosztu MFlops staje się zupełnie monstrualny 10 / 93500 = 25 razy.
Zupełnie niejasne jest, dlaczego nadal potrzebujemy serwerów i scentralizowanego przetwarzania o takich możliwościach na peryferiach!
Skok odwrotny - spirala wykonała obrót
Stacje bezdyskowe
Pierwszym sygnałem, że offshoring obliczeniowy nie oznacza końca drogi, było pojawienie się technologii stacji roboczych bezdyskowych. Biorąc pod uwagę znaczne rozproszenie stanowisk pracy na terenie przedsiębiorstwa, a w szczególności na terenach zanieczyszczonych, kwestia zarządzania i obsługi tych stanowisk staje się bardzo trudna.

Pojawia się koncepcja „czasu korytarzowego” – procent czasu, w którym pracownik pomocy technicznej znajduje się na korytarzu, w drodze do pracownika mającego problem. Tym razem jest to czas płatny, ale zupełnie bezproduktywny. Awarie dysków twardych odegrały znaczącą rolę, zwłaszcza na obszarach skażonych. Wyjmijmy dysk ze stacji roboczej i wykonajmy wszystkie inne czynności za pośrednictwem sieci, łącznie z uruchomieniem systemu. Oprócz adresu z serwera DHCP, karta sieciowa otrzymuje również dodatkowe informacje - adres serwera TFTP (uproszczona usługa plików) i nazwę obrazu rozruchowego, ładuje go do pamięci RAM i uruchamia maszynę.
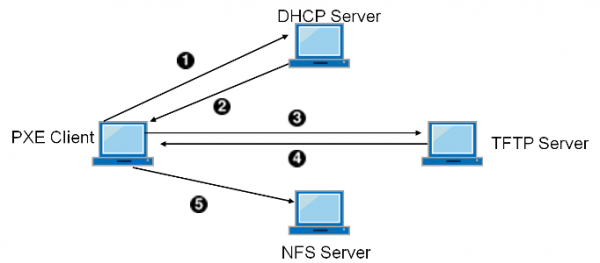
Oprócz mniejszej liczby awarii i skróconego czasu przejazdu, maszynę można teraz regulować bez konieczności debugowania na miejscu; Można przywieźć nowy egzemplarz i zabrać stary na diagnostykę do wyposażonego stanowiska pracy. Ale to nie wszystko!
Stacja bezdyskowa staje się o wiele bezpieczniejsza - jeśli nagle ktoś włamie się do budynku i zabierze wszystkie komputery, to będzie to tylko strata sprzętu. Na stacjach bezdyskowych nie przechowuje się żadnych danych.
Zapamiętajmy ten moment, bezpieczeństwo informacji zaczyna odgrywać coraz ważniejszą rolę po „beztroskim dzieciństwie” informatyki. A w branży IT coraz częściej pojawiają się przerażające, choć ważne 3 litery GRC (Governance, Risk, Compliance).
Serwery terminalowe
Rozwój coraz wydajniejszych komputerów osobistych na peryferiach znacznie wyprzedził rozwój publicznych sieci dostępowych. Klasyczne aplikacje klient-serwer z lat 90. i początku XXI wieku nie działały zbyt dobrze na wąskim kanale, jeśli wymiana danych osiągała znaczące wartości. Było to szczególnie trudne dla biur zdalnych, które łączyły się za pomocą modemu i linii telefonicznej, które również okresowo się zawieszały lub psuły. I…
Spirala zawróciła i wróciła do trybu terminalowego wraz z koncepcją serwerów terminalowych.
