


O principal objetivo do Patroni é fornecer Alta Disponibilidade para PostgreSQL. Mas o Patroni é apenas um modelo, não uma ferramenta pronta (o que, em geral, é dito na documentação). À primeira vista, depois de configurar o Patroni no laboratório de teste, você pode ver como é uma ótima ferramenta e com que facilidade lida com nossas tentativas de quebrar o cluster. Porém, na prática, em um ambiente de produção, nem sempre tudo acontece de forma tão bonita e elegante como em um laboratório de testes.

Vou contar um pouco sobre mim. Comecei como administrador de sistemas. Trabalhou em desenvolvimento web. Trabalho na Data Egret desde 2014. A empresa está envolvida em consultoria na área de Postgres. E atendemos exatamente Postgres, e trabalhamos com Postgres todos os dias, então temos diferentes expertises relacionados à operação.
E no final de 2018, começamos a usar o Patroni aos poucos. E alguma experiência foi acumulada. De alguma forma, diagnosticamos, ajustamos e chegamos às nossas melhores práticas. E neste relato falarei sobre eles.
Além do Postgres, eu gosto de LinuxAdoro mexer e explorar, e adoro compilar kernels. Adoro virtualização, contêineres, Docker e Kubernetes. Tenho interesse em tudo isso porque meus antigos hábitos de administração estão voltando. Adoro mexer com monitoramento. Também adoro coisas relacionadas ao Postgres e à administração, como replicação e backups. E no meu tempo livre, programo em Go. Não sou engenheiro de software, apenas programo em Go para mim mesmo. E gosto disso.

- Acho que muitos de vocês sabem que o Postgres não tem HA (alta disponibilidade) pronto para uso. Para obter o HA, você precisa instalar algo, configurá-lo, fazer um esforço e obtê-lo.
- Existem várias ferramentas e o Patroni é uma delas que resolve HA bem legal e muito bem. Mas colocando tudo em um laboratório de testes e rodando, a gente vê que dá certo, a gente consegue reproduzir alguns problemas, ver como o Patroni atende. E veremos que tudo funciona muito bem.
- Mas, na prática, enfrentamos problemas diferentes. E vou falar sobre esses problemas.
- Vou lhe contar como diagnosticamos, o que ajustamos - se isso nos ajudou ou não.

- Não vou te dizer como instalar o Patroni, porque você pode pesquisar no Google na Internet, pode olhar os arquivos de configuração para entender como tudo começa, como está configurado. Você pode entender os esquemas, arquiteturas, encontrando informações sobre isso na Internet.
- Não vou falar sobre a experiência de outra pessoa. Vou falar apenas sobre os problemas que enfrentamos.
- E não vou falar de problemas que estão fora do Patroni e do PostgreSQL. Se, por exemplo, houver problemas associados ao balanceamento, quando nosso cluster entrar em colapso, não falarei sobre isso.

E um pequeno aviso antes de começarmos nosso relatório.
Todos esses problemas que encontramos, tivemos nos primeiros 6-7-8 meses de operação. Com o tempo, chegamos às nossas melhores práticas internas. E nossos problemas desapareceram. Portanto, o relatório foi anunciado há cerca de seis meses, quando tudo estava fresco na minha cabeça e eu me lembrava perfeitamente.
Enquanto preparava o relatório, já levantei velhas autópsias, examinei os registros. E alguns detalhes podem ser esquecidos, ou alguns detalhes não puderam ser totalmente investigados durante a análise dos problemas, então em alguns pontos pode parecer que os problemas não são totalmente considerados, ou há alguma falta de informação. E por isso peço que me desculpem por este momento.

O que é Patroni?
- Este é um modelo para construir HA. É o que diz na documentação. E do meu ponto de vista, este é um esclarecimento muito correto. O Patroni não é uma bala de prata que vai resolver todos os seus problemas, ou seja, você precisa se esforçar para que dê certo e traga benefícios.
- Este é um serviço de agente que é instalado em todos os serviços de banco de dados e é uma espécie de sistema init para seu Postgres. Ele inicia o Postgres, para, reinicia, reconfigura e altera a topologia do seu cluster.
- Assim, para armazenar o estado do cluster, sua representação atual, ao que parece, é necessário algum tipo de armazenamento. E desse ponto de vista, Patroni tomou o caminho de armazenar o estado em um sistema externo. É um sistema de armazenamento de configuração distribuída. Pode ser Etcd, Consul, ZooKeeper ou kubernetes Etcd, ou seja, uma dessas opções.
- E um dos recursos do Patroni é que você tira o autofiler da caixa, apenas configurando-o. Se tomarmos Repmgr para comparação, o arquivador será incluído lá. Com Repmgr, obtemos uma transição, mas se quisermos um autofiler, precisamos configurá-lo adicionalmente. O Patroni já possui um autofiler pronto para uso.
- E há muitas outras coisas. Por exemplo, manutenção de configurações, vazamento de novas réplicas, backup, etc. Mas isso está fora do escopo do relatório, não vou falar sobre isso.

E um pequeno resultado é que a principal tarefa do Patroni é fazer um autofile bem e confiável para que nosso cluster permaneça operacional e o aplicativo não perceba alterações na topologia do cluster.

Mas quando começamos a usar o Patroni, nosso sistema fica um pouco mais complicado. Se antes tínhamos o Postgres, ao usar o Patroni obtemos o próprio Patroni, obtemos o DCS onde o estado é armazenado. E tudo tem que funcionar de alguma forma. Então, o que pode dar errado?
Pode quebrar:
- Postgres pode quebrar. Pode ser um mestre ou uma réplica, um deles pode falhar.
- O próprio Patroni pode quebrar.
- O DCS onde o estado é armazenado pode quebrar.
- E a rede pode quebrar.
Todos esses pontos eu considerarei no relatório.

