

Okresowo pojawia się zadanie wyszukiwania powiązanych danych za pomocą zestawu kluczy, aż osiągniemy wymaganą liczbę rekordów.
Najbardziej „realnym” przykładem jest wywnioskowanie 20 najstarszych zadań, wymienione na liście pracowników (na przykład w ramach jednego działu). Podobny temat jest często wymagany w przypadku różnych paneli zarządczych zawierających krótkie podsumowania obszarów roboczych.

W tym artykule rozważymy implementację na PostgreSQL „naiwnego” rozwiązania takiego problemu, „mądrzejszego” i bardzo złożonego algorytmu „pętla” w SQL z warunkiem wyjścia opartym na znalezionych danych, które może być przydatne zarówno do ogólnego rozwoju, jak i do zastosowań w innych podobnych przypadkach.
Weźmy zestaw danych testowych z . Aby zapobiec „przeskakiwaniu” rekordów wyjściowych od czasu do czasu, gdy posortowane wartości się zgadzają, Rozszerzmy indeks tematyczny dodając klucz podstawowy. Jednocześnie nada mu to natychmiast unikalność i zagwarantuje nam jednoznaczną kolejność sortowania:
CREATE INDEX ON task(owner_id, task_date, id);
-- а старый - удалим
DROP INDEX task_owner_id_task_date_idx;Jest napisane tak, jak brzmi
Najpierw naszkicujmy najprostszą wersję żądania, przekazując identyfikatory wykonawców :
SELECT
*
FROM
task
WHERE
owner_id = ANY('{1,2,4,8,16,32,64,128,256,512}'::integer[])
ORDER BY
task_date, id
LIMIT 20; 
Trochę smutno – zamówiliśmy tylko 20 płyt, a Index Scan je nam odesłał 960 linii, które następnie należało posortować... Spróbujmy mniej czytać.
gniazdo + TABLICA
Pierwszą rzeczą, która nam pomoże, jest to, czy potrzebujemy łącznie 20 posortowanych rekordy, to wystarczy przeczytać nie więcej niż 20 posortowanych w tej samej kolejności dla każdego klawisz. Dobry, odpowiedni indeks (id_właściciela, data_zadania, id) mamy.
Zastosujmy ten sam mechanizm ekstrakcji i „obrótu kolumny” wpis do tabeli integralnej, jak w . Zastosujemy również składanie do tablicy za pomocą funkcji ARRAY():
WITH T AS (
SELECT
unnest(ARRAY(
SELECT
t
FROM
task t
WHERE
owner_id = unnest
ORDER BY
task_date, id
LIMIT 20 -- ограничиваем тут...
)) r
FROM
unnest('{1,2,4,8,16,32,64,128,256,512}'::integer[])
)
SELECT
(r).*
FROM
T
ORDER BY
(r).task_date, (r).id
LIMIT 20; -- ... и тут - тоже 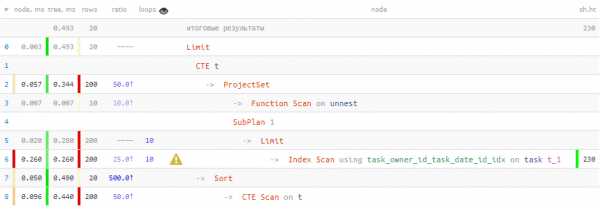
O, tak jest o wiele lepiej! O 40% szybciej i 4.5x mniej danych Musiałem to przeczytać.
