

وخت په وخت، د کیلي ګانو د یوې سیټ په واسطه د اړوندو معلوماتو د لټون دنده راپورته کیږي، تر هغه چې موږ د ریکارډونو اړین شمیر ته ورسیږو.
تر ټولو "حقیقي ژوند" مثال د دې استنباط کول دي چې ۲۰ زړې دندې، لیست شوی د کارمندانو په لیست کې (د مثال په توګه، په یوه څانګه کې). د مختلفو مدیریت ډشبورډونو لپاره چې د کاري ساحو لنډ لنډیز لري، ډیری وختونه ورته موضوع ته اړتیا وي.

په دې مقاله کې، موږ به په PostgreSQL کې د دې ستونزې لپاره د "ساده" حل پلي کولو په اړه غور وکړو، یو "هوښیار" او یو ډیر پیچلی الګوریتم. "لوپ" په SQL کې د موندلو معلوماتو پراساس د وتلو حالت سره، کوم چې د عمومي پراختیا او په نورو ورته قضیو کې د پلي کولو لپاره ګټور کیدی شي.
راځئ چې د ازموینې ډیټا سیټ واخلو له د دې لپاره چې د محصول ریکارډونه د یو وخت څخه بل وخت ته د "کود کولو" څخه مخنیوی وشي کله چې ترتیب شوي ارزښتونه سره سمون خوري، راځئ چې د موضوع شاخص د لومړني کیلي په اضافه کولو سره پراخه کړو.دا به سمدلاسه دا ځانګړی کړي او د ترتیب کولو روښانه ترتیب به تضمین کړي:
CREATE INDEX ON task(owner_id, task_date, id);
-- а старый - удалим
DROP INDEX task_owner_id_task_date_idx;دا لکه څنګه چې غږېږي لیکل شوی دی.
لومړی، راځئ چې د غوښتنې ترټولو ساده نسخه رسم کړو، د ترسره کونکو IDs تیر کړو. :
SELECT
*
FROM
task
WHERE
owner_id = ANY('{1,2,4,8,16,32,64,128,256,512}'::integer[])
ORDER BY
task_date, id
LIMIT 20; 
دا یو څه خواشینونکی دی - موږ یوازې 20 ریکارډونه امر کړل، او د انډیکس سکین هغه موږ ته بیرته راکړل. ۹۶۰ کرښې، کوم چې بیا باید ترتیب شي... راځئ چې لږ لوستلو هڅه وکړو.
انسټ + اری
لومړی غور چې زموږ سره به مرسته وکړي دا دی چې ایا موږ اړتیا لرو یوازې ۲۰ ترتیب شوي ریکارډونه، نو دا د لوستلو لپاره کافي دي د هر یو لپاره په ورته ترتیب کې له 20 څخه ډیر نه ترتیب شوي کیلي. له نېکه مرغه، مناسب شاخص (د مالک_پېژندپاڼه، د کار_نیټه، پېژندپاڼه) موږ لرو.
راځئ چې د استخراج او "ستونونو ته د خلاصیدو" ورته میکانیزم وکاروو. د بشپړ جدول ننوتنهلکه څنګه چې . موږ به د دې فنکشن په کارولو سره په صف کې فولډینګ هم پلي کړو ARRAY():
WITH T AS (
SELECT
unnest(ARRAY(
SELECT
t
FROM
task t
WHERE
owner_id = unnest
ORDER BY
task_date, id
LIMIT 20 -- ограничиваем тут...
)) r
FROM
unnest('{1,2,4,8,16,32,64,128,256,512}'::integer[])
)
SELECT
(r).*
FROM
T
ORDER BY
(r).task_date, (r).id
LIMIT 20; -- ... и тут - тоже 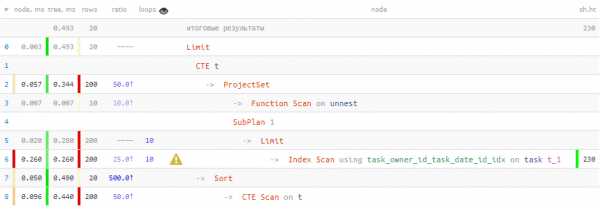
او، دا ډېر ښه دی! ۴۰٪ ګړندی او ۴.۵ ځله لږ معلومات زه باید دا ولولم.
