

نو، تاسو میټریکونه راټولوئ. او موږ هم کوو. موږ میټریکونه هم راټولوو. البته، هغه چې د سوداګرۍ سره تړاو لري. نن به موږ تاسو ته زموږ د څارنې سیسټم کې د لومړي لینک په اړه ووایو — د سټیټس ډی سره مطابقت لرونکي راټولولو سرور. ، ولې موږ دا ولیکل او ولې موږ بروبیک پریښود.
زموږ د تیرو مقالو څخه (, ) تاسو کولی شئ ومومئ چې تر څه مودې دمخه موږ د کارولو سره ټګونه راټول کړل دا په C ژبه لیکل شوی دی. دا د موږک په څیر ساده دی (کوم چې مهم دی کله چې تاسو غواړئ ونډه واخلئ) او تر ټولو مهم، زموږ د 2 ملیون میټریکونو په ثانیه کې (MPS) د اعظمي حجم پرته له کومې ستونزې اداره کوي. اسناد د ستوري سره د 4 ملیون MPS لپاره ملاتړ ادعا کوي. دا پدې مانا ده چې تاسو به بیان شوی ارقام ترلاسه کړئ که تاسو شبکه په سمه توګه تنظیم کړئ. Linux(موږ نه پوهیږو چې که تاسو شبکه همداسې پریږدئ نو تاسو به څومره MPS ترلاسه کړئ.) د دې ګټو سره سره، موږ د بروبیک په اړه ډیری جدي شکایتونه درلودل.
ادعا ۱. د پروژې پراختیا کونکی، ګیتوب، د دې ملاتړ بند کړ: د پیچونو او اصلاحاتو خپرول، زموږ د عامه اړیکو (او نورو) منل. فعالیت په تیرو څو میاشتو کې بیا پیل شو (د فبروري - مارچ 2018 شاوخوا)، مګر له هغې دمخه نږدې دوه کاله بشپړ چوپتیا وه. سربیره پردې، پروژه د پراختیا په حال کې ده. ، کوم چې د نویو ځانګړتیاو پلي کولو لپاره یو جدي خنډ کیدی شي.
ادعا ۱. د محاسبې دقت. بروبیک د راټولولو لپاره یوازې 65536 ارزښتونه راټولوي. زموږ په قضیه کې، د ځینو میټریکونو لپاره، د راټولولو موده (30 ثانیې) کولی شي د پام وړ ډیر ارزښتونه ترلاسه کړي (په اوج کې 1,527,392). د دې نمونې اخیستلو په پایله کې، اعظمي او لږترلږه ارزښتونه بې ګټې ښکاري. د مثال په توګه، د دې په څیر:
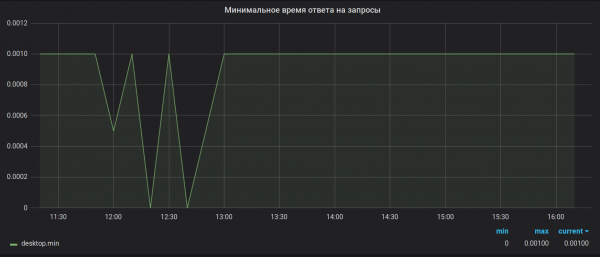
لکه څنګه چې دا وه
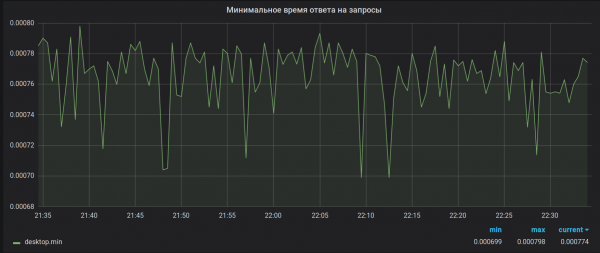
څنګه باید وای؟
د همدې دلیل لپاره، پیسې په غلط ډول محاسبه کیږي. پدې کې د 32-bit فلوټ اوور فلو سره یوه ستونزه اضافه کړئ، کوم چې سرور د ظاهرا بې ګناه میټریک ترلاسه کولو پرمهال سیګ فالټ ته لیږي، او هرڅه بشپړ کیږي. په تصادفي توګه، دا ستونزه هیڅکله نه ده حل شوې.