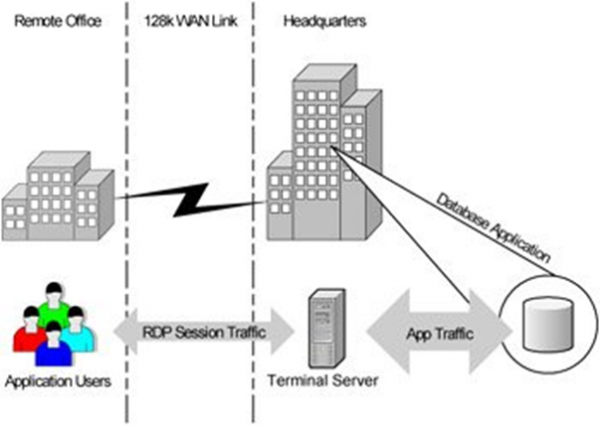
W zasadzie wróciliśmy do lat 70., kiedy nie było klientów i istniała scentralizowana moc obliczeniowa. Szybko stało się jasne, że oprócz czysto ekonomicznych implikacji kanałów, dostęp terminalowy oferuje ogromny potencjał bezpiecznego dostępu zewnętrznego, w tym pracy zdalnej dla pracowników, lub niezwykle ograniczonego i kontrolowanego dostępu dla kontrahentów z niezaufanych sieci i niezaufanych/niekontrolowanych urządzeń.
Jednakże serwery terminalowe, pomimo wszystkich swoich zalet i progresywności, miały również szereg wad – niską elastyczność, problem hałaśliwego sąsiada, a także ściśle serwerową Windows i tak dalej.
Narodziny Proto VDI

To prawda, że na początku i w połowie pierwszej dekady XXI wieku przemysłowa wirtualizacja platformy x86 była już w pełnym rozkwicie. Ktoś podsunął pomysł, który po prostu wisiał w powietrzu: zamiast centralizować wszystkich klientów w farmach terminali serwerowych, dajmy każdemu własną maszynę wirtualną z klientem. Windows i nawet dostęp administratora?
Odrzucenie grubych klientów
Równolegle z wirtualizacją sesji i systemu operacyjnego opracowano podejście mające na celu uproszczenie funkcji klienta na poziomie aplikacji.
Logika stojąca za tym była dość prosta, gdyż nie wszyscy mieli własne laptopy, nie wszyscy mieli dostęp do Internetu, a wielu mogło łączyć się z Internetem jedynie za pośrednictwem kawiarenek internetowych, mając, delikatnie mówiąc, bardzo ograniczone prawa. W zasadzie można było uruchomić jedynie przeglądarkę. Przeglądarka stała się nieodłącznym atrybutem systemu operacyjnego, a Internet stał się nieodłączną częścią naszego życia.
Innymi słowy, równolegle rozwijał się trend przenoszenia logiki od klienta do centrum w postaci aplikacji internetowych, do których dostęp wymagał jedynie najprostszego klienta, Internetu i przeglądarki.
I okazało się, że nie jesteśmy w punkcie wyjścia – z zerową liczbą klientów i centralnymi serwerami. Dotarliśmy tam kilkoma niezależnymi ścieżkami.

Infrastruktura wirtualnego pulpitu
Broker
W 2007 roku lider rynku wirtualizacji przemysłowej, firma VMware, wydała pierwszą wersję swojego produktu VDM (Virtual Desktop Manager), który stał się pierwszym produktem na rodzącym się rynku wirtualnych pulpitów. Oczywiście nie musieliśmy długo czekać na odpowiedź lidera rynku serwerów terminalowych, firmy Citrix, i już w 2008 roku, wraz z przejęciem XenSource, pojawił się XenDesktop. Oczywiście byli też inni sprzedawcy z własnymi propozycjami, ale nie zagłębiajmy się za bardzo w historię, odchodząc od koncepcji.
A koncepcja ta pozostaje aktualna. Kluczowym elementem VDI jest broker połączeń.
To serce infrastruktury wirtualnych pulpitów.
Broker odpowiada za najważniejsze procesy operacyjne VDI:
- Określa zasoby (maszyny/sesje) dostępne dla podłączonego klienta;
- W razie potrzeby równoważy konta klientów w pulach maszyn/sesji;
- Przekierowuje klienta do wybranego zasobu.