د CTE له لارې د جدول ریکارډونو مادي کولزه غواړم ستاسو پام دې حقیقت ته راواړوم چې په ځینو مواردو کې په فرعي پوښتنې کې د لټون وروسته سمدلاسه د ریکارډ ساحو سره د کار کولو هڅه کول، پرته له دې چې دا په CTE کې "لپټ" کړي، کولی شي د د InitPlan "ضرب" د دې ورته ساحو د شمیر سره متناسب:
SELECT
((
SELECT
t
FROM
task t
WHERE
owner_id = 1
ORDER BY
task_date, id
LIMIT 1
).*);Result (cost=4.77..4.78 rows=1 width=16) (actual time=0.063..0.063 rows=1 loops=1)
Buffers: shared hit=16
InitPlan 1 (returns $0)
-> Limit (cost=0.42..1.19 rows=1 width=48) (actual time=0.031..0.032 rows=1 loops=1)
Buffers: shared hit=4
-> Index Scan using task_owner_id_task_date_id_idx on task t (cost=0.42..387.57 rows=500 width=48) (actual time=0.030..0.030 rows=1 loops=1)
Index Cond: (owner_id = 1)
Buffers: shared hit=4
InitPlan 2 (returns $1)
-> Limit (cost=0.42..1.19 rows=1 width=48) (actual time=0.008..0.009 rows=1 loops=1)
Buffers: shared hit=4
-> Index Scan using task_owner_id_task_date_id_idx on task t_1 (cost=0.42..387.57 rows=500 width=48) (actual time=0.008..0.008 rows=1 loops=1)
Index Cond: (owner_id = 1)
Buffers: shared hit=4
InitPlan 3 (returns $2)
-> Limit (cost=0.42..1.19 rows=1 width=48) (actual time=0.008..0.008 rows=1 loops=1)
Buffers: shared hit=4
-> Index Scan using task_owner_id_task_date_id_idx on task t_2 (cost=0.42..387.57 rows=500 width=48) (actual time=0.008..0.008 rows=1 loops=1)
Index Cond: (owner_id = 1)
Buffers: shared hit=4"
InitPlan 4 (returns $3)
-> Limit (cost=0.42..1.19 rows=1 width=48) (actual time=0.009..0.009 rows=1 loops=1)
Buffers: shared hit=4
-> Index Scan using task_owner_id_task_date_id_idx on task t_3 (cost=0.42..387.57 rows=500 width=48) (actual time=0.009..0.009 rows=1 loops=1)
Index Cond: (owner_id = 1)
Buffers: shared hit=4
ورته ریکارډ څلور ځله "لټون" شوی و... تر PostgreSQL 11 پورې، دا چلند په منظم ډول مخ کېده، او حل یې دا و چې دا په CTE کې "لپټ" شي، کوم چې پدې نسخو کې د اصلاح کونکي لپاره مطلق حد دی.
تکراري جمع کوونکی
په تیرو نسخو کې، موږ په ټولیزه توګه لوستل ۹۶۰ کرښې د اړتیا وړ ۲۰ لپاره. نور ۹۶۰ نه، بلکې حتی لږ - ایا دا ممکنه ده؟
راځئ چې هڅه وکړو هغه پوهه وکاروو چې موږ ورته اړتیا لرو ټولټال ۱۷ ریکارډونه. دا دی، موږ به د معلوماتو لوستل یوازې تر هغه وخته تکرار کړو تر څو چې موږ اړین شمیر ته ورسیږو.
