

Dla osób zajmujących się technologią wykres Gartnera jest niczym pokaz haute couture. Dzięki temu możesz dowiedzieć się z wyprzedzeniem, jakie słowa będą najbardziej popularne w tym sezonie i co usłyszysz na nadchodzących konferencjach.
Odszyfrowaliśmy, co kryje się za pięknymi słowami w tej tabeli, dzięki czemu i Ty możesz mówić tym językiem.
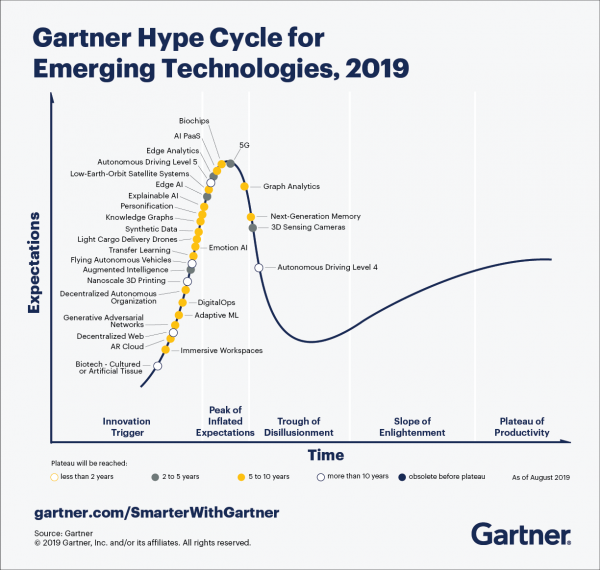
Najpierw kilka słów o tym, jaki to rodzaj wykresu. Co roku w sierpniu agencja konsultingowa Gartner publikuje raport – Gartner Hype Curve. W języku rosyjskim nazywa się to „krzywą szumu” lub, prościej, szumem medialnym. 30 lat temu raperzy z grupy Public Enemy śpiewali: „Nie wierz w szum medialny”. To, czy w to wierzysz, czy nie, to kwestia osobista, ale warto przynajmniej znać te słowa kluczowe, jeśli pracujesz w branży technologicznej i chcesz śledzić światowe trendy.
Oto wykres oczekiwań społecznych wobec konkretnej technologii. Według Gartnera, w idealnym przypadku technologia przechodzi przez pięć etapów: wprowadzenie na rynek, szczyt zawyżonych oczekiwań, dolina rozczarowania, szczyt oświecenia, płaskowyż produktywności. Ale zdarza się też, że tonie w „dolinie rozczarowania” – przykłady można sobie łatwo przypomnieć, weźmy te same bitcoiny: początkowo osiągnęły szczyt jako „pieniądze przyszłości”, ale szybko zaczęły spadać, gdy ujawniły się niedociągnięcia technologii, przede wszystkim ograniczenia liczby transakcji i szalona ilość energii elektrycznej potrzebnej do wygenerowania bitcoinów (co już pociąga za sobą problemy środowiskowe). Oczywiście nie możemy zapominać, że wykres Gartnera to tylko prognoza: tutaj na przykład można przeczytać szczegółową prognozę , w którym analizowane są najbardziej uderzające, niespełnione przewidywania.
Przyjrzyjmy się zatem nowemu wykresowi Gartnera. Technologie dzielą się na 5 dużych grup tematycznych:
- Zaawansowana sztuczna inteligencja i analityka
- Postklasyczne obliczenia i komunikacja
- Wyczuwanie i mobilność
- Rozszerzony Człowiek
- Ekosystemy cyfrowe
1. Zaawansowana sztuczna inteligencja i analityka
Ostatnie 10 lat było okresem największej popularności głębokiego uczenia się. Sieci te są naprawdę skuteczne w swoim zakresie zadań. W 2018 roku Yann LeCun, Geoffrey Hinton i Yoshua Bengio otrzymali za swoje odkrycia w tej dziedzinie Nagrodę Turinga – najbardziej prestiżową nagrodę, odpowiednik Nagrody Nobla w dziedzinie informatyki. Oto główne trendy w tym obszarze, które przedstawiono na wykresie:
1.1. Transfer uczenia się
Nie trenujesz sieci neuronowej od podstaw, ale bierzesz już wytrenowaną sieć i przypisujesz jej inny cel. Czasami wymaga to ponownego trenowania części sieci, ale nie całej sieci, co jest znacznie szybsze. Na przykład, biorąc gotową sieć neuronową ResNet50, wytrenowaną na zbiorze danych ImageNet1000, otrzymujemy algorytm zdolny do klasyfikowania wielu różnych obiektów według obrazu na bardzo głębokim poziomie (1000 klas w oparciu o cechy wygenerowane przez 50 warstw sieci neuronowej). Ale nie ma potrzeby trenowania całej sieci, bo zajęłoby to miesiące.
В Na przykład „Sieci neuronowe i komputerowe widzenie” firmy Samsung znalazły się w finale wraz z klasyfikacją talerzy na czyste i brudne, zaprezentowano podejście, które w ciągu 5 minut pozwala na stworzenie głębokiej sieci neuronowej zdolnej odróżniać talerze brudne od czystych, zbudowanej w oparciu o architekturę opisaną powyżej. Pierwotna sieć w ogóle nie wiedziała, co to są płyty, uczyła się dopiero odróżniać ptaki od psów (patrz ImageNet).

Źródło: Samsung „Sieci neuronowe i komputerowe widzenie”
W przypadku uczenia transferowego musisz wiedzieć, które podejścia są skuteczne i jakie gotowe, podstawowe architektury są dostępne. Ogólnie rzecz biorąc, znacznie przyspiesza to powstawanie praktycznych zastosowań uczenia maszynowego.
1.2. Sieci generatywne przeciwstawne (GAN)
Dotyczy to przypadków, w których trudno jest nam sformułować cel nauki. Im zadanie jest bliższe rzeczywistości, tym bardziej staje się dla nas zrozumiałe („przynieś szafkę nocną”), ale tym trudniej je sformułować jako zadanie techniczne. GAN jest tylko próbą pozbycia się tego problemu.
Mamy tu do czynienia z dwiema sieciami: jedna jest generatorem (Generative), a druga dyskryminatorem (Adversarial). Jedna sieć uczy się wykonywać pożyteczne prace (klasyfikować obrazy, rozpoznawać dźwięki, rysować kreskówki). A inna sieć uczy się uczyć inną sieć: ma prawdziwe przykłady i uczy się znajdować nieznany dotąd złożony wzór, pozwalający porównywać wyniki generowane przez część generatywną sieci z obiektami ze świata rzeczywistego (próbka treningowa) na podstawie naprawdę ważnych, głębokich cech: liczby oczu, bliskości stylu Miyazakiego, poprawnej wymowy języka angielskiego.