Obecnie klientem (terminalem) VDI może być praktycznie wszystko, co posiada ekran – laptop, smartfon, tablet, kiosk, klient cienki lub zerowy. A częścią odpowiedzialną, tą, która wykonuje obciążenie produkcyjne, jest sesja serwera terminalowego, maszyna fizyczna, maszyna wirtualna. Nowoczesne, dojrzałe produkty VDI są ściśle zintegrowane z infrastrukturą wirtualną i zarządzają nią automatycznie, wdrażając lub usuwając zbędne maszyny wirtualne.
Trochę na marginesie, ale dla niektórych klientów niezwykle ważną technologią VDI jest obsługa sprzętowej akceleracji grafiki 3D dla potrzeb projektantów i inżynierów.
Protokół
Drugą niezwykle ważną częścią dojrzałego rozwiązania VDI jest protokół dostępu do zasobów wirtualnych. Jeśli mówimy o pracy w ramach korporacyjnej sieci lokalnej z doskonałą niezawodną siecią 1 Gbps do miejsca pracy i opóźnieniem 1 ms, to można wziąć praktycznie dowolne i w ogóle o tym nie myśleć.
Trzeba pomyśleć o tym, kiedy połączenie odbywa się przez niekontrolowaną sieć, a jakość tej sieci może być absolutnie różna, aż do prędkości dziesiątek kilobitów i nieprzewidywalnych opóźnień. Świetnie nadają się do organizacji prawdziwej pracy zdalnej, z domków letniskowych, z domu, z lotnisk i restauracji.
Serwery terminalowe kontra maszyny wirtualne klientów
Wraz z pojawieniem się technologii VDI wydawało się, że nadszedł czas pożegnania się z serwerami terminalowymi. Po co są potrzebne, skoro każdy ma swoją własną maszynę wirtualną?
Jednak z punktu widzenia czystej ekonomii okazało się, że dla typowych masowych miejsc pracy, identycznych do znudzenia, nie ma nic wydajniejszego pod względem stosunku ceny do liczby sesji niż serwery terminalowe. Mimo wszystkich zalet podejście „1 użytkownik = 1 maszyna wirtualna” wymaga znacznie większych zasobów na sprzęt wirtualny i pełnoprawny system operacyjny, co pogarsza sytuację ekonomiczną w typowych miejscach pracy.
W przypadku stacji roboczych najwyższego szczebla zarządzania, niestandardowych i intensywnie użytkowanych stacji roboczych, konieczności posiadania wysokich uprawnień (nawet administratora), dedykowana maszyna wirtualna dla każdego użytkownika ma przewagę. W obrębie tej maszyny wirtualnej można indywidualnie przydzielać zasoby, przyznawać uprawnienia dowolnego poziomu oraz równoważyć maszyny wirtualne między hostami wirtualizacji przy dużym obciążeniu.
VDI i gospodarka
Od lat słyszę to samo pytanie – w jaki sposób VDI jest tańsze niż po prostu rozdawanie laptopów każdemu? I przez lata słyszałem dokładnie to samo: dla zwykłych pracowników biurowych VDI nie jest tańsze, jeśli weźmiemy pod uwagę same koszty dostarczenia sprzętu. Jakkolwiek na to nie spojrzeć, laptopy są coraz tańsze, ale serwery, systemy pamięci masowej i oprogramowanie systemowe kosztują już całkiem sporo pieniędzy. Jeśli nadszedł czas na unowocześnienie floty i uważasz, że możesz zaoszczędzić pieniądze, stosując VDI, odpowiedź brzmi: nie, nie uda Ci się.
Wspomniałem powyżej o przerażających trzech literach GRC - cóż, VDI dotyczy GRC. Chodzi o zarządzanie ryzykiem, bezpieczeństwo i wygodę kontrolowanego dostępu do danych. A wdrożenie tego wszystkiego na wielu różnych typach sprzętu zwykle wiąże się z dużymi kosztami. Dzięki VDI kontrola jest prostsza, bezpieczeństwo większe, a włosy stają się miękkie i jedwabiste.
