

Começou em 10 de agosto em Slurm , no qual o analisamos completamente - desde abstrações básicas até parâmetros de rede.
Neste artigo falaremos sobre a história do Docker e suas principais abstrações: Image, Cli, Dockerfile. A palestra é destinada a iniciantes, portanto é improvável que seja do interesse de usuários experientes. Não haverá sangue, apêndice ou imersão profunda. O básico.

O que é Docker
Vejamos a definição de Docker da Wikipedia.
Docker é um software para automatizar a implantação e gerenciamento de aplicações em ambientes conteinerizados.
Nada fica claro nesta definição. Não está especialmente claro o que significa “em ambientes que suportam conteinerização”. Para descobrir, vamos voltar no tempo. Comecemos com a era que convencionalmente chamo de “Era Monolítica”.
Era monolítica
A era monolítica é o início dos anos 2000, quando todos os aplicativos eram monolíticos, com um monte de dependências. O desenvolvimento demorou muito. Ao mesmo tempo, não havia muitos servidores, todos nós os conhecíamos pelo nome e os monitorávamos. Há uma comparação tão engraçada:

Animais de estimação são animais domésticos. Na era monolítica, tratávamos nossos servidores como animais de estimação, cuidados e cuidados, soprando partículas de poeira. E para uma melhor gestão dos recursos, utilizamos a virtualização: pegamos um servidor e o dividimos em diversas máquinas virtuais, garantindo assim o isolamento do ambiente.
Sistemas de virtualização baseados em hipervisor
Todo mundo provavelmente já ouviu falar sobre sistemas de virtualização: VMware, VirtualBox, Hyper-V, Qemu KVM, etc. Eles fornecem isolamento de aplicativos e gerenciamento de recursos, mas também apresentam desvantagens. Para fazer virtualização, você precisa de um hipervisor. E o hipervisor é uma sobrecarga de recursos. E a própria máquina virtual geralmente é um colosso - uma imagem pesada contendo um sistema operacional, Nginx, Apache e possivelmente MySQL. A imagem é grande e a operação da máquina virtual é inconveniente. Como resultado, trabalhar com máquinas virtuais pode ser lento. Para resolver este problema, foram criados sistemas de virtualização no nível do kernel.
Sistemas de virtualização em nível de kernel
A virtualização em nível de kernel é suportada por OpenVZ, Systemd-nspawn e LXC. Um excelente exemplo desse tipo de virtualização é o LXC (Linux Contêineres).
LXC é um sistema de virtualização em nível de sistema operacional para executar múltiplas instâncias isoladas de sistemas operacionais. Linux em um único nó. O LXC não usa máquinas virtuais, mas cria um ambiente virtual com seu próprio espaço de processo e pilha de rede.
Essencialmente, o LXC cria contêineres. Qual é a diferença entre máquinas virtuais e contêineres?
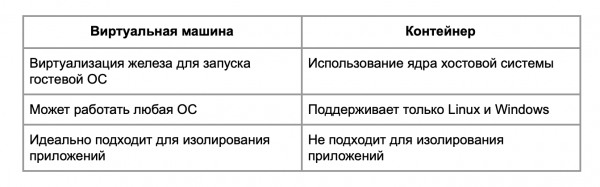
O contêiner não é adequado para isolar processos: vulnerabilidades são encontradas em sistemas de virtualização no nível do kernel que permitem que eles escapem do contêiner para o host. Portanto, se precisar isolar algo, é melhor usar uma máquina virtual.
As diferenças entre virtualização e conteinerização podem ser vistas no diagrama.
Existem hipervisores de hardware, hipervisores no sistema operacional e contêineres.
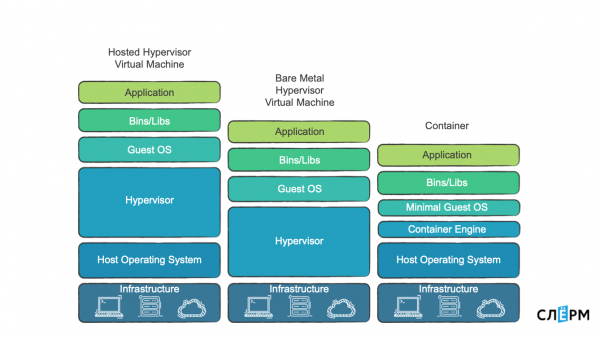
Hipervisores de hardware são legais se você realmente deseja isolar algo. Porque é possível isolar ao nível das páginas de memória e dos processadores.