Przykład wyników działania sieci służącej do generowania postaci anime.
Ale oczywiście trudno jest tam budować architekturę. Samo rzucanie neuronami nie wystarczy, trzeba je też przygotować. A uczyć się trzeba tygodniami. Moi koledzy z Samsung AI Center pracują nad tematem GAN; jest to jedno z ich kluczowych pytań badawczych. Na przykład ten : wykorzystywanie sieci generatywnych do syntezy realistycznych zdjęć ludzi w różnych pozach — na przykład w celu stworzenia wirtualnej przymierzalni lub syntezy twarzy, co może ograniczyć ilość informacji, które muszą być przechowywane lub przesyłane, aby zapewnić wysokiej jakości komunikację wideo, transmisję lub ochronę prywatności.

1.3. Wyjaśnialna sztuczna inteligencja
W przypadku niektórych rzadkich zadań postęp w dziedzinie głębokich architektur nagle zbliżył głębokie sieci neuronowe do możliwości poziomu ludzkiego. Teraz trwa walka o rozszerzenie zakresu takich zadań. Na przykład robot odkurzający mógłby z łatwością odróżnić kota od psa, gdy te spotkają się twarzą w twarz. Jednak w większości sytuacji życiowych nie będzie w stanie znaleźć kota śpiącego wśród pościeli czy mebli (tak jak my w większości przypadków...).
Jaki jest powód sukcesu głębokich sieci neuronowych? Tworzą reprezentację problemu, opierając się nie na informacjach „widocznych gołym okiem” (piksele fotografii, skoki głośności itp.), lecz na cechach uzyskanych po wstępnym przetworzeniu tych informacji przez kilkaset warstw sieci neuronowej. Niestety, relacje te mogą być również pozbawione znaczenia, niespójne lub odzwierciedlać niedoskonałości oryginalnego zestawu danych. Na przykład istnieje mała gra komputerowa o tym, do czego może doprowadzić nierozważne wykorzystanie sztucznej inteligencji w rekrutacji .

System tagowania obrazów oznaczył osobę gotującą jako kobietę, chociaż w rzeczywistości na zdjęciu jest mężczyzna (). to w Instytucie Wirginii.
Aby analizować złożone i głębokie relacje, których często nie potrafimy sami sformułować, potrzebujemy metod sztucznej inteligencji, którą można wyjaśnić. Organizują cechy głębokich sieci neuronowych w taki sposób, aby po treningu można było analizować wewnętrzną reprezentację przyswojoną przez sieć, zamiast po prostu polegać na jej decyzji.
1.4. Analityka brzegowa / AI
Wszystko, co zawiera słowo Edge, oznacza dosłownie: przeniesienie części algorytmów z chmury/serwera na poziom urządzenia końcowego/bramy. Ten algorytm będzie działał szybciej i nie będzie wymagał połączenia z serwerem centralnym, aby działać. Jeśli znasz abstrakcję „cienkiego klienta”, to tutaj nieco zagęścimy tego klienta.
Może to mieć duże znaczenie dla Internetu rzeczy. Na przykład, jeśli maszyna się przegrzała i wymaga schłodzenia, warto o tym natychmiast poinformować na poziomie zakładu, bez czekania, aż dane dotrą do chmury i stamtąd do kierownika zmiany. Inny przykład: samochody autonomiczne potrafią samodzielnie oceniać sytuację na drodze, bez konieczności kontaktowania się z centralnym serwerem.
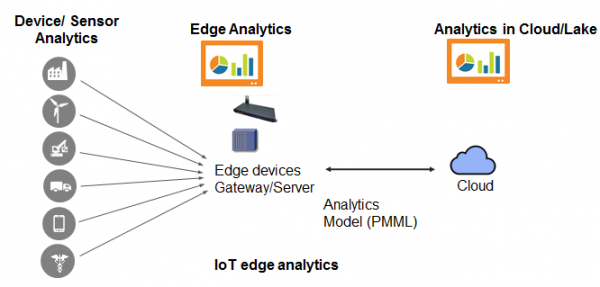
Albo inny przykład, dlaczego jest to ważne z punktu widzenia bezpieczeństwa: gdy wpisujesz teksty na swoim telefonie, zapamiętuje on typowe dla Ciebie słowa, dzięki czemu klawiatura telefonu może je później łatwo podpowiedzieć – to tzw. predykcyjne wprowadzanie tekstu. Wysyłanie wszystkiego, co wpisujesz na klawiaturze, do centrum danych byłoby naruszeniem Twojej prywatności i po prostu nie byłoby bezpieczne. Dlatego nauka korzystania z klawiatury odbywa się wyłącznie w obrębie samego urządzenia.
1.5. Platforma AI jako usługa (AI PaaS)
PaaS – Platforma jako usługa – to model biznesowy, w którym uzyskujemy dostęp do zintegrowanej platformy, obejmującej m.in. przechowywanie danych w chmurze i gotowe procedury. Dzięki temu możemy uwolnić się od zadań infrastrukturalnych i w pełni skupić się na wytwarzaniu czegoś pożytecznego. Przykłady platform PaaS dla zadań związanych ze sztuczną inteligencją: IBM Cloud, Microsoft Azure, Amazon Machine Learning, Google AI Platform.
1.6. Adaptacyjne uczenie maszynowe (Adaptive ML)
A co jeśli pozwolimy sztucznej inteligencji się dostosować... Pytasz - mam na myśli jak? Czy ona nie dostosowuje się już do zadania? Problem polega na tym, że starannie formułujemy każde takie zadanie, zanim stworzymy algorytm sztucznej inteligencji, który będzie je rozwiązywał. Powiedzą ci, że okazuje się, że ten łańcuch można uprościć.
Tradycyjne uczenie maszynowe opiera się na zasadzie pętli otwartej: przygotowujesz dane, tworzysz sieć neuronową (lub coś takiego), trenujesz ją, a następnie przyglądasz się kilku wskaźnikom i jeśli wszystko Ci się podoba, możesz wysłać sieć neuronową do smartfonów, aby rozwiązywała problemy użytkowników. Jednak w zastosowaniach, w których występuje duża ilość danych i ich charakter stopniowo się zmienia, konieczne są inne metody. Takie systemy, które same się dostosowują i uczą, są zorganizowane w zamknięte, samouczące się układy (pętle zamknięte) i muszą działać sprawnie.
Zastosowania obejmują Stream Analytics, z którego korzysta wielu przedsiębiorców do podejmowania decyzji, lub adaptacyjne zarządzanie produkcją. Biorąc pod uwagę skalę współczesnych zastosowań i lepiej poznane zagrożenia dla ludzi, metody stanowiące rozwiązanie tego problemu zostały zebrane pod ogólną nazwą Adaptive AI.
Patrząc na to zdjęcie, trudno pozbyć się wrażenia, że futurolodzy niczego nie chcieliby bardziej, niż nauczyć robota oddychać…
Postklasyczne obliczenia i komunikacja
2.1. Piąta generacja komunikacji mobilnej (5G)
To tak ciekawy temat, że od razu odsyłamy do naszego . No cóż, oto krótkie podsumowanie. Technologia 5G sprawi, że prędkość Internetu stanie się nierealnie duża ze względu na zwiększenie częstotliwości transmisji danych. Fale krótkie mają większe trudności z przechodzeniem przez przeszkody, więc struktura sieci będzie zupełnie inna: potrzeba 500 razy więcej stacji bazowych.
Oprócz prędkości otrzymamy nowe zjawiska: gry w czasie rzeczywistym z rozszerzoną rzeczywistością, wykonywanie skomplikowanych zadań (np. operacji) dzięki teleobecności, zapobieganie wypadkom i trudnym sytuacjom na drogach dzięki komunikacji między samochodami. A teraz bardziej prozaicznie: mobilny Internet w końcu przestanie się rozłączać podczas imprez masowych, na przykład meczów na stadionach.

