

Przed rozpoczęciem kursu Przygotowaliśmy dla Ciebie kolejne przydatne tłumaczenie.
Grafowe bazy danych to ważna technologia dla specjalistów od baz danych. Staram się śledzić nowinki i nowe technologie w tym obszarze i po pracy z relacyjnymi i NoSQLowymi bazami danych widzę, że rola grafowych baz danych staje się coraz większa. Podczas pracy ze złożonymi danymi hierarchicznymi nie tylko tradycyjne bazy danych, ale także NoSQL są nieefektywne. Często wraz ze wzrostem liczby poziomów łączy i rozmiaru bazy danych następuje spadek wydajności. W miarę jak relacje stają się bardziej złożone, rośnie również liczba połączeń JOIN.
Oczywiście w modelu relacyjnym istnieją rozwiązania do pracy z hierarchiami (na przykład z wykorzystaniem rekurencyjnych CTE), ale to wciąż obejścia. Jednocześnie funkcjonalność grafowych baz danych programu SQL Server ułatwia obsługę wielu poziomów hierarchii. Zarówno model danych, jak i zapytania są uproszczone, przez co zwiększa się ich efektywność. Znacznie zmniejsza ilość kodu.
Grafowe bazy danych to ekspresyjny język do reprezentowania złożonych systemów. Technologia ta jest już dość szeroko stosowana w branży IT w obszarach takich jak sieci społecznościowe, systemy antyfraudowe, analiza sieci IT, rekomendacje społecznościowe, rekomendacje produktów i treści.
Funkcjonalność bazy danych wykresów w programie SQL Server jest odpowiednia dla scenariuszy, w których dane są silnie połączone i mają dobrze zdefiniowane relacje.
Grafowy model danych
Graf to zbiór wierzchołków (węzłów, węzłów) i krawędzi (relacji, krawędzi). Wierzchołki reprezentują jednostki, a krawędzie reprezentują połączenia, których atrybuty mogą zawierać informacje.
Baza danych grafów modeluje jednostki jako graf, zgodnie z definicją w teorii grafów. Struktury danych to wierzchołki i krawędzie. Atrybuty to właściwości wierzchołków i krawędzi. Połączenie to połączenie wierzchołków.
W przeciwieństwie do innych modeli danych, grafowe bazy danych nadają priorytet relacjom między jednostkami. Dlatego nie ma potrzeby obliczania relacji przy użyciu kluczy obcych lub w inny sposób. Możliwe jest tworzenie złożonych modeli danych przy użyciu tylko abstrakcji wierzchołków i krawędzi.
W dzisiejszym świecie modelowanie relacji wymaga coraz bardziej wyrafinowanych technik. Aby modelować relacje, SQL Server 2017 oferuje funkcje bazy danych grafów. Wierzchołki i krawędzie grafu są reprezentowane jako nowe typy tablic: NODE i EDGE. Zapytania grafowe używają nowej funkcji T-SQL o nazwie PODAJ.POZYCJĘ(). Ponieważ ta funkcja jest wbudowana w SQL Server 2017, można jej używać w istniejących bazach danych bez konieczności jakiejkolwiek konwersji bazy danych.
Korzyści z modelu grafowego
W dzisiejszych czasach firmy i użytkownicy wymagają aplikacji, które pracują z coraz większą ilością danych, jednocześnie oczekując wysokiej wydajności i niezawodności. Graficzna reprezentacja danych oferuje wygodny sposób obsługi złożonych relacji. Takie podejście rozwiązuje wiele problemów i pomaga uzyskać wyniki w określonym kontekście.
Wygląda na to, że w przyszłości wiele aplikacji skorzysta z grafowych baz danych.
Modelowanie danych: od modelowania relacyjnego do modelowania grafowego
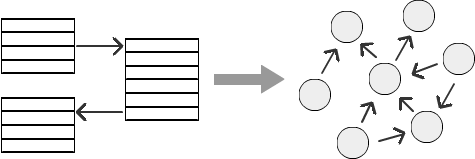
Przykład
Spójrzmy na przykład struktury organizacyjnej z hierarchią pracowników: pracownik podlega kierownikowi, kierownik podlega kierownikowi wyższego szczebla i tak dalej. W zależności od konkretnej firmy hierarchia ta może mieć dowolną liczbę poziomów. Ale wraz ze wzrostem liczby poziomów obliczanie relacji w relacyjnej bazie danych staje się coraz trudniejsze. Dość trudno sobie wyobrazić hierarchię pracowników, hierarchię w marketingu czy powiązaniach w mediach społecznościowych. Zobaczmy, jak SQL Graph może rozwiązać problem obsługi różnych poziomów hierarchii.