Rozwiązania HPE do pracy zdalnej
Zarządzanie zdalne i w chmurze
iLO
Firma HPE nie jest nowicjuszem w dziedzinie zdalnego zarządzania infrastrukturą serwerową. To nie żart — legendarna firma iLO (Integrated Lights Out) skończyła w marcu 18 lat. Wspominając moje czasy administracyjne w latach 00., osobiście nie mógłbym być szczęśliwszy. Wszystko, co trzeba było zrobić w głośnym i zimnym centrum danych, to montaż szafy i okablowanie. Całą resztę konfiguracji, łącznie z ładowaniem systemu operacyjnego, można było wykonać w miejscu pracy, przy dwóch monitorach i kubku gorącej kawy. A to było 13 lat temu!

Serwery HPE nie bez powodu stanowią dziś niepodważalny, długoterminowy standard jakości, a złoty standard systemu zdalnego zarządzania iLO odgrywa w tym znaczącą rolę.
Chciałbym osobno odnotować działania HPE mające na celu utrzymanie kontroli ludzkości nad koronawirusem. , że co najmniej do końca 2020 roku licencja iLO Advanced będzie dostępna dla każdego za darmo.
Informacje
Jeśli w swojej infrastrukturze posiadasz więcej niż 10 serwerów i administratorowi to nie przeszkadza, to oczywiście system chmurowy HPE Infosight bazujący na sztucznej inteligencji będzie doskonałym uzupełnieniem standardowych narzędzi monitorujących. System nie tylko monitoruje stan i tworzy wykresy, ale także samodzielnie rekomenduje dalsze działania na podstawie bieżącej sytuacji i trendów.
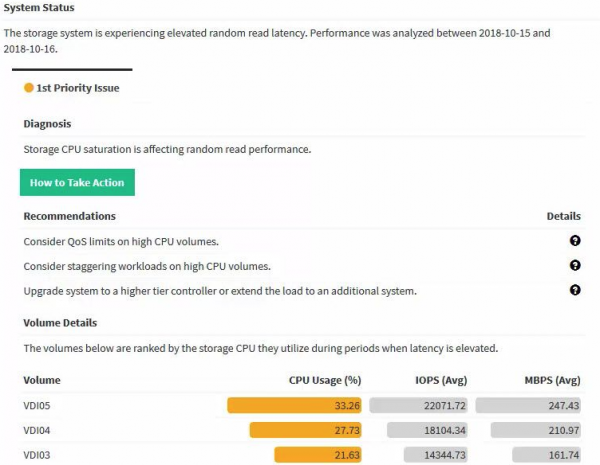
Bądź mądry, wypróbuj Infosight!
Jeden widok
Na koniec chciałbym wspomnieć o HPE OneView – całym portfolio produktów oferujących ogromne możliwości monitorowania i zarządzania całą infrastrukturą. I to wszystko bez wstawania od biurka, które w obecnej sytuacji pewnie znajduje się nawet na Twojej działce.
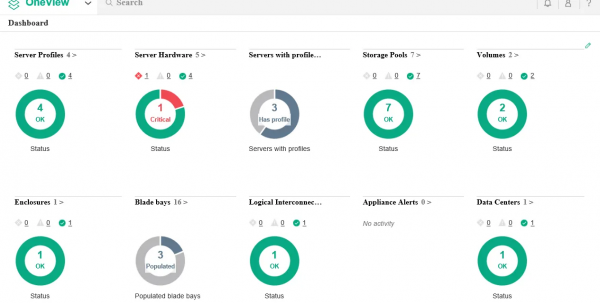
Systemy przechowywania również nie są łatwe w obsłudze!
Oczywiście, wszystkie systemy pamięci masowej są zarządzane i monitorowane zdalnie - tak było wiele lat temu. Dlatego dziś chciałbym porozmawiać o czymś innym, a mianowicie o skupiskach metropolitalnych.
Klastry metra nie są nowością na rynku, ale właśnie dlatego nie cieszą się jeszcze dużą popularnością – bezwładność myślenia i pierwsze wrażenia robią swoje. Oczywiście, istniały już 10 lat temu, ale kosztowały tyle, co most żeliwny. Lata, które upłynęły od powstania pierwszych skupisk metropolitalnych, zmieniły branżę i dostępność technologii dla ogółu społeczeństwa.
