

Dzisiaj porozmawiamy o zasadach i modelach GitOps, a także o tym, jak te modele są implementowane na platformie OpenShift. Dostępny jest interaktywny przewodnik na ten temat .

W skrócie GitOps to zestaw praktyk umożliwiających wykorzystanie żądań ściągnięcia Git do zarządzania konfiguracją infrastruktury i aplikacji. Repozytorium Git w GitOps traktowane jest jako pojedyncze źródło informacji o stanie systemu, a wszelkie zmiany tego stanu są w pełni identyfikowalne i audytowalne.
Pomysł śledzenia zmian w GitOps nie jest nowy, podejście to od dawna stosowane jest niemal powszechnie podczas pracy z kodem źródłowym aplikacji. GitOps po prostu implementuje podobne funkcjonalności (recenzje, pull requesty, tagi itp.) w zarządzaniu infrastrukturą i konfiguracją aplikacji i zapewnia podobne korzyści jak w przypadku zarządzania kodem źródłowym.
Nie ma akademickiej definicji ani zatwierdzonego zestawu zasad GitOps, a jedynie zbiór zasad, na których zbudowana jest ta praktyka:
- Deklaratywny opis systemu przechowywany jest w repozytorium Git (konfiguracje, monitorowanie itp.).
- Zmiany stanu są wprowadzane za pomocą żądań ściągnięcia.
- Stan działających systemów jest dostosowywany do danych w repozytorium za pomocą żądań push Git.
Zasady GitOpsa
- Definicje systemów są opisane jako kod źródłowy
Konfiguracja systemu traktowana jest jak kod, dzięki czemu może być przechowywana i automatycznie wersjonowana w repozytorium Git, które służy jako pojedyncze źródło prawdy. Takie podejście ułatwia wdrażanie i wycofywanie zmian w systemach.
- Pożądany stan i konfiguracja systemów są ustawiane i wersjonowane w Git
Przechowując i wersjonując pożądany stan systemów w Git, jesteśmy w stanie łatwo wdrażać i wycofywać zmiany w systemach i aplikacjach. Za pomocą mechanizmów bezpieczeństwa Gita możemy także kontrolować własność kodu i weryfikować jego autentyczność.
- Zmiany konfiguracji można automatycznie zastosować za pomocą żądań ściągnięcia
Korzystając z żądań ściągnięcia Git, możemy łatwo kontrolować sposób stosowania zmian w konfiguracjach w repozytorium. Można je na przykład przekazać innym członkom zespołu do przeglądu lub przejść przez testy CI itp.
Jednocześnie nie ma potrzeby rozdzielania uprawnień administratora na lewo i prawo. Aby zatwierdzić zmiany w konfiguracji, użytkownicy potrzebują jedynie odpowiednich uprawnień w repozytorium Git, w którym przechowywane są te konfiguracje.
- Naprawienie problemu niekontrolowanego dryfu konfiguracji
Gdy już pożądany stan systemu zostanie zapisany w repozytorium Git, pozostaje nam jedynie znaleźć oprogramowanie, które zapewni, że bieżący stan systemu będzie zgodny ze stanem pożądanym. Jeżeli tak nie jest, to oprogramowanie to powinno – w zależności od ustawień – albo samodzielnie wyeliminować rozbieżność, albo powiadomić nas o zmianie konfiguracji.
Modele GitOps dla OpenShift
Narzędzie do uzgadniania zasobów w klastrze
Według tego modelu klaster posiada kontroler, który odpowiada za porównywanie zasobów Kubernetesa (plików YAML) znajdujących się w repozytorium Git z rzeczywistymi zasobami klastra. W przypadku wykrycia niezgodności administrator wysyła powiadomienia i ewentualnie podejmuje działania mające na celu skorygowanie niezgodności. Ten model GitOps jest używany w Anthos Config Management i Weaveworks Flux.
