

Observação. trad.: Esta história reveladora do Omio – um agregador de viagens europeu – leva os leitores da teoria básica às fascinantes complexidades práticas da configuração do Kubernetes. A familiaridade com esses casos ajuda não apenas a ampliar seus horizontes, mas também a prevenir problemas não triviais.
Você já teve um aplicativo travado, parou de responder às verificações de integridade e não conseguiu descobrir o porquê? Uma possível explicação está relacionada aos limites de cota de recursos da CPU. É sobre isso que falaremos neste artigo.
TL; DR:
Recomendamos fortemente desativar os limites de CPU no Kubernetes (ou desativar as quotas do CFS no Kubelet) se você estiver usando uma versão do kernel. Linux com um erro de quota CFS. No kernel sério e um bug que leva a afogamentos e atrasos excessivos.
Em Ómio toda a infraestrutura é gerenciada pelo Kubernetes. Todas as nossas cargas de trabalho com e sem estado são executadas exclusivamente no Kubernetes (usamos o Google Kubernetes Engine). Nos últimos seis meses, começamos a observar desacelerações aleatórias. Os aplicativos congelam ou param de responder às verificações de integridade, perdem a conexão com a rede, etc. Esse comportamento nos intrigou por muito tempo e finalmente decidimos levar o problema a sério.
Resumo do artigo:
- Algumas palavras sobre containers e Kubernetes;
- Como as solicitações e limites de CPU são implementados;
- Como funciona o limite de CPU em ambientes multi-core;
- Como rastrear a aceleração da CPU;
- Solução de problemas e nuances.
Algumas palavras sobre contêineres e Kubernetes
Kubernetes é essencialmente o padrão moderno no mundo da infraestrutura. Sua principal tarefa é a orquestração de contêineres.
Containers
No passado, tínhamos que criar artefatos como Java JARs/WARs, Python Eggs ou executáveis para rodar em servidores. Porém, para fazê-los funcionar, foi necessário realizar um trabalho adicional: instalar o ambiente de execução (Java/Python), colocar os arquivos necessários nos lugares certos, garantir a compatibilidade com uma versão específica do sistema operacional, etc. Em outras palavras, era preciso prestar muita atenção ao gerenciamento de configuração (que era frequentemente uma fonte de discórdia entre desenvolvedores e administradores de sistema).
Os contêineres mudaram tudo. Agora o artefato é uma imagem de contêiner. Ele pode ser representado como uma espécie de arquivo executável estendido contendo não apenas o programa, mas também um ambiente de execução completo (Java/Python/...), bem como os arquivos/pacotes necessários, pré-instalados e prontos para uso. correr. Os contêineres podem ser implantados e executados em servidores diferentes sem nenhuma etapa adicional.
Além disso, os contêineres são executados em seu próprio ambiente isolado (sandbox). Eles possuem seu próprio adaptador de rede virtual, seu próprio sistema de arquivos com acesso restrito, sua própria hierarquia de processos, seus próprios limites de CPU e memória, e assim por diante. Tudo isso é implementado graças a um subsistema especial do kernel. Linux — espaços de nomes.
Kubernetes
Conforme afirmado anteriormente, o Kubernetes é um orquestrador de contêineres. Funciona assim: você fornece um pool de máquinas e depois diz: “Ei, Kubernetes, vamos lançar dez instâncias do meu contêiner com 2 processadores e 3 GB de memória cada, e mantê-las funcionando!” O Kubernetes cuidará do resto. Ele encontrará capacidade livre, iniciará contêineres e os reiniciará se necessário, lançará uma atualização ao alterar versões, etc. Essencialmente, o Kubernetes permite abstrair o componente de hardware e tornar uma ampla variedade de sistemas adequados para implantação e execução de aplicativos.
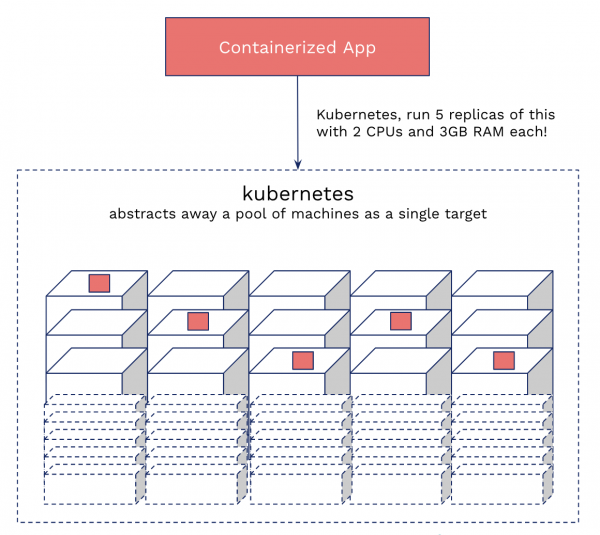
Kubernetes do ponto de vista do leigo
O que são solicitações e limites no Kubernetes
Ok, cobrimos contêineres e Kubernetes. Também sabemos que vários contêineres podem residir na mesma máquina.