Vou considerar os casos à medida que se tornam mais complexos, não do ponto de vista de que o caso envolve muitos componentes. E do ponto de vista dos sentimentos subjetivos, que esse caso foi difícil para mim, foi difícil desmontá-lo ... e vice-versa, algum caso era leve e era fácil desmontá-lo.

E o primeiro caso é o mais fácil. Esse é o caso quando pegamos um cluster de banco de dados e implantamos nosso armazenamento DCS no mesmo cluster. Este é o erro mais comum. Isso é um erro na construção de arquiteturas, ou seja, combinar diferentes componentes em um só lugar.
Então, houve um arquivo, vamos lidar com o que aconteceu.

E aqui estamos interessados em saber quando o arquivador aconteceu. Ou seja, estamos interessados nesse momento no tempo em que o estado do cluster mudou.
Mas o filer nem sempre é instantâneo, ou seja, não leva nenhuma unidade de tempo, pode ser atrasado. Pode ser duradouro.
Portanto, tem um horário de início e um horário de término, ou seja, é um evento contínuo. E dividimos todos os eventos em três intervalos: temos tempo antes do arquivador, durante o arquivador e depois do arquivador. Ou seja, consideramos todos os eventos nesta linha do tempo.

E a primeira coisa, quando aconteceu um arquivador, a gente procura a causa do que aconteceu, qual foi a causa do que levou ao arquivador.
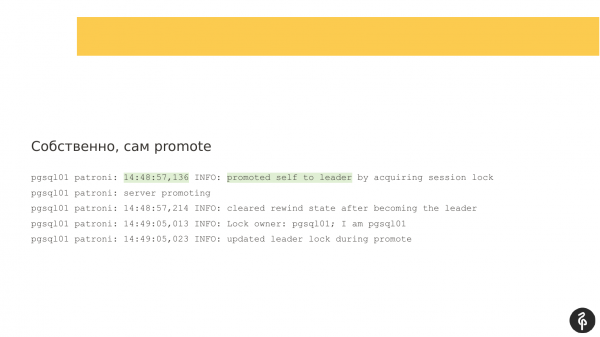
Se olharmos para os logs, eles serão logs clássicos do Patroni. Ele nos diz que o servidor se tornou o mestre e a função do mestre passou para este nó. Aqui está destacado.

Em seguida, precisamos entender por que o arquivador aconteceu, ou seja, quais eventos ocorreram que fizeram com que a função mestre se movesse de um nó para outro. E neste caso, tudo é simples. Ocorreu um erro ao interagir com o sistema de armazenamento. O mestre percebeu que não poderia trabalhar com DCS, ou seja, havia algum tipo de problema na interação. E ele diz que não pode mais ser mestre e se demite. Esta linha “auto rebaixado” diz exatamente isso.

Se olharmos para os eventos que precederam o arquivador, podemos ver aí os próprios motivos que foram o problema para a continuação do assistente.
Se olharmos os logs do Patroni, veremos que temos muitos erros, timeouts, ou seja, o agente Patroni não consegue trabalhar com DCS. Neste caso, este é o agente Consul, que está se comunicando na porta 8500.
O problema aqui é que o Patroni e o banco de dados estão rodando no mesmo host. Os servidores Consul também estavam rodando nesse mesmo host. Ao sobrecarregar o servidor, criamos problemas para servidores Cônsul. Eles não conseguiam se comunicar normalmente.

Depois de algum tempo, quando a carga diminuiu, nosso Patroni conseguiu se comunicar novamente com os agentes. Trabalho normal retomado. E o mesmo servidor Pgdb-2 tornou-se o mestre novamente. Ou seja, houve um pequeno flip, pelo qual o nó renunciou aos poderes do mestre, para depois retomá-los, ou seja, tudo voltou como estava.

E isso pode ser considerado um alarme falso, ou pode-se considerar que Patroni fez tudo certo. Ou seja, ele percebeu que não conseguiria manter o estado do cluster e retirou sua autoridade.
E aqui surgiu o problema pelo fato dos servidores Consul estarem no mesmo hardware das bases. Da mesma forma, qualquer carga: seja a carga em discos ou processadores, também afeta a interação com o cluster Consul.

E decidimos que não deveria morar junto, alocamos um cluster separado para o Consul. E o Patroni já trabalhava com um Consul separado, ou seja, tinha um cluster Postgres separado, um cluster Consul separado. Esta é uma instrução básica sobre como carregar e guardar todas essas coisas para que não vivam juntas.
Como opção, você pode torcer os parâmetros ttl, loop_wait, retry_timeout, ou seja, tente sobreviver a esses picos de carga de curto prazo aumentando esses parâmetros. Mas esta não é a opção mais adequada, pois essa carga pode demorar muito. E simplesmente iremos além desses limites desses parâmetros. E isso pode não ajudar muito.
O primeiro problema, como você entende, é simples. Pegamos e colocamos o DCS junto com a base, deu um problema.

O segundo problema é semelhante ao primeiro. É semelhante porque novamente temos problemas de interoperabilidade com o sistema DCS.

Se olharmos os logs, veremos que novamente temos um erro de comunicação. E Patroni diz que não posso interagir com o DCS, então o mestre atual entra no modo de réplica.
O velho mestre se torna uma réplica, aqui o Patroni funciona, como deveria ser. Ele executa pg_rewind para rebobinar o log de transações e, em seguida, conecta-se ao novo mestre para alcançá-lo. Aqui Patroni trabalha, como deveria.

Aqui devemos encontrar o local que precedeu o filer, ou seja, aqueles erros que nos levaram a ter um filer. E, a esse respeito, os logs do Patroni são bastante convenientes para trabalhar. Ele escreve as mesmas mensagens em um determinado intervalo. E se começarmos a percorrer esses logs rapidamente, veremos nos logs que os logs foram alterados, o que significa que alguns problemas começaram. Voltamos rapidamente a este lugar, para ver o que acontece.
E em uma situação normal, os logs se parecem com isso. O proprietário do bloqueio é verificado. E se o proprietário, por exemplo, mudou, podem ocorrer alguns eventos aos quais o Patroni deve responder. Mas neste caso, estamos bem. Estamos procurando o local onde os erros começaram.

