

Cześć wszystkim. Poniżej znajduje się transkrypcja .
– system monitorowania różnych systemów i usług, za pomocą którego administratorzy systemów mogą zbierać informacje o bieżących parametrach systemów i konfigurować alerty, aby otrzymywać powiadomienia o odchyleniach w działaniu systemów.
Raport będzie zawierał porównanie и — projekty długoterminowego przechowywania metryk Prometheusa.



Najpierw opowiem wam o Prometeuszu. Jest to system monitorowania, który zbiera metryki z określonych celów i zapisuje je w pamięci lokalnej. Prometheus może rejestrować metryki w zdalnym magazynie oraz generować alerty i reguły rejestrowania.

Ograniczenia Prometeusza:
- Nie ma globalnego widoku zapytań. Dzieje się tak, gdy masz wiele niezależnych instancji Prometeusza. Zbierają metryki. Chcesz także wykonywać zapytania na podstawie wszystkich metryk zebranych z różnych instancji Prometheusa. Prometeusz na to nie pozwala.
- W przypadku Prometheusa wydajność jest ograniczona tylko do jednego serwera. Prometheus nie skaluje się automatycznie na wielu serwerach. Możesz jedynie ręcznie podzielić swoje cele pomiędzy wieloma Prometeuszami.
- Zakres metryk w Prometheusie jest ograniczony tylko do jednego serwera z tego samego powodu, dla którego nie można automatycznie skalować go na wielu serwerach.
- Zorganizowanie bezpieczeństwa danych w Prometheusie nie jest takie proste.

Rozwiązania tych problemów/wyzwań?
Rozwiązania to:
Wszystkie te rozwiązania służą do zdalnego przechowywania danych zebranych przez firmę Prometheus. Rozwiązują problem zdalnego przechowywania z poprzedniego slajdu na różne sposoby. W tej prezentacji omówię tylko dwa pierwsze rozwiązania: и .
Po raz pierwszy informacja o pojawił się przez . Jest tam opisana architektura i jak to działa.

Thanos pobiera dane, które Prometheus zapisał na dysku lokalnym i kopiuje je do S3, na który lub do innego magazynu obiektów.

W ten sposób Thanos zapewnia globalny widok zapytań. Możesz wysyłać zapytania do danych przechowywanych w pamięci obiektowej z wielu instancji Prometheusa.

Thanos obsługuje PromQL i .

Thanos używa kodu Prometeusza do przechowywania danych.

Thanos jest tworzony przez tych samych programistów, co Prometheus.
Про . Tutaj , o którym po raz pierwszy rozmawialiśmy .
VictoriaMetrics otrzymuje dane od kilku Prometeuszów protokół obsługiwany przez Prometheus.
VictoriaMetrics zapewnia globalny widok zapytań, ponieważ wiele instancji Prometheus może zapisywać dane w jednym VictoriaMetrics. W związku z tym możesz zadawać zapytania dotyczące wszystkich tych danych.

VictoriaMetrics obsługuje również, podobnie jak Thanos, PromQL i Prometheus API zapytań.

W przeciwieństwie do Thanos, kod źródłowy VictoriaMetrics jest napisany od podstaw i zoptymalizowany pod kątem szybkości i zużycia zasobów.

VictoriaMetrics, w przeciwieństwie do Thanos, skaluje się zarówno w pionie, jak i w poziomie. Jeść , który skaluje się w pionie. Możesz zacząć od jednego procesora i 1 GB pamięci i stopniowo rozwijać się do setek procesorów i 1 TB pamięci. VictoriaMetrics może korzystać ze wszystkich tych zasobów. Jego wydajność wzrośnie około 100 razy w porównaniu do systemu 1-rdzeniowego.

Historia Thanosa rozpoczęła się w listopadzie 2017 roku, kiedy pojawił się pierwszy publiczny commit. Wcześniej Thanos był rozwijany wewnętrznie .

W czerwcu 2019 ukazała się przełomowa wersja 0.5.0, w której protokół. Został usunięty z Thanosa, ponieważ nie radził sobie dobrze. Często klaster Thanos nie działał poprawnie, węzły do niego podłączały się niepoprawnie ze względu na protokół plotek. Dlatego postanowiliśmy go stamtąd usunąć. Myślę, że to słuszna decyzja.

