

Sugiro que você leia a transcrição do relatório de Alexey Lesovsky do Data Egret “Fundamentos do monitoramento PostgreSQL”
Neste relatório, Alexey Lesovsky falará sobre os pontos-chave das estatísticas pós-agressão, o que significam e por que devem estar presentes no monitoramento; sobre quais gráficos devem constar no monitoramento, como adicioná-los e como interpretá-los. O relatório será útil para administradores de banco de dados, administradores de sistema e desenvolvedores interessados na solução de problemas do Postgres.


Meu nome é Alexey Lesovsky, represento a empresa Data Egret.
Algumas palavras sobre mim. Comecei há muito tempo como administrador de sistema.
Administrei todo tipo de coisa diferente. Linux, esteve envolvido em várias atividades relacionadas a LinuxOu seja, virtualização, monitoramento, trabalho com proxies, etc. Mas em certo momento, comecei a trabalhar mais com bancos de dados, PostgreSQL. Gostei muito. E em certo ponto, comecei a dedicar a maior parte do meu tempo ao PostgreSQL. E assim, gradualmente, me tornei um DBA de PostgreSQL.
E ao longo da minha carreira sempre me interessei pelos temas de estatística, monitoramento e telemetria. E quando eu era administrador de sistema, trabalhei em estreita colaboração com o Zabbix. E eu escrevi um pequeno conjunto de scripts como Era bastante popular na sua época. E você podia monitorar muitas coisas importantes lá, não apenas... Linux, mas também componentes diferentes.
Agora estou trabalhando no PostgreSQL. Já estou escrevendo outra coisa que permite trabalhar com estatísticas do PostgreSQL. É chamado (artigo sobre Habré - ).

Uma pequena nota introdutória. Que situações nossos clientes, nossos clientes têm? Há algum tipo de acidente relacionado ao banco de dados. E quando o banco de dados já está restaurado, chega o chefe do departamento ou chefe de desenvolvimento e diz: “Amigos, precisamos monitorar o banco de dados, porque algo ruim aconteceu e precisamos evitar que isso aconteça no futuro”. E aqui começa o interessante processo de escolha de um sistema de monitoramento ou adaptação de um sistema de monitoramento existente para que você possa monitorar seu banco de dados - PostgreSQL, MySQL ou alguns outros. E os colegas começam a sugerir: “Ouvi dizer que existe tal e tal banco de dados. Vamos usá-lo." Os colegas começam a discutir entre si. E no final descobrimos que selecionamos algum tipo de banco de dados, mas o monitoramento do PostgreSQL é apresentado nele de maneira bastante precária e sempre temos que acrescentar algo. Pegue alguns repositórios do GitHub, clone-os, adapte scripts e personalize-os de alguma forma. E no final acaba sendo uma espécie de trabalho manual.

Portanto, nesta palestra tentarei dar alguns conhecimentos sobre como escolher o monitoramento não só para PostgreSQL, mas também para o banco de dados. E dar-lhe o conhecimento que lhe permitirá completar o seu monitoramento para obter algum benefício dele, para que você possa monitorar seu banco de dados com benefício, a fim de prevenir prontamente quaisquer situações de emergência que possam surgir.
E as ideias que estarão neste relatório podem ser adaptadas diretamente a qualquer banco de dados, seja um SGBD ou noSQL. Portanto, não existe apenas o PostgreSQL, mas haverá muitas receitas de como fazer isso no PostgreSQL. Haverá exemplos de consultas, exemplos de entidades que o PostgreSQL possui para monitoramento. E se o seu SGBD tiver as mesmas coisas que permitem colocá-los no monitoramento, você também pode adaptá-los, adicioná-los e ficará bom.
 Eu não estarei no relatório
Eu não estarei no relatório
fale sobre como entregar e armazenar métricas. Não direi nada sobre pós-processamento dos dados e apresentação ao usuário. E não direi nada sobre alertar.
Mas à medida que a história avança, irei mostrar diferentes capturas de tela do monitoramento existente e de alguma forma criticá-los. Mesmo assim, tentarei não nomear marcas para não criar publicidade ou antipublicidade para esses produtos. Portanto, todas as coincidências são aleatórias e ficam por conta da sua imaginação.