لومړی ګام: د لیست پیل کول
په څرګنده توګه، زموږ د "هدف" د 20 ریکارډونو لیست باید زموږ د مالک_ایډ کیلي لپاره د "لومړي" ریکارډونو سره پیل شي. نو، راځئ چې لومړی هغه ومومئ د هرې کیلي لپاره "لومړی" او په لیست کې یې اضافه کړئ، په هغه ترتیب سره یې ترتیب کړئ چې موږ یې غواړو - (د کار نیټه، ID).
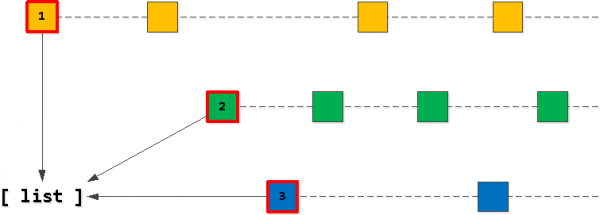
دوهم ګام: "راتلونکی" ریکارډونه ومومئ
اوس که موږ له خپل لیست څخه لومړی داخله واخلو او پیل وکړو د شاخص په اوږدو کې "ګام پورته کړئ" د مالک_ایډ کیلي ساتلو سره، بیا ټول موندل شوي ریکارډونه په پایله کې د انتخاب په راتلونکي کې دي. البته، یوازې تر هغه چې موږ د تطبیق شوي کیلي څخه تیر شو په لیست کې دوهم داخله.
که دا معلومه شي چې موږ دوهم داخله "تیر" کړې، نو بیا وروستۍ لوستل شوې لیکنه باید د لومړۍ لیکنې پر ځای په لیست کې اضافه شي. (د ورته مالک_ایډ سره)، له هغې وروسته موږ لیست بیا تنظیموو.
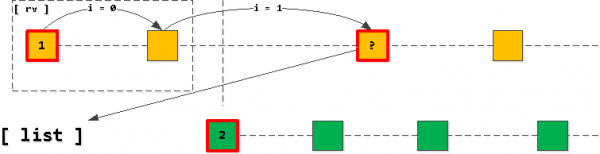
دا، موږ تل د دې حقیقت سره پای ته رسیږو چې لیست د هرې کیلي لپاره له یوې څخه ډیر داخلې نلري (که چیرې داخلې پای ته ورسیږي او موږ یې "کراس" نه کړو، نو لومړی داخله به په ساده ډول له لیست څخه ورک شي او هیڅ شی به اضافه نشي)، او دوی تل ترتیب شوی د غوښتنلیک کیلي (د کار نیټه، ID) په لوړیدو ترتیب کې.
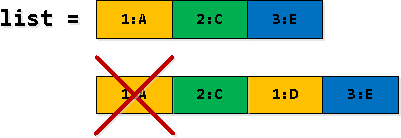
دریم ګام: ریکارډونه فلټر او پراخ کړئ
زموږ د تکراري انتخاب په ځینو کرښو کې، ځینې ریکارډونه rv نقل شوي داخلې - موږ لومړی داسې داخلې پیدا کوو لکه "په لیست کې د دوهم داخلې له پولې څخه تیریدل"، او بیا یې په لیست کې د لومړۍ داخلې په توګه بدلوو. نو، لومړۍ پیښه باید فلټر شي.
