

Olá a todos! Meu nome é Golov Nikolai. Anteriormente trabalhei na Avito e gerenciei a Plataforma de Dados por seis anos, ou seja, atuei em todos os bancos de dados: analítico (Vertica, ClickHouse), streaming e OLTP (Redis, Tarantool, VoltDB, MongoDB, PostgreSQL). Durante esse tempo, lidei com um grande número de bancos de dados - muito diferentes e inusitados, e com casos atípicos de seu uso.
Atualmente estou trabalhando no ManyChat. Em essência, esta é uma startup - nova, ambiciosa e em rápido crescimento. E quando entrei na empresa, surgiu uma pergunta clássica: “O que uma jovem startup deve tirar agora do mercado de SGBD e banco de dados?”
Neste artigo, baseado em meu relatório em , vou responder a esta pergunta. Uma versão em vídeo do relatório está disponível em .
Bancos de dados comumente conhecidos 2020
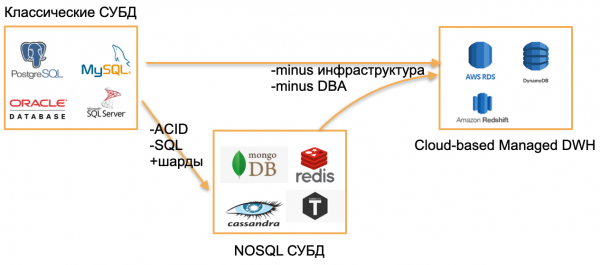
Estamos em 2020, olhei em volta e vi três tipos de bancos de dados.
Primeiro tipo - bancos de dados OLTP clássicos: PostgreSQL, SQL Server, Oracle, MySQL. Eles foram escritos há muito tempo, mas ainda são relevantes porque são muito familiares à comunidade de desenvolvedores.
O segundo tipo é bases de "zero". Eles tentaram se afastar dos padrões clássicos abandonando o SQL, as estruturas tradicionais e o ACID, adicionando sharding integrado e outros recursos atraentes. Por exemplo, este é Cassandra, MongoDB, Redis ou Tarantool. Todas estas soluções pretendiam oferecer ao mercado algo fundamentalmente novo e ocuparam o seu nicho porque se revelaram extremamente convenientes para determinadas tarefas. Irei denotar esses bancos de dados com o termo genérico NOSQL.
Os “zeros” acabaram, nos acostumamos com os bancos de dados NOSQL, e o mundo, do meu ponto de vista, deu o próximo passo - para bancos de dados gerenciados. Esses bancos de dados têm o mesmo núcleo dos bancos de dados OLTP clássicos ou dos novos bancos NoSQL. Mas eles não precisam de DBA e DevOps e são executados em hardware gerenciado nas nuvens. Para um desenvolvedor, isso é “apenas uma base” que funciona em algum lugar, mas ninguém se importa como está instalado no servidor, quem configurou o servidor e quem o atualiza.
Exemplos de tais bancos de dados:
- AWS RDS é um wrapper gerenciado para PostgreSQL/MySQL.
- DynamoDB é um análogo AWS de um banco de dados baseado em documentos, semelhante ao Redis e MongoDB.
- Amazon Redshift é um banco de dados analítico gerenciado.
São basicamente bancos de dados antigos, mas criados em ambiente gerenciado, sem a necessidade de trabalhar com hardware.
Observação. Os exemplos são usados para o ambiente AWS, mas seus análogos também existem no Microsoft Azure, Google Cloud ou Yandex.Cloud.
O que há de novo nisso? Em 2020, nada disso.
Conceito sem servidor
O que realmente há de novo no mercado em 2020 são as soluções serverless ou serverless.
Tentarei explicar o que isso significa usando o exemplo de um serviço regular ou aplicativo de back-end.
Para implantar um aplicativo de back-end regular, compramos ou alugamos um servidor, copiamos o código nele, publicamos o endpoint externamente e pagamos regularmente aluguel, eletricidade e serviços de data center. Este é o esquema padrão.
