

Arthur Khachuyan é um conhecido especialista russo em processamento de big data, fundador da empresa Social Data Hub (agora Tazeros Global). Sócio da Escola Superior de Economia da National Research University. Preparou e apresentou, em conjunto com a Escola Superior de Economia da Universidade Nacional de Pesquisa, um projeto de lei sobre Big Data no Conselho da Federação. Ele falou no Instituto Curie em Paris, na Universidade Estadual de São Petersburgo, na Universidade Federal sob o governo da Federação Russa, na Red Apple, International OpenDataDay, RIW 2016, AlfaFuturePeople.
A palestra foi gravada no festival ao ar livre “Geek Picnic” em Moscou em 2019.

Arthur Khachuyan (doravante – AH): – Se for de um grande número de indústrias - da medicina, da construção, de alguma coisa, alguma coisa, para escolher aquela onde a tecnologia de big data, aprendizado de máquina, aprendizado profundo é mais usada, então provavelmente isso é marketing. Porque nos últimos três anos, tudo o que nos rodeia em algum tipo de comunicação publicitária está agora ligado precisamente à análise de dados e precisamente ao que pode ser chamado de inteligência artificial. Portanto, hoje vou contar para vocês sobre isso de uma história tão distante...
Se você imaginar a inteligência artificial e sua aparência, provavelmente é algo assim. A imagem estranha é uma das redes neurais que escrevi há um ano para encontrar a dependência do que meu cachorro faz - quantas vezes ele precisa ficar grande, pequeno e como isso geralmente depende de quanto ele come ou não? Esta é uma piada sobre como a inteligência artificial poderia ser imaginada.

Mesmo assim, vamos pensar em como tudo funciona na comunicação publicitária. Existem três maneiras pelas quais algoritmos modernos de publicidade e marketing podem interagir conosco. É claro que a primeira história visa obter e extrair conhecimento adicional sobre você e eu, e então usá-lo para alguns propósitos bons e não tão bons; personalizar a abordagem para cada pessoa específica; Naturalmente, depois disso, crie uma certa demanda para realizar a ação alvo principal e realizar uma determinada venda.
Usando a tecnologia, eles estão tentando resolver o problema da comunicação eficaz
Se eu disser para você pensar no que o Pornhub e M. têm em comum. Vídeo”, o que você está pensando?
Comentários do público (doravante denominados C): - TV, audiência.
OH: – O meu conceito é que estes são dois locais onde as pessoas vêm em busca de um determinado tipo de serviço, ou digamos um determinado tipo de mercadoria. E esse público é diferente porque não quer contar nada ao vendedor. Ela quer entrar e obter o que lhe interessa de alguma forma explícita ou implícita. Naturalmente, ninguém vem a M. Video” não quer se comunicar com nenhum vendedor, não quer entender, não quer responder nenhuma de suas perguntas.
Portanto, a primeira história decorre de tudo isso.
Quando surgiram tecnologias para obter conhecimentos adicionais para evitar de alguma forma a comunicação com uma pessoa. Todos nós adoramos quando ligamos para o banco e ele nos diz: “Olá. Alexey, você é nosso cliente VIP. Agora algum supergerente falará com você.” Você chega a este banco e realmente existe um gerente único que pode falar com você. Infelizmente ou felizmente, nenhuma empresa ainda descobriu como contratar mil gerentes pessoais para mil clientes; e como a maioria dessas pessoas agora está online, a tarefa é entender que tipo de pessoa é essa e como se comunicar com ela corretamente antes que ela acesse algum recurso publicitário. E assim, de fato, surgiram tecnologias que tentam resolver esse problema.
Extração de dados é o novo petróleo
Vamos imaginar que você é dono de uma barraca de flores. Três pessoas vêm ver você. O primeiro fica muito tempo parado, hesita, tenta falar com você, pega uma espécie de buquê - você vai embrulhar, sai para fazer alguma coisa ali; ele foge da barraca com este buquê - você perdeu seus três mil rublos. Por que isso aconteceu? Você não sabe nada sobre essa pessoa: não conhece seu histórico de prisões no Ministério da Administração Interna, não sabe que ele é cleptomaníaco e está inscrito em dispensário psiquiátrico. Por que? Porque você viu pela primeira vez e não é analista comportamental.
Chega outra pessoa... Vitaly. Vitaly também leva muito tempo para descobrir, ele diz: “Bem, eu preciso disso e daquilo”. E você diz a ele: “Flores para a mãe, certo?” E você vende um buquê para ele.
O conceito aqui é descobrir dados suficientes para entender o que a pessoa realmente precisa. Todos imediatamente pensaram em algum tipo de rede de publicidade e assim por diante...
Todo mundo provavelmente já ouviu a frase estúpida de que “os dados são o novo petróleo” mais de uma vez? Certamente todo mundo já ouviu falar. Na verdade, as pessoas aprenderam a coletar dados há muito tempo, mas extrair dados desses dados é a tarefa que a inteligência artificial em marketing, ou algum tipo de algoritmo estatístico, está tentando resolver agora. Por que? Porque se você conversar com uma pessoa, ela pode lhe dar uma resposta certa, errada ou de alguma forma colorida. A piada que conto aos meus alunos é como as pesquisas diferem das estatísticas. Vou contar isso como uma anedota:
Isto significa que em duas aldeias decidiram realizar um estudo sobre a duração média da masculinidade. Isso significa que na primeira aldeia, Villaribo, o comprimento médio é de 15 centímetros, na aldeia de Villabaggio - 25. Sabe por quê? Porque as medições foram feitas na primeira aldeia e na segunda foi feito um levantamento.
A indústria pornográfica é o carro-chefe dos sistemas de recomendação
É por isso que a abordagem moderna é analisar todas as pessoas sem exceção, mesmo que sejam um pouco menos de 100%, mas essas são as pessoas que você não precisa perguntar, não precisa olhar para elas. Basta analisar o que hoje se chama de pegada digital para entender o que essa pessoa precisa, como falar corretamente com ela, como criar corretamente a demanda ao seu redor. Por um lado, esta é uma máquina irracional (mas você e eu sabemos disso muito bem); não queremos nos comunicar com pessoas de M. Vídeo”, e mais ainda, quando recorremos a recursos como o Pornhub, queremos obter exatamente o que precisamos.
Por que sempre falo sobre o Pornhub? Porque a indústria adulta é a primeira a chegar à análise de tais tecnologias, à implementação de tais tecnologias, à análise de dados. Se você pegar as três bibliotecas mais populares nesta área (por exemplo, TensorFlow ou Pandas para Python, para processamento de arquivos CSV e assim por diante), se você abri-lo no Github, com um breve Google de todos esses nomes você encontrará um algumas pessoas que trabalharam ou trabalham atualmente na empresa Pornhub e foram as primeiras a implementar sistemas de recomendação lá. No geral essa história está muito avançada, e mostra o quanto esse público, o quanto essa empresa avançou.

