

Muitas pessoas usam ferramentas especializadas para criar rotinas de extração, transformação e carregamento de dados em bancos de dados relacionais. O processo das ferramentas é registrado, os erros são registrados.
Em caso de erro, o log contém informações de que a ferramenta falhou ao concluir a tarefa e quais módulos (geralmente java) pararam e onde. As últimas linhas podem conter um erro de banco de dados, como uma violação da chave exclusiva de uma tabela.
Para responder à questão de qual o papel das informações de erro de ETL, classifiquei todos os problemas que ocorreram nos últimos dois anos em um repositório bastante grande.
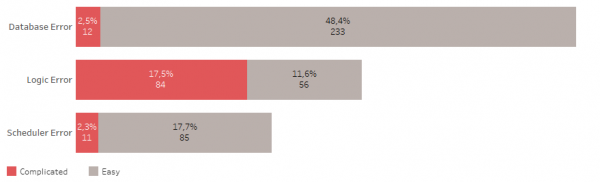
Erros de banco de dados incluem: não havia espaço suficiente, a conexão foi perdida, a sessão foi interrompida, etc.
Erros lógicos incluem violações de chaves de tabela, objetos inválidos, falta de acesso a objetos, etc.
O agendador pode não ser iniciado na hora certa, pode congelar, etc.
Erros simples não levam muito tempo para serem corrigidos. Um bom ETL pode lidar com a maioria deles sozinho.
Erros complexos tornam necessário abrir e verificar procedimentos de tratamento de dados e investigar fontes de dados. Muitas vezes levam à necessidade de testar alterações e implantar.
Portanto, metade de todos os problemas está relacionada ao banco de dados. 48% de todos os erros são erros simples.
Um terço de todos os problemas está relacionado a mudanças na lógica ou modelo de armazenamento; mais da metade desses erros são complexos.
E menos de um quarto de todos os problemas estão relacionados ao agendador de tarefas, 18% dos quais são erros simples.
No geral, 22% de todos os erros que ocorrem são complexos e requerem mais atenção e tempo para serem corrigidos. Eles acontecem cerca de uma vez por semana. Embora erros simples aconteçam quase todos os dias.
Obviamente, o monitoramento dos processos ETL será eficaz quando a localização do erro for indicada no log com a maior precisão possível e for necessário um tempo mínimo para encontrar a origem do problema.
Monitoramento eficaz
O que eu queria ver no processo de monitoramento de ETL?
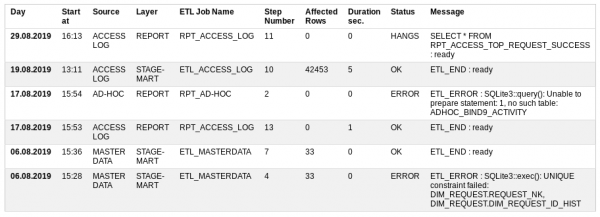
Comece em - quando comecei a trabalhar,
Fonte - fonte de dados,
Camada - qual nível de armazenamento é carregado,
ETL Job Name é um procedimento de carregamento que consiste em muitas pequenas etapas,
Número da etapa - número da etapa que está sendo executada,
Linhas afetadas - quantos dados já foram processados,
Duração seg - quanto tempo leva para ser executado,
Status - se está tudo bem ou não: OK, ERRO, EM EXECUÇÃO, TRAVA
Mensagem — última mensagem de sucesso ou descrição do erro.
Com base no status dos registros, você pode enviar um email. carta para outros participantes. Se não houver erros, não será necessária uma carta.
Desta forma, em caso de erro, o local do incidente é claramente indicado.
Às vezes acontece que a própria ferramenta de monitoramento não funciona. Neste caso, é possível chamar a visão (visualização) diretamente no banco de dados, com base na qual o relatório é construído.
Tabela de monitoramento ETL
Para implementar o monitoramento dos processos ETL, basta uma tabela e uma visualização.
Para fazer isso você pode retornar para e crie um protótipo no banco de dados sqlite.
