

É sabido que a competência de um CTO só é testada na segunda vez que ele assume o cargo. Uma coisa é trabalhar para uma empresa por vários anos, evoluindo junto com ela e, ainda dentro do mesmo contexto cultural, assumindo gradualmente mais responsabilidades. Outra coisa bem diferente é assumir diretamente o cargo de CTO em uma empresa com um histórico de problemas e uma série de questões cuidadosamente varridas para debaixo do tapete.
Nesse sentido, a experiência de Leon Fayer, que ele compartilhou em Não é exatamente algo único, mas, combinado com sua experiência e a quantidade de funções diferentes que desempenhou ao longo de 20 anos, é muito útil. Abaixo, segue uma cronologia dos eventos ao longo de 90 dias e muitas anedotas que são engraçadas quando acontecem com outras pessoas, mas não tão agradáveis de se presenciar pessoalmente.
Leon fala russo de forma muito fluente, então, se você tiver de 35 a 40 minutos, recomendo assistir ao vídeo. A versão em texto está abaixo para economizar tempo.

A primeira versão do relatório era uma descrição bem estruturada do trabalho com pessoas e processos, contendo recomendações úteis. Mas não capturou todas as surpresas encontradas ao longo do caminho. Então, mudei o formato e apresentei os problemas que surgiram na nova empresa como peças de um quebra-cabeça, e os métodos para resolvê-los, em ordem cronológica.
Um mês antes
Como muitas boas histórias, esta começou com álcool. Estávamos sentados num bar com alguns amigos e, como é típico nos círculos de TI, todos reclamavam dos seus problemas. Um deles tinha acabado de mudar de emprego e estava me contando sobre seus problemas com tecnologia, pessoas e a equipe. Quanto mais eu ouvia, mais percebia que ele deveria me contratar, porque esses são exatamente os tipos de problemas que venho resolvendo nos últimos 15 anos. Eu disse isso a ele e, no dia seguinte, nos encontramos em um ambiente de trabalho. A empresa se chamava Teaching Strategies.
A Teaching Strategies é líder de mercado em software educacional para crianças bem pequenas — do nascimento aos três anos de idade. A empresa tradicional, com seu software impresso, tem 40 anos, enquanto a versão digital SaaS da plataforma existe há 10 anos. O processo de adaptação da tecnologia digital aos padrões da empresa começou relativamente há pouco tempo. A "nova" versão foi lançada em 2017 e era quase idêntica à antiga, porém com menos funcionalidades.
O mais interessante é que o fluxo de clientes dessa empresa é muito previsível — dia após dia, ano após ano, é possível prever com precisão quantas pessoas acessarão o site e em que horário. Por exemplo, entre 13h e 15h, todas as crianças da pré-escola vão dormir e os professores começam a inserir informações no sistema. E isso acontece todos os dias, exceto nos fins de semana, porque quase ninguém trabalha aos fins de semana.
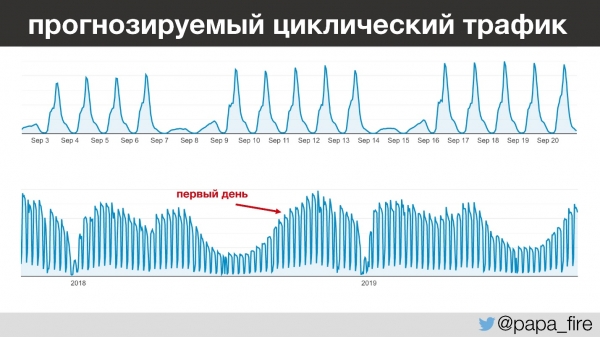
Olhando um pouco para o futuro, observo que iniciei meu trabalho durante o período de maior tráfego anual, o que é interessante por vários motivos.
A plataforma, que parecia ter apenas dois anos, possuía uma pilha de tecnologias única: ColdFusion e SQL Server de 2008. ColdFusion, caso você não saiba (e provavelmente não sabe), é uma linguagem PHP empresarial que surgiu em meados da década de 90, e eu nunca mais ouvi falar dela desde então. Ela também incluía Ruby, MySQL, PostgreSQL, Java, Go e Python. Mas o núcleo monolítico rodava em ColdFusion e SQL Server.
Problemas
Quanto mais eu conversava com os funcionários da empresa sobre o trabalho deles e os desafios que enfrentavam, mais percebia que os problemas não eram apenas técnicos. Tudo bem, a tecnologia era antiga — eles já tinham trabalhado com piores —, mas havia problemas com a equipe e os processos, e a empresa estava começando a entender isso.
