

Dobra, staromodna gra w chowanego może być świetnym testem dla botów sztucznej inteligencji (AI), pozwalającym zademonstrować, w jaki sposób podejmują decyzje i wchodzą w interakcje ze sobą oraz różnymi otaczającymi je obiektami.
w jego , opublikowane przez badaczy z OpenAI, organizacji non-profit zajmującej się badaniami nad sztuczną inteligencją, która zyskała sławę w grze komputerowej Dota 2 naukowcy opisują, jak agenci kontrolowani przez sztuczną inteligencję byli szkoleni, aby byli bardziej wyrafinowani w wyszukiwaniu i ukrywaniu się przed sobą w środowisku wirtualnym. Wyniki badania wykazały, że zespół dwóch botów uczy się skuteczniej i szybciej niż jakikolwiek pojedynczy agent bez sojuszników.

Naukowcy zastosowali metodę, która od dawna zyskała sławę , w którym sztuczna inteligencja zostaje umieszczona w nieznanym jej środowisku, mając jednocześnie określone sposoby interakcji z nią, a także system nagród i kar za taki lub inny wynik jej działań. Metoda ta jest dość skuteczna ze względu na zdolność sztucznej inteligencji do wykonywania różnych działań w środowisku wirtualnym z ogromną prędkością, miliony razy większą, niż człowiek może sobie wyobrazić. Pozwala to metodą prób i błędów znaleźć najskuteczniejszą strategię rozwiązania danego problemu. Ale to podejście ma też pewne ograniczenia, np. stworzenie środowiska i prowadzenie licznych cykli szkoleniowych wymaga ogromnych zasobów obliczeniowych, a sam proces wymaga dokładnego systemu porównywania wyników działań AI z jej celem. Dodatkowo nabyte w ten sposób umiejętności agenta ograniczają się do opisywanego zadania i gdy tylko sztuczna inteligencja nauczy się sobie z nim radzić, nie będzie dalszych usprawnień.
Aby wyszkolić sztuczną inteligencję do zabawy w chowanego, naukowcy zastosowali podejście zwane „nieukierunkowaną eksploracją”, w ramach którego agenci mają pełną swobodę w rozwijaniu zrozumienia świata gry i opracowywaniu zwycięskich strategii. Jest to podobne do podejścia do uczenia się wieloagentowego, które badacze z DeepMind stosowali w przypadku wielu systemów sztucznej inteligencji . Podobnie jak w tym przypadku agenci AI nie byli wcześniej przeszkoleni w zakresie zasad gry, ale z biegiem czasu nauczyli się podstawowych strategii i potrafili nawet zaskoczyć badaczy nietrywialnymi rozwiązaniami.
W grze w chowanego kilku agentów, których zadaniem było ukrywanie się, było zmuszonych do uniknięcia pola widzenia przeciwników po niewielkiej przewadze, gdy zespół poszukiwaczy był unieruchomiony. Co więcej, „linią wzroku” w tym kontekście jest stożek o kącie 135 stopni przed pojedynczym botem. Agenci nie mogli zbytnio oddalić się od obszaru gry i byli zmuszeni poruszać się po losowo generowanych pokojach z możliwością korzystania z rozrzuconych po nich obiektów zewnętrznych (skrzynie, ruchome ściany, specjalne rampy), które można było wykorzystać zarówno do tworzenia osłony, jak i infiltracji.
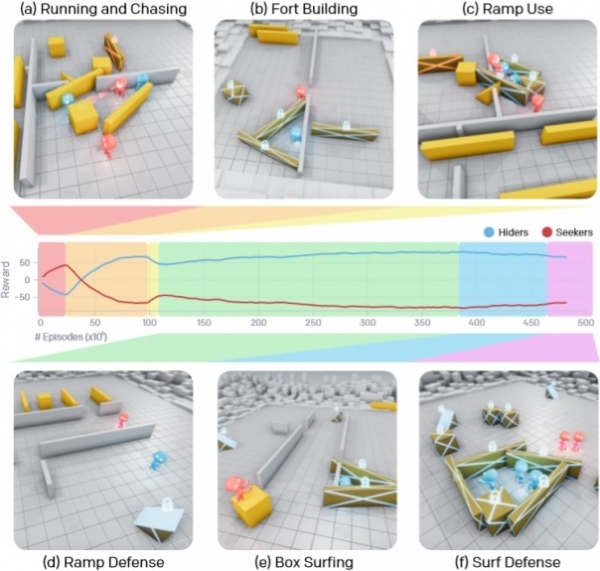
Poprzez długi proces uczenia się agenci AI nauczyli się sześciu unikalnych strategii, z których każda pomogła im przejść do kolejnego etapu gry. Na początku zespoły poszukujących i ukrywających się po prostu uciekały i goniły się nawzajem, ale po około 25 milionach meczów drużyna ukrywających się nauczyła się blokować przejścia pudłami i budować z nich schronienia. Po kolejnych 75 milionach meczów zespół odkrył sposoby wykorzystania ramp, aby dostać się do tych kryjówek. Po kolejnych 10 milionach rund ukrywacze nauczyli się przeciągać rampy na krawędź obszaru gry i blokować je w miejscu, aby uniemożliwić przeciwnikom ich użycie.