Tabelas DDL
CREATE TABLE UTL_JOB_STATUS (
/* Table for logging of job execution log. Important that the job has the steps ETL_START and ETL_END or ETL_ERROR */
UTL_JOB_STATUS_ID INTEGER NOT NULL PRIMARY KEY AUTOINCREMENT,
SID INTEGER NOT NULL DEFAULT -1, /* Session Identificator. Unique for every Run of job */
LOG_DT INTEGER NOT NULL DEFAULT 0, /* Date time */
LOG_D INTEGER NOT NULL DEFAULT 0, /* Date */
JOB_NAME TEXT NOT NULL DEFAULT 'N/A', /* Job name like JOB_STG2DM_GEO */
STEP_NAME TEXT NOT NULL DEFAULT 'N/A', /* ETL_START, ... , ETL_END/ETL_ERROR */
STEP_DESCR TEXT, /* Description of task or error message */
UNIQUE (SID, JOB_NAME, STEP_NAME)
);
INSERT INTO UTL_JOB_STATUS (UTL_JOB_STATUS_ID) VALUES (-1);Ver/relatar DDL
CREATE VIEW IF NOT EXISTS UTL_JOB_STATUS_V
AS /* Content: Package Execution Log for last 3 Months. */
WITH SRC AS (
SELECT LOG_D,
LOG_DT,
UTL_JOB_STATUS_ID,
SID,
CASE WHEN INSTR(JOB_NAME, 'FTP') THEN 'TRANSFER' /* file transfer */
WHEN INSTR(JOB_NAME, 'STG') THEN 'STAGE' /* stage */
WHEN INSTR(JOB_NAME, 'CLS') THEN 'CLEANSING' /* cleansing */
WHEN INSTR(JOB_NAME, 'DIM') THEN 'DIMENSION' /* dimension */
WHEN INSTR(JOB_NAME, 'FCT') THEN 'FACT' /* fact */
WHEN INSTR(JOB_NAME, 'ETL') THEN 'STAGE-MART' /* data mart */
WHEN INSTR(JOB_NAME, 'RPT') THEN 'REPORT' /* report */
ELSE 'N/A' END AS LAYER,
CASE WHEN INSTR(JOB_NAME, 'ACCESS') THEN 'ACCESS LOG' /* source */
WHEN INSTR(JOB_NAME, 'MASTER') THEN 'MASTER DATA' /* source */
WHEN INSTR(JOB_NAME, 'AD-HOC') THEN 'AD-HOC' /* source */
ELSE 'N/A' END AS SOURCE,
JOB_NAME,
STEP_NAME,
CASE WHEN STEP_NAME='ETL_START' THEN 1 ELSE 0 END AS START_FLAG,
CASE WHEN STEP_NAME='ETL_END' THEN 1 ELSE 0 END AS END_FLAG,
CASE WHEN STEP_NAME='ETL_ERROR' THEN 1 ELSE 0 END AS ERROR_FLAG,
STEP_NAME || ' : ' || STEP_DESCR AS STEP_LOG,
SUBSTR( SUBSTR(STEP_DESCR, INSTR(STEP_DESCR, '***')+4), 1, INSTR(SUBSTR(STEP_DESCR, INSTR(STEP_DESCR, '***')+4), '***')-2 ) AS AFFECTED_ROWS
FROM UTL_JOB_STATUS
WHERE datetime(LOG_D, 'unixepoch') >= date('now', 'start of month', '-3 month')
)
SELECT JB.SID,
JB.MIN_LOG_DT AS START_DT,
strftime('%d.%m.%Y %H:%M', datetime(JB.MIN_LOG_DT, 'unixepoch')) AS LOG_DT,
JB.SOURCE,
JB.LAYER,
JB.JOB_NAME,
CASE
WHEN JB.ERROR_FLAG = 1 THEN 'ERROR'
WHEN JB.ERROR_FLAG = 0 AND JB.END_FLAG = 0 AND strftime('%s','now') - JB.MIN_LOG_DT > 0.5*60*60 THEN 'HANGS' /* half an hour */
WHEN JB.ERROR_FLAG = 0 AND JB.END_FLAG = 0 THEN 'RUNNING'
ELSE 'OK'
END AS STATUS,
ERR.STEP_LOG AS STEP_LOG,
JB.CNT AS STEP_CNT,
JB.AFFECTED_ROWS AS AFFECTED_ROWS,
strftime('%d.%m.%Y %H:%M', datetime(JB.MIN_LOG_DT, 'unixepoch')) AS JOB_START_DT,
strftime('%d.%m.%Y %H:%M', datetime(JB.MAX_LOG_DT, 'unixepoch')) AS JOB_END_DT,
JB.MAX_LOG_DT - JB.MIN_LOG_DT AS JOB_DURATION_SEC
FROM
( SELECT SID, SOURCE, LAYER, JOB_NAME,
MAX(UTL_JOB_STATUS_ID) AS UTL_JOB_STATUS_ID,
MAX(START_FLAG) AS START_FLAG,
