


Sieci neuronowe w wizji komputerowej aktywnie się rozwijają, wiele problemów jest wciąż dalekich od rozwiązania. Aby być na czasie w swojej branży, wystarczy śledzić influencerów na Twitterze i czytać odpowiednie artykuły na arXiv.org. Ale mieliśmy okazję pojechać na Międzynarodową Konferencję Widzenia Komputerowego (ICCV) 2019. W tym roku odbywa się ona w Korei Południowej. Teraz chcemy podzielić się z czytelnikami Habr tym, co widzieliśmy i czego się nauczyliśmy.
Było nas tam sporo z Yandexu: przyszli twórcy samochodów autonomicznych, badacze i ci, którzy zajmują się zadaniami CV w usługach. Ale teraz chcemy przedstawić nieco subiektywny punkt widzenia naszego zespołu - Laboratorium Inteligencji Maszyn (Yandex MILAB). Pozostali prawdopodobnie spojrzeli na konferencję ze swojej perspektywy.
Czym zajmuje się laboratorium?Realizujemy eksperymentalne projekty związane z generacją obrazu i muzyki do celów rozrywkowych. Nas szczególnie interesują sieci neuronowe, które umożliwiają zmianę treści od użytkownika (w przypadku zdjęć zadanie to nazywa się manipulacją obrazem). efekt naszej pracy z konferencji YaC 2019.
Konferencji naukowych jest wiele, ale na pierwszy plan wysuwają się te najważniejsze, tzw. konferencje A*, na których zazwyczaj publikowane są artykuły dotyczące najciekawszych i najważniejszych technologii. Nie ma dokładnej listy konferencji A*, oto lista przybliżona i niepełna: NeurIPS (dawniej NIPS), ICML, SIGIR, WWW, WSDM, KDD, ACL, CVPR, ICCV, ECCV. Trzy ostatnie specjalizują się w tematyce CV.
ICCV w skrócie: plakaty, tutoriale, warsztaty, stoiska
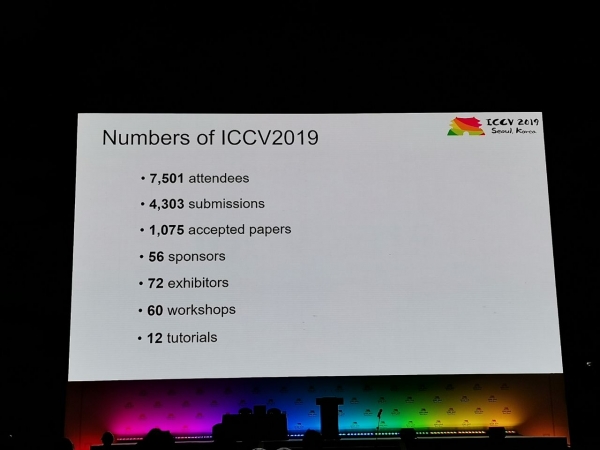
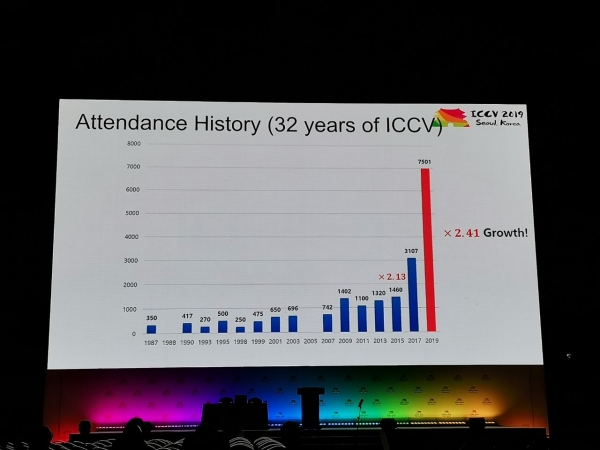
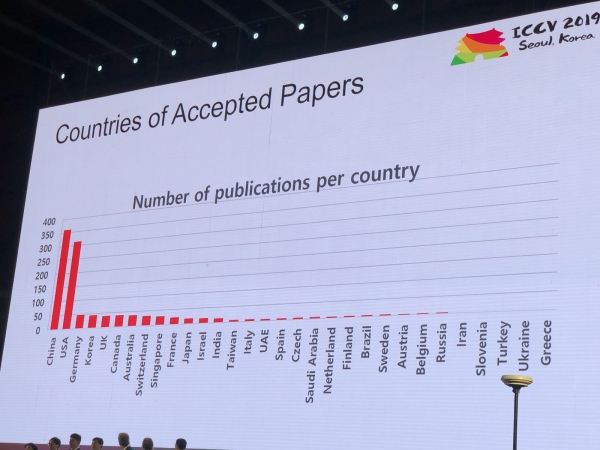
Na konferencję napłynęło 1075 referatów, wzięło w niej udział 7500 uczestników, 103 osoby przyjechały z Rosji, pojawiły się artykuły pracowników Yandex, Skoltech, Samsung AI Center Moskwa i Samara University. W tym roku ICCV odwiedziło niewielu czołowych badaczy, ale na przykład Alexey (Alyosha) Efros, który zawsze przyciąga wiele osób:

Statystyki 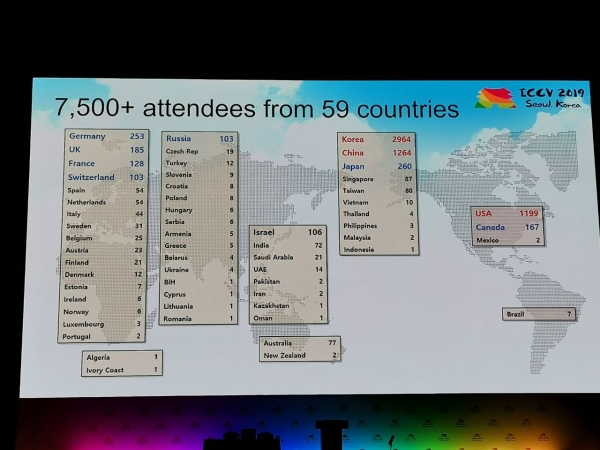

Na wszystkich tego typu konferencjach artykuły prezentowane są w formie plakatów ( o formacie), a najlepsze prezentowane są także w formie krótkich reportaży.
Oto niektóre prace z Rosji 


Dzięki tutorialom możesz zagłębić się w konkretny obszar tematyczny; przypomina to wykład na uniwersytecie. Czyta ją jedna osoba, zazwyczaj nie wspominając o konkretnych dziełach. Przykład fajnego samouczka ():

Przeciwnie, na warsztatach rozmawia się o artykułach. Zwykle są to prace o jakiejś wąskiej tematyce, opowieści kierowników laboratoriów o wszystkich najnowszych pracach studentów lub artykuły, które nie zostały przyjęte na konferencję główną.
Firmy sponsorujące przyjeżdżają do ICCV ze stoiskami. W tym roku przyjechały Google, Facebook, Amazon i wiele innych międzynarodowych firm, a także duża liczba startupów - koreańskich i chińskich. Szczególnie dużo było startupów, które specjalizowały się w tagowaniu danych. Na stoiskach odbywają się występy, można zabrać ze sobą gadżety i zadać pytania. W celach łowieckich firmy sponsorujące organizują imprezy. Możesz się do nich dostać, jeśli przekonasz rekruterów, że jesteś zainteresowany i że potencjalnie możesz przejść rozmowy kwalifikacyjne. Jeśli opublikowałeś artykuł (lub w dodatku go przedstawiłeś), rozpocząłeś lub kończysz doktorat, to jest to plus, ale czasem można negocjować na stoisku, zadając ciekawe pytania inżynierom firmy.
Trendy
Konferencja pozwala przyjrzeć się całemu polu CV. Po liczbie plakatów na dany temat możesz ocenić, jak gorący jest ten temat. Niektóre wnioski nasuwają się same na podstawie słów kluczowych:

Zero-shot, one-shot, kilka strzałów, samonadzorowany i częściowo nadzorowany: nowe podejście do długo badanych zadań
Ludzie uczą się efektywniej wykorzystywać dane. Na przykład w możliwe jest wygenerowanie mimiki zwierząt, których nie było w zestawie treningowym (w aplikacji poprzez udostępnienie kilku zdjęć referencyjnych). Pomysły Deep Image Prior zostały rozwinięte i teraz sieci GAN można trenować na jednym obrazie – o tym porozmawiamy poniżej . Możesz zastosować samonadzorowanie do wstępnego szkolenia (rozwiązując problem, dla którego możesz zsyntetyzować dopasowane dane, na przykład przewidywanie kąta obrotu obrazu) lub uczyć się jednocześnie na danych oznaczonych i nieoznaczonych. W tym sensie artykuł można uznać za koronę stworzenia . A oto szkolenie wstępne na ImageNet pomaga.

3D i 360°
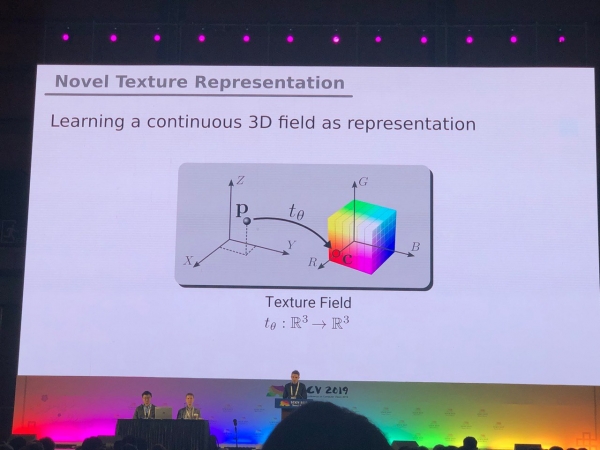
Problemy, które w większości zostały rozwiązane w przypadku zdjęć (segmentacja, detekcja) wymagają dodatkowych badań dla modeli 3D i filmów panoramicznych. Widzieliśmy wiele artykułów na temat konwersji RGB i RGB-D na 3D. Niektóre problemy, takie jak oszacowanie pozycji człowieka, można rozwiązać w bardziej naturalny sposób, przechodząc na modele 3D. Nie ma jednak jeszcze zgody co do tego, jak dokładnie reprezentować modele XNUMXD - w postaci siatki, chmury punktów, wokseli czy SDF. Oto inna opcja:
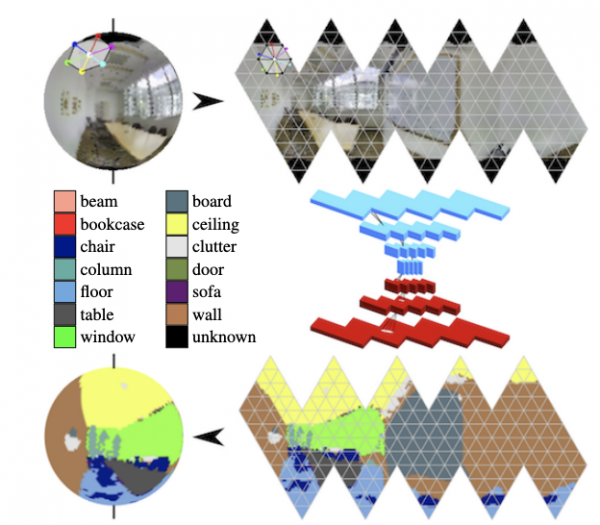
W panoramach aktywnie rozwijają się zwoje na kuli (patrz. ) i wyszukaj kluczowe obiekty w kadrze.
Wykrywanie pozycji i przewidywanie ruchu człowieka
Poczyniono już postępy w wykrywaniu pozycji w 2D – obecnie nacisk przesunął się na pracę z wieloma kamerami i w 3D. Można na przykład wykryć szkielet przez ścianę, śledząc zmiany w sygnale Wi-Fi przechodzącym przez ludzkie ciało.
Wiele pracy włożono w dziedzinie wykrywania punktów kluczowych dłoni. Pojawiły się nowe zbiory danych, w tym te oparte na filmach przedstawiających dialogi dwojga ludzi – teraz możesz przewidzieć gesty rąk na podstawie dźwięku lub tekstu rozmowy! Ten sam postęp osiągnięto w zadaniach związanych ze śledzeniem wzroku (oceną wzroku).