E tendo rolado até o ponto em que os erros começaram a aparecer, vemos que tivemos um auto-fileover. E como nossos erros estavam relacionados à interação com o DCS e no nosso caso usamos o Consul, também olhamos os logs do Consul, o que aconteceu lá.
Comparando aproximadamente o tempo do arquivador e o tempo nos logs Consul, vemos que nossos vizinhos no cluster Consul começaram a duvidar da existência de outros membros do cluster Consul.

E se você olhar os logs de outros agentes Consul, também poderá ver que há algum tipo de colapso de rede acontecendo ali. E todos os membros do grupo Consul duvidam da existência uns dos outros. E esse foi o ímpeto para o arquivador.
Se você observar o que aconteceu antes desses erros, verá que há todos os tipos de erros, por exemplo, deadline, RPC caído, ou seja, há claramente algum tipo de problema na interação dos membros do cluster Consul uns com os outros .

A resposta mais simples é reparar a rede. Mas para mim, estando no pódio, é fácil dizer isso. Mas as circunstâncias são tais que nem sempre o cliente pode pagar pelo reparo da rede. Ele pode morar em um DC e pode não conseguir consertar a rede, afetar os equipamentos. E assim algumas outras opções são necessárias.

Existem opções:
- A opção mais simples, que está escrita, na minha opinião, até na documentação, é desabilitar as verificações do Consul, ou seja, simplesmente passar um array vazio. E dizemos ao agente Consul para não usar cheques. Com essas verificações, podemos ignorar essas tempestades de rede e não iniciar um arquivador.
- Outra opção é verificar novamente raft_multiplier. Este é um parâmetro do próprio servidor Consul. Por padrão, é definido como 5. Esse valor é recomendado pela documentação para ambientes de preparação. Na verdade, isso afeta a frequência das mensagens entre os membros da rede Consul. Na verdade, esse parâmetro afeta a velocidade de comunicação do serviço entre os membros do cluster Consul. E para produção, já é recomendável reduzi-lo para que os nós troquem mensagens com mais frequência.
- Outra opção que encontramos é aumentar a prioridade dos processos do Consul entre outros processos para o agendador de processos do sistema operacional. Existe um parâmetro tão “bom”, ele apenas determina a prioridade dos processos que é levado em consideração pelo agendador do SO ao agendar. Também reduzimos o valor do nice para agentes Consul, ou seja, aumentou a prioridade para que o sistema operacional dê aos processos Consul mais tempo para trabalhar e executar seu código. No nosso caso, isso resolveu nosso problema.
- Outra opção é não usar Consul. Tenho um amigo que é um grande apoiador do Etcd. E discutimos regularmente com ele qual é o melhor Etcd ou Consul. Mas em relação ao que é melhor, geralmente concordamos com ele que o Consul tem um agente que deve estar rodando em cada nó com um banco de dados. Ou seja, a interação do Patroni com o cluster Consul passa por esse agente. E esse agente vira um gargalo. Se algo acontecer com o agente, o Patroni não poderá mais trabalhar com o cluster Consul. E esse é o problema. Não há agente no plano Etcd. O Patroni pode trabalhar diretamente com uma lista de servidores Etcd e já se comunicar com eles. Nesse sentido, se você usa o Etcd em sua empresa, provavelmente o Etcd será uma escolha melhor do que o Consul. Mas nós, nossos clientes, sempre somos limitados pelo que o cliente escolheu e usa. E temos Consul na maioria para todos os clientes.
- E o último ponto é revisar os valores dos parâmetros. Podemos aumentar esses parâmetros na esperança de que nossos problemas de rede de curto prazo sejam curtos e não fiquem fora do intervalo desses parâmetros. Desta forma, podemos reduzir a agressividade do Patroni para autofile se ocorrerem alguns problemas de rede.
Acho que muitos que usam o Patroni estão familiarizados com esse comando.
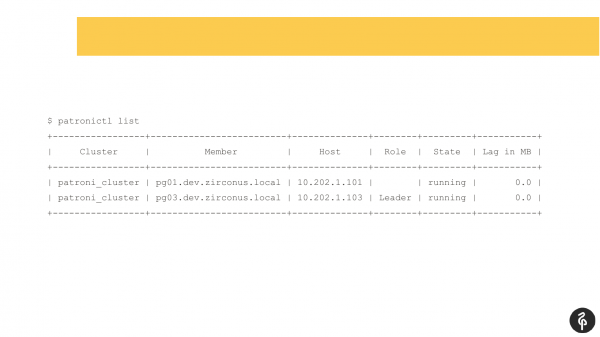
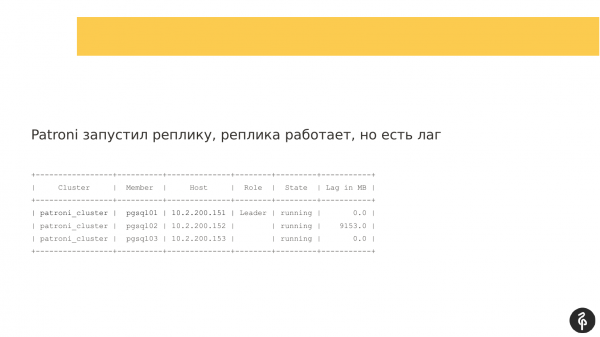
Este comando mostra o estado atual do cluster. E à primeira vista, essa imagem pode parecer normal. Temos um mestre, temos uma réplica, não há atraso na replicação. Mas esse quadro é normal exatamente até sabermos que esse cluster deve ter três nós, não dois.

Assim, houve um autofile. E depois desse autofile, nossa réplica desapareceu. Precisamos descobrir por que ela desapareceu e trazê-la de volta, restaurá-la. E novamente vamos aos logs e vemos por que tivemos um fileover automático.