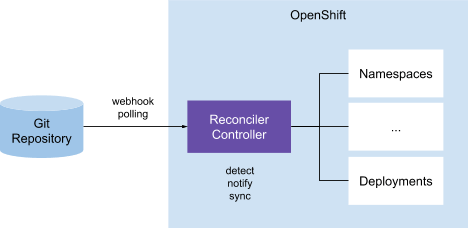
Urządzenie do uzgadniania zasobów zewnętrznych (Push)
Model ten można uznać za odmianę poprzedniego, gdy mamy jeden lub więcej kontrolerów odpowiedzialnych za synchronizację zasobów w parach „repozytorium Git – klaster Kubernetes”. Różnica polega na tym, że każdy zarządzany klaster niekoniecznie ma swój własny, oddzielny kontroler. Pary klastrów Git - k8s są często definiowane jako CRD (niestandardowe definicje zasobów), które mogą opisywać, w jaki sposób kontroler powinien przeprowadzać synchronizację. W ramach tego modelu kontrolerzy porównują repozytorium Git określone w CRD z zasobami klastra Kubernetes, które również są określone w CRD i na podstawie wyników porównania wykonują odpowiednie działania. W szczególności ten model GitOps jest używany w ArgoCD.
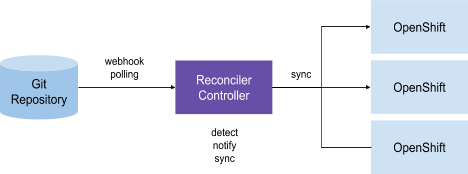
GitOps na platformie OpenShift
Administrowanie wieloklastrową infrastrukturą Kubernetes
Wraz z upowszechnieniem się Kubernetesa i rosnącą popularnością strategii wielochmurowych i obliczeń brzegowych, rośnie również średnia liczba klastrów OpenShift na klienta.
Na przykład w przypadku korzystania z przetwarzania brzegowego klastry jednego klienta mogą być wdrażane w setkach, a nawet tysiącach. W rezultacie jest zmuszony zarządzać kilkoma niezależnymi lub skoordynowanymi klastrami OpenShift w chmurze publicznej i on-premise.
W takim przypadku należy rozwiązać wiele problemów, w szczególności:
- Kontroluj, czy klastry są w identycznym stanie (konfiguracje, monitorowanie, magazyn itp.)
- Odtwórz (lub przywróć) klastry na podstawie znanego stanu.
- Utwórz nowe klastry na podstawie znanego stanu.
- Wdrażaj zmiany w wielu klastrach OpenShift.
- Wycofuj zmiany w wielu klastrach OpenShift.
- Połącz konfiguracje oparte na szablonach z różnymi środowiskami.
Konfiguracje aplikacji
W trakcie swojego cyklu życia aplikacje często przechodzą przez łańcuch klastrów (programowanie, etap itp.), zanim trafią do klastra produkcyjnego. Ponadto ze względu na wymagania dotyczące dostępności i skalowalności klienci często wdrażają aplikacje w wielu klastrach lokalnych lub wielu regionach platformy chmury publicznej.
W takim przypadku należy rozwiązać następujące zadania:
- Zapewnij przenoszenie aplikacji (plików binarnych, konfiguracji itp.) pomiędzy klastrami (programista, etap itp.).
- Wdrażaj zmiany w aplikacjach (pliki binarne, konfiguracje itp.) w kilku klastrach OpenShift.
- Cofnij zmiany w aplikacjach do poprzedniego znanego stanu.
Przypadki użycia OpenShift GitOps
1. Zastosowanie zmian z repozytorium Git
Administrator klastra może przechowywać konfiguracje klastrów OpenShift w repozytorium Git i automatycznie je stosować, aby bez wysiłku tworzyć nowe klastry i doprowadzać je do stanu identycznego ze znanym stanem przechowywanym w repozytorium Git.
2. Synchronizacja z Secret Managerem
Administrator skorzysta także z możliwości synchronizacji tajnych obiektów OpenShift z odpowiednim oprogramowaniem typu Vault, aby zarządzać nimi za pomocą specjalnie do tego stworzonych narzędzi.
3. Kontrola konfiguracji znoszenia
Administrator będzie przychylny tylko wtedy, gdy sam OpenShift GitOps zidentyfikuje i ostrzeże o rozbieżnościach pomiędzy konfiguracjami rzeczywistymi a tymi określonymi w repozytorium, aby móc szybko zareagować na dryf.
4. Powiadomienia o dryfie konfiguracyjnym
Są przydatne w przypadku, gdy administrator chce szybko poznać przypadki dryfowania konfiguracji, aby szybko samodzielnie podjąć odpowiednie działania.
5. Ręczna synchronizacja konfiguracji podczas driftu
Umożliwia administratorowi synchronizację klastra OpenShift z repozytorium Git w przypadku zmiany konfiguracji, aby szybko przywrócić klaster do poprzedniego znanego stanu.