Primeiro, vamos descobrir o que é monitoramento. O monitoramento é uma coisa muito importante de se ter. Todo mundo entende isso. Mas, ao mesmo tempo, a monitorização não está relacionada com um produto empresarial e não afecta directamente o lucro da empresa, pelo que o tempo é sempre atribuído à monitorização numa base residual. Se tivermos tempo, então fazemos monitoramento; se não tivermos tempo, tudo bem, vamos colocar no backlog e um dia voltaremos a essas tarefas.
Portanto, pela nossa prática, quando chegamos aos clientes, o monitoramento muitas vezes é incompleto e não tem nada de interessante que nos ajude a fazer um trabalho melhor com o banco de dados. E, portanto, o monitoramento sempre precisa ser concluído.
Os bancos de dados são coisas tão complexas que também precisam ser monitorados, porque os bancos de dados são um repositório de informações. E a informação é muito importante para a empresa, não pode ser perdida de forma alguma. Mas, ao mesmo tempo, os bancos de dados são softwares muito complexos. Eles consistem em um grande número de componentes. E muitos destes componentes precisam ser monitorados.
 Se estamos falando especificamente do PostgreSQL, ele pode ser representado como um esquema que consiste em um grande número de componentes. Esses componentes interagem entre si. E ao mesmo tempo, o PostgreSQL possui o chamado subsistema Stats Collector, que permite coletar estatísticas sobre o funcionamento desses subsistemas e fornecer algum tipo de interface ao administrador ou usuário para que ele possa visualizar essas estatísticas.
Se estamos falando especificamente do PostgreSQL, ele pode ser representado como um esquema que consiste em um grande número de componentes. Esses componentes interagem entre si. E ao mesmo tempo, o PostgreSQL possui o chamado subsistema Stats Collector, que permite coletar estatísticas sobre o funcionamento desses subsistemas e fornecer algum tipo de interface ao administrador ou usuário para que ele possa visualizar essas estatísticas.
Essas estatísticas são apresentadas na forma de um determinado conjunto de funções e visualizações. Eles também podem ser chamados de tabelas. Ou seja, usando um cliente psql normal, você pode se conectar ao banco de dados, selecionar essas funções e visualizações e obter alguns números específicos sobre o funcionamento dos subsistemas PostgreSQL.
Você pode adicionar esses números ao seu sistema de monitoramento favorito, desenhar gráficos, adicionar funções e obter análises de longo prazo.
Mas neste relatório não cobrirei todas estas funções completamente, porque poderia demorar o dia inteiro. Abordarei literalmente duas, três ou quatro coisas e contarei como elas ajudam a melhorar o monitoramento.

E se falamos em monitoramento de banco de dados, então o que precisa ser monitorado? Em primeiro lugar, precisamos monitorar a disponibilidade, pois o banco de dados é um serviço que dá acesso aos dados aos clientes e precisamos monitorar a disponibilidade, além de fornecer algumas de suas características qualitativas e quantitativas.

Também precisamos monitorar os clientes que se conectam ao nosso banco de dados, pois podem ser tanto clientes normais quanto clientes prejudiciais que podem prejudicar o banco de dados. Eles também precisam ser monitorados e suas atividades monitoradas.

Quando os clientes se conectam ao banco de dados, é óbvio que eles começam a trabalhar com nossos dados, por isso precisamos monitorar como os clientes trabalham com os dados: com quais tabelas e, em menor grau, com quais índices. Ou seja, precisamos avaliar a carga de trabalho que é criada pelos nossos clientes.

Mas a carga de trabalho também consiste, obviamente, em solicitações. As aplicações se conectam ao banco de dados, acessam os dados através de consultas, por isso é importante avaliar quais consultas temos no banco de dados, monitorar sua adequação, se não estão escritas tortas, se algumas opções precisam ser reescritas e feitas para que funcionem mais rápido e com melhor desempenho.

E como estamos falando de um banco de dados, o banco de dados é sempre um processo em segundo plano. Os processos em segundo plano ajudam a manter o desempenho do banco de dados em um bom nível, portanto, exigem uma certa quantidade de recursos para funcionarem. E, ao mesmo tempo, eles podem se sobrepor aos recursos de solicitação do cliente, de modo que processos gananciosos em segundo plano podem afetar diretamente o desempenho das solicitações do cliente. Portanto, eles também precisam ser monitorados e rastreados para que não haja distorções em termos de processos em segundo plano.

E tudo isso em termos de monitoramento do banco de dados fica na métrica do sistema. Mas considerando que a maior parte da nossa infraestrutura está migrando para as nuvens, as métricas do sistema de um host individual sempre ficam em segundo plano. Mas em bancos de dados eles ainda são relevantes e, claro, também é necessário monitorar as métricas do sistema.

Está tudo mais ou menos bem com as métricas do sistema, todos os sistemas de monitoramento modernos já suportam essas métricas, mas em geral alguns componentes ainda não são suficientes e algumas coisas precisam ser adicionadas. Também irei abordá-los, haverá vários slides sobre eles.

O primeiro ponto do plano é a acessibilidade. O que é acessibilidade? Disponibilidade no meu entendimento é a capacidade da base de atender conexões, ou seja, a base é elevada, ela, como serviço, aceita conexões de clientes. E essa acessibilidade pode ser avaliada por determinadas características. É muito conveniente exibir essas características em painéis.

Todo mundo sabe o que são painéis. Foi então que você deu uma olhada na tela onde estão resumidas as informações necessárias. E você pode determinar imediatamente se há algum problema no banco de dados ou não.
Dessa forma, a disponibilidade do banco de dados e outras características-chave devem ser sempre exibidas nos dashboards para que essas informações estejam à mão e sempre disponíveis para você. Alguns detalhes adicionais que já auxiliam na investigação de incidentes, ao investigar algumas situações de emergência, já precisam ser colocados em dashboards secundários, ou escondidos em links de detalhamento que levam a sistemas de monitoramento de terceiros.
Um exemplo de um sistema de monitoramento bem conhecido. Este é um sistema de monitoramento muito legal. Ela coleta muitos dados, mas do meu ponto de vista tem um conceito estranho de dashboards. Existe um link para “criar um painel”. Mas quando você cria um painel, você cria uma lista de duas colunas, uma lista de gráficos. E quando precisar olhar alguma coisa, você começa a clicar com o mouse, rolar, procurar o gráfico desejado. E isso leva tempo, ou seja, não existem painéis propriamente ditos. Existem apenas listas de gráficos.

