

Sugiro que você leia a transcrição da palestra "Hadoop. ZooKeeper" da série "Métodos para processamento distribuído de grandes volumes de dados no Hadoop"
O que é ZooKeeper, seu lugar no ecossistema Hadoop. Inverdades sobre computação distribuída. Diagrama de um sistema distribuído padrão. Dificuldade em coordenar sistemas distribuídos. Problemas típicos de coordenação. Os princípios por trás do design do ZooKeeper. Modelo de dados ZooKeeper. sinalizadores znode. Sessões. API do cliente. Primitivos (configuração, participação em grupo, bloqueios simples, eleição de líder, bloqueio sem efeito manada). Arquitetura do ZooKeeper. Banco de dados ZooKeeper. ZAB. Manipulador de solicitações.


Hoje falaremos sobre ZooKeeper. Essa coisa é muito útil. Ele, como qualquer produto Apache Hadoop, possui um logotipo. Representa um homem.
Antes disso, falamos principalmente sobre como os dados podem ser processados ali, como armazená-los, ou seja, como usá-los de alguma forma e trabalhar com eles de alguma forma. E hoje gostaria de falar um pouco sobre construção de aplicações distribuídas. E o ZooKeeper é uma daquelas coisas que permite simplificar esse assunto. Este é um tipo de serviço que se destina a algum tipo de coordenação da interação de processos em sistemas distribuídos, em aplicações distribuídas.
A necessidade de tais aplicações é cada vez maior a cada dia, é disso que trata o nosso curso. Por um lado, o MapReduce e este framework pronto permitem nivelar essa complexidade e liberar o programador de escrever primitivas como interação e coordenação de processos. Mas, por outro lado, ninguém garante que isso não terá que ser feito de qualquer maneira. MapReduce ou outras estruturas prontas nem sempre substituem completamente alguns casos que não podem ser implementados com isso. Incluindo o próprio MapReduce e vários outros projetos Apache; eles, na verdade, também são aplicativos distribuídos. E para facilitar a escrita, eles escreveram o ZooKeeper.
Como todos os aplicativos relacionados ao Hadoop, foi desenvolvido pelo Yahoo! Agora também é um aplicativo oficial do Apache. Não é desenvolvido tão ativamente quanto o HBase. Se você for ao JIRA HBase, todos os dias há um monte de relatórios de bugs, um monte de propostas para otimizar alguma coisa, ou seja, a vida no projeto está acontecendo constantemente. E o ZooKeeper, por um lado, é um produto relativamente simples e, por outro, garante sua confiabilidade. E é bastante fácil de usar, por isso se tornou um padrão em aplicações do ecossistema Hadoop. Então pensei que seria útil revisá-lo para entender como funciona e como usá-lo.
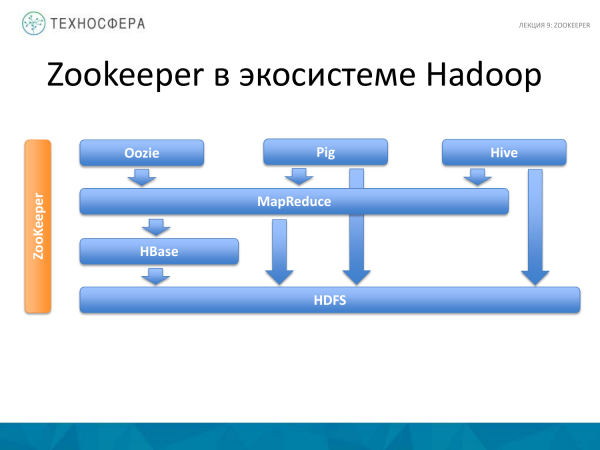
Esta é uma foto de uma palestra que tivemos. Podemos dizer que é ortogonal a tudo o que consideramos até agora. E tudo o que está indicado aqui, de uma forma ou de outra, funciona com o ZooKeeper, ou seja, é um serviço que utiliza todos esses produtos. Nem o HDFS nem o MapReduce escrevem seus próprios serviços semelhantes que funcionariam especificamente para eles. Conseqüentemente, o ZooKeeper é usado. E isso simplifica o desenvolvimento e algumas coisas relacionadas a erros.

De onde vem tudo isso? Parece que lançamos dois aplicativos em paralelo em computadores diferentes, conectamos-os com um barbante ou malha e tudo funciona. Mas o problema é que a rede não é confiável, e se você detectar o tráfego ou observar o que está acontecendo lá em um nível baixo, como os clientes interagem na rede, muitas vezes poderá ver que alguns pacotes são perdidos ou reenviados. Não foi à toa que foram inventados os protocolos TCP, que permitem estabelecer uma determinada sessão e garantir a entrega de mensagens. Mas, em qualquer caso, mesmo o TCP nem sempre pode salvá-lo. Tudo tem um tempo limite. A rede pode simplesmente cair por um tempo. Pode apenas piscar. E tudo isso leva ao fato de que você não pode confiar na confiabilidade da rede. Esta é a principal diferença de escrever aplicativos paralelos que rodam em um computador ou em um supercomputador, onde não há rede, onde há um barramento de troca de dados mais confiável na memória. E esta é uma diferença fundamental.
Entre outras coisas, ao utilizar a Rede, há sempre uma certa latência. O disco também tem, mas a Rede tem mais. Latência é algum tempo de atraso, que pode ser pequeno ou bastante significativo.
A topologia da rede está mudando. O que é topologia é a colocação de nossos equipamentos de rede. Existem data centers, existem racks, existem velas. Tudo isso pode ser reconectado, movido, etc. Tudo isso também precisa ser levado em consideração. Os nomes de IP mudam, o roteamento pelo qual nosso tráfego viaja muda. Isto também precisa ser levado em consideração.
A rede também pode sofrer alterações em termos de equipamentos. Pela prática, posso dizer que nossos engenheiros de rede gostam muito de atualizar periodicamente algo nas velas. De repente, um novo firmware foi lançado e eles não estavam particularmente interessados em algum cluster Hadoop. Eles têm seu próprio trabalho. Para eles, o principal é que a Rede funcione. Conseqüentemente, eles desejam recarregar algo lá, fazer um flash em seu hardware, e o hardware também muda periodicamente. Tudo isso precisa ser levado em consideração de alguma forma. Tudo isso afeta nosso aplicativo distribuído.
Normalmente as pessoas que começam a trabalhar com grandes quantidades de dados por algum motivo acreditam que a Internet é ilimitada. Se houver um arquivo de vários terabytes, você poderá levá-lo para o seu servidor ou computador e abri-lo usando gato e assistir. Outro erro está em Vim veja os registros. Nunca faça isso porque é ruim. Porque o Vim tenta armazenar tudo em buffer, carregar tudo na memória, principalmente quando começamos a percorrer esse log e procurar por algo. São coisas esquecidas, mas que valem a pena considerar.

