


No Badoo, monitoramos constantemente novas tecnologias e avaliamos se vale a pena usá-las em nosso sistema. Gostaríamos de compartilhar um desses estudos com a comunidade. É dedicado ao Loki, um sistema de agregação de logs.
Loki é uma solução para armazenar e visualizar logs, e essa pilha também fornece um sistema flexível para analisá-los e enviar dados ao Prometheus. Em maio, foi lançada outra atualização, promovida ativamente pelos criadores. Estávamos interessados no que o Loki pode fazer, quais recursos ele oferece e até que ponto ele pode atuar como uma alternativa ao ELK, a pilha que usamos agora.
O que é Loki
Grafana Loki é um conjunto de componentes para um sistema completo de trabalho com logs. Ao contrário de outros sistemas semelhantes, o Loki é baseado na ideia de indexar apenas metadados de log - rótulos (os mesmos do Prometheus) e compactar os próprios logs em pedaços separados.
,
Antes de entrarmos no que você pode fazer com o Loki, quero esclarecer o que queremos dizer com “a ideia de indexar apenas metadados”. Vamos comparar a abordagem Loki e a abordagem de indexação em soluções tradicionais como Elasticsearch, usando o exemplo de uma linha do log nginx:
172.19.0.4 - - [01/Jun/2020:12:05:03 +0000] "GET /purchase?user_id=75146478&item_id=34234 HTTP/1.1" 500 8102 "-" "Stub_Bot/3.0" "0.001"Os sistemas tradicionais analisam a linha inteira, incluindo campos com um grande número de valores exclusivos de user_id e item_id, e armazenam tudo em grandes índices. A vantagem dessa abordagem é que você pode executar consultas complexas rapidamente, já que quase todos os dados estão no índice. Mas isso tem um custo, pois o índice se torna grande, o que se traduz em requisitos de memória. Como resultado, o índice de log de texto completo é comparável em tamanho aos próprios logs. Para pesquisá-lo rapidamente, o índice deve ser carregado na memória. E quanto mais logs, mais rápido o índice cresce e mais memória ele consome.
A abordagem Loki exige que apenas os dados necessários sejam extraídos de uma string, cujo número de valores é pequeno. Dessa forma, obtemos um pequeno índice e podemos pesquisar os dados filtrando-os por tempo e por campos indexados e, em seguida, verificando o restante com expressões regulares ou pesquisa de substring. O processo não parece dos mais rápidos, mas Loki divide a solicitação em diversas partes e as executa em paralelo, processando uma grande quantidade de dados em pouco tempo. O número de fragmentos e solicitações paralelas neles é configurável; assim, a quantidade de dados que pode ser processada por unidade de tempo depende linearmente da quantidade de recursos fornecidos.
Essa compensação entre um índice grande e rápido e um índice de força bruta pequeno e paralelo permite que Loki controle o custo do sistema. Pode ser configurado e expandido de forma flexível de acordo com as necessidades.
A pilha Loki consiste em três componentes: Promtail, Loki, Grafana. Promtail coleta logs, processa-os e envia-os para Loki. Loki os mantém. E o Grafana pode solicitar dados do Loki e exibi-los. Em geral, o Loki pode ser usado não apenas para armazenar logs e pesquisá-los. A pilha inteira oferece grandes oportunidades para processar e analisar dados recebidos usando o método Prometheus.
Uma descrição do processo de instalação pode ser encontrada .
Pesquisar por registros
Você pode pesquisar os logs em uma interface especial do Grafana - Explorer. As consultas utilizam a linguagem LogQL, que é muito semelhante ao PromQL utilizado no Prometheus. Em princípio, pode ser pensado como um grep distribuído.