Materializacja rekordów tabeli za pomocą CTEChciałbym zwrócić Państwa uwagę na fakt, że w niektórych przypadkach próba pracy z polami rekordu bezpośrednio po wyszukaniu ich w podzapytaniu, bez „opakowania” ich w CTE, może prowadzić do „mnożenie” InitPlan proporcjonalnie do liczby tych samych pól:
SELECT
((
SELECT
t
FROM
task t
WHERE
owner_id = 1
ORDER BY
task_date, id
LIMIT 1
).*);Result (cost=4.77..4.78 rows=1 width=16) (actual time=0.063..0.063 rows=1 loops=1)
Buffers: shared hit=16
InitPlan 1 (returns $0)
-> Limit (cost=0.42..1.19 rows=1 width=48) (actual time=0.031..0.032 rows=1 loops=1)
Buffers: shared hit=4
-> Index Scan using task_owner_id_task_date_id_idx on task t (cost=0.42..387.57 rows=500 width=48) (actual time=0.030..0.030 rows=1 loops=1)
Index Cond: (owner_id = 1)
Buffers: shared hit=4
InitPlan 2 (returns $1)
-> Limit (cost=0.42..1.19 rows=1 width=48) (actual time=0.008..0.009 rows=1 loops=1)
Buffers: shared hit=4
-> Index Scan using task_owner_id_task_date_id_idx on task t_1 (cost=0.42..387.57 rows=500 width=48) (actual time=0.008..0.008 rows=1 loops=1)
Index Cond: (owner_id = 1)
Buffers: shared hit=4
InitPlan 3 (returns $2)
-> Limit (cost=0.42..1.19 rows=1 width=48) (actual time=0.008..0.008 rows=1 loops=1)
Buffers: shared hit=4
-> Index Scan using task_owner_id_task_date_id_idx on task t_2 (cost=0.42..387.57 rows=500 width=48) (actual time=0.008..0.008 rows=1 loops=1)
Index Cond: (owner_id = 1)
Buffers: shared hit=4"
InitPlan 4 (returns $3)
-> Limit (cost=0.42..1.19 rows=1 width=48) (actual time=0.009..0.009 rows=1 loops=1)
Buffers: shared hit=4
-> Index Scan using task_owner_id_task_date_id_idx on task t_3 (cost=0.42..387.57 rows=500 width=48) (actual time=0.009..0.009 rows=1 loops=1)
Index Cond: (owner_id = 1)
Buffers: shared hit=4
Ten sam rekord został „przeszukany” 4 razy... Do czasu wydania PostgreSQL 11 takie zachowanie występowało regularnie i rozwiązaniem było „opakowanie” go w CTE, co stanowi absolutne ograniczenie dla optymalizatora w tych wersjach.
Akumulator rekurencyjny
W poprzedniej wersji przeczytaliśmy w sumie 200 linii dla potrzebnych 20. Już nie 960, ale jeszcze mniej - czy to możliwe?
Spróbujmy wykorzystać wiedzę, której potrzebujemy łącznie 20 dokumentacja. Oznacza to, że będziemy powtarzać odczyt danych aż do momentu, gdy osiągniemy potrzebną nam ilość.
Krok 1: Lista startowa
Oczywiste jest, że nasza „docelowa” lista 20 rekordów powinna zaczynać się od „pierwszych” rekordów dla jednego z naszych kluczy owner_id. Więc najpierw znajdźmy te „pierwszy” dla każdego z kluczy i dodajemy do listy, sortując w kolejności, w jakiej chcemy - (task_date, id).
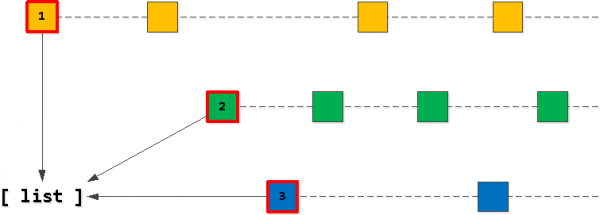
Krok 2: Znajdź „następne” rekordy
Teraz, jeśli weźmiemy pierwszy wpis z naszej listy i zaczniemy „krok” dalej wzdłuż indeksu jeśli klucz owner_id zostanie zachowany, wszystkie znalezione rekordy będą kolejnymi w wynikach selekcji. Oczywiście, tylko dopóki nie przekroczymy zastosowanego klucza drugi wpis na liście.
Jeżeli okaże się, że „przekroczyliśmy” drugi wpis, to ostatni przeczytany wpis powinien zostać dodany do listy zamiast pierwszego (z tym samym owner_id), po czym ponownie sortujemy listę.
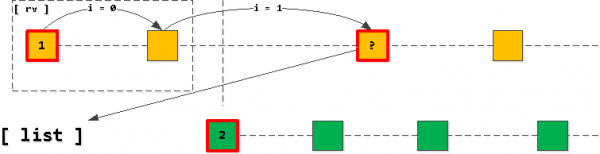
Czyli zawsze kończymy z tym, że lista nie ma więcej niż jednego wpisu dla każdego z kluczy (jeśli wpisy się wyczerpią i ich nie „skreślimy”, to pierwszy wpis po prostu zniknie z listy i nic nie zostanie dodane), a oni zawsze posortowane w kolejności rosnącej klucza aplikacji (task_date, id).
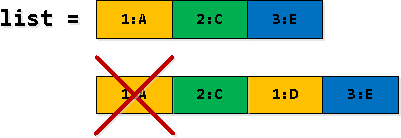
Krok 3: Filtruj i „rozwijaj” rekordy
W niektórych wierszach naszego wyboru rekurencyjnego niektóre rekordy rv zduplikowane - najpierw znajdujemy, np. „przekroczenie granicy 2. wpisu na liście”, a następnie podstawiamy je jako 1. wpis z listy. Tak więc pierwsze pojawienie się musi zostać odfiltrowane.
