


Sobre quais princípios é construído um Data Warehouse ideal?
Concentre-se no valor comercial e na análise, na ausência de código padronizado. Gerenciando DWH como base de código: versionamento, revisão, testes automatizados e CI. Modular, extensível, de código aberto e comunitário. Documentação amigável e visualização de dependências (Data Lineage).
Mais sobre tudo isso e sobre o papel do DBT no ecossistema Big Data & Analytics - bem-vindo ao cat.
Olá pessoal
Artemy Kozyr está em contato. Há mais de 5 anos trabalho com data warehouses, construção de ETL/ELT, bem como análise e visualização de dados. Atualmente estou trabalhando em , eu ensino na OTUS em um curso , e hoje quero compartilhar com vocês um artigo que escrevi antes do início nova inscrição no curso.
Visão geral
A estrutura DBT gira em torno do T na sigla ELT (Extract - Transform - Load).
Com o advento de bancos de dados analíticos produtivos e escalonáveis como BigQuery, Redshift, Snowflake, não fazia sentido fazer transformações fora do Data Warehouse.
O DBT não baixa dados de fontes, mas oferece ótimas oportunidades para trabalhar com dados que já foram carregados no armazenamento (em armazenamento interno ou externo).
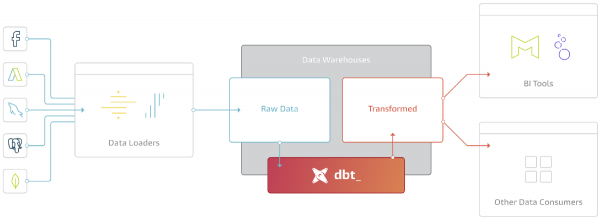
O objetivo principal do DBT é pegar o código, compilá-lo em SQL, executar os comandos na sequência correta no Repositório.
Estrutura do Projeto DBT
O projeto consiste em diretórios e arquivos de apenas 2 tipos:
- Modelo (.sql) - uma unidade de transformação expressa por uma consulta SELECT
- Arquivo de configuração (.yml) – parâmetros, configurações, testes, documentação
A nível básico, o trabalho está estruturado da seguinte forma:
- O usuário prepara o código do modelo em qualquer IDE conveniente
- Usando a CLI, os modelos são lançados, o DBT compila o código do modelo em SQL
- O código SQL compilado é executado no Storage em uma determinada sequência (gráfico)
Esta é a aparência da execução a partir da CLI:
Tudo é SELECIONADO
Este é um recurso matador da estrutura da Data Build Tool. Ou seja, o DBT abstrai todo o código associado à materialização de suas consultas na Store (variações dos comandos CREATE, INSERT, UPDATE, DELETE ALTER, GRANT, ...).
Qualquer modelo envolve escrever uma consulta SELECT que define o conjunto de dados resultante.
Neste caso, a lógica de transformação pode ser multinível e consolidar dados de diversos outros modelos. Um exemplo de modelo que irá construir uma vitrine de pedidos (f_orders):
{% set payment_methods = ['credit_card', 'coupon', 'bank_transfer', 'gift_card'] %}
with orders as (
select * from {{ ref('stg_orders') }}
),
order_payments as (
select * from {{ ref('order_payments') }}
),
final as (
select
orders.order_id,
orders.customer_id,
orders.order_date,
orders.status,
{% for payment_method in payment_methods -%}
order_payments.{{payment_method}}_amount,
{% endfor -%}
order_payments.total_amount as amount
from orders
left join order_payments using (order_id)
)
select * from final
Que coisas interessantes podemos ver aqui?
Primeiro: usei CTE (Common Table Expressions) - para organizar e entender o código que contém muitas transformações e lógica de negócios
Segundo: o código do modelo é uma mistura de SQL e linguagem (linguagem de modelo).