Pamiętam projekty, w których części systemu pamięci masowej były specjalnie rozdzielone – osobno dla usług nadkrytycznych w klastrze metropolitalnym, osobno dla replikacji synchronicznej (kilkakrotnie tańsze).
W rzeczywistości w 2020 roku utworzenie klastra miejskiego nic Cię nie będzie kosztowało, jeśli zorganizujesz dwie witryny i kanały. Ale kanały wymagane do replikacji synchronicznej są dokładnie takie same, jak te wymagane w klastrach metropolitalnych. Licencjonowanie oprogramowania odbywa się już od dawna w pakietach, a replikacja synchroniczna wiąże się z klastrem metropolitalnym, a jedynym czynnikiem podtrzymującym przy życiu replikację jednokierunkową jest konieczność zorganizowania rozszerzonej sieci L2. A nawet wówczas poziom L2 nad L3 już jest w pełnym rozkwicie w całym kraju.
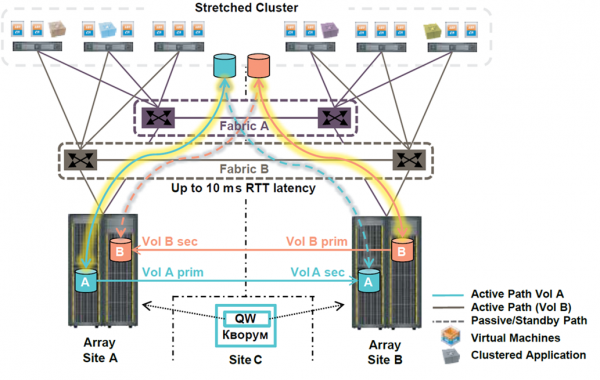
Jaka jest zatem zasadnicza różnica między replikacją synchroniczną a klastrem metropolitalnym z perspektywy pracy zdalnej?
Wszystko jest bardzo proste. Metroklaster działa automatycznie, zawsze, niemal natychmiast.
Jak wygląda proces przełączania obciążenia przy replikacji synchronicznej w infrastrukturze składającej się z co najmniej kilkuset maszyn wirtualnych?
- Odebrano sygnał alarmowy.
- Dyżur polega na analizie sytuacji – możesz spokojnie przeznaczyć od 10 do 30 minut na odebranie sygnału i podjęcie decyzji.
- Jeśli dyżurujący inżynierowie nie mają uprawnień do samodzielnego zainicjowania przełączenia, to śmiało poświęć kolejne 30 minut na skontaktowanie się z osobą posiadającą takie uprawnienia i formalne potwierdzenie rozpoczęcia przełączenia.
- Naciśnięcie dużego czerwonego przycisku.
- 10–15 minut na przekroczenie limitu czasu oraz ponowne montowanie woluminów i ponowną rejestrację maszyny wirtualnej.
- 30 minut na zmianę adresowania IP to optymistyczny szacunek.
- Na koniec uruchamiana jest maszyna wirtualna i uruchamiane są usługi produkcyjne.
Łącznie RTO (czas przywrócenia procesów biznesowych) można bezpiecznie oszacować na 4 godziny.
Porównajmy to z sytuacją w klastrze metropolitalnym.
- System pamięci masowej rozumie, że połączenie z ramieniem klastra metra zostało utracone - 15-30 sekund.
- Hosty wirtualizacji zdają sobie sprawę, że pierwsze centrum danych zostaje utracone - 15-30 sekund (jednocześnie z p 1).
- Automatyczne ponowne uruchomienie połowy do jednej trzeciej maszyn wirtualnych w drugim centrum danych na 10–15 minut przed załadowaniem usług.
- W tym momencie dyżurny zdaje sobie sprawę, co się stało.
Łącznie: RTO = 0 dla poszczególnych usług, ogólnie 10–15 minut.
