

KDB+, produto da empresa é um banco de dados colunar amplamente conhecido em círculos estreitos, extremamente rápido, projetado para armazenar séries temporais e cálculos analíticos baseados nelas. Inicialmente, era (e é) muito popular no setor financeiro - todos os 10 principais bancos de investimento e muitos fundos de hedge, bolsas e outras organizações bem conhecidos o utilizam. Recentemente, a KX decidiu ampliar sua base de clientes e agora oferecer soluções em outras áreas onde existe grande quantidade de dados, organizados por tempo ou não – telecomunicações, bioinformática, manufatura, etc. Eles também se tornaram parceiros da equipe Aston Martin Red Bull Racing na Fórmula 1, onde ajudam a coletar e processar dados de sensores de carros e analisar testes em túnel de vento. Neste artigo, quero contar quais recursos do KDB+ o tornam de alto desempenho, por que as empresas estão dispostas a gastar muito dinheiro nele e, finalmente, por que ele não é realmente um banco de dados.

Neste artigo tentarei contar de forma geral o que é KDB+, quais capacidades e limitações ele possui e quais são seus benefícios para empresas que desejam processar grandes quantidades de dados. Não entrarei em detalhes da implementação do KDB+ ou de sua linguagem de programação Q. Ambos os tópicos são muito amplos e merecem artigos separados. Muitas informações sobre esses tópicos podem ser encontradas em code.kx.com, incluindo um livro sobre Q - Q For Mortals (veja o link abaixo).
Alguns termos
- Banco de dados na memória. Um banco de dados que armazena dados em RAM para acesso mais rápido. As vantagens de tal banco de dados são claras, mas as desvantagens são a possibilidade de perda de dados e a necessidade de ter muita memória no servidor.
- Banco de dados colunar. Um banco de dados onde os dados são armazenados coluna por coluna, em vez de registro por registro. A principal vantagem desse banco de dados é que os dados de uma coluna são armazenados juntos no disco e na memória, o que acelera significativamente o acesso a ele. Não há necessidade de carregar colunas que não são utilizadas na consulta. A principal desvantagem é que é difícil modificar e excluir registros.
- Série temporal. Dados com coluna de data ou hora. Normalmente, a ordem temporal é importante para esses dados, para que você possa determinar facilmente qual registro precede ou segue o atual, ou para aplicar funções cujos resultados dependem da ordem dos registros. Os bancos de dados clássicos são construídos com base em um princípio completamente diferente - representando uma coleção de registros como um conjunto, onde a ordem dos registros não é, em princípio, definida.
- Vetor. No contexto do KDB+, esta é uma lista de elementos do mesmo tipo atômico, por exemplo, números. Em outras palavras, uma matriz de elementos. As matrizes, ao contrário das listas, podem ser armazenadas de forma compacta e processadas usando instruções do processador vetorial.
Informação histórica
A KX foi fundada em 1993 por Arthur Whitney, que anteriormente trabalhou no Morgan Stanley Bank na linguagem A+, a sucessora do APL - uma linguagem muito original e ao mesmo tempo popular no mundo financeiro. Claro que em KX, Arthur continuou com o mesmo espírito e criou a linguagem vetorial-funcional K, guiada pelas ideias do minimalismo radical. Os programas K parecem uma confusão de pontuação e caracteres especiais, o significado dos sinais e funções depende do contexto e cada operação carrega muito mais significado do que nas linguagens de programação convencionais. Devido a isso, um programa K ocupa um espaço mínimo – algumas linhas podem substituir páginas de texto em uma linguagem detalhada como Java – e é uma implementação superconcentrada do algoritmo.