A interface de pesquisa é semelhante a esta:
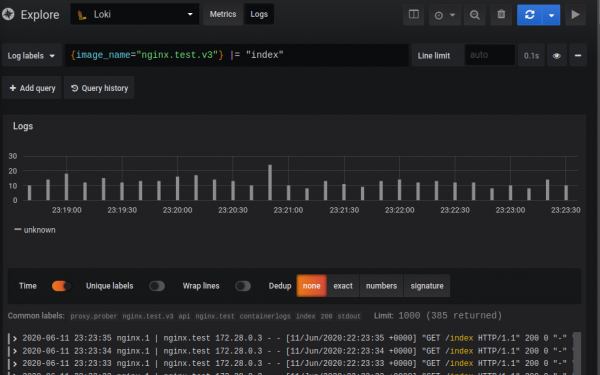
A solicitação em si consiste em duas partes: seletor e filtro. Seletor é uma pesquisa que usa metadados indexados (rótulos) atribuídos a logs, e filtro é uma string de pesquisa ou regexp que filtra os registros definidos pelo seletor. No exemplo dado: Entre chaves existe um seletor, tudo depois é um filtro.
{image_name="nginx.promtail.test"} |= "index"Devido à forma como o Loki funciona, você não pode fazer consultas sem um seletor, mas os rótulos podem ser tão gerais quanto você desejar.
Um seletor é um valor-chave entre chaves. Você pode combinar seletores e especificar diferentes condições de pesquisa usando os operadores =, != ou expressões regulares:
{instance=~"kafka-[23]",name!="kafka-dev"}
// Найдёт логи с лейблом instance, имеющие значение kafka-2, kafka-3, и исключит dev Um filtro é um texto ou regexp que filtrará todos os dados recebidos pelo seletor.
É possível obter gráficos ad-hoc com base nos dados recebidos no modo métrico. Por exemplo, você pode descobrir com que frequência uma entrada contendo o índice de string aparece nos logs do nginx:
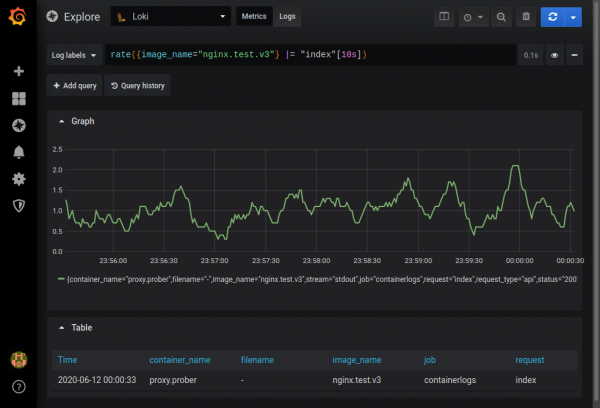
Uma descrição completa dos recursos pode ser encontrada na documentação .
Análise de log
Existem várias maneiras de coletar logs:
- Usando Promtail, um componente padrão da pilha para coleta de logs.
- Diretamente do contêiner docker usando
- Use Fluentd ou Fluent Bit, que pode enviar dados para Loki. Ao contrário do Promtail, eles possuem analisadores prontos para quase qualquer tipo de log e também podem lidar com logs multilinhas.
Normalmente o Promtail é usado para análise. Ele faz três coisas:
- Encontra fontes de dados.
- Anexa etiquetas a eles.
- Envia dados para Loki.
Atualmente o Promtail pode ler logs de arquivos locais e do diário do systemd. Ele deve ser instalado em cada máquina da qual os logs são coletados.
Há integração com Kubernetes: o Promtail automaticamente, por meio da API REST do Kubernetes, reconhece o estado do cluster e coleta logs de um nó, serviço ou pod, colocando imediatamente rótulos com base nos metadados do Kubernetes (nome do pod, nome do arquivo, etc.) .
Você também pode pendurar rótulos com base nos dados do log usando Pipeline. O Pipeline Promtail pode consistir em quatro tipos de estágios. Mais detalhes em , notarei imediatamente algumas nuances.