O que você deve adicionar a esses painéis? Você pode começar com uma característica como o tempo de resposta. PostgreSQL possui a visualização pg_stat_statements. Está desabilitado por padrão, mas é uma das visualizações importantes do sistema que sempre deve ser habilitada e usada. Ele armazena informações sobre todas as consultas em execução no banco de dados.
Assim, podemos partir do fato de que podemos pegar o tempo total de execução de todas as solicitações e dividi-lo pelo número de solicitações usando os campos acima. Mas esta é a temperatura média no hospital. Podemos partir de outros campos – tempo mínimo de execução da consulta, máximo e mediana. E podemos até construir percentis; o PostgreSQL tem funções correspondentes para isso. E podemos obter alguns números que caracterizam o tempo de resposta do nosso banco de dados para solicitações já concluídas, ou seja, não executamos a solicitação falsa 'select 1' e olhamos o tempo de resposta, mas analisamos o tempo de resposta para solicitações já concluídas e sorteamos ou uma figura separada ou construímos um gráfico com base nela.
Também é importante monitorar o número de erros gerados atualmente pelo sistema. E para isso você pode usar a visualização pg_stat_database. Nós nos concentramos no campo xact_rollback. Este campo mostra não apenas o número de reversões que ocorrem no banco de dados, mas também leva em consideração o número de erros. Relativamente falando, podemos exibir esse número em nosso painel e ver quantos erros temos atualmente. Se houver muitos erros, esse é um bom motivo para examinar os registros e ver que tipo de erros são e por que ocorrem, e então investir e resolvê-los.

Você pode adicionar algo como um tacômetro. Estes são o número de transações por segundo e o número de solicitações por segundo. Relativamente falando, você pode usar esses números como o desempenho atual do seu banco de dados e observar se há picos nas solicitações, picos nas transações ou, inversamente, se o banco de dados está sobrecarregado porque algum back-end falhou. É importante sempre olhar para esse número e lembrar que para o nosso projeto esse tipo de desempenho é normal, mas os valores acima e abaixo já são meio problemáticos e incompreensíveis, o que significa que precisamos ver porque esses números são tão alto.
Para estimar o número de transações, podemos novamente consultar a visualização pg_stat_database. Podemos adicionar o número de commits e o número de reversões e obter o número de transações por segundo.
Todos entendem que várias solicitações podem caber em uma transação? Portanto, TPS e QPS são ligeiramente diferentes.
O número de solicitações por segundo pode ser obtido em pg_stat_statements e simplesmente calcular a soma de todas as solicitações concluídas. É claro que comparamos o valor atual com o anterior, subtraímos, obtemos o delta e obtemos a quantidade.

Você pode adicionar métricas adicionais, se desejar, que também ajudam a avaliar a disponibilidade de nosso banco de dados e monitorar se houve algum tempo de inatividade.
Uma dessas métricas é o tempo de atividade. Mas o tempo de atividade no PostgreSQL é um pouco complicado. Eu vou te dizer por quê. Quando o PostgreSQL é iniciado, o tempo de atividade inicia o relatório. Mas se em algum momento, por exemplo, alguma tarefa estava sendo executada à noite, um assassino OOM veio e encerrou à força o processo filho do PostgreSQL, então, neste caso, o PostgreSQL encerra a conexão de todos os clientes, redefine a área de memória fragmentada e inicia a recuperação de o último ponto de verificação. E enquanto durar essa recuperação do checkpoint, o banco de dados não aceita conexões, ou seja, esta situação pode ser avaliada como tempo de inatividade. Mas o contador de uptime não será zerado, pois leva em consideração o tempo de inicialização do postmaster desde o primeiro momento. Portanto, tais situações podem ser ignoradas.
Você também deve monitorar o número de trabalhadores do vácuo. Todo mundo sabe o que é autovacuum no PostgreSQL? Este é um subsistema interessante no PostgreSQL. Muitos artigos foram escritos sobre ela, muitos relatórios foram feitos. Há muitas discussões sobre o vácuo e como ele deve funcionar. Muitos consideram isso um mal necessário. Mas é assim que é. Este é um tipo de coletor de lixo que limpa versões desatualizadas de linhas que não são necessárias para nenhuma transação e libera espaço em tabelas e índices para novas linhas.
Por que você precisa monitorá-lo? Porque o vácuo às vezes dói muito. Ele consome uma grande quantidade de recursos e, como resultado, as solicitações dos clientes começam a ser prejudicadas.
E deve ser monitorado através da visualização pg_stat_activity, da qual falarei na próxima seção. Esta visualização mostra a atividade atual no banco de dados. E através desta atividade podemos acompanhar o número de aspiradores que estão funcionando neste momento. Podemos rastrear os vácuos e ver que, se excedemos o limite, esse é um motivo para examinar as configurações do PostgreSQL e de alguma forma otimizar a operação do vácuo.
Outra coisa sobre o PostgreSQL é que o PostgreSQL está cansado de transações longas. Principalmente em transações que permanecem por muito tempo e não fazem nada. Este é o chamado status ocioso na transação. Tal transação mantém bloqueios e impede o funcionamento do vácuo. E como resultado, as mesas incham e aumentam de tamanho. E as consultas que funcionam com essas tabelas começam a funcionar mais lentamente, porque você precisa remover todas as versões antigas das linhas da memória para o disco e vice-versa. Portanto, o tempo, a duração das transações mais longas e das solicitações de vácuo mais longas também precisam ser monitorados. E se virmos alguns processos que estão em execução há muito tempo, já há mais de 10-20-30 minutos para uma carga OLTP, então precisamos prestar atenção a eles e encerrá-los à força, ou otimizar o aplicativo para que eles não são chamados e não ficam pendurados por tanto tempo. Para uma carga de trabalho analítica, 10-20-30 minutos é normal; há também outras mais longas.