Źródło obrazu: Reuters, Niantic
2.2. Pamięć nowej generacji
Tutaj mówimy o piątej generacji pamięci RAM – DDR5. Samsung ogłosił, że produkty oparte na pamięci DDR2019 będą dostępne do końca 5 roku. Oczekuje się, że nowa pamięć będzie dwa razy szybsza i dwa razy pojemniejsza, przy zachowaniu tego samego formatu, co oznacza, że będziemy mogli uzyskać pamięci o pojemności do 32 GB dla naszego komputera. W przyszłości będzie to szczególnie istotne w przypadku smartfonów (nowa pamięć będzie w wersji energooszczędnej) i laptopów (w których liczba gniazd DIMM jest ograniczona). Uczenie maszynowe wymaga również dużej ilości pamięci RAM.
2.3. Systemy satelitarne na niskiej orbicie okołoziemskiej
Pomysł zastąpienia ciężkich, drogich i wydajnych satelitów rojem małych i tanich nie jest nowy i pojawił się już w latach 90. O tym Dziś już tylko leniwi o tym nie słyszeli. Najsłynniejszą firmą w tym regionie jest Iridium, która zbankrutowała pod koniec lat 90., ale została uratowana przez Departament Obrony USA (nie mylić z iRidium, rosyjskim systemem inteligentnego domu). Projekt Elona Muska (Starlink) to nie jedyny taki projekt — w wyścigu satelitarnym biorą udział także Richard Branson (OneWeb — 1440 proponowanych satelitów), Boeing (3000 satelitów), Samsung (4600 satelitów) i inni.
Jak wygląda sytuacja w tym rejonie, jaka jest tam gospodarka – czytaj w . Czekamy na pierwsze testy tych systemów przez pierwszych użytkowników, co powinno nastąpić w przyszłym roku.
2.4. Drukowanie 3D w skali nano
Druk 3D, choć nie na dobre zagościł w życiu każdego (w postaci obiecywanej domowej fabryki plastiku), to jednak już dawno wyszedł z niszy technologii przeznaczonej dla maniaków komputerowych. Można to wywnioskować z faktu, że każdy uczeń wie o istnieniu przynajmniej długopisów do rzeźbienia w 3D, a wielu marzy o zakupie pudełka z prowadnicami i wytłaczarką do... „tak po prostu” (albo już je kupiło).
Stereolitografia (laserowe drukarki 3D) umożliwia drukowanie za pomocą pojedynczych fotonów: prowadzone są badania nad nowymi polimerami, które do utwardzenia wymagają zaledwie dwóch fotonów. Dzięki temu będziemy mogli tworzyć zupełnie nowe filtry, uchwyty, sprężyny, kapilary, soczewki i... Wasze opcje w komentarzach, w warunkach pozalaboratoryjnych! A stąd już niedaleko do fotopolimeryzacji – tylko ta technologia pozwala na „drukowanie” procesorów i układów obliczeniowych. Poza tym istnieje już od kilku lat , ale bez radykalnego rozwoju.