Dlaczego restartuje tylko połowę lub jedną trzecią maszyny wirtualnej? Spójrz, co się dzieje:
- Wszystko robisz mądrze i włączasz automatyczne równoważenie maszyn wirtualnych. W rezultacie średnio tylko połowa maszyn wirtualnych działa w jednym z centrów danych. W końcu cała istota klastra metropolitalnego polega na minimalizacji przestojów, dlatego w Twoim interesie leży minimalizowanie liczby maszyn wirtualnych narażonych na ryzyko.
- Niektóre usługi można klastrować na poziomie aplikacji i rozmieszczać na różnych maszynach wirtualnych. Zatem te sparowane maszyny wirtualne są mocowane jedna po drugiej lub przypinane taśmą do różnych centrów danych, dzięki czemu w razie awarii usługa nie musi czekać na ponowne uruchomienie maszyny wirtualnej.
Dzięki dobrze zbudowanej infrastrukturze z rozbudowanymi klastrami metropolitalnymi użytkownicy biznesowi mogą pracować z minimalnymi opóźnieniami z dowolnego miejsca, nawet w razie awarii w centrum danych. W najgorszym przypadku opóźnienie będzie równe jednej filiżance kawy.
Oczywiście, klastry metropolitalne działają świetnie zarówno na platformie HPE 3Par, która zmierza w kierunku Valinoru, jak i na nowej platformie Primera!

Infrastruktura pracy zdalnej
Serwery terminalowe
Nie ma potrzeby wymyślania czegokolwiek nowego dla serwerów terminalowych; Od wielu lat HPE dostarcza im najlepsze serwery na świecie. Ponadczasową klasyką są DL360 (1U) lub DL380 (2U), a dla miłośników AMD – DL385. Oczywiście dostępne są również serwery typu blade, zarówno klasyczny C7000, jak i nowa, składana platforma Synergy.

Dla każdego gustu, dla każdego koloru, maksymalna liczba sesji na serwer!
„Klasyczna” prostota VDI + HPE
W tym przypadku, gdy mówię „klasyczny VDI”, mam na myśli koncepcję 1 użytkownika = 1 maszyny wirtualnej z klientem WindowsOczywiście, nie ma obciążenia bliższego lub bardziej zaznajomionego z systemami hiperkonwergentnymi niż VDI, szczególnie w kontekście deduplikacji i kompresji.

W tym zakresie HPE może zaoferować zarówno własną hiperkonwergentną platformę Simplivity, jak i serwery/certyfikowane węzły dla rozwiązań partnerskich, takich jak węzły VSAN Ready do budowy VDI w infrastrukturze VMware VSAN.
Porozmawiajmy trochę więcej o rozwiązaniu Simplivity. Na pierwszym planie, jak delikatnie sugeruje nazwa, znajduje się prostota. Łatwe do wdrożenia, łatwe do zarządzania, łatwe do skalowania.
Systemy hiperkonwergentne są jednym z najgorętszych tematów w dzisiejszym IT, a liczba dostawców na różnych poziomach wynosi około 40. Według magicznego kwadratu Gartnera, HPE znajduje się w pierwszej piątce na świecie i jest zaliczane do kwadratu liderów — tych, którzy rozumieją, w jakim kierunku rozwija się branża, i potrafią ucieleśnić tę wiedzę w sprzęcie.
Pod względem architektonicznym Simplivity jest klasycznym systemem hiperkonwergentnym z maszynami wirtualnymi opartymi na kontrolerach, co oznacza, że może obsługiwać różne hiperwizory, w przeciwieństwie do systemów zintegrowanych z hiperwizorami. Rzeczywiście, od kwietnia 2020 r. obsługiwane są VMware vSphere i Microsoft Hyper-V, a ogłoszono także plany wprowadzenia obsługi KVM. Kluczową cechą Simplivity od momentu jego wprowadzenia na rynek jest sprzętowe przyspieszenie kompresji i deduplikacji za pomocą dedykowanej karty akceleratora.
