

Isso não é nem uma piada, parece que esta imagem em particular reflete com mais precisão a essência desses bancos de dados, e no final ficará claro o porquê:

De acordo com o DB-Engines Ranking, os dois bancos de dados colunares NoSQL mais populares são Cassandra (doravante CS) e HBase (HB).
Pela vontade do destino, nossa equipe de gerenciamento de carregamento de dados no Sberbank já e trabalha em estreita colaboração com a HB. Durante esse tempo, estudamos muito bem seus pontos fortes e fracos e aprendemos a cozinhá-lo. Porém, a presença de uma alternativa na forma de CS sempre nos obrigou a nos atormentar um pouco com dúvidas: fizemos a escolha certa? Além disso, os resultados , realizado pela DataStax, eles disseram que o CS vence facilmente o HB com uma pontuação quase esmagadora. Por outro lado, a DataStax é uma parte interessada e você não deve acreditar apenas na palavra deles. Também ficamos confusos com a pequena quantidade de informações sobre as condições de teste, então decidimos descobrir por conta própria quem é o rei do BigData NoSql, e os resultados obtidos foram muito interessantes.
Porém, antes de passar aos resultados dos testes realizados, é necessário descrever os aspectos significativos das configurações do ambiente. O fato é que o CS pode ser usado de um modo que permite a perda de dados. Aqueles. é quando apenas um servidor (nó) é responsável pelos dados de uma determinada chave, e se por algum motivo ele falhar, o valor dessa chave será perdido. Para muitas tarefas isto não é crítico, mas para o sector bancário isto é a excepção e não a regra. No nosso caso, é importante ter várias cópias dos dados para um armazenamento confiável.
Portanto, foi considerado apenas o modo de operação CS no modo de replicação tripla, ou seja, A criação do casespace foi realizada com os seguintes parâmetros:
CREATE KEYSPACE ks WITH REPLICATION = {'class' : 'NetworkTopologyStrategy', 'datacenter1' : 3}; A seguir, existem duas maneiras de garantir o nível de consistência necessário. Regra geral:
NO + NR > RF
O que significa que o número de confirmações dos nós durante a escrita (NW) mais o número de confirmações dos nós durante a leitura (NR) deve ser maior que o fator de replicação. No nosso caso, RF = 3, o que significa que as seguintes opções são adequadas:
2 + 2> 3
3 + 1> 3
Como é de fundamental importância armazenar os dados da forma mais confiável possível, o esquema 3+1 foi escolhido. Além disso, o HB funciona segundo um princípio semelhante, ou seja, tal comparação será mais justa.
Deve-se notar que o DataStax fez o oposto em seu estudo, eles definiram RF = 1 para CS e HB (para este último alterando as configurações do HDFS). Este é um aspecto muito importante porque o impacto no desempenho do CS neste caso é enorme. Por exemplo, a imagem abaixo mostra o aumento no tempo necessário para carregar dados no CS:
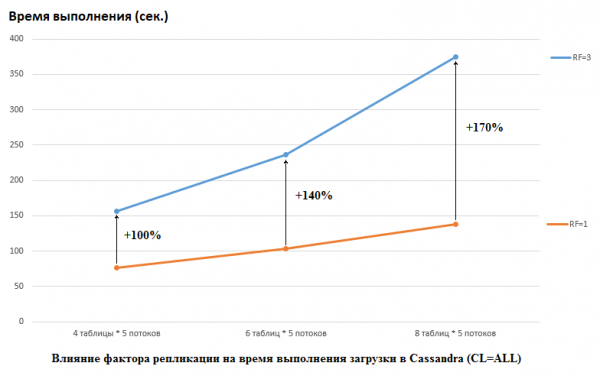
Aqui vemos o seguinte: quanto mais threads concorrentes gravam dados, mais tempo leva. Isto é natural, mas é importante que a degradação do desempenho para RF=3 seja significativamente maior. Em outras palavras, se escrevermos 4 threads em 5 tabelas cada (20 no total), então RF=3 perde cerca de 2 vezes (150 segundos para RF=3 versus 75 para RF=1). Mas se aumentarmos a carga carregando dados em 8 tabelas com 5 threads cada (40 no total), então a perda de RF=3 já é 2,7 vezes (375 segundos versus 138).