Uma analogia pode ser feita com um apartamento comunitário. Um espaço espaçoso (máquinas/unidades) é alugado e alugado a vários inquilinos (contentores). Kubernetes atua como corretor de imóveis. Surge a questão: como evitar conflitos entre os inquilinos? E se um deles, digamos, decidir pedir emprestado o banheiro por metade do dia?
É aqui que entram em jogo as solicitações e os limites. CPU SOLICITAÇÃO necessário apenas para fins de planejamento. Isso é algo como uma “lista de desejos” do contêiner e é usado para selecionar o nó mais adequado. Ao mesmo tempo, a CPU Limitar pode ser comparado a um contrato de locação - assim que selecionamos uma unidade para o contêiner, o não será capaz ir além dos limites estabelecidos. E é aí que surge o problema...
Como as solicitações e limites são implementados no Kubernetes
O Kubernetes usa um mecanismo de otimização (ignorando ciclos de clock) integrado ao kernel para implementar limites de CPU. Se um aplicativo exceder o limite, a aceleração será habilitada (ou seja, ele receberá menos ciclos de CPU). As solicitações e limites de memória são organizados de maneira diferente, por isso são mais fáceis de detectar. Para isso, basta verificar o status da última reinicialização do pod: se ele é “OOMKilled”. A otimização da CPU não é tão simples, já que o K8s só disponibiliza métricas por uso, não por cgroups.
Solicitação de CPU
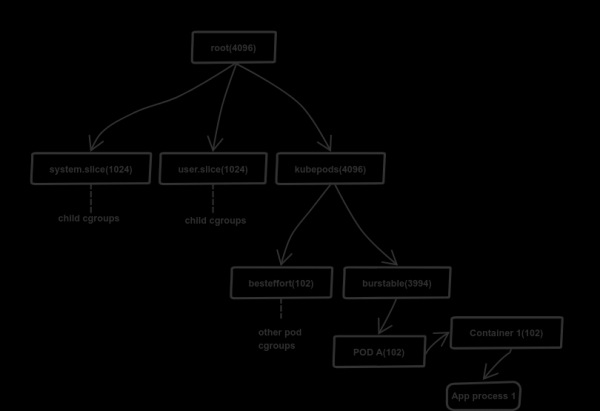
Como a solicitação de CPU é implementada
Para simplificar, vejamos o processo usando uma máquina com CPU de 4 núcleos como exemplo.
K8s usa um mecanismo de grupo de controle (cgroups) para controlar a alocação de recursos (memória e processador). Um modelo hierárquico está disponível para isso: o filho herda os limites do grupo pai. Os detalhes da distribuição são armazenados em um sistema de arquivos virtual (/sys/fs/cgroup). No caso de um processador isso é /sys/fs/cgroup/cpu,cpuacct/*.
K8s usa arquivo cpu.share para alocar recursos do processador. No nosso caso, o cgroup raiz obtém 4096 compartilhamentos de recursos da CPU - 100% da potência disponível do processador (1 núcleo = 1024; este é um valor fixo). O grupo raiz distribui recursos proporcionalmente dependendo das parcelas de descendentes registrados em cpu.share, e eles, por sua vez, fazem o mesmo com seus descendentes, etc. Em um nó típico do Kubernetes, o cgroup raiz tem três filhos: system.slice, user.slice и kubepods. Os dois primeiros subgrupos são usados para distribuir recursos entre cargas críticas do sistema e programas de usuário fora do K8s. Último - kubepods — criado pelo Kubernetes para distribuir recursos entre pods.
O diagrama acima mostra que o primeiro e o segundo subgrupos receberam cada 1024 compartilhamentos, com o subgrupo kuberpod alocado 4096 ações Como isso é possível: afinal, o grupo raiz tem acesso apenas 4096 ações, e a soma das ações de seus descendentes excede significativamente esse número (6144A questão é que o valor tem um significado lógico, então o planejador Linux O CFS usa isso para distribuir os recursos da CPU proporcionalmente. No nosso caso, os dois primeiros grupos recebem 680 ações reais (16,6% de 4096), e kubepod recebe o restante 2736 ações Em caso de indisponibilidade, os dois primeiros grupos não utilizarão os recursos alocados.