- Estágios de análise. Este é o estágio RegEx e JSON. Nesta fase, extraímos os dados dos logs para o chamado mapa extraído. Podemos extrair do JSON simplesmente copiando os campos necessários no mapa extraído ou por meio de expressões regulares (RegEx), onde grupos nomeados são “mapeados” no mapa extraído. O mapa extraído é um armazenamento de valor-chave, onde chave é o nome do campo e valor é o valor dos logs.
- Estágios de transformação. Esta etapa possui duas opções: transform, onde definimos as regras de transformação, e source - a fonte de dados para transformação do mapa extraído. Caso não exista tal campo no mapa extraído, ele será criado. Desta forma é possível criar rótulos que não sejam baseados no mapa extraído. Nesta fase podemos manipular os dados no mapa extraído usando uma ferramenta bastante poderosa . Além disso, devemos lembrar que o mapa extraído é carregado integralmente durante a análise, o que possibilita, por exemplo, verificar o valor nele contido: “{{if .tag}o valor da tag existe{end}}”. O modelo oferece suporte a condições, loops e algumas funções de string, como Substituir e Aparar.
- Etapas de ação. Neste ponto você pode fazer algo com o conteúdo extraído:
- Crie um rótulo a partir dos dados extraídos, que será indexado pelo Loki.
- Altere ou defina a hora do evento no log.
- Altere os dados (texto do log) que irão para o Loki.
- Crie métricas.
- Estágios de filtragem. O estágio de correspondência, onde podemos enviar entradas que não precisamos para /dev/null ou encaminhá-las para processamento posterior.
Usando um exemplo de processamento de logs nginx regulares, mostrarei como você pode analisar logs usando o Promtail.
Para o teste, vamos tomar como nginx-proxy uma imagem nginx modificada jwilder/nginx-proxy:alpine e um pequeno daemon que pode se perguntar via HTTP. O daemon possui vários endpoints, aos quais pode fornecer respostas de diferentes tamanhos, com diferentes status HTTP e com diferentes atrasos.
Coletaremos logs de contêineres docker, que podem ser encontrados no caminho /var/lib/docker/containers/ / -json.log
Em docker-compose.yml configuramos o Promtail e especificamos o caminho para a configuração:
promtail:
image: grafana/promtail:1.4.1
// ...
volumes:
- /var/lib/docker/containers:/var/lib/docker/containers:ro
- promtail-data:/var/lib/promtail/positions
- ${PWD}/promtail/docker.yml:/etc/promtail/promtail.yml
command:
- '-config.file=/etc/promtail/promtail.yml'
// ...
Adicione o caminho dos logs para promtail.yml (há uma opção “docker” na configuração, que faz a mesma coisa em uma linha, mas não ficaria tão claro):
scrape_configs:
- job_name: containers
static_configs:
labels:
job: containerlogs
__path__: /var/lib/docker/containers/*/*log # for linux onlyQuando esta configuração estiver habilitada, os logs de todos os contêineres serão enviados ao Loki. Para evitar isso, alteramos as configurações do nginx de teste em docker-compose.yml - adicionamos um campo de tag de registro:
proxy:
image: nginx.test.v3
//…
logging:
driver: "json-file"
options:
tag: "{{.ImageName}}|{{.Name}}"Editando promtail.yml e configurando o Pipeline. A entrada inclui logs do seguinte tipo:
{"log":"u001b[0;33;1mnginx.1 | u001b[0mnginx.test 172.28.0.3 - - [13/Jun/2020:23:25:50 +0000] "GET /api/index HTTP/1.1" 200 0 "-" "Stub_Bot/0.1" "0.096"n","stream":"stdout","attrs":{"tag":"nginx.promtail.test|proxy.prober"},"time":"2020-06-13T23:25:50.66740443Z"}
{"log":"u001b[0;33;1mnginx.1 | u001b[0mnginx.test 172.28.0.3 - - [13/Jun/2020:23:25:50 +0000] "GET /200 HTTP/1.1" 200 0 "-" "Stub_Bot/0.1" "0.000"n","stream":"stdout","attrs":{"tag":"nginx.promtail.test|proxy.prober"},"time":"2020-06-13T23:25:50.702925272Z"}Estágio de pipeline:
- json:
expressions:
stream: stream
attrs: attrs
tag: attrs.tagExtraímos os campos stream, attrs, attrs.tag (se existirem) do JSON recebido e os colocamos no mapa extraído.