Można wyróżnić także duże skupisko prac związanych z przewidywaniem ruchu człowieka (np. lub ). Zadanie jest ważne i – jak wynika z rozmów z autorami – najczęściej wykorzystywane jest do analizy zachowań pieszych podczas jazdy autonomicznej.
Manipulacje ludźmi na zdjęciach i filmach, wirtualne przymierzalnie
Głównym trendem jest zmiana wizerunków twarzy zgodnie z możliwymi do zinterpretowania parametrami. Pomysły: deepfake na podstawie jednego zdjęcia, zmiana wyrazu na podstawie renderowania twarzy (), wyprzedzanie — zmień parametry (na przykład ). Transfery stylistyczne przeszły od tytułu tematu do zastosowania dzieła. Wirtualne przymierzalnie to inna historia, prawie zawsze słabo działają, dema.


Generowanie na podstawie szkiców/wykresów
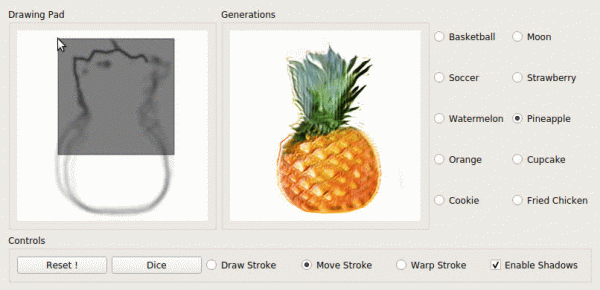
Rozwój idei „Niech siatka wygeneruje coś na podstawie wcześniejszych doświadczeń” stał się kolejnym: „Pokażmy siatce, która opcja nas interesuje”.
pozwala na wykonanie inpaintu z przewodnikiem: użytkownik może dokończyć malowanie części twarzy w wymazanym obszarze obrazu i uzyskać przywrócony obraz w zależności od ukończenia.
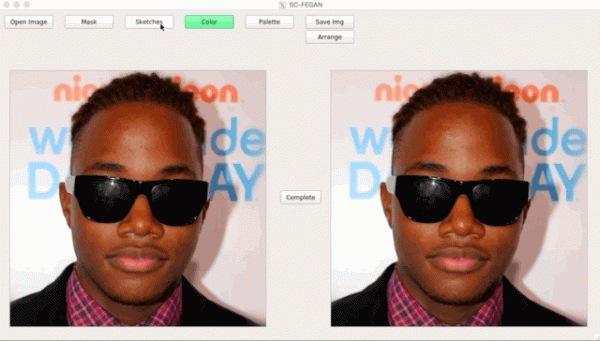
Jeden z 25 artykułów Adobe dla ICCV łączy w sobie dwa GAN: jeden kończy szkic dla użytkownika, drugi generuje fotorealistyczny obraz ze szkicu ().
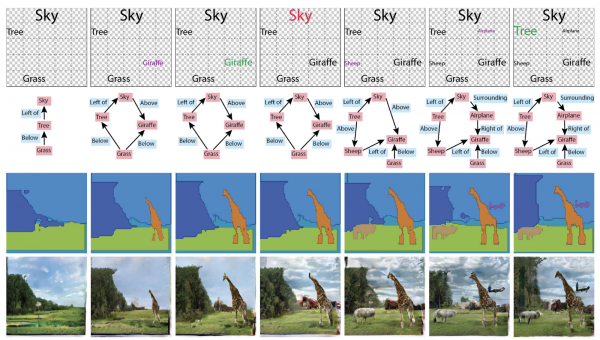
Wcześniej wykresy nie były potrzebne do generowania obrazu, ale teraz stały się pojemnikiem wiedzy o scenie. Artykuł zdobył także nagrodę Best Paper Honorable Mentions na podstawie wyników ICCV . Ogólnie rzecz biorąc, można ich używać na różne sposoby: generować wykresy z obrazków lub obrazy i teksty z wykresów.
Ponowna identyfikacja osób i samochodów, zliczenie wielkości tłumu (!)
Wiele artykułów poświęconych jest śledzeniu ludzi i ponownej identyfikacji ludzi i maszyn. Ale to, co nas zaskoczyło, to kilka artykułów na temat liczenia tłumów, wszystkie z Chin.
Plakaty 