Talvez este seja parcialmente o segredo do sucesso dos testes de carga realizados pelo DataStax for CS, porque para a HB em nosso estande a alteração do fator de replicação de 2 para 3 não teve nenhum efeito. Aqueles. discos não são o gargalo HB para nossa configuração. No entanto, existem muitas outras armadilhas aqui, porque deve-se notar que nossa versão do HB foi ligeiramente corrigida e ajustada, os ambientes são completamente diferentes, etc. Também é importante notar que talvez eu simplesmente não saiba como preparar CS corretamente e existem algumas maneiras mais eficazes de trabalhar com ele, e espero que descubramos nos comentários. Mas primeiro as primeiras coisas.
Todos os testes foram realizados em um cluster de hardware composto por 4 servidores, cada um com a seguinte configuração:
CPU: Xeon E5-2680 v4 @ 2.40 GHz 64 threads.
Discos: HDD SATA de 12 peças
versão java: 1.8.0_111
Versão CS: 3.11.5
Parâmetros cassandra.ymlnum_tokens: 256
hinted_handoff_enabled: verdadeiro
sugerido_handoff_throttle_in_kb: 1024
max_hints_delivery_threads: 2
diretório_de dicas: /data10/cassandra/dicas
dicas_flush_period_in_ms: 10000
max_hints_file_size_in_mb: 128
batchlog_replay_throttle_in_kb: 1024
autenticador: AllowAllAuthenticator
autorizador: AllowAllAuthorizer
role_manager: CassandraRoleManager
funções_validade_em_ms: 2000
permissões_validade_em_ms: 2000
credenciais_validade_em_ms: 2000
particionador: org.apache.cassandra.dht.Murmur3Partitioner
data_file_directory:
- /data1/cassandra/data # cada diretório dataN é um disco separado
- /data2/cassandra/dados
- /data3/cassandra/dados
- /data4/cassandra/dados
- /data5/cassandra/dados
- /data6/cassandra/dados
- /data7/cassandra/dados
- /data8/cassandra/dados
commitlog_directory: /data9/cassandra/commitlog
cdc_enabled: falso
disk_failure_policy: parar
commit_failure_policy: parar
preparada_statements_cache_size_mb:
thrift_prepared_statements_cache_size_mb:
key_cache_size_in_mb:
key_cache_save_period: 14400
row_cache_size_in_mb: 0
row_cache_save_period: 0
counter_cache_size_in_mb:
counter_cache_save_period: 7200
diretório_saved_caches: /data10/cassandra/saved_caches
commitlog_sync: periódico
commitlog_sync_period_in_ms: 10000
commitlog_segment_size_in_mb: 32
provedor_semente:
- nome_da_classe:org.apache.cassandra.locator.SimpleSeedProvider
parâmetros:
— sementes: "*,*"
concurrent_reads: 256 # tentei 64 - nenhuma diferença notada
concurrent_writes: 256 # tentei 64 - nenhuma diferença notada
concurrent_counter_writes: 256 # tentei 64 - nenhuma diferença notada
concurrent_materialized_view_writes: 32
memtable_heap_space_in_mb: 2048 # tentei 16 GB - foi mais lento