6.Automatyczna synchronizacja konfiguracji podczas driftu
Administrator może także skonfigurować klaster OpenShift tak, aby automatycznie synchronizował się z repozytorium po wykryciu dryfu, dzięki czemu konfiguracja klastra zawsze będzie zgodna z konfiguracjami w Git.
7. Kilka klastrów – jedno repozytorium
Administrator może przechowywać konfiguracje kilku różnych klastrów OpenShift w jednym repozytorium Git i selektywnie je stosować w razie potrzeby.
8. Hierarchia konfiguracji klastrów (dziedziczenie)
Administrator może ustawić hierarchię konfiguracji klastrów w repozytorium (stage, prod, portfolio aplikacji itp. z dziedziczeniem). Innymi słowy, może określić, czy konfiguracje powinny zostać zastosowane do jednego, czy większej liczby klastrów.
Na przykład, jeśli administrator ustawi hierarchię „Klastry produkcyjne (prod) → Klastry Systemu X → Klastry produkcyjne systemu X” w repozytorium Git, wówczas do klastrów produkcyjnych systemu X zostanie zastosowana kombinacja następujących konfiguracji:
- Konfiguracje wspólne dla wszystkich klastrów produkcyjnych.
- Konfiguracje klastra System X.
- Konfiguracje klastra produkcyjnego systemu X.
9. Szablony i nadpisania konfiguracji
Administrator może zastąpić zestaw odziedziczonych konfiguracji i ich wartości, na przykład w celu dostrojenia konfiguracji dla określonych klastrów, do których zostaną one zastosowane.
10. Selektywne uwzględnianie i wykluczanie konfiguracji, konfiguracji aplikacji
Administrator może ustawić warunki stosowania lub niestosowania określonych konfiguracji do klastrów o określonych cechach.
11. Obsługa szablonów
Programiści skorzystają z możliwości wyboru sposobu definiowania zasobów aplikacji (Helm Chart, czysty yaml Kubernetes itp.), aby zastosować najbardziej odpowiedni format dla każdej konkretnej aplikacji.
Narzędzia GitOps na platformie OpenShift
ArgoCD
ArgoCD implementuje model uzgadniania zasobów zewnętrznych i oferuje scentralizowany interfejs użytkownika do organizowania relacji jeden do wielu pomiędzy klastrami i repozytoriami Git. Wady tego programu obejmują brak możliwości zarządzania aplikacjami, gdy ArgoCD nie działa.
Topnik
Flux implementuje model On-Cluster Resource Reconcile i w rezultacie nie ma scentralizowanego zarządzania repozytorium definicji, co jest słabym punktem. Z drugiej strony, właśnie ze względu na brak centralizacji, możliwość zarządzania aplikacjami pozostaje nawet w przypadku awarii jednego klastra.
Instalowanie ArgoCD na OpenShift
ArgoCD oferuje doskonały interfejs wiersza poleceń i konsolę internetową, więc nie będziemy tutaj omawiać Fluxa i innych alternatyw.
Aby wdrożyć ArgoCD na platformie OpenShift 4, wykonaj następujące kroki jako administrator klastra:
Wdrażanie komponentów ArgoCD na platformie OpenShift
# Create a new namespace for ArgoCD components
oc create namespace argocd
# Apply the ArgoCD Install Manifest
oc -n argocd apply -f https://raw.githubusercontent.com/argoproj/argo-cd/v1.2.2/manifests/install.yaml
# Get the ArgoCD Server password
ARGOCD_SERVER_PASSWORD=$(oc -n argocd get pod -l "app.kubernetes.io/name=argocd-server" -o jsonpath='{.items[*].metadata.name}')Ulepszenie serwera ArgoCD tak, aby był widoczny przez OpenShift Route
# Patch ArgoCD Server so no TLS is configured on the server (--insecure)
PATCH='{"spec":{"template":{"spec":{"$setElementOrder/containers":[{"name":"argocd-server"}],"containers":[{"command":["argocd-server","--insecure","--staticassets","/shared/app"],"name":"argocd-server"}]}}}}'
oc -n argocd patch deployment argocd-server -p $PATCH
# Expose the ArgoCD Server using an Edge OpenShift Route so TLS is used for incoming connections
oc -n argocd create route edge argocd-server --service=argocd-server --port=http --insecure-policy=RedirectWdrażanie narzędzia ArgoCD Cli
# Download the argocd binary, place it under /usr/local/bin and give it execution permissions
curl -L https://github.com/argoproj/argo-cd/releases/download/v1.2.2/argocd-linux-amd64 -o /usr/local/bin/argocd
chmod +x /usr/local/bin/argocdZmiana hasła administratora serwera ArgoCD
# Get ArgoCD Server Route Hostname
ARGOCD_ROUTE=$(oc -n argocd get route argocd-server -o jsonpath='{.spec.host}')
# Login with the current admin password
argocd --insecure --grpc-web login ${ARGOCD_ROUTE}:443 --username admin --password ${ARGOCD_SERVER_PASSWORD}
# Update admin's password
argocd --insecure --grpc-web --server ${ARGOCD_ROUTE}:443 account update-password --current-password ${ARGOCD_SERVER_PASSWORD} --new-password Po wykonaniu tych kroków możesz pracować z serwerem ArgoCD za pośrednictwem konsoli internetowej ArgoCD WebUI lub narzędzia wiersza poleceń ArgoCD Cli.