Na potrzeby tego przykładu utwórzmy prosty model danych. Utwórz tabelę pracowników EMP z identyfikatorem EMPNO i kolumna MGRA wskazujące na identyfikator szefa (kierownika) pracownika. Wszystkie informacje o hierarchii są przechowywane w tej tabeli i można je wyszukiwać za pomocą kolumn EMPNO и MGR.
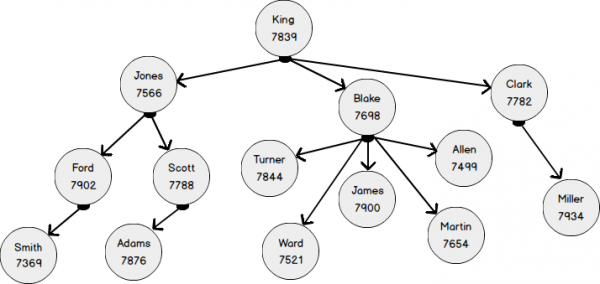
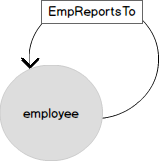
Na poniższym diagramie przedstawiono również ten sam model schematu organizacyjnego z czterema poziomami zagnieżdżenia w bardziej znanej formie. Pracownicy to wierzchołki grafu z tabeli EMP. Podmiot „pracownik” jest powiązany ze sobą relacją „zgłasza” (ReportsTo). W terminologii grafów łącze to krawędź (EDGE), która łączy węzły (NODE) pracowników.
Stwórzmy zwykłą tabelę EMP i dodaj tam wartości zgodnie z powyższym schematem.
CREATE TABLE EMP
(EMPNO INT NOT NULL,
ENAME VARCHAR(20),
JOB VARCHAR(10),
MGR INT,
JOINDATE DATETIME,
SALARY DECIMAL(7, 2),
COMMISIION DECIMAL(7, 2),
DNO INT)
INSERT INTO EMP VALUES
(7369, 'SMITH', 'CLERK', 7902, '02-MAR-1970', 8000, NULL, 2),
(7499, 'ALLEN', 'SALESMAN', 7698, '20-MAR-1971', 1600, 3000, 3),
(7521, 'WARD', 'SALESMAN', 7698, '07-FEB-1983', 1250, 5000, 3),
(7566, 'JONES', 'MANAGER', 7839, '02-JUN-1961', 2975, 50000, 2),
(7654, 'MARTIN', 'SALESMAN', 7698, '28-FEB-1971', 1250, 14000, 3),
(7698, 'BLAKE', 'MANAGER', 7839, '01-JAN-1988', 2850, 12000, 3),
(7782, 'CLARK', 'MANAGER', 7839, '09-APR-1971', 2450, 13000, 1),
(7788, 'SCOTT', 'ANALYST', 7566, '09-DEC-1982', 3000, 1200, 2),
(7839, 'KING', 'PRESIDENT', NULL, '17-JUL-1971', 5000, 1456, 1),
(7844, 'TURNER', 'SALESMAN', 7698, '08-AUG-1971', 1500, 0, 3),
(7876, 'ADAMS', 'CLERK', 7788, '12-MAR-1973', 1100, 0, 2),
(7900, 'JAMES', 'CLERK', 7698, '03-NOV-1971', 950, 0, 3),
(7902, 'FORD', 'ANALYST', 7566, '04-MAR-1961', 3000, 0, 2),
(7934, 'MILLER', 'CLERK', 7782, '21-JAN-1972', 1300, 0, 1)Poniższy rysunek przedstawia pracowników:
- pracownik z EMPNO 7369 jest podporządkowany 7902;
- pracownik z EMPNO 7902 podporządkowany 7566
- pracownik z EMPNO 7566 podporządkowany 7839
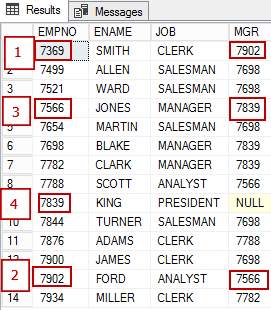
Przyjrzyjmy się teraz reprezentacji tych samych danych w postaci wykresu. Węzeł PRACOWNIK ma kilka atrybutów i jest powiązany ze sobą relacją „przesyła” (EmplReportsTo). EmplReportsTo to nazwa relacji.
Tabela krawędzi (EDGE) może również mieć atrybuty.
Utwórz tabelę węzłów EmpNode
Składnia tworzenia węzła jest dość prosta: do wyrażenia UTWÓRZ TABELĘ dodany na koniec JAKO WĘZEŁ.
CREATE TABLE dbo.EmpNode(
ID Int Identity(1,1),
EMPNO NUMERIC(4) NOT NULL,
ENAME VARCHAR(10),
MGR NUMERIC(4),
DNO INT
) AS NODE;Teraz przekonwertujmy dane ze zwykłej tabeli na wykres. Następny INSERT wstawia dane z tabeli relacyjnej EMP.