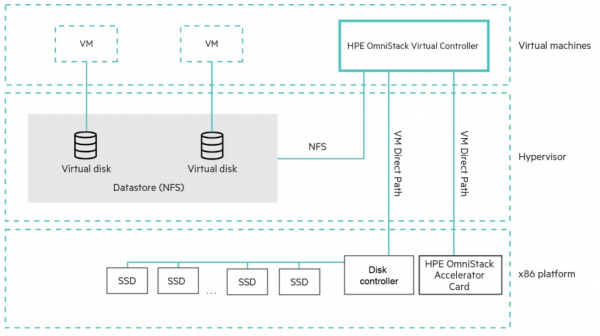
Należy pamiętać, że kompresja z deduplikacją ma charakter globalny i jest zawsze włączona, co oznacza, że nie jest to funkcja opcjonalna, a architektura rozwiązania.
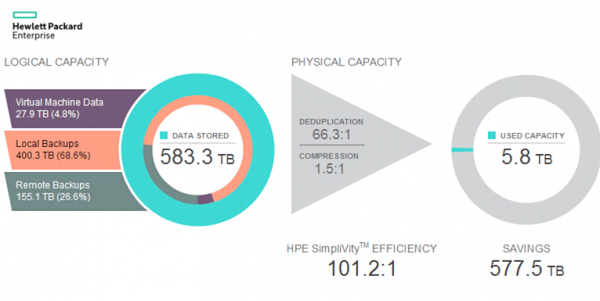
HPE oczywiście trochę nieszczerze twierdzi, że jego wydajność wynosi 100:1, ponieważ obliczył ją w specjalny sposób, ale efektywność wykorzystania przestrzeni jest w rzeczywistości bardzo wysoka. Po prostu liczba 100:1 jest zbyt piękna. Zastanówmy się, w jaki sposób technicznie zaimplementowano Simplivity, aby wyświetlać takie liczby.
Migawka. Migawki są w 100% poprawnie implementowane jako RoW (Redirect-on-Write), dzięki czemu powstają natychmiast i nie powodują spadku wydajności. Na przykład czym różnią się od innych systemów. Dlaczego potrzebujemy lokalnych migawek bez kar? Tak, to bardzo proste – można skrócić RPO z 24 godzin (średni RPO dla kopii zapasowych) do dziesiątek, a nawet minut.
backup. Migawka różni się od kopii zapasowej tylko tym, jak jest postrzegana przez system zarządzania maszyną wirtualną. Jeśli usunięcie maszyny powoduje usunięcie wszystkiego innego, to była to migawka. Jeśli coś pozostało, to jest to kopia zapasowa. W związku z tym każdą migawkę można uznać za pełną kopię zapasową, jeżeli została oznaczona w systemie i nie została usunięta.
Oczywiście, wiele osób zaprotestuje – co to za kopia zapasowa, skoro jest przechowywana w tym samym systemie? I tutaj mamy bardzo prostą odpowiedź w formie pytania ripostującego: powiedz mi, czy masz formalny model zagrożeń, który ustala zasady przechowywania kopii zapasowej? Jest to całkowicie uczciwa kopia zapasowa zabezpieczająca przed usunięciem pliku znajdującego się na maszynie wirtualnej. Jest to kopia zapasowa zabezpieczająca przed usunięciem samej maszyny wirtualnej. Jeśli chcesz przechowywać kopię zapasową wyłącznie w oddzielnym systemie, możesz replikować tę migawkę do drugiego klastra Simplivity lub do HPE StoreOnce.
I tu właśnie okazuje się, że tego typu architektura jest po prostu idealna dla każdego typu VDI. W końcu VDI to setki, a nawet tysiące bardzo podobnych maszyn z tym samym systemem operacyjnym i tymi samymi aplikacjami. Globalna deduplikacja rozdrobni to wszystko i skompresuje nawet nie w stosunku 100:1, ale znacznie lepiej. Wdrożyć 1000 maszyn wirtualnych na podstawie jednego szablonu? Nie stanowi to żadnego problemu, ale zarejestrowanie tych maszyn w vCenter potrwa dłużej niż ich klonowanie.
Seria Simplivity G została stworzona specjalnie dla użytkowników o szczególnych wymaganiach wydajnościowych oraz dla tych, którzy potrzebują akceleratorów 3D.