GitOps — nigdy nie jest za późno
„Pociąg odjechał” – tak mówią o sytuacji, w której przegapiono okazję do zrobienia czegoś. W przypadku OpenShift chęć natychmiastowego rozpoczęcia korzystania z tej nowej, fajnej platformy często stwarza dokładnie taką sytuację w przypadku zarządzania i utrzymywania tras, wdrożeń i innych obiektów OpenShift. Ale czy szansa zawsze jest całkowicie utracona?
Kontynuacja serii artykułów dot , dzisiaj pokażemy Ci, jak przekształcić ręcznie stworzoną aplikację i jej zasoby w proces, w którym wszystkim zarządzają narzędzia GitOps. Aby to zrobić, najpierw ręcznie wdrożymy aplikację httpd. Poniższy zrzut ekranu pokazuje, jak tworzymy przestrzeń nazw, wdrożenie i usługę, a następnie udostępniamy tę usługę w celu utworzenia trasy.
oc create -f https://raw.githubusercontent.com/openshift/federation-dev/master/labs/lab-4-assets/namespace.yaml
oc create -f https://raw.githubusercontent.com/openshift/federation-dev/master/labs/lab-4-assets/deployment.yaml
oc create -f https://raw.githubusercontent.com/openshift/federation-dev/master/labs/lab-4-assets/service.yaml
oc expose svc/httpd -n simple-appMamy więc ręcznie wykonaną aplikację. Teraz należy go przenieść pod zarządzanie GitOps bez utraty dostępności. W skrócie robi to tak:
- Utwórz repozytorium Git dla kodu.
- Eksportujemy nasze aktualne obiekty i przesyłamy je do repozytorium Git.
- Wybór i wdrożenie narzędzi GitOps.
- Do tego zestawu narzędzi dodajemy nasze repozytorium.
- Definiujemy aplikację w naszym narzędziu GitOps.
- Przeprowadzamy testowe uruchomienie aplikacji z wykorzystaniem zestawu narzędzi GitOps.
- Synchronizujemy obiekty za pomocą narzędzia GitOps.
- Włącz oczyszczanie i automatyczną synchronizację obiektów.
Jak już wspomniano w poprzednim , w GitOps istnieje jedno i tylko jedno źródło informacji o wszystkich obiektach w klastrze(ach) Kubernetes – repozytorium Git. Następnie wychodzimy z założenia, że Twoja organizacja korzysta już z repozytorium Git. Może być publiczny lub prywatny, ale musi być dostępny dla klastrów Kubernetes. Może to być to samo repozytorium, co dla kodu aplikacji, lub oddzielne repozytorium utworzone specjalnie na potrzeby wdrożeń. Zaleca się posiadanie ścisłych uprawnień w repozytorium, ponieważ będą tam przechowywane sekrety, trasy i inne rzeczy wrażliwe na bezpieczeństwo.
W naszym przykładzie utworzymy nowe publiczne repozytorium na GitHubie. Możesz to nazwać jak chcesz, my używamy nazwy blogpost.