memtable_allocation_type: heap_buffers
index_summary_capacity_in_mb:
index_summary_resize_interval_in_minutos: 60
trickle_fsync: falso
trickle_fsync_interval_in_kb: 10240
porta_de_armazenamento: 7000
ssl_storage_port: 7001
endereço_de_escuta: *
endereço_de_transmissão: *
listen_on_broadcast_address: verdadeiro
internode_authenticator: org.apache.cassandra.auth.AllowAllInternodeAuthenticator
start_native_transport: verdadeiro
porta_de_transporte_nativo: 9042
start_rpc: verdadeiro
endereço_rpc: *
porta_rpc: 9160
rpc_keepalive: verdadeiro
rpc_server_type: sincronização
thrift_framed_transport_size_in_mb: 15
backups_incrementais: falso
snapshot_before_compaction: falso
instantâneo_automático: verdadeiro
coluna_index_size_in_kb: 64
coluna_index_cache_size_in_kb: 2
compactadores_concorrentes: 4
compactação_throughput_mb_per_sec: 1600
sstable_preemptive_open_interval_in_mb: 50
read_request_timeout_in_ms: 100000
range_request_timeout_in_ms: 200000
write_request_timeout_in_ms: 40000
counter_write_request_timeout_in_ms: 100000
cas_contention_timeout_in_ms: 20000
truncar_request_timeout_in_ms: 60000
request_timeout_in_ms: 200000
slow_query_log_timeout_in_ms: 500
cross_node_timeout: falso
endpoint_snitch: GossipingPropertyFileSnitch
Dynamic_snitch_update_interval_in_ms: 100
Dynamic_snitch_reset_interval_in_ms: 600000
Dynamic_snitch_badness_threshold: 0.1
request_scheduler:org.apache.cassandra.scheduler.NoScheduler
server_encryption_options:
internode_encryption: nenhum
client_encryption_options:
habilitado: falso
compressão_internode: dc
inter_dc_tcp_nodelay: falso
tracetype_query_ttl: 86400
tracetype_repair_ttl: 604800
enable_user_defined_functions: falso
enable_scripted_user_defined_functions: falso
windows_timer_interval: 1
transparente_data_encryption_options:
habilitado: falso
tombstone_warn_threshold: 1000
tombstone_failure_threshold: 100000
batch_size_warn_threshold_in_kb: 200
batch_size_fail_threshold_in_kb: 250
unlogged_batch_across_partitions_warn_threshold: 10
compactação_large_partition_warning_threshold_mb: 100
gc_warn_threshold_in_ms: 1000
back_pression_enabled: falso
enable_materialized_views: verdadeiro
enable_sasi_indexes: verdadeiro
Configurações do GC:
### Configurações de CMS-XX:+UseParNewGC
-XX: + UseConcMarkSweepGC
-XX:+CMSParallelRemarkHabilitado
-XX: Taxa de Sobrevivência = 8
-XX:MaxTenuringThreshold=1
-XX:CMSInitiatingOccupancyFraction=75
-XX:+UsarCMSInitiatingOccupancyOnly
-XX:CMSWaitDuration=10000
-XX:+CMSParallelInitialMarkHabilitado
-XX:+CMSEdenChunksRecordAlways
-XX: + CMSClassUnloadingEnabled
A memória jvm.options foi alocada em 16 Gb (também tentamos 32 Gb, nenhuma diferença foi notada).