A seguir temos a opção com clientes conectados. Quando já tivermos criado um painel e postado as principais métricas de disponibilidade nele, também poderemos adicionar informações adicionais sobre os clientes conectados.
As informações sobre clientes conectados são importantes porque, da perspectiva do PostgreSQL, os clientes são diferentes. Existem bons clientes e existem clientes ruins.
Um exemplo simples. Por cliente eu entendo a aplicação. A aplicação se conectou ao banco de dados e imediatamente começa a enviar suas solicitações para lá, o banco de dados as processa e executa e retorna os resultados ao cliente. Estes são clientes bons e corretos.
Tem situações que o cliente conectou, segura a conexão, mas não faz nada. Está em estado inativo.
Mas existem clientes ruins. Por exemplo, o mesmo cliente se conectou, abriu uma transação, fez algo no banco de dados e depois entrou no código, por exemplo, para acessar uma fonte externa ou para processar os dados recebidos ali. Mas ele não fechou a transação. E a transação fica suspensa no banco de dados e é mantida em um bloqueio na linha. Esta é uma condição ruim. E se de repente um aplicativo em algum lugar dentro de si falhar com uma exceção, a transação poderá permanecer aberta por muito tempo. E isso afeta diretamente o desempenho do PostgreSQL. PostgreSQL será mais lento. Portanto, é importante rastrear esses clientes em tempo hábil e encerrar seu trabalho à força. E você precisa otimizar sua aplicação para que tais situações não ocorram.
Outros clientes ruins são clientes em espera. Mas eles se tornam maus por causa das circunstâncias. Por exemplo, uma transação ociosa simples: ela pode abrir uma transação, bloquear algumas linhas e, em seguida, em algum lugar do código ela falhará, deixando uma transação suspensa. Outro cliente virá e solicitará os mesmos dados, mas encontrará um bloqueio, porque aquela transação suspensa já contém bloqueios em algumas linhas necessárias. E a segunda transação ficará aguardando a conclusão da primeira transação ou seu fechamento forçado pelo administrador. Portanto, as transações pendentes podem se acumular e preencher o limite de conexões com o banco de dados. E quando o limite estiver cheio, o aplicativo não poderá mais trabalhar com o banco de dados. Esta já é uma situação de emergência para o projeto. Portanto, clientes ruins precisam ser rastreados e respondidos em tempo hábil.
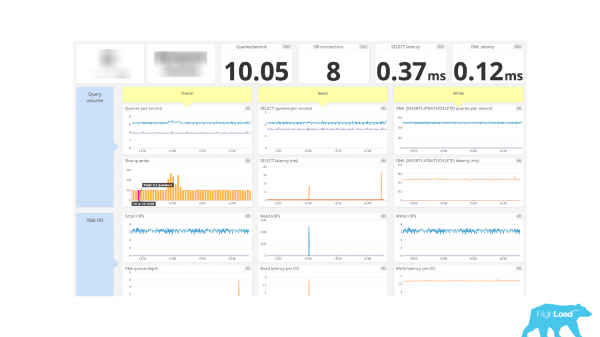
Outro exemplo de monitoramento. E já existe um painel decente aqui. Há informações sobre conexões acima. Conexão DB – 8 peças. E é tudo. Não temos informações sobre quais clientes estão ativos, quais clientes estão ociosos, sem fazer nada. Não há informações sobre transações pendentes e conexões pendentes, ou seja, este é um número que mostra a quantidade de conexões e pronto. E então adivinhe por si mesmo.

Dessa forma, para adicionar essas informações ao monitoramento, é necessário acessar a visualização do sistema pg_stat_activity. Se você passa muito tempo no PostgreSQL, então esta é uma visualização muito boa que deve se tornar sua amiga, pois mostra a atividade atual no PostgreSQL, ou seja, o que está acontecendo nele. Para cada processo existe uma linha separada que mostra informações sobre este processo: de qual host a conexão foi feita, sob qual usuário, sob qual nome, quando a transação foi iniciada, qual solicitação está em execução no momento, qual solicitação foi executada pela última vez. E, consequentemente, podemos avaliar o estado do cliente usando o campo stat. Relativamente falando, podemos agrupar por este campo e obter as estatísticas que estão atualmente no banco de dados e a quantidade de conexões que possuem essa estatística no banco de dados. E podemos enviar os números já recebidos para o nosso monitoramento e traçar gráficos a partir deles.
Também é importante avaliar a duração da transação. Já disse que é importante avaliar a duração dos vácuos, mas as transações são avaliadas da mesma forma. Existem campos xact_start e query_start. Eles, relativamente falando, mostram a hora de início da transação e a hora de início da solicitação. Pegamos a função now(), que mostra o carimbo de data/hora atual, e subtraímos o carimbo de data/hora da transação e da solicitação. E obtemos a duração da transação, a duração da solicitação.
Se virmos transações longas, já devemos concluí-las. Para uma carga OLTP, transações longas já duram mais de 1-2-3 minutos. Para uma carga de trabalho OLAP, transações longas são normais, mas se levarem mais de duas horas para serem concluídas, isso também é um sinal de que temos uma distorção em algum lugar.