MAX(END_FLAG) AS END_FLAG,
MAX(ERROR_FLAG) AS ERROR_FLAG,
MIN(LOG_DT) AS MIN_LOG_DT,
MAX(LOG_DT) AS MAX_LOG_DT,
SUM(1) AS CNT,
SUM(IFNULL(AFFECTED_ROWS, 0)) AS AFFECTED_ROWS
FROM SRC
GROUP BY SID, SOURCE, LAYER, JOB_NAME
) JB,
( SELECT UTL_JOB_STATUS_ID, SID, JOB_NAME, STEP_LOG
FROM SRC
WHERE 1 = 1
) ERR
WHERE 1 = 1
AND JB.SID = ERR.SID
AND JB.JOB_NAME = ERR.JOB_NAME
AND JB.UTL_JOB_STATUS_ID = ERR.UTL_JOB_STATUS_ID
ORDER BY JB.MIN_LOG_DT DESC, JB.SID DESC, JB.SOURCE;SQL Verificando a capacidade de obter um novo número de sessão
SELECT SUM (
CASE WHEN start_job.JOB_NAME IS NOT NULL AND end_job.JOB_NAME IS NULL /* existed job finished */
AND NOT ( 'y' = 'n' ) /* force restart PARAMETER */
THEN 1 ELSE 0
END ) AS IS_RUNNING
FROM
( SELECT 1 AS dummy FROM UTL_JOB_STATUS WHERE sid = -1) d_job
LEFT OUTER JOIN
( SELECT JOB_NAME, SID, 1 AS dummy
FROM UTL_JOB_STATUS
WHERE JOB_NAME = 'RPT_ACCESS_LOG' /* job name PARAMETER */
AND STEP_NAME = 'ETL_START'
GROUP BY JOB_NAME, SID
) start_job /* starts */
ON d_job.dummy = start_job.dummy
LEFT OUTER JOIN
( SELECT JOB_NAME, SID
FROM UTL_JOB_STATUS
WHERE JOB_NAME = 'RPT_ACCESS_LOG' /* job name PARAMETER */
AND STEP_NAME in ('ETL_END', 'ETL_ERROR') /* stop status */
GROUP BY JOB_NAME, SID
) end_job /* ends */
ON start_job.JOB_NAME = end_job.JOB_NAME
AND start_job.SID = end_job.SIDRecursos da tabela:
- o início e o fim do procedimento de tratamento de dados devem ser acompanhados das etapas ETL_START e ETL_END
- em caso de erro, deverá ser criada uma etapa ETL_ERROR com sua descrição
- a quantidade de dados processados deve ser destacada, por exemplo, com asteriscos
- o mesmo procedimento pode ser iniciado ao mesmo tempo com o parâmetro force_restart=y; sem ele, o número da sessão é emitido apenas para o procedimento concluído
- no modo normal é impossível executar o mesmo procedimento de processamento de dados em paralelo
As operações necessárias para trabalhar com a mesa são as seguintes:
- obtendo o número da sessão do procedimento ETL que está sendo iniciado
- inserindo uma entrada de log em uma tabela
- obtendo o último registro bem-sucedido de um procedimento ETL
Em bancos de dados como Oracle ou Postgres, essas operações podem ser implementadas com funções integradas. sqlite requer um mecanismo externo e neste caso .
Jogar aviator online grátis: hack aviator funciona
Assim, o relatório de erros em ferramentas de processamento de dados desempenha um papel extremamente importante. Mas dificilmente podem ser considerados ideais para encontrar rapidamente a causa do problema. Quando o número de procedimentos se aproxima de cem, o monitoramento de processos se transforma em um projeto complexo.
O artigo fornece um exemplo de uma possível solução para o problema na forma de um protótipo. Todo o protótipo do pequeno repositório está disponível no gitlab .
Fonte: habr.com