Existem hipervisores como programa e existem contêineres, e falaremos sobre eles mais adiante. Os sistemas de conteinerização não possuem hipervisor, mas existe um Container Engine que cria e gerencia contêineres. Essa coisa é mais leve, portanto, devido ao trabalho com o núcleo, há menos sobrecarga ou nenhuma sobrecarga.
O que é usado para conteinerização no nível do kernel
As principais tecnologias que permitem criar um container isolado de outros processos são Namespaces e Grupos de Controle.
Namespaces: PID, Rede, Montagem e Usuário. Existem mais, mas para facilitar a compreensão vamos nos concentrar nestes.
O namespace PID limita os processos. Quando, por exemplo, criamos um Namespace PID e colocamos um processo nele, ele fica com PID 1. Geralmente em sistemas o PID 1 é systemd ou init. Assim, quando colocamos um processo em um novo namespace, ele também recebe o PID 1.
Networking Namespace permite limitar/isolar a rede e colocar suas próprias interfaces dentro dela. Mount é uma limitação do sistema de arquivos. Usuário — restrição aos usuários.
Grupos de controle: Memória, CPU, IOPS, Rede – cerca de 12 configurações no total. Caso contrário, eles também são chamados de Cgroups (“grupos C”).
Grupos de controle gerenciam recursos para um contêiner. Através dos Grupos de Controle podemos afirmar que o container não deve consumir mais do que uma determinada quantidade de recursos.
Para que a conteinerização funcione plenamente, são utilizadas tecnologias adicionais: Capabilities, Copy-on-write e outras.
Capacidades são quando dizemos a um processo o que ele pode ou não fazer. No nível do kernel, estes são simplesmente bitmaps com muitos parâmetros. Por exemplo, o usuário root tem privilégios totais e pode fazer tudo. O servidor de horário pode alterar a hora do sistema: ele possui recursos no Time Capsule e é isso. Usando privilégios, você pode configurar restrições de processos de maneira flexível e, assim, proteger-se.
O sistema Copy-on-write nos permite trabalhar com imagens Docker e utilizá-las de forma mais eficiente.
Atualmente, o Docker tem problemas de compatibilidade com o Cgroups v2, portanto, este artigo se concentra especificamente no Cgroups v1.
Mas voltemos à história.
Quando os sistemas de virtualização apareceram no nível do kernel, eles começaram a ser usados ativamente. A sobrecarga no hipervisor desapareceu, mas alguns problemas permaneceram:
- imagens grandes: eles colocam um sistema operacional, bibliotecas, vários softwares diferentes no mesmo OpenVZ e, no final, a imagem ainda fica bem grande;
- Não existe um padrão normal de embalagem e entrega, então o problema das dependências permanece. Existem situações em que dois trechos de código utilizam a mesma biblioteca, mas com versões diferentes. Pode haver um conflito entre eles.
Para resolver todos estes problemas, chegou a próxima era.
Era dos contêineres
Quando chegou a Era dos Containers, a filosofia de trabalhar com eles mudou:
- Um processo – um contêiner.
- Entregamos todas as dependências que o processo precisa em seu contêiner. Isso requer transformar monólitos em microsserviços.
- Quanto menor a imagem, melhor - há menos vulnerabilidades possíveis, ela é implementada mais rapidamente e assim por diante.
- As instâncias tornam-se efêmeras.
Lembra do que eu disse sobre animais de estimação versus gado? Anteriormente, as instâncias eram como animais domésticos, mas agora tornaram-se como gado. Anteriormente, havia um monólito - um aplicativo. Agora são 100 microsserviços, 100 contêineres. Alguns contêineres podem ter de 2 a 3 réplicas. Torna-se menos importante para nós controlar todos os contêineres. O que é mais importante para nós é a disponibilidade do próprio serviço: o que este conjunto de contentores faz. Isso muda as abordagens de monitoramento.