É mais fácil escrever um programa que rode em um computador com um processador.
Quando nosso sistema crescer, queremos paralelizar tudo, e paralelizá-lo não apenas em um computador, mas também em um cluster. Surge a pergunta: como coordenar esse assunto? Nossas aplicações podem até não interagir entre si, mas rodamos vários processos em paralelo em vários servidores. E como monitorar se tudo está indo bem para eles? Por exemplo, eles enviam algo pela Internet. Eles devem escrever sobre seu estado em algum lugar, por exemplo, em algum tipo de banco de dados ou log, depois agregar esse log e analisá-lo em algum lugar. Além disso, precisamos levar em consideração que o processo estava funcionando e funcionando, de repente apareceu algum erro nele ou travou, então com que rapidez saberemos disso?
É claro que tudo isso pode ser monitorado rapidamente. Isso também é bom, mas o monitoramento é algo limitado que permite monitorar algumas coisas no mais alto nível.
Quando queremos que nossos processos comecem a interagir uns com os outros, por exemplo, para enviar alguns dados uns aos outros, surge também a pergunta - como isso acontecerá? Haverá algum tipo de condição de corrida, eles se substituirão, os dados chegarão corretamente, alguma coisa será perdida ao longo do caminho? Precisamos desenvolver algum tipo de protocolo, etc.
A coordenação de todos estes processos não é algo trivial. E força o desenvolvedor a descer para um nível ainda mais baixo e escrever sistemas do zero ou não do zero, mas isso não é tão simples.
Se você criar um algoritmo criptográfico ou mesmo implementá-lo, jogue-o fora imediatamente, porque provavelmente não funcionará para você. Provavelmente conterá vários erros que você esqueceu de corrigir. Nunca o use para nada sério porque provavelmente será instável. Porque todos os algoritmos que existem foram testados pelo tempo há muito tempo. Está bugado pela comunidade. Este é um tópico separado. E é a mesma coisa aqui. Se for possível não implementar algum tipo de sincronização de processos por conta própria, então é melhor não fazer isso, porque é bastante complicado e leva você pelo caminho instável da busca constante por erros.
Hoje estamos falando sobre ZooKeeper. Por um lado, é um framework, por outro, é um serviço que facilita a vida do desenvolvedor e simplifica ao máximo a implementação da lógica e coordenação dos nossos processos.
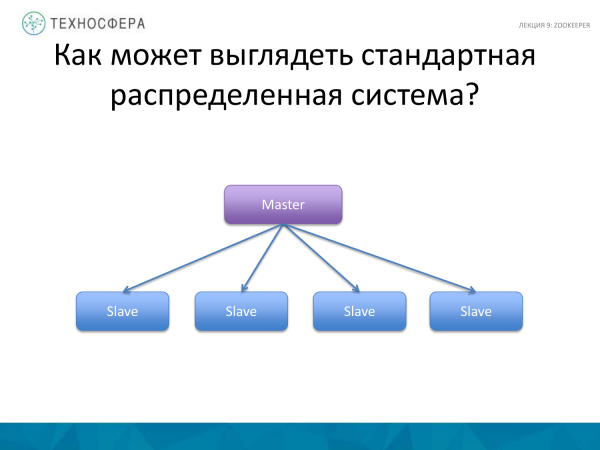