Uma função em K que implementa a maior parte do gerador do analisador LL1 de acordo com uma determinada gramática:
1. pp:{q:{(x;p3(),y)};r:$[-11=@x;$x;11=@x;q[`N;$*x];10=abs@@x;q[`N;x]
2. ($)~*x;(`P;p3 x 1);(1=#x)&11=@*x;pp[{(1#x;$[2=#x;;,:]1_x)}@*x]
3. (?)~*x;(`Q;pp[x 1]);(*)~*x;(`M;pp[x 1]);(+)~*x;(`MP;pp[x 1]);(!)~*x;(`Y;p3 x 1)
4. (2=#x)&(@x 1)in 100 101 107 7 -7h;($[(@x 1)in 100 101 107h;`Ff;`Fi];p3 x 1;pp[*x])
5. (|)~*x;`S,(pp'1_x);2=#x;`C,{@[@[x;-1+#x;{x,")"}];0;"(",]}({$[".s.C"~4#x;6_-2_x;x]}'pp'x);'`pp];
6. $[@r;r;($[1<#r;".s.";""],$*r),$[1<#r;"[",(";"/:1_r),"]";""]]}
Arthur incorporou essa filosofia de extrema eficiência com um mínimo de movimentos corporais no KDB+, que surgiu em 2003 (acho que agora está claro de onde vem a letra K do nome) e nada mais é do que um intérprete da quarta versão do K linguagem. Uma versão mais amigável foi adicionada em cima de K K chamada Q. Q também adicionou suporte para um dialeto específico de SQL - QSQL, e o intérprete - suporte para tabelas como um tipo de dados do sistema, ferramentas para trabalhar com tabelas na memória e no disco, etc.
Portanto, da perspectiva do usuário, KDB+ é simplesmente um interpretador de linguagem Q com suporte para tabelas e expressões estilo LINQ semelhantes a SQL de C#. Esta é a diferença mais importante entre o KDB+ e outras bases de dados e a sua principal vantagem competitiva, que muitas vezes é esquecida. Este não é um banco de dados + linguagem auxiliar desabilitada, mas uma linguagem de programação poderosa e completa + suporte integrado para funções de banco de dados. Esta distinção terá um papel decisivo na listagem de todos os benefícios do KDB+. Por exemplo…
Tamanho
Pelos padrões modernos, o KDB+ é simplesmente microscópico em tamanho. É literalmente um arquivo executável de submegabyte e um pequeno arquivo de texto com algumas funções do sistema. Na realidade - menos de um megabyte, e por este programa as empresas pagam dezenas de milhares de dólares por ano por um processador no servidor.
- Esse tamanho permite que o KDB+ funcione bem em qualquer hardware - desde um microcomputador Pi até servidores com terabytes de memória. Isso não afeta de forma alguma a funcionalidade; além disso, Q inicia instantaneamente, o que permite que seja usado, entre outras coisas, como uma linguagem de script.
- Nesse tamanho, o interpretador Q cabe inteiramente no cache do processador, o que acelera a execução do programa.
- Com esse tamanho de arquivo executável, o processo Q ocupa um espaço insignificante na memória; você pode executar centenas deles. Além disso, se necessário, Q pode operar com dezenas ou centenas de gigabytes de memória dentro de um único processo.
versatilidade
Q é ótimo para uma ampla gama de aplicações. O Processo Q pode atuar como um banco de dados histórico e fornecer acesso rápido a terabytes de informações. Por exemplo, temos dezenas de bancos de dados históricos, em alguns dos quais um dia de dados não compactados ocupa mais de 100 gigabytes. Entretanto, sob restrições razoáveis, uma consulta ao banco de dados será concluída em dezenas a centenas de milissegundos. Em geral, temos um tempo limite universal para solicitações de usuários - 30 segundos - e isso raramente funciona.
Q poderia facilmente ser um banco de dados na memória. Novos dados são adicionados às tabelas na memória tão rapidamente que as solicitações do usuário são o fator limitante. Os dados nas tabelas são armazenados em colunas, o que significa que qualquer operação em uma coluna usará o cache do processador em capacidade total. Além disso, KX tentou implementar todas as operações básicas como aritmética através de instruções vetoriais do processador, maximizando sua velocidade. Q também pode executar tarefas que não são típicas de bancos de dados - por exemplo, processar dados de streaming e calcular em “tempo real” (com um atraso de dezenas de milissegundos a vários segundos dependendo da tarefa) várias funções de agregação para instrumentos financeiros para diferentes tempos intervalos ou construir um modelo de influência das transações realizadas no mercado e traçar seu perfil quase imediatamente após sua conclusão. Nessas tarefas, na maioria das vezes o principal atraso não é Q, mas a necessidade de sincronizar dados de diferentes fontes. A alta velocidade é alcançada devido ao fato de os dados e as funções que os processam estarem em um processo, e o processamento se reduzir à execução de diversas expressões e junções QSQL, que não são interpretadas, mas executadas por código binário.