او په پای کې، د X ادعاد لیکلو په وخت کې، موږ چمتو یو چې دا د ټولو 14 لږ یا ډیر کار کولو سټیټسډ پلي کولو په وړاندې ازموینه وکړو چې موږ موندلي دي. راځئ چې تصور وکړو چې یو ځانګړی زیربنا دومره وده کړې چې د 4 ملیون MPS کارول نور کافي ندي. یا، حتی که دا لا وده نه وي کړې، میټریکونه ستاسو لپاره دومره مهم دي چې حتی په ګرافونو کې لنډ، 2-3 دقیقې کمښت کولی شي مهم شي او په مدیرانو کې د نه منلو وړ خپګان رامینځته کړي. څرنګه چې د خپګان درملنه یو بې شکره کار دی، تخنیکي حلونو ته اړتیا ده.
لومړی، د غلطیو زغم، ترڅو د سرور ناڅاپه ستونزه په دفتر کې د رواني زومبي اپوکالیپس لامل نشي. دوهم، د پیمانه کولو وړتیا، ترڅو دا د شبکې سټیک ته د ژور کیندلو پرته له 4 ملیون څخه ډیر MPS اداره کړي. Linux او په ارامه توګه "په عرض کې" اړین اندازې ته وده ورکړئ.
څرنګه چې موږ د پیمانه کولو لپاره یو څه سر خونه درلوده، موږ پریکړه وکړه چې د غلطۍ زغم سره پیل وکړو. "اوه! د غلطۍ زغم! دا ساده ده، موږ دا کولی شو،" موږ فکر وکړ، او دوه سرورونه یې پیل کړل، په هر یو یې د بروبیک کاپي چلوله. د دې کولو لپاره، موږ باید د میټریکونو سره ټرافیک دواړو سرورونو ته کاپي کړو او حتی د هغې لپاره د کوډ سنیپټ ولیکو. موږ د غلطۍ زغم ستونزه په دې ډول حل کړه، خو... ډېره ښه نه وه. په لومړي سر کې، هرڅه سم ښکارېدل: هر بروبیک خپل د راټولولو نسخه راټولوي، په هرو 30 ثانیو کې ګرافیټ ته معلومات لیکي، زاړه وقفه له سره لیکي (دا د ګرافیټ اړخ کې ترسره کیږي). که چیرې یو سرور ناکام شي، موږ تل دوهم یو د راټول شوي معلوماتو د خپل کاپي سره لرو. مګر دلته ستونزه ده: که چیرې یو سرور ناکام شي، نو په ګرافونو کې د "سا-ټو-سا" نمونه ښکاري. دا د دې حقیقت له امله ده چې د بروبیک 30 ثانیو وقفې همغږي نه کیږي، او کله چې یو له دوی څخه ناکام شي، نو دا له سره نه لیکي. ورته شی پیښیږي کله چې دوهم سرور پیل شي. دا د زغم وړ دی، مګر موږ غوره غواړو! د پیمانه کولو مسله هم پاتې ده. ټول میټریکونه لاهم یو واحد سرور ته ځي، او له همدې امله موږ ورته 2-4 ملیون MPS پورې محدود یو، د شبکې فعالیت پورې اړه لري.
که تاسو د واورې پاکولو پرمهال د ستونزې په اړه یو څه فکر وکړئ، نو ممکن ستاسو په ذهن کې یو څرګند نظر راشي: تاسو یو سټیټسډ ته اړتیا لرئ چې په ویشل شوي حالت کې کار وکړي. دا هغه دی چې د وخت او میټریکونو له مخې د نوډونو ترمنځ همغږي پلي کوي. "یقینا داسې حل شاید دمخه شتون ولري،" موږ وویل، او ګوګل ته لاړو... او هیڅ مو ونه موند. د مختلفو سټیټسډ لپاره د اسنادو له کتلو وروسته ( د ۲۰۱۷ کال د دسمبر تر ۱۱مې پورې، موږ په بشپړه توګه هیڅ ونه موندل. ظاهرا، نه پراختیا کونکي او نه هم د دې حلونو کاروونکي کله هم له دومره ډیرو معیارونو سره مخ شوي دي، که نه نو دوی به خامخا یو څه رامینځته کړي وای.