3. Wyczuwanie i mobilność
3.1. Poziom autonomicznej jazdy 4 i 5
Aby nie pogubić się w terminologii, warto zrozumieć, jakie poziomy autonomii są rozróżniane (na podstawie szczegółowego , do którego odsyłamy wszystkich zainteresowanych):
Poziom 1: Tempomat: pomaga kierowcy w bardzo ograniczonych sytuacjach (np. utrzymanie samochodu na zadanej prędkości po zdjęciu nogi z pedału przez kierowcę)
Poziom 2: Ograniczone wspomaganie układu kierowniczego i hamulcowego. Kierowca musi być gotowy do przejęcia kontroli nad pojazdem niemal natychmiast. Jego ręce spoczywają na kierownicy, a wzrok skierowany jest na drogę. To jest to, co Tesla i General Motors już mają.
Poziom 3: Kierowca nie musi już nieustannie zwracać uwagi na drogę. Ale musisz zachować czujność i być gotowym przejąć kontrolę. Tego jeszcze nie ma w samochodach dostępnych na rynku. Wszystkie obecnie istniejące są na poziomie 1-2.
Poziom 4: Prawdziwy autopilot, ale z ograniczeniami: jazda wyłącznie w znanym obszarze, dokładnie zmapowanym i ogólnie znanym systemowi, a także pod pewnymi warunkami, na przykład gdy nie ma śniegu. Waymo i General Motors mają już takie prototypy i planują zaprezentować je w kilku miastach oraz przetestować w warunkach rzeczywistych. Yandex ma strefy testowe taksówek autonomicznych w Skolkovo i Innopolis: przejazd odbywa się pod nadzorem inżyniera siedzącego na fotelu pasażera; Do końca roku firma planuje rozszerzyć swoją flotę do 100 pojazdów bezzałogowych.
Poziom 5: Jazda w pełni automatyczna, całkowite zastąpienie kierowcy. Takie systemy nie istnieją i jest mało prawdopodobne, aby pojawiły się w najbliższych latach.
Na ile realistyczne jest przewidywanie tego wszystkiego w dającej się przewidzieć przyszłości? Tutaj chciałbym odesłać czytelnika do artykułu . Wynika to częściowo z braku łączności 5G: obecne prędkości 4G są niewystarczające. Częściowo z powodu bardzo wysokich kosztów pojazdów autonomicznych: nie są one jeszcze rentowne, a ich model biznesowy jest niejasny. Krótko mówiąc, „wszystko jest tutaj skomplikowane” i nieprzypadkowo Gartner pisze, że prognoza masowego wdrożenia poziomów 4 i 5 nie jest wcześniejsza niż za 10 lat.
3.2. Kamery z czujnikiem 3D
Osiem lat temu kontroler do gier Kinect firmy Microsoft zrobił furorę, oferując przystępne i stosunkowo niedrogie rozwiązanie umożliwiające oglądanie w 3D. Od tego czasu gry taneczne i wychowanie fizyczne z wykorzystaniem Kinecta przeżywały okresy wzlotów i upadków, natomiast kamery 3D zaczęły być stosowane w robotach przemysłowych, pojazdach bezzałogowych i telefonach komórkowych do identyfikacji twarzy. Technologia ta stała się tańsza, bardziej kompaktowa i bardziej dostępna.

Telefon Samsung S10 ma kamerę z funkcją Time-of-Flight, która mierzy odległość do obiektu, ułatwiając ustawianie ostrości.
Jeśli interesuje Cię ten temat, odsyłamy do bardzo dobrej, szczegółowej recenzji kamer głębinowych: , .
3.3. Drony do dostaw lekkich ładunków
Amazon wywołał w tym roku sensację, prezentując nowego latającego drona, który może przenosić małe ładunki o wadze do 2 kg. W mieście, w którym panują korki, wydaje się to rozwiązaniem idealnym. Zobaczmy, jak te drony będą się sprawować w niedalekiej przyszłości. Warto może w tym miejscu zachować ostrożny sceptycyzm: istnieje wiele problemów, począwszy od możliwości łatwej kradzieży drona, aż po ograniczenia prawne dotyczące bezzałogowych statków powietrznych. Usługa Amazon Prime Air istnieje już od sześciu lat, ale nadal znajduje się w fazie testów.

Nowy dron Amazona zaprezentowany tej wiosny. Jest w nim coś z Gwiezdnych Wojen.
Oprócz Amazona na tym rynku działają również inni gracze (istnieje szczegółowy opis ), ale nie ma ani jednego gotowego produktu: wszystko jest na etapie testowania i wprowadzania na rynek. Warto osobno wspomnieć o dość ciekawej, wysoko wyspecjalizowanej medycynie w Afryce: akcje krwiodawstwa w Ghanie (14 000 pobrań, Zipline) i Rwandzie (Matternet).
3.4. Latające pojazdy autonomiczne
Trudno tutaj cokolwiek konkretnego powiedzieć. Według Gartnera, nie nastąpi to wcześniej niż za 10 lat. Generalnie rzecz biorąc, występują tu wszystkie te same problemy, co w przypadku samochodów autonomicznych, zyskują one jednak nowy wymiar – pionowy. Porsche, Boeing i Uber ogłosiły zamiar zbudowania latającej taksówki.
3.5. Chmura rozszerzonej rzeczywistości (AR Cloud)
Trwała cyfrowa kopia rzeczywistego świata, umożliwiająca stworzenie nowej warstwy rzeczywistości, z której mogą korzystać wszyscy użytkownicy. Mówiąc bardziej technicznie, chodzi o stworzenie otwartej platformy chmurowej, z którą programiści będą mogli integrować swoje aplikacje rozszerzonej rzeczywistości. Model monetyzacji jest przejrzysty, jest to swego rodzaju analogia do Steama. Idea ta tak się zakorzeniła, że niektórzy uważają obecnie, iż rzeczywistość rozszerzona bez chmury jest po prostu bezużyteczna.
Jak to może wyglądać w przyszłości, pokazuje krótki film. Wygląda jak kolejny odcinek Black Mirror:

Możesz również przeczytać w
4. Rozszerzony człowiek
4.1. Emocje AI
Jak mierzyć, symulować i reagować na ludzkie emocje? Niektórzy klienci to firmy produkujące asystentów głosowych, np. Amazon Alexa. Ludzie będą mogli naprawdę przyzwyczaić się do domu, jeśli nauczą się rozpoznawać nastrój: zrozumieją powód niezadowolenia użytkownika i postarają się poprawić sytuację. Ogólnie rzecz biorąc, w kontekście jest o wiele więcej informacji niż w samej wiadomości. A kontekstem jest mimika twarzy, intonacja i zachowanie niewerbalne.
Inne praktyczne zastosowania obejmują: analizę emocji podczas rozmów kwalifikacyjnych (za pomocą nagrań wideo), ocenę reakcji na reklamy lub inne treści wideo (uśmiech, śmiech) oraz wspomaganie nauki (np. w celu samodzielnego ćwiczenia sztuki publicznego przemawiania).
Trudno jest wypowiedzieć się na ten temat lepiej niż autor 6-minutowego filmu krótkometrażowego . Ten pomysłowy i stylowo zrobiony film pokazuje, jak można mierzyć nasze emocje w celach marketingowych. Na podstawie chwilowych reakcji twojej twarzy możesz dowiedzieć się, czy lubisz pizzę, psy, Kanye Westa, a nawet jaki jest twój poziom dochodów i przybliżone IQ. Klikając powyższy link, możesz wziąć udział w interaktywnym filmie, oglądając go za pomocą wbudowanej kamery swojego laptopa. Film był już pokazywany na kilku festiwalach filmowych.