Felizmente, o agendador possui um mecanismo para evitar o desperdício de recursos de CPU não utilizados. Transfere capacidade “ociosa” para um pool global, de onde é distribuída para grupos que necessitam de potência adicional de processador (a transferência ocorre em lotes para evitar arredondamentos de perdas). Um método semelhante é aplicado a todos os descendentes de descendentes.
Este mecanismo garante uma distribuição justa do poder do processador e garante que nenhum processo “roube” recursos de outros.
Limite de CPU
Apesar de as configurações de limites e solicitações nos K8s parecerem semelhantes, sua implementação é radicalmente diferente: esta mais enganoso e a parte menos documentada.
K8s se envolve para implementar limites. Suas configurações são especificadas em arquivos cfs_period_us и cfs_quota_us no diretório cgroup (o arquivo também está localizado lá cpu.share).
Ao contrário cpu.share, a cota é baseada em período de tempoe não na potência disponível do processador. cfs_period_us especifica a duração do período (época) - é sempre 100000 μs (100 ms). Existe a opção de alterar esse valor no K8s, mas por enquanto só está disponível em alfa. O agendador usa a época para reiniciar as cotas usadas. Segundo arquivo cfs_quota_us, especifica o tempo disponível (cota) em cada época. Observe que também é especificado em microssegundos. A cota pode exceder a duração da época; em outras palavras, pode ser superior a 100 ms.
Vejamos dois cenários em máquinas de 16 núcleos (o tipo de computador mais comum que temos na Omio):

Cenário 1: 2 threads e limite de 200 ms. Sem limitação
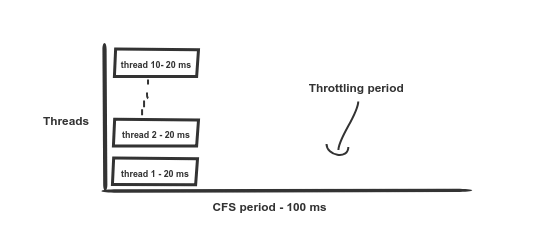
Cenário 2: 10 threads e limite de 200 ms. A aceleração começa após 20 ms, o acesso aos recursos do processador é retomado após outros 80 ms
Digamos que você defina o limite da CPU para 2 grãos; O Kubernetes traduzirá esse valor para 200 ms. Isso significa que o contêiner pode usar no máximo 200 ms de tempo de CPU sem limitação.
E é aqui que a diversão começa. Conforme mencionado acima, a cota disponível é de 200 ms. Se você estiver trabalhando em paralelo dez threads em uma máquina de 12 núcleos (veja a ilustração do cenário 2), enquanto todos os outros pods estiverem ociosos, a cota será esgotada em apenas 20 ms (já que 10 * 20 ms = 200 ms) e todos os threads deste pod serão interrompidos » (acelerador) pelos próximos 80 ms. O já mencionado , devido ao qual ocorre um estrangulamento excessivo e o contêiner nem consegue cumprir a cota existente.
Como avaliar a limitação em pods?
Basta fazer login no pod e executar cat /sys/fs/cgroup/cpu/cpu.stat.
-
nr_periods— o número total de períodos do programador; -
nr_throttled— número de períodos limitados na composiçãonr_periods; -
throttled_time— tempo estrangulado cumulativo em nanossegundos.
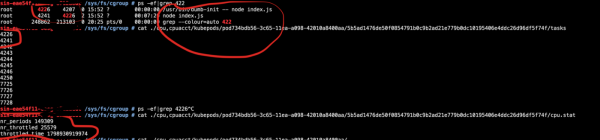
O que realmente está acontecendo?
Como resultado, obtemos uma alta aceleração em todas as aplicações. Às vezes ele está dentro uma vez e meia mais forte do que calculado!
Isso leva a vários erros – falhas na verificação de prontidão, congelamentos de contêineres, quebras de conexão de rede, tempos limite nas chamadas de serviço. Em última análise, isso resulta em maior latência e taxas de erro mais altas.