Três níveis de identificação
Existe um enorme conjunto de dados em torno de uma pessoa que pode ser identificado. Normalmente divido isso formalmente em três níveis, indo cada vez mais fundo. Naturalmente, a empresa possui seus próprios dados.
Se, digamos, estamos falando sobre a construção de um sistema de recomendação, então o primeiro nível são os dados que estão localizados na própria loja (histórico de compras, todos os tipos de transações, como uma pessoa interagiu com a interface).
Em seguida, há um nível (relativamente o maior) - é o que chamamos de fontes abertas. Não pense que eu encorajo você a vasculhar as redes sociais, mas na verdade, o que está disponível em fontes abertas abre um enorme conjunto de dados que você pode, digamos, aprender sobre uma pessoa.
E a terceira parte principal é o ambiente da própria pessoa. Sim, existe a opinião de que se uma pessoa não está nas redes sociais, não existem dados sobre ela (provavelmente você já sabe que isso não é verdade), mas o mais importante é que os dados que estão no perfil de uma pessoa (ou em alguma aplicação) representa apenas 40% do conhecimento que pode ser obtido sobre o assunto. O restante das informações é obtido em seu ambiente. A frase “diga-me quem é seu amigo e eu lhe direi quem você é” ganha um novo significado no século XNUMX porque uma enorme quantidade de dados pode ser obtida em torno dessa pessoa.
Se falarmos mais perto das comunicações publicitárias, então receber comunicações publicitárias não de publicidade, mas de algum amigo, conhecido ou pessoa verificada de alguma forma é um recurso muito interessante que muitos profissionais de marketing usam. Quando algum aplicativo de repente lhe dá um código promocional gratuito, você faz uma postagem sobre isso e, assim, atrai um novo público. Na verdade, este código promocional para o “Yandex.Taxi” condicional não foi escolhido ao acaso, mas para isso foi analisada uma enorme quantidade de dados sobre o seu potencial para atrair um novo público e de alguma forma interagir com ele.

Eles até analisam o comportamento de personagens de séries de TV
Vou te mostrar três fotos e você me diz qual é a diferença entre elas.
Este aqui:

Este:

E este:

Qual é a diferença entre eles? Tudo é simples aqui. Tal como na mecânica quântica, neste caso esta criatividade foi formada pelo observador. Ou seja, a diferença numa mesma campanha publicitária, realizada pela mesma marca ao mesmo tempo, está apenas em quem assistiu a esse criativo. Pessoalmente, quando vou ao Amediateka, ainda mostram Khal Drogo. Não sei o que Amediateka pensa sobre minhas preferências, mas por algum motivo isso acontece.
O que hoje é chamado de comunicações personalizadas é a história mais popular de atrair um público e interagir adequadamente com ele. Se na primeira fase identificamos pessoas usando dados de nossa própria marca, dados de código aberto e, por exemplo, dados do ambiente dessa pessoa, nós, após analisá-la, podemos entender quem ela é, como falar com ela corretamente e, o mais importante , que idioma ele fala, fale com ele.
Aqui a tecnologia foi tão longe que os personagens das séries de TV que as pessoas assistem agora estão sendo analisados. Ou seja, você gosta de séries de TV - eles [curtir] são assistidos, olham com quem você interagiu ali, para entender que tipo de pessoa seria adequada para você interagir. Parece um absurdo completo, mas apenas por diversão, experimente em um dos recursos - pessoas diferentes veem criativos diferentes (para interagir corretamente com eles).
Nem uma única mídia moderna ou qualquer recurso de vídeo apenas mostra algumas novidades. Vá para a mídia - é carregado um grande número de algoritmos que identificam você, entendem toda a sua atividade anterior, apelam ao modelo matemático e depois mostram algo. Neste caso, há uma história tão estranha.
Como as necessidades são determinadas? Psicometria. Fisionomia
Existem muitas abordagens (reais) para determinar as necessidades reais de uma pessoa e como comunicar-se com ela corretamente. São muitas abordagens, tudo se resolve de forma diferente, é impossível dizer o que é bom e o que é ruim. Os principais parecem saber tudo.
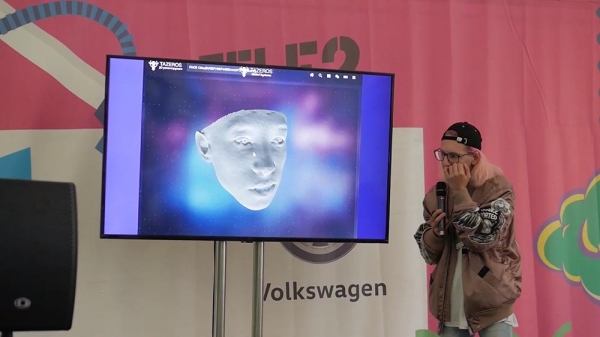
Psicometria. Depois da história com a Cambridge Analytics, houve uma espécie de reviravolta chocante, na minha opinião, porque cada segunda empresa política agora chega e diz: “Oh, você pode me fazer gostar de Trump? Eu também quero vencer e assim por diante.” Na verdade, isto, claro, não faz sentido para as nossas realidades, por exemplo, eleições políticas. Mas para determinar os psicótipos, são utilizados três modelos:
- a primeira é baseada no conteúdo que você consome – as palavras que você escreve, algumas informações que você gosta, vídeos, etc.;
- a segunda está ligada a como você interage com a interface da web, como você digita, quais botões você pressiona - na verdade, existem empresas inteiras que, com base na caligrafia do teclado, podem determinar com bastante segurança o que hoje é chamado de psicótipos.
- Não sou muito psicólogo, não entendo muito bem como funciona, mas do ponto de vista da comunicação publicitária, os públicos divididos nesses segmentos funcionam muito bem, porque alguém precisa ver uma tela vermelha com uma azul mulher, alguém precisa ver uma tela escura - fundo azul com algum tipo de abstração, e funciona muito bem. Em alguns níveis baixos - tanto que a pessoa nem pensa nisso. Qual é o principal problema do mercado publicitário atualmente? Todo mundo é um agente de inteligência, todo mundo está se escondendo, todo mundo tem um milhão de mil permissões de navegador instaladas, para não ser identificado de forma alguma - você provavelmente tem “Adblocks”, “Gostrey” e todos os tipos de aplicativos que bloqueiam o rastreamento. Por causa disso, é muito difícil entender alguma coisa sobre uma pessoa. E a tecnologia avançou - você precisa não apenas saber que essa pessoa voltou ao seu site pela 125ª vez, mas que ela também é uma pessoa tão estranha.
A fisionomia é uma ciência muito controversa. Nem é considerado ciência. Este é um grupo de pessoas que costumavam programar detectores de mentiras para alguns Ministérios da Administração Interna e agora estão engajados no que é chamado de personificação da criatividade. A abordagem aqui é muito simples: várias de suas fotografias públicas são tiradas de algumas redes sociais e a geometria tridimensional é construída a partir delas. E se você for advogado, agora dirá que se trata de uma pessoa e de um dado pessoal; mas direi que são 300 mil pontos localizados no espaço, e isso não é uma pessoa e não são dados pessoais. Isso é o que todo mundo costuma dizer quando Roskomnadzor vem até eles.
Mas falando sério, seu rosto separadamente, se seu nome e sobrenome não estiverem assinados lá, não são seus dados pessoais. A questão é que os rapazes marcam diversas características faciais que influenciam a forma como uma pessoa toma decisões e como interagir com ela corretamente. Em algumas áreas isto funciona mal, em alguns segmentos publicitários; em quais segmentos funciona muito bem. No final, acontece que quando você vai em algum recurso, você não vê apenas um banner que é mostrado para todo mundo, mas, por exemplo... agora é normal fazer 16 ou 20 opções para públicos diferentes - e funciona muito legal. Sim, isto é ainda mais triste do ponto de vista do consumidor, porque as pessoas começam a ser cada vez mais manipuladas. Mesmo assim, do ponto de vista empresarial funciona muito bem.
A caixa preta do aprendizado de máquina
Isto dá origem ao seguinte problema com tais tecnologias: afinal, para a maioria dos desenvolvedores agora, o que é chamado de aprendizagem profunda é uma “caixa preta”. Se você já esteve imerso nessa história e conversou com os desenvolvedores, eles sempre dizem: “Ah, ouça, bem, codificamos algo tão incompreensível aí e não sabemos como funciona”. Talvez alguém tenha acontecido isso.
Na verdade, isso está longe de ser verdade. O que hoje é chamado de aprendizado de máquina está longe de ser uma “caixa preta”. Há um grande número de abordagens para descrever os dados de entrada e saída e, no final, a empresa pode entender completamente com base em quais sinais a máquina decidiu mostrar a você este ou outro vídeo pornográfico. A questão é que nenhuma das empresas alguma vez divulga isso, porque: em primeiro lugar, é um segredo comercial; em segundo lugar, haverá uma enorme quantidade de dados que você nem conhecia.
Por exemplo, antes disso, numa discussão sobre ética, discutimos como as redes sociais analisam mensagens pessoais para marcar pessoas em algum tipo de matéria publicitária. Se você escreve algo para alguém, com base nisso você recebe uma tag específica para, de fato, algum tipo de comunicação publicitária. E você nunca vai provar isso, e provavelmente não faz sentido provar isso. No entanto, se padrões semelhantes fossem revelados, eles existiriam. Acontece que o mercado para a construção de tais sistemas de recomendação finge não saber por que isso aconteceu.
As pessoas não querem saber o que sabem sobre elas
E a segunda história é que o cliente nunca quer saber por que recebeu esse anúncio específico, esse produto específico. Vou te contar essa história. Minha primeira experiência na implementação comercial de sistemas de recomendação baseados em algoritmos semelhantes precisamente para fins de pesquisa foi em 2015, em uma rede muito grande de sex shops (sim, também não é uma história particularmente desagradável).