As tabelas foram criadas com o comando:
CREATE TABLE ks.t1 (id bigint PRIMARY KEY, title text) WITH compression = {'sstable_compression': 'LZ4Compressor', 'chunk_length_kb': 64};Versão HB: 1.2.0-cdh5.14.2 (na classe org.apache.hadoop.hbase.regionserver.HRegion excluímos MetricsRegion que levou ao GC quando o número de regiões era superior a 1000 no RegionServer)
Parâmetros HBase não padrãozookeeper.session.timeout: 120000
hbase.rpc.timeout: 2 minuto(s)
hbase.client.scanner.timeout.period: 2 minuto(s)
hbase.master.handler.count: 10
hbase.regionserver.lease.period, hbase.client.scanner.timeout.period: 2 minuto(s)
hbase.regionserver.handler.count: 160
hbase.regionserver.metahandler.count: 30
hbase.regionserver.logroll.period: 4 hora(s)
hbase.regionserver.maxlogs: 200
hbase.hregion.memstore.flush.size: 1 GiB
hbase.hregion.memstore.block.multiplicador: 6
hbase.hstore.compactionThreshold: 5
hbase.hstore.blockingStoreFiles: 200
hbase.hregion.majorcompact: 1 dia(s)
Snippet de configuração avançada do serviço HBase (válvula de segurança) para hbase-site.xml:
hbase.regionserver.wal.codecorg.apache.hadoop.hbase.regionserver.wal.IndexedWALEditCodec
hbase.master.namespace.init.timeout3600000
hbase.regionserver.optionalcacheflushinterval18000000
hbase.regionserver.thread.compaction.large12
hbase.regionserver.wal.enablecompressiontrue
hbase.hstore.compaction.max.size1073741824
hbase.server.compactchecker.interval.multiplier200
Opções de configuração Java para HBase RegionServer:
-XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:CMSInitiatingOccupancyFraction=70 -XX:+CMSParallelRemarkEnabled -XX:ReservedCodeCacheSize=256m
hbase.snapshot.master.timeoutMillis: 2 minuto(s)
hbase.snapshot.region.timeout: 2 minuto(s)
hbase.snapshot.master.timeout.millis: 2 minuto(s)
Tamanho máximo do log do servidor HBase REST: 100 MiB
Backups máximos de arquivos de log do servidor HBase REST: 5
Tamanho máximo do log do servidor HBase Thrift: 100 MiB
Backups máximos de arquivos de log do servidor HBase Thrift: 5
Tamanho máximo do log mestre: 100 MiB
Backups máximos mestres de arquivos de log: 5
Tamanho máximo do log do RegionServer: 100 MiB
Backups máximos de arquivos de log do RegionServer: 5
Janela de detecção do HBase Active Master: 4 minuto(s)
dfs.client.hedged.read.threadpool.size: 40
dfs.client.hedged.read.threshold.millis: 10 milissegundo(s)
hbase.rest.threads.min: 8
hbase.rest.threads.max: 150
Descritores máximos de arquivos de processo: 180000
hbase.thrift.minWorkerThreads: 200
hbase.master.executor.openregion.threads: 30
hbase.master.executor.closeregion.threads: 30
hbase.master.executor.serverops.threads: 60
hbase.regionserver.thread.compaction.small: 6
hbase.ipc.server.read.threadpool.size: 20
Tópicos do Movimentador de Região: 6
Tamanho de heap Java do cliente em bytes: 1 GiB
Grupo padrão do servidor HBase REST: 3 GiB
Grupo padrão do servidor HBase Thrift: 3 GiB
Tamanho de heap Java do HBase Master em bytes: 16 GiB
Tamanho de heap Java do HBase RegionServer em bytes: 32 GiB
+Zookeeper
maxClientCnxns: 601
maxSessionTimeout: 120000
Criando tabelas:
hbase org.apache.hadoop.hbase.util.RegionSplitter ns:t1 UniformSplit -c 64 -f cf
alter 'ns:t1', {NAME => 'cf', DATA_BLOCK_ENCODING => 'FAST_DIFF', COMPRESSION => 'GZ'}
Há um ponto importante aqui: a descrição do DataStax não diz quantas regiões foram usadas para criar as tabelas HB, embora isso seja crítico para grandes volumes. Portanto, para os testes foi escolhida a quantidade = 64, que permite armazenar até 640 GB, ou seja. mesa de tamanho médio.
No momento do teste, o HBase contava com 22 mil tabelas e 67 mil regiões (isso teria sido letal para a versão 1.2.0 se não fosse o patch mencionado acima).