Existe alguma outra maneira? Com serviços sem servidor você pode.
Qual é o foco dessa abordagem: não existe servidor, não existe nem aluguel de instância virtual na nuvem. Para implantar o serviço, copie o código (funções) para o repositório e publique-o no endpoint. Então simplesmente pagamos por cada chamada a esta função, ignorando completamente o hardware onde ela é executada.
Tentarei ilustrar essa abordagem com fotos.
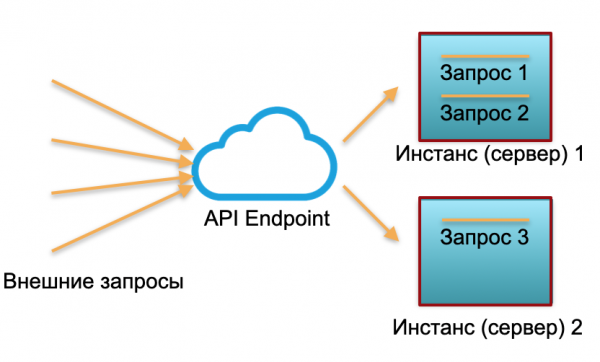
Implantação clássica. Temos um serviço com uma determinada carga. Levantamos duas instâncias: servidores físicos ou instâncias em AWS. As solicitações externas são enviadas para essas instâncias e ali processadas.
Como você pode ver na imagem, os servidores não são distribuídos de forma igual. Um está 100% utilizado, há duas solicitações e um está apenas 50% - parcialmente ocioso. Se não chegarem três solicitações, mas 30, todo o sistema não será capaz de lidar com a carga e começará a desacelerar.
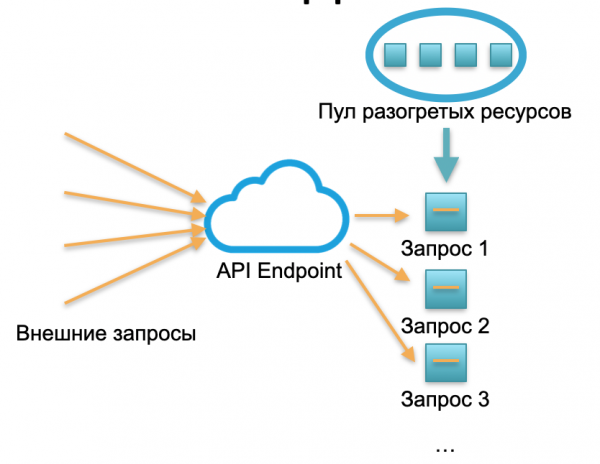
Implantação sem servidor. Em um ambiente sem servidor, tal serviço não possui instâncias ou servidores. Há um certo conjunto de recursos aquecidos - pequenos contêineres Docker preparados com código de função implantado. O sistema recebe solicitações externas e para cada uma delas o framework serverless levanta um pequeno contêiner com código: ele processa essa solicitação específica e mata o contêiner.
Uma solicitação - um contêiner levantado, 1000 solicitações - 1000 contêineres. E a implantação em servidores de hardware já é trabalho do provedor de nuvem. Está completamente oculto pela estrutura sem servidor. Neste conceito pagamos por cada chamada. Por exemplo, recebia uma ligação por dia - pagamos por uma ligação, recebia um milhão por minuto - pagamos por um milhão. Ou num segundo, isso também acontece.
O conceito de publicação de uma função sem servidor é adequado para um serviço sem estado. E se você precisar de um serviço statefull (estado), adicionamos um banco de dados ao serviço. Nesse caso, quando se trata de trabalhar com estado, cada função statefull simplesmente escreve e lê no banco de dados. Além disso, a partir de uma base de dados de qualquer um dos três tipos descritos no início do artigo.