Depois que os clientes se conectam ao banco de dados, eles começam a trabalhar com nossos dados. Eles acessam tabelas, acessam índices para obter dados da tabela. E é importante avaliar como os clientes interagem com esses dados.
Isso é necessário para avaliar nossa carga de trabalho e entender aproximadamente quais tabelas são as “mais quentes” para nós. Por exemplo, isso é necessário em situações em que queremos colocar tabelas “quentes” em algum tipo de armazenamento SSD rápido. Por exemplo, algumas tabelas de arquivo que não usamos há muito tempo podem ser movidas para algum tipo de arquivo “frio”, para drives SATA e deixá-las residir lá, elas serão acessadas conforme necessário.
Isso também é útil para detectar anomalias após quaisquer lançamentos e implantações. Digamos que o projeto lançou algum novo recurso. Por exemplo, adicionamos novas funcionalidades para trabalhar com o banco de dados. E se traçarmos gráficos de uso de tabelas, podemos detectar facilmente essas anomalias nesses gráficos. Por exemplo, atualize bursts ou exclua bursts. Será muito visível.
Você também pode detectar anomalias em estatísticas “flutuantes”. O que isso significa? O PostgreSQL possui um agendador de consultas muito forte e muito bom. E os desenvolvedores dedicam muito tempo ao seu desenvolvimento. Como ele funciona? Para fazer bons planos, o PostgreSQL coleta estatísticas sobre a distribuição dos dados nas tabelas em um determinado intervalo de tempo e com uma determinada frequência. Estes são os valores mais comuns: o número de valores únicos, informações sobre NULL na tabela, muita informação.
Com base nessas estatísticas, o planejador constrói diversas consultas, seleciona a mais ideal e usa esse plano de consulta para executar a própria consulta e retornar dados.
E acontece que as estatísticas “flutuam”. Os dados de qualidade e quantidade mudaram de alguma forma na tabela, mas as estatísticas não foram coletadas. E os planos formados podem não ser os ideais. E se os nossos planos se revelarem abaixo do ideal com base no monitoramento coletado, com base nas tabelas, poderemos ver essas anomalias. Por exemplo, em algum lugar os dados mudaram qualitativamente e em vez do índice, passou a ser utilizada uma passagem sequencial pela tabela, ou seja, se uma consulta precisar retornar apenas 100 linhas (há um limite de 100), será realizada uma pesquisa completa para esta consulta. E isso sempre tem um efeito muito ruim no desempenho.
E podemos ver isso no monitoramento. E já olhe para esta consulta, execute uma explicação para ela, colete estatísticas, construa um novo índice adicional. E já responda a esse problema. É por isso que é importante.
Outro exemplo de monitoramento. Acho que muitas pessoas o reconheceram porque ele é muito popular. Quem usa em seus projetos ? Quem usa este produto em conjunto com o Prometheus? O fato é que no repositório padrão deste monitoramento existe um dashboard para trabalhar com PostgreSQL - Prometeu. Mas há um detalhe ruim.
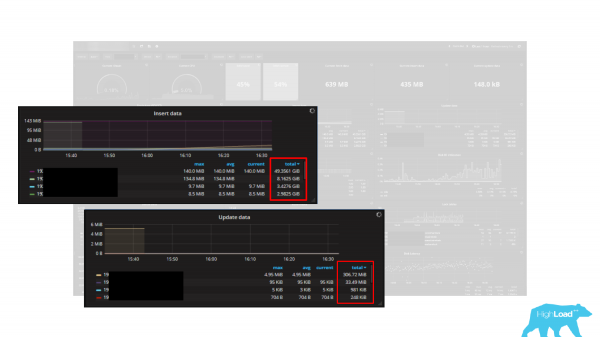
Existem vários gráficos. E os bytes são indicados como unidade, ou seja, existem 5 gráficos. Estes são Inserir dados, Atualizar dados, Excluir dados, Buscar dados e Retornar dados. A medida da unidade é bytes. Mas o fato é que as estatísticas no PostgreSQL retornam dados em tuplas (linhas). E, portanto, esses gráficos são uma ótima maneira de subestimar sua carga de trabalho várias vezes, dezenas de vezes, porque uma tupla não é um byte, uma tupla é uma string, tem muitos bytes e sempre tem comprimento variável. Ou seja, calcular a carga de trabalho em bytes usando tuplas é uma tarefa irreal ou muito difícil. Portanto, ao utilizar um dashboard ou monitoramento integrado, é sempre importante entender que ele funciona corretamente e retorna dados avaliados corretamente.