Nesse caso, a segunda réplica se tornou a master. Está tudo bem aqui.

E precisamos olhar para a réplica que caiu e que não está no cluster. Abrimos os logs do Patroni e vemos que tivemos um problema durante o processo de conexão com o cluster no estágio pg_rewind. Para se conectar ao cluster, você precisa retroceder o log de transações, solicitar o log de transações necessário do mestre e usá-lo para alcançar o mestre.
Nesse caso, não temos um log de transações e a réplica não pode ser iniciada. Assim, paramos o Postgres com um erro. E, portanto, não está no cluster.

Precisamos entender por que não está no cluster e por que não havia logs. Vamos ao novo mestre e olhamos o que ele tem nas toras. Acontece que quando o pg_rewind foi concluído, ocorreu um ponto de verificação. E alguns dos logs de transações antigos foram simplesmente renomeados. Quando o antigo mestre tentou se conectar ao novo mestre e consultar esses logs, eles já estavam renomeados, simplesmente não existiam.

Eu comparei carimbos de data/hora quando esses eventos aconteceram. E aí a diferença é literalmente 150 milissegundos, ou seja, o checkpoint concluído em 369 milissegundos, os segmentos WAL foram renomeados. E literalmente em 517, após 150 milissegundos, o retrocesso começou na réplica antiga. Ou seja, literalmente 150 milissegundos foram suficientes para nós, para que a réplica não pudesse se conectar e ganhar.

Quais são as opções?
Inicialmente usamos slots de replicação. Nós pensamos que era bom. Embora no primeiro estágio de operação tenhamos desligado os slots. Pareceu-nos que, se os slots acumularem muitos segmentos WAL, podemos descartar o mestre. Ele vai cair. Sofremos por algum tempo sem slots. E percebemos que precisamos de slots, devolvemos os slots.
Mas há um problema aqui, quando o mestre vai para a réplica, ele apaga os slots e apaga os segmentos WAL junto com os slots. E para eliminar esse problema, decidimos aumentar o parâmetro wal_keep_segments. O padrão é 8 segmentos. Aumentamos para 1 e verificamos quanto espaço livre tínhamos. E doamos 000 gigabytes para wal_keep_segments. Ou seja, ao alternar, sempre temos uma reserva de 16 gigabytes de logs de transações em todos os nós.
E mais - ainda é relevante para tarefas de manutenção de longo prazo. Digamos que precisamos atualizar uma das réplicas. E queremos desligá-lo. Precisamos atualizar o software, talvez o sistema operacional, outra coisa. E quando desligamos uma réplica, o slot dessa réplica também é removido. E se usarmos um pequeno wal_keep_segments, com uma longa ausência de uma réplica, os logs de transação serão perdidos. Levantaremos uma réplica, ela solicitará aqueles logs de transações onde parou, mas podem não estar no master. E a réplica também não conseguirá se conectar. Por isso, mantemos um grande estoque de revistas.

Nós temos uma base de produção. Já existem projetos em andamento.
Havia um arquivador. Entramos e olhamos - está tudo em ordem, as réplicas estão no lugar, não há atraso na replicação. Também não há erros nos logs, está tudo em ordem.
A equipe de produto diz que deveria haver alguns dados, mas os vemos de uma fonte, mas não os vemos no banco de dados. E precisamos entender o que aconteceu com eles.

É claro que pg_rewind sentiu falta deles. Nós imediatamente entendemos isso, mas fomos ver o que estava acontecendo.

Nos logs, podemos sempre encontrar quando o filer aconteceu, quem se tornou o master, e podemos determinar quem era o antigo master e quando ele queria se tornar uma réplica, ou seja, precisamos desses logs para saber a quantidade de logs de transação que estava perdido.
Nosso antigo mestre foi reiniciado. E Patroni foi registrado no autorun. Lançado Patroni. Ele então iniciou o Postgres. Mais precisamente, antes de iniciar o Postgres e antes de torná-lo uma réplica, Patroni lançou o processo pg_rewind. Assim, ele apagou parte dos logs de transações, baixou novos e conectou. Aqui Patroni funcionou de forma inteligente, ou seja, conforme o esperado. O cluster foi restaurado. Tínhamos 3 nós, depois do arquivador 3 nós - tudo bem.

Perdemos alguns dados. E precisamos entender o quanto perdemos. Estamos procurando apenas o momento em que tivemos um retrocesso. Podemos encontrá-lo em tais entradas de diário. Rewind começou, fez algo lá e terminou.

Precisamos encontrar a posição no log de transações onde o mestre antigo parou. Neste caso, esta é a marca. E precisamos de uma segunda marca, ou seja, a distância pela qual o antigo mestre difere do novo.
Pegamos o pg_wal_lsn_diff usual e comparamos essas duas marcas. E neste caso, obtemos 17 megabytes. Muito ou pouco, cada um decide por si. Porque para alguém 17 megabytes não é muito, para alguém é muito e inaceitável. Aqui, cada indivíduo determina por si mesmo de acordo com as necessidades do negócio.