INSERT INTO EmpNode(EMPNO,ENAME,MGR,DNO) select empno,ename,MGR,dno from emp 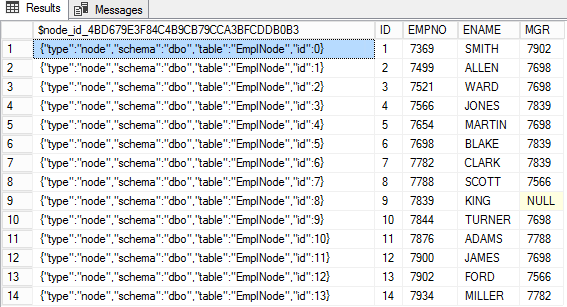
W tabeli węzłów w specjalnej kolumnie $node_id_* identyfikator hosta jest przechowywany jako JSON. Pozostałe kolumny tej tabeli zawierają atrybuty węzła.
Utwórz krawędzie (KRAWĘDŹ)
Tworzenie tabeli krawędzi jest bardzo podobne do tworzenia tabeli węzłów, z tą różnicą, że słowo kluczowe JAKO KRAWĘDŹ.
CREATE TABLE empReportsTo(Deptno int) AS EDGE 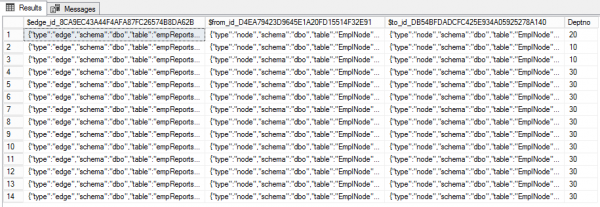
Teraz zdefiniujmy relacje między pracownikami za pomocą kolumn EMPNO и MGR. Schemat organizacyjny wyraźnie pokazuje, jak pisać INSERT.
INSERT INTO empReportsTo VALUES ((SELECT $node_id FROM EmpNode WHERE ID = 1),
(SELECT $node_id FROM EmpNode WHERE id = 13),20);
INSERT INTO empReportsTo VALUES ((SELECT $node_id FROM EmpNode WHERE ID = 2),
(SELECT $node_id FROM EmpNode WHERE id = 6),10);
INSERT INTO empReportsTo VALUES ((SELECT $node_id FROM EmpNode WHERE ID = 3),
(SELECT $node_id FROM EmpNode WHERE id = 6),10)
INSERT INTO empReportsTo VALUES ((SELECT $node_id FROM EmpNode WHERE ID = 4),
(SELECT $node_id FROM EmpNode WHERE id = 9),30);
INSERT INTO empReportsTo VALUES ((SELECT $node_id FROM EmpNode WHERE ID = 5),
(SELECT $node_id FROM EmpNode WHERE id = 6),30);
INSERT INTO empReportsTo VALUES ((SELECT $node_id FROM EmpNode WHERE ID = 6),
(SELECT $node_id FROM EmpNode WHERE id = 9),30);
INSERT INTO empReportsTo VALUES ((SELECT $node_id FROM EmpNode WHERE ID = 7),
(SELECT $node_id FROM EmpNode WHERE id = 9),30);
INSERT INTO empReportsTo VALUES ((SELECT $node_id FROM EmpNode WHERE ID = 8),
(SELECT $node_id FROM EmpNode WHERE id = 4),30);
INSERT INTO empReportsTo VALUES ((SELECT $node_id FROM EmpNode WHERE ID = 9),
(SELECT $node_id FROM EmpNode WHERE id = 9),30);
INSERT INTO empReportsTo VALUES ((SELECT $node_id FROM EmpNode WHERE ID = 10),
(SELECT $node_id FROM EmpNode WHERE id = 6),30);
INSERT INTO empReportsTo VALUES ((SELECT $node_id FROM EmpNode WHERE ID = 11),
(SELECT $node_id FROM EmpNode WHERE id = 8),30);
INSERT INTO empReportsTo VALUES ((SELECT $node_id FROM EmpNode WHERE ID = 12),
(SELECT $node_id FROM EmpNode WHERE id = 6),30);
INSERT INTO empReportsTo VALUES ((SELECT $node_id FROM EmpNode WHERE ID = 13),
(SELECT $node_id FROM EmpNode WHERE id = 4),30);
INSERT INTO empReportsTo VALUES ((SELECT $node_id FROM EmpNode WHERE ID = 14),
(SELECT $node_id FROM EmpNode WHERE id = 7),30); Tabela krawędzi ma domyślnie trzy kolumny. Pierwszy, $edge_id — identyfikator krawędzi w postaci JSON. Pozostałe dwa ($from_id и $to_id) reprezentują relacje między węzłami. Ponadto krawędzie mogą mieć dodatkowe właściwości. W naszym przypadku to Nr wydziału.