Wręcz przeciwnie, Facebook anonimizuje zdjęcie. I robi to w ciekawy sposób: uczy sieć neuronową generowania twarzy pozbawionej unikalnych szczegółów – podobnej, ale nie na tyle podobnej, aby mogły ją poprawnie zidentyfikować systemy rozpoznawania twarzy.

Ochrona przed atakami przeciwnika
Wraz z rozwojem zastosowań widzenia komputerowego w świecie rzeczywistym (w samochodach autonomicznych, w rozpoznawaniu twarzy) coraz częściej pojawia się pytanie o niezawodność takich systemów. Aby w pełni wykorzystać CV, trzeba mieć pewność, że system jest odporny na ataki kontradyktoryjne - dlatego nie mniej artykułów o ochronie przed nimi pojawiło się nie mniej niż o samych atakach. Dużo pracy włożono w wyjaśnienie przewidywań sieci (mapa istotności) i pomiar zaufania do wyniku.
Połączone zadania
W większości zadań mających jeden cel możliwości poprawy jakości są praktycznie wyczerpane, a jednym z nowych kierunków dalszego podnoszenia jakości jest nauczenie sieci neuronowych rozwiązywania kilku podobnych problemów jednocześnie. Przykłady:
— przewidywanie działania + przewidywanie przepływu optycznego,
— prezentacja wideo + prezentacja językowa (),
- .
Znajdują się tam również artykuły dotyczące segmentacji, określania pozycji i ponownej identyfikacji zwierząt!

Przegląd najważniejszych wydarzeń
Prawie wszystkie artykuły były znane z góry, tekst był dostępny na arXiv.org. Dlatego prezentacja takich dzieł jak „Everybody Dance Now”, „FUNIT”, „Image2StyleGAN” wydaje się dość dziwna – są to dzieła bardzo przydatne, ale nie nowe. Wydaje się, że załamuje się tu klasyczny proces publikacji naukowych – nauka postępuje zbyt szybko.
Bardzo trudno wskazać te najlepsze prace – jest ich wiele, tematyka jest różna. Otrzymano kilka artykułów .
Chcemy wyróżnić prace ciekawe z punktu widzenia manipulacji obrazem, bo to jest nasz temat. Okazały się dla nas całkiem świeże i ciekawe (nie udajemy, że jesteśmy obiektywni).
SinGAN (nagroda za najlepszy artykuł) i InGAN
SinGAN: , , .
InGAN: , , .
Rozwój głębokiego obrazu Wcześniejszy pomysł Dmitrija Uljanowa, Andrei Vedaldiego i Victora Lempickiego. Zamiast uczyć sieć GAN na zbiorze danych, sieci uczą się na podstawie fragmentów tego samego obrazu, aby zapamiętać zawarte w nim statystyki. Wyszkolona sieć pozwala na edycję i animację zdjęć (SinGAN) lub generowanie nowych obrazów o dowolnym rozmiarze z tekstur oryginalnego obrazu, z zachowaniem lokalnej struktury (InGAN).
SinGAN:

InGAN:

Widząc, czego GAN nie może wygenerować
.
Sieci neuronowe generujące obrazy często przyjmują jako dane wejściowe wektor losowego szumu. W wyszkolonej sieci wiele wektorów wejściowych tworzy przestrzeń, wzdłuż której niewielkie ruchy prowadzą do niewielkich zmian w obrazie. Korzystając z optymalizacji, możesz rozwiązać problem odwrotny: znaleźć odpowiedni wektor wejściowy dla obrazu ze świata rzeczywistego. Autor pokazuje, że prawie nigdy nie jest możliwe znalezienie całkowicie pasującego obrazu w sieci neuronowej. Niektóre obiekty na zdjęciu nie są generowane (najwyraźniej ze względu na dużą zmienność tych obiektów).
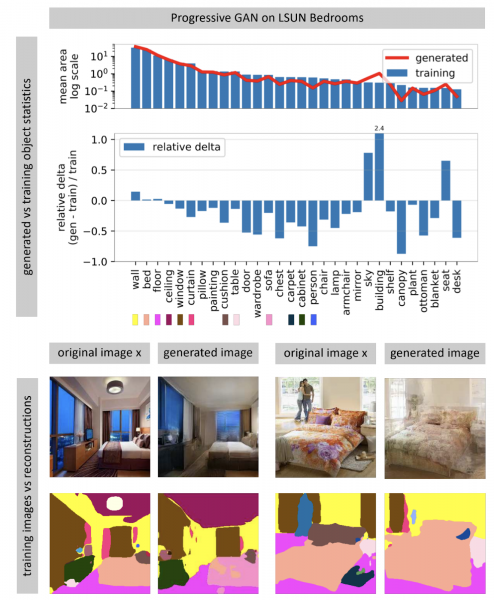
Autor stawia hipotezę, że GAN nie obejmuje całej przestrzeni obrazów, a jedynie pewien jej podzbiór, wypchany dziurami niczym ser. Gdy będziemy próbowali znaleźć w nim zdjęcia z realnego świata, zawsze nam się to nie uda, bo GAN wciąż generuje zdjęcia nie do końca realne. Różnice pomiędzy obrazem rzeczywistym a wygenerowanym można przezwyciężyć jedynie zmieniając wagi sieci, czyli przekwalifikowując ją pod kątem konkretnego zdjęcia.

Gdy sieć zostanie dodatkowo przeszkolona pod kątem konkretnego zdjęcia, można próbować różnych manipulacji tym obrazem. W poniższym przykładzie do zdjęcia dodano okno, a sieć dodatkowo wygenerowała odbicia na zabudowie kuchennej. Oznacza to, że sieć nawet po dodatkowym treningu fotograficznym nie straciła możliwości dostrzegania powiązań pomiędzy obiektami w scenie.

GANalyze: w stronę wizualnych definicji właściwości obrazu poznawczego
, .
Korzystając z podejścia zastosowanego w tej pracy, można wizualizować i analizować to, czego nauczyła się sieć neuronowa. Autorzy proponują trenowanie sieci GAN w celu tworzenia obrazów, dla których sieć będzie generować określone przewidywania. W artykule jako przykłady wykorzystano kilka sieci, w tym MemNet, który przewiduje zapamiętywanie zdjęć. Okazało się, że dla lepszej zapamiętywalności obiekt na zdjęciu powinien:
- być bliżej centrum
- mają bardziej okrągły lub kwadratowy kształt i prostą konstrukcję,
- znajdować się na jednolitym tle,
- zawierać wyraziste oczy (przynajmniej w przypadku zdjęć psów),
- być jaśniejszy, bardziej nasycony, w niektórych przypadkach bardziej czerwony.

Liquid Warping GAN: ujednolicone ramy dla imitacji ruchu człowieka, przenoszenia wyglądu i nowatorskiej syntezy widoku
, , .
Potok do generowania zdjęć ludzi, jedno zdjęcie na raz. Autorzy pokazują udane przykłady przenoszenia ruchu jednej osoby na drugą, przenoszenia ubrań między ludźmi i generowania nowych perspektyw osoby - wszystko z jednego zdjęcia. W przeciwieństwie do poprzednich prac, tutaj nie używamy kluczowych punktów w 2D (poza), ale trójwymiarowej siatki ciała (poza + kształt), aby stworzyć warunki. Autorzy wymyślili także sposób przeniesienia informacji z oryginalnego obrazu do wygenerowanego (Liquid Warping Block). Wyniki wyglądają przyzwoicie, ale rozdzielczość powstałego obrazu to tylko 3x256. Dla porównania, pojawił się rok temu vid256vid, który potrafi generować w rozdzielczości 2x2048, ale wymaga aż 1024 minut nagrania wideo jako zbiór danych.

