

Engenheiro - traduzido do latim - inspirado.
Um engenheiro pode fazer qualquer coisa. (c) R. Diesel.
Epígrafes.

Ou uma história sobre por que um administrador de banco de dados precisa se lembrar de seu passado de programação.
Prefácio
Todos os nomes foram alterados. As partidas são aleatórias. O material é apenas a opinião pessoal do autor.
Isenção de garantias: na série planejada de artigos não haverá descrição detalhada e precisa das tabelas e scripts usados. Os materiais não podem ser usados imediatamente "COMO ESTÃO".
Primeiro, devido à grande quantidade de material,
em segundo lugar, devido à nitidez com a base de produção de um cliente real.
Portanto, apenas idéias e descrições na forma mais geral serão dadas nos artigos.
Talvez no futuro o sistema cresça a ponto de postar no GitHub, ou talvez não. O tempo mostrará.
O começo da história-".
O que aconteceu como resultado, nos termos mais gerais - "»
Por que eu preciso de tudo isso?
Bem, em primeiro lugar, para não se esquecer de si mesmo, lembrando-se dos dias gloriosos da aposentadoria.
Em segundo lugar, para sistematizar o que foi escrito. Para mim, às vezes começo a ficar confuso e esqueço partes separadas.
Bem, e o mais importante - de repente pode ser útil para alguém e ajudar a não reinventar a roda e não coletar um ancinho. Em outras palavras, melhore seu karma (não Khabrovsky). Pois o que há de mais valioso neste mundo são as ideias. O principal é encontrar uma ideia. E traduzir a ideia em realidade já é uma questão puramente técnica.
Então vamos começar devagar...
Formulação do problema.
Existe:
PostgreSQL(10.5), carga mista (OLTP+DSS), carga média a leve, hospedado na nuvem AWS.
Não há monitoramento de banco de dados, o monitoramento de infraestrutura é apresentado como ferramentas padrão da AWS em uma configuração mínima.
exige:
Monitore o desempenho e o status do banco de dados, encontre e tenha informações iniciais para otimizar consultas pesadas ao banco de dados.
Breve introdução ou análise de soluções
Para começar, vamos tentar analisar as opções de solução do problema do ponto de vista de uma análise comparativa dos benefícios e inconveniências para o engenheiro, e deixar quem deveria estar na lista de funcionários lidar com os benefícios e prejuízos de gestão.
Opção 1 - "Trabalhando sob demanda"
Deixamos tudo como está. Se o cliente não estiver satisfeito com algo na saúde, desempenho do banco de dados ou aplicativo, ele notificará os engenheiros DBA por e-mail ou criando um incidente na caixa de entrada.
Um engenheiro, ao receber uma notificação, entenderá o problema, oferecerá uma solução ou arquivará o problema, esperando que tudo se resolva e, de qualquer maneira, tudo logo será esquecido.
Pão de mel e rosquinhas, hematomas e solavancosPão de mel e donuts:
1. Nada extra para fazer
2. Sempre há a oportunidade de sair e se sujar.
3. Muito tempo que você pode gastar sozinho.
Contusões e inchaços:
1. Mais cedo ou mais tarde, o cliente pensará na essência do ser e da justiça universal neste mundo e mais uma vez se perguntará - por que estou pagando meu dinheiro a eles? A consequência é sempre a mesma - a única dúvida é quando o cliente fica entediado e se despede. E o alimentador está vazio. É triste.
2. O desenvolvimento de um engenheiro é zero.
3. Dificuldades em agendar trabalho e carregamento
Opção 2 - “Dance com pandeiros, calce e calce os sapatos”
Parágrafo 1-Por que precisamos de um sistema de monitoramento, receberemos todas as solicitações. Lançamos vários tipos de consultas ao dicionário de dados e exibições dinâmicas, ativamos todos os tipos de contadores, colocamos tudo em tabelas, analisamos periodicamente listas e tabelas, por assim dizer. Como resultado, temos gráficos, tabelas, relatórios bonitos ou não. A principal coisa - isso seria mais, mais.
Parágrafo 2-Gerar atividade-executar a análise de tudo isso.
Parágrafo 3-Estamos preparando um determinado documento, chamamos esse documento, simplesmente - "como equipamos o banco de dados".
Parágrafo 4- O cliente, vendo toda essa magnificência de gráficos e figuras, fica com uma confiança ingênua infantil - agora tudo vai dar certo para nós, em breve. E, com facilidade e sem dor, desfaça-se de seus recursos financeiros. A administração também tem certeza de que nossos engenheiros estão trabalhando duro. Carregamento máx.
Parágrafo 5- Repita o passo 1 regularmente.
Pão de mel e rosquinhas, hematomas e solavancosPão de mel e donuts:
1. A vida dos gerentes e engenheiros é simples, previsível e cheia de atividades. Tudo está agitado, todo mundo está ocupado.
2. A vida do cliente também não é ruim - ele sempre tem certeza de que você precisa ter um pouco de paciência e tudo vai dar certo. Não está melhorando, bem, bem - este mundo é injusto, na próxima vida - você terá sorte.
Contusões e inchaços:
1. Mais cedo ou mais tarde, haverá um provedor mais inteligente de um serviço semelhante que fará a mesma coisa, mas um pouco mais barato. E se o resultado é o mesmo, por que pagar mais? O que novamente levará ao desaparecimento do alimentador.