او بیا موږ د "لوبو" سټیټسډ، بایوینو یادونه وکړه، کوم چې موږ په "Just for Fun" هیکاتون کې لیکلی و (د پروژې نوم د هیکاتون څخه دمخه د سکریپټ لخوا رامینځته شوی و) او پوه شو چې موږ په بیړني ډول خپلو سټیټسډ ته اړتیا لرو. ولې؟
- ځکه چې په نړۍ کې ډېر کم سټیټډ کلونونه شتون لري،
- ځکه چې دا ممکنه ده چې مطلوب یا نږدې مطلوب غلطی زغم او پیمانه وړتیا چمتو کړئ (پشمول د سرورونو ترمنځ د راټول شوي میټریکونو همغږي کول او د لیږلو پرمهال د شخړو ستونزه حل کول)،
- ځکه چې تاسو کولی شئ د بروبیک په پرتله ډیر دقیق میټریکونه محاسبه کړئ،
- ځکه چې موږ کولی شو پخپله ډیر مفصل احصایې راټول کړو، کوم چې بروبیک په عملي توګه هیڅکله موږ ته ندي چمتو کړي،
- ځکه چې ما د خپل هایپر-پرفارمنس ویشل شوي پیمانه غوښتنلیک پروګرام کولو فرصت درلود، کوم چې به د بل داسې هایپر-پرفارمنس جوړښت په بشپړ ډول نقل نه کړي ... ښه، تاسو یې ترلاسه کوئ.
په څه کې ولیکم؟ البته، زنګ. ولې؟
- ځکه چې د حل یوه نمونه لا دمخه موجوده وه،
- ځکه چې د مقالې لیکوال په هغه وخت کې زنګ لا دمخه پیژندلی و او لیواله و چې په هغې کې د تولید لپاره یو څه ولیکي چې د خلاصې سرچینې په توګه یې د خپرولو امکان ولري،
- ځکه چې د GC سره ژبې زموږ لپاره مناسبې ندي ځکه چې د ترلاسه شوي ترافیک طبیعت (تقریبا ریښتیني وخت) او د GC وقفې په عملي ډول د منلو وړ ندي،
- ځکه چې موږ د C سره پرتله کولو وړ اعظمي فعالیت ته اړتیا لرو
- ځکه چې رسټ موږ ته بې ډاره همغږي راکوي، او که موږ یې په C/C++ کې لیکل پیل کړو، نو موږ به د بروبیک، زیان منونکو، بفر اوور فلو، د نسل شرایطو او نورو ویرونکو کلمو څخه ډیر څه ترلاسه کړو.
د رسټ پر ضد هم یو دلیل موجود و. شرکت په رسټ کې د پروژو جوړولو تجربه نه درلوده، او موږ پلان نه درلود چې دا زموږ په اصلي پروژه کې وکاروو. نو، جدي اندیښنې وې چې دا به کار ونکړي، مګر موږ پریکړه وکړه چې یو چانس واخلو او هڅه یې وکړو.
وخت تېر شو…
بالاخره، د څو ناکامو هڅو وروسته، لومړۍ کاري نسخه چمتو شوه. څه پیښ شول؟ دا هغه څه دي چې ښکاري.