Agora, para o código. Como não estava claro quais configurações eram mais vantajosas para uma determinada base de dados, foram realizados testes em diversas combinações. Aqueles. em alguns testes, 4 tabelas foram carregadas simultaneamente (todos os 4 nós foram usados para conexão). Nos demais testes trabalhamos com 8 tabelas diferentes. Em alguns casos, o tamanho do lote era 100, em outros 200 (parâmetro do lote - veja o código abaixo). O tamanho dos dados para valor é 10 bytes ou 100 bytes (dataSize). No total, 5 milhões de registros foram gravados e lidos em cada tabela a cada vez. Ao mesmo tempo, 5 threads foram gravados/lidos em cada tabela (thread number - thNum), cada um usando seu próprio intervalo de chaves (count = 1 milhão):
if (opType.equals("insert")) {
for (Long key = count * thNum; key < count * (thNum + 1); key += 0) {
StringBuilder sb = new StringBuilder("BEGIN BATCH ");
for (int i = 0; i < batch; i++) {
String value = RandomStringUtils.random(dataSize, true, true);
sb.append("INSERT INTO ")
.append(tableName)
.append("(id, title) ")
.append("VALUES (")
.append(key)
.append(", '")
.append(value)
.append("');");
key++;
}
sb.append("APPLY BATCH;");
final String query = sb.toString();
session.execute(query);
}
} else {
for (Long key = count * thNum; key < count * (thNum + 1); key += 0) {
StringBuilder sb = new StringBuilder("SELECT * FROM ").append(tableName).append(" WHERE id IN (");
for (int i = 0; i < batch; i++) {
sb = sb.append(key);
if (i+1 < batch)
sb.append(",");
key++;
}
sb = sb.append(");");
final String query = sb.toString();
ResultSet rs = session.execute(query);
}
}
Assim, funcionalidade semelhante foi fornecida para HB:
Configuration conf = getConf();
HTable table = new HTable(conf, keyspace + ":" + tableName);
table.setAutoFlush(false, false);
List<Get> lGet = new ArrayList<>();
List<Put> lPut = new ArrayList<>();
byte[] cf = Bytes.toBytes("cf");
byte[] qf = Bytes.toBytes("value");
if (opType.equals("insert")) {
for (Long key = count * thNum; key < count * (thNum + 1); key += 0) {
lPut.clear();
for (int i = 0; i < batch; i++) {
Put p = new Put(makeHbaseRowKey(key));
String value = RandomStringUtils.random(dataSize, true, true);
p.addColumn(cf, qf, value.getBytes());
lPut.add(p);
key++;
}
table.put(lPut);
table.flushCommits();
}
} else {
for (Long key = count * thNum; key < count * (thNum + 1); key += 0) {
lGet.clear();
for (int i = 0; i < batch; i++) {
Get g = new Get(makeHbaseRowKey(key));
lGet.add(g);
key++;
}
Result[] rs = table.get(lGet);
}
}
Como no HB o cliente deve cuidar da distribuição uniforme dos dados, a função key salting ficou assim:
public static byte[] makeHbaseRowKey(long key) {
byte[] nonSaltedRowKey = Bytes.toBytes(key);
CRC32 crc32 = new CRC32();
crc32.update(nonSaltedRowKey);
long crc32Value = crc32.getValue();
byte[] salt = Arrays.copyOfRange(Bytes.toBytes(crc32Value), 5, 7);
return ArrayUtils.addAll(salt, nonSaltedRowKey);
}
Agora a parte mais interessante: os resultados:
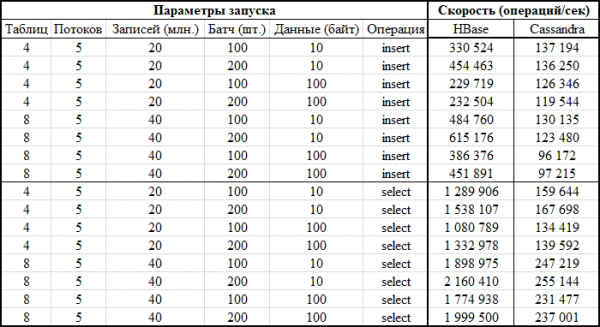
A mesma coisa em forma de gráfico:
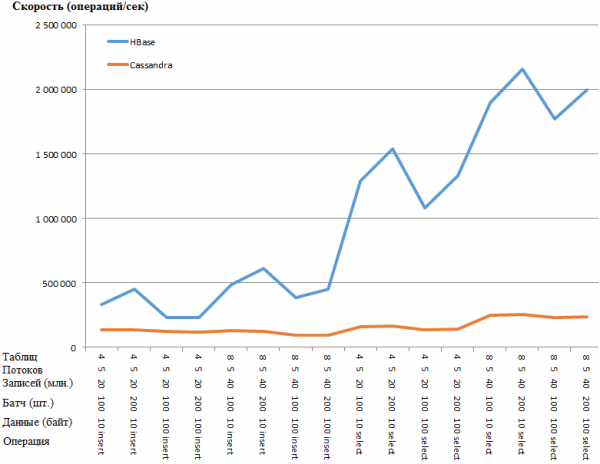
A vantagem do HB é tão surpreendente que existe a suspeita de que haja algum tipo de gargalo na configuração do CS. No entanto, pesquisar no Google e pesquisar os parâmetros mais óbvios (como concurrent_writes ou memtable_heap_space_in_mb) não acelerou as coisas. Ao mesmo tempo, as toras estão limpas e não xingam nada.