Qual é a limitação comum de todos esses bancos de dados? Esses são os custos de um servidor de nuvem ou hardware usado constantemente (ou vários servidores). Não importa se usamos um banco de dados clássico ou gerenciado, se temos Devops e um administrador ou não, ainda pagamos pelo aluguel de hardware, eletricidade e data center 24 horas por dia, 7 dias por semana. Se tivermos uma base clássica, pagamos por mestre e escravo. Se for um banco de dados fragmentado altamente carregado, pagamos por 10, 20 ou 30 servidores e pagamos constantemente.
A presença de servidores permanentemente reservados na estrutura de custos era anteriormente percebida como um mal necessário. Os bancos de dados convencionais também apresentam outras dificuldades, como limites no número de conexões, restrições de escala, consenso geo-distribuído - podem de alguma forma ser resolvidos em determinados bancos de dados, mas não todos de uma vez e não de forma ideal.
Banco de dados sem servidor – teoria
Pergunta de 2020: é possível tornar um banco de dados sem servidor também? Todo mundo já ouviu falar sobre backend serverless... vamos tentar tornar o banco de dados serverless?
Isso parece estranho, porque o banco de dados é um serviço statefull, não muito adequado para infraestrutura sem servidor. Ao mesmo tempo, o estado do banco de dados é muito grande: gigabytes, terabytes e, em bancos de dados analíticos, até petabytes. Não é tão fácil criá-lo em contêineres Docker leves.
Por outro lado, quase todos os bancos de dados modernos contêm uma enorme quantidade de lógica e componentes: transações, coordenação de integridade, procedimentos, dependências relacionais e muita lógica. Para muita lógica de banco de dados, um estado pequeno é suficiente. Gigabytes e Terabytes são usados diretamente por apenas uma pequena parte da lógica do banco de dados envolvida na execução direta de consultas.
Assim, a ideia é: se parte da lógica permite a execução sem estado, por que não dividir a base em partes com estado e sem estado?
Sem servidor para soluções OLAP
Vamos ver como seria dividir um banco de dados em partes com e sem estado usando exemplos práticos.
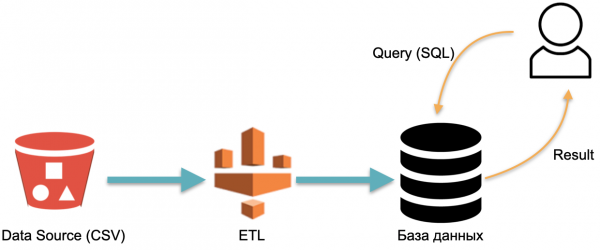
Por exemplo, temos um banco de dados analítico: dados externos (cilindro vermelho à esquerda), um processo ETL que carrega dados no banco de dados e um analista que envia consultas SQL ao banco de dados. Este é um esquema clássico de operação de data warehouse.
Neste esquema, o ETL é executado condicionalmente uma vez. Então você precisa pagar constantemente pelos servidores nos quais o banco de dados é executado com dados preenchidos com ETL, para que haja algo para onde enviar consultas.
Vejamos uma abordagem alternativa implementada no AWS Athena Serverless. Não há hardware permanentemente dedicado no qual os dados baixados sejam armazenados. Em vez disso:
- O usuário envia uma consulta SQL ao Athena. O otimizador Athena analisa a consulta SQL e pesquisa no armazenamento de metadados (Metadados) os dados específicos necessários para executar a consulta.
- O otimizador, com base nos dados coletados, baixa os dados necessários de fontes externas para o armazenamento temporário (banco de dados temporário).
- Uma consulta SQL do usuário é executada no armazenamento temporário e o resultado é retornado ao usuário.
- O armazenamento temporário é limpo e os recursos são liberados.
Nesta arquitetura, pagamos apenas pelo processo de execução da solicitação. Sem solicitações - sem custos.