Istnieje nawet ciekawe badanie: jak rozpoznać sarkazm w tekście. Wzięliśmy tweety z hashtagiem #sarcasm i stworzyliśmy próbkę treningową składającą się z 25 000 tweetów z sarkazmem i 100 000 zwykłych tweetów na każdy temat pod słońcem. Wykorzystaliśmy bibliotekę TensorFlow, przeszkoliliśmy system i oto wynik:

Jeśli więc nie jesteś pewien, czy Twój kolega lub przyjaciel powiedział Ci coś poważnie, czy sarkastycznie, możesz skorzystać z już istniejącego narzędzia. !
4.2. Rozszerzona inteligencja
Automatyzacja pracy intelektualnej z wykorzystaniem metod uczenia maszynowego. Wydawałoby się, że nie ma nic nowego? Ale samo sformułowanie jest tutaj istotne, zwłaszcza że w skrócie odpowiada ono terminowi Sztuczna Inteligencja. To sprowadza nas z powrotem do debaty na temat „silnej” i „słabej” sztucznej inteligencji.
Silna sztuczna inteligencja to ta sama sztuczna inteligencja, którą znamy z filmów science fiction, która jest w pełni równoważna ludzkiemu umysłowi i jest świadoma siebie jako jednostki. Coś takiego jeszcze nie istnieje i nie jest jasne, czy w ogóle powstanie.
Słaba sztuczna inteligencja nie jest samodzielną osobowością, lecz asystentem człowieka. Nie twierdzi, że potrafi myśleć jak człowiek, ale po prostu potrafi rozwiązywać problemy informacyjne, na przykład określać, co jest przedstawione na obrazku lub tłumaczyć tekst.

W tym sensie rozszerzona inteligencja to czysta „słaba sztuczna inteligencja”, a sformułowanie to wydaje się udane, ponieważ nie wprowadza zamieszania i pokusy, by widzieć w tym przypadku tę samą „silną sztuczną inteligencję”, o której każdy marzy (lub się jej boi, jeśli przypomnimy sobie liczne dyskusje na temat „powstania maszyn”). Używając określenia „inteligencja rozszerzona”, od razu stajemy się bohaterami innego filmu: z science fiction (np. „Ja, robot” Asimova) przenosimy się do cyberpunku (w tym gatunku „augmentacje” to wszelkiego rodzaju implanty rozszerzające ludzkie możliwości).
jak Erik Brynjolfsson i Andrew McAfee: „To właśnie wydarzy się w ciągu najbliższych 10 lat. To nie AI zastąpi menedżerów, ale ci menedżerowie, którzy używają AI, zastąpią tych, którzy jeszcze tego nie zrobili”.
Przykłady:
- Medycyna: Uniwersytet Stanforda opracował , który radzi sobie z zadaniem rozpoznawania patologii na zdjęciach rentgenowskich klatki piersiowej średnio tak samo dobrze, jak większość lekarzy
- Edukacja: pomoc uczniom i nauczycielom, analiza reakcji uczniów na materiały, opracowywanie indywidualnych ścieżek nauczania.
- Analityka biznesowa: wstępne przetwarzanie danych, według statystyk, zajmuje badaczowi 80% czasu, a sam eksperyment zajmuje tylko 20%
4.3. Biochipy
To ulubiony motyw wszystkich filmów i książek cyberpunkowych. Ogólnie rzecz biorąc, wszczepianie mikroczipów zwierzętom nie jest nową praktyką. Teraz jednak zaczęto wszczepiać takie chipy także ludziom.
W tym przypadku szum jest najprawdopodobniej związany z głośną sprawą amerykańskiej firmy Three Square Market. Tam pracodawca zaczął oferować wszczepianie chipów pod skórę w zamian za nagrodę. Dzięki chipowi można otwierać drzwi, logować się do komputerów, kupować przekąski w automatach – innymi słowy, jest to uniwersalna karta pracownicza. Jednocześnie taki chip pełni funkcję właśnie dowodu osobistego; nie posiada modułu GPS, więc nie da się śledzić nikogo korzystającego z niego. A jeśli ktoś chce wyjąć chip z ręki, zajmuje to 5 minut pod opieką lekarza.
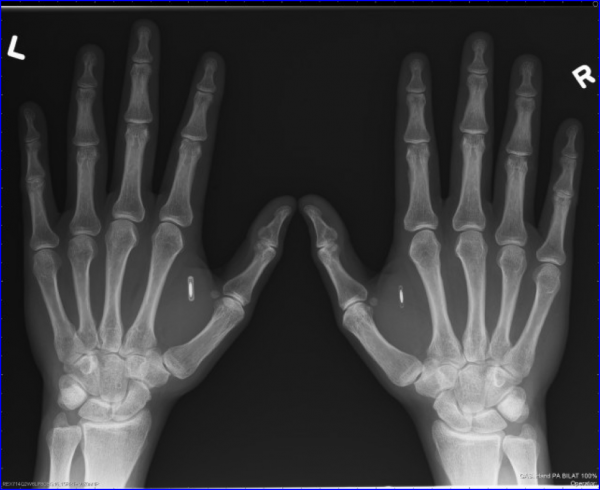
Chipy wszczepia się zazwyczaj pomiędzy kciuk i palec wskazujący.
Przeczytaj więcej o stanie rzeczy w zakresie mikroczipowania na świecie.
4.4. Przestrzeń robocza immersyjna
„Zanurzeniowy” to kolejne nowe słowo, którego po prostu nie da się uniknąć. Jest wszędzie. Teatr immersyjny, wystawa, kino. Co to oznacza? Immersyjność to tworzenie efektu immersyjnego, w którym zaciera się granica między autorem a widzem, między światem wirtualnym a rzeczywistym. W miejscu pracy oznacza to prawdopodobnie zatarcie granicy między wykonawcą a inicjatorem i zachęcanie pracowników do zajęcia bardziej aktywnej postawy poprzez zmianę otoczenia, w którym pracują.
Ponieważ obecnie wszędzie mamy Agile, elastyczność i ścisłą współpracę, miejsca pracy powinny być jak najłatwiej konfigurowalne i zachęcać do pracy zespołowej. Gospodarka dyktuje swoje warunki: przybywa pracowników tymczasowych, rosną koszty wynajmu powierzchni biurowych, a w warunkach konkurencyjnego rynku pracy firmy IT starają się zwiększyć zadowolenie pracowników z pracy, tworząc strefy rekreacyjne i inne świadczenia. Wszystko to znajduje odzwierciedlenie w projektowaniu miejsc pracy.
Z Pagórek
4.5. Uosobienie
Każdy wie, na czym polega personalizacja w reklamie. To jest ten moment, kiedy dzisiaj rozmawiasz z kolegą, że powietrze w pomieszczeniu jest trochę suche i powinieneś kupić nawilżacz powietrza do biura, a następnego dnia widzisz reklamę na swoim portalu społecznościowym – „kup nawilżacz powietrza” (to prawdziwy przypadek, który mi się przydarzył).