- regex:
expression: ^(?P<image_name>([^|]+))|(?P<container_name>([^|]+))$
source: "tag"Se conseguimos colocar o campo tag no mapa extraído, então usando regexp extraímos os nomes da imagem e do container.
- labels:
image_name:
container_name:Atribuímos rótulos. Se as chaves image_name e container_name forem encontradas nos dados extraídos, seus valores serão atribuídos aos rótulos correspondentes.
- match:
selector: '{job="docker",container_name="",image_name=""}'
action: dropDescartamos todos os logs que não possuem os rótulos image_name e container_name instalados.
- match:
selector: '{image_name="nginx.promtail.test"}'
stages:
- json:
expressions:
row: logPara todos os logs cujo image_name é nginx.promtail.test, extraia o campo de log do log de origem e coloque-o no mapa extraído com a chave de linha.
- regex:
# suppress forego colors
expression: .+nginx.+|.+[0m(?P<virtual_host>[a-z_.-]+) +(?P<nginxlog>.+)
source: logrowLimpamos a linha de entrada com expressões regulares e extraímos o host virtual nginx e a linha de log nginx.
- regex:
source: nginxlog
expression: ^(?P<ip>[w.]+) - (?P<user>[^ ]*) [(?P<timestamp>[^ ]+).*] "(?P<method>[^ ]*) (?P<request_url>[^ ]*) (?P<request_http_protocol>[^ ]*)" (?P<status>[d]+) (?P<bytes_out>[d]+) "(?P<http_referer>[^"]*)" "(?P<user_agent>[^"]*)"( "(?P<response_time>[d.]+)")?Analise o log nginx usando expressões regulares.
- regex:
source: request_url
expression: ^.+.(?P<static_type>jpg|jpeg|gif|png|ico|css|zip|tgz|gz|rar|bz2|pdf|txt|tar|wav|bmp|rtf|js|flv|swf|html|htm)$
- regex:
source: request_url
expression: ^/photo/(?P<photo>[^/?.]+).*$
- regex:
source: request_url
expression: ^/api/(?P<api_request>[^/?.]+).*$Vamos analisar request_url. Usando regexp determinamos a finalidade da solicitação: para dados estáticos, para fotos, para API e definimos a chave correspondente no mapa extraído.
- template:
source: request_type
template: "{{if .photo}}photo{{else if .static_type}}static{{else if .api_request}}api{{else}}other{{end}}"Usando operadores condicionais no Template, verificamos os campos instalados no mapa extraído e definimos os valores necessários para o campo request_type: foto, estático, API. Atribua outro se falhar. request_type agora contém o tipo de solicitação.
- labels:
api_request:
virtual_host:
request_type:
status:Definimos os rótulos api_request, virtual_host, request_type e status (status HTTP) com base no que conseguimos colocar no mapa extraído.
- output:
source: nginx_log_rowAlterar saída. Agora, o log nginx limpo do mapa extraído vai para Loki.
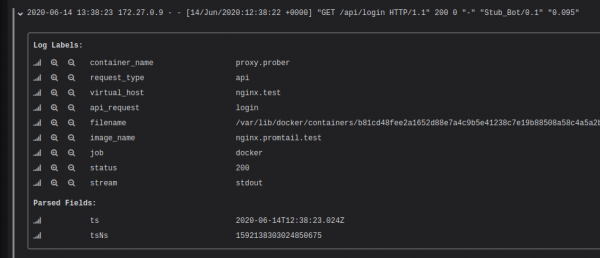
Depois de executar a configuração acima, você pode ver que cada entrada recebe rótulos com base nos dados do log.