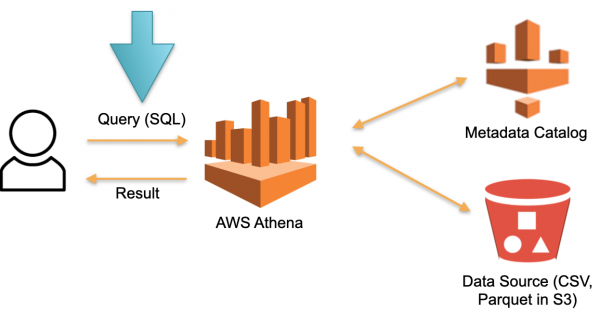
Esta é uma abordagem funcional e é implementada não apenas no Athena Serverless, mas também no Redshift Spectrum (na AWS).
O exemplo do Athena mostra que o banco de dados Serverless funciona em consultas reais com dezenas e centenas de Terabytes de dados. Centenas de Terabytes exigirão centenas de servidores, mas não precisamos pagar por eles – pagamos pelas solicitações. A velocidade de cada solicitação é (muito) baixa em comparação com bancos de dados analíticos especializados como o Vertica, mas não pagamos por períodos de inatividade.
Esse banco de dados é aplicável para consultas analíticas ad hoc raras. Por exemplo, quando decidimos espontaneamente testar uma hipótese sobre uma quantidade gigantesca de dados. Athena é perfeita para esses casos. Para solicitações regulares, esse sistema é caro. Nesse caso, armazene os dados em cache em alguma solução especializada.
Sem servidor para soluções OLTP
O exemplo anterior analisou tarefas OLAP (analíticas). Agora vamos dar uma olhada nas tarefas OLTP.
Vamos imaginar PostgreSQL ou MySQL escalável. Vamos criar uma instância gerenciada regular PostgreSQL ou MySQL com recursos mínimos. Quando a instância receber mais carga, conectaremos réplicas adicionais às quais distribuiremos parte da carga de leitura. Se não houver solicitações ou carga, desligamos as réplicas. A primeira instância é a mestre e as demais são réplicas.
Essa ideia é implementada em um banco de dados chamado Aurora Serverless AWS. O princípio é simples: as solicitações de aplicativos externos são aceitas pela frota proxy. Vendo o aumento da carga, ele aloca recursos computacionais de instâncias mínimas pré-aquecidas - a conexão é feita o mais rápido possível. A desativação de instâncias ocorre da mesma maneira.
Dentro do Aurora existe o conceito de Aurora Capacity Unit, ACU. Esta é (condicionalmente) uma instância (servidor). Cada ACU específica pode ser mestre ou escrava. Cada Unidade de Capacidade possui sua própria RAM, processador e disco mínimo. Conseqüentemente, um é mestre, o restante são réplicas somente leitura.
O número dessas unidades de capacidade do Aurora em execução é um parâmetro configurável. A quantidade mínima pode ser um ou zero (neste caso o banco de dados não funciona se não houver solicitações).
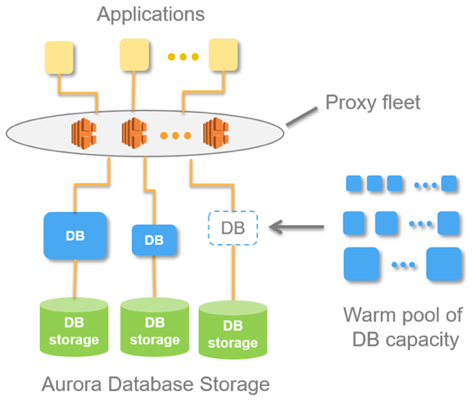
Quando a base recebe solicitações, a frota proxy aumenta o Aurora CapacityUnits, aumentando os recursos de desempenho do sistema. A capacidade de aumentar e diminuir recursos permite ao sistema “fazer malabarismos” com recursos: exibir automaticamente ACUs individuais (substituindo-as por novas) e implementar todas as atualizações atuais para os recursos retirados.
A base Aurora Serverless pode dimensionar a carga de leitura. Mas a documentação não diz isso diretamente. Pode parecer que eles conseguem levantar um multi-master. Não há mágica.