Os dados foram distribuídos uniformemente entre os nós, as estatísticas de todos os nós eram aproximadamente as mesmas.
Esta é a aparência das estatísticas da tabela de um dos nósEspaço-chave: ks
Contagem de leitura: 9383707
Latência de leitura: 0.04287025042448576 ms
Contagem de gravação: 15462012
Latência de gravação: 0.1350068438699957 ms
Liberações pendentes: 0
Tabela: t1
Contagem de tabelas SS: 16
Espaço usado (ao vivo): 148.59 MiB
Espaço utilizado (total): 148.59 MiB
Espaço usado por snapshots (total): 0 bytes
Memória off-heap usada (total): 5.17 MiB
Taxa de compressão SSTable: 0.5720989576459437
Número de partições (estimativa): 3970323
Contagem de células memtable: 0
Tamanho dos dados da tabela mem: 0 bytes
Memtable fora da memória heap usada: 0 bytes
Contagem de switches Memtable: 5
Contagem de leitura local: 2346045
Latência de leitura local: NaN ms
Contagem de gravação local: 3865503
Latência de gravação local: NaN ms
Liberações pendentes: 0
Porcentagem reparada: 0.0
Filtro Bloom falsos positivos: 25
Proporção falsa do filtro Bloom: 0.00000
Espaço do filtro Bloom usado: 4.57 MiB
Filtro Bloom da memória heap usada: 4.57 MiB
Resumo do índice da memória heap usada: 590.02 KiB
Metadados de compactação da memória heap usados: 19.45 KiB
Bytes mínimos da partição compactada: 36
Máximo de bytes da partição compactada: 42
Bytes médios da partição compactada: 42
Média de células vivas por fatia (últimos cinco minutos): NaN
Máximo de células vivas por fatia (últimos cinco minutos): 0
Média de lápides por fatia (últimos cinco minutos): NaN
Máximo de lápides por fatia (últimos cinco minutos): 0
Mutações eliminadas: 0 bytes
A tentativa de diminuir o tamanho do lote (mesmo enviando individualmente) não surtiu efeito, só piorou. É possível que de fato este seja realmente o desempenho máximo para CS, já que os resultados obtidos para CS são semelhantes aos obtidos para DataStax - cerca de centenas de milhares de operações por segundo. Além disso, se olharmos para a utilização de recursos, veremos que o CS utiliza muito mais CPU e discos:
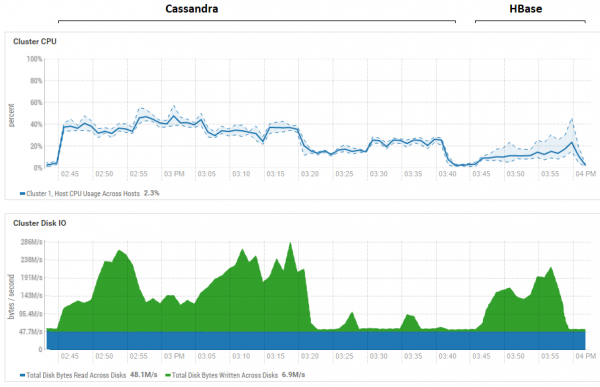
A figura mostra a utilização durante a execução de todos os testes consecutivos para ambos os bancos de dados.