Vamos lembrar como seria um sistema distribuído padrão. Foi sobre isso que falamos - HDFS, HBase. Existe um processo Master que gerencia processos trabalhadores e escravos. Ele é responsável por coordenar e distribuir tarefas, reiniciar trabalhadores, lançar novos e distribuir a carga.
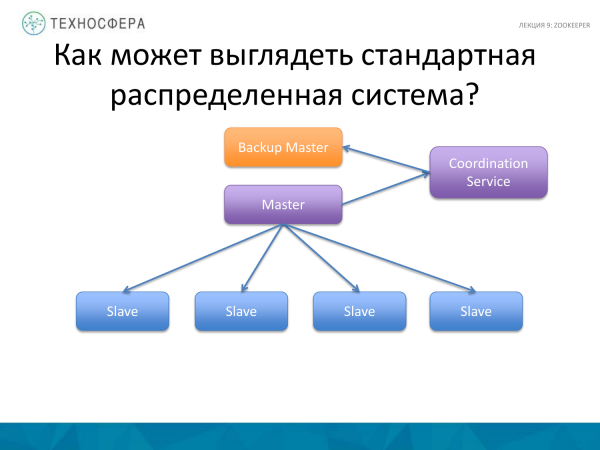
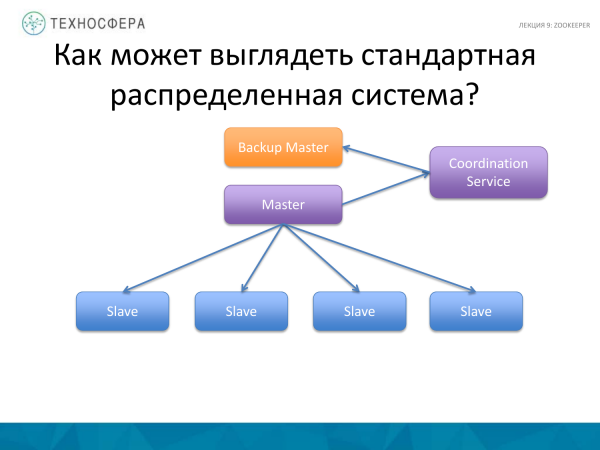
Uma coisa mais avançada é o Serviço de Coordenação, ou seja, mover a própria tarefa de coordenação para um processo separado, além de executar algum tipo de backup ou stanby Master em paralelo, pois o Master pode falhar. E se o Mestre cair, nosso sistema não funcionará. Estamos executando backup. Alguns afirmam que o Master precisa ser replicado para backup. Isto também pode ser confiado ao Serviço de Coordenação. Mas neste diagrama, o próprio Mestre é responsável pela coordenação dos trabalhadores; aqui o serviço está coordenando as atividades de replicação de dados.
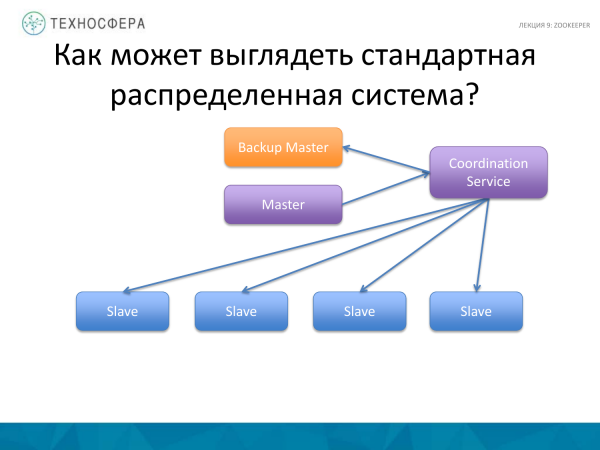
Uma opção mais avançada é quando toda a coordenação é feita pelo nosso serviço, como normalmente é feito. Ele assume a responsabilidade de garantir que tudo funcione. E se algo não dá certo, a gente descobre e tenta contornar essa situação. De qualquer forma, ficamos com um Mestre que de alguma forma interage com os escravos e pode enviar dados, informações, mensagens, etc. através de algum serviço.
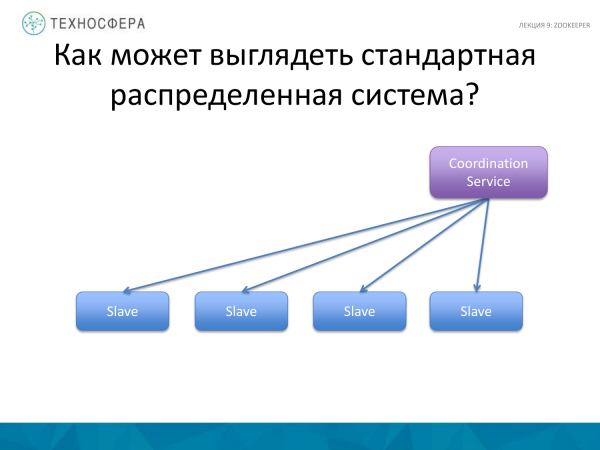
Existe um esquema ainda mais avançado, quando não temos um Mestre, todos os nós são mestres-escravos, diferentes em seu comportamento. Mas eles ainda precisam interagir entre si, então ainda resta algum serviço para coordenar essas ações. Provavelmente, Cassandra, que trabalha com esse princípio, se enquadra nesse esquema.
É difícil dizer qual destes esquemas funciona melhor. Cada um tem seus prós e contras.
E não há necessidade de ter medo de algumas coisas com o Mestre, porque, como mostra a prática, ele não é tão suscetível a servir constantemente. O principal aqui é escolher a solução certa para hospedar este serviço em um nó poderoso separado, para que tenha recursos suficientes, para que, se possível, os usuários não tenham acesso lá, para que não interrompam acidentalmente esse processo. Mas, ao mesmo tempo, em tal esquema é muito mais fácil gerenciar os trabalhadores do processo Master, ou seja, este esquema é mais simples em termos de implementação.
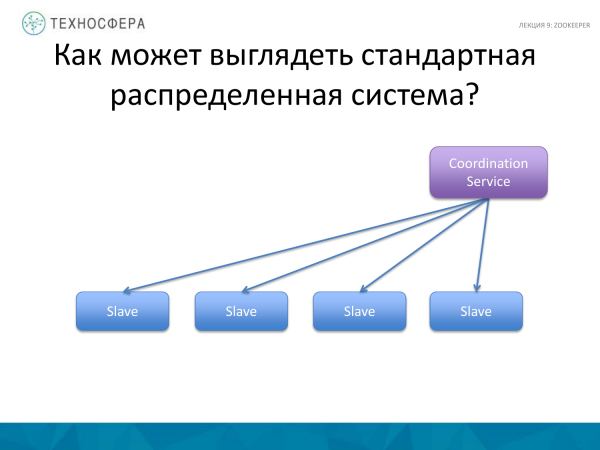
E este esquema (acima) é provavelmente mais complexo, mas mais confiável.