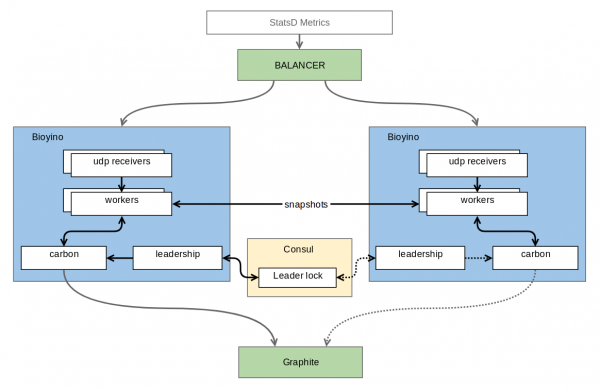
هر نوډ د میټریکونو خپل سیټ ترلاسه کوي او راټولوي یې، مګر د هغو ډولونو لپاره میټریکونه نه راټولوي چیرې چې بشپړ سیټ به د وروستي راټولولو لپاره اړین وي. نوډونه د توزیع شوي لاک پروتوکول له لارې وصل دي، کوم چې دوی ته اجازه ورکوي چې هغه یو غوره کړي (موږ دلته غږ وکړ) چې لوی ته میټریکونه لیږلو وړ وي. دا ستونزه اوس مهال د لخوا حل کیږي ، مګر په راتلونکي کې د لیکوال ارمانونه پراخیږي رافټ، چیرې چې د اجماع مشر نوډ، البته، ترټولو ارزښتناک دی. د اجماع سربیره، نوډونه ډیری وختونه (په ډیفالټ ډول، په هره ثانیه کې یو ځل) خپلو ګاونډیانو ته د مخکې راټول شوي میټریکونو هغه برخې لیږي چې دوی یې په دې ثانیه کې راټول کړي دي. دا د پیمانه کولو وړتیا او د غلطیو زغم ساتي - هر نوډ لاهم د میټریکونو بشپړ سیټ ساتي، مګر میټریکونه د TCP له لارې راټول شوي او په بائنری پروتوکول کې کوډ شوي، د UDP په پرتله د نقل لګښتونه د پام وړ کموي. د راتلونکو میټریکونو نسبتا لوی شمیر سره سره، راټولول خورا لږ حافظې او حتی لږ CPU ته اړتیا لري. زموږ د ښه کمپریس شوي میټریکونو لپاره، دا یوازې د څو لسګونو میګابایټ ډیټا ته رسیږي. یو اضافي بونس په ګرافایټ کې د غیر ضروري ډیټا بیا لیکلو څخه مخنیوی دی، لکه څنګه چې د بربیک سره قضیه وه.
د میټریکونو سره د UDP پاکټونه د شبکې تجهیزاتو کې د نوډونو ترمنځ د ساده راؤنډ رابین په کارولو سره غیر متوازن دي. په طبیعي ډول، د شبکې هارډویر د پیکټ مینځپانګې نه تجزیه کوي او له همدې امله کولی شي په هره ثانیه کې له 4M څخه ډیر پیکټونه اداره کړي، د هغو میټریکونو یادونه نه کول چې دا یې په اړه هیڅ نه پوهیږي. په پام کې نیولو سره چې میټریکونه په هر پیکټ کې په انفرادي ډول نه ترلاسه کیږي، موږ دلته د فعالیت کومه ستونزه نه اټکل کوو. که چیرې سرور خراب شي، د شبکې وسیله په چټکۍ سره (د 1-2 ثانیو دننه) دا کشف کوي او ښکته شوی سرور له گردش څخه لرې کوي. په پایله کې، غیر فعال (یعنې، غیر لیډر) نوډونه په ګرافونو کې د پام وړ کمښت سره فعال او بند کیدی شي. تر ټولو ډیر هغه میټریکونه دي چې موږ یې له لاسه ورکوو هغه ځینې میټریکونه دي چې په وروستي ثانیه کې رسیدلي. د لیډر ناڅاپي ضایع / بدلول به لاهم یو کوچنی انومالي رامینځته کړي (د 30 ثانیو وقفه لاهم د همغږۍ څخه بهر ده)، مګر که چیرې د نوډونو ترمنځ اړیکه شتون ولري، نو دا ستونزې کم کیدی شي، د بیلګې په توګه، د همغږۍ پیکټونو لیږلو سره.