Em 2014-2015, o Docker floresceu - a tecnologia da qual falaremos agora.
Docker mudou a filosofia e padronizou o pacote de aplicativos. Usando o Docker, podemos empacotar um aplicativo, enviá-lo para um repositório, baixá-lo de lá e implantá-lo.
Colocamos tudo o que precisamos no contêiner Docker, para que o problema de dependência seja resolvido. Docker garante reprodutibilidade. Acho que muitas pessoas encontraram a irreprodutibilidade: tudo funciona para você, você coloca em produção e aí ele para de funcionar. Com o Docker esse problema desaparece. Se o seu contêiner Docker iniciar e fizer o que precisa, então com um alto grau de probabilidade ele iniciará a produção e fará o mesmo lá.
Digressão sobre despesas gerais
Existe um debate constante sobre sobrecarga. Alguns argumentam que o Docker não incorre em nenhuma sobrecarga adicional porque utiliza o kernel. Linux e todos os seus processos necessários para a conteinerização. Tipo, "Se você diz que o Docker é um recurso adicional, então o kernel também é." Linux "acima da cabeça".
Por outro lado, se você for mais fundo, há de fato várias coisas no Docker que, com certa extensão, podem ser consideradas sobrecargas.
O primeiro é o namespace PID. Quando colocamos um processo em um namespace, ele recebe o PID 1. Ao mesmo tempo, esse processo possui outro PID, que está localizado no namespace do host, fora do contêiner. Por exemplo, lançamos o Nginx em um contêiner, ele se tornou PID 1 (processo mestre). E no host tem PID 12623. E é difícil dizer quanto de sobrecarga isso representa.
A segunda coisa são os Cgroups. Vamos considerar os Cgroups por memória, ou seja, a capacidade de limitar a memória de um contêiner. Quando habilitado, os contadores e a contabilização da memória são ativados: o kernel precisa entender quantas páginas foram alocadas e quantas ainda estão livres para este container. Isto é possivelmente uma sobrecarga, mas não vi nenhum estudo preciso sobre como isso afeta o desempenho. E eu mesmo não percebi que o aplicativo em execução no Docker sofreu repentinamente uma perda acentuada de desempenho.
E mais uma observação sobre desempenho. Alguns parâmetros do kernel são passados do host para o contêiner. Em particular, alguns parâmetros de rede. Portanto, se você deseja executar algo de alto desempenho no Docker, por exemplo, algo que usará ativamente a rede, você precisará pelo menos ajustar esses parâmetros. Alguns nf_conntrack, por exemplo.
Sobre o conceito Docker
Docker consiste em vários componentes:
- Docker Daemon é o mesmo Container Engine; lança contêineres.
- Docker CII é um utilitário de gerenciamento Docker.
- Dockerfile – instruções sobre como construir uma imagem.
- Imagem — a imagem a partir da qual o contêiner é implementado.
- Recipiente.
- O registro Docker é um repositório de imagens.
Esquematicamente é algo assim:
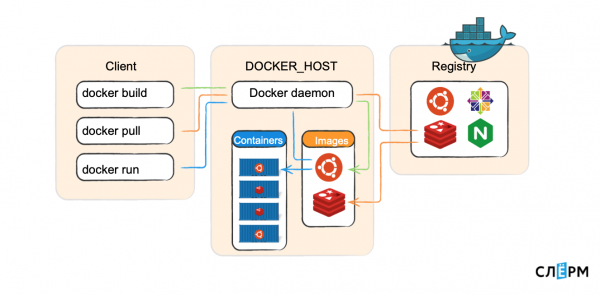
O daemon Docker é executado em Docker_host e inicia contêineres. Existe um Cliente que envia comandos: construir a imagem, baixar a imagem, lançar o container. O daemon Docker vai para o registro e os executa. O cliente Docker pode acessar localmente (para um soquete Unix) e via TCP de um host remoto.
Vamos examinar cada componente.
Daemon Docker - esta é a parte do servidor, funciona na máquina host: baixa imagens e lança containers a partir delas, cria uma rede entre containers, coleta logs. Quando dizemos “crie uma imagem”, o demônio também está fazendo isso.