Seria ta nie korzysta ze sprzętowego akceleratora deduplikacji, dzięki czemu zmniejsza się liczba dysków na węzeł, dzięki czemu kontroler może obsługiwać tę funkcję programowo. Dzięki temu zwalniają się gniazda PCIe dla innych akceleratorów. Ilość dostępnej pamięci na węzeł została podwojona do 3 TB na potrzeby najbardziej wymagających obciążeń.

Prostota jest idealnym rozwiązaniem do organizowania rozproszonych geograficznie infrastruktur VDI z replikacją danych do centralnego ośrodka danych.
Tego rodzaju architektura VDI (i nie tylko VDI) jest szczególnie interesująca w kontekście rosyjskich realiów – ogromnych odległości (a więc i opóźnień) i dalekich od ideału kanałów. Tworzone są centra regionalne (lub nawet tylko 1–2 węzły Simplivity w całkowicie zdalnym biurze), w których lokalni użytkownicy łączą się za pomocą szybkich kanałów, zachowana jest pełna kontrola i zarządzanie z poziomu centrum, a do centrum replikowana jest tylko niewielka ilość prawdziwych, cennych i nieśmieciowych danych.
Oczywiście Simplivity jest w pełni zintegrowany z OneView i InfoSight.
Klienci ciency i zerowi
Urządzenia typu thin client to specjalistyczne rozwiązania przeznaczone wyłącznie do użytku jako terminale. Ponieważ klient nie ma praktycznie żadnego obciążenia poza obsługą kanału i dekodowaniem wideo, prawie zawsze jest dostępny procesor z pasywnym chłodzeniem, mały dysk rozruchowy przeznaczony wyłącznie do uruchamiania specjalnego systemu operacyjnego i to wszystko. Praktycznie nie ma w nim nic, co można by zniszczyć, a kradzież mija się z celem. Koszt jest niski i nie są w nim przechowywane żadne dane.
Istnieje specjalna kategoria klientów cienkich, tzw. klientów zerowych. Główną różnicą w stosunku do cienkich komputerów jest brak choćby ogólnego systemu operacyjnego i praca wyłącznie w oparciu o mikroprocesor z oprogramowaniem układowym. Często są one wyposażone w specjalne akceleratory sprzętowe do dekodowania strumieni wideo w protokołach terminalowych takich jak PCoIP czy HDX.
Pomimo podziału dużego koncernu Hewlett Packard na osobne HPE i HP, nie sposób nie wspomnieć o cienkich klientach produkowanych przez HP.
Wybór jest szeroki, dostosowany do każdego gustu i potrzeb - aż po stacje robocze z wieloma monitorami i sprzętową akceleracją strumieniowego przesyłania wideo.

Usługa HPE dla Twojej pracy zdalnej
Na koniec chciałbym wspomnieć o serwisie HPE. Wymienienie wszystkich poziomów usług i możliwości HPE zajęłoby zbyt wiele czasu, ale przynajmniej istnieje jedna niezwykle ważna oferta w środowisku pracy zdalnej. Mianowicie inżynier serwisu z HPE/autoryzowanego centrum serwisowego. Nadal pracujesz zdalnie, ze swojej ulubionej daczy, słuchając brzęczenia trzmieli, podczas gdy pszczoła z HPE, która przybyła do centrum danych, wymienia dyski lub naprawia zepsuty zasilacz w Twoich serwerach.
HPE Zadzwoń do domu
W dzisiejszych warunkach, przy ograniczeniach w przemieszczaniu się, funkcja Call Home staje się ważniejsza niż kiedykolwiek. Każdy system HPE wyposażony w tę funkcję może samodzielnie zgłosić awarię sprzętu lub oprogramowania do centrum wsparcia HPE. Jest całkiem możliwe, że część zamienna i/lub inżynier serwisowy dotrą do Ciebie na długo zanim zauważysz jakiekolwiek usterki lub problemy z produktywnością usług.
Osobiście gorąco polecam włączenie tej funkcji.
Źródło: www.habr.com