د داخلي برخو په اړه لږ څه. البته، غوښتنلیک څو تارونه لري، مګر د تار جوړښت د بروبیک کې کارول شوي څخه توپیر لري. په بروبیک کې تارونه ورته دي - هر یو د معلوماتو راټولولو او راټولولو لپاره مسؤل دی. په بایوینو کې، د کارګر تارونه په دوه ډلو ویشل شوي دي: هغه چې د شبکې پروسس کولو مسؤلیت لري او هغه چې د راټولولو مسؤلیت لري. دا ویش د میټریکونو ډول پورې اړه لري د ډیر انعطاف وړ غوښتنلیک مدیریت ته اجازه ورکوي: چیرې چې شدید راټولولو ته اړتیا وي، راټولونکي اضافه کیدی شي، پداسې حال کې چې چیرې چې د شبکې ډیر ترافیک وي، د شبکې نور تارونه اضافه کیدی شي. اوس مهال، موږ په خپلو سرورونو کې د اتو شبکې تارونو او څلورو راټولولو تارونو سره کار کوو.
د محاسبې (جمع کولو) برخه خورا ستړې کوونکې ده. د شبکې جریانونو څخه ډک بفرونه د کمپیوټري تارونو ترمنځ ویشل شوي، چیرته چې دوی وروسته تحلیل او راټول شوي. د غوښتنې سره سم، میټریکونه نورو نوډونو ته لیږل کیږي. دا ټول، د نوډونو ترمنځ د معلوماتو لیږد او د قونسل سره تعامل په شمول، په غیر متقابل ډول ترسره کیږي او په چوکاټ کې پرمخ ځي. .
د شبکې هغه برخه چې د میټریکونو ترلاسه کولو مسؤلیت لري، د پراختیا لپاره ډیرې ننګونې وړاندې کړې. د شبکې جریانونو جلا کولو لومړنی هدف په جلا ادارو کې د هر جریان مصرف شوي وخت کمول وو. نه د ساکټ څخه د معلوماتو لوستلو لپاره. د غیر متزلزل UDP او منظم recvmsg کارولو اختیارونه په چټکۍ سره بې ګټې شول: پخوانی د پیښې پروسس کولو لپاره د کارونکي ځای CPU ډیر مصرفوي، پداسې حال کې چې وروستی ډیر شرایط سویچونه مصرفوي. له همدې امله، اوسنی چلند دا دی د لویو بفرونو سره (او بفرونه، ښاغلو افسرانو، یوازې هیڅ شی نه دي!). د منظم UDP ملاتړ د ټیټ بار قضیو لپاره ساتل کیږي کله چې recvmmsg ته اړتیا نه وي. ملټي میسیج حالت اصلي هدف ترلاسه کوي: د شبکې تار د خپل وخت لویه برخه د OS قطار پاکولو کې تیروي — د ساکټ څخه ډیټا لوستل او د کارونکي ځای بفر ته لیږدول، یوازې کله ناکله د بشپړ بفر راټولونکو ته د سپارلو لپاره بدلیږي. د ساکټ قطار په عملي توګه هیڅکله نه راټولیږي، او د غورځول شوي پیکټونو شمیر په سختۍ سره زیاتیږي.
تبصره
په ډیفالټ ډول، د بفر اندازه خورا لویه ټاکل شوې ده. که تاسو پریکړه وکړئ چې پخپله سرور ازموینه وکړئ، تاسو ممکن ومومئ چې د لږ شمیر میټریکونو لیږلو وروسته، دوی په ګرافایټ کې نه راځي، د شبکې سټریم بفر کې پاتې کیږي. د لږ شمیر میټریکونو اداره کولو لپاره، تاسو باید د بف سایز او ټاسک-کیو-سایز ترتیب فایلونو کې کوچني ارزښتونه تنظیم کړئ.
په پای کې، د چارټ مینه والو لپاره ځینې چارټونه.