Uma coisa a ter em mente é que recuperar rótulos com um grande número de valores (cardinalidade) pode desacelerar significativamente o Loki. Ou seja, você não deve colocar, por exemplo, user_id no índice. Leia mais sobre isso no artigo “" Mas isso não significa que você não possa pesquisar por user_id sem índices. Você precisa usar filtros ao pesquisar (“capturar” os dados), e o índice aqui atua como um identificador de fluxo.
Visualização de logs
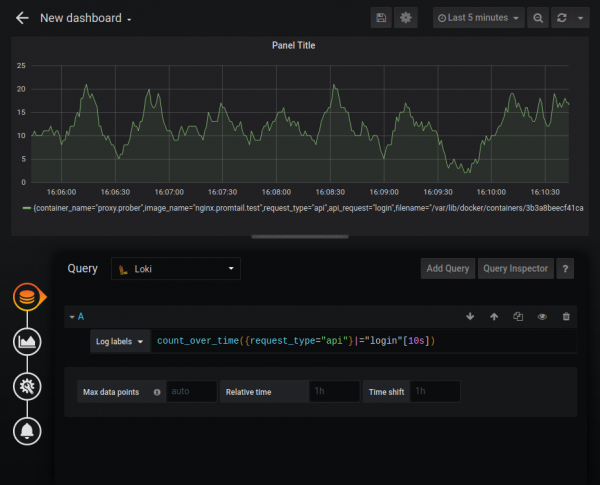
Loki pode atuar como fonte de dados para gráficos Grafana usando LogQL. Os seguintes recursos são suportados:
- taxa — número de registros por segundo;
- contagem ao longo do tempo — o número de registros no intervalo especificado.
Existem também funções de agregação Sum, Avg e outras. Você pode construir gráficos bastante complexos, por exemplo, um gráfico do número de erros HTTP:
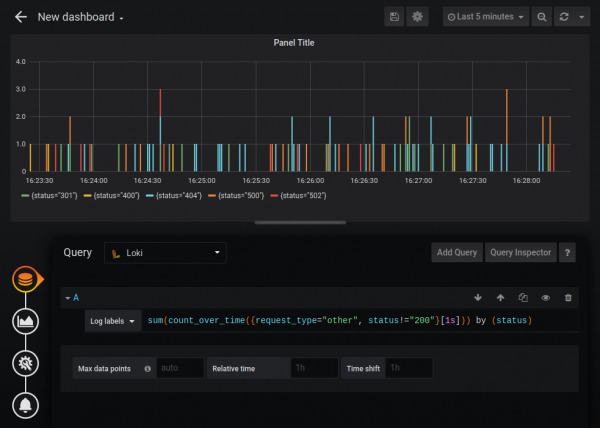
A fonte de dados padrão Loki tem funcionalidade um pouco reduzida em comparação com a fonte de dados Prometheus (por exemplo, você não pode alterar a legenda), mas Loki pode ser conectado como uma fonte com o tipo Prometheus. Não tenho certeza se este é um comportamento documentado, mas a julgar pela resposta dos desenvolvedores “”, por exemplo, é totalmente legal, e Loki é totalmente compatível com PromQL.
Adicione Loki como fonte de dados com o tipo Prometheus e adicione URL /loki:

E podemos fazer gráficos, como se estivéssemos trabalhando com métricas do Prometheus:
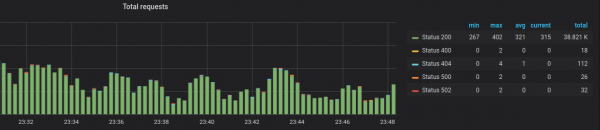
Acho que a discrepância na funcionalidade é temporária e os desenvolvedores corrigirão isso no futuro.