Como obter estatísticas sobre essas tabelas? Para isso, o PostgreSQL possui uma determinada família de visualizações. E a visão principal é . User_tables - significa tabelas criadas em nome do usuário. Em contraste, existem visualizações de sistema que são usadas pelo próprio PostgreSQL. E há uma tabela de resumo Alltables, que inclui as do sistema e do usuário. Você pode começar por qualquer um deles que mais gostar.
Usando os campos acima você pode estimar o número de inserções, atualizações e exclusões. O exemplo de dashboard que utilizei utiliza esses campos para avaliar as características de uma carga de trabalho. Portanto, também podemos construir sobre eles. Mas vale lembrar que são tuplas, não bytes, então não podemos fazer isso apenas em bytes.
Com base nesses dados, podemos construir as chamadas tabelas TopN. Por exemplo, Top-5, Top-10. E você pode rastrear as mesas quentes que são mais recicladas do que outras. Por exemplo, 5 tabelas “quentes” para inserção. E usando essas tabelas TopN avaliamos nossa carga de trabalho e podemos avaliar picos de carga de trabalho após quaisquer lançamentos, atualizações e implantações.
Também é importante avaliar o tamanho da tabela, porque às vezes os desenvolvedores lançam um novo recurso, e nossas tabelas começam a inchar em seus tamanhos grandes, porque decidiram adicionar uma quantidade adicional de dados, mas não previram como isso aconteceria. afetar o tamanho do banco de dados. Tais casos também nos surpreendem.

E agora uma pequena pergunta para você. Que pergunta surge quando você percebe a carga no servidor de banco de dados? Qual é a próxima pergunta que você tem?

Mas, na verdade, a questão surge da seguinte forma. Quais solicitações a carga causa? Ou seja, não é interessante olhar os processos que são causados pela carga. É claro que se o host tiver um banco de dados, então o banco de dados estará rodando lá e é claro que apenas os bancos de dados serão descartados lá. Se abrirmos o Top, veremos uma lista de processos no PostgreSQL que estão fazendo alguma coisa. Não ficará claro para Top o que eles estão fazendo.

Dessa forma, você precisa encontrar as consultas que causam maior carga, pois ajustar as consultas, via de regra, dá mais lucro do que ajustar o PostgreSQL ou a configuração do sistema operacional, ou mesmo ajustar o hardware. De acordo com minha estimativa, isso é aproximadamente 80-85-90%. E isso é feito muito mais rápido. É mais rápido corrigir uma solicitação do que corrigir a configuração, agendar uma reinicialização, especialmente se o banco de dados não puder ser reiniciado ou adicionar hardware. É mais fácil reescrever a consulta em algum lugar ou adicionar um índice para obter um resultado melhor desta consulta.
Nesse sentido, é necessário monitorar as solicitações e sua adequação. Vejamos outro exemplo de monitoramento. E aqui também parece haver um excelente monitoramento. Há informações sobre replicação, há informações sobre rendimento, bloqueio e utilização de recursos. Está tudo bem, mas não há informações sobre os pedidos. Não está claro quais consultas estão sendo executadas em nosso banco de dados, por quanto tempo estão sendo executadas, quantas dessas consultas são. Precisamos sempre ter essas informações em nosso monitoramento.

E para obter essas informações podemos usar o módulo pg_stat_statements. Com base nisso, você pode construir uma variedade de gráficos. Por exemplo, você pode obter informações sobre as consultas mais frequentes, ou seja, sobre as consultas que são executadas com mais frequência. Sim, após as implantações também é muito útil olhar e entender se há algum aumento nas solicitações.
Você pode monitorar as consultas mais longas, ou seja, aquelas que demoram mais para serem concluídas. Eles são executados no processador e consomem E/S. Também podemos avaliar isso usando os campos total_time, mean_time, blk_write_time e blk_read_time.
Podemos avaliar e monitorar as requisições mais pesadas em termos de uso de recursos, aquelas que leem do disco, que trabalham com memória, ou, ao contrário, criam algum tipo de carga de escrita.
Podemos avaliar os pedidos mais generosos. Estas são as consultas que retornam um grande número de linhas. Por exemplo, pode ser algum pedido em que se esqueceram de definir um limite. E simplesmente retorna todo o conteúdo da tabela ou consulta nas tabelas consultadas.
E você também pode monitorar consultas que usam arquivos temporários ou tabelas temporárias.

E ainda temos processos em segundo plano. Os processos em segundo plano são principalmente pontos de verificação ou também chamados de pontos de verificação, são autovacuum e replicação.
Outro exemplo de monitoramento. Há uma guia Manutenção à esquerda, acesse-a e espere ver algo útil. Mas aqui é apenas o momento da operação do vácuo e da coleta de estatísticas, nada mais. Esta é uma informação muito pobre, por isso precisamos sempre ter informações sobre como funcionam os processos em segundo plano em nosso banco de dados e se há algum problema em seu trabalho.

Quando olhamos para os pontos de verificação, devemos lembrar que os pontos de verificação liberam as páginas sujas da área de memória fragmentada para o disco e, em seguida, criam um ponto de verificação. E esse ponto de verificação pode então ser usado como um local de recuperação se o PostgreSQL for encerrado repentinamente em uma emergência.
Conseqüentemente, para liberar todas as páginas “sujas” no disco, você precisa escrever uma certa quantidade. E, via de regra, em sistemas com grande quantidade de memória, isso é muito. E se fizermos checkpoints com muita frequência em um intervalo curto, o desempenho do disco cairá significativamente. E as solicitações dos clientes sofrerão com a falta de recursos. Eles competirão por recursos e não terão produtividade.
Assim, através de pg_stat_bgwriter usando os campos especificados podemos monitorar o número de pontos de verificação que ocorrem. E se tivermos muitos postos de controle durante um determinado período de tempo (em 10-15-20 minutos, em meia hora), por exemplo, 3-4-5, então isso já pode ser um problema. E você já precisa olhar no banco de dados, olhar na configuração, o que causa tanta abundância de checkpoints. Talvez haja algum tipo de grande gravação acontecendo. Já podemos avaliar a carga de trabalho, pois já adicionamos gráficos de carga de trabalho. Já podemos ajustar os parâmetros do ponto de verificação e garantir que eles não afetem muito o desempenho da consulta.