Mas o que descobrimos por nós mesmos?
Primeiro, devemos decidir por nós mesmos - sempre precisamos que o Patroni inicie automaticamente após a reinicialização do sistema? Muitas vezes acontece que temos que ir ao velho mestre, ver até onde ele foi. Talvez inspecione segmentos do log de transações, veja o que está lá. E para entender se podemos perder esses dados ou se precisamos executar o antigo mestre no modo autônomo para extrair esses dados.
E somente depois disso devemos decidir se podemos descartar esses dados ou podemos restaurá-los, conectar esse nó como uma réplica ao nosso cluster.
Além disso, há um parâmetro "maximum_lag_on_failover". Por padrão, se não me falha a memória, esse parâmetro tem o valor de 1 megabyte.
Como ele funciona? Se nossa réplica estiver atrasada em 1 megabyte de dados no atraso da replicação, essa réplica não participará das eleições. E se de repente houver um fileover, Patroni verifica quais réplicas estão ficando para trás. Se eles estiverem atrasados por um grande número de logs de transações, eles não poderão se tornar um mestre. Este é um recurso de segurança muito bom que evita que você perca muitos dados.
Mas há um problema em que o atraso de replicação no cluster Patroni e DCS é atualizado em um determinado intervalo. Acho que 30 segundos é o valor ttl padrão.
Conseqüentemente, pode haver uma situação em que haja um atraso de replicação para réplicas no DCS, mas na verdade pode haver um atraso completamente diferente ou pode não haver nenhum atraso, ou seja, isso não é em tempo real. E nem sempre reflete a imagem real. E não vale a pena fazer uma lógica sofisticada nisso.
E o risco de perda sempre permanece. E no pior caso, uma fórmula, e no caso médio, outra fórmula. Ou seja, quando planejamos a implementação do Patroni e avaliamos quantos dados podemos perder, devemos nos basear nessas fórmulas e imaginar aproximadamente quantos dados podemos perder.
E há boas notícias. Quando o antigo mestre avança, ele pode prosseguir devido a alguns processos em segundo plano. Ou seja, houve algum tipo de autovácuo, ele anotou os dados, salvou no log de transações. E podemos facilmente ignorar e perder esses dados. Não há problema nisso.

E é assim que os logs se parecem se maximum_lag_on_failover estiver definido e um arquivador tiver ocorrido e você precisar selecionar um novo mestre. A réplica se avalia como incapaz de participar das eleições. E ela se recusa a participar da corrida pelo líder. E ela espera que um novo mestre seja selecionado, para então se conectar a ele. Esta é uma medida adicional contra a perda de dados.

Aqui temos uma equipe de produto que escreveu que seu produto está tendo problemas com o Postgres. Ao mesmo tempo, o próprio mestre não pode ser acessado, pois não está disponível via SSH. E o autofile também não acontece.
Este host foi forçado a reiniciar. Por causa da reinicialização, ocorreu um arquivo automático, embora fosse possível fazer um arquivo automático manual, como agora entendo. E após a reinicialização, já veremos o que tínhamos com o mestre atual.
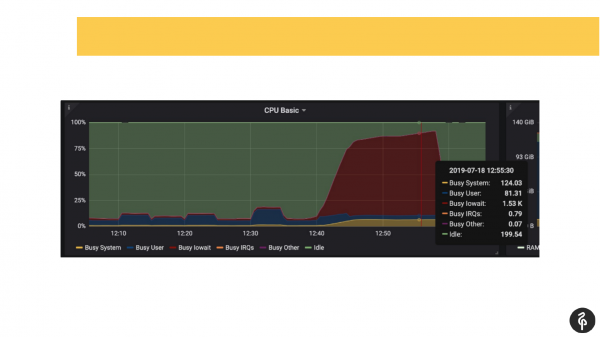
Ao mesmo tempo, sabíamos de antemão que tínhamos problemas com os discos, ou seja, já sabíamos pelo monitoramento onde cavar e o que procurar.

Entramos no log do postgres, começamos a ver o que estava acontecendo lá. Vimos commits que duram ali um, dois, três segundos, o que não é nada normal. Vimos que nosso autovacuum inicia de forma muito lenta e estranha. E vimos arquivos temporários no disco. Ou seja, todos esses são indicadores de problemas com discos.

Examinamos o dmesg do sistema (log do kernel). E vimos que temos problemas com um dos discos. O subsistema de disco era o software Raid. Examinamos /proc/mdstat e vimos que faltava uma unidade. Ou seja, há um Raid de 8 discos, falta um. Se você olhar atentamente para o slide, verá na saída que não temos sde lá. Para nós, condicionalmente falando, o disco caiu. Isso desencadeou problemas de disco e os aplicativos também tiveram problemas ao trabalhar com o cluster Postgres.

E nesse caso o Patroni não iria nos ajudar em nada, porque o Patroni não tem a função de monitorar o estado do servidor, o estado do disco. E devemos monitorar tais situações por monitoramento externo. Adicionamos rapidamente o monitoramento de disco ao monitoramento externo.
E houve tal pensamento - o software de esgrima ou cão de guarda poderia nos ajudar? Achamos que dificilmente ele teria nos ajudado neste caso, pois durante os problemas o Patroni continuou interagindo com o cluster DCS e não viu nenhum problema. Ou seja, do ponto de vista do DCS e do Patroni, estava tudo bem com o cluster, embora na verdade houvesse problemas com o disco, havia problemas com a disponibilidade do banco de dados.
Na minha opinião, este é um dos problemas mais estranhos que pesquisei por muito tempo, li muitos logs, escolhi novamente e chamei de simulador de cluster.

O problema era que o mestre antigo não conseguia se tornar uma réplica normal, ou seja, Patroni começou, Patroni mostrou que esse nó estava presente como uma réplica, mas ao mesmo tempo não era uma réplica normal. Agora você vai ver o porquê. Isso é o que guardei da análise desse problema.

E como tudo começou? Começou, como no problema anterior, com freios a disco. Tivemos confirmações por um segundo, dois.

Houve quebras nas conexões, ou seja, clientes foram interrompidos.

Houve bloqueios de gravidade variável.

E, portanto, o subsistema de disco não responde muito bem.