O principal problema são as falhas parciais. Por exemplo, quando enviamos uma mensagem pela Rede, ocorre algum tipo de acidente, e quem enviou a mensagem não saberá se sua mensagem foi recebida e o que aconteceu do lado do destinatário, não saberá se a mensagem foi processada corretamente , ou seja, ele não receberá nenhuma confirmação.
Assim, devemos processar esta situação. E o mais simples é reenviar esta mensagem e aguardar até recebermos uma resposta. Neste caso, não é levado em consideração se o estado do receptor mudou. Podemos enviar uma mensagem e adicionar os mesmos dados duas vezes.
O ZooKeeper oferece maneiras de lidar com essas recusas, o que também facilita nossa vida.

Como mencionado um pouco antes, isso é semelhante a escrever programas multithread, mas a principal diferença é que em aplicações distribuídas que construímos em máquinas diferentes, a única forma de comunicação é a Rede. Essencialmente, esta é uma arquitetura sem compartilhamento. Cada processo ou serviço executado em uma máquina possui sua própria memória, seu próprio disco, seu próprio processador, que não compartilha com ninguém.
Se escrevermos um programa multithread em um computador, poderemos usar memória compartilhada para trocar dados. Temos uma mudança de contexto aí, os processos podem mudar. Isso afeta o desempenho. Por um lado, não existe tal coisa no programa em cluster, mas há problemas com a Rede.

Conseqüentemente, os principais problemas que surgem ao escrever sistemas distribuídos são a configuração. Estamos escrevendo algum tipo de aplicativo. Se for simples, então codificamos todos os tipos de números no código, mas isso é inconveniente, porque se decidirmos que em vez de um tempo limite de meio segundo queremos um tempo limite de um segundo, então precisaremos recompilar o aplicativo e desenrole tudo novamente. Uma coisa é quando está em uma máquina, quando você pode simplesmente reiniciá-la, mas quando temos muitas máquinas, temos que copiar tudo constantemente. Devemos tentar tornar o aplicativo configurável.
Aqui estamos falando sobre configuração estática para processos do sistema. Isso não é inteiramente, talvez do ponto de vista do sistema operacional, pode ser uma configuração estática para nossos processos, ou seja, é uma configuração que não pode simplesmente ser tomada e atualizada.
Também existe uma configuração dinâmica. Esses são os parâmetros que queremos alterar na hora para que sejam selecionados lá.
Qual é o problema aqui? Atualizamos a configuração, implementamos, e daí? O problema pode ser que por um lado lançamos a configuração, mas esquecemos da novidade, a configuração permaneceu lá. Em segundo lugar, durante o lançamento, a configuração foi atualizada em alguns lugares, mas não em outros. E alguns processos do nosso aplicativo que rodam em uma máquina foram reiniciados com uma nova configuração e em algum lugar com uma antiga. Isso pode fazer com que nosso aplicativo distribuído seja inconsistente do ponto de vista da configuração. Este problema é comum. Para uma configuração dinâmica, é mais relevante porque implica que pode ser alterada em tempo real.
Outro problema é a adesão ao grupo. Sempre temos algum conjunto de trabalhadores, sempre queremos saber qual deles está vivo, qual deles está morto. Se houver um Mestre, ele deve entender quais trabalhadores podem ser redirecionados aos clientes para que façam cálculos ou trabalhem com dados e quais não podem. Um problema que surge constantemente é que precisamos saber quem está trabalhando no nosso cluster.
Outro problema típico são as eleições de líderes, quando queremos saber quem está no comando. Um exemplo é a replicação, quando temos algum processo que recebe operações de escrita e depois as replica entre outros processos. Ele será o líder, todos os outros irão obedecê-lo, irão segui-lo. É necessário escolher um processo que seja inequívoco para todos, para que não aconteça que sejam selecionados dois líderes.
Também existe acesso mutuamente exclusivo. O problema aqui é mais complexo. Existe um mutex, quando você escreve programas multithread e deseja que o acesso a algum recurso, por exemplo, uma célula de memória, seja limitado e realizado por apenas um thread. Aqui o recurso poderia ser algo mais abstrato. E diferentes aplicações de diferentes nós da nossa Rede só devem receber acesso exclusivo a um determinado recurso, e não para que todos possam alterá-lo ou escrever algo ali. Estas são as chamadas fechaduras.
ZooKeeper permite que você resolva todos esses problemas de uma forma ou de outra. E vou mostrar com exemplos como isso permite que você faça isso.

Não há primitivas de bloqueio. Quando começamos a usar algo, esta primitiva não esperará que nenhum evento ocorra. Muito provavelmente, isso funcionará de forma assíncrona, permitindo assim que os processos não sejam interrompidos enquanto aguardam algo. Isso é algo muito útil.
Todas as solicitações do cliente são processadas na ordem da fila geral.
E os clientes têm a oportunidade de receber notificações sobre alterações em algum estado, sobre alterações nos dados, antes que o próprio cliente veja os dados alterados.