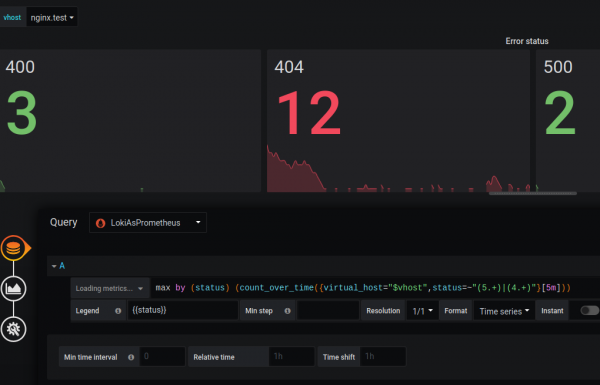
Métricas
Loki oferece a capacidade de extrair métricas numéricas de logs e enviá-las ao Prometheus. Por exemplo, o log nginx contém o número de bytes por resposta, bem como, com uma certa modificação no formato de log padrão, o tempo em segundos que levou para responder. Esses dados podem ser extraídos e enviados ao Prometheus.
Adicione outra seção ao promtail.yml:
- match:
selector: '{request_type="api"}'
stages:
- metrics:
http_nginx_response_time:
type: Histogram
description: "response time ms"
source: response_time
config:
buckets: [0.010,0.050,0.100,0.200,0.500,1.0]
- match:
selector: '{request_type=~"static|photo"}'
stages:
- metrics:
http_nginx_response_bytes_sum:
type: Counter
description: "response bytes sum"
source: bytes_out
config:
action: add
http_nginx_response_bytes_count:
type: Counter
description: "response bytes count"
source: bytes_out
config:
action: incA opção permite definir e atualizar métricas com base nos dados do mapa extraído. Essas métricas não são enviadas ao Loki - elas aparecem no endpoint Promtail /metrics. O Prometheus deve estar configurado para receber os dados recebidos nesta fase. No exemplo acima, para request_type=“api” coletamos uma métrica de histograma. Com este tipo de métrica é conveniente obter percentis. Para estática e foto, coletamos a soma dos bytes e o número de linhas em que recebemos bytes para calcular a média.
Leia mais sobre métricas .
Abra a porta no Promtail:
promtail:
image: grafana/promtail:1.4.1
container_name: monitoring.promtail
expose:
- 9080
ports:
- "9080:9080"Certifique-se de que as métricas com o prefixo promtail_custom apareçam:
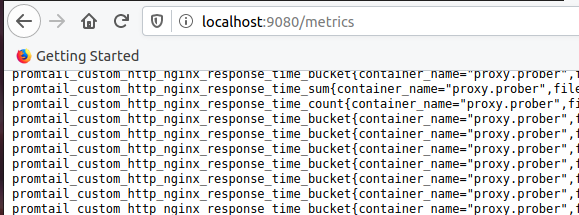
Configurando o Prometheus. Adicionar promessa de emprego:
- job_name: 'promtail'
scrape_interval: 10s
static_configs:
- targets: ['promtail:9080']E desenhamos um gráfico:
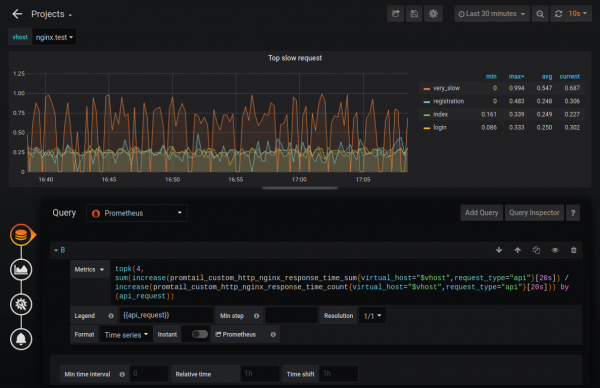
Desta forma você pode descobrir, por exemplo, as quatro consultas mais lentas. Você também pode configurar o monitoramento para essas métricas.