Tradicionalmente, os especialistas em tecnologia ficavam num canto, fazendo suas próprias coisas. Mas, cada vez mais, os negócios começaram a migrar para o digital. Então, no último ano antes de eu começar a trabalhar lá, a empresa adicionou novos membros: um conselho administrativo, um diretor de tecnologia (CTO), um diretor de produtos (CPO) e um diretor de controle de qualidade (QA). Em outras palavras, a empresa começou a investir em tecnologia.
Os vestígios de um legado problemático não estavam apenas nos sistemas. A empresa tinha processos obsoletos, pessoas obsoletas e uma cultura obsoleta. Tudo isso precisava mudar. Imaginei que não seria uma tarefa entediante, então decidi tentar.
Dois dias antes
Dois dias antes de começar meu novo emprego, cheguei ao escritório, preenchi a papelada final, conheci a equipe e descobri que eles estavam enfrentando um problema. O problema era que o tempo médio de carregamento da página havia aumentado para 4 segundos, o dobro.
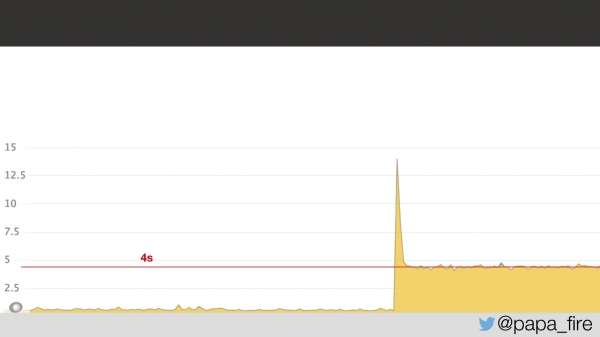
Analisando o gráfico, algo claramente tinha dado errado, e não estava claro o quê. Descobriu-se que era um problema de latência de rede no data center: 5 ms de latência no data center se traduziam em 2 segundos para os usuários. Eu não sabia por que isso acontecia, mas pelo menos ficou claro que o problema estava no data center.
Um dia
Passaram-se dois dias e, no meu primeiro dia de trabalho, descobri que o problema não havia desaparecido.
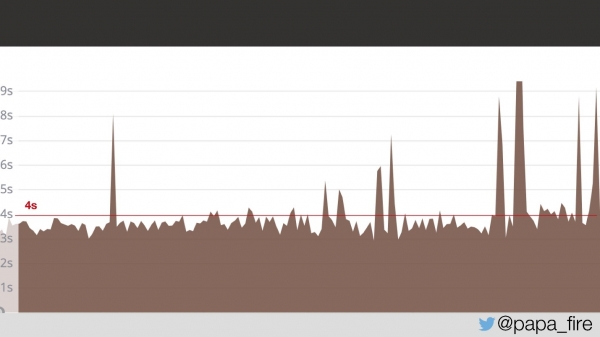
Durante dois dias, as páginas dos usuários estavam carregando em uma média de 4 segundos. Perguntei se eles haviam encontrado o problema.
- Sim, abrimos um chamado.
- e?
— Bem, eles ainda não nos responderam.
Foi aí que percebi que tudo o que me haviam dito antes era apenas a ponta do iceberg que precisava ser combatido.
Existe uma citação muito apropriada para este caso:
"Às vezes, para mudar a tecnologia, é preciso mudar a organização."
Mas como comecei a trabalhar durante a época mais movimentada do ano, tive que considerar soluções tanto imediatas quanto de longo prazo. E tive que começar pelo que era crucial naquele momento.
Dia três
Assim, o tempo de carregamento é de 4 segundos, e os picos mais altos ocorrem entre 13 e 15 segundos.