Finalmente, você pode escrever qualquer processo de serviço em Q. Por exemplo, processos de gateway que distribuem automaticamente solicitações de usuários aos bancos de dados e servidores necessários. O programador tem total liberdade para implementar qualquer algoritmo de balanceamento, priorização, tolerância a falhas, direitos de acesso, cotas e basicamente qualquer outra coisa que seu coração desejar. O principal problema aqui é que você terá que implementar tudo isso sozinho.
Como exemplo, listarei quais tipos de processos temos. Todos eles são usados ativamente e trabalham juntos, combinando dezenas de bancos de dados diferentes em um, processando dados de diversas fontes e atendendo centenas de usuários e aplicativos.
- Conectores (feedhandler) para fontes de dados. Esses processos normalmente usam bibliotecas externas que são carregadas em Q. A interface C em Q é extremamente simples e permite criar facilmente funções de proxy para qualquer biblioteca C/C++. Q é rápido o suficiente para lidar, por exemplo, com o processamento simultâneo de uma enxurrada de mensagens FIX de todas as bolsas de valores europeias.
- Distribuidores de dados (tickerplant), que servem como elo intermediário entre conectores e consumidores. Ao mesmo tempo, eles gravam os dados recebidos em um log binário especial, proporcionando robustez aos consumidores contra perdas ou reinicializações de conexão.
- Banco de dados na memória (rdb). Esses bancos de dados fornecem o acesso mais rápido possível a dados brutos e atualizados, armazenando-os na memória. Normalmente, eles acumulam dados em tabelas durante o dia e os reiniciam à noite.
- Banco de dados persistente (pdb). Esses bancos de dados garantem que os dados atuais sejam armazenados em um banco de dados histórico. Via de regra, diferentemente do rdb, eles não armazenam dados na memória, mas usam um cache especial no disco durante o dia e copiam os dados à meia-noite para o banco de dados histórico.
- Bancos de dados históricos (hdb). Esses bancos de dados fornecem acesso a dados de dias, meses e anos anteriores. Seu tamanho (em dias) é limitado apenas pelo tamanho dos discos rígidos. Os dados podem estar localizados em qualquer lugar, principalmente em discos diferentes para agilizar o acesso. É possível compactar dados usando vários algoritmos para escolher. A estrutura do banco de dados é bem documentada e simples, os dados são armazenados coluna por coluna em arquivos regulares, para que possam ser processados, inclusive por meio do sistema operacional.
- Bancos de dados com informações agregadas. Eles armazenam várias agregações, geralmente agrupadas por nome do instrumento e intervalo de tempo. Os bancos de dados na memória atualizam seu estado a cada mensagem recebida, e os bancos de dados históricos armazenam dados pré-computados para acelerar o acesso aos dados históricos.
- Por fim, o processos de gatewayatendendo aplicativos e usuários. Q permite implementar processamento completamente assíncrono de mensagens recebidas, distribuindo-as em bancos de dados, verificando direitos de acesso, etc. Observe que as mensagens não são limitadas e na maioria das vezes não são expressões SQL, como acontece em outros bancos de dados. Na maioria das vezes, a expressão SQL está oculta em uma função especial e é construída com base nos parâmetros solicitados pelo usuário - o tempo é convertido, filtrado, os dados são normalizados (por exemplo, o preço das ações é equalizado se os dividendos forem pagos), etc.
Arquitetura típica para um tipo de dados:
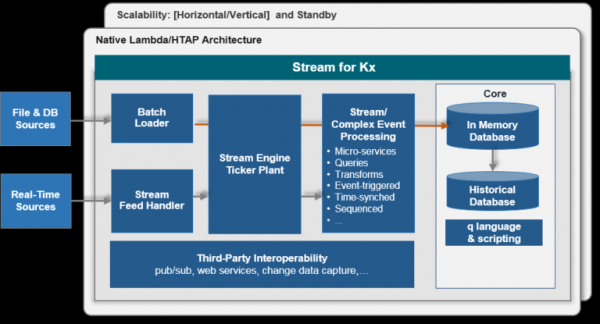
velocidade
Embora Q seja uma linguagem interpretada, também é uma linguagem vetorial. Isto significa que muitas funções integradas, particularmente as aritméticas, aceitam argumentos de qualquer forma - números, vetores, matrizes, listas - e espera-se que o programador implemente o programa como operações de array. Nessa linguagem, se você adicionar dois vetores de um milhão de elementos, não importa mais que a linguagem seja interpretada; a adição será realizada por uma função binária superotimizada. Como a maior parte do tempo em programas Q é gasto em operações com tabelas que usam essas funções vetorizadas básicas, o resultado é uma velocidade operacional muito decente, que nos permite processar uma grande quantidade de dados, mesmo em um processo. Isso é semelhante às bibliotecas matemáticas em Python - embora o próprio Python seja uma linguagem muito lenta, ele possui muitas bibliotecas excelentes, como numpy, que permitem processar dados numéricos na velocidade de uma linguagem compilada (a propósito, numpy é ideologicamente próximo de Q ).