O ZooKeeper pode operar em dois modos. O primeiro é autônomo, em um único nó. Isso é conveniente para testes. Ele também pode operar em modo cluster, em qualquer número de nós. servidoresSe tivermos um cluster de 100 máquinas, não é necessário que o ZooKeeper seja executado em todas elas. Basta alocar algumas máquinas para que ele possa rodar. E ele adere ao princípio de alta disponibilidade. O ZooKeeper armazena uma cópia completa dos dados em cada instância em execução. Explicarei como isso é feito mais adiante. Ele não fragmenta nem particiona os dados. Por um lado, isso é uma desvantagem, pois não podemos armazenar muita coisa, mas, por outro lado, é desnecessário. Ele não foi projetado para isso; não é um banco de dados.
Os dados podem ser armazenados em cache no lado do cliente. Este é um princípio padrão para não interrompermos o serviço e não carregá-lo com as mesmas solicitações. Um cliente inteligente geralmente sabe disso e armazena em cache.
Por exemplo, algo mudou aqui. Existe algum tipo de aplicativo. Foi eleito um novo líder, responsável, por exemplo, pelo processamento das operações de escrita. E queremos replicar os dados. Uma solução é colocá-lo em loop. E questionamos constantemente o nosso serviço - alguma coisa mudou? A segunda opção é mais ideal. Este é um mecanismo de observação que permite notificar os clientes de que algo mudou. Este é um método menos dispendioso em termos de recursos e mais conveniente para os clientes.

Cliente é o usuário que usa o ZooKeeper.
Servidor é o próprio processo do ZooKeeper.
Znode é a chave no ZooKeeper. Todos os znodes são armazenados na memória pelo ZooKeeper e são organizados em forma de diagrama hierárquico, em forma de árvore.
Existem dois tipos de operações. A primeira é atualização/gravação, quando alguma operação altera o estado da nossa árvore. A árvore é comum.
E é possível que o cliente não conclua uma solicitação e seja desconectado, mas possa estabelecer uma sessão através da qual interaja com o ZooKeeper.

O modelo de dados do ZooKeeper se assemelha a um sistema de arquivos. Existe uma raiz padrão e então passamos pelos diretórios que vão da raiz. E então o catálogo do primeiro nível, do segundo nível. Isso é tudo znodes.
Cada znode pode armazenar alguns dados, geralmente não muito grandes, por exemplo, 10 kilobytes. E cada znode pode ter um certo número de filhos.

Znodes vêm em vários tipos. Eles podem ser criados. E ao criar um znode, especificamos o tipo ao qual ele deve pertencer.
Existem dois tipos. A primeira é a bandeira efêmera. Znode vive dentro de uma sessão. Por exemplo, o cliente estabeleceu uma sessão. E enquanto esta sessão estiver viva, ela existirá. Isso é necessário para não produzir algo desnecessário. Isso também é adequado para momentos em que é importante armazenar dados primitivos em uma sessão.
O segundo tipo é o sinalizador sequencial. Ele incrementa o contador no caminho para o znode. Por exemplo, tínhamos um diretório com o aplicativo 1_5. E quando criamos o primeiro nó, ele recebeu p_1, o segundo - p_2. E cada vez que chamamos esse método, passamos o caminho completo, indicando apenas parte do caminho, e esse número é incrementado automaticamente porque indicamos o tipo de nó - sequencial.
Nó normal. Ela sempre viverá e terá o nome que lhe dissermos.

Outra coisa útil é a bandeira do relógio. Se instalarmos, o cliente poderá assinar alguns eventos para um nó específico. Mostrarei mais tarde com um exemplo como isso é feito. O próprio ZooKeeper notifica o cliente de que os dados no nó foram alterados. No entanto, as notificações não garantem a chegada de novos dados. Eles simplesmente dizem que algo mudou, então você ainda terá que comparar os dados posteriormente com chamadas separadas.
E como já disse, a ordem dos dados é determinada em kilobytes. Não há necessidade de armazenar grandes dados de texto ali, porque não é um banco de dados, é um servidor de coordenação de ações.

Deixe-me explicar um pouco sobre sessões. Se tivermos vários servidores, podemos alternar de um servidor para outro de forma transparente. servidor, usando o ID da sessão. Isso é bastante conveniente.
Cada sessão tem algum tipo de tempo limite. Uma sessão é definida pelo fato de o cliente enviar algo ao servidor durante essa sessão. Se ele não transmitiu nada durante o tempo limite, a sessão será interrompida ou o próprio cliente poderá fechá-la.

Não possui muitos recursos, mas você pode fazer coisas diferentes com esta API. Aquela chamada que vimos create cria um znode e leva três parâmetros. Este é o caminho para o znode e deve ser especificado por completo na raiz. E também estes são alguns dados que queremos transferir para lá. E o tipo de bandeira. E após a criação ele retorna o caminho para o znode.
Em segundo lugar, você pode excluí-lo. O truque aqui é que o segundo parâmetro, além do caminho para o znode, pode especificar a versão. Conseqüentemente, esse znode será excluído se a versão que transferimos for equivalente à que realmente existe.
Se não quisermos verificar esta versão, simplesmente passamos o argumento "-1".

Terceiro, verifica a existência de um znode. Retorna verdadeiro se o nó existir, falso caso contrário.
E então aparece o sinalizador watch, que permite monitorar este nó.
Você pode definir esse sinalizador mesmo em um nó inexistente e receber uma notificação quando ele aparecer. Isso também pode ser útil.
Mais alguns desafios são Obter dados. É claro que podemos receber dados via znode. Você também pode usar o relógio de bandeira. Neste caso, ele não será instalado se não houver nenhum nó. Portanto, você precisa entender que ele existe e então receber os dados.