Po 388 milionach meczów poszukiwacze nauczyli się korzystać z zablokowanych ramp, aby wspinać się na przyniesione im skrzynie, a następnie przechodząc bezpośrednio na nie, penetrować kryjówki wroga utworzone z przenośnych ścian. I wreszcie, po 458 milionach meczów, drużyna ukrywająca się doszła do wniosku, że musi zablokować wszystkie obiekty, a następnie zbudować schron, co najwyraźniej doprowadziło do ich ostatecznego zwycięstwa.
Szczególnie imponujące jest to, że po 22 milionach meczów agenci nauczyli się koordynować swoje działania, a efektywność ich pracy w przyszłości tylko wzrosła, np. każdy przyniósł własne pudełko lub ściankę, aby stworzyć schronienie i wybrał swój udział w przedmiotach, które będzie chciał wykorzystać. blok, aby skomplikować grę przeciwnikom.

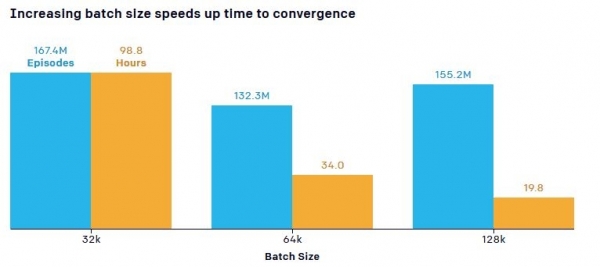
Naukowcy zwrócili także uwagę na ważny punkt związany z wpływem liczby obiektów uczących (ilości danych przesyłanych przez sieć neuronową – „Rozmiar wsadu”) na szybkość uczenia się. Domyślny model wymagał 132,3 miliona meczów w ciągu 34 godzin treningu, aby osiągnąć punkt, w którym ukrywająca się drużyna nauczyła się blokować rampy, natomiast większa ilość danych skutkowała zauważalnym skróceniem czasu szkolenia. Przykładowo zwiększenie liczby parametrów (część danych uzyskanych podczas całego procesu uczenia) z 0,5 mln do 5,8 mln zwiększyło efektywność próbkowania 2,2-krotnie, a zwiększenie rozmiaru danych wejściowych z 64 KB do 128 KB skróciło szkolenie raz prawie półtora raza.
Pod koniec pracy badacze postanowili sprawdzić, w jakim stopniu szkolenie w grze może pomóc agentom w radzeniu sobie z podobnymi zadaniami poza grą. W sumie przeprowadzono pięć testów: świadomość liczby obiektów (zrozumienie, że przedmiot nadal istnieje, nawet jeśli jest poza zasięgiem wzroku i nie jest używany); „zablokuj i wróć” - możliwość zapamiętania swojej pierwotnej pozycji i powrotu do niej po wykonaniu dodatkowego zadania; „blokowanie sekwencyjne” – 4 skrzynki zostały losowo rozmieszczone w trzech pokojach bez drzwi, ale z rampami umożliwiającymi wejście do środka, agenci musieli je wszystkie znaleźć i zablokować; umieszczanie skrzynek w określonych miejscach; utworzenie schronu wokół obiektu w formie walca.
W rezultacie w trzech z pięciu zadań boty, które przeszły wstępne szkolenie w grze, uczyły się szybciej i wykazywały lepsze wyniki niż sztuczna inteligencja przeszkolona do rozwiązywania problemów od podstaw. Nieco lepiej radzili sobie z wykonaniem zadania i powrotem do pozycji wyjściowej, sekwencyjnym blokowaniem skrzynek w zamkniętych pomieszczeniach i umieszczaniem skrzynek w określonych obszarach, natomiast nieco słabiej radzili sobie z rozpoznawaniem liczby obiektów i tworzeniem osłony wokół innego obiektu.
Badacze przypisują mieszane wyniki sposobowi, w jaki sztuczna inteligencja uczy się i zapamiętuje pewne umiejętności. „Uważamy, że zadania, w których najlepiej sprawdzał się trening wstępny w grze, polegały na ponownym wykorzystaniu wcześniej poznanych umiejętności w znajomy sposób, natomiast wykonanie pozostałych zadań lepiej niż sztuczna inteligencja wyszkolona od podstaw wymagałaby wykorzystania ich w inny sposób, co znacznie bardziej skomplikowane” – piszą współautorzy pracy. „Wynik ten podkreśla potrzebę opracowania metod skutecznego ponownego wykorzystania umiejętności nabytych podczas szkolenia podczas przenoszenia ich z jednego środowiska do drugiego”.
Wykonana praca jest naprawdę imponująca, ponieważ perspektywa zastosowania tej metody nauczania wykracza daleko poza granice jakichkolwiek gier. Naukowcy twierdzą, że ich praca stanowi znaczący krok w kierunku stworzenia sztucznej inteligencji o zachowaniu „opartym na fizyce” i „podobnym do człowieka”, która może diagnozować choroby, przewidywać struktury złożonych cząsteczek białek i analizować tomografię komputerową.
Na poniższym filmie wyraźnie widać, jak przebiegał cały proces uczenia się, jak sztuczna inteligencja nauczyła się pracy zespołowej, a jej strategie stawały się coraz bardziej przebiegłe i złożone.

Źródło: 3dnews.ru