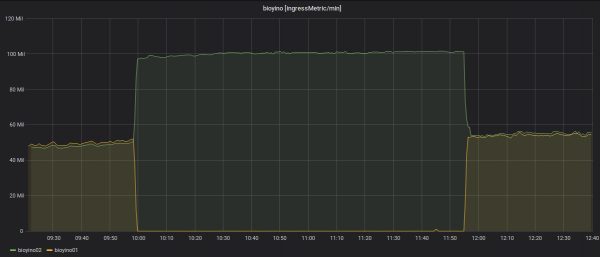
د هر سرور لپاره د راتلونکو میټریکونو شمیر په اړه احصایې: له 2 ملیون MPS څخه ډیر.
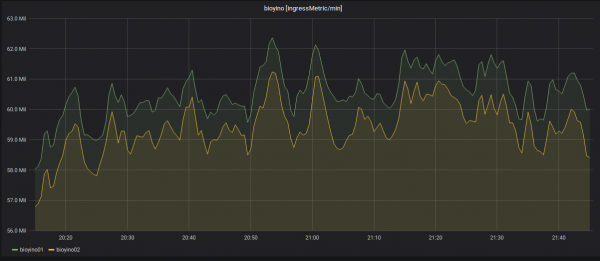
د یو نوډ غیر فعال کول او د راتلونکو میټریکونو بیا ویش.
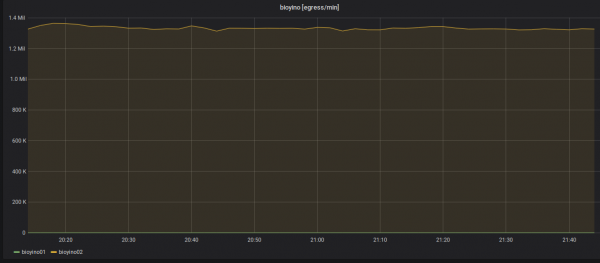
د وتلو میټریکونو په اړه احصایې: یوازې یو نوډ تل لیږي - د برید مالک.
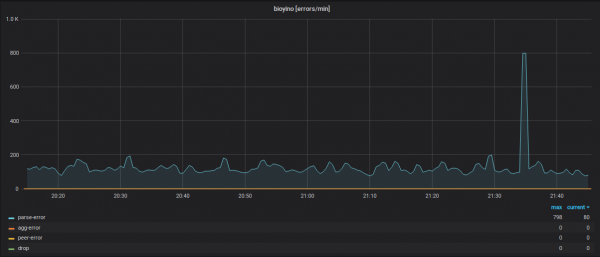
د هر نوډ د عملیاتو احصایې، د مختلفو سیسټم ماډلونو کې د غلطیو په پام کې نیولو سره.
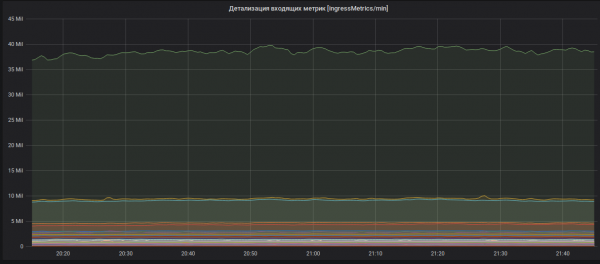
د راتلونکو میټریکونو توضیحات (میټریک نومونه پټ دي).
موږ پلان لرو چې له دې ټولو سره بل څه وکړو؟ البته، د کوډ لیکلو لپاره! دا پروژه په اصل کې د خلاصې سرچینې په توګه پلان شوې وه او د خپل ټول ژوند لپاره به همداسې پاتې شي. زموږ سمدستي پلانونو کې د رافټ خپل نسخې ته بدلول، د پیر پروتوکول ډیر پورټ ایبل ته بدلول، اضافي داخلي احصایې اضافه کول، نوي میټریک ډولونه، د بګ اصلاحات، او نور پرمختګونه شامل دي.
البته، هرڅوک چې د پروژې په پراختیا کې مرسته کولو ته لیواله وي، ښه راغلاست دی: عامه اړیکې، مسلې رامینځته کړئ، او موږ به هرکله چې امکان ولري ځواب ووایو، ښه به یې کړو، او داسې نور.
بس همدا خلک دي، لکه څنګه چې دوی وايي، زموږ فیلان واخلئ!

سرچینه: www.habr.com