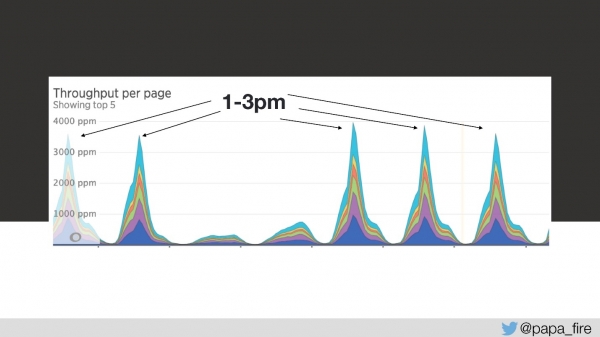
No terceiro dia desse período, a velocidade de download foi a seguinte:
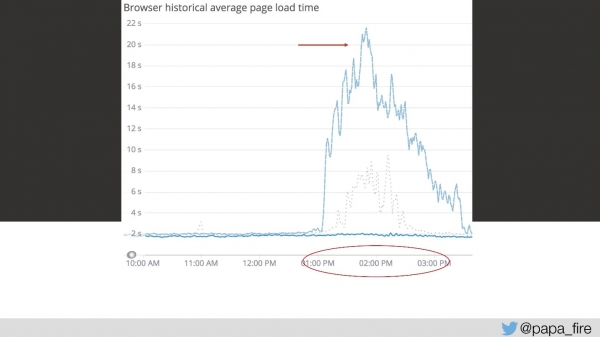
Do meu ponto de vista, nada funcionou. Do ponto de vista de todos os outros, funcionou um pouco mais lentamente do que o normal. Mas isso não acontece por acaso — é um problema sério.
Tentei convencer a equipe, mas eles me disseram que simplesmente precisavam de mais servidores. Essa é certamente uma solução, mas está longe de ser a única ou a mais eficaz. Perguntei por que não havia servidores suficientes e qual era o volume de tráfego. Extrapolei os dados e descobri que tínhamos cerca de 150 solicitações por segundo, o que geralmente está dentro de limites razoáveis.
Mas não devemos esquecer que, antes de obtermos a resposta certa, precisamos fazer a pergunta certa. Minha próxima pergunta foi: quantos servidores front-end temos? A resposta me deixou um pouco atônito — tínhamos 17 servidores front-end!
— Tenho vergonha de perguntar, mas 150 dividido por 17 dá aproximadamente 8? Você está dizendo que cada servidor processa 8 requisições por segundo e, se amanhã tivermos 160 requisições por segundo, precisaremos de mais dois servidores?
É claro que não precisávamos de servidores adicionais. A solução estava no próprio código, bem ali, à vista de todos:
var currentClass = classes.getCurrentClass();
return currentClass; Havia uma função getCurrentClass(), porque tudo no site funciona corretamente dentro do contexto da classe. E para essa função específica em cada página, Mais de 200 solicitações.
A solução, portanto, foi muito simples, não havia necessidade de reescrever nada: bastava não solicitar as mesmas informações novamente.
if ( !isDefined("REQUEST.currentClass") ) {
var classes = new api.private.classes.base();
REQUEST.currentClass = classes.getCurrentClass();
}
return REQUEST.currentClass;Fiquei radiante porque pensei ter encontrado o problema principal logo no terceiro dia. Que ingenuidade a minha, era apenas um entre muitos problemas.
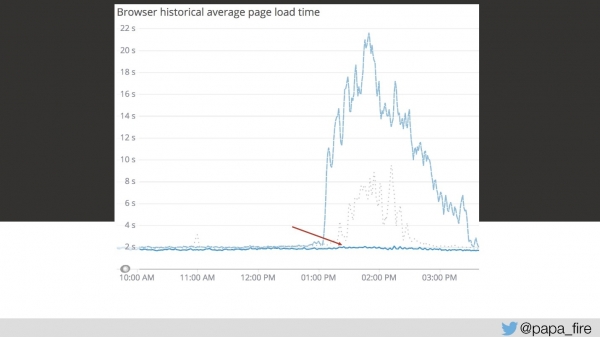
Mas a resolução desse primeiro problema fez com que o gráfico caísse muito mais.
Ao mesmo tempo, estávamos trabalhando em outras otimizações. Havia muitas coisas que podiam ser corrigidas imediatamente. Por exemplo, naquele terceiro dia, descobri que o sistema tinha um cache (a princípio, pensei que todas as solicitações viessem diretamente do banco de dados). Quando penso em cache, imagino o Redis ou o Memcached padrão. Mas essa era apenas a minha impressão, porque o cache naquele sistema usava MongoDB e SQL Server — o mesmo de onde acabávamos de ler os dados.
Décimo dia
Na primeira semana, dediquei-me a resolver problemas que precisavam de atenção imediata. Por volta da segunda semana, participei pela primeira vez de uma reunião diária para conversar com a equipe, entender o que estava acontecendo e como todo o processo estava progredindo.
Algo interessante surgiu novamente. A equipe era composta por: 18 desenvolvedores; 8 testadores; 3 gerentes; 2 arquitetos. E todos participavam de rituais compartilhados, o que significa que mais de 30 pessoas compareciam à reunião diária e relatavam o que estavam fazendo. Claramente, a reunião não durava 5 ou 15 minutos. Ninguém ouvia ninguém, pois cada um trabalhava em sistemas diferentes. Nesse formato, 2 a 3 tarefas resolvidas por hora durante uma sessão de refinamento já era um bom resultado.