2. É chato. Que chato qualquer pequena atividade significativa.
3. Como na versão anterior - sem desenvolvimento. Mas para um engenheiro, o menos é que, ao contrário da primeira opção, aqui você precisa gerar um BID constantemente. E isso leva tempo. Que pode ser gasto em benefício de seu ente querido. Pois você não pode cuidar de si mesmo, todo mundo se preocupa com você.
Opção 3 - Não precisa inventar uma bicicleta, você precisa comprá-la e andar nela.
Engenheiros de outras empresas comem pizza com cerveja conscientemente (oh, os tempos gloriosos de São Petersburgo nos anos 90). Vamos usar sistemas de monitoramento que são feitos, depurados e funcionando, e de um modo geral, eles trazem benefícios (bem, pelo menos para seus criadores).
Pão de mel e rosquinhas, hematomas e solavancosPão de mel e donuts:
1. Não precisa perder tempo inventando o que já está inventado. Pegue e use.
2. Os sistemas de monitoramento não são escritos por tolos e, claro, são úteis.
3. Os sistemas de monitoramento em funcionamento geralmente fornecem informações filtradas úteis.
Contusões e inchaços:
1. O engenheiro neste caso não é um engenheiro, mas apenas um usuário do produto de outra pessoa, ou um usuário.
2. O cliente deve estar convencido da necessidade de comprar algo que geralmente não quer entender, e não deveria, e em geral o orçamento do ano foi aprovado e não vai mudar. Então você precisa alocar um recurso separado, configurá-lo para um sistema específico. Aqueles. Primeiro você precisa pagar, pagar e pagar novamente. E o cliente é mesquinho. Esta é a norma desta vida.
O que fazer, Chernyshevsky? Sua pergunta é muito pertinente. (Com)
Neste caso particular e na situação atual, você pode fazer um pouco diferente - vamos fazer nosso próprio sistema de monitoramento.

Bem, não é um sistema, é claro, no sentido pleno da palavra, isso é muito alto e presunçoso, mas pelo menos de alguma forma facilite para você e colete mais informações para resolver incidentes de desempenho. Para não se encontrar em uma situação - “vá lá, não sei onde, encontre isso, não sei o quê”.
Quais são os prós e contras desta opção:
Prós:
1. É interessante. Bem, pelo menos mais interessante do que a constante "encolher arquivo de dados, alterar espaço de tabela, etc."
2. Estas são novas habilidades e novos desenvolvimentos. Que no futuro, mais cedo ou mais tarde, dará o merecido pão de mel e rosquinhas.
Contras:
1. Tem que trabalhar. Trabalhar muito.
2. Você terá que explicar regularmente o significado e as perspectivas de todas as atividades.
3. Algo terá que ser sacrificado, pois o único recurso de que dispõe o engenheiro - o tempo - é limitado pelo Universo.
4. O pior e mais desagradável - como resultado, lixo como "Não é um rato, não é um sapo, mas um bichinho desconhecido" pode acabar.
Quem não arrisca algo não bebe champanhe.
Então, a diversão começa.
Ideia geral - esquema
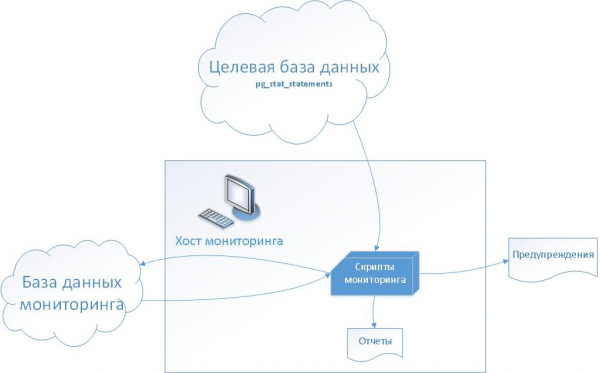
(Ilustração retirada do artigo «")
Explicação:
- O banco de dados de destino é instalado com a extensão padrão do PostgreSQL “pg_stat_statements”.
- No banco de dados de monitoramento, criamos um conjunto de tabelas de serviço para armazenar o histórico de pg_stat_statements no estágio inicial e para configurar métricas e monitoramento no futuro
- No host de monitoramento, criamos um conjunto de scripts bash, incluindo aqueles para geração de incidentes no sistema de tickets.
