

Cuidado com operações que trazem buffers...
Usando uma pequena consulta como exemplo, vejamos algumas abordagens universais para otimizar consultas no PostgreSQL. Depende de você usá-los ou não, mas vale a pena conhecê-los.
Em algumas versões subsequentes do PG a situação pode mudar à medida que o escalonador se torna mais inteligente, mas para 9.4/9.6 parece aproximadamente o mesmo, como nos exemplos aqui.
Vejamos um pedido muito real:
SELECT
TRUE
FROM
"Документ" d
INNER JOIN
"ДокументРасширение" doc_ex
USING("@Документ")
INNER JOIN
"ТипДокумента" t_doc ON
t_doc."@ТипДокумента" = d."ТипДокумента"
WHERE
(d."Лицо3" = 19091 or d."Сотрудник" = 19091) AND
d."$Черновик" IS NULL AND
d."Удален" IS NOT TRUE AND
doc_ex."Состояние"[1] IS TRUE AND
t_doc."ТипДокумента" = 'ПланРабот'
LIMIT 1; sobre nomes de tabelas e camposOs nomes “russos” de campos e tabelas podem ser tratados de forma diferente, mas isso é uma questão de gosto. Porque o não há desenvolvedores estrangeiros, e o PostgreSQL nos permite dar nomes até mesmo em hieróglifos, se eles entre aspas, então preferimos nomear os objetos de forma inequívoca e clara para que não haja discrepâncias.
Vejamos o plano resultante:
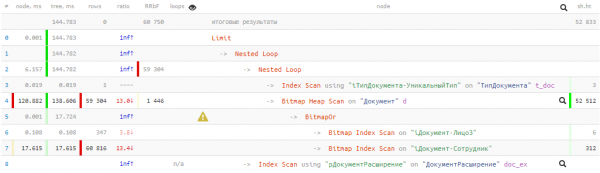
144 ms e quase 53 mil buffers - ou seja, mais de 400MB de dados! E teremos sorte se todos eles estiverem no cache no momento da nossa solicitação, caso contrário, a leitura do disco demorará muito mais.
O algoritmo é o mais importante!
Para otimizar de alguma forma qualquer solicitação, você deve primeiro entender o que ela deve fazer.
Vamos deixar o desenvolvimento da estrutura do banco de dados em si fora do escopo deste artigo por enquanto e concordar que podemos fazer algo relativamente “barato” reescrever o pedido e/ou rolar na base algumas das coisas que precisamos Índices.
Então o pedido:
— verifica a existência de pelo menos algum documento
- na condição que precisamos e de um certo tipo
- onde o autor ou intérprete é o funcionário que precisamos
PARTICIPE + LIMITE 1
Muitas vezes é mais fácil para um desenvolvedor escrever uma consulta onde um grande número de tabelas é unido primeiro e então resta apenas um registro de todo esse conjunto. Mas mais fácil para o desenvolvedor não significa mais eficiente para o banco de dados.
No nosso caso havia apenas 3 mesas - e qual é o efeito...
Vamos primeiro nos livrar da conexão com a tabela "Tipo de Documento" e ao mesmo tempo informar ao banco de dados que nosso registro de tipo é único (sabemos disso, mas o agendador ainda não tem ideia):
WITH T AS (
SELECT
"@ТипДокумента"
FROM
"ТипДокумента"
WHERE
"ТипДокумента" = 'ПланРабот'
LIMIT 1
)
...
WHERE
d."ТипДокумента" = (TABLE T)
...Sim, se a tabela/CTE consiste em um único campo de um único registro, então no PG você pode até escrever assim, em vez de
d."ТипДокумента" = (SELECT "@ТипДокумента" FROM T LIMIT 1)Avaliação preguiçosa em consultas PostgreSQL
BitmapOr vs UNION
Em alguns casos, o Bitmap Heap Scan nos custará muito - por exemplo, em nossa situação, quando muitos registros atendem à condição exigida. Conseguimos porque Condição OR transformada em BitmapOr- operação em plano.
Voltemos ao problema original - precisamos encontrar um registro correspondente para qualquer das condições - ou seja, não há necessidade de procurar todos os registros de 59K em ambas as condições. Existe uma maneira de resolver uma condição e vá para o segundo somente quando nada foi encontrado no primeiro. O seguinte design nos ajudará:
(
SELECT
...