Este banco de dados é adequado para evitar gastos enormes em sistemas com acesso imprevisível. Por exemplo, ao criar sites MVP ou de marketing de cartões de visita, geralmente não esperamos uma carga estável. Assim, se não houver acesso, não pagamos pelas instâncias. Quando ocorre uma carga inesperada, por exemplo, após uma conferência ou campanha publicitária, multidões de pessoas visitam o site e a carga aumenta drasticamente, o Aurora Serverless pega automaticamente essa carga e conecta rapidamente os recursos ausentes (ACU). Aí a conferência passa, todos se esquecem do protótipo, os servidores (ACU) desligam e os custos caem a zero - conveniente.
Esta solução não é adequada para alta carga estável porque não dimensiona a carga de gravação. Todas essas conexões e desconexões de recursos ocorrem no chamado “ponto de escala” - um momento em que o banco de dados não é suportado por uma transação ou tabelas temporárias. Por exemplo, dentro de uma semana o ponto de escala pode não acontecer, e a base funciona com os mesmos recursos e simplesmente não pode expandir ou contrair.
Não há mágica - é o PostgreSQL normal. Mas o processo de adicionar máquinas e desconectá-las é parcialmente automatizado.
Sem servidor por design
Aurora Serverless é um banco de dados antigo reescrito para a nuvem para aproveitar alguns dos benefícios do Serverless. E agora vou falar sobre a base, que foi originalmente escrita para a nuvem, para a abordagem sem servidor - Serverless-by-design. Foi imediatamente desenvolvido sem a suposição de que funcionaria em servidores físicos.
Essa base é chamada de floco de neve. Possui três blocos principais.
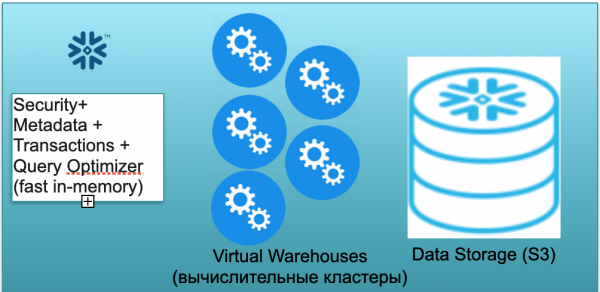
O primeiro é um bloco de metadados. Este é um serviço rápido na memória que resolve problemas de segurança, metadados, transações e otimização de consultas (mostrado na ilustração à esquerda).
O segundo bloco é um conjunto de clusters de computação virtual para cálculos (na ilustração há um conjunto de círculos azuis).
O terceiro bloco é um sistema de armazenamento de dados baseado em S3. S3 é um armazenamento de objetos adimensionais na AWS, uma espécie de Dropbox adimensional para empresas.
Vamos ver como o Snowflake funciona, assumindo uma inicialização a frio. Ou seja, existe um banco de dados, os dados são carregados nele, não há consultas em execução. Assim, se não houver solicitações ao banco de dados, acionamos o serviço rápido de metadados na memória (primeiro bloco). E temos o armazenamento S3, onde são armazenados os dados da tabela, divididos nas chamadas micropartições. Para simplificar: se a tabela contém transações, então as micropartições são os dias das transações. Cada dia é uma micropartição separada, um arquivo separado. E quando o banco de dados opera neste modo, você paga apenas pelo espaço ocupado pelos dados. Além disso, a taxa por assento é muito baixa (especialmente tendo em conta a compressão significativa). O serviço de metadados também funciona constantemente, mas não são necessários muitos recursos para otimizar as consultas, e o serviço pode ser considerado shareware.
Agora vamos imaginar que um usuário acessou nosso banco de dados e enviou uma consulta SQL. A consulta SQL é enviada imediatamente ao serviço de metadados para processamento. Assim, ao receber um pedido, este serviço analisa o pedido, os dados disponíveis, as permissões do utilizador e, se tudo correr bem, traça um plano de processamento do pedido.