E o mais misterioso para mim é o pedido de desligamento imediato que chegou. Postgres tem três modos de desligamento:
- É gracioso quando esperamos que todos os clientes se desconectem por conta própria.
- É rápido quando forçamos os clientes a desconectar porque vamos desligar.
- E imediato. Nesse caso, o imediato nem diz aos clientes para desligar, apenas desliga sem avisar. E para todos os clientes, o sistema operacional já envia uma mensagem RST (uma mensagem TCP de que a conexão foi interrompida e o cliente não tem mais nada para pegar).
Quem enviou este sinal? Os processos em segundo plano do Postgres não enviam esses sinais entre si, ou seja, isso é kill-9. Eles não enviam essas coisas um para o outro, eles apenas reagem a essas coisas, ou seja, esta é uma reinicialização de emergência do Postgres. Quem mandou, não sei.
Eu olhei para o comando "último" e vi uma pessoa que também logou neste servidor conosco, mas fiquei com vergonha de fazer uma pergunta. Talvez tenha sido matar -9. Eu veria kill -9 nos logs, porque Postgres diz que levou kill -9, mas não vi nos logs.

Olhando mais adiante, vi que Patroni não gravava no log por um bom tempo - 54 segundos. E se compararmos dois timestamps, não houve mensagens por cerca de 54 segundos.
E durante esse tempo houve um autofile. Patroni fez um ótimo trabalho aqui novamente. Nosso antigo mestre não estava disponível, algo aconteceu com ele. E a eleição de um novo mestre começou. Tudo funcionou bem aqui. Nosso pgsql01 se tornou o novo líder.

Temos uma réplica que se tornou mestre. E há uma segunda resposta. E houve problemas com a segunda réplica. Ela tentou reconfigurar. Pelo que entendi, ela tentou alterar o recovery.conf, reiniciar o Postgres e conectar-se ao novo mestre. Ela escreve mensagens a cada 10 segundos que está tentando, mas não está conseguindo.

E durante essas tentativas, um sinal de desligamento imediato chega ao antigo mestre. O mestre é reiniciado. E também a recuperação pára porque o antigo mestre entra em reinicialização. Ou seja, a réplica não consegue se conectar a ela, pois está em modo de desligamento.

Em algum momento funcionou, mas a replicação não começou.
Meu único palpite é que havia um endereço mestre antigo em recovery.conf. E quando um novo mestre apareceu, a segunda réplica ainda tentou se conectar ao antigo mestre.
Quando o Patroni foi inicializado na segunda réplica, o nó foi inicializado, mas não pôde ser replicado. E um atraso de replicação foi formado, que se parecia com isso. Ou seja, todos os três nós estavam no lugar, mas o segundo nó ficou para trás.
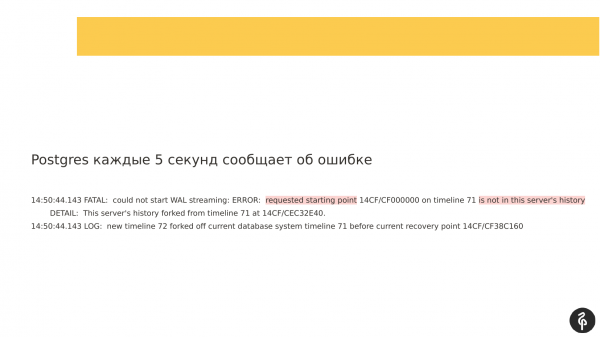
Ao mesmo tempo, se você observar os logs que foram gravados, poderá ver que a replicação não pôde ser iniciada porque os logs de transação eram diferentes. E os logs de transação que o mestre oferece, especificados em recovery.conf, simplesmente não se encaixam em nosso nó atual.

E aqui eu cometi um erro. Eu tive que vir e ver o que estava em recovery.conf para testar minha hipótese de que estávamos nos conectando com o master errado. Mas então eu estava apenas lidando com isso e não me ocorreu, ou vi que a réplica estava ficando para trás e teria que ser recarregada, ou seja, de alguma forma trabalhei descuidadamente. Este era o meu baseado.

Após 30 minutos, o administrador já veio, ou seja, reiniciei o Patroni na réplica. Eu já acabei com isso, pensei que teria que ser reabastecido. E pensei - vou reiniciar o Patroni, talvez algo bom aconteça. Recuperação iniciada. E a base mesmo aberta, já estava pronta para receber conexões.
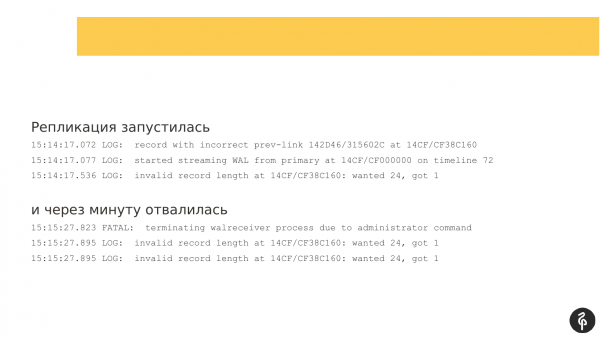
A replicação foi iniciada. Mas um minuto depois, ela caiu com um erro de que os logs de transação não são adequados para ela.

Eu pensei em reiniciar novamente. Reiniciei o Patroni novamente e não reiniciei o Postgres, mas reiniciei o Patroni na esperança de que ele iniciasse magicamente o banco de dados.

A replicação começou novamente, mas as marcas no log de transações eram diferentes, não eram as mesmas da tentativa de início anterior. A replicação parou novamente. E a mensagem já era um pouco diferente. E não foi muito informativo para mim.

E então me ocorre - e se eu reiniciar o Postgres, neste momento eu fizer um checkpoint no mestre atual para mover o ponto no log de transações um pouco para frente para que a recuperação comece em outro momento? Além disso, ainda tínhamos estoques de WAL.

Reiniciei o Patroni, fiz alguns pontos de verificação no mestre, alguns pontos de reinicialização na réplica quando ela foi aberta. E ajudou. Pensei por muito tempo por que isso ajudou e como funcionou. E a réplica começou. E a replicação não foi mais rasgada.