mesas de serviço
Para começar, um ERD esquematicamente simplificado, o que aconteceu no final:
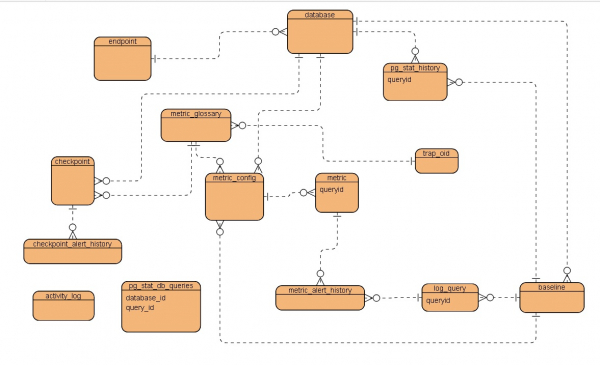
Breve descrição das tabelasPonto final - host, ponto de conexão com a instância
banco de dados - opções de banco de dados
pg_stat_history - uma tabela histórica para armazenar instantâneos temporários da exibição pg_stat_statements do banco de dados de destino
glossário_métrico - Dicionário de métricas de desempenho
metric_config - configuração de métricas individuais
métrico - uma métrica específica para a solicitação que está sendo monitorada
metric_alert_history - histórico de avisos de desempenho
log_query - tabela de serviço para armazenar registros analisados do arquivo de log do PostgreSQL baixado da AWS
baseline - parâmetros do período de tempo usado como base
ponto de verificação - configuração de métricas para verificar o status do banco de dados
checkpoint_alert_history - histórico de avisos de métricas de verificação de status do banco de dados
pg_stat_db_queries — tabela de serviço de requisições ativas
registro de atividade — tabela de serviço de log de atividades
trap_oid - tabela de serviço de configuração de trap
Estágio 1 - coletar estatísticas de desempenho e obter relatórios
Uma tabela é usada para armazenar informações estatísticas. pg_stat_history
estrutura da tabela pg_stat_history
Tabela "public.pg_stat_history" Coluna | tipo | Modificadores-------------------+--------------------- ---+---- -------------------------------- id | inteiro | não nulo padrão nextval('pg_stat_history_id_seq'::regclass) snapshot_timestamp | timestamp sem fuso horário | banco de dados_id | inteiro | dbid | oid | ID do usuário | oid | id da consulta | bigint | consulta | texto | chamadas | bigint | tempo_total | dupla precisão | min_time | dupla precisão | max_time | dupla precisão | tempo médio | dupla precisão | stddev_time | dupla precisão | linhas | bigint | shared_blks_hit | bigint | shared_blks_read | bigint | shared_blks_dirtied | bigint | shared_blks_write | bigint | local_blks_hit | bigint | local_blks_read | bigint | local_blks_dirtied | bigint | local_blks_write | bigint | temp_blks_read | bigint | temp_blks_escrito | bigint | blk_read_time | dupla precisão | blk_write_time | dupla precisão | baseline_id | inteiro | Índices: "pg_stat_history_pkey" PRIMARY KEY, btree (id) "database_idx" btree (database_id) "queryid_idx" btree (queryid) "snapshot_timestamp_idx" btree (snapshot_timestamp) Restrições de chave estrangeira: "database_id_fk" FOREIGN KEY (database_id) REFERENCES database(id) ) EM APAGAR CASCATAComo você pode ver, a tabela é apenas uma visão cumulativa de dados pg_stat_statements no banco de dados de destino.
A utilização desta mesa é muito simples.
pg_stat_history representará as estatísticas acumuladas de execução da consulta para cada hora. No início de cada hora, após o preenchimento da tabela, as estatísticas pg_stat_statements redefinir com pg_stat_statements_reset().
Nota: As estatísticas são coletadas para solicitações com duração superior a 1 segundo.
Preenchendo a tabela pg_stat_history
--pg_stat_history.sql
CREATE OR REPLACE FUNCTION pg_stat_history( ) RETURNS boolean AS $$
DECLARE
endpoint_rec record ;
database_rec record ;
pg_stat_snapshot record ;
current_snapshot_timestamp timestamp without time zone;
BEGIN
current_snapshot_timestamp = date_trunc('minute',now());
FOR endpoint_rec IN SELECT * FROM endpoint
LOOP
FOR database_rec IN SELECT * FROM database WHERE endpoint_id = endpoint_rec.id
LOOP
RAISE NOTICE 'NEW SHAPSHOT IS CREATING';
--Connect to the target DB
EXECUTE 'SELECT dblink_connect(''LINK1'',''host='||endpoint_rec.host||' dbname='||database_rec.name||' user=USER password=PASSWORD '')';
RAISE NOTICE 'host % and dbname % ',endpoint_rec.host,database_rec.name;
RAISE NOTICE 'Creating snapshot of pg_stat_statements for database %',database_rec.name;
SELECT
*
INTO
pg_stat_snapshot
FROM dblink('LINK1',
'SELECT
dbid , SUM(calls),SUM(total_time),SUM(rows) ,SUM(shared_blks_hit) ,SUM(shared_blks_read) ,SUM(shared_blks_dirtied) ,SUM(shared_blks_written) ,
SUM(local_blks_hit) , SUM(local_blks_read) , SUM(local_blks_dirtied) , SUM(local_blks_written) , SUM(temp_blks_read) , SUM(temp_blks_written) , SUM(blk_read_time) , SUM(blk_write_time)