Além disso, a KX adotou uma abordagem muito cuidadosa ao projetar tabelas e otimizar o trabalho com elas. Em primeiro lugar, são suportados vários tipos de índices, que são suportados por funções integradas e podem ser aplicados não apenas às colunas da tabela, mas também a quaisquer vetores - agrupamento, classificação, atributo de exclusividade e agrupamento especial para bancos de dados históricos. O índice é aplicado de forma simples e ajustado automaticamente ao adicionar elementos à coluna/vetor. Os índices podem ser aplicados com igual sucesso às colunas da tabela na memória e no disco. Ao executar uma consulta QSQL, os índices são usados automaticamente, se possível. Em segundo lugar, o trabalho com dados históricos é feito através do mecanismo de exibição de arquivos do SO (mapa de memória). Tabelas grandes nunca são carregadas na memória; em vez disso, as colunas necessárias são mapeadas diretamente na memória e apenas a parte delas é realmente carregada (os índices também ajudam aqui) que são necessárias. Não faz diferença para o programador se os dados estão na memória ou não; o mecanismo para trabalhar com o mmap está completamente escondido nas profundezas do Q.
KDB+ não é um banco de dados relacional; as tabelas podem conter dados arbitrários, enquanto a ordem das linhas na tabela não muda quando novos elementos são adicionados e podem e devem ser usadas ao escrever consultas. Este recurso é urgentemente necessário para trabalhar com séries temporais (dados de exchanges, telemetria, logs de eventos), pois se os dados forem classificados por tempo, o usuário não precisará usar nenhum truque SQL para encontrar a primeira ou a última linha ou N linhas na tabela, determine qual linha segue a enésima linha, etc. As junções de tabelas são ainda mais simplificadas, por exemplo, encontrar a última cotação para 16000 transações VOD.L (Vodafone) em uma tabela de 500 milhões de elementos leva cerca de um segundo no disco e dezenas de milissegundos na memória.
Um exemplo de time join - a tabela de cotações é mapeada para a memória, portanto não há necessidade de especificar VOD.L onde, o índice na coluna sym e o fato de os dados serem classificados por tempo são usados implicitamente. Quase todas as junções em Q são funções regulares, não fazem parte de uma expressão select:
1. aj[`sym`time;select from trade where date=2019.03.26, sym=`VOD.L;select from quote where date=2019.03.26]
Finalmente, vale a pena notar que os engenheiros da KX, começando pelo próprio Arthur Whitney, são verdadeiramente obcecados pela eficiência e fazem de tudo para tirar o máximo proveito dos recursos padrão do Q e otimizar os padrões de uso mais comuns.
Total
O KDB+ é popular entre as empresas principalmente devido à sua versatilidade excepcional – ele serve igualmente bem como banco de dados na memória, como banco de dados para armazenar terabytes de dados históricos e como plataforma para análise de dados. Pelo fato do processamento dos dados ocorrer diretamente no banco de dados, consegue-se alta velocidade de trabalho e economia de recursos. Uma linguagem de programação completa integrada às funções de banco de dados permite implementar toda a pilha de processos necessários em uma plataforma - desde o recebimento de dados até o processamento de solicitações de usuários.