Widoki systemowe
W widoku systemowym sys.tables Są dwie nowe kolumny:
- is_edge
- is_node
SELECT t.is_edge,t.is_node,*
FROM sys.tables t
WHERE name like 'emp%' 
SMS-y
Obiekty związane z wykresami znajdują się w folderze Graph Tables. Ikona tabeli węzłów jest oznaczona kropką, a ikona tabeli krawędzi jest oznaczona dwoma połączonymi okręgami (co wygląda trochę jak okulary).
DOPASUJ wyrażenie
Wyrażenie MATCH zaczerpnięte z CQL (Cypher Query Language). Jest to skuteczny sposób badania właściwości wykresu. CQL zaczyna się od wyrażenia MATCH.
składnia
MATCH (<graph_search_pattern>)
<graph_search_pattern>::=
{<node_alias> {
{ <-( <edge_alias> )- }
| { -( <edge_alias> )-> }
<node_alias>
}
}
[ { AND } { ( <graph_search_pattern> ) } ]
[ ,...n ]
<node_alias> ::=
node_table_name | node_alias
<edge_alias> ::=
edge_table_name | edge_aliasПримеры
Spójrzmy na kilka przykładów.
Poniższe zapytanie wyświetla pracowników, którym podlega Smith i jego kierownik.
SELECT
E.EMPNO,E.ENAME,E.MGR,E1.EMPNO,E1.ENAME,E1.MGR
FROM
empnode e, empnode e1, empReportsTo m
WHERE
MATCH(e-(m)->e1)
and e.ENAME='SMITH' 
Poniższe zapytanie ma na celu znalezienie pracowników i kierowników drugiego stopnia dla firmy Smith. Jeśli usuniesz ofertę WHERE, to w wyniku zostaną wyświetleni wszyscy pracownicy.
SELECT
E.EMPNO,E.ENAME,E.MGR,E1.EMPNO,E1.ENAME,E1.MGR,E2.EMPNO,e2.ENAME,E2.MGR
FROM
empnode e, empnode e1, empReportsTo m ,empReportsTo m1, empnode e2
WHERE
MATCH(e-(m)->e1-(m1)->e2)
and e.ENAME='SMITH' 
I na koniec prośba do pracowników i managerów trzeciego stopnia.
SELECT
E.EMPNO,E.ENAME,E.MGR,E1.EMPNO,E1.ENAME,E1.MGR,E2.EMPNO,e2.ENAME,E2.MGR,E3.EMPNO,e3.ENAME,E3.MGR
FROM
empnode e, empnode e1, empReportsTo m ,empReportsTo m1, empnode e2, empReportsTo M2, empnode e3
WHERE
MATCH(e-(m)->e1-(m1)->e2-(m2)->e3)
and e.ENAME='SMITH' 
Teraz zmieńmy kierunek, by dopaść bossów Smitha.
SELECT
E.EMPNO,E.ENAME,E.MGR,E1.EMPNO,E1.ENAME,E1.MGR,E2.EMPNO,e2.ENAME,E2.MGR,E3.EMPNO,e3.ENAME,E3.MGR
FROM
empnode e, empnode e1, empReportsTo m ,empReportsTo m1, empnode e2, empReportsTo M2, empnode e3
WHERE
MATCH(e<-(m)-e1<-(m1)-e2<-(m2)-e3) 
wniosek
SQL Server 2017 ugruntował swoją pozycję jako kompletne rozwiązanie korporacyjne dla różnych biznesowych potrzeb IT. Pierwsza wersja SQL Graph jest bardzo obiecująca. Nawet pomimo pewnych ograniczeń, istnieje już wystarczająca funkcjonalność, aby zbadać możliwości wykresów.
Funkcjonalność SQL Graph jest w pełni zintegrowana z SQL Engine. Jednak, jak już wspomniano, SQL Server 2017 ma następujące ograniczenia:
Brak obsługi polimorfizmu.
- Obsługiwane są tylko łącza jednokierunkowe.
- Edges nie może aktualizować swoich kolumn $from_id i $to_id przez UPDATE.
- Zamknięcia przechodnie nie są obsługiwane, ale można je uzyskać za pomocą CTE.
- Ograniczona obsługa obiektów OLTP w pamięci.
- Tabele czasowe (tabela czasowa z wersjami systemowymi), tymczasowe tabele lokalne i globalne nie są obsługiwane.
- Typy tabel i zmienne tabel nie mogą być deklarowane jako NODE lub EDGE.
- Zapytania między bazami danych nie są obsługiwane.
- Nie ma bezpośredniego sposobu ani jakiegoś kreatora (kreatora) do konwersji zwykłych tabel na tabele wykresów.
- Nie ma GUI do wyświetlania wykresów, ale można użyć Power BI.
Czytaj więcej:
Źródło: www.habr.com