Esse problema para mim é um dos mais misteriosos, sobre os quais ainda me pergunto o que realmente aconteceu lá.
Quais são as implicações aqui? Patroni pode funcionar como pretendido e sem erros. Mas, ao mesmo tempo, isso não é uma garantia de 100% de que está tudo bem conosco. A réplica pode ser iniciada, mas pode estar em estado semi-funcional e o aplicativo não pode funcionar com essa réplica, porque haverá dados antigos.
E depois do arquivador, você sempre precisa verificar se está tudo em ordem com o cluster, ou seja, se há o número necessário de réplicas, não há atraso na replicação.
E enquanto passamos por essas questões, farei recomendações. Tentei combiná-los em dois slides. Provavelmente, todas as histórias poderiam ser combinadas em dois slides e apenas contadas.

Quando você usa o Patroni, você deve ter monitoramento. Você sempre deve saber quando ocorreu um autofileover, porque se não souber que teve um autofileover, não terá controle sobre o cluster. E isso é ruim.
Após cada filer, sempre temos que verificar manualmente o cluster. Precisamos ter certeza de que sempre temos um número de réplicas atualizado, não há lag de replicação, não há erros nos logs relacionados à replicação de streaming, com Patroni, com o sistema DCS.
A automação pode funcionar com sucesso, o Patroni é uma ferramenta muito boa. Pode funcionar, mas não levará o cluster ao estado desejado. E se não descobrirmos, estaremos em apuros.
E Patroni não é uma bala de prata. Ainda precisamos entender como funciona o Postgres, como funciona a replicação e como funciona o Patroni com o Postgres, e como é feita a comunicação entre os nós. Isso é necessário para poder resolver problemas com as mãos.

Como abordar a questão do diagnóstico? Acontece que trabalhamos com clientes diferentes e ninguém tem pilha ELK, e temos que separar os logs abrindo 6 consoles e 2 abas. Em uma guia, esses são os logs do Patroni para cada nó, na outra guia, esses são os logs do Consul ou do Postgres, se necessário. É muito difícil diagnosticar isso.
Que abordagens desenvolvi? Primeiro, sempre olho quando o arquivador chega. E para mim isso é um divisor de águas. Eu vejo o que aconteceu antes do arquivador, durante o arquivador e depois do arquivador. O fileover tem duas marcas: esta é a hora inicial e final.
Em seguida, procuro nos logs eventos anteriores ao arquivador, que precederam o arquivador, ou seja, procuro os motivos pelos quais o arquivador aconteceu.
E isso dá uma imagem de entender o que aconteceu e o que pode ser feito no futuro para que tais circunstâncias não ocorram (e, como resultado, não há arquivo).
E onde costumamos olhar? Eu olho:
- Primeiro, para os logs do Patroni.
- Em seguida, examino os logs do Postgres ou os logs do DCS, dependendo do que foi encontrado nos logs do Patroni.
- E os logs do sistema às vezes também fornecem uma compreensão do que causou o arquivador.

O que eu acho do Patroni? Tenho uma relação muito boa com o Patroni. Na minha opinião, é o melhor que existe hoje. Conheço muitos outros produtos. Estes são Stolon, Repmgr, Pg_auto_failover, PAF. 4 ferramentas. Eu tentei todos eles. Patroni é o meu favorito.
Se me perguntarem: "Recomendo o Patroni?". Direi que sim, porque gosto do Patroni. E acho que aprendi a cozinhá-lo.
Se você estiver interessado em ver quais outros problemas existem com o Patroni além dos problemas que mencionei, você sempre pode conferir a página no GitHub. Existem muitas histórias diferentes e muitas questões interessantes são discutidas lá. E como resultado, alguns bugs foram introduzidos e resolvidos, ou seja, esta é uma leitura interessante.
Existem algumas histórias interessantes sobre pessoas que deram tiros no próprio pé. Muito informativo. Você leu e entendeu que não é necessário fazê-lo. Eu me marquei.
E gostaria de agradecer muito a Zalando por desenvolver este projeto, nomeadamente a Alexander Kukushkin e Alexey Klyukin. Aleksey Klyukin é um dos coautores, ele não trabalha mais na Zalando, mas são duas pessoas que começaram a trabalhar com este produto.
E eu acho que o Patroni é uma coisa muito legal. Estou feliz que ela exista, é interessante para ela. E um grande obrigado a todos os contribuidores que escrevem patches para o Patroni. Espero que Patroni se torne mais maduro, legal e eficiente com a idade. Já está funcional, mas espero que fique ainda melhor. Portanto, se você planeja usar o Patroni, não tenha medo. Esta é uma boa solução, pode ser implementada e usada.
Isso é tudo. Se você possui dúvidas, pergunte.