FROM pg_stat_statements WHERE dbid=(SELECT oid from pg_database where datname=current_database() )
GROUP BY dbid
'
)
AS t
( dbid oid , calls bigint ,
total_time double precision ,
rows bigint , shared_blks_hit bigint , shared_blks_read bigint ,shared_blks_dirtied bigint ,shared_blks_written bigint ,
local_blks_hit bigint ,local_blks_read bigint , local_blks_dirtied bigint ,local_blks_written bigint ,
temp_blks_read bigint ,temp_blks_written bigint ,
blk_read_time double precision , blk_write_time double precision
);
INSERT INTO pg_stat_history
(
snapshot_timestamp ,database_id ,
dbid , calls ,total_time ,
rows ,shared_blks_hit ,shared_blks_read ,shared_blks_dirtied ,shared_blks_written ,local_blks_hit ,
local_blks_read,local_blks_dirtied,local_blks_written,temp_blks_read,temp_blks_written,
blk_read_time, blk_write_time
)
VALUES
(
current_snapshot_timestamp ,
database_rec.id ,
pg_stat_snapshot.dbid ,pg_stat_snapshot.calls,
pg_stat_snapshot.total_time,
pg_stat_snapshot.rows ,pg_stat_snapshot.shared_blks_hit ,pg_stat_snapshot.shared_blks_read ,pg_stat_snapshot.shared_blks_dirtied ,pg_stat_snapshot.shared_blks_written ,
pg_stat_snapshot.local_blks_hit , pg_stat_snapshot.local_blks_read , pg_stat_snapshot.local_blks_dirtied , pg_stat_snapshot.local_blks_written ,
pg_stat_snapshot.temp_blks_read , pg_stat_snapshot.temp_blks_written , pg_stat_snapshot.blk_read_time , pg_stat_snapshot.blk_write_time
);
RAISE NOTICE 'Creating snapshot of pg_stat_statements for queries with min_time more than 1000ms';
FOR pg_stat_snapshot IN
--All queries with max_time greater than 1000 ms
SELECT
*
FROM dblink('LINK1',
'SELECT
dbid , userid ,queryid,query,calls,total_time,min_time ,max_time,mean_time, stddev_time ,rows ,shared_blks_hit ,
shared_blks_read ,shared_blks_dirtied ,shared_blks_written ,
local_blks_hit , local_blks_read , local_blks_dirtied ,
local_blks_written , temp_blks_read , temp_blks_written , blk_read_time ,
blk_write_time
FROM pg_stat_statements
WHERE dbid=(SELECT oid from pg_database where datname=current_database() AND min_time >= 1000 )
'
)
AS t
( dbid oid , userid oid , queryid bigint ,query text , calls bigint ,
total_time double precision ,min_time double precision ,max_time double precision , mean_time double precision , stddev_time double precision ,
rows bigint , shared_blks_hit bigint , shared_blks_read bigint ,shared_blks_dirtied bigint ,shared_blks_written bigint ,
local_blks_hit bigint ,local_blks_read bigint , local_blks_dirtied bigint ,local_blks_written bigint ,
temp_blks_read bigint ,temp_blks_written bigint ,
blk_read_time double precision , blk_write_time double precision
)
LOOP
INSERT INTO pg_stat_history
(
snapshot_timestamp ,database_id ,
dbid ,userid , queryid , query , calls ,total_time ,min_time ,max_time ,mean_time ,stddev_time ,
rows ,shared_blks_hit ,shared_blks_read ,shared_blks_dirtied ,shared_blks_written ,local_blks_hit ,
local_blks_read,local_blks_dirtied,local_blks_written,temp_blks_read,temp_blks_written,
blk_read_time, blk_write_time
)
VALUES
(
current_snapshot_timestamp ,
database_rec.id ,
pg_stat_snapshot.dbid ,pg_stat_snapshot.userid ,pg_stat_snapshot.queryid,pg_stat_snapshot.query,pg_stat_snapshot.calls,
pg_stat_snapshot.total_time,pg_stat_snapshot.min_time ,pg_stat_snapshot.max_time,pg_stat_snapshot.mean_time, pg_stat_snapshot.stddev_time ,
pg_stat_snapshot.rows ,pg_stat_snapshot.shared_blks_hit ,pg_stat_snapshot.shared_blks_read ,pg_stat_snapshot.shared_blks_dirtied ,pg_stat_snapshot.shared_blks_written ,
pg_stat_snapshot.local_blks_hit , pg_stat_snapshot.local_blks_read , pg_stat_snapshot.local_blks_dirtied , pg_stat_snapshot.local_blks_written ,
pg_stat_snapshot.temp_blks_read , pg_stat_snapshot.temp_blks_written , pg_stat_snapshot.blk_read_time , pg_stat_snapshot.blk_write_time
);
END LOOP;
PERFORM dblink_disconnect('LINK1');
END LOOP ;--FOR database_rec IN SELECT * FROM database WHERE endpoint_id = endpoint_rec.id
END LOOP;
RETURN TRUE;
END
$$ LANGUAGE plpgsql;Como resultado, após um certo período de tempo na tabela pg_stat_history teremos um conjunto de instantâneos do conteúdo da tabela pg_stat_statements banco de dados de destino.
realmente relatando
Usando consultas simples, você pode obter relatórios bastante úteis e interessantes.