Estou voltando ao autovacuum novamente porque é algo que, como eu disse, pode facilmente aumentar o desempenho do disco e da consulta, por isso é sempre importante estimar a quantidade de autovacuum.
O número de trabalhadores do autovacuum no banco de dados é limitado. Por padrão são três, então se sempre tivermos três trabalhadores trabalhando no banco de dados, isso significa que nosso autovacuum não está configurado, precisamos aumentar os limites, revisar as configurações do autovacuum e entrar na configuração.
É importante avaliar quais aspiradores temos. Ou foi lançado pelo usuário, o DBA veio e lançou manualmente algum tipo de vácuo, e isso criou uma carga. Temos algum tipo de problema. Ou este é o número de aspiradores que desenroscam o contador de transações. Para algumas versões do PostgreSQL estes são vácuos muito pesados. E eles podem facilmente aumentar o desempenho porque leem a tabela inteira e examinam todos os blocos dessa tabela.
E, claro, a duração dos vácuos. Se tivermos aspiradores de longa duração que funcionam por muito tempo, isso significa que precisamos novamente prestar atenção à configuração do vácuo e talvez reconsiderar suas configurações. Porque pode surgir uma situação em que o vácuo funciona na mesa por um longo tempo (3-4 horas), mas durante o tempo em que o vácuo funcionou, uma grande quantidade de linhas mortas conseguiu se acumular novamente na mesa. E assim que o vácuo for concluído, ele precisará aspirar esta mesa novamente. E chegamos a uma situação – um vácuo sem fim. E, neste caso, o vácuo não dá conta do seu trabalho e as tabelas gradualmente começam a aumentar de tamanho, embora o volume de dados úteis nelas permaneça o mesmo. Portanto, durante longos vácuos, sempre olhamos a configuração e tentamos otimizá-la, mas ao mesmo tempo para que o desempenho das solicitações do cliente não seja prejudicado.

Hoje em dia praticamente não existe instalação do PostgreSQL que não possua replicação de streaming. A replicação é o processo de mover dados de um mestre para uma réplica.
A replicação no PostgreSQL é feita através de um log de transações. O assistente gera um log de transações. O log de transações percorre a conexão de rede até a réplica e depois é reproduzido na réplica. É simples.
Conseqüentemente, a visualização pg_stat_replication é usada para monitorar o atraso da replicação. Mas nem tudo é simples com ela. Na versão 10, a visualização sofreu diversas alterações. Em primeiro lugar, alguns campos foram renomeados. E alguns campos foram adicionados. Na versão 10, surgiram campos que permitem estimar o atraso de replicação em segundos. É muito confortável. Antes da versão 10, era possível estimar o atraso de replicação em bytes. Esta opção permanece na versão 10, ou seja, você pode escolher o que é mais conveniente para você - estimar o atraso em bytes ou estimar o atraso em segundos. Muitas pessoas fazem as duas coisas.
Mesmo assim, para avaliar o atraso de replicação, é necessário saber a posição do log na transação. E essas posições do log de transações estão exatamente na visualização pg_stat_replication. Relativamente falando, podemos obter dois pontos no log de transações usando a função pg_xlog_location_diff(). Calcule o delta entre eles e obtenha o atraso de replicação em bytes. É muito conveniente e simples.
Na versão 10, esta função foi renomeada para pg_wal_lsn_diff(). Em geral, em todas as funções, visualizações e utilitários onde a palavra “xlog” apareceu, ela foi substituída pelo valor “wal”. Isso se aplica a visualizações e funções. Esta é uma grande inovação.
Além disso, na versão 10, foram adicionadas linhas que mostram especificamente o atraso. Estes são atraso de gravação, atraso de liberação e atraso de repetição. Ou seja, é importante monitorar essas coisas. Se percebermos que temos um atraso na replicação, precisamos investigar por que ele apareceu, de onde veio e corrigir o problema.

Quase tudo está em ordem com as métricas do sistema. Quando qualquer monitoramento começa, ele começa com as métricas do sistema. Trata-se do descarte de processadores, memória, swap, rede e disco. No entanto, muitos parâmetros não estão lá por padrão.
Se tudo estiver em ordem com o processo de reciclagem, haverá problemas com a reciclagem do disco. Como regra, os desenvolvedores de monitoramento adicionam informações sobre o rendimento. Pode ser em iops ou bytes. Mas eles esquecem a latência e a utilização dos dispositivos de disco. Esses são parâmetros mais importantes que nos permitem avaliar o quão carregados estão nossos discos e quão lentos eles são. Se tivermos alta latência, isso significa que há alguns problemas com os discos. Se tivermos alta utilização, significa que os discos não estão dando conta. Estas são características melhores do que o rendimento.
Além disso, essas estatísticas também podem ser obtidas no sistema de arquivos /proc, como é feito para processadores de reciclagem. Não sei por que essa informação não é agregada ao monitoramento. Mas mesmo assim é importante ter isso no seu acompanhamento.
O mesmo se aplica às interfaces de rede. Há informações sobre o rendimento da rede em pacotes, em bytes, mas mesmo assim não há informações sobre latência e nem informações sobre utilização, embora também sejam informações úteis.