Jeśli pliki obiektowe YAML nie były przechowywane lokalnie lub w Git, będziesz musiał użyć plików binarnych oc lub kubectl. Na poniższym zrzucie ekranu prosimy YAML o naszą przestrzeń nazw, wdrożenie, usługę i trasę. Wcześniej sklonowaliśmy nowo utworzone repozytorium i wprowadziliśmy do niego płytę CD.
oc get namespace simple-app -o yaml --export > namespace.yaml
oc get deployment httpd -o yaml -n simple-app --export > deployment.yaml
oc get service httpd -o yaml -n simple-app --export > service.yaml
oc get route httpd -o yaml -n simple-app --export > route.yamlTeraz zmodyfikujmy plik Deployment.yaml, aby usunąć pole, którego Argo CD nie może zsynchronizować.
sed -i '/sgeneration: .*/d' deployment.yamlPoza tym trzeba zmienić trasę. Najpierw ustawimy zmienną wielowierszową, a następnie zastąpimy ingress: null zawartością tej zmiennej.
export ROUTE=" ingress:
- conditions:
- status: 'True'
type: Admitted"
sed -i "s/ ingress: null/$ROUTE/g" route.yamlWięc uporządkowaliśmy pliki, pozostaje tylko zapisać je w repozytorium Git. Po czym to repozytorium stanie się jedynym źródłem informacji, a wszelkie ręczne zmiany obiektów powinny być surowo zabronione.
git commit -am ‘initial commit of objects’
git push origin masterDalej wychodzimy z faktu, że już wdrożyłeś ArgoCD (jak to zrobić - patrz poprzedni ). Dlatego do płyty Argo CD dodamy utworzone przez nas repozytorium zawierające kod aplikacji z naszego przykładu. Upewnij się tylko, że podałeś dokładnie repozytorium, które utworzyłeś wcześniej.
argocd repo add https://github.com/cooktheryan/blogpostTeraz utwórzmy aplikację. Aplikacja ustawia wartości tak, aby zestaw narzędzi GitOps rozumiał, jakiego repozytorium i ścieżek użyć, jakiego OpenShift potrzeba do zarządzania obiektami, która konkretna gałąź repozytorium jest potrzebna oraz czy zasoby powinny się automatycznie synchronizować.
argocd app create --project default
--name simple-app --repo https://github.com/cooktheryan/blogpost.git
--path . --dest-server https://kubernetes.default.svc
--dest-namespace simple-app --revision master --sync-policy none Po określeniu aplikacji na płycie CD Argo zestaw narzędzi rozpoczyna sprawdzanie już wdrożonych obiektów pod kątem definicji w repozytorium. W naszym przykładzie automatyczna synchronizacja i czyszczenie są wyłączone, więc elementy jeszcze się nie zmieniają. Należy pamiętać, że w interfejsie Argo CD nasza aplikacja będzie miała status „Brak synchronizacji”, ponieważ nie ma etykiety dostarczanej przez ArgoCD.
Dlatego też, gdy synchronizację rozpoczniemy nieco później, obiekty nie zostaną ponownie rozmieszczone.
Teraz wykonajmy uruchomienie testowe, aby upewnić się, że w naszych plikach nie ma błędów.
argocd app sync simple-app --dry-runJeśli nie ma błędów, możesz przystąpić do synchronizacji.
argocd app sync simple-appPo uruchomieniu polecenia argocd get w naszej aplikacji powinniśmy zobaczyć, że status aplikacji zmienił się na Zdrowy lub Zsynchronizowany. Będzie to oznaczać, że wszystkie zasoby w repozytorium Git odpowiadają teraz zasobom, które zostały już wdrożone.
argocd app get simple-app
Name: simple-app
Project: default
Server: https://kubernetes.default.svc
Namespace: simple-app
URL: https://argocd-server-route-argocd.apps.example.com/applications/simple-app
Repo: https://github.com/cooktheryan/blogpost.git
Target: master
Path: .
Sync Policy: <none>
Sync Status: Synced to master (60e1678)
Health Status: Healthy
... Teraz możesz włączyć automatyczną synchronizację i czyszczenie, aby mieć pewność, że nic nie zostanie utworzone ręcznie i że za każdym razem, gdy obiekt zostanie utworzony lub zaktualizowany w repozytorium, nastąpi wdrożenie.
argocd app set simple-app --sync-policy automated --auto-prune W ten sposób pomyślnie przejęliśmy kontrolę nad aplikacją GitOps, która początkowo w żaden sposób nie korzystała z GitOps.
Źródło: www.habr.com