Personalizacja, jak wynika z danych firmy Gartner, jest odpowiedzią na rosnące obawy użytkowników dotyczące wykorzystywania ich danych osobowych w celach reklamowych. Celem jest opracowanie podejścia, w którym wyświetlane nam reklamy są istotne w kontekście, w jakim się znajdujemy, a nie w odniesieniu do nas osobiście. Na przykład nasza lokalizacja, rodzaj urządzenia, pora dnia, warunki pogodowe – to nie są rzeczy, które naruszają nasze dane osobowe, a my nie mamy nieprzyjemnego uczucia, że jesteśmy „śledzeni”.
Przeczytaj o różnicy między tymi dwoma koncepcjami Andrew Frank na blogu na stronie internetowej Gartnera. Istnieje tu tak subtelna różnica, a słowa są tak podobne, że jeśli nie zwrócisz uwagi na różnicę, ryzykujesz, że będziesz długo dyskutował ze swoim rozmówcą, nie podejrzewając, że generalnie obaj mają rację (i to jest prawdziwy przypadek, który przydarzył się autorowi).
4.6. Biotechnologia – tkanka hodowana czy sztuczna
Chodzi tu przede wszystkim o hodowanie sztucznego mięsa. W tym samym czasie kilka zespołów na całym świecie pracuje nad laboratoryjnym „Mięsem 2.0” – oczekuje się, że stanie się ono tańsze niż zwykle, a następnie przestawią się na nie restauracje typu fast food, a następnie supermarkety. Do inwestorów w tę technologię zaliczają się m.in. Bill Gates, Sergey Brin i Richard Branson.