FSGAN: Zamiana i rekonstrukcja twarzy niezależnie od podmiotu
, .
Na pierwszy rzut oka wydaje się, że nie ma w tym nic niezwykłego: deepfake o mniej więcej normalnej jakości. Ale głównym osiągnięciem pracy jest podstawienie twarzy z jednego obrazu. W odróżnieniu od poprzednich prac, szkolenie wymagało wielu fotografii konkretnej osoby. Potok okazał się uciążliwy (rekonstrukcja i segmentacja, interpolacja widoku, malowanie, mieszanie) i wymagał wielu technicznych hacków, ale wynik był tego wart.

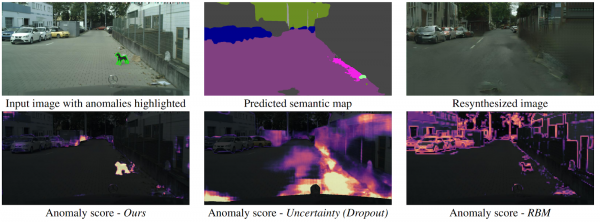
Wykrywanie nieoczekiwanego poprzez resyntezę obrazu
.
Jak dron może zrozumieć, że nagle pojawił się przed nim obiekt, który nie mieści się w żadnej klasie segmentacji semantycznej? Metod jest kilka, jednak autorzy proponują nowy, intuicyjny algorytm, który działa lepiej niż jego poprzednicy. Segmentacja semantyczna jest przewidywana na podstawie wejściowego obrazu drogi. Jest on podawany jako sygnał wejściowy do sieci GAN (pix2pixHD), która stara się odtworzyć oryginalny obraz wyłącznie z mapy semantycznej. Anomalie, które nie mieszczą się w żadnym z segmentów, będą się znacznie różnić pod względem wyniku i wygenerowanego obrazu. Trzy obrazy (oryginalny, segmentacyjny i zrekonstruowany) są następnie wprowadzane do innej sieci, która przewiduje anomalie. Zbiór danych do tego celu został wygenerowany na podstawie dobrze znanego zbioru danych Cityscapes, losowo zmieniając klasy w segmentacji semantycznej. Co ciekawe, w tym ustawieniu pies stojący na środku drogi, ale prawidłowo posegmentowany (czyli jest dla niego klasa), nie jest anomalią, bo system był w stanie go rozpoznać.
wniosek
Przed konferencją ważne jest, aby wiedzieć, jakie są Twoje zainteresowania naukowe, w jakich prezentacjach chciałbyś uczestniczyć i z kim rozmawiać. Wtedy wszystko będzie znacznie bardziej produktywne.
ICCV to przede wszystkim networking. Rozumiesz, że istnieją topowe instytuty i najlepsze wydziały naukowe, zaczynasz to rozumieć, poznajesz ludzi. A artykuły na arXiv można przeczytać – a swoją drogą to bardzo fajne, że nie trzeba nigdzie jechać, żeby zdobyć wiedzę.
Dodatkowo na konferencji możesz zgłębić tematy, które nie są Ci bliskie i dostrzec trendy. Cóż, napisz listę artykułów do przeczytania. Jeśli jesteś studentem, jest to dla Ciebie szansa na spotkanie z potencjalnym nauczycielem, jeśli jesteś z branży, to z nowym pracodawcą, a jeśli z firmą, to na pokazanie się.
Subskrybuj ! To projekt osobisty: prowadzimy go wspólnie z . Wszystkie prace, które nam się podobały podczas konferencji, zamieściliśmy tutaj: .
Źródło: www.habr.com