Escala
Loki pode estar no modo binário único ou no modo fragmentado (modo escalonável horizontalmente). No segundo caso, ele pode salvar os dados na nuvem, e os pedaços e o índice são armazenados separadamente. A versão 1.5 introduz a capacidade de armazenamento em um só lugar, mas ainda não é recomendado usá-lo em produção.
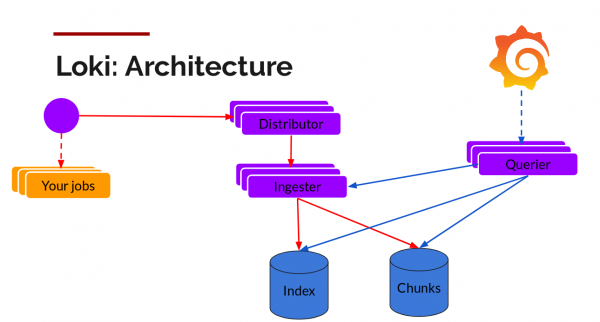
Os pedaços podem ser armazenados em armazenamento compatível com S3 e bancos de dados escaláveis horizontalmente podem ser usados para armazenar índices: Cassandra, BigTable ou DynamoDB. Outras partes do Loki - Distribuidores (para escrita) e Querier (para consultas) - não têm estado e também são dimensionadas horizontalmente.
Na conferência DevOpsDays Vancouver 2019, um dos participantes Callum Styan anunciou que com Loki seu projeto possui petabytes de logs com índice inferior a 1% do tamanho total: “".
Comparação de Loki e ELK
Tamanho do índice
Para testar o tamanho do índice resultante, peguei logs do contêiner nginx para o qual o Pipeline acima foi configurado. O arquivo de log continha 406 linhas com volume total de 624 MB. Os logs foram gerados em uma hora, aproximadamente 109 entradas por segundo.
Exemplo de duas linhas do log:

Quando indexado pelo ELK, obteve um tamanho de índice de 30,3 MB:
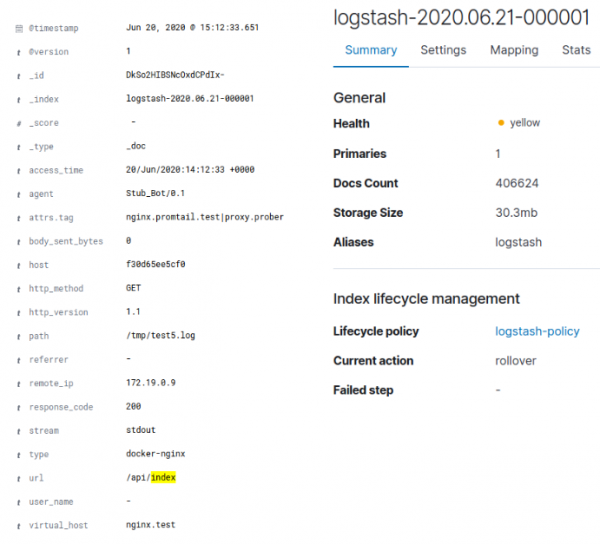
No caso do Loki, isso resultou em aproximadamente 128 KB de índice e aproximadamente 3,8 MB de dados em blocos. Vale ressaltar que o log foi gerado artificialmente e não possuía grande variedade de dados. Um simples gzip no log JSON do Docker original com dados deu uma compactação de 95,4%, e levando em consideração o fato de que apenas o log nginx limpo foi enviado para o próprio Loki, a compactação de até 4 MB é compreensível. O número total de valores exclusivos para rótulos Loki foi 35, o que explica o pequeno tamanho do índice. Para ELK, o log também foi apagado. Assim, Loki comprimiu os dados originais em 96% e ELK em 70%.