A primeira coisa que fizemos foi dividir a equipe em várias linhas de produto. Para diferentes seções e sistemas, criamos equipes separadas, incluindo desenvolvedores, testadores, gerentes de produto e analistas de negócios.
O resultado foi:
- Redução de manifestações e comícios.
- Conhecimento específico do produto.
- Um senso de propriedade. Quando as pessoas costumavam alternar constantemente entre sistemas, sabiam que seus problemas provavelmente seriam resolvidos por outra pessoa, e não por elas mesmas.
- Colaboração entre equipes. É evidente que, antes, a equipe de controle de qualidade e os programadores não interagiam muito; o gerente de produto trabalhava isoladamente, etc. Agora, eles compartilham a responsabilidade por suas ações.
Nosso foco principal era a eficiência, a produtividade e a qualidade — esses eram os problemas que estávamos tentando resolver ao transformar a equipe.
Dia onze
No processo de mudança da estrutura da equipe, descobri como calcular HistóriaPontos1 SP equivalia a um dia, e cada ticket continha SP tanto para desenvolvimento quanto para controle de qualidade, ou seja, pelo menos 2 SP.
Como descobri isso?
Encontramos um bug: em um dos relatórios, onde você insere as datas de início e término do período para o qual precisa do relatório, o último dia não é considerado. Ou seja, em algum lugar da consulta não havia <=, mas simplesmente <. Fui informado de que isso custa três Pontos de História, o que significa 3 dias.
Depois disso nós:
- Revisamos o sistema de Pontos de História. Agora, pequenas correções de bugs que podem ser processadas rapidamente pelo sistema chegam aos usuários mais rapidamente.
- Começamos a consolidar os tickets relacionados de desenvolvimento e teste. Antes, cada ticket, cada bug, era um ecossistema fechado, desconectado de tudo. Alterar três botões em uma única página poderia resultar em três tickets diferentes com três processos de controle de qualidade distintos, em vez de um único teste automatizado por página.
- Começamos a trabalhar com os desenvolvedores em uma abordagem para estimar os custos de mão de obra. Três dias para alterar um botão não é brincadeira.
Vigésimo dia
Por volta da metade do primeiro mês, a situação se estabilizou um pouco, eu entendi basicamente o que estava acontecendo e comecei a olhar para o futuro e a pensar em soluções a longo prazo.
Metas de longo prazo:
- Plataforma gerenciada. Centenas de consultas em cada página não são graves.
- Tendências previsíveis. Havia picos periódicos de tráfego que, à primeira vista, não pareciam ter correlação com outras métricas — precisávamos entender por que isso acontecia e aprender a prever esse fenômeno.
- Expansão da plataforma. O negócio está em constante crescimento, com cada vez mais usuários e aumento do tráfego.
Antigamente, costumava-se dizer: "Vamos reescrever tudo em [linguagem/framework], tudo funcionará melhor!"
Na maioria dos casos, isso não funciona; é uma vitória se a reescrita funcionar. Portanto, precisávamos criar um roteiro — uma estratégia concreta que ilustrasse passo a passo como alcançaríamos nossos objetivos de negócios (o que faríamos e por quê), que:
- Reflete a missão e os objetivos do projeto;
- prioriza metas-chave;
- Contém um cronograma para alcançá-los.
Antes disso, ninguém havia discutido com a equipe o propósito de quaisquer mudanças. Isso exige métricas de sucesso adequadas. Pela primeira vez na história da empresa, definimos KPIs para a equipe técnica e vinculamos essas métricas às métricas organizacionais.
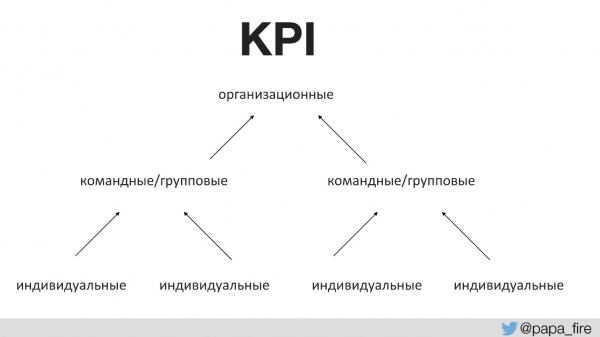
Em outras palavras, os KPIs organizacionais são suportados pelas equipes, e os KPIs das equipes são suportados pelos KPIs individuais. Caso contrário, se os KPIs de processo não estiverem alinhados com os organizacionais, todos sairão prejudicados.