CLI do Docker — Parte do cliente Docker, utilitário de console para trabalhar com o daemon. Repito, pode funcionar não apenas localmente, mas também na rede.
Comandos básicos:
docker ps – mostra contêineres que estão atualmente em execução no host Docker.
imagens docker - mostra imagens baixadas localmente.
docker search <> - procura uma imagem no registro.
docker pull <> - baixa uma imagem do registro para a máquina.
compilação do docker < > - colete a imagem.
docker run <> - inicia o contêiner.
docker rm <> - remova o contêiner.
logs do docker <> - logs do contêiner
docker start/stop/restart <> - trabalhando com o contêiner
Se você domina esses comandos e tem confiança em usá-los, considere-se 70% proficiente em Docker no nível do usuário.
dockerfile - instruções para criar uma imagem. Quase todo comando de instrução é uma nova camada. Vejamos um exemplo.
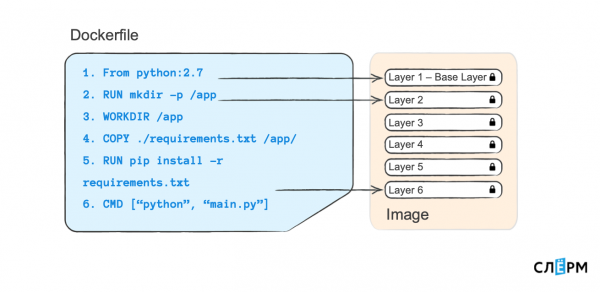
Esta é a aparência do Dockerfile: comandos à esquerda, argumentos à direita. Cada comando que está aqui (e geralmente escrito no Dockerfile) cria uma nova camada na imagem.
Mesmo olhando para o lado esquerdo, você pode entender aproximadamente o que está acontecendo. Dizemos: “crie uma pasta para nós” - esta é uma camada. “Fazer a pasta funcionar” é outra camada e assim por diante. O bolo em camadas facilita a vida. Se eu criar outro Dockerfile e alterar algo na última linha - eu executo algo diferente de “python” “main.py” ou instalo dependências de outro arquivo - então as camadas anteriores serão reutilizadas como cache.
Imagem - esta é uma embalagem de contêiner; os contêineres são lançados a partir da imagem. Se olharmos para o Docker do ponto de vista de um gerenciador de pacotes (como se estivéssemos trabalhando com pacotes deb ou rpm), então image é essencialmente um pacote rpm. Através do yum install podemos instalar o aplicativo, excluí-lo, localizá-lo no repositório e baixá-lo. É quase a mesma coisa aqui: os contêineres são iniciados a partir da imagem, são armazenados no registro do Docker (semelhante ao yum, em um repositório) e cada imagem possui um hash SHA-256, um nome e uma tag.
A imagem é construída de acordo com as instruções do Dockerfile. Cada instrução do Dockerfile cria uma nova camada. As camadas podem ser reutilizadas.
Registro do Docker é um repositório de imagens Docker. Semelhante ao sistema operacional, o Docker possui um registro de padrão público - dockerhub. Mas você pode construir seu próprio repositório, seu próprio registro Docker.
Recipiente - o que é lançado a partir da imagem. Construímos uma imagem de acordo com as instruções do Dockerfile e depois a iniciamos a partir desta imagem. Este contêiner é isolado dos demais contêineres e deve conter tudo o que é necessário para o funcionamento da aplicação. Neste caso, um contêiner – um processo. Acontece que você tem que fazer dois processos, mas isso é um tanto contrário à ideologia do Docker.
O requisito “um contêiner, um processo” está relacionado ao Namespace PID. Quando um processo com PID 1 inicia no Namespace, se ele morrer repentinamente, todo o contêiner morrerá também. Se dois processos estiverem em execução lá: um está ativo e o outro está morto, o contêiner ainda continuará ativo. Mas isso é uma questão de Melhores Práticas, falaremos delas em outros materiais.
Para estudar mais detalhadamente as funcionalidades e a programação completa do curso, siga o link: “".
Autor: Marcel Ibraev, administrador certificado do Kubernetes, engenheiro praticante em Southbridge, palestrante e desenvolvedor de cursos Slurm.
Fonte: habr.com