Dados agregados para um determinado período de tempo
Pedido
SELECT
database_id ,
SUM(calls) AS calls ,SUM(total_time) AS total_time ,
SUM(rows) AS rows , SUM(shared_blks_hit) AS shared_blks_hit,
SUM(shared_blks_read) AS shared_blks_read ,
SUM(shared_blks_dirtied) AS shared_blks_dirtied,
SUM(shared_blks_written) AS shared_blks_written ,
SUM(local_blks_hit) AS local_blks_hit ,
SUM(local_blks_read) AS local_blks_read ,
SUM(local_blks_dirtied) AS local_blks_dirtied ,
SUM(local_blks_written) AS local_blks_written,
SUM(temp_blks_read) AS temp_blks_read,
SUM(temp_blks_written) temp_blks_written ,
SUM(blk_read_time) AS blk_read_time ,
SUM(blk_write_time) AS blk_write_time
FROM
pg_stat_history
WHERE
queryid IS NULL AND
database_id = DATABASE_ID AND
snapshot_timestamp BETWEEN BEGIN_TIMEPOINT AND END_TIMEPOINT
GROUP BY database_id ;D.B. Hora
to_char(interval '1 milissegundo' * pg_total_stat_history_rec.total_time, 'HH24:MI:SS.MS')
Tempo de E/S
to_char(interval '1 milissegundo' * ( pg_total_stat_history_rec.blk_read_time + pg_total_stat_history_rec.blk_write_time ), 'HH24:MI:SS.MS')
TOP10 SQL por total_time
Pedido
SELECT
queryid ,
SUM(calls) AS calls ,
SUM(total_time) AS total_time
FROM
pg_stat_history
WHERE
queryid IS NOT NULL AND
database_id = DATABASE_ID AND
snapshot_timestamp BETWEEN BEGIN_TIMEPOINT AND END_TIMEPOINT
GROUP BY queryid
ORDER BY 3 DESC
LIMIT 10-------------------------------------------------- ------------------------------------ | SQL TOP10 POR TEMPO TOTAL DE EXECUÇÃO | #| id da consulta| chamadas| chamadas %| tempo_total (ms) | dbtime % +----+-----------+-----------+-----------+------ ---------------------+---------- | 1| 821760255| 2| .00001|00:03:23.141( 203141.681 ms.)| 5.42 | 2| 4152624390| 2| .00001|00:03:13.929( 193929.215 ms.)| 5.17 | 3| 1484454471| 4| .00001|00:02:09.129( 129129.057 ms.)| 3.44 | 4| 655729273| 1| .00000|00:02:01.869( 121869.981 ms.)| 3.25 | 5| 2460318461| 1| .00000|00:01:33.113( 93113.835 ms.)| 2.48 | 6| 2194493487| 4| .00001|00:00:17.377( 17377.868 ms.)| .46 | 7| 1053044345| 1| .00000|00:00:06.156( 6156.352 ms.)| .16 | 8| 3644780286| 1| .00000|00:00:01.063( 1063.830 ms.)| .03
TOP10 SQL por tempo total de E/S
Pedido
SELECT
queryid ,
SUM(calls) AS calls ,
SUM(blk_read_time + blk_write_time) AS io_time
FROM
pg_stat_history
WHERE
queryid IS NOT NULL AND
database_id = DATABASE_ID AND
snapshot_timestamp BETWEEN BEGIN_TIMEPOINT AND END_TIMEPOINT
GROUP BY queryid
ORDER BY 3 DESC
LIMIT 10-------------------------------------------------- -------------------------------------- | SQL TOP10 POR TEMPO TOTAL DE E/S | #| id da consulta| chamadas| chamadas %| Tempo de E/S (ms)|db Tempo de E/S % +----+-----------+-----------+------ -----+--------------------------------+----------- -- | 1| 4152624390| 2| .00001|00:08:31.616( 511616.592 ms.)| 31.06 de junho | 2| 821760255| 2| .00001|00:08:27.099( 507099.036 ms.)| 30.78 | 3| 655729273| 1| .00000|00:05:02.209( 302209.137 ms.)| 18.35h4 | 2460318461| 1| 00000| .00|04:05.981:245981.117( 14.93 ms.)| 5 | 1484454471| 4| 00001| .00|00:39.144:39144.221( 2.38 ms.)| 6 | 2194493487| 4| 00001| .00|00:18.182:18182.816( 1.10 ms.)| 7 | 1053044345| 1| 00000| .00|00:16.611:16611.722( 1.01 ms.)| 8 | 3644780286| 1| 00000| .00|00:00.436:436.205( 03 ms.)| .XNUMX
TOP10 SQL por tempo máximo de execução
Pedido
SELECT
id AS snapshotid ,
queryid ,
snapshot_timestamp ,
max_time
FROM
pg_stat_history
WHERE
queryid IS NOT NULL AND
database_id = DATABASE_ID AND
snapshot_timestamp BETWEEN BEGIN_TIMEPOINT AND END_TIMEPOINT
ORDER BY 4 DESC
LIMIT 10-------------------------------------------------- ------------------------------------ | SQL TOP10 POR TEMPO MÁXIMO DE EXECUÇÃO | #| instantâneo| ID do instantâneo| id da consulta| max_time (ms) +----+------------------+-----------+--------- ---+--------------------------------------- | 1| 05.04.2019/01/03 4169:655729273| 00| 02| 01.869:121869.981:2( 04.04.2019 ms.) | 17| 00/4153/821760255 00:01| 41.570| 101570.841| 3:04.04.2019:16( 00 ms.) | 4146| 821760255/00/01 41.570:101570.841| 4| 04.04.2019| 16:00:4144( 4152624390 ms.) | 00| 01/36.964/96964.607 5:04.04.2019| 17| 00| 4151:4152624390:00( 01 ms.) | 36.964| 96964.607/6/05.04.2019 10:00| 4188| 1484454471| 00:01:33.452( 93452.150 ms.) | 7| 04.04.2019/17/00 4150:2460318461 | 00| 01| 33.113:93113.835:8( 04.04.2019 ms.) | 15| 00/4140/1484454471 00:00| 11.892| 11892.302| 9:04.04.2019:16( 00 ms.) | 4145| 1484454471/00/00 11.892:11892.302| 10| 04.04.2019| 17:00:4152( 1484454471 ms.) | 00| 00/11.892/11892.302 XNUMX:XNUMX| XNUMX| XNUMX| XNUMX:XNUMX:XNUMX( XNUMX ms.) | XNUMX| XNUMX/XNUMX/XNUMX XNUMX:XNUMX| XNUMX| XNUMX| XNUMX:XNUMX:XNUMX(XNUMX ms.)