Por exemplo, um dos KPIs organizacionais é o aumento da participação de mercado por meio de novos produtos.
Como podemos apoiar o objetivo de termos mais produtos novos?
- Em primeiro lugar, queremos dedicar mais tempo ao desenvolvimento de novos produtos em vez de corrigir defeitos. Esta é uma decisão lógica e facilmente mensurável.
- Em segundo lugar, queremos apoiar o crescimento do volume de transações, porque quanto maior a quota de mercado, mais utilizadores e, consequentemente, mais tráfego.
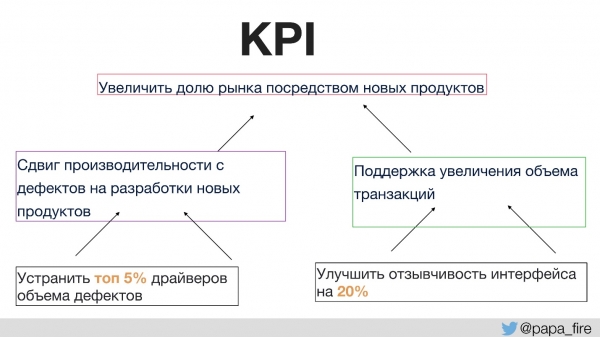
Em seguida, os KPIs individuais que podem ser implementados dentro do grupo serão, por exemplo, aqueles localizados onde os principais defeitos se originam. Ao focar especificamente nessa seção, é possível reduzir significativamente os defeitos, aumentando o tempo dedicado ao desenvolvimento de novos produtos e, consequentemente, contribuindo para os KPIs da organização.
Portanto, cada decisão, incluindo a reescrita de código, deve estar alinhada aos objetivos específicos que a empresa definiu para nós (crescimento organizacional, novas funcionalidades, recrutamento).
Durante esse processo, surgiu algo interessante, novidade não só para a equipe técnica, mas para toda a empresa: todos os tickets devem estar focados em pelo menos um KPI. Portanto, se um gerente de produto diz que quer criar um novo recurso, a primeira pergunta deve ser: "Qual KPI esse recurso suporta?". Se nenhum, então, infelizmente, parece um recurso desnecessário.
Trigésimo dia
No final do mês, descobri mais uma nuance: ninguém da minha equipe de Operações jamais tinha visto os contratos que assinamos com os clientes. Você pode se perguntar: por que alguém iria querer ver os contratos?
- Em primeiro lugar, porque os SLAs são especificados em contratos.
- Em segundo lugar, todos os SLAs são diferentes. Cada cliente tinha seus próprios requisitos, e a equipe de vendas os assinou sem analisá-los.
Outro detalhe interessante: o contrato com um de nossos maiores clientes estipula que todas as versões de software suportadas pela plataforma devem ser n-1, ou seja, não a versão mais recente, mas a penúltima.
Fica claro o quão longe estávamos de n-1 se a plataforma era baseada em ColdFusion e SQL Server 2008, que deixou de ter qualquer suporte em julho.
Dia quarenta e cinco
Por volta da metade do segundo mês, tive tempo suficiente para sentar e fazer valortransmitir canaismapeamento Todo o processo. Estas são as etapas necessárias que devem ser seguidas, desde a criação do produto até a entrega ao consumidor, e devem ser descritas com o máximo de detalhes possível.
Você divide o processo em pequenas partes e analisa o que está demorando muito, o que pode ser otimizado, melhorado etc. Por exemplo, quanto tempo leva para uma solicitação de produto passar pela triagem inicial, quando ela chega ao nível de um ticket que um desenvolvedor pode resolver, para a equipe de controle de qualidade etc. Você analisa cada etapa em detalhes e pensa no que pode ser otimizado.
Enquanto fazia isso, duas coisas me chamaram a atenção:
- alta porcentagem de tickets devolvidos da equipe de controle de qualidade para os desenvolvedores;
- As revisões dos pull requests demoraram muito.
O problema era que essas conclusões eram do tipo: parece demorar muito tempo, mas não temos certeza de quanto tempo exatamente.
"Não se pode melhorar aquilo que não se pode medir."
Como você pode justificar a gravidade de um problema? Ele está desperdiçando dias ou horas?
Para medir isso, adicionamos algumas etapas ao processo do Jira: "pronto para desenvolvimento" e "pronto para controle de qualidade" para medir quanto tempo cada ticket fica aguardando e quantas vezes ele retorna a uma etapa específica.