Foi oferecido aos clientes o seguinte: eles entram, fazem login em sua rede social e após cerca de 5 segundos recebem uma loja totalmente personalizada para eles, ou seja, todos os produtos mudaram - eles se enquadram em uma determinada categoria, e assim por diante . Você sabe quanto aumentou a taxa de conversão desta loja? De forma alguma! As pessoas entraram e imediatamente fugiram. Eles entraram e perceberam que lhes foi oferecido exatamente o que estavam pensando...
O problema desse teste é que embaixo de cada produto estava escrito por que aquele produto específico foi oferecido a você (“porque você é membro do grupo oculto “Mulher poderosa está procurando um homem que seja capacho”). Portanto, os sistemas de recomendação modernos nunca mostram os dados com base nos quais a “previsão” foi feita.
Uma história muito popular é a mídia porque todos usam sistemas de recomendação semelhantes. Anteriormente, os algoritmos eram muito simples: olhe a categoria “Política” - e eles mostram notícias da categoria “Política”. Agora está tudo tão complicado que eles analisam os locais onde você parou o mouse, em quais palavras você se concentrou, o que copiou, como geralmente interagiu com esta página. Depois analisa o vocabulário das próprias mensagens: sim, você não está apenas lendo notícias sobre Putin, mas de uma certa forma, com um certo colorido emocional. E quando uma pessoa recebe alguma notícia, ela nem pensa em como chegou até aqui. No entanto, ele interage com esse conteúdo.
Tudo isso, naturalmente, visa manter o pobre e infeliz homenzinho que já está enlouquecendo com a enorme quantidade de informações que o rodeiam. Deve-se dizer aqui que seria bom usar tais sistemas para personalizar o criativo ao seu redor e coletar algumas informações, mas, infelizmente, ainda não existem tais serviços.
Inteligência artificial pega o cliente no ar e cria demanda
E aqui surge uma questão filosófica muito interessante, passando da criação de um sistema de recomendação para a criação de demanda. Raramente alguém pensa nisso, mas quando você tenta perguntar ao chamado Instagram: “Por que você está coletando dados? Por que não me mostrar publicidade absolutamente aleatória?” - O Instagram vai te dizer: “Amigo, tudo isso é feito para te mostrar exatamente o que é interessante para você.” Tipo, queremos conhecê-lo com tanta precisão que possamos mostrar exatamente o que você procura.

Mas a tecnologia já ultrapassou há muito tempo esse limiar terrível e tecnologias semelhantes já não prevêem o que você precisa. Eles (atenção!) criam demanda. Esta é provavelmente a coisa mais assustadora que gira em torno da inteligência artificial nessas comunicações. O mais assustador é que ele tem sido usado em quase todos os lugares nos últimos 3-5 anos - desde os resultados de pesquisa do Google até os resultados de pesquisa do Yandex, até alguns sistemas... Ok, não direi nada de ruim sobre o Yandex; e bom.
Qual é o objetivo? Já faz muito tempo que essas comunicações publicitárias se afastaram da estratégia em que você escreve “Quero comprar uma cadeira infantil” e vê cem bilhões de publicações. Passaram para o seguinte: assim que a mulher postava uma foto com a barriga pouco visível, o marido imediatamente começava a ser seguido de mensagens: “Cara, o parto está chegando. Compre uma cadeira infantil."
Aqui, você poderia razoavelmente perguntar: por que, com avanços tão gigantescos na tecnologia, ainda vemos publicidade tão ruim nas redes sociais? O problema é que neste mercado tudo ainda é decidido pelo dinheiro, então num belo momento algum anunciante como a Coca-Cola pode chegar e dizer: “Aqui estão 20 milhões para você - mostre meus banners de merda para toda a Internet”. E eles realmente farão isso.
Mas se você fizer algum tipo de conta limpa e testar a precisão com que esses algoritmos adivinham você: eles primeiro tentam adivinhar você e depois começam a fazer algo com você com antecedência. E o cérebro humano funciona de tal forma que, ao receber uma informação que lhe é confiável, nem sequer processa o momento em que recebeu essa informação. A primeira regra para determinar se você está sonhando é entender como você veio aqui. Uma pessoa nunca se lembra do momento em que foi parar em uma determinada sala. É a mesma coisa aqui.
O Google pode começar a moldar sua visão de mundo
Tais estudos foram realizados por diversas empresas estrangeiras que atuam no i-tracking. Eles instalaram dispositivos em computadores especiais que registram para onde os olhos do sujeito de teste estão olhando. Levei de cinco a sete mil voluntários que simplesmente rolaram o feed, interagiram com as redes sociais, com a publicidade, e registraram informações sobre quais partes dos banners e criativos essas pessoas pararam de olhar.
E acontece que quando as pessoas recebem um criativo tão hiperpersonalizado, elas nem sequer pensam nisso – elas imediatamente seguem em frente, começam a interagir com ele. Do ponto de vista empresarial isso é bom, mas do ponto de vista de nós, como usuários, não é muito legal, porque - do que eles têm medo? – Que num determinado momento o “Google” condicional possa começar (ou, claro, pode não começar) a formar a sua própria visão do mundo. Amanhã, por exemplo, ele poderá começar a mostrar às pessoas a notícia de que a Terra é plana.
Brincadeirinha, mas já foram pegos tantas vezes que durante as eleições passam a dar certas informações para certas pessoas. Estamos todos habituados ao facto de o motor de busca obter tudo de forma honesta. Mas, como sempre digo, se você realmente quer saber como o mundo funciona, escreva seu próprio mecanismo de busca, sem filtros, sem prestar atenção aos direitos autorais, sem classificar alguns de seus amigos nos resultados de busca. A exibição de dados reais na Internet é geralmente diferente daquela mostrada pelo Google, Yandex, Bing e assim por diante. Alguns materiais estão escondidos porque amigos, colegas, inimigos ou outra pessoa (ou um ex-amante com quem você dormiu) – não importa.
Como Trump venceu
Quando houve a última eleição nos Estados Unidos, foi realizado um estudo muito simples. Eles atenderam às mesmas solicitações em lugares diferentes, de endereços IP diferentes, de cidades diferentes, pessoas diferentes pesquisaram a mesma coisa no Google. Convencionalmente, o pedido era do tipo: quem vai ganhar as eleições? E, surpreendentemente, os resultados foram construídos de tal forma que, nos estados onde o maior número de pessoas tentou votar no candidato errado, receberam boas notícias sobre o candidato promovido pelo Google. Qual deles? Bem, está claro qual deles - aquele que se tornou presidente. Esta é uma história absolutamente improvável, e todos estes estudos são um dedo na água. O Google pode dizer: “Gente, tudo isso é feito para que a gente mostre o conteúdo mais relevante para vocês”.
De agora em diante, você deve saber que o que é chamado de maximamente relevante não é absolutamente o caso. A empresa chama de relevante algo que precisa ser vendido a você por algum motivo bom ou ruim.
Quem não tem dinheiro agora já está se preparando para compras futuras
Há outro ponto interessante aqui sobre o qual vou falar. Um grande número de públicos ativos agora nas redes sociais e nas aplicações são os jovens. Vamos chamar assim - jovens insolventes: crianças de 8 a 9 anos que jogam jogos idiotas, são 12-13-14 que estão apenas se cadastrando nas redes sociais. Por que grandes empresas gastariam enormes orçamentos e recursos para criar aplicativos para um público não pagante que nunca é monetizado? No momento em que esse público se tornar solvente, haverá dados suficientes sobre ele para prever muito bem seu comportamento.