Consumo de memória
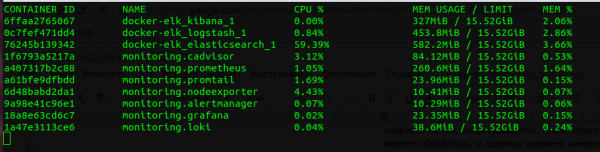
Se compararmos toda a pilha do Prometheus e do ELK, Loki “come” várias vezes menos. É claro que um serviço Go consome menos que um serviço Java, e comparar o tamanho do JVM Heap Elasticsearch e a memória alocada para Loki está incorreto, mas mesmo assim é importante notar que Loki usa muito menos memória. Sua vantagem de CPU não é tão óbvia, mas também está presente.
velocidade
Loki “devora” registros mais rápido. A velocidade depende de muitos fatores - que tipo de log são, quão sofisticados somos em analisá-los, rede, disco, etc. - mas é definitivamente maior que o ELK (no meu teste - cerca de duas vezes mais). Isso se explica pelo fato de Loki colocar muito menos dados no índice e, consequentemente, gastar menos tempo na indexação. Com a velocidade de pesquisa, a situação é oposta: Loki fica visivelmente mais lento em dados maiores que vários gigabytes, enquanto a velocidade de pesquisa do ELK não depende do tamanho dos dados.
Pesquisar por registros
Loki é significativamente inferior ao ELK em termos de recursos de pesquisa de log. Grep com expressões regulares é poderoso, mas é inferior a um banco de dados maduro. A falta de consultas de intervalo, agregação apenas por rótulos, a impossibilidade de pesquisar sem rótulos - tudo isso nos limita na busca por informações de interesse em Loki. Isso não significa que nada pode ser encontrado usando o Loki, mas define o fluxo de trabalho com logs quando você encontra pela primeira vez um problema nos gráficos do Prometheus e, em seguida, usa esses rótulos para procurar o que aconteceu nos logs.
Interface.
Em primeiro lugar, é lindo (desculpe, não resisti). O Grafana tem uma interface bonita, mas o Kibana é muito mais rico em recursos.
Prós e contras de Loki
Uma das vantagens é que o Loki se integra ao Prometheus, então obtemos métricas e alertas prontos para uso. É conveniente coletar logs e armazená-los em pods do Kubernetes, pois possui descoberta de serviço herdada do Prometheus e anexa rótulos automaticamente.
A desvantagem é a documentação fraca. Algumas coisas, por exemplo, os recursos e capacidades do Promtail, descobri apenas no processo de estudo do código, felizmente é de código aberto. Outra desvantagem são os fracos recursos de análise. Por exemplo, Loki não pode analisar logs multilinhas. Outra desvantagem é que Loki é uma tecnologia relativamente jovem (a versão 1.0 foi em novembro de 2019).
Conclusão
Loki é uma tecnologia 100% interessante e adequada para projetos de pequeno e médio porte, permitindo resolver diversos problemas de agregação de logs, busca de logs, monitoramento e análise de logs.
Não usamos Loki no Badoo porque temos uma pilha ELK adequada para nós e que foi repleta de várias soluções personalizadas ao longo dos anos. Para nós, o obstáculo é pesquisar nos registros. Com quase 100 GB de logs por dia, é importante para nós conseguirmos encontrar tudo e um pouco mais e fazê-lo rapidamente. Para mapeamento e monitoramento, utilizamos outras soluções adaptadas às nossas necessidades e integradas entre si. A pilha Loki tem benefícios tangíveis, mas não nos dará mais do que já temos, e os seus benefícios certamente não compensarão o custo da migração.
E embora depois de pesquisas tenha ficado claro que não podemos usar o Loki, esperamos que este post o ajude na sua escolha.
O repositório com o código utilizado no artigo está localizado .
Fonte: habr.com