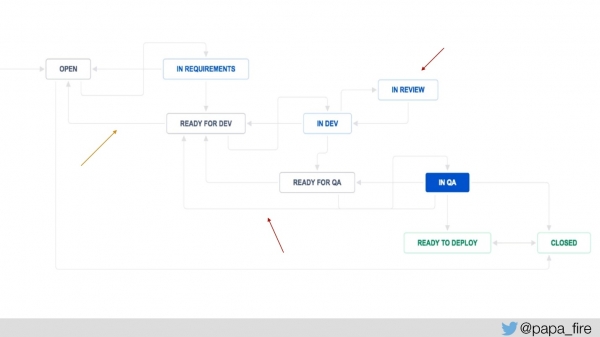
Adicionamos também a categoria "em análise" para acompanhar o tempo médio que os tickets ficam em análise e, a partir daí, podemos começar a mensurar os resultados. Já tínhamos métricas do sistema, mas agora adicionamos novas e começamos a medi-las:
- Eficiência do processo: Desempenho e planejado/executado.
- Qualidade do processo: Número de defeitos, defeitos provenientes do controle de qualidade.
Entender o que está funcionando bem e o que não está realmente ajudando é fundamental.
quinquagésimo dia
Tudo isso é muito bom e interessante, claro, mas perto do final do segundo mês, aconteceu algo que era basicamente previsível, embora eu não esperasse uma escala tão grande. As pessoas começaram a sair porque a alta direção havia mudado. Novas pessoas entraram na gerência e começaram a mudar tudo, e os antigos se demitiram. E normalmente, em uma empresa que existe há alguns anos, todos são amigos e se conhecem.
Isso era esperado, mas a escala das demissões foi inesperada. Por exemplo, em uma semana, dois líderes de equipe entregaram seus pedidos de demissão simultaneamente. Então, eu tive que não só esquecer outros assuntos, mas também me concentrar em... Criando uma equipeEste é um problema longo e difícil de resolver, mas era necessário abordá-lo porque queríamos manter as pessoas que permaneceram (ou pelo menos a maioria delas). Precisávamos, de alguma forma, dar uma resposta às pessoas que saíram para manter o moral da equipe.
Em teoria, isso é algo bom: uma pessoa nova chega com total liberdade de ação, pode avaliar as habilidades da equipe e substituir os funcionários existentes. Na prática, é impossível simplesmente contratar novas pessoas por uma série de motivos. É sempre necessário haver equilíbrio.
- Velhos e novos. Precisamos manter as pessoas antigas que podem mudar e apoiar a missão. Mas, ao mesmo tempo, precisamos trazer sangue novo, o que discutiremos um pouco mais adiante.
- Experiência. Conversei bastante com jovens talentosos que estavam ansiosos para se juntar à nossa equipe. Mas não pude contratá-los porque não havia profissionais experientes suficientes para apoiá-los e orientá-los. Precisávamos recrutar primeiro os melhores e só depois os mais jovens.
- Cenoura e vara.
Não tenho uma boa resposta para a pergunta sobre qual é o equilíbrio certo, como mantê-lo, quantas pessoas manter e quanta pressão exercer. É um processo puramente individual.
Dia cinquenta e um
Comecei a analisar a equipe para ver quem eu tinha, e mais uma vez me lembrei:
"A maioria dos problemas são problemas de pessoas."
Descobri que a equipe como um todo, tanto os desenvolvedores quanto a equipe de operações, tinha três grandes problemas:
- Satisfação com o estado atual das coisas.
- Falta de responsabilidade — porque ninguém jamais traduziu os resultados do trabalho dos artistas em seu impacto nos negócios.
- Medo da mudança.

A mudança sempre nos tira da zona de conforto, e quanto mais jovens as pessoas, mais elas resistem à mudança porque não entendem o porquê ou como. A resposta mais comum que ouvi foi: "Nunca fizemos assim". Isso chegou ao ponto do completo absurdo — até a menor mudança não era aceita sem que alguém reclamasse. E não importava o quanto a mudança afetasse o trabalho, as pessoas diziam: "Não, por que se incomodar? Não vai funcionar".
Mas você não consegue melhorar sem mudar nada.
Tive uma conversa completamente absurda com um funcionário. Eu estava lhe contando minhas ideias para otimização, ao que ele respondeu:
Ah, você não viu o que tivemos no ano passado!
- Então o que?
— Está muito melhor agora do que estava.
Então, não pode ficar melhor?
Por que?