W tym samym czerwcu 2019 przesłali numer wniosku в .

A po kilku miesiącach Thanos został przyjęty , który obejmuje Prometheus, Kubernetes i inne popularne projekty.

W styczniu 2018 roku rozpoczął się rozwój VictoriaMetrics.

We wrześniu 2018 po raz pierwszy publicznie wspomniałem o VictoriaMetrics.

W grudniu 2018 roku opublikowano wersję jednowęzłową.

W maju 2019 źródła zarówno wersji jednowęzłowej, jak i klastrowej.

W czerwcu 2019 podobnie jak Thanos złożyliśmy wniosek do fundacji CNCF pod numerem . Zgłosiliśmy się dzień przed zgłoszeniem Thanos.

Ale niestety nadal nie zostaliśmy tam przyjęci. Potrzebna pomoc społeczności.

Przyjrzyjmy się najważniejszym slajdom przedstawiającym architekturę Thanos i VictoriaMetrics.
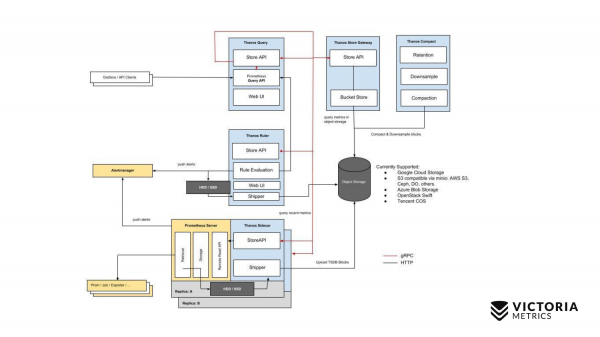
Zacznijmy od Thanosa. Żółte komponenty to komponenty Prometheusa. Cała reszta to komponenty Thanos. Zacznijmy od najważniejszego elementu. Thanos Sidecar to komponent instalowany obok każdego Prometheusa. Ładuje dane Prometheusa z pamięci lokalnej do S3 lub innej pamięci obiektowej.
Istnieje również komponent o nazwie Thanos Store Gateway, który może odczytywać te dane z Object Storage po przychodzących żądaniach z Thanos Query. Thanos Query implementuje PromQL i Prometheus API. Oznacza to, że z zewnątrz wygląda jak Prometeusz. Odbiera zapytania PromQL, wysyła je do Thanos Store Gateway, Thanos Store Gateway pobiera niezbędne dane z Object Storage i odsyła je z powrotem.
Jednak przechowujemy dane w Object Storage bez ostatnich dwóch godzin ze względu na funkcję implementacji Thanos Sidecar, która nie może przesłać ostatnich dwóch godzin do Object Storage S3, ponieważ Prometheus nie utworzył jeszcze plików dla tych dwóch godzin w pamięci lokalnej.
Jak postanowiłeś to obejść? Thanos Query oprócz żądań do Thanos Store Gateway wysyła równoległe żądania do każdego Thanos Sidecar, który znajduje się obok Prometheusa.
Z kolei Thanos Sidecar przekazuje żądania dalej do Prometeusza i pobiera dane z ostatnich dwóch godzin.
Oprócz tych komponentów istnieje również opcjonalny komponent, bez którego Thanos nie będzie działał dobrze. To Thanos Compact, który jest odpowiedzialny za łączenie małych plików w Object Storage w większe pliki, które zostały przesłane tutaj przez Thanos Sidecars. Thanos Sidecar przesyła tam pliki danych w ciągu dwóch godzin. Pliki te, jeśli nie zostaną połączone w większe pliki, wówczas ich liczba może bardzo znacząco wzrosnąć. Im więcej takich plików, tym więcej pamięci potrzeba dla Thanos Store Gateway, tym więcej zasobów potrzeba do przesyłania danych przez sieć i metadanych. Brama sklepu Thanos staje się nieskuteczna. Dlatego konieczne jest uruchomienie Thanos Compact, który łączy małe pliki w większe, aby było ich mniej i aby zmniejszyć obciążenie Thanos Store Gateway.
Istnieje również taki komponent jak Thanos Ruler. Wykonuje reguły ostrzegania Prometheusa i może oceniać reguły nagrywania Prometheusa w celu ponownego zapisania danych do Object Storage. Ale tego składnika nie zaleca się używać, ponieważ... On .
To jest prosty schemat Thanosa.
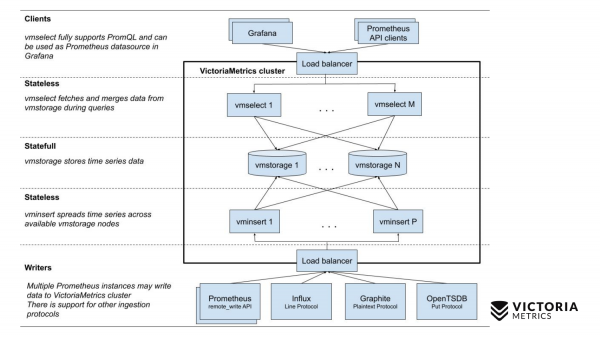
Porównajmy to teraz ze schematem VictoriaMetrics.
VictoriaMetrics ma 2 wersje: wersję jednowęzłową i klastrową. Pojedynczy węzeł działa na jednym komputerze. Pojedynczy węzeł nie ma tych komponentów, tylko jeden plik binarny. Ten plik binarny na slajdzie wygląda jak ten kwadrat. Wszystko, co znajduje się wewnątrz kwadratu, jest zawartością pliku binarnego wersji jednowęzłowej. Nie musisz o nim wiedzieć. Po prostu uruchamiasz plik binarny i wszystko działa dla nas.
Wersja klastra jest bardziej skomplikowana. Wewnątrz znajdują się trzy różne komponenty: vmselect, vminsert i vmstorage. Z ich nazwy powinno być jasne, czym każdy z nich się zajmuje. Komponent Insert akceptuje dane w różnych formatach: z API zdalnego zapisu Prometheus, protokołu liniowego Influx, protokołu Graphite i protokołu OpenTSDB. Komponent Insert akceptuje je, analizuje i dystrybuuje pomiędzy istniejącymi komponentami pamięci masowej, w których dane są już przechowywane. Komponent Select z kolei akceptuje zapytania PromQL. Wdraża , a także interfejs API zapytań Prometheus i może być używany jako zamiennik Prometheusa w Grafanie lub innych klientach API Prometheus. Select akceptuje żądanie promql, analizuje je, odczytuje dane niezbędne do wykonania tego żądania z węzłów magazynowania, przetwarza te dane i zwraca odpowiedź.