O exemplo usa um loop pela para gerar o valor para cada forma de pagamento especificada na expressão conjunto. A função também é usada ref — a capacidade de fazer referência a outros modelos dentro do código:
- Durante a compilação ref será convertido em um ponteiro de destino para uma tabela ou visualização no armazenamento
- ref permite que você construa um gráfico de dependência do modelo
Exatamente adiciona possibilidades quase ilimitadas ao DBT. Os mais comumente usados são:
- Instruções if/else - instruções de ramificação
- Para loops - ciclos
- Variáveis
- Macro - criando macros
Materialização: Tabela, Visualização, Incremental
A estratégia de materialização é uma abordagem segundo a qual o conjunto resultante de dados do modelo será armazenado no Storage.
Em termos básicos é:
- Tabela – tabela física no Storage
- Ver - visualizar, tabela virtual no armazenamento
Existem também estratégias de materialização mais complexas:
- Incremental - carregamento incremental (de grandes tabelas de fatos); novas linhas são adicionadas, as linhas alteradas são atualizadas, as linhas excluídas são apagadas
- Efêmero – o modelo não se materializa diretamente, mas participa como CTE em outros modelos
- Quaisquer outras estratégias que você mesmo possa adicionar
Além das estratégias de materialização, existem oportunidades de otimização para Storages específicos, por exemplo:
- Floco de neve: Tabelas transitórias, Comportamento de mesclagem, Cluster de tabelas, Cópia de concessões, Visualizações seguras
- Redshift: Distkey, Sortkey (intercalado, composto), visualizações de ligação tardia
- BigQuery: particionamento e clustering de tabelas, comportamento de mesclagem, criptografia KMS, rótulos e tags
- Faísca: Formato de arquivo (parquet, csv, json, orc, delta), partição_by, clustered_by, buckets, incremental_strategy
Os seguintes armazenamentos são atualmente suportados:
- postgres
- Redshift
- BigQuery
- Floco de neve
- Presto (parcialmente)
- Faísca (parcialmente)
- Microsoft SQL Server (adaptador comunitário)
Vamos melhorar nosso modelo:
- Vamos tornar seu preenchimento incremental (Incremental)
- Vamos adicionar chaves de segmentação e classificação para Redshift
-- Конфигурация модели:
-- Инкрементальное наполнение, уникальный ключ для обновления записей (unique_key)
-- Ключ сегментации (dist), ключ сортировки (sort)
{{
config(
materialized='incremental',
unique_key='order_id',
dist="customer_id",
sort="order_date"
)
}}
{% set payment_methods = ['credit_card', 'coupon', 'bank_transfer', 'gift_card'] %}
with orders as (
select * from {{ ref('stg_orders') }}
where 1=1
{% if is_incremental() -%}
-- Этот фильтр будет применен только для инкрементального запуска
and order_date >= (select max(order_date) from {{ this }})
{%- endif %}
),
order_payments as (
select * from {{ ref('order_payments') }}
),
final as (
select
orders.order_id,
orders.customer_id,
orders.order_date,
orders.status,
{% for payment_method in payment_methods -%}
order_payments.{{payment_method}}_amount,
{% endfor -%}
order_payments.total_amount as amount
from orders
left join order_payments using (order_id)
)
select * from final
Gráfico de dependência do modelo
Também é uma árvore de dependências. Também é conhecido como DAG (Gráfico Acíclico Direcionado).
O DBT constrói um gráfico baseado na configuração de todos os modelos de projeto, ou melhor, ref() vincula dentro dos modelos a outros modelos. Ter um gráfico permite que você faça o seguinte:
- Executando modelos na sequência correta
- Paralelização da formação da vitrine
- Executando um subgráfico arbitrário
Exemplo de visualização gráfica:
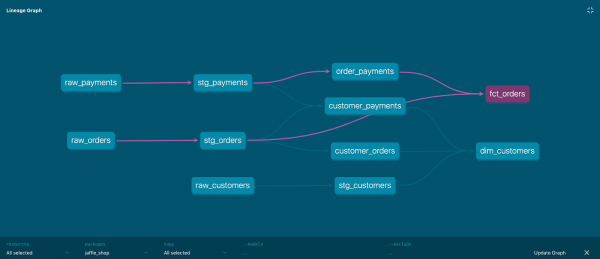
Cada nó do gráfico é um modelo; as arestas do gráfico são especificadas pela expressão ref.