TOP10 SQL por leitura/gravação de buffer COMPARTILHADO
Pedido
SELECT
id AS snapshotid ,
queryid ,
snapshot_timestamp ,
shared_blks_read ,
shared_blks_written
FROM
pg_stat_history
WHERE
queryid IS NOT NULL AND
database_id = DATABASE_ID AND
snapshot_timestamp BETWEEN BEGIN_TIMEPOINT AND END_TIMEPOINT AND
( shared_blks_read > 0 OR shared_blks_written > 0 )
ORDER BY 4 DESC , 5 DESC
LIMIT 10-------------------------------------------------- ------------------------------------ | SQL TOP10 POR BUFFER COMPARTILHADO LEITURA/GRAVAÇÃO | #| instantâneo| ID do instantâneo| id da consulta| blocos compartilhados lidos| blocos compartilhados escrever +----+------------------+-----------+---------- -+---------------------+--------------------- | 1| 04.04.2019/17/00 4153:821760255| 797308| 0| 2| 04.04.2019 | 16| 00/4146/821760255 797308:0| 3| 05.04.2019| 01| 03 | 4169| 655729273/797158/0 4:04.04.2019| 16| 00| 4144| 4152624390 | 756514| 0/5/04.04.2019 17:00| 4151| 4152624390| 756514| 0 | 6| 04.04.2019/17/00 4150:2460318461| 734117| 0| 7| 04.04.2019 | 17| 00/4155/3644780286 52973:0| 8| 05.04.2019| 01| 03 | 4168| 1053044345/52818/0 9:04.04.2019| 15| 00| 4141| 2194493487 | 52813| 0/10/04.04.2019 16:00| 4147| 2194493487| 52813| 0 | XNUMX| XNUMX/XNUMX/XNUMX XNUMX:XNUMX| XNUMX| XNUMX| XNUMX| XNUMX | XNUMX| XNUMX/XNUMX/XNUMX XNUMX:XNUMX| XNUMX| XNUMX| XNUMX| XNUMX -------------------------------------------------- --------------------------------------------------
Histograma de distribuição de consultas por tempo máximo de execução
pedidos
SELECT
MIN(max_time) AS hist_min ,
MAX(max_time) AS hist_max ,
(( MAX(max_time) - MIN(min_time) ) / hist_columns ) as hist_width
FROM
pg_stat_history
WHERE
queryid IS NOT NULL AND
database_id = DATABASE_ID AND
snapshot_timestamp BETWEEN BEGIN_TIMEPOINT AND END_TIMEPOINT ;
SELECT
SUM(calls) AS calls
FROM
pg_stat_history
WHERE
queryid IS NOT NULL AND
database_id =DATABASE_ID AND
snapshot_timestamp BETWEEN BEGIN_TIMEPOINT AND END_TIMEPOINT AND
( max_time >= hist_current_min AND max_time < hist_current_max ) ;
|------------------------------------------------- ---------------------------------------- | HISTOGRAMA MAX_TIME | TOTAL DE CHAMADAS: 33851920 | TEMPO MÍN: 00:00:01.063 | TEMPO MÁX: 00:02:01.869 ---------------------------------- -------- ----------------------- | duração mínima| duração máxima| chamadas +--------------------------------+------------- ---------------------+---------- | 00:00:01.063( 1063.830 ms.) | 00:00:13.144( 13144.445 ms.) | 9 | 00:00:13.144( 13144.445 ms.) | 00:00:25.225( 25225.060 ms.) | 0 | 00:00:25.225( 25225.060 ms.) | 00:00:37.305( 37305.675 ms.) | 0 | 00:00:37.305( 37305.675 ms.) | 00:00:49.386( 49386.290 ms.) | 0 | 00:00:49.386( 49386.290 ms.) | 00:01:01.466( 61466.906 ms.) | 0 | 00:01:01.466( 61466.906 ms.) | 00:01:13.547(73547.521 ms.) | 0 | 00:01:13.547(73547.521 ms.) | 00:01:25.628( 85628.136 ms.) | 0 | 00:01:25.628( 85628.136 ms.) | 00:01:37.708( 97708.751 ms.) | 4 | 00:01:37.708( 97708.751 ms.) | 00:01:49.789( 109789.366 ms.) | 2 | 00:01:49.789( 109789.366 ms.) | 00:02:01.869( 121869.981 ms.) | 0
Os 10 melhores instantâneos por consulta por segundo
pedidos
--pg_qps.sql
--Calculate Query Per Second
CREATE OR REPLACE FUNCTION pg_qps( pg_stat_history_id integer ) RETURNS double precision AS $$
DECLARE
pg_stat_history_rec record ;
prev_pg_stat_history_id integer ;
prev_pg_stat_history_rec record;
total_seconds double precision ;
result double precision;
BEGIN
result = 0 ;
SELECT *
INTO pg_stat_history_rec
FROM
pg_stat_history
WHERE id = pg_stat_history_id ;
IF pg_stat_history_rec.snapshot_timestamp IS NULL
THEN
RAISE EXCEPTION 'ERROR - Not found pg_stat_history for id = %',pg_stat_history_id;