Porównajmy złożoność instalacji Thanos i VictoriaMetrics.

Zacznijmy od Thanosa. Zanim zaczniesz pracować z Thanosem, musisz utworzyć w Object Storage segment, taki jak S3 lub GCS, aby Thanos Sidecar mógł zapisywać w nim dane.

Następnie dla każdego Prometeusza musisz zainstalować Thanos Sidecar. Wcześniej należy pamiętać o wyłączeniu zagęszczania danych w Prometheusie. Kompaktowanie danych okresowo kompresuje dane w lokalnej pamięci Prometheus w celu zmniejszenia zużycia zasobów.
Kiedy instalujesz Thanos Sidecar na swoim Prometheusie, musisz wyłączyć tę funkcję zagęszczania danych, ponieważ Thanos Sidecar nie działa poprawnie po włączeniu zagęszczania danych. Oznacza to, że Twój Prometheus zaczyna zapisywać dane w dwugodzinnych blokach i przestaje łączyć te bloki w większe. W związku z tym, jeśli utworzysz zapytania trwające dłużej niż dwie ostatnie godziny, nie będą one działać tak wydajnie, jak mogłyby, gdyby włączono zagęszczanie danych.

Dlatego Thanos zaleca skrócenie czasu przechowywania danych w pamięci lokalnej do 6-8 godzin, aby zmniejszyć obciążenie związane z dużą liczbą małych bloków.
Po zainstalowaniu Thanos Sidecar musisz zainstalować dwa komponenty dla każdego pojemnika do przechowywania obiektów. Są to Thanos Compactor i Thanos Store Gateway.