Decisão e consequências
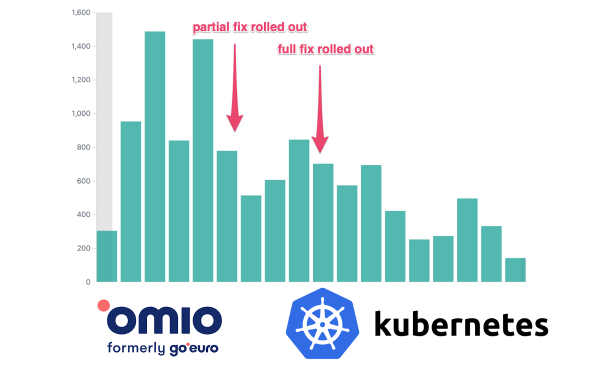
Tudo é simples aqui. Abandonamos os limites de CPU e começamos a atualizar o kernel do SO em clusters para a versão mais recente, na qual o bug foi corrigido. O número de erros (HTTP 5xx) em nossos serviços caiu imediatamente de forma significativa:
Erros HTTP 5xx
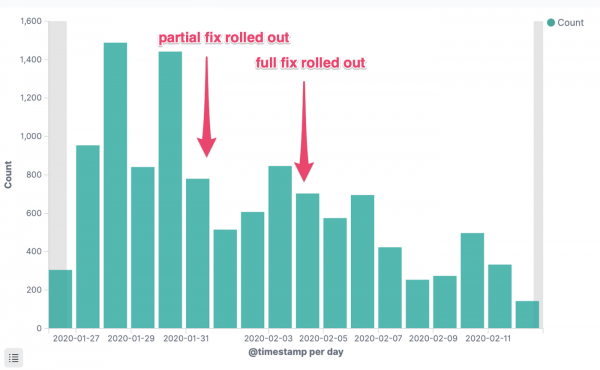
Erros HTTP 5xx para um serviço crítico
Tempo de resposta p95
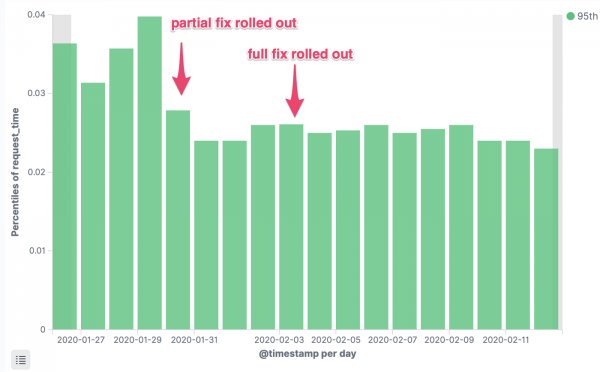
Latência de solicitação de serviço crítica, percentil 95
Custos operacionais
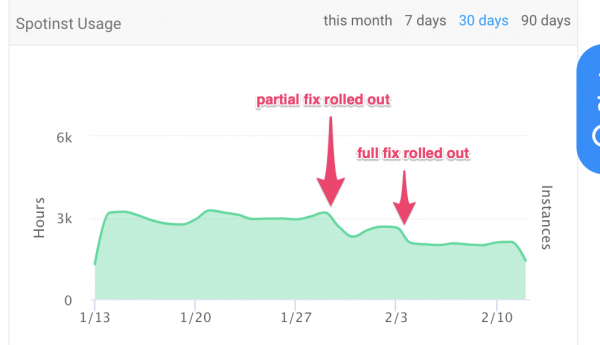
Número de horas de instância gastas
Qual é o truque?
Conforme afirmado no início do artigo:
Uma analogia pode ser feita com um apartamento comunitário... Kubernetes atua como corretor de imóveis. Mas como evitar conflitos entre os inquilinos? E se um deles, digamos, decidir pedir emprestado o banheiro por metade do dia?
Aqui está o problema. Um contêiner descuidado pode consumir todos os recursos de CPU disponíveis em uma máquina. Se você tiver uma pilha de aplicativos inteligente (por exemplo, JVM, Go, Node VM estão configurados corretamente), isso não será um problema: você poderá trabalhar nessas condições por muito tempo. Mas se os aplicativos estiverem mal otimizados ou nem um pouco otimizados (FROM java:latest), a situação pode ficar fora de controle. Na Omio, automatizamos Dockerfiles básicos com configurações padrão adequadas para a pilha de idiomas principal, portanto, esse problema não existia.
Recomendamos monitorar as métricas (uso, saturação e erros), atrasos de API e taxas de erro. Garantir que os resultados atendam às expectativas.
referências
Esta é a nossa história. Os seguintes materiais ajudaram muito a entender o que estava acontecendo:
- ;
- ;
- ;
- ;
- - procure por “aceleração da CPU”.
Relatórios de bugs do Kubernetes:
- ;
- ;
- .
Você encontrou problemas semelhantes em sua prática ou tem experiência relacionada à limitação em ambientes de produção em contêineres? Compartilhe sua história nos comentários!
PS do tradutor
Leia também em nosso blog:
- «";
- «";
- «".
Fonte: habr.com