وېروونکې وروستۍ پوښتنه
WITH RECURSIVE T AS (
-- #1 : заносим в список "первые" записи по каждому из ключей набора
WITH wrap AS ( -- "материализуем" record'ы, чтобы обращение к полям не вызывало умножения InitPlan/SubPlan
WITH T AS (
SELECT
(
SELECT
r
FROM
task r
WHERE
owner_id = unnest
ORDER BY
task_date, id
LIMIT 1
) r
FROM
unnest('{1,2,4,8,16,32,64,128,256,512}'::integer[])
)
SELECT
array_agg(r ORDER BY (r).task_date, (r).id) list -- сортируем список в нужном порядке
FROM
T
)
SELECT
list
, list[1] rv
, FALSE not_cross
, 0 size
FROM
wrap
UNION ALL
-- #2 : вычитываем записи 1-го по порядку ключа, пока не перешагнем через запись 2-го
SELECT
CASE
-- если ничего не найдено для ключа 1-й записи
WHEN X._r IS NOT DISTINCT FROM NULL THEN
T.list[2:] -- убираем ее из списка
-- если мы НЕ пересекли прикладной ключ 2-й записи
WHEN X.not_cross THEN
T.list -- просто протягиваем тот же список без модификаций
-- если в списке уже нет 2-й записи
WHEN T.list[2] IS NULL THEN
-- просто возвращаем пустой список
'{}'
-- пересортировываем словарь, убирая 1-ю запись и добавляя последнюю из найденных
ELSE (
SELECT
coalesce(T.list[2] || array_agg(r ORDER BY (r).task_date, (r).id), '{}')
FROM
unnest(T.list[3:] || X._r) r
)
END
, X._r
, X.not_cross
, T.size + X.not_cross::integer
FROM
T
, LATERAL(
WITH wrap AS ( -- "материализуем" record
SELECT
CASE
-- если все-таки "перешагнули" через 2-ю запись
WHEN NOT T.not_cross
-- то нужная запись - первая из спписка
THEN T.list[1]
ELSE ( -- если не пересекли, то ключ остался как в предыдущей записи - отталкиваемся от нее
SELECT
_r
FROM
task _r
WHERE
owner_id = (rv).owner_id AND
(task_date, id) > ((rv).task_date, (rv).id)
ORDER BY
task_date, id
LIMIT 1
)
END _r
)
SELECT
_r
, CASE
-- если 2-й записи уже нет в списке, но мы хоть что-то нашли
WHEN list[2] IS NULL AND _r IS DISTINCT FROM NULL THEN
TRUE
ELSE -- ничего не нашли или "перешагнули"
coalesce(((_r).task_date, (_r).id) < ((list[2]).task_date, (list[2]).id), FALSE)
END not_cross
FROM
wrap
) X
WHERE
T.size < 20 AND -- ограничиваем тут количество
T.list IS DISTINCT FROM '{}' -- или пока список не кончился
)
-- #3 : "разворачиваем" записи - порядок гарантирован по построению
SELECT
(rv).*
FROM
T
WHERE
not_cross; -- берем только "непересекающие" записи 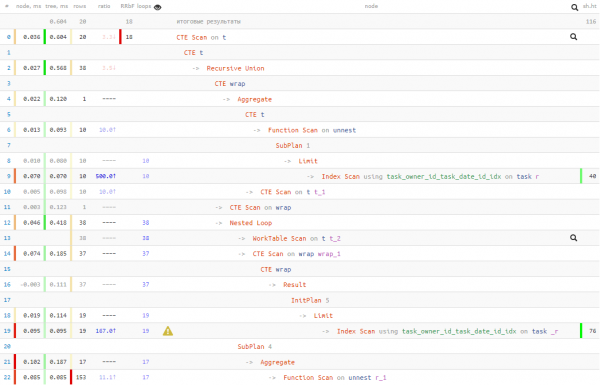
نو موږ د اجرا کولو وخت د 20٪ لپاره د معلوماتو لوستلو 50٪ سوداګري شوېدا، که تاسو دلیل لرئ چې باور ولرئ چې لوستل ممکن ورو وي (د مثال په توګه، معلومات اکثرا په زیرمه کې نه وي او باید له ډیسک څخه بیرته ترلاسه شي)، نو دا طریقه کولی شي ستاسو په لوستلو تکیه کمه کړي.
په هر حالت کې، د اجرا کولو وخت د "ساده" لومړي انتخاب په پرتله ښه و. مګر د دې دریو انتخابونو څخه کوم یو وکاروئ دا ستاسو پورې اړه لري.
سرچینه: www.habr.com