Następnie musisz zainstalować Thanos Query i skonfigurować go tak, aby mógł łączyć się ze wszystkimi bramami Thanos Store, które posiadasz, a także mógł łączyć się ze wszystkimi Thanos Sidecars.
Tutaj może być mały problem.

Musisz skonfigurować niezawodne i bezpieczne połączenie Thanos Query z tymi komponentami. A jeśli Twój Prometheus znajduje się w różnych centrach danych lub w różnych VPC, wówczas połączenia z nimi z zewnątrz są zabronione. Ale aby Thanos Query zadziałało, musisz w jakiś sposób skonfigurować tam połączenie i znaleźć sposób.
Jeśli masz wiele takich centrów danych, odpowiednio zmniejsza się niezawodność całego systemu. Ponieważ Thanos Query musi stale utrzymywać połączenia ze wszystkimi Thanos Sidecars zlokalizowanymi w różnych centrach danych. Dla każdego przychodzącego żądania będzie kierowane do wszystkich wózków Thanos Sidecar. Jeśli połączenie zostanie przerwane, otrzymasz niekompletny zestaw danych lub otrzymasz odpowiedź „klaster nie działa”.

W VictoriaMetrics wszystko jest trochę prostsze. W przypadku wersji jednowęzłowej wystarczy uruchomić jeden plik binarny i wszystko działa.

W wersji klastrowej wystarczy uruchomić wszystkie trzy powyższe rodzaje komponentów w dowolnej ilości, jakiej potrzebujesz lub użyjesz do automatyzacji uruchamiania komponentów w Kubernetesie. Planujemy także wykonanie operatora Kubernetes. Tabela Helm nie obejmuje niektórych przypadków i pozwala strzelić sobie w stopę. Pozwala na przykład zmniejszyć liczbę węzłów magazynowania, co doprowadzi do utraty danych.

Po uruchomieniu wersji binarnej lub klastrowej wystarczy dodać Prometheusa do konfiguracji tak, aby rozpoczynał zapisywanie danych równolegle do pamięci lokalnej i pamięci zdalnej. Jak widać, ta konfiguracja powinna działać znacznie bardziej niezawodnie w porównaniu z konfiguracją Thanos. Nie musimy utrzymywać połączenia z VictoriaMetrics do wszystkich Prometheusów, ponieważ Prometheus sami łączą się z VictoriaMetrics i przesyłają dane.

Rozważmy wsparcie Thanos i VictoriaMetrics.

Thanos musi monitorować Sidecar, aby mieć pewność, że nie przestaną ładować danych do Object Storage. Mogą zatrzymać pobieranie danych z powodu błędów pobierania, na przykład połączenie sieciowe z Object Storage zostało tymczasowo przerwane lub Object Storage jest chwilowo niedostępne. Thanos Sidecar zauważy to w tym momencie, zgłosi błąd, może ulec awarii, a następnie przestać działać. Jeśli nie będziesz tego monitorował, zaprzestaniesz przesyłania danych do Object Storage. Jeśli czas przechowywania minie (zalecane 6-8 godzin), utracisz dane, które nie trafiły do Object Storage.

Zagęszczarki Thanos mogą przestać działać z powodu . Kompaktory pobierają dane z Object Storage i łączą je w większe fragmenty danych. Ponieważ kompaktory nie są zsynchronizowane z Sidecars, mogą się zdarzyć następujące zdarzenia: Sidecar nie miał jeszcze czasu na ukończenie bloku, Compactor uzna, że ten blok został w całości zapisany. Compactor zaczyna go czytać. Nie czyta bloku w całości i przestaje działać. Patrz szczegóły .

Store Gateway może zwracać niespójne dane z powodu wyścigów pomiędzy Compactor i Sidecars. To samo dzieje się tutaj, ponieważ Store Gateway nie jest w żaden sposób zsynchronizowany z Zagęszczarkami i Wózkami Bocznymi. W związku z tym mogą wystąpić warunki wyścigu, gdy Store Gateway nie widzi części danych lub widzi niepotrzebne dane.