Agora pergunte a qualquer targetologista: qual é o público mais difícil? Dirão: altamente lucrativo. Porque vender, por exemplo, um apartamento no valor de 150 milhões de rublos através das redes sociais é quase impossível. Há casos isolados em que você faz algum tipo de publicidade para 10 mil pessoas, uma compra esse apartamento - o cliente é um sucesso... Mas um em cada dez mil, do ponto de vista estatístico, é uma porcaria completa. Então, por que é difícil identificar um público de alta renda? Porque as pessoas que hoje fazem parte de um público altamente lucrativo nasceram quando a Internet ainda era muito pequena, quando ninguém conhecia Artemy Lebedev ainda e não havia informações sobre eles. É impossível prever o seu padrão de comportamento, é impossível compreender quem são os seus formadores de opinião e de que fontes de conteúdo eles recebem.
Então, quando todos vocês se tornarem bilionários em 25 anos, e as empresas que vão vender algo a vocês terão uma enorme quantidade de dados. É por isso que temos agora um maravilhoso RGPD na Europa que impede a recolha de dados de menores.
Naturalmente, isso não funciona na prática, já que todas as crianças ainda brincam nas contas da mãe e do pai - é assim que as informações são coletadas. Da próxima vez que você der um tablet ao seu filho, pense nisso.
Absolutamente não é um futuro assustador e distópico, quando todos morrerão em uma guerra com as máquinas – uma história absolutamente real agora. Há um grande número de empresas que estão criando algoritmos para traçar perfis psicológicos de pessoas com base em como elas jogam. Uma indústria muito interessante. Com base em tudo isso, as pessoas são segmentadas para de alguma forma se comunicarem com elas.

A previsão do comportamento dessas pessoas estará disponível em 10 a 15 anos - justamente no momento em que se tornarem um público solvente. O mais importante é que essas pessoas já deram autorização prévia para processar seus dados pessoais, transferi-los a terceiros, e tudo isso é uma felicidade, e assim por diante.
Quem perderá o emprego?
E a minha última história é que todo mundo sempre pergunta o que vai acontecer daqui a 50 anos: vamos todos morrer, vai ter desemprego para os marqueteiros... Tem marqueteiros aqui que estão preocupados com o desemprego, né? Em geral, não se preocupe, pois qualquer pessoa altamente qualificada não perderá o emprego.

Não importa quais algoritmos sejam criados, não importa o quão perto a máquina se aproxime do que temos aqui (aponta para a cabeça), se ela se desenvolver com rapidez suficiente, essas pessoas nunca ficarão ociosas, porque alguém terá que criar essas coisas criativas fazer. Sim, existem todos os tipos de “gans” que fazem desenhos que se parecem com pessoas e criam música, mas ainda é improvável que as pessoas nesta área percam os seus empregos.

Eu tenho tudo com a história, então você pode tirar dúvidas se tiver mais. Obrigado.

Chumbo: – Amigos, passamos agora para o bloco “Perguntas e Respostas”. Você levanta a mão - eu vou até você.

Pergunta do público (XNUMX): – Pergunta sobre a “caixa preta”. Disseram que era possível entender especificamente por que tal ou tal resultado foi obtido para tal ou qual usuário. Isso é algum tipo de algoritmo ou precisa ser analisado sempre para cada modelo ad hoc (nota do autor: “especialmente para isso” - uma unidade fraseológica latina)? Ou existem redes prontas para algum tipo de rede neural que, grosso modo, pode fazer sentido para os negócios?
OH: – Aqui você precisa entender o seguinte: há um grande número de tarefas no aprendizado de máquina. Por exemplo, existe uma tarefa - regressão. Para regressão, nenhuma rede neural é necessária. É simples: você tem vários indicadores, precisa calcular o seguinte. Existem tarefas em que é necessário recorrer ao aprendizado profundo. Na verdade, no aprendizado profundo é difícil entender com segurança quais pesos foram atribuídos a quais neurônios, mas legalmente tudo que você precisa é entender quais dados estavam na entrada e como eles funcionaram na saída. Isso é legalmente suficiente para patentear tal decisão e é suficiente para entender em que base a história foi feita.
Não é como se você fosse ao site e visse algum tipo de banner porque você tirou uma foto ruiva no Instagram há dois meses. Se o desenvolvedor não incluir a coleta desses dados e a marcação da cor do cabelo neste modelo, então não sairá do nada.
Como vender os resultados dos sistemas de aprendizado de máquina?
Z: – É só uma questão de quê: exatamente como explicar, como vender para alguém que não entende de machine learning. Quero dizer: meu modelo passa claramente da cor do cabelo para... bem, a cor do cabelo muda... Isso é possível ou não?
OH: - Talvez sim. Mas do ponto de vista de vendas, o único esquema vai funcionar: você tem uma campanha publicitária, substituímos a audiência pela gerada pela máquina - e você só vê o resultado. Esta, infelizmente, é a única forma de convencer o cliente de forma confiável de que tal história funciona, porque existem muitas soluções no mercado que já foram implementadas e não funcionaram.
Sobre a criação de uma personalidade virtual
Z: - Olá. Obrigado pela palestra. A questão é: que chance tem uma pessoa, que por algum motivo não quer seguir o exemplo do aprendizado de máquina, de criar para si uma personalidade virtual radicalmente diferente de sua própria personalidade, por meio da interação com a interface ou para alguns Outra razão?