Qualidade de dados e documentação
Além de gerar os próprios modelos, o DBT permite testar uma série de suposições sobre o conjunto de dados resultante, como:
- Não nulo
- Único
- Integridade de Referência - integridade referencial (por exemplo, customer_id na tabela de pedidos corresponde ao id na tabela de clientes)
- Correspondendo à lista de valores aceitáveis
É possível adicionar testes próprios (testes de dados personalizados), como, por exemplo, % de desvio da receita com indicadores de um dia, uma semana, um mês atrás. Qualquer suposição formulada como uma consulta SQL pode se tornar um teste.
Dessa forma, você pode detectar desvios e erros indesejados nos dados nas janelas do Warehouse.
Em termos de documentação, o DBT fornece mecanismos para adicionar, versionar e distribuir metadados e comentários no modelo e até mesmo nos níveis de atributo.
Esta é a aparência da adição de testes e documentação no nível do arquivo de configuração:
- name: fct_orders
description: This table has basic information about orders, as well as some derived facts based on payments
columns:
- name: order_id
tests:
- unique # проверка на уникальность значений
- not_null # проверка на наличие null
description: This is a unique identifier for an order
- name: customer_id
description: Foreign key to the customers table
tests:
- not_null
- relationships: # проверка ссылочной целостности
to: ref('dim_customers')
field: customer_id
- name: order_date
description: Date (UTC) that the order was placed
- name: status
description: '{{ doc("orders_status") }}'
tests:
- accepted_values: # проверка на допустимые значения
values: ['placed', 'shipped', 'completed', 'return_pending', 'returned']
E aqui está a aparência desta documentação no site gerado:
Macros e Módulos
O objetivo do DBT não é tanto se tornar um conjunto de scripts SQL, mas fornecer aos usuários um meio poderoso e rico em recursos para construir suas próprias transformações e distribuir esses módulos.
Macros são conjuntos de construções e expressões que podem ser chamadas como funções dentro de modelos. As macros permitem reutilizar SQL entre modelos e projetos de acordo com o princípio de engenharia DRY (Don't Repeat Yourself).
Exemplo macro:
{% macro rename_category(column_name) %}
case
when {{ column_name }} ilike '%osx%' then 'osx'
when {{ column_name }} ilike '%android%' then 'android'
when {{ column_name }} ilike '%ios%' then 'ios'
else 'other'
end as renamed_product
{% endmacro %}
E seu uso:
{% set column_name = 'product' %}
select
product,
{{ rename_category(column_name) }} -- вызов макроса
from my_table
O DBT vem com um gerenciador de pacotes que permite aos usuários publicar e reutilizar módulos e macros individuais.
Isso significa ser capaz de carregar e usar bibliotecas como:
- : trabalhando com Data/Hora, Chaves Substitutas, Testes de Esquema, Pivot/Unpivot e outros
- Modelos de vitrine prontos para serviços como и
- Bibliotecas para armazenamentos de dados específicos, por ex.
- — Módulo para registro da operação DBT
Uma lista completa de pacotes pode ser encontrada em .
Ainda mais recursos
Aqui descreverei alguns outros recursos e implementações interessantes que a equipe e eu usamos para construir um Data Warehouse em .