Em relação à poderosa vantagem de leitura do HB. Aqui você pode ver que para ambos os bancos de dados, a utilização do disco durante a leitura é extremamente baixa (os testes de leitura são a parte final do ciclo de teste de cada banco de dados, por exemplo, para CS é das 15h20 às 15h40). No caso do HB, o motivo é claro - a maioria dos dados fica pendurada na memória, no memstore, e alguns são armazenados em cache no blockcache. Quanto ao CS, não está muito claro como funciona, mas a reciclagem do disco também não é visível, mas por precaução, foi feita uma tentativa de habilitar o cache row_cache_size_in_mb = 2048 e definir caching = {'keys': 'ALL', 'rows_per_partition': '2000000'}, mas isso tornou tudo ainda um pouco pior.
Vale ressaltar também mais uma vez um ponto importante sobre a quantidade de regiões em HB. No nosso caso, o valor foi especificado como 64. Se reduzirmos e igualarmos, por exemplo, 4, então na leitura a velocidade cai 2 vezes. A razão é que o memstore ficará cheio mais rápido e os arquivos serão liberados com mais frequência e durante a leitura, mais arquivos precisarão ser processados, o que é uma operação bastante complicada para o HB. Em condições reais, isso pode ser tratado pensando em uma estratégia de pré-divisão e compactação; em particular, usamos um utilitário escrito por nós mesmos que coleta lixo e compacta HFiles constantemente em segundo plano. É bem possível que para os testes do DataStax eles tenham alocado apenas 1 região por tabela (o que não é correto) e isso esclareceria um pouco porque o HB foi tão inferior em seus testes de leitura.
As seguintes conclusões preliminares são tiradas disso. Supondo que nenhum erro grave tenha sido cometido durante os testes, então Cassandra parece um colosso com pés de barro. Mais precisamente, enquanto se equilibra em uma perna, como na foto do início do artigo, ela apresenta resultados relativamente bons, mas em uma luta nas mesmas condições ela perde completamente. Ao mesmo tempo, levando em consideração a baixa utilização da CPU em nosso hardware, aprendemos a plantar dois HBs RegionServer por host e, assim, dobramos o desempenho. Aqueles. Tendo em conta a utilização de recursos, a situação da CS é ainda mais deplorável.
É claro que estes testes são bastante sintéticos e a quantidade de dados utilizados aqui é relativamente modesta. É possível que se mudássemos para terabytes a situação fosse diferente, mas enquanto para HB podemos carregar terabytes, para CS isso acabou sendo problemático. Muitas vezes gerava uma OperationTimedOutException mesmo com esses volumes, embora os parâmetros de espera por uma resposta já tenham sido aumentados várias vezes em comparação com os padrões.
Espero que através de esforços conjuntos encontremos os gargalos do CS e se conseguirmos agilizar, então no final do post com certeza acrescentarei informações sobre os resultados finais.
UPD: Graças aos conselhos dos camaradas, consegui agilizar a leitura. Era:
159 operações (644 tabelas, 4 streams, lote 5).
Adicionado:
.withLoadBalancingPolicy(new TokenAwarePolicy(DCAwareRoundRobinPolicy.builder().build()))
E brinquei com o número de tópicos. O resultado é o seguinte:
4 tabelas, 100 threads, lote = 1 (peça por peça): 301 operações
4 tabelas, 100 threads, lote = 10: 447 operações
4 tabelas, 100 threads, lote = 100: 625 operações
Posteriormente aplicarei outras dicas de ajuste, executarei um ciclo completo de testes e adicionarei os resultados no final do post.
Fonte: habr.com