Em seguida, o serviço inicia o lançamento do cluster de computação. Um cluster de computação é um cluster de servidores que realizam cálculos. Ou seja, este é um cluster que pode conter 1 servidor, 2 servidores, 4, 8, 16, 32 - quantos você quiser. Você lança uma solicitação e a inicialização deste cluster começa imediatamente. Realmente leva segundos.
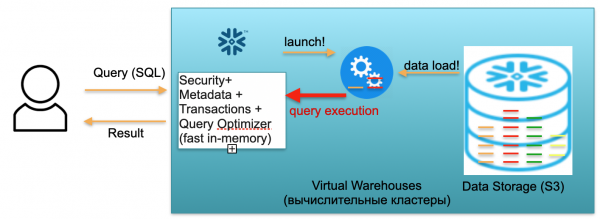
Em seguida, após o início do cluster, as micropartições necessárias para processar sua solicitação começam a ser copiadas do S3 para o cluster. Ou seja, vamos imaginar que para executar uma consulta SQL você precisa de duas partições de uma tabela e uma da segunda. Neste caso, apenas as três partições necessárias serão copiadas para o cluster, e não todas as tabelas inteiramente. É por isso que, e precisamente porque tudo está localizado dentro de um data center e conectado por canais muito rápidos, todo o processo de transferência ocorre muito rapidamente: em segundos, muito raramente em minutos, a menos que estejamos falando de algumas solicitações monstruosas. Conseqüentemente, as micropartições são copiadas para o cluster de computação e, após a conclusão, a consulta SQL é executada neste cluster de computação. O resultado dessa solicitação pode ser uma linha, várias linhas ou uma tabela – elas são enviadas externamente ao usuário para que ele possa baixá-las, exibi-las em sua ferramenta de BI ou utilizá-las de alguma outra forma.
Cada consulta SQL pode não apenas ler agregados de dados carregados anteriormente, mas também carregar/gerar novos dados no banco de dados. Ou seja, pode ser uma consulta que, por exemplo, insere novos registros em outra tabela, o que leva ao aparecimento de uma nova partição no cluster computacional, que, por sua vez, é salva automaticamente em um único armazenamento S3.
O cenário descrito acima, desde a chegada do usuário até o levantamento do cluster, carregamento de dados, execução de consultas, obtenção de resultados, é pago à taxa por minutos de utilização do cluster de computação virtual levantado, armazém virtual. A taxa varia dependendo da zona AWS e do tamanho do cluster, mas em média é de alguns dólares por hora. Um cluster de quatro máquinas é duas vezes mais caro que um cluster de duas máquinas, e um cluster de oito máquinas ainda é duas vezes mais caro. Estão disponíveis opções de 16, 32 máquinas, dependendo da complexidade das solicitações. Mas você paga apenas pelos minutos em que o cluster está realmente em execução, porque quando não há solicitações, você meio que tira as mãos e, após 5 a 10 minutos de espera (um parâmetro configurável), ele dispara sozinho, libere recursos e torne-se livre.
Um cenário completamente realista é quando você envia uma requisição, o cluster aparece, relativamente falando, em um minuto, ele conta mais um minuto, depois cinco minutos para desligar, e você acaba pagando por sete minutos de operação desse cluster, e não por meses e anos.
O primeiro cenário descreveu o uso do Snowflake em uma configuração de usuário único. Agora vamos imaginar que existem muitos usuários, o que está mais próximo do cenário real.
Digamos que temos muitos analistas e relatórios do Tableau que bombardeiam constantemente nosso banco de dados com um grande número de consultas SQL analíticas simples.
Além disso, digamos que temos Cientistas de Dados inventivos que estão tentando fazer coisas monstruosas com dados, operar com dezenas de Terabytes, analisar bilhões e trilhões de linhas de dados.
Para os dois tipos de carga de trabalho descritos acima, o Snowflake permite criar vários clusters de computação independentes de diferentes capacidades. Além disso, esses clusters computacionais funcionam de forma independente, mas com dados comuns consistentes.