Também há SetData. Aqui passamos a versão. E se repassarmos isso, os dados do znode de uma determinada versão serão atualizados.
Você também pode especificar "-1" para excluir esta verificação.
Outro método útil é obterCrianças. Também podemos obter uma lista de todos os znodes que pertencem a ele. Podemos monitorar isso definindo flag watch.
E método sincronizar permite que todas as alterações sejam enviadas de uma só vez, garantindo assim que elas sejam salvas e que todos os dados sejam completamente alterados.
Se fizermos analogias com a programação normal, quando você usa métodos como write, que grava algo no disco e depois retorna uma resposta para você, não há garantia de que você gravou os dados no disco. E mesmo quando o sistema operacional tem certeza de que tudo foi gravado, existem mecanismos no próprio disco onde o processo passa por camadas de buffers, e só depois disso os dados são colocados no disco.

Principalmente chamadas assíncronas são usadas. Isso permite que o cliente trabalhe em paralelo com diferentes solicitações. Você pode usar a abordagem síncrona, mas é menos produtiva.
As duas operações de que falamos são atualização/gravação, que alteram dados. Estes são criar, definir dados, sincronizar, excluir. E a leitura existe, getData, getChildren.
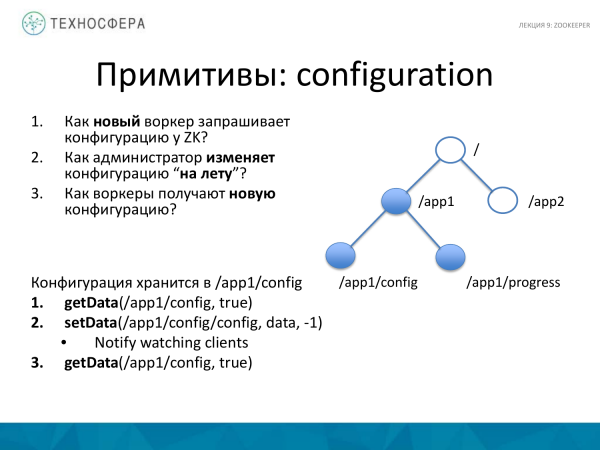
Agora, alguns exemplos de como você pode criar primitivas para trabalhar em um sistema distribuído. Por exemplo, relacionado à configuração de algo. Um novo trabalhador apareceu. Adicionamos a máquina e iniciamos o processo. E há as três perguntas a seguir. Como ele consulta o ZooKeeper para configuração? E se quisermos alterar a configuração, como a alteramos? E depois que mudamos, como os trabalhadores que tínhamos conseguiram isso?
O ZooKeeper torna isso relativamente fácil. Por exemplo, existe nossa árvore znode. Existe um nó para nossa aplicação aqui, criamos um nó adicional nele, que contém dados da configuração. Estes podem ou não ser parâmetros separados. Como o tamanho é pequeno, o tamanho da configuração geralmente também é pequeno, então é bem possível armazená-lo aqui.
Você está usando o método Obter dados para obter a configuração do trabalhador do nó. Defina como verdadeiro. Se por algum motivo este nó não existir, seremos informados sobre ele quando ele aparecer ou quando mudar. Se quisermos saber se algo mudou, definimos isso como verdadeiro. E se os dados neste nó mudarem, saberemos disso.
SetData. Definimos os dados, definimos “-1”, ou seja, não verificamos a versão, assumimos que temos sempre uma configuração, não precisamos armazenar muitas configurações. Se precisar armazenar muito, você precisará adicionar outro nível. Aqui acreditamos que existe apenas um, por isso atualizamos apenas o mais recente, para não verificarmos a versão. Neste momento, todos os clientes que já se inscreveram recebem uma notificação de que algo mudou neste nó. E depois de recebê-los, também deverão solicitar novamente os dados. A notificação é que eles não recebem os dados em si, mas apenas notificação de alterações. Depois disso, eles deverão solicitar novos dados.
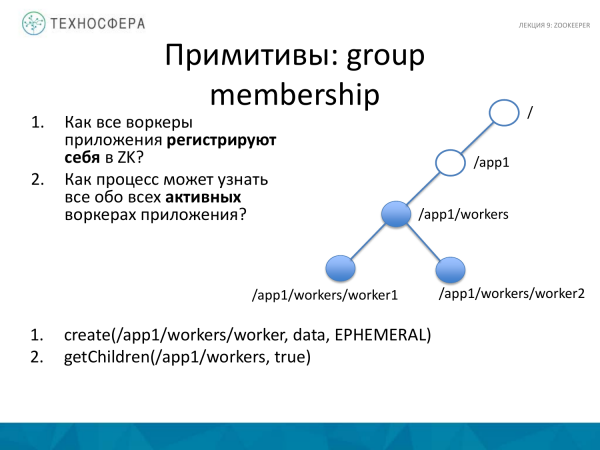
A segunda opção para usar o primitivo é filiação ao grupo. Temos uma aplicação distribuída, há muitos trabalhadores e queremos entender se estão todos funcionando. Portanto, eles devem se cadastrar para trabalhar em nosso aplicativo. E também queremos saber, seja no processo Master ou em outro lugar, todos os trabalhadores ativos que temos atualmente.
Como vamos fazer isso? Para o aplicativo, criamos um nó de trabalho e adicionamos um subnível usando o método create. Tenho um erro no slide. Aqui você precisa seqüente especificar, então todos os trabalhadores serão criados um por um. E a aplicação, solicitando todos os dados dos filhos deste nó, recebe todos os trabalhadores ativos que existem.
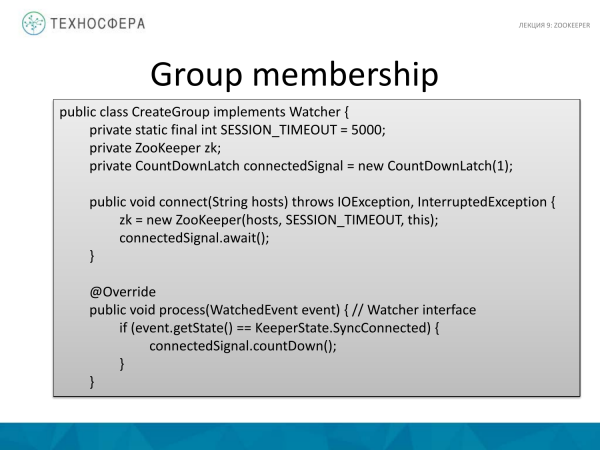