Komponent Query w Thanos domyślnie zwraca częściowy wynik, jeśli niektóre przyczepy boczne lub bramy sklepu nie są w tej chwili dostępne. Otrzymasz część danych i nawet nie będziesz wiedział, że nie otrzymałeś wszystkich danych. Tak to działa domyślnie. W podobnej sytuacji VictoriaMetrics zwraca oznaczone dane jako częściowe.

W przeciwieństwie do Thanos, VictoriaMetrics rzadko traci dane. Nawet jeśli połączenie Prometheus z VictoriaMetrics zostanie przerwane, nie stanowi to problemu, ponieważ Prometheus w dalszym ciągu rejestruje przychodzące nowe dane w dzienniku zapisu z wyprzedzeniem, którego rozmiar wynosi 2 godziny. Jeśli w ciągu dwóch godzin przywrócisz połączenie z VictoriaMetrics, Twoje dane nie zostaną utracone. Prometeusz .

W przeciwieństwie do Thanos, który zapisuje dane do pamięci obiektowej dopiero po dwóch godzinach, Prometheus automatycznie replikuje dane przy użyciu protokołu zdalnego zapisu do zdalnej pamięci masowej, takiej jak VictoriaMetrics. Nie boisz się utraty lokalnego magazynu w Prometheusie. Jeśli nagle utraci pamięć lokalną, w najgorszym przypadku stracisz ostatnie sekundy danych, które nie miały czasu na zapisanie w pamięci zdalnej.

Kubernetes automatycznie zarządza klastrem, w przeciwieństwie do Thanos. Trudno jest umieścić wszystkie komponenty Thanos w jednym klastrze Kubernetes, w przeciwieństwie do komponentów klastra VictoriaMetrics.

VictoriaMetrics doczekało się bardzo prostej aktualizacji do nowej wersji. Po prostu zatrzymaj VictoriaMetrics, zaktualizuj pliki binarne i uruchom je. Po zatrzymaniu za pomocą sygnału SIGINT wszystkie pliki binarne VictoriaMetrics wykonują płynne zamknięcie. Prawidłowo zapisują niezbędne dane, poprawnie zamykają połączenia przychodzące, aby niczego nie stracić. Dzięki temu nic nie stracisz podczas aktualizacji.

VictoriaMetrics bardzo ułatwia rozszerzanie klastra. Wystarczy dodać niezbędne komponenty i kontynuować pracę.

O pułapkach w Thanosie i VictoriaMetrics.

Thanos ma następujące pułapki. Prometheus musi przechowywać dane z ostatnich dwóch godzin. Jeśli się zgubią, stracisz je całkowicie, ponieważ nie zostały jeszcze zapisane w Object Storage, tak jak S3.

Komponent Store Gateway i komponent kompaktora mogą wymagać dużej ilości pamięci do pracy z dużą pamięcią obiektową, jeśli jest tam przechowywanych wiele małych plików. Im większa liczba i rozmiar plików, tym więcej Store Gateway i kompaktora RAM potrzeba do przechowywania metainformacji. Thanos ma z tym wiele problemów .

Reklamowane jest, że Thanos skaluje się w nieskończoność w zależności od ilości posiadanego Prometeusza. To nie jest prawda. Ponieważ wszystkie żądania przechodzą przez komponent Query, który musi jednocześnie odpytywać wszystkie komponenty Store Gateway i wszystkie komponenty Sidecar, pobieraj stamtąd dane, a następnie je wstępnie przetwarzaj. Oczywiście prędkość żądania jest ograniczona przez najwolniejsze słabe łącze, najwolniejszą bramę sklepu lub najwolniejszy wózek boczny.
Elementy te mogą być nierównomiernie obciążone. Na przykład masz Prometheus, który zbiera miliony metryk na sekundę. Jest też Prometheus, który zbiera tysiące danych na sekundę. Prometheus, który gromadzi miliony metryk na sekundę, znacznie obciąża serwer, na którym działa. W związku z tym Sidecar działa tam wolniej. I ogólnie wszystko tam działa powoli. Komponent Query będzie bardzo powoli pobierał stamtąd dane. W związku z tym wydajność całego klastra będzie ograniczona przez ten powolny Sidecar.