źródło
Powody, dla których wszyscy tak bardzo interesują się sztucznym mięsem:
- Globalne ocieplenie: emisje metanu z gospodarstw rolnych. Stanowi to 18% całkowitej objętości gazów wpływających na klimat na świecie.
- Wzrost populacji. Zapotrzebowanie na mięso rośnie, a wykarmienie wszystkich naturalnym mięsem nie jest możliwe – jest ono po prostu drogie.
- Brak miejsca. 70% lasów amazońskich zostało już wyciętych pod pastwiska.
- Rozważania etyczne. Są tacy, dla których jest to ważne. Organizacja ochrony praw zwierząt PETA już zaoferowała nagrodę w wysokości 1 miliona dolarów naukowcowi, który wprowadzi na rynek sztuczne mięso z kurczaka.
Zastąpienie soi prawdziwym mięsem jest rozwiązaniem częściowym, ponieważ ludzie są bardzo wrażliwi na różnicę w smaku i konsystencji, a mało prawdopodobne jest, aby zrezygnowali ze steka na rzecz soi. Potrzebne jest więc prawdziwe, ekologicznie hodowane mięso. Niestety, sztuczne mięso jest zbyt drogie: od 12 dolarów za kilogram. Wynika to ze złożonego procesu technologicznego hodowli takiego mięsa. Przeczytaj o tym wszystkim .
Jeśli mówimy o innych przypadkach hodowli tkanek – już w medycynie – to temat sztucznych organów jest interesujący: na przykład „łatka” na mięsień sercowy, za pomocą specjalnej drukarki 3D. Znany podobne do sztucznie wyhodowanego serca myszy, ale ogólnie rzecz biorąc, wszystko nie wyszło jeszcze poza zakres badań klinicznych. Dlatego mało prawdopodobne jest, abyśmy w najbliższych latach ujrzeli Frankensteina.
Gartner jest w tym przypadku bardzo ostrożny w swoich szacunkach, najwyraźniej mając na uwadze swoją nieudaną prognozę z 2015 r., zgodnie z którą do 2019 r. 10% populacji krajów rozwiniętych będzie posiadało implant medyczny wykonany w technologii druku 3D. Dlatego wskazuje ona czas osiągnięcia plateau produktywności – nie krótszy niż 10 lat.
5. Ekosystemy cyfrowe
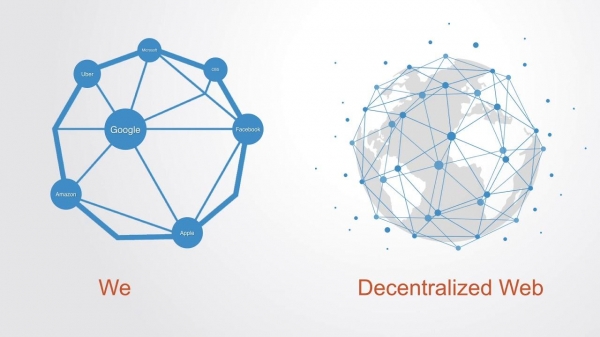
5.1. Zdecentralizowana sieć
Koncepcja ta jest ściśle związana z nazwiskiem wynalazcy sieci WWW, laureata Nagrody Turinga, Sir Tima Burnersa-Lee. Dla niego kwestie etyki w informatyce i kolektywnego charakteru Internetu zawsze były istotne: tworząc podwaliny hipertekstu, był przekonany, że sieć powinna działać jak pajęczyna, a nie jak hierarchia. Tak było na wczesnym etapie rozwoju sieci. Jednak w miarę rozwoju Internetu jego struktura ulegała centralizacji, z kilku powodów. Okazuje się, że dostęp do sieci na terenie całego kraju można łatwo zablokować, korzystając z usług zaledwie kilku dostawców. Dane użytkowników stały się źródłem siły i dochodu dla firm internetowych.
„Internet jest już zdecentralizowany” – mówi Burners-Lee. — Problem polega na tym, że dominuje jedna wyszukiwarka, jedna duża sieć społecznościowa, jedna platforma mikroblogowa. Nie mamy problemów technologicznych, ale mamy problemy społeczne.
W jego Z okazji 30. rocznicy powstania sieci World Wide Web jej twórca przedstawił trzy główne problemy Internetu:
- Celowe szkody, takie jak hakowanie sponsorowane przez państwo, przestępstwa i nękanie w Internecie
- Sama struktura systemu, która na niekorzyść użytkownika stwarza podstawy dla takich mechanizmów jak: zachęty finansowe do clickbaitów i wirusowe rozprzestrzenianie fałszywych informacji
- Niezamierzone konsekwencje projektu systemu prowadzące do konfliktów i niskiej jakości dyskusji online
A Tim Berners-Lee ma już odpowiedź na temat tego, na jakich zasadach mógłby opierać się „zdrowy Internet”, pozbawiony problemu numer 2: „Dla wielu użytkowników jedynym modelem interakcji z siecią pozostaje dochód z reklam. Nawet jeśli ludzie boją się tego, co dzieje się z ich danymi, są gotowi zawrzeć umowę z machiną marketingową w zamian za możliwość otrzymywania treści za darmo. Wyobraź sobie świat, w którym płacenie za towary i usługi jest łatwe i przyjemne dla obu stron”. Jednym ze sposobów osiągnięcia tego celu byłoby umożliwienie muzykom sprzedaży swoich nagrań bez konieczności korzystania z pośredników, takich jak iTunes, a także umożliwienie serwisom informacyjnym korzystania z systemu mikropłatności za przeczytanie pojedynczego artykułu, zamiast zarabiania na reklamach.
Tim Berners-Lee uruchomił projekt SOLID, będący eksperymentalnym prototypem takiego nowego Internetu. Pomysł opiera się na możliwości przechowywania danych w „kapsule” — urządzeniu przechowującym informacje — i udostępniania tych danych aplikacjom zewnętrznym. Ale w zasadzie to Ty jesteś panem swoich danych. Wszystko to jest ściśle powiązane z koncepcją sieci peer-to-peer, co oznacza, że komputer nie tylko żąda usług, ale także je świadczy, tak aby nie być uzależnionym od jednego serwera jako jedynego kanału.
5.2. Zdecentralizowane organizacje autonomiczne
Jest to organizacja, którą rządzą zasady zapisane w formie programu komputerowego. Jej działalność finansowa opiera się na technologii blockchain. Celem tworzenia takich organizacji jest wyeliminowanie państwa z roli pośrednika i stworzenie wspólnego, zaufanego środowiska dla kontrahentów, które nie jest własnością nikogo indywidualnie, lecz jest własnością wszystkich. Teoretycznie oznacza to, że jeśli pomysł się przyjmie, powinno to doprowadzić do zniesienia notariuszy i innych tradycyjnych instytucji weryfikacyjnych.
Najbardziej znanym przykładem takiej organizacji jest skoncentrowana na inwestycjach venture capital organizacja The DAO, która w 2016 r. zebrała 150 mln USD, z czego 50 mln USD zostało natychmiast skradzionych dzięki luce prawnej w przepisach. Natychmiast pojawił się trudny dylemat: cofnąć decyzję i zwrócić pieniądze, czy uznać, że wypłata pieniędzy była legalna, ponieważ w żaden sposób nie naruszała zasad platformy. W rezultacie, aby zwrócić pieniądze inwestorom, twórcy musieli zniszczyć The DAO, przepisując blockchain i naruszając jego główną zasadę – niezmienność.

Komiks o Ethereum (po lewej) i The DAO (po prawej).
Cała ta historia nadszarpnęła reputację samej idei DAO. Projekt powstał na bazie kryptowaluty Ethereum, w przyszłym roku spodziewana jest wersja Ether 2.0 – być może autorzy (wśród których jest słynny Vitalik Buterin) wezmą pod uwagę błędy i pokażą coś nowego. To jest prawdopodobnie powód, dla którego Gartner umieścił DAO na linii rosnącej.
5.3.Dane syntetyczne
Do trenowania sieci neuronowych potrzebne są duże ilości danych. Ręczne etykietowanie danych wymaga ogromnej ilości pracy, którą może wykonać tylko człowiek. Dzięki temu możliwe jest tworzenie sztucznych zbiorów danych. Na przykład te same zbiory twarzy ludzkich na stronie . Są one tworzone przy użyciu algorytmów GAN, o których była mowa powyżej.