Uma boa pergunta: por quê? Como se, se as coisas estão melhores agora do que antes, então tudo está bom o suficiente. Isso leva a uma falta de responsabilidade, o que é perfeitamente normal. Como eu disse, a equipe de tecnologia estava um pouco à margem. A empresa achava que eles deveriam estar presentes, mas Ninguém jamais estabeleceu padrõesA equipe de suporte técnico nunca tinha visto um SLA, então para o grupo era perfeitamente "aceitável" (e foi isso que mais me impressionou):
- 12 segundos de carregamento;
- Tempo de inatividade de 5 a 10 minutos por versão;
- Questões críticas levam dias e semanas para serem resolvidas;
- Sem equipe disponível 24 horas por dia, 7 dias por semana, em regime de plantão.
Ninguém nunca tentou perguntar por que não conseguíamos fazer melhor, e ninguém nunca percebeu que não deveria ser assim.
Para piorar a situação, havia mais um problema: falta de experiênciaOs veteranos saíram, e a equipe jovem restante cresceu sob o regime anterior e foi contaminada por ele.
Além de tudo isso, as pessoas também tinham medo de falhar e de parecer incompetentes. Isso se refletia no fato de que, em primeiro lugar, Em hipótese alguma pedi ajuda.Quantas vezes, em conversas em grupo e individualmente, eu disse: "Pergunte se não souber como fazer algo"? Tenho confiança e sei que consigo resolver qualquer problema, mas isso leva tempo. Então, se eu puder perguntar a alguém que saiba como resolvê-lo em 10 minutos, eu o farei. Quanto menos experiência você tem, mais medo sente de perguntar, porque acha que será considerado incompetente.
Esse medo de fazer perguntas se manifesta de maneiras interessantes. Por exemplo, você pergunta: "Como está indo essa tarefa?" e a pessoa responde: "Faltam só algumas horas, já estou quase terminando". No dia seguinte, você pergunta novamente e a resposta é que está tudo bem, mas há um pequeno problema, que com certeza estará resolvido até o final do dia. Mais um dia se passa e, até que você a pressione e a force a falar com alguém, a situação continua assim. Ela quer resolver o problema sozinha, acreditando que não resolvê-lo por conta própria será um grande fracasso.
É por isso os desenvolvedores inflacionaram as estimativasFoi uma verdadeira piada: quando estávamos discutindo uma tarefa específica, eles me deram um número que me surpreendeu bastante. Disseram que, em suas estimativas, o desenvolvedor inclui o tempo que leva para o ticket ser devolvido pelo controle de qualidade porque eles encontram bugs, o tempo que leva para o pull request ser aberto e o tempo que as pessoas que deveriam revisá-lo estão ocupadas — em outras palavras, tudo o que for possível.
Em segundo lugar, pessoas que têm medo de parecer incompetentes, analisar demaisQuando você lhes diz exatamente o que precisa ser feito, eles começam a dizer: "Não, e se pensarmos nisso aqui?" Nesse sentido, nossa empresa não é única; é um problema comum entre os jovens.
Em resposta, introduzi as seguintes práticas:
- A regra dos 30 minutos. Se você não conseguir resolver o problema em meia hora, peça ajuda a outra pessoa. Isso funciona com resultados variáveis, porque as pessoas geralmente não pedem ajuda, mas pelo menos o processo começou.
- Elimine tudo, exceto a essência.Ao estimar o tempo necessário para concluir uma tarefa, considere apenas quanto tempo levará para escrever o código.
- Formação contínua Para quem analisa demais. É apenas trabalho constante com pessoas.
Dia sessenta
Enquanto eu fazia tudo isso, chegou a hora de organizar o orçamento. Claro, descobri muitas coisas interessantes sobre como estávamos gastando dinheiro. Por exemplo, tínhamos um rack inteiro em um data center separado, abrigando um único servidor FTP usado por um único cliente. Acontece que "...nós o mudamos, mas ele continuou lá, não o substituímos". Isso foi há dois anos.
A fatura da nuvem foi particularmente interessante. Tenho certeza de que o principal motivo para a fatura alta é que os desenvolvedores, pela primeira vez na vida, têm acesso ilimitado a servidores. Eles não precisam mais pedir "Por favor, me dê um servidor de teste" — eles podem usar quando quiserem. Além disso, os desenvolvedores sempre querem construir um sistema tão incrível que deixaria o Facebook e a Netflix com inveja.
Mas os desenvolvedores não têm experiência em aquisição de servidores nem as habilidades para determinar o tamanho ideal do servidor, porque nunca precisaram fazer isso antes. E muitas vezes não entendem completamente a diferença entre escalabilidade e desempenho.