Esta é uma implementação terrível de como isso pode ser feito em código Java. Vamos começar do final, com o método principal. Esta é a nossa classe, vamos criar seu método. Como primeiro argumento usamos host, onde estamos nos conectando, ou seja, definimos como argumento. E o segundo argumento é o nome do grupo.
Como acontece a conexão? Este é um exemplo simples da API usada. Tudo é relativamente simples aqui. Existe uma classe padrão ZooKeeper. Passamos hosts para ele. E defina o tempo limite, por exemplo, para 5 segundos. E temos um membro chamado conectadoSignal. Essencialmente, criamos um grupo ao longo do caminho transmitido. Não escrevemos dados lá, embora algo pudesse ter sido escrito. E o nó aqui é do tipo persistente. Essencialmente, este é um nó regular comum que existirá o tempo todo. É aqui que a sessão é criada. Esta é a implementação do próprio cliente. Nosso cliente enviará mensagens periódicas indicando que a sessão está ativa. E quando terminamos a sessão, chamamos close e pronto, a sessão cai. Isso ocorre para o caso de algo acontecer para nós, para que o ZooKeeper descubra e interrompa a sessão.
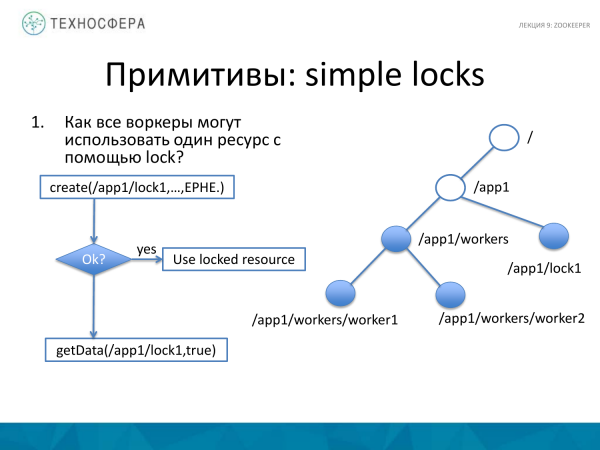
Como bloquear um recurso? Aqui tudo é um pouco mais complicado. Temos um conjunto de trabalhadores, existe algum recurso que queremos bloquear. Para fazer isso, criamos um nó separado, por exemplo, chamado lock1. Se conseguirmos criá-lo, teremos um cadeado aqui. E se não conseguimos criá-lo, então o trabalhador tenta obter getData daqui, e como o nó já foi criado, colocamos um observador aqui e no momento em que o estado desse nó mudar, saberemos disso. E podemos tentar ter tempo para recriá-lo. Se pegamos esse nó, pegamos esse bloqueio, então depois que não precisarmos mais do bloqueio, vamos abandoná-lo, pois o nó existe apenas dentro da sessão. Conseqüentemente, ele desaparecerá. E outro cliente, no âmbito de outra sessão, poderá fazer o bloqueio deste nó, ou melhor, receberá uma notificação de que algo mudou e poderá tentar fazê-lo a tempo.
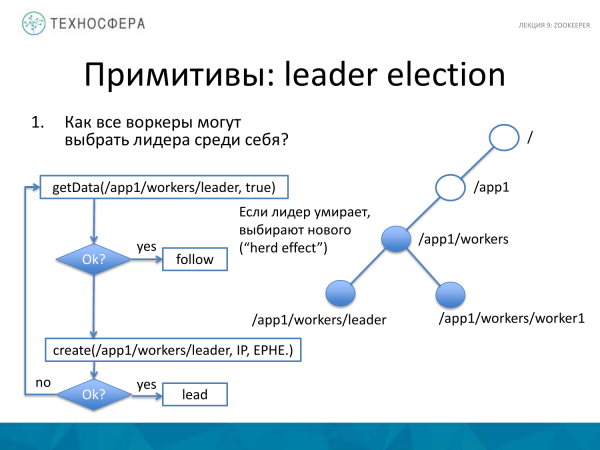
Outro exemplo de como você pode escolher o líder principal. Isso é um pouco mais complicado, mas também relativamente simples. O que está acontecendo aqui? Existe um nó principal que agrega todos os trabalhadores. Estamos tentando obter dados sobre o líder. Se isso aconteceu com sucesso, ou seja, recebemos alguns dados, então nosso trabalhador começa a seguir esse líder. Ele acredita que já existe um líder.
Se o líder morreu por algum motivo, por exemplo, caiu, então tentamos criar um novo líder. E se tivermos sucesso, então o nosso trabalhador se torna o líder. E se alguém neste momento conseguiu criar um novo líder, então tentamos entender quem é e depois segui-lo.
Aqui surge o chamado efeito manada, ou seja, o efeito manada, porque quando um líder morre, aquele que for o primeiro no tempo se tornará o líder.
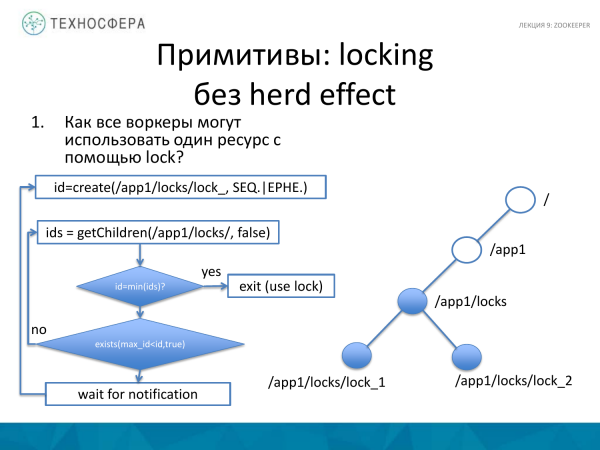
Ao capturar um recurso, você pode tentar usar uma abordagem um pouco diferente, que é a seguinte. Por exemplo, queremos obter um bloqueio, mas sem o efeito hert. Consistirá no fato de que nosso aplicativo solicitará listas de todos os IDs de nós para um nó já existente com um bloqueio. E se antes disso o nó para o qual criamos um bloqueio é o menor do conjunto que recebemos, isso significa que capturamos o bloqueio. Verificamos se recebemos um bloqueio. Como verificação, haverá a condição de que o id que recebemos ao criar um novo bloqueio seja mínimo. E se o recebemos, trabalhamos mais.
Se houver um determinado id menor que o nosso bloqueio, colocamos um observador neste evento e aguardamos a notificação até que algo mude. Ou seja, recebemos esse bloqueio. E até que caia, não nos tornaremos o id mínimo e não receberemos o bloqueio mínimo, e assim poderemos fazer o login. E se essa condição não for atendida, então vamos imediatamente aqui e tentamos obter esse bloqueio novamente, pois algo pode ter mudado durante esse tempo.
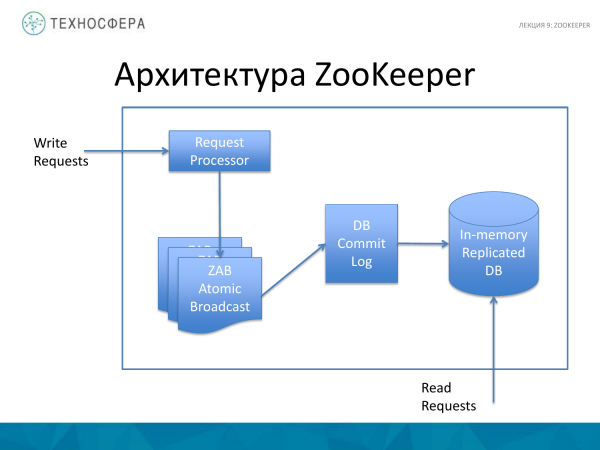
Em que consiste o ZooKeeper? Existem 4 coisas principais. Este é o processamento de processos - Solicitação. E também ZooKeeper Atomic Broadcast. Existe um Commit Log onde todas as operações são registradas. E o próprio banco de dados replicado na memória, ou seja, o próprio banco de dados onde toda essa árvore está armazenada.
Vale ressaltar que todas as operações de gravação passam pelo Processador de Solicitações. E as operações de leitura vão diretamente para o banco de dados na memória.