OH: – Existem vários plug-ins diferentes que tratam especificamente do comportamento aleatório. Há uma coisa legal - Ghostery, que, na minha opinião, esconde você quase completamente de um monte de rastreadores diferentes que não conseguem registrar essas informações. Mas, na verdade, agora tudo que você precisa é de um perfil fechado nas redes sociais para que ninguém, nenhum raspador malvado, possa coletar nada lá. Provavelmente é melhor instalar algum tipo de extensão ou escrever algo você mesmo.
Veja bem, o conceito aqui é que legalmente, por exemplo, dados pessoais referem-se a dados pelos quais você pode ser identificado, e a lei dá como exemplo seu endereço de residência, idade e assim por diante. Hoje em dia existem inúmeros dados pelos quais você pode ser identificado: a mesma caligrafia do teclado, a mesma pressão, a assinatura digital do navegador... Mais cedo ou mais tarde, uma pessoa comete um erro. Ele pode estar em algum lugar de um “café” usando “Thor”, mas no final, em um belo momento, ou a VPN vai esquecer de ligar, ou outra coisa, e nesse momento ele poderá ser identificado. Então a maneira mais fácil é criar uma conta privada e instalar alguma extensão.
O mercado está caminhando para um ponto em que você só precisa apertar um botão para obter resultados.
Z: - Obrigado pela história. Como sempre, sempre muito interessante (estou te seguindo). A questão é: que progresso há em termos de criação de sistemas positivos para os utilizadores, sistemas de recomendação? Você disse que certa vez estava trabalhando em um sistema de recomendação para encontrar um parceiro sexual, um amigo para a vida (ou uma música que uma pessoa pudesse gostar)... Quão promissor é tudo isso, e como você vê seu desenvolvimento a partir de agora? o ponto de vista da criação de sistemas que as pessoas precisam?
OH: – Em geral, o mercado está a evoluir para um ponto em que as pessoas precisam de premir um botão e obter imediatamente o que necessitam. Quanto à minha experiência na criação de aplicativos de namoro (aliás, vamos relançá-lo no final do ano), além do fato de 65% serem homens casados, o problema de recomendação mais difícil era que vários modelos eram oferecidos a uma pessoa no início da aplicação - “ Amizade", "Sexo", "Amizade Sexual" e "Negócios". As pessoas não escolhiam o que precisavam. Os homens vieram e escolheram “Amor”, mas na realidade jogaram nudez em todos, e assim por diante.
O problema era identificar uma pessoa que não se enquadrasse em um desses modelos e, de alguma forma, pegá-la e movê-la na outra direção. Devido à pequena quantidade de dados, é muito difícil determinar se se trata de um erro no algoritmo de previsão ou se uma pessoa não pertence à sua categoria. É o mesmo com a música: agora existem poucos algoritmos realmente valiosos que podem “facast” bem a música. Talvez “Yandex.Music”. Algumas pessoas acham que o algoritmo Yandex.Music é ruim. Por exemplo, eu gosto dela. Eu pessoalmente, por exemplo, não gosto do algoritmo de música do YouTube e assim por diante.
Existem, é claro, algumas sutilezas - tudo está vinculado a licenças... Mas, na realidade, a demanda por tais sistemas é bastante alta. Ao mesmo tempo, era conhecida a empresa Retail Rocket, que estava envolvida na implementação de sistemas de recomendação, mas agora de alguma forma não se sai muito bem - aparentemente porque eles não desenvolvem seus algoritmos há muito tempo. Tudo vai nesse sentido - a ponto de entrarmos e, sem pressionar nada, conseguirmos o que precisamos (e ficarmos completamente estúpidos, porque a nossa capacidade de escolha desapareceu completamente).
Marketing de influência
Z: - Olá. Meu nome é Constantino. Gostaria de levantar uma questão sobre marketing de influência. Você conhece algum sistema que permite a uma empresa selecionar um blogueiro adequado para o negócio com base em alguns dados estatísticos e assim por diante? E com que base isso é feito?

OH: – Sim, vou começar de longe e dizer desde já que o problema de todas estas tecnologias é que toda esta inteligência artificial no marketing é agora como um equilibrista na corda bamba: à esquerda estão as grandes empresas que têm muito dinheiro, e em em qualquer caso, tudo será eficaz para eles funcionarem porque suas campanhas publicitárias visam simplesmente visualizações; por outro lado, há muitas pequenas empresas para as quais isto não funcionará, porque possuem muitos dados. Até agora, a aplicabilidade dessas histórias está em algum ponto intermediário.
Quando já existem bons orçamentos e a tarefa é processar esses orçamentos corretamente (e, em princípio, já existem muitos dados)… Conheço alguns serviços, algo como o Getblogger, que parecem ter algoritmos. Para ser honesto, não estudei esses algoritmos. Posso dizer qual abordagem usamos para encontrar formadores de opinião quando precisamos dar um presente para algumas mães.
Usamos uma métrica chamada Tempo de Distribuição de Conteúdo. Funciona assim: você pega uma pessoa cujo público você está analisando e precisa coletar sistematicamente (por exemplo, uma vez a cada 5 minutos) informações sobre cada postagem, quem gostou, comentou e assim por diante. Dessa forma, você pode entender em que momento cada pessoa do seu público interagiu com o seu conteúdo. Repita essa operação para cada representante do seu público, e assim, utilizando a métrica do tempo médio de divulgação do conteúdo, ele pode, por exemplo, ser colorido em um grande gráfico de rede dessas pessoas e utilizar essa métrica para construir clusters.
Isto funciona muito bem se quisermos, por exemplo, encontrar 15 mães que mantêm a sua opinião pública em algum woman.ru. Mas esta é uma implementação técnica bastante complexa (embora teoricamente possa ser feita em Python). O resultado final é que o problema do marketing de influência nas grandes agências de publicidade é que elas precisam de blogueiros grandes, legais e caros que não trabalhem por merda nenhuma. Agora, uma marca de automóveis quer vender algum produto através de algum formador de opinião - eles precisam usar um blogueiro de carros como último recurso, porque seu público já comprou um carro ou sabe exatamente que tipo de carro deseja, apenas senta e olha para carros legais. Aqui é importante não perder a análise do público da própria pessoa.
Bots de marketing
Z: – Diga-me, até que ponto os bots nas redes sociais afetam a recolha de informação e a sua qualidade?