Resultados do inventário:
- Originários do mesmo centro de dados.
- Encerramos os contratos com três serviços de registro de logs. Tínhamos cinco deles — cada desenvolvedor que começava a experimentar algo contratava um novo.
- Sete sistemas da AWS foram desligados. Novamente, os projetos inativos não foram encerrados; eles continuaram em operação.
- Redução dos custos de software em 6 vezes.
Dia setenta e cinco
O tempo passou e, em dois meses e meio, eu tinha uma reunião agendada com o conselho administrativo. Nosso conselho não é melhor nem pior do que qualquer outro; como todos os conselhos, ele quer saber de tudo. As pessoas investem dinheiro e querem entender como nosso trabalho se alinha aos nossos indicadores-chave de desempenho (KPIs).
O conselho administrativo recebe muitas informações todos os meses: o número de usuários, seu crescimento, quais serviços eles usam e como, o desempenho e a produtividade e, finalmente, a velocidade média de carregamento da página.
O único problema é que eu acho que a média é pura maldade. Mas é muito difícil explicar isso para o conselho administrativo. Eles estão acostumados a trabalhar com números agregados, não, por exemplo, com a distribuição dos tempos de carregamento por segundo.
Havia alguns pontos interessantes a esse respeito. Por exemplo, eu disse que o tráfego deveria ser dividido entre servidores web separados, dependendo do tipo de conteúdo.

Então, o ColdFusion utiliza o Jetty e o Nginx para carregar as páginas. Já as imagens, o JavaScript e o CSS passam por um Nginx separado, com suas próprias configurações. Essa é uma prática bastante comum, da qual estou falando. Há apenas alguns anos. Como resultado, as imagens carregam muito mais rápido e... a velocidade média de carregamento aumentou em 200 ms.
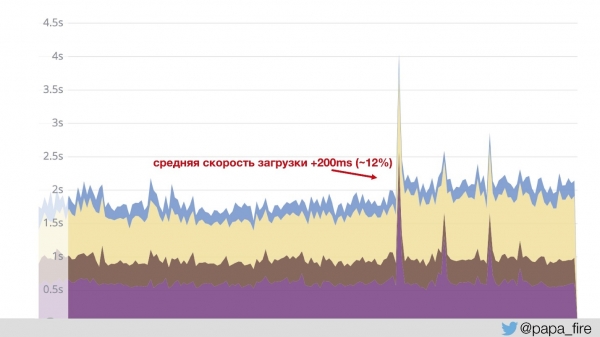
Isso aconteceu porque o gráfico se baseia em dados do Jetty. Ou seja, o conteúdo rápido não está incluído no cálculo — o valor médio aumentou. Entendemos isso e demos risada, mas como poderíamos explicar ao conselho administrativo por que fizemos algo que causou uma queda de 12%?
Dia oitenta e cinco
Ao final do terceiro mês, percebi que havia uma coisa com a qual eu não havia contado: o tempo. Tudo o que mencionei leva tempo.

Este é o meu calendário semanal real — uma semana de trabalho simples, não muito agitada. Não há tempo suficiente para tudo. Então, mais uma vez, preciso recrutar pessoas para me ajudarem a lidar com os problemas.
Conclusão
Mas não é só isso. Nesta história, nem sequer mencionei como trabalhamos com o produto e tentamos chegar a um consenso, ou como integramos o suporte técnico, ou como resolvemos outros problemas técnicos. Por exemplo, descobri por acaso que não usamos SEQUENCETemos uma função escrita por nós mesmos nextIDE não é utilizado em uma transação.
Havia um milhão de outras coisas semelhantes que poderiam ser discutidas longamente. Mas o mais importante a mencionar é a cultura.

É a cultura, ou a falta dela, que leva a todos os outros problemas. Estamos tentando construir uma cultura onde as pessoas:
- não têm medo do fracasso;
- Aprenda com os erros;
- colaborar com outras equipes;
- demonstrar iniciativa;
- assumir a responsabilidade;
- Acolha o resultado como um objetivo;
- Comemore o sucesso.
Com isso, tudo o mais virá.
Fogo de Leão , e .
Existem duas estratégias para lidar com o legado: evitá-lo a todo custo ou superar corajosamente as dificuldades que o acompanham. Nós Estamos seguindo o segundo caminho, mudando processos e abordagens. Junte-se a nós em , и E juntos implementaremos a cultura DevOps.
Fonte: habr.com