Separação de ambientes de tempo de execução DEV - TEST - PROD
Mesmo dentro do mesmo cluster DWH (dentro de esquemas diferentes). Por exemplo, usando a seguinte expressão:
with source as (
select * from {{ source('salesforce', 'users') }}
where 1=1
{%- if target.name in ['dev', 'test', 'ci'] -%}
where timestamp >= dateadd(day, -3, current_date)
{%- endif -%}
)
Este código diz literalmente: para ambientes desenvolvedor, teste, ci obtenha dados apenas dos últimos 3 dias e nada mais. Ou seja, rodar nesses ambientes será muito mais rápido e exigirá menos recursos. Ao executar no ambiente estímulo a condição do filtro será ignorada.
Materialização com codificação de coluna alternativa
Redshift é um DBMS colunar que permite definir algoritmos de compactação de dados para cada coluna individual. A seleção de algoritmos ideais pode reduzir o espaço em disco em 20-50%.
Macro executará o comando ANALYZE COMPRESSION, criará uma nova tabela com os algoritmos de codificação de coluna recomendados, chaves de segmentação especificadas (dist_key) e chaves de classificação (sort_key), transferirá os dados para ela e, se necessário, excluirá a cópia antiga.
Assinatura macro:
{{ compress_table(schema, table,
drop_backup=False,
comprows=none|Integer,
sort_style=none|compound|interleaved,
sort_keys=none|List<String>,
dist_style=none|all|even,
dist_key=none|String) }}
O modelo de registro é executado
Você pode anexar ganchos a cada execução do modelo, que será executada antes do lançamento ou imediatamente após a conclusão da criação do modelo:
pre-hook: "{{ logging.log_model_start_event() }}"
post-hook: "{{ logging.log_model_end_event() }}"
O módulo de registro permitirá registrar todos os metadados necessários em uma tabela separada, que poderá posteriormente ser usada para auditar e analisar gargalos.
Esta é a aparência do painel com base nos dados de registro no Looker:
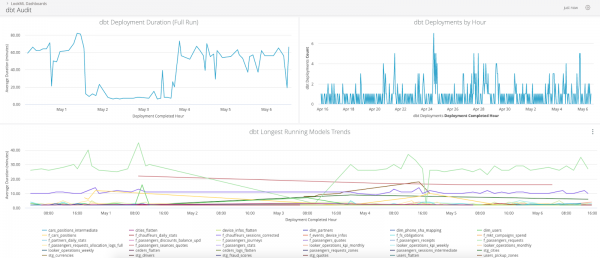
Automação da Manutenção de Armazenamento
Se você usar algumas extensões da funcionalidade do Repositório usado, como UDF (User Defined Functions), então o versionamento dessas funções, controle de acesso e lançamento automatizado de novos lançamentos é muito conveniente de fazer no DBT.
Usamos UDF em Python para calcular hashes, domínios de email e decodificação de máscara de bits.
Um exemplo de macro que cria uma UDF em qualquer ambiente de execução (dev, test, prod):
{% macro create_udf() -%}
{% set sql %}
CREATE OR REPLACE FUNCTION {{ target.schema }}.f_sha256(mes "varchar")
RETURNS varchar
LANGUAGE plpythonu
STABLE
AS $$
import hashlib
return hashlib.sha256(mes).hexdigest()
$$
;
{% endset %}
{% set table = run_query(sql) %}
{%- endmacro %}
Na Wheely usamos o Amazon Redshift, que é baseado em PostgreSQL. Para o Redshift, é importante coletar regularmente estatísticas nas tabelas e liberar espaço em disco - os comandos ANALYZE e VACUUM, respectivamente.