Domyślnie Thanos udostępnia częściowe dane, jeśli niektóre przyczepy boczne i brama sklepu są niedostępne. Na przykład, jeśli Twoje Sidecary są rozproszone po całym świecie, w różnych centrach danych, prawdopodobieństwo awarii połączenia i niedostępności komponentów znacznie wzrasta. W związku z tym w większości przypadków otrzymasz częściowe dane, nawet o tym nie wiedząc.
VictoriaMetrics ma również pułapki. Pierwszą pułapką jest opcja ograniczająca ilość pamięci RAM wykorzystywanej przez pamięć podręczną VictoriaMetrics. Domyślnie jest to 60% pamięci RAM na komputerze, na którym działa VictoriaMetrics lub 60% pamięci RAM podu VictoriaMetrics w Kubernetesie.
Jeśli zmienisz tę wartość nieprawidłowo, możesz zrujnować wydajność VictoriaMetrics. Na przykład, jeśli ustawisz zbyt niską wartość, dane mogą nie mieścić się już w pamięci podręcznej VictoriaMetrics. Z tego powodu będzie musiała wykonać dodatkową pracę i załadować procesor i dysk. Jeśli ustawisz tę opcję na zbyt dużą, po pierwsze, zwiększy to prawdopodobieństwo, że VictoriaMetrics ulegnie awarii z powodu błędu braku pamięci, a po drugie, doprowadzi to do tego, że w pamięci systemu operacyjnego pozostanie bardzo mało pamięci RAM na pamięć podręczna plików. Wydajność VictoriaMetrics opiera się na pamięci podręcznej plików. Jeśli to nie wystarczy, obciążenie dysku może znacznie wzrosnąć. Dlatego rada: nie zmieniać parametru, jeśli nie jest to absolutnie konieczne.
Druga opcja. To jest okres retencji — okres domyślnie ustawiony na 1 miesiąc. Jest to czas przechowywania danych przez VictoriaMetrics. Po tym okresie VictoriaMetrics usuwa dane.
Wiele osób uruchamia VictoriaMetrics bez tego parametru i zapisuje dane przez miesiąc. A potem pytają: dlaczego zniknęły dane za poprzedni miesiąc? Ponieważ domyślny okres przechowywania wynosi 1 miesiąc. Dlatego musisz znać i ustawić prawidłowy okres przechowywania.

Przyjrzyjmy się unikalnym funkcjom.

Thanos ma funkcję zwaną próbkowaniem w dół: interwały 5-minutowe i godzinne, które często . Jeśli poszukasz w Google i spojrzysz na ich problem na githubie, istnieje wiele problemów związanych z tym próbkowaniem w dół, czasami nie działa ono poprawnie lub nie działa zgodnie z oczekiwaniami użytkowników.

Thanos posiada deduplikację danych dla par Prometheus HA. Kiedy dwóch Prometeuszów zbiera te same metryki od tych samych celów, a Thanos przechowuje je w Object Storage. W przeciwieństwie do VictoriaMetrics Thanos może prawidłowo deduplikować te dane.

Thanos ma komponent ostrzegawczy, który był na schemacie Thanosa. Ale on .

Thanos ma tę zaletę, że Thanos i Prometeusz mają ten sam kod. Thanos i Prometheus są opracowywane przez tych samych programistów. Dzięki ulepszeniom Thanosa lub Prometeusza druga strona wygrywa.

Główną funkcją VictoriaMetrics jest MetricsQL. Są to rozszerzenia VictoriaMetrics dla PromQL, o których mówiłem na poprzednim dużym spotkaniu monitorującym.

VictoriaMetrics obsługuje ładowanie danych przy użyciu wielu różnych protokołów. VictoriaMetrics może przyjmować dane nie tylko z Prometheusa, ale także za pośrednictwem protokołów Influx, OpenTSDB i Graphite.

Dane VictoriaMetrics zajmują znacznie mniej miejsca w porównaniu do Thanos i Prometheus.
Jeśli nagrywasz prawdziwe dane, użytkownicy mówią o 2-5-krotnym zmniejszeniu rozmiaru danych na dysku w porównaniu do Prometheusa i Thanos.