OH: – É uma coisa muito interessante com bots. Os bots baratos são muito fáceis de identificar - ou têm o mesmo conteúdo, ou são amigos, ou estão na mesma rede. Existem também abordagens para lidar com bots complexos. Ou você está perguntando o problema de como conectar uma pessoa à sua falsificação?
Z: – Qual será o resultado de informações de alta qualidade com todo esse lixo?
OH: – Aqui funciona assim: pelo fato de haver uma grande quantidade de dados (por exemplo, para algum tipo de pesquisa de marketing), toda essa ralé pode simplesmente ser jogada fora. Ou seja, é melhor jogar fora um pouco mais de gente real do que capturar bots, porque é inútil para eles mostrar qualquer publicidade. Mas se você coletar métricas, por exemplo, interações com banners ou sistemas de recomendação, essas contas podem ser descartadas.
Agora, nas redes sociais, existem cerca de seis por cento de personagens virtuais ou simplesmente páginas abandonadas ou introvertidos, que os algoritmos “combinam” com bots. Quanto a vincular uma pessoa à sua conta falsa, também aqui tudo está ligado ao fato de que a pessoa mais cedo ou mais tarde cometerá um erro, e o fato é que o modelo de comportamento é o mesmo - tanto sua conta real quanto sua conta falsa. Mais cedo ou mais tarde, eles assistirão ao mesmo conteúdo ou a outra coisa.
Aqui tudo se resume não à porcentagem de erro, mas à quantidade de tempo necessária para identificar uma pessoa com segurança. Para quem convive com o Instagram, esse tempo de identificação confiável se resume a cinco minutos. Para alguns – por volta de seis a oito meses.
Para quem e como vender dados?
Z: - Olá. Estou interessado em saber como os dados são vendidos entre empresas? Por exemplo, tenho um aplicativo no qual você pode descobrir (para o desenvolvedor) onde uma pessoa vai, quais lojas ela vai e quanto dinheiro ela gasta lá. E estou interessado em saber como, digamos, posso vender dados sobre meu público para essas lojas ou colocar meus dados em um enorme banco de dados e ser pago por isso?

OH: – Quanto a vender dados diretamente a alguém, você e todos os outros estavam à frente dos OFD – operadores de dados fiscais, que astuciosamente se construíram entre a transferência de cheques e a Repartição de Finanças e agora tentam vender dados a todos. Na verdade, eles derrubaram todo o mercado de análise móvel. Na verdade, você pode incorporar seu aplicativo, por exemplo, o pixel do Facebook, seu sistema DMP; então use esse público para vender. Por exemplo, o pixel “Alvo de maio”. Só não sei que tipo de público você tem, você precisa entender. Mas em qualquer caso, você pode integrar no Yandex ou no My Target, que são os maiores sistemas DMP.
Esta é uma história bastante interessante. O único problema é que você dará a eles todo o tráfego, e eles, como exchanges, assumirão a monetização desse tráfego. Eles podem ou não dizer que 10 pessoas usaram seu público. Portanto, ou você constrói sua própria rede de publicidade ou se rende a grandes DMPs.
Quem vencerá: o artista ou o técnico?
Z: – Uma pergunta um pouco distante da parte técnica. Foi dito sobre os temores dos profissionais de marketing sobre o desemprego em massa que se aproxima. Existe algum tipo de luta competitiva entre o marketing criativo (esses caras que inventaram a publicidade do frango, a publicidade da Volkswagen, ao que parece) e aqueles envolvidos no Big Data (que dizem: agora vamos apenas coletar todos os dados e entregar publicidade direcionada para todos)? Como pessoa diretamente envolvida, qual a sua opinião sobre quem vai ganhar - um artista, um técnico ou haverá algum tipo de efeito sinérgico?

OH: – Ouça, bem, eles trabalham juntos. Engenheiros não inventam criatividade. Quem é criativo não inventa um público. Há algum tipo de história multidisciplinar aqui. Os verdadeiros problemas agora são de quem senta e aperta botões, de quem faz o “trabalho de macaco”, apertando a mesma coisa todos os dias – essas são as pessoas que vão desaparecer.
Mas quem analisa os dados naturalmente permanecerá, mas alguém deve processar esses dados. Alguém terá que inventar essas fotos, desenhá-las. Uma máquina não pode ter tanta criatividade! Isso é uma loucura completa! Ou como, por exemplo, a publicidade viral da Carprice, que, aliás, funcionou muito bem. Lembre-se, havia este no YouTube: “Venda na Carprice”, absolutamente maluco. É claro que nenhuma rede neural irá gerar tal história.
De uma forma geral, defendo que não serão as pessoas que perderão o emprego, mas sim que terão um pouco mais de tempo livre e poderão dedicar esse tempo livre à auto-educação.
A publicidade primitiva desaparecerá
Z: - Em geral, a publicidade que é veiculada, os banners - em geral, até os textos de venda não estão escritos ali: “Você precisa de janelas - pegue!”, “Você precisa de outra coisa - pegue!”, isto é, não há criatividade ali.
OH: – Essa publicidade desaparecerá, é claro, mais cedo ou mais tarde. Ele desaparecerá não tanto por causa do desenvolvimento da tecnologia, mas por causa do desenvolvimento de você e de mim.
É melhor misturar o relevante com o irrelevante
Z: - Estou aqui! Tenho uma pergunta sobre o experimento que você disse que não funcionou para você (com o sistema de recomendação). Na sua opinião, o problema é o que estava assinado ali, por que é recomendado, ou será que tudo que o usuário viu lhe pareceu relevante? Porque li uma experiência para mães, e ainda não havia muitos dados, e não havia muitos dados da Internet, havia apenas dados de um supermercado que previa a gravidez (que seriam mães). E quando mostraram uma seleção de produtos para gestantes, as mães ficaram horrorizadas por terem descoberto antes de qualquer coisa oficial. E não funcionou. E para resolver este problema, misturaram deliberadamente produtos relevantes com algo completamente irrelevante.