END IF ;
--RAISE NOTICE 'pg_stat_history_id = % , snapshot_timestamp = %', pg_stat_history_id ,
pg_stat_history_rec.snapshot_timestamp ;
SELECT
MAX(id)
INTO
prev_pg_stat_history_id
FROM
pg_stat_history
WHERE
database_id = pg_stat_history_rec.database_id AND
queryid IS NULL AND
id < pg_stat_history_rec.id ;
IF prev_pg_stat_history_id IS NULL
THEN
RAISE NOTICE 'Not found previous pg_stat_history shapshot for id = %',pg_stat_history_id;
RETURN NULL ;
END IF;
SELECT *
INTO prev_pg_stat_history_rec
FROM
pg_stat_history
WHERE id = prev_pg_stat_history_id ;
--RAISE NOTICE 'prev_pg_stat_history_id = % , prev_snapshot_timestamp = %', prev_pg_stat_history_id , prev_pg_stat_history_rec.snapshot_timestamp ;
total_seconds = extract(epoch from ( pg_stat_history_rec.snapshot_timestamp - prev_pg_stat_history_rec.snapshot_timestamp ));
--RAISE NOTICE 'total_seconds = % ', total_seconds ;
--RAISE NOTICE 'calls = % ', pg_stat_history_rec.calls ;
IF total_seconds > 0
THEN
result = pg_stat_history_rec.calls / total_seconds ;
ELSE
result = 0 ;
END IF;
RETURN result ;
END
$$ LANGUAGE plpgsql;
SELECT
id ,
snapshot_timestamp ,
calls ,
total_time ,
( select pg_qps( id )) AS QPS ,
blk_read_time ,
blk_write_time
FROM
pg_stat_history
WHERE
queryid IS NULL AND
database_id = DATABASE_ID AND
snapshot_timestamp BETWEEN BEGIN_TIMEPOINT AND END_TIMEPOINT AND
( select pg_qps( id )) IS NOT NULL
ORDER BY 5 DESC
LIMIT 10
|------------------------------------------------- ---------------------------------------- | TOP10 Instantâneos ordenados por números QueryPerSeconds -------------------------------------- ------ -------------------------------------------- ------ ------------------------------------------- | #| instantâneo| ID do instantâneo| chamadas| dbtime total| QPS | tempo de E/S | Tempo de E/S % +-----+------------------+-----------+------- ----+---------------------------------+---------- -+---------------------------------+----------- | 1| 04.04.2019/20/04 4161:5758631| 00| 06| 30.513:390513.926:1573.396(00 ms.)| 00| 01.470:1470.110:376( 2 ms.)| .04.04.2019 | 17| 00/4149/3529197 00:11| 48.830| 708830.618| 980.332:00:12(47.834 ms.)| 767834.052| 108.324:3:04.04.2019(16 ms.)| 00 | 4143| 3525360/00/10 13.492:613492.351| 979.267| 00| 08:41.396:521396.555( 84.988 ms.)| 4| 04.04.2019:21:03( 4163ms.)| 2781536 | 00| 03/06.470/186470.979 785.745:00| 00| 00.249| 249.865:134:5( 04.04.2019ms.)| 19| 03:4159:2890362( 00 ms.)| .03 | 16.784| 196784.755/776.979/00 00:01.441| 1441.386| 732| 6:04.04.2019:14( 00 ms.)| 4137| 2397326:00:04( 43.033 ms.)| .283033.854 | 665.924| 00/00/00.024 24.505:009 | 7| 04.04.2019| 15:00:4139( 2394416ms.)| 00| 04:51.435:291435.010( 665.116 ms.)| .00 | 00| 12.025/12025.895/4.126 8:04.04.2019| 13| 00| 4135:2373043:00( 04 ms.)| 26.791| 266791.988:659.179:00( 00 ms.)| 00.064 | 64.261| 024/9/05.04.2019 01:03| 4167| 4387191| 00:06:51.380( 411380.293 ms.)| 609.332| 00:05:18.847( 318847.407 ms.)| .77.507 | 10| 04.04.2019/18/01 4157:1145596| 00| 01| 19.217:79217.372:313.004(00 ms.)| 00| 01.319:1319.676:1.666(XNUMX ms.)| XNUMX | XNUMX| XNUMX/XNUMX/XNUMX XNUMX:XNUMX| XNUMX| XNUMX| XNUMX:XNUMX:XNUMX(XNUMX ms.)| XNUMX| XNUMX:XNUMX:XNUMX( XNUMX ms.)| XNUMX
Histórico de execução por hora com QueryPerSeconds e tempo de E/S
Pedido
SELECT
id ,
snapshot_timestamp ,
calls ,
total_time ,
( select pg_qps( id )) AS QPS ,
blk_read_time ,
blk_write_time
FROM
pg_stat_history
WHERE
queryid IS NULL AND
database_id = DATABASE_ID AND
snapshot_timestamp BETWEEN BEGIN_TIMEPOINT AND END_TIMEPOINT
ORDER BY 2