Te twarze nie należą do ludzi.
Dużą zaletą takich danych jest to, że nie występują żadne trudności prawne w ich wykorzystaniu: nie ma konieczności udzielania zgody na przetwarzanie danych osobowych.
5.4.Operacje cyfrowe
Sufiks „Ops” stał się niezwykle modny odkąd DevOps wszedł do naszego słownika. A teraz o tym, czym jest DigitalOps – to po prostu uogólnienie DevOps, DesignOps, MarketingOps… Czy już się znudziłeś? Krótko mówiąc, jest to przeniesienie podejścia DevOps ze sfery oprogramowania na wszystkie inne aspekty biznesu – marketing, design itd.
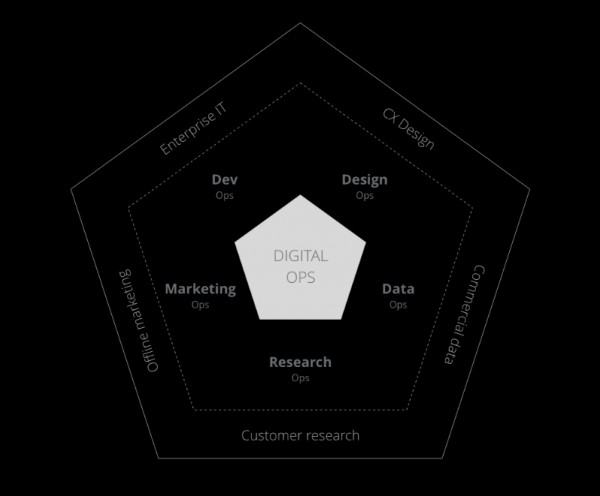
Ideą DevOps było usunięcie barier między rozwojem a operacjami (procesami biznesowymi) poprzez tworzenie wspólnych zespołów, w skład których wchodzili programiści, testerzy, specjaliści ds. bezpieczeństwa i administratorzy; wdrożenie określonych praktyk: ciągła integracja, infrastruktura jako kod, skrócenie i wzmocnienie pętli sprzężenia zwrotnego. Celem było przyspieszenie wprowadzenia produktu na rynek. Jeśli myślisz, że to brzmi jak Agile, masz rację. Teraz przenieś w myślach to podejście ze sfery tworzenia oprogramowania na rozwój w ogóle, a zrozumiesz, czym jest DigitalOps.
5.5. Wykresy wiedzy
Metoda programistyczna służąca do modelowania dziedziny wiedzy, obejmująca wykorzystanie algorytmów uczenia maszynowego. Wykres wiedzy buduje się na podstawie istniejących baz danych, aby połączyć ze sobą wszystkie informacje: zarówno ustrukturyzowane (listę wydarzeń lub osób), jak i nieustrukturyzowane (tekst artykułu).
Najprostszym przykładem jest karta, którą możesz zobaczyć w wynikach wyszukiwania Google. Jeżeli szukasz osoby lub instytucji, po prawej stronie zobaczysz kartę:
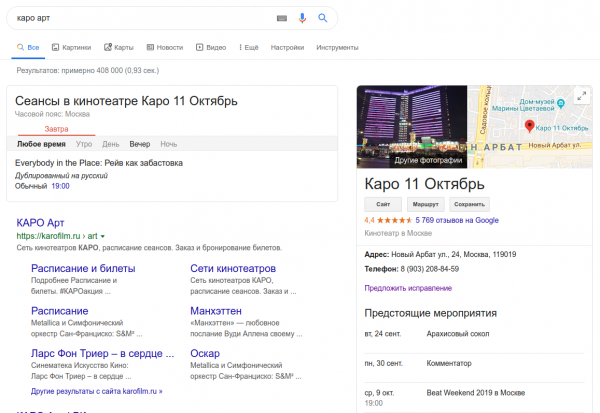
Należy pamiętać, że „Nadchodzące wydarzenia” nie są kopią informacji z Google Maps, lecz zintegrowaną wersją harmonogramu z Yandex.Afisha: można to łatwo sprawdzić, klikając na wydarzenia. Oznacza to połączenie kilku źródeł danych w jedno.
Jeśli poprosisz o listę – na przykład „sławni reżyserzy” – zostanie Ci pokazana „karuzela”:
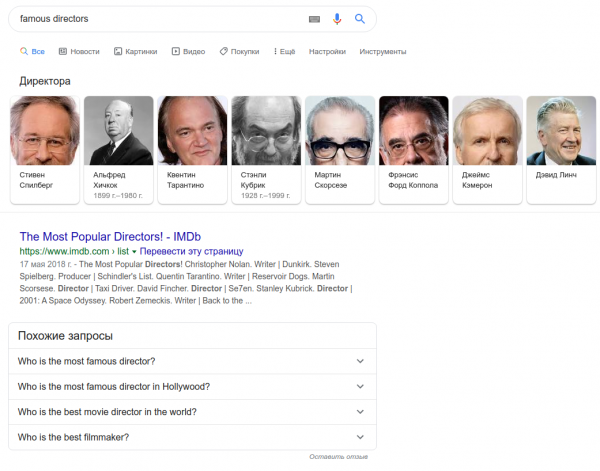
Bonus dla tych, którzy doczytali do końca
A teraz, gdy już wyjaśniliśmy sobie znaczenie każdego z punktów, możemy spojrzeć na ten sam obrazek, ale po rosyjsku:
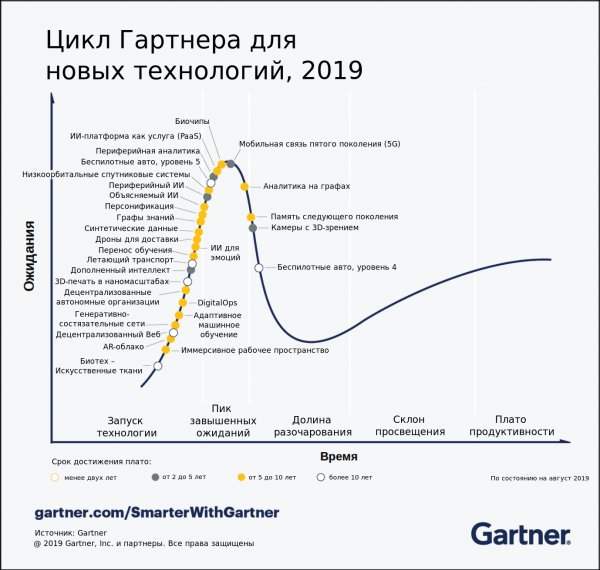
Zachęcamy do udostępniania go w mediach społecznościowych!

Tatyana Volkova — autorka programu nauczania dla kierunku Internet rzeczy w Samsung IT Academy, specjalistka ds. programów społecznej odpowiedzialności biznesu w Samsung Research Center
Źródło: www.habr.com