OH: “Mostramos especificamente às pessoas a base sobre a qual as recomendações foram feitas para compreender o seu feedback. Na verdade, foi aí que nasceu o conceito de que as pessoas não precisam ser informadas de que esses são produtos super relevantes para ele.
Sim, a propósito, existe uma abordagem para misturá-los com outros irrelevantes. Mas há o oposto: às vezes as pessoas entram e interagem com esse produto irrelevante – ocorrem valores discrepantes aleatórios, modelos quebram e as coisas ficam ainda mais complicadas. Mas isso realmente existe. Além disso, muitas empresas deliberadamente, se souberem que alguém está processando seus dados (alguém poderia roubar-lhes esse resultado), às vezes confundem tudo para que possam provar mais tarde que você não obteve os dados de seu sistema de recomendação, mas de o chamado Yandex.Market.
Bloqueadores de anúncios e segurança do navegador
Z: - Olá. Você mencionou Ghostery e Adblock. Você pode nos dizer quão eficazes são esses rastreadores em geral (talvez com base em estatísticas)? E você recebeu algum pedido de empresas: eles dizem, certifique-se de que nossa publicidade não possa ser fechada pelo Adblock.
OH: – Não contactamos diretamente as plataformas de publicidade – precisamente para que não peçam para tornar a sua publicidade visível para todos. Eu pessoalmente uso o Ghostery – acho uma extensão muito legal. Agora todos os navegadores estão lutando pela privacidade: a Mozilla lançou vários tipos de atualizações, o Google Chrome agora é superseguro. Todos eles bloqueiam tudo que podem. O “Safari” até desativou o “Giroscópio” por padrão.
E essa tendência, claro, é boa (não para quem coleta dados, embora também tenha escapado), porque primeiro as pessoas bloquearam os cookies. Todos os proprietários de redes de publicidade se lembraram de uma tecnologia tão maravilhosa como as impressões digitais do navegador - são algoritmos que recebem 60 parâmetros diferentes (resolução da tela, versão, fontes instaladas) e com base neles calculam um “ID” exclusivo. Vamos prosseguir com isso. E os navegadores começaram a ter dificuldades com isso. Em geral, esta será uma batalha interminável de titãs.
O mais recente desenvolvedor Mozilla é bastante seguro. Ele praticamente não salva cookies e tem uma vida útil curta. Especialmente se você ativar o “Incógnito”, ninguém o encontrará. A questão é que será inconveniente inserir senhas em todos os serviços.
Onde a psicotipagem e a fisionomia funcionam e não funcionam?
Z: – Arthur, muito obrigado pela palestra. Também gosto de acompanhar suas palestras no YouTube. Você mencionou que os profissionais de marketing estão recorrendo cada vez mais ao uso de psicotipagem e fisionomia. Minha pergunta é: em quais categorias de marca isso funciona? Minha convicção é que isso só é adequado para FMCG. Por exemplo, escolher um carro é...
OH: – Posso fazer o download onde funciona exatamente. Isso funciona em todos os tipos de histórias como “Amediateka”, séries de TV, filmes e assim por diante. Isso funciona bem em bancos e produtos bancários, se não for o segmento premium, mas todo tipo de cartão de estudante, parcelamento - esse tipo de coisa. Isso realmente funciona muito bem em FMCG e em todos os tipos de iPhones, carregadores, toda essa porcaria. Isso funciona bem em produtos “familiares”. Embora eu saiba que na pesca (existe esse assunto)... Já houve casos com pescadores várias vezes - eles nunca podem ser segmentados de forma confiável. Eu não sei porque. Algum tipo de erro estatístico.
Isso não funciona bem com motoristas, joias ou alguns utensílios domésticos. Na verdade, não funciona bem com coisas sobre as quais as pessoas nunca escreveriam nas redes sociais – você pode verificar desta forma. Convencionalmente, com a compra de uma máquina de lavar: veja como entender quem tem máquina de lavar e quem não tem? Parece que todo mundo tem. Você pode usar dados OFD - ver quem comprou o quê usando recibos e combinar essas pessoas usando recibos. Mas, na verdade, há coisas sobre as quais você nunca falaria, por exemplo, no Instagram - é difícil trabalhar com essas coisas.
As máquinas reconhecem os truques como preenchimento estatístico.
Z: – Tenho uma pergunta sobre segmentação. É possível (ou existem de repente) um personagem aleatório condicional que se contradiz em tudo: primeiro ele pesquisa “as melhores academias” no Google, e depois pesquisa “10 maneiras de não fazer nada” no Google? E assim é em tudo. A segmentação pode acompanhar algo que se contradiz?
OH: – A única questão aqui é esta: se você usa o Google há 2 anos, contou tudo o que pode sobre você e agora instala um plugin para você que escreverá consultas aleatórias semelhantes, então, é claro, a partir das estatísticas você irá ser capaz de compreender – o que você está fazendo agora é uma exceção estatística, e tudo isso é uma questão de peneirar. Se quiser, cadastre uma nova conta, mas o volume de publicidade não mudará. Ela só vai ficar estranha. Embora ela ainda seja estranha.

Alguns anúncios 🙂
Obrigado por ficar com a gente. Gostou dos nossos artigos? Quer ver mais conteúdos interessantes? Apoie-nos fazendo um pedido ou recomendando a amigos, , um análogo exclusivo de servidores básicos, que foi inventado por nós para você: (disponível com RAID1 e RAID10, até 24 núcleos e até 40 GB DDR4).
Dell R730xd 2x mais barato no data center Equinix Tier IV em Amsterdã? Só aqui na Holanda! Dell R420 - 2x E5-2430 2.2Ghz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB - a partir de US$ 99! Ler sobre
Fonte: habr.com