LIMIT 1
)
UNION ALL
(
SELECT
...
LIMIT 1
)
LIMIT 1“Externo” LIMIT 1 garante que a pesquisa termine quando o primeiro registro for encontrado. E se já for encontrado no primeiro bloco, o segundo bloco não será executado (nunca executado em relação a).
“Ocultando condições difíceis sob CASE”
Há um momento extremamente inconveniente na consulta original - verificar o status em relação à tabela relacionada “DocumentExtension”. Independentemente da verdade de outras condições na expressão (por exemplo, d.“Excluído” NÃO É VERDADEIRO), essa conexão é sempre executada e “custa recursos”. Mais ou menos deles serão gastos - depende do tamanho desta mesa.
Mas você pode modificar a consulta para que a busca por um registro relacionado ocorra apenas quando for realmente necessário:
SELECT
...
FROM
"Документ" d
WHERE
... /*index cond*/ AND
CASE
WHEN "$Черновик" IS NULL AND "Удален" IS NOT TRUE THEN (
SELECT
"Состояние"[1] IS TRUE
FROM
"ДокументРасширение"
WHERE
"@Документ" = d."@Документ"
)
END Uma vez da tabela vinculada para nós nenhum dos campos é necessário para o resultado, então teremos a oportunidade de transformar JOIN em uma condição em uma subconsulta.
Vamos deixar os campos indexados “fora dos colchetes CASE”, adicionar condições simples do registro ao bloco WHEN - e agora a consulta “pesada” é executada apenas ao passar para THEN.
Meu sobrenome é "Total"
Coletamos a consulta resultante com toda a mecânica descrita acima:
WITH T AS (
SELECT
"@ТипДокумента"
FROM
"ТипДокумента"
WHERE
"ТипДокумента" = 'ПланРабот'
)
(
SELECT
TRUE
FROM
"Документ" d
WHERE
("Лицо3", "ТипДокумента") = (19091, (TABLE T)) AND
CASE
WHEN "$Черновик" IS NULL AND "Удален" IS NOT TRUE THEN (
SELECT
"Состояние"[1] IS TRUE
FROM
"ДокументРасширение"
WHERE
"@Документ" = d."@Документ"
)
END
LIMIT 1
)
UNION ALL
(
SELECT
TRUE
FROM
"Документ" d
WHERE
("ТипДокумента", "Сотрудник") = ((TABLE T), 19091) AND
CASE
WHEN "$Черновик" IS NULL AND "Удален" IS NOT TRUE THEN (
SELECT
"Состояние"[1] IS TRUE
FROM
"ДокументРасширение"
WHERE
"@Документ" = d."@Документ"
)
END
LIMIT 1
)
LIMIT 1;Ajustando [para] índices
Um olhar treinado notou que as condições indexadas nos subblocos UNION são ligeiramente diferentes - isso ocorre porque já temos índices adequados na tabela. E se não existissem, valeria a pena criar: Documento(Person3, DocumentType) и Documento(DocumentType, Funcionário).
sobre a ordem dos campos nas condições ROWDo ponto de vista do planejador, é claro, você pode escrever (A, B) = (constA, constB)E (B, A) = (constB, constA). Mas ao gravar na ordem dos campos no índice, tal solicitação é simplesmente mais conveniente para depurar posteriormente.
O que está no plano?
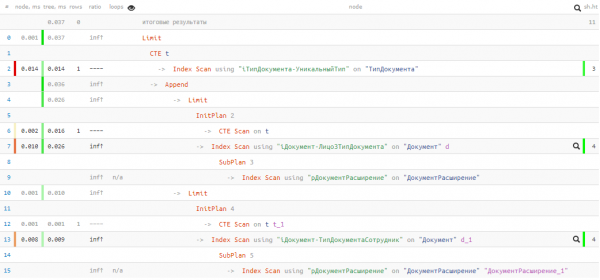
Infelizmente, não tivemos sorte e nada foi encontrado no primeiro bloco UNION, então o segundo ainda foi executado. Mas mesmo assim - apenas 0.037 ms e 11 buffers!
Aceleramos a solicitação e reduzimos o bombeamento de dados na memória vários milhares de vezes, usando técnicas bastante simples - um bom resultado com um pouco de copiar e colar. 🙂
Fonte: habr.com