Para fazer isso, os comandos da macro redshift_maintenance são executados todas as noites:
{% macro redshift_maintenance() %}
{% set vacuumable_tables=run_query(vacuumable_tables_sql) %}
{% for row in vacuumable_tables %}
{% set message_prefix=loop.index ~ " of " ~ loop.length %}
{%- set relation_to_vacuum = adapter.get_relation(
database=row['table_database'],
schema=row['table_schema'],
identifier=row['table_name']
) -%}
{% do run_query("commit") %}
{% if relation_to_vacuum %}
{% set start=modules.datetime.datetime.now() %}
{{ dbt_utils.log_info(message_prefix ~ " Vacuuming " ~ relation_to_vacuum) }}
{% do run_query("VACUUM " ~ relation_to_vacuum ~ " BOOST") %}
{{ dbt_utils.log_info(message_prefix ~ " Analyzing " ~ relation_to_vacuum) }}
{% do run_query("ANALYZE " ~ relation_to_vacuum) %}
{% set end=modules.datetime.datetime.now() %}
{% set total_seconds = (end - start).total_seconds() | round(2) %}
{{ dbt_utils.log_info(message_prefix ~ " Finished " ~ relation_to_vacuum ~ " in " ~ total_seconds ~ "s") }}
{% else %}
{{ dbt_utils.log_info(message_prefix ~ ' Skipping relation "' ~ row.values() | join ('"."') ~ '" as it does not exist') }}
{% endif %}
{% endfor %}
{% endmacro %}
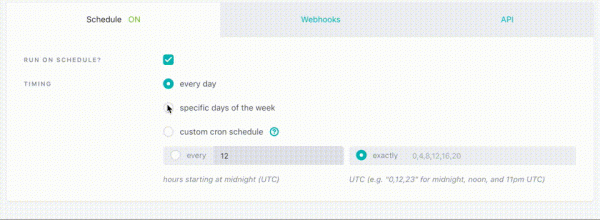
Nuvem DBT
É possível utilizar o DBT como serviço (Managed Service). Incluído:
- IDE Web para desenvolvimento de projetos e modelos
- Configuração e agendamento de trabalho
- Acesso simples e conveniente aos logs
- Site com documentação do seu projeto
- Conectando CI (integração contínua)
Conclusão
Preparar e consumir DWH torna-se tão agradável e benéfico quanto beber um smoothie. DBT consiste em Jinja, extensões de usuário (módulos), um compilador, um executor e um gerenciador de pacotes. Ao reunir esses elementos você obtém um ambiente de trabalho completo para seu Data Warehouse. Não existe hoje uma maneira melhor de gerir a transformação dentro da DWH.

As crenças seguidas pelos desenvolvedores do DBT são formuladas da seguinte forma:
- Código, não GUI, é a melhor abstração para expressar lógica analítica complexa
- Trabalhar com dados deve adaptar as melhores práticas em engenharia de software (Engenharia de Software)
- A infraestrutura de dados críticos deve ser controlada pela comunidade de usuários como software de código aberto
- Não apenas as ferramentas analíticas, mas também o código se tornarão cada vez mais propriedade da comunidade Open Source
Essas crenças fundamentais geraram um produto que é usado hoje por mais de 850 empresas e formam a base de muitas extensões interessantes que serão criadas no futuro.
Para os interessados, há um vídeo de uma aula aberta que dei há alguns meses como parte de uma aula aberta na OTUS - .
Além de DBT e Data Warehousing, como parte do curso Data Engineer na plataforma OTUS, meus colegas e eu ministramos aulas sobre uma série de outros temas relevantes e modernos:
- Conceitos de arquitetura para aplicações de Big Data
- Pratique com Spark e Spark Streaming
- Explorando métodos e ferramentas para carregar fontes de dados
- Construindo vitrines analíticas em DWH
- Conceitos NoSQL: HBase, Cassandra, ElasticSearch
- Princípios de monitoramento e orquestração
- Projeto Final: reunir todas as competências sob apoio de mentoria
Links:
- — Documentação oficial
- — Artigo de revisão de um dos autores do DBT
- — YouTube, Gravação de uma aula aberta OTUS
- — A próxima aula aberta é 15 de maio de 2020
- —OTUS
- — Uma olhada no futuro dos dados e análises
- — A evolução da análise e a influência do código aberto
- — Princípios de construção de IC usando DBT
- — Prática, instruções passo a passo para trabalho independente
- — Github, código do projeto educacional
Fonte: habr.com