Qualquer monitoramento tem desvantagens. E não importa que tipo de monitoramento você faça, nem sempre ele atenderá a alguns critérios. Mesmo assim, eles estão se desenvolvendo, novos recursos e coisas novas estão sendo adicionadas, então escolha algo e termine.
E para finalizar, você deve sempre ter uma ideia do que significam as estatísticas fornecidas e como você pode utilizá-las para resolver problemas.
E alguns pontos-chave:
- Você deve sempre monitorar a disponibilidade e ter dashboards para avaliar rapidamente se está tudo em ordem com o banco de dados.
- Você sempre precisa ter uma ideia de quais clientes estão trabalhando com seu banco de dados para eliminar clientes ruins e derrubá-los.
- É importante avaliar como esses clientes trabalham com os dados. Você precisa ter uma ideia sobre sua carga de trabalho.
- É importante avaliar como essa carga de trabalho é formada, com o auxílio de quais consultas. Você pode avaliar consultas, otimizá-las, refatorá-las e construir índices para elas. É muito importante.
- Os processos em segundo plano podem impactar negativamente as solicitações dos clientes, por isso é importante monitorar se eles não estão usando muitos recursos.
- As métricas do sistema permitem que você faça planos para dimensionar e aumentar a capacidade de seus servidores, por isso é importante rastreá-los e avaliá-los também.

Se você estiver interessado neste tópico, poderá seguir estes links.
- esta é a documentação oficial do coletor de estatísticas. Há uma descrição de todas as visualizações estatísticas e uma descrição de todos os campos. Você pode lê-los, compreendê-los e analisá-los. E com base neles, construa seus gráficos e adicione-os ao seu monitoramento.
Exemplos de solicitação:
Este é nosso repositório corporativo e meu. Eles contêm consultas de exemplo. Não há consultas da série select* from lá. Já existem consultas prontas com junções, usando funções interessantes que permitem transformar números brutos em valores legíveis e convenientes, ou seja, são bytes, tempo. Você pode pegá-los, observá-los, analisá-los, adicioná-los ao seu monitoramento, construir seu monitoramento com base neles.
perguntas
Pergunta: Você disse que não vai divulgar marcas, mas ainda estou curioso - que tipo de dashboard você usa em seus projetos?
Resposta: Varia. Acontece que chegamos a um cliente e ele já tem seu próprio monitoramento. E orientamos o cliente sobre o que precisa ser agregado ao seu monitoramento. A pior situação é com o Zabbix. Porque não tem capacidade de construir gráficos TopN. Nós mesmos usamos , porque estávamos consultando esses caras sobre monitoramento. Eles monitoraram o PostgreSQL com base em nossas especificações técnicas. Estou escrevendo meu próprio projeto de estimação, que coleta dados via Prometheus e os renderiza em . Minha tarefa é criar meu próprio exportador no Prometheus e depois renderizar tudo no Grafana.
Pergunta: Existem análogos aos relatórios AWR ou... agregação? Você sabe de algo assim?
Resposta: Sim, eu sei o que é AWR, é uma coisa legal. No momento, existem muitas bicicletas que implementam aproximadamente o seguinte modelo. Em algum intervalo de tempo, algumas linhas de base são gravadas no mesmo PostgreSQL ou em um armazenamento separado. Você pode pesquisá-los no Google na Internet, eles estão lá. Um dos desenvolvedores de tal coisa está no fórum sql.ru no tópico PostgreSQL. Você pode pegá-lo lá. Sim, existem essas coisas, elas podem ser usadas. Mais em seu Também estou escrevendo algo que permite que você faça a mesma coisa.
PS1 Se você estiver usando postgres_exporter, qual painel você está usando? Existem vários deles. Eles já estão desatualizados. Talvez a comunidade crie um modelo atualizado?
PS2 Removido o pganalyze porque é uma oferta SaaS proprietária que se concentra no monitoramento de desempenho e sugestões de ajuste automatizado.
Apenas usuários registrados podem participar da pesquisa. por favor
Qual monitoramento postgresql auto-hospedado (com painel) você considera o melhor?
30,0%Zabbix + adições de Alexey Lesovsky ou zabbix 4.4 ou libzbxpgsql + zabbix libzbxpgsql + zabbix3
0,0%https://github.com/lesovsky/pgcenter0
0,0%https://github.com/pg-monz/pg_monz0
20,0%https://github.com/cybertec-postgresql/pgwatch22
20,0%https://github.com/postgrespro/mamonsu2
0,0%https://www.percona.com/doc/percona-monitoring-and-management/conf-postgres.html0
10,0%pganalyze é um SaaS proprietário – não consigo excluí-lo1
10,0%https://github.com/powa-team/powa1
0,0%https://github.com/darold/pgbadger0
0,0%https://github.com/darold/pgcluu0
0,0%https://github.com/zalando/PGObserver0
10,0%https://github.com/spotify/postgresql-metrics1
10 usuários votaram. 26 usuários se abstiveram.
Fonte: habr.com