Straszne ostatnie zapytanie
WITH RECURSIVE T AS (
-- #1 : заносим в список "первые" записи по каждому из ключей набора
WITH wrap AS ( -- "материализуем" record'ы, чтобы обращение к полям не вызывало умножения InitPlan/SubPlan
WITH T AS (
SELECT
(
SELECT
r
FROM
task r
WHERE
owner_id = unnest
ORDER BY
task_date, id
LIMIT 1
) r
FROM
unnest('{1,2,4,8,16,32,64,128,256,512}'::integer[])
)
SELECT
array_agg(r ORDER BY (r).task_date, (r).id) list -- сортируем список в нужном порядке
FROM
T
)
SELECT
list
, list[1] rv
, FALSE not_cross
, 0 size
FROM
wrap
UNION ALL
-- #2 : вычитываем записи 1-го по порядку ключа, пока не перешагнем через запись 2-го
SELECT
CASE
-- если ничего не найдено для ключа 1-й записи
WHEN X._r IS NOT DISTINCT FROM NULL THEN
T.list[2:] -- убираем ее из списка
-- если мы НЕ пересекли прикладной ключ 2-й записи
WHEN X.not_cross THEN
T.list -- просто протягиваем тот же список без модификаций
-- если в списке уже нет 2-й записи
WHEN T.list[2] IS NULL THEN
-- просто возвращаем пустой список
'{}'
-- пересортировываем словарь, убирая 1-ю запись и добавляя последнюю из найденных
ELSE (
SELECT
coalesce(T.list[2] || array_agg(r ORDER BY (r).task_date, (r).id), '{}')
FROM
unnest(T.list[3:] || X._r) r
)
END
, X._r
, X.not_cross
, T.size + X.not_cross::integer
FROM
T
, LATERAL(
WITH wrap AS ( -- "материализуем" record
SELECT
CASE
-- если все-таки "перешагнули" через 2-ю запись
WHEN NOT T.not_cross
-- то нужная запись - первая из спписка
THEN T.list[1]
ELSE ( -- если не пересекли, то ключ остался как в предыдущей записи - отталкиваемся от нее
SELECT
_r
FROM
task _r
WHERE
owner_id = (rv).owner_id AND
(task_date, id) > ((rv).task_date, (rv).id)
ORDER BY
task_date, id
LIMIT 1
)
END _r
)
SELECT
_r
, CASE
-- если 2-й записи уже нет в списке, но мы хоть что-то нашли
WHEN list[2] IS NULL AND _r IS DISTINCT FROM NULL THEN
TRUE
ELSE -- ничего не нашли или "перешагнули"
coalesce(((_r).task_date, (_r).id) < ((list[2]).task_date, (list[2]).id), FALSE)
END not_cross
FROM
wrap
) X
WHERE
T.size < 20 AND -- ограничиваем тут количество
T.list IS DISTINCT FROM '{}' -- или пока список не кончился
)
-- #3 : "разворачиваем" записи - порядок гарантирован по построению
SELECT
(rv).*
FROM
T
WHERE
not_cross; -- берем только "непересекающие" записи 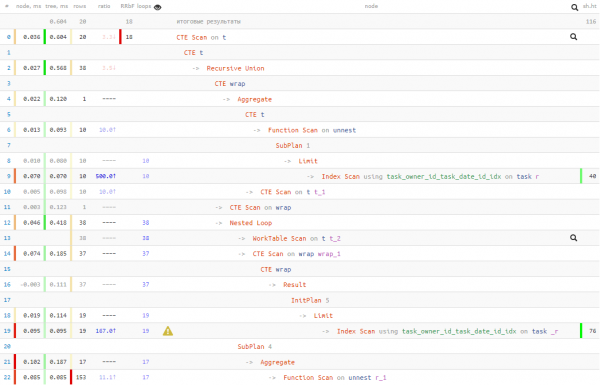
Tak więc my handlowano 50% odczytów danych za 20% czasu wykonania. Oznacza to, że jeśli masz powody sądzić, że odczyt może potrwać długo (na przykład dane często nie znajdują się w pamięci podręcznej i trzeba je pobrać z dysku), wówczas możesz w ten sposób mniej polegać na odczycie.
W każdym razie czas wykonania okazał się lepszy niż w „naiwnej” pierwszej wersji. Ale od Ciebie zależy, którą z tych 3 opcji wybierzesz.
Źródło: www.habr.com