O próprio banco de dados é totalmente replicado. Todas as instâncias do ZooKeeper armazenam uma cópia completa dos dados.
Para restaurar o banco de dados após uma falha, existe um log de Commit. A prática padrão é que, antes que os dados cheguem à memória, eles sejam gravados lá para que, em caso de falha, esse log possa ser reproduzido e o estado do sistema possa ser restaurado. E instantâneos periódicos do banco de dados também são usados.

ZooKeeper Atomic Broadcast é algo usado para manter dados replicados.
O ZAB seleciona internamente um líder do ponto de vista do nó ZooKeeper. Outros nós se tornam seus seguidores e esperam algumas ações dela. Se receberem inscrições, encaminham todas para o líder. Ele primeiro realiza uma operação de gravação e depois envia uma mensagem sobre o que mudou para seus seguidores. Isto, na verdade, deve ser realizado de forma atômica, ou seja, a operação de gravação e transmissão de tudo deve ser realizada de forma atômica, garantindo assim a consistência dos dados.
 Ele processa apenas solicitações de gravação. Sua principal tarefa é transformar a operação em uma atualização transacional. Esta é uma solicitação gerada especialmente.
Ele processa apenas solicitações de gravação. Sua principal tarefa é transformar a operação em uma atualização transacional. Esta é uma solicitação gerada especialmente.
E aqui vale destacar que a idempotência das atualizações para a mesma operação está garantida. O que é isso? Essa coisa, se executada duas vezes, terá o mesmo estado, ou seja, a solicitação em si não mudará. E isso precisa ser feito para que em caso de travamento você possa reiniciar a operação, revertendo assim as alterações que caíram no momento. Neste caso, o estado do sistema se tornará o mesmo, ou seja, não deveria acontecer que uma série do mesmo, por exemplo, processos de atualização, levasse a diferentes estados finais do sistema.








Fonte: habr.com