Kolejną zaletą VictoriaMetrics jest to, że jest zoptymalizowany pod kątem szybkości.

Spójrzmy na koszty infrastruktury.

Jedną z zalet Thanos jest to, że przechowuje dane w pamięci obiektowej, która jest stosunkowo tania.
Podczas przechowywania danych w pamięci obiektowej należy zapłacić za operacje zapisu i odczytu danych (10 USD za milion operacji). Zapisując dane do pamięci obiektowej, płacisz koszty hostingu za przesyłanie danych do Internetu; jeśli Twojego klastra nie ma w AWS, tam jest to bezpłatne. Odczytując dane, płacisz od 10 do 230 USD za 1 TB. Może to mieć znaczenie, jeśli często wysyłasz zapytania do danych historycznych z klastra Thanos.

W przypadku klastra Thanos trzeba zapłacić za serwery Compact, Store Gateway, komponenty Query wymagające dużej ilości pamięci i procesor dla dużych ilości danych.

VictoriaMetrics ma następujące wydatki. Jeśli przechowujesz dane na dyskach twardych GCE, cena za 40 TB wynosi 1 USD. W przypadku VictoriaMetrics wystarczą zwykłe dyski HDD, nie są potrzebne pięciokrotnie droższe dyski SSD. VictoriaMetrics jest zoptymalizowany pod kątem dysku twardego.

VictoriaMetrics wymaga serwerów dla komponentów: albo komponentów jednowęzłowych, albo klastrowych, które w przeciwieństwie do komponentów Thanos wymagają znacznie mniej procesora i pamięci RAM - i odpowiednio będą tańsze.

Przykłady realizacji.

Thanos ma przykład implementacji w Gitlabie. Gitlab działa całkowicie na Thanosie. Ale nie wszystko jest tam takie gładkie. Jeśli na nie spojrzysz , wtedy widać, że stale je mają : Za mało pamięci dla komponentów Store Gateway lub Query. Muszą stale zwiększać ilość pamięci.
Z tego powodu rosną koszty rozwiązania tych problemów.
Drugą realizacją, która może odnieść większy sukces, jest firma Improbable, która rozpoczęła prace nad Thanosem. Opublikowali kod źródłowy Thanos. Improbable to firma zajmująca się tworzeniem silników gier.

VictoriaMetrics ma przykłady wdrożeń publicznych:
- Kreator stron internetowych wix.com
- Adidas wdraża VictoriaMetrics i nawet przeprowadził prezentację na ostatnim PromCon 2019
- TrafficStars - sieć reklamowa
- Seznam.cz to popularna czeska wyszukiwarka.
A potem były jeszcze firmy bez nazwy, których nie potrafię teraz wymienić. Nie wyrazili zgody.
- Jeden z głównych twórców gier. Większy niż im Nieprawdopodobne.
- Główny programista oprogramowania graficznego.
- Duży rosyjski bank.
- Europejski producent turbin wiatrowych, który pomyślnie przetestował VictoriaMetrics. Ten producent wdraża VictoriaMetrics w celu monitorowania danych zebranych z turbin wiatrowych z szybkością 50 próbek na sekundę na czujnik. Każda turbina wiatrowa ma kilkaset czujników. Mają kilkaset turbin wiatrowych.
- Rosyjskie linie lotnicze, które chcą wdrożyć VictoriaMetrics, ale nadal nie mogą. Jesteśmy z nimi na etapie kontraktowania.
 Wnioski.
Wnioski.
VictoriaMetrics i Thanos rozwiązują podobne problemy, ale na różne sposoby:
- Globalny widok zapytania
- skalowanie poziome
- dowolne zatrzymanie

Dziękuję.
Czekamy na Ciebie w naszym .

W ankiecie mogą brać udział tylko zarejestrowani użytkownicy. , Proszę.
Czego używasz jako długoterminowego magazynu dla Prometheusa?
35,3%Thanos6
0,0%Korteks0
0,0%M3DB0
41,2%VictoriaMetrics7
23,5%inne4
Głosowało 17 użytkowników. 16 użytkowników wstrzymało się od głosu.
Źródło: www.habr.com