|----------------------------------------------------------------------------------------------- | HOURLY EXECUTION HISTORY WITH QueryPerSeconds and I/O Time ----------------------------------------------------------------------------------------------------------------------------------------------- | QUERY PER SECOND HISTORY | #| snapshot| snapshotID| calls| total dbtime| QPS| I/O time| I/O time % +-----+------------------+-----------+-----------+----------------------------------+-----------+----------------------------------+----------- | 1| 04.04.2019 11:00| 4131| 3747| 00:00:00.835( 835.374 ms.)| 1.041| 00:00:00.000( .000 ms.)| .000 | 2| 04.04.2019 12:00| 4133| 1002722| 00:01:52.419( 112419.376 ms.)| 278.534| 00:00:00.149( 149.105 ms.)| .133 | 3| 04.04.2019 13:00| 4135| 2373043| 00:04:26.791( 266791.988 ms.)| 659.179| 00:00:00.064( 64.261 ms.)| .024 | 4| 04.04.2019 14:00| 4137| 2397326| 00:04:43.033( 283033.854 ms.)| 665.924| 00:00:00.024( 24.505 ms.)| .009 | 5| 04.04.2019 15:00| 4139| 2394416| 00:04:51.435( 291435.010 ms.)| 665.116| 00:00:12.025( 12025.895 ms.)| 4.126 | 6| 04.04.2019 16:00| 4143| 3525360| 00:10:13.492( 613492.351 ms.)| 979.267| 00:08:41.396( 521396.555 ms.)| 84.988 | 7| 04.04.2019 17:00| 4149| 3529197| 00:11:48.830( 708830.618 ms.)| 980.332| 00:12:47.834( 767834.052 ms.)| 108.324 | 8| 04.04.2019 18:01| 4157| 1145596| 00:01:19.217( 79217.372 ms.)| 313.004| 00:00:01.319( 1319.676 ms.)| 1.666 | 9| 04.04.2019 19:03| 4159| 2890362| 00:03:16.784( 196784.755 ms.)| 776.979| 00:00:01.441( 1441.386 ms.)| .732 | 10| 04.04.2019 20:04| 4161| 5758631| 00:06:30.513( 390513.926 ms.)| 1573.396| 00:00:01.470( 1470.110 ms.)| .376 | 11| 04.04.2019 21:03| 4163| 2781536| 00:03:06.470( 186470.979 ms.)| 785.745| 00:00:00.249( 249.865 ms.)| .134 | 12| 04.04.2019 23:03| 4165| 1443155| 00:01:34.467( 94467.539 ms.)| 200.438| 00:00:00.015( 15.287 ms.)| .016 | 13| 05.04.2019 01:03| 4167| 4387191| 00:06:51.380( 411380.293 ms.)| 609.332| 00:05:18.847( 318847.407 ms.)| 77.507 | 14| 05.04.2019 02:03| 4171| 189852| 00:00:10.989( 10989.899 ms.)| 52.737| 00:00:00.539( 539.110 ms.)| 4.906 | 15| 05.04.2019 03:01| 4173| 3627| 00:00:00.103( 103.000 ms.)| 1.042| 00:00:00.004( 4.131 ms.)| 4.010 | 16| 05.04.2019 04:00| 4175| 3627| 00:00:00.085( 85.235 ms.)| 1.025| 00:00:00.003( 3.811 ms.)| 4.471 | 17| 05.04.2019 05:00| 4177| 3747| 00:00:00.849( 849.454 ms.)| 1.041| 00:00:00.006( 6.124 ms.)| .721 | 18| 05.04.2019 06:00| 4179| 3747| 00:00:00.849( 849.561 ms.)| 1.041| 00:00:00.000( .051 ms.)| .006 | 19| 05.04.2019 07:00| 4181| 3747| 00:00:00.839( 839.416 ms.)| 1.041| 00:00:00.000( .062 ms.)| .007 | 20| 05.04.2019 08:00| 4183| 3747| 00:00:00.846( 846.382 ms.)| 1.041| 00:00:00.000( .007 ms.)| .001 | 21| 05.04.2019 09:00| 4185| 3747| 00:00:00.855( 855.426 ms.)| 1.041| 00:00:00.000( .065 ms.)| .008 | 22| 05.04.2019 10:00| 4187| 3797| 00:01:40.150( 100150.165 ms.)| 1.055| 00:00:21.845( 21845.217 ms.)| 21.812
Texto de todas as seleções SQL
Pedido
SELECT
queryid ,
query
FROM
pg_stat_history
WHERE
queryid IS NOT NULL AND
database_id = DATABASE_ID AND
snapshot_timestamp BETWEEN BEGIN_TIMEPOINT AND END_TIMEPOINT
GROUP BY queryid , query
Total
Como você pode ver, por meios bastante simples, você pode obter muitas informações úteis sobre a carga de trabalho e o estado do banco de dados.
Nota:Se você corrigir o queryid nas consultas, obteremos o histórico de uma solicitação separada (para economizar espaço, os relatórios de uma solicitação separada são omitidos).
Portanto, dados estatísticos sobre o desempenho da consulta estão disponíveis e coletados.
A primeira fase "recolha de dados estatísticos" está concluída.
Você pode prosseguir para o segundo estágio - "configurar métricas de desempenho".

Mas esta é uma história completamente diferente.
Para ser continuado ...
Fonte: habr.com