Para um grande número de consultas leves, você pode criar de 2 a 3 pequenos clusters, com aproximadamente 2 máquinas cada. Este comportamento pode ser implementado, entre outras coisas, através de configurações automáticas. Então você diz: “Floco de neve, crie um pequeno cacho. Se a carga aumentar acima de um determinado parâmetro, aumente um segundo, terceiro semelhante. Quando a carga começar a diminuir, apague o excesso.” Para que não importa quantos analistas venham e comecem a analisar os relatórios, todos tenham recursos suficientes.
Ao mesmo tempo, se os analistas estiverem dormindo e ninguém olhar os relatórios, os clusters podem ficar completamente escuros e você deixará de pagar por eles.
Ao mesmo tempo, para consultas pesadas (de cientistas de dados), você pode criar um cluster muito grande para 32 máquinas. Este cluster também será pago apenas pelos minutos e horas em que sua solicitação gigante estiver sendo executada lá.
A oportunidade descrita acima permite dividir não apenas 2, mas também mais tipos de carga de trabalho em clusters (ETL, monitoramento, materialização de relatórios,...).
Vamos resumir o floco de neve. A base combina uma bela ideia e uma implementação viável. No ManyChat, usamos o Snowflake para analisar todos os dados que temos. Não temos três clusters, como no exemplo, mas sim de 5 a 9, de tamanhos diferentes. Temos convencionais de 16 máquinas, 2 máquinas e também superpequenos de 1 máquina para algumas tarefas. Eles distribuem a carga com sucesso e nos permitem economizar muito.
O banco de dados dimensiona com êxito a carga de leitura e gravação. Esta é uma grande diferença e um grande avanço em relação ao mesmo “Aurora”, que carregava apenas a carga de leitura. Snowflake permite dimensionar sua carga de trabalho de escrita com esses clusters de computação. Ou seja, como mencionei, usamos vários clusters no ManyChat, clusters pequenos e superpequenos são usados principalmente para ETL, para carregamento de dados. E os analistas já vivem em clusters médios, que não são absolutamente afetados pela carga de ETL, por isso trabalham muito rapidamente.
Conseqüentemente, o banco de dados é adequado para tarefas OLAP. No entanto, infelizmente, ainda não é aplicável a cargas de trabalho OLTP. Em primeiro lugar, esta base de dados é colunar, com todas as consequências daí decorrentes. Em segundo lugar, a abordagem em si, quando para cada solicitação, se necessário, você cria um cluster de computação e o inunda com dados, infelizmente, ainda não é rápida o suficiente para cargas OLTP. Esperar segundos para tarefas OLAP é normal, mas para tarefas OLTP é inaceitável; 100 ms seria melhor, ou 10 ms seria ainda melhor.
Total
Um banco de dados sem servidor é possível dividindo o banco de dados em partes Stateless e Stateful. Você deve ter notado que em todos os exemplos acima, a parte Stateful é, relativamente falando, armazenar micropartições no S3, e Stateless é o otimizador, trabalhando com metadados, lidando com problemas de segurança que podem ser levantados como serviços Stateless leves e independentes.
A execução de consultas SQL também pode ser percebida como serviços de estado leve que podem aparecer no modo sem servidor, como clusters de computação Snowflake, baixar apenas os dados necessários, executar a consulta e “sair”.
Os bancos de dados de nível de produção sem servidor já estão disponíveis para uso e estão funcionando. Esses bancos de dados sem servidor já estão prontos para lidar com tarefas OLAP. Infelizmente, para tarefas OLTP eles são usados... com nuances, pois existem limitações. Por um lado, isso é um sinal de menos. Mas, por outro lado, esta é uma oportunidade. Talvez um dos leitores encontre uma maneira de tornar um banco de dados OLTP completamente sem servidor, sem as limitações do Aurora.
Espero que você tenha achado interessante. Sem servidor é o futuro :)
Fonte: habr.com