perguntas
Obrigado pelo relatório! Se depois de um arquivador você ainda precisa olhar com muito cuidado, por que precisamos de um arquivador automático?
Porque é uma coisa nova. Estamos com ela há apenas um ano. Melhor estar seguro. Queremos entrar e ver que tudo realmente funcionou como deveria. Este é o nível de desconfiança dos adultos - é melhor verificar novamente e ver.
Por exemplo, a gente ia de manhã e olhava, né?
Não pela manhã, geralmente aprendemos sobre o autofile quase imediatamente. Recebemos notificações, vemos que ocorreu um arquivo automático. Nós quase imediatamente vamos e olhamos. Mas todas essas verificações devem ser trazidas para o nível de monitoramento. Se você acessar o Patroni por meio da API REST, haverá um histórico. Pelo histórico, você pode ver os carimbos de data/hora quando o arquivador aconteceu. Com base nisso, o monitoramento pode ser feito. Você pode ver a história, quantos eventos estavam lá. Se tivermos mais eventos, ocorreu um arquivo automático. Você pode ir e ver. Ou nossa automação de monitoramento verificou se temos todas as réplicas no lugar, não há atraso e está tudo bem.
Obrigado!
Muito obrigado pela ótima história! Se movermos o cluster DCS para algum lugar longe do cluster Postgres, esse cluster também precisa ser atendido periodicamente? Quais são as melhores práticas de que algumas partes do cluster DCS precisam ser desativadas, algo a ver com elas etc.? Como toda essa estrutura sobrevive? E como você faz essas coisas?
Para uma empresa foi necessário fazer uma matriz de problemas, o que acontece se um dos componentes ou vários componentes falharem. De acordo com esta matriz, percorremos sequencialmente todos os componentes e construímos cenários em caso de falha desses componentes. Assim, para cada cenário de falha, você pode ter um plano de ação para recuperação. E no caso do DCS, ele faz parte da infraestrutura padrão. E o administrador administra, e já contamos com os administradores que administram e com sua capacidade de consertar em caso de acidentes. Se não houver nenhum DCS, então nós o implantamos, mas ao mesmo tempo não o monitoramos particularmente, porque não somos responsáveis pela infraestrutura, mas damos recomendações sobre como e o que monitorar.
Ou seja, entendi bem que preciso desabilitar o Patroni, desabilitar o filer, desabilitar tudo antes de fazer qualquer coisa com os hosts?
Depende de quantos nós temos no cluster DCS. Se houver muitos nós e desabilitarmos apenas um dos nós (a réplica), o cluster manterá um quorum. E o Patroni continua operacional. E nada é acionado. Se tivermos algumas operações complexas que afetam mais nós, cuja ausência pode arruinar o quorum, então - sim, pode fazer sentido colocar o Patroni em pausa. Tem um comando correspondente - pausa patronictl, resume patronictl. Nós apenas pausamos e o autofiler não funciona naquele momento. Fazemos manutenção no cluster DCS, depois tiramos a pausa e continuamos a viver.
Thank you very much!
Muito obrigado pelo seu relatório! Como a equipe de produto se sente em relação à perda de dados?
As equipes de produto não se importam e os líderes de equipe estão preocupados.
Que garantias existem?
As garantias são muito difíceis. Alexander Kukushkin tem um relatório “Como calcular RPO e RTO”, ou seja, tempo de recuperação e quantos dados podemos perder. Acho que precisamos encontrar esses slides e estudá-los. Tanto quanto me lembro, existem passos específicos sobre como calcular essas coisas. Quantas transações podemos perder, quantos dados podemos perder. Como opção, podemos usar replicação síncrona no nível Patroni, mas essa é uma faca de dois gumes: ou temos confiabilidade de dados ou perdemos velocidade. Existe replicação síncrona, mas também não garante 100% de proteção contra perda de dados.
Alexey, obrigado pelo ótimo relatório! Alguma experiência com o uso do Patroni para proteção de nível zero? Ou seja, em conjunto com o modo de espera síncrono? Esta é a primeira pergunta. E a segunda pergunta. Você usou soluções diferentes. Usamos Repmgr, mas sem autofiler, e agora estamos planejando incluir autofiler. E consideramos o Patroni como uma solução alternativa. O que você pode dizer como vantagens em relação ao Repmgr?
A primeira pergunta foi sobre réplicas síncronas. Ninguém usa replicação síncrona aqui, porque todos estão com medo (Vários clientes já estão usando, a princípio não notaram problemas de desempenho - Nota do palestrante). Mas desenvolvemos uma regra para nós mesmos de que deve haver pelo menos três nós em um cluster de replicação síncrona, porque se tivermos dois nós e se o mestre ou a réplica falhar, o Patroni muda esse nó para o modo Standalone para que o aplicativo continue a trabalhar. Neste caso, existe o risco de perda de dados.
Em relação à segunda pergunta, usamos o Repmgr e ainda o fazemos com alguns clientes por questões históricas. O que pode ser dito? O Patroni vem com um autofiler pronto para uso, o Repmgr vem com o autofiler como um recurso adicional que precisa ser ativado. Precisamos executar o daemon Repmgr em cada nó e então podemos configurar o autofiler.
Repmgr verifica se os nós do Postgres estão ativos. Os processos Repmgr verificam a existência uns dos outros, esta não é uma abordagem muito eficiente. pode haver casos complexos de isolamento de rede em que um grande cluster Repmgr pode se desintegrar em vários menores e continuar funcionando. Faz muito tempo que não acompanho o Repmgr, talvez tenha sido consertado ... ou talvez não. Mas a remoção de informações sobre o estado do cluster no DCS, como Stolon, Patroni faz, é a opção mais viável.
Alexey, eu tenho uma pergunta, talvez mais idiota. Em um dos primeiros exemplos, você moveu o DCS da máquina local para um host remoto. A gente entende que a rede é uma coisa que tem características próprias, vive por conta própria. E o que acontece se, por algum motivo, o cluster DCS ficar indisponível? Não direi os motivos, podem ser muitos: das mãos tortas dos networkers aos problemas reais.
Eu não disse isso em voz alta, mas o cluster DCS também deve ser failover, ou seja, é um número ímpar de nós, para que um quorum seja atendido. O que acontece se o cluster DCS ficar indisponível ou um quorum não puder ser atendido, ou seja, algum tipo de divisão de rede ou falha de nó? Nesse caso, o cluster Patroni entra no modo somente leitura. O cluster Patroni não pode determinar o estado do cluster e o que fazer. Ele não pode entrar em contato com o DCS e armazenar o novo estado do cluster lá, então todo o cluster entra em somente leitura. E aguarda a intervenção manual do operador ou a recuperação do DCS.
Grosso modo, o DCS se torna um serviço para nós tão importante quanto a própria base?
Sim Sim. Em muitas empresas modernas, o Service Discovery é parte integrante da infraestrutura. Ele está sendo implementado antes mesmo de haver um banco de dados na infraestrutura. Relativamente falando, a infraestrutura foi lançada, implantada no DC, e imediatamente temos o Service Discovery. Se for Consul, o DNS pode ser construído nele. Se for Etcd, pode haver uma parte do cluster Kubernetes, na qual todo o resto será implantado. Parece-me que o Service Discovery já é parte integrante das infraestruturas modernas. E eles pensam nisso muito antes dos bancos de dados.
Obrigado!
Fonte: habr.com