Para mais informações,
Contras:
Uma desvantagem significativa do KDB+/Q é o alto limite de entrada. A linguagem tem uma sintaxe estranha, algumas funções estão muito sobrecarregadas (o valor, por exemplo, tem cerca de 11 casos de uso). Mais importante ainda, requer uma abordagem radicalmente diferente para escrever programas. Em uma linguagem vetorial, você deve sempre pensar em termos de transformações de array, implementar todos os loops através de diversas variantes das funções map/reduce (que são chamadas de advérbios em Q) e nunca tentar economizar dinheiro substituindo operações vetoriais por operações atômicas. Por exemplo, para encontrar o índice da enésima ocorrência de um elemento em um array, você deve escrever:
1. (where element=vector)[N]
embora isso pareça terrivelmente ineficiente para os padrões C/Java (= cria um vetor booleano, onde retorna os índices verdadeiros dos elementos nele contidos). Mas esta notação torna o significado da expressão mais claro e você usa operações vetoriais rápidas em vez de operações atômicas lentas. A diferença conceitual entre uma linguagem vetorial e outras é comparável à diferença entre abordagens imperativas e funcionais de programação, e você precisa estar preparado para isso.
Alguns usuários também estão insatisfeitos com o QSQL. A questão é que parece apenas SQL real. Na realidade, é apenas um interpretador de expressões do tipo SQL que não oferece suporte à otimização de consultas. O próprio usuário deve escrever as consultas ideais e em Q, para as quais muitos não estão preparados. Por outro lado, é claro, você sempre pode escrever a consulta ideal sozinho, em vez de depender de um otimizador de caixa preta.
Além disso, um livro sobre Q - Q For Mortals está disponível gratuitamente em , também há muitos outros materiais úteis coletados lá.
Outra grande desvantagem é o custo da licença. São dezenas de milhares de dólares por ano por CPU. Somente grandes empresas podem arcar com tais despesas. Recentemente, a KX flexibilizou sua política de licenciamento e oferece a oportunidade de pagar apenas pelo tempo de uso ou alugar o KDB+ nas nuvens Google e Amazon. KX também oferece para download (versão 32 bits ou 64 bits mediante solicitação).
concorrentes
Existem alguns bancos de dados especializados construídos com base em princípios semelhantes - colunares, na memória, focados em grandes quantidades de dados. O problema é que se trata de bancos de dados especializados. Um exemplo notável é Clickhouse. Este banco de dados tem um princípio muito semelhante ao KDB+ para armazenar dados em disco e construir um índice; ele executa algumas consultas mais rapidamente que o KDB+, embora não de forma significativa. Mas mesmo como banco de dados, o Clickhouse é mais especializado que o KDB+ - web analytics vs séries temporais arbitrárias (essa diferença é muito importante - por causa dela, por exemplo, no Clickhouse não é possível utilizar a ordenação de registros). Mas, o mais importante, Clickhouse não tem a versatilidade do KDB+, uma linguagem que permitiria processar dados diretamente no banco de dados, em vez de carregá-los primeiro em uma aplicação separada, construir expressões SQL arbitrárias, aplicar funções arbitrárias em uma consulta, criar processos não relacionado à execução de funções históricas de banco de dados. Portanto, é difícil comparar o KDB+ com outros bancos de dados; eles podem ser melhores em certos casos de uso ou simplesmente melhores quando se trata de tarefas clássicas de banco de dados, mas não conheço outra ferramenta igualmente eficaz e versátil para processar dados temporários.
Integração Python
Para tornar o KDB+ mais fácil de usar para pessoas não familiarizadas com a tecnologia, KX criou bibliotecas para integração estreita com Python em um único processo. Você pode chamar qualquer função Python de Q ou vice-versa - chamar qualquer função Q de Python (em particular, expressões QSQL). As bibliotecas convertem, se necessário (nem sempre por uma questão de eficiência), dados do formato de uma linguagem para o formato de outra. Como resultado, Q e Python vivem em uma simbiose tão próxima que as fronteiras entre eles ficam confusas. Como resultado, o programador, por um lado, tem acesso total a inúmeras bibliotecas úteis do Python, por outro lado, recebe uma base rápida para trabalhar com big data integrada ao Python, o que é especialmente útil para quem está envolvido em aprendizado de máquina. ou modelagem.
Trabalhando com Q em Python:
1. >>> q()
2.q)trade:([]date:();sym:();qty:())
3. q)
4. >>> q.insert('trade', (date(2006,10,6), 'IBM', 200))
5. k(',0')
6. >>> q.insert('trade', (date(2006,10,6), 'MSFT', 100))
7. k(',1')
referências
O site da empresa -
Site para desenvolvedores -
Livro Q Para Mortais (em inglês) -
Artigos sobre aplicativos KDB+/Q de funcionários kx -
Fonte: habr.com
