

De tempos em tempos, surge a tarefa de buscar dados relacionados por meio de um conjunto de chaves. até atingirmos o número total necessário de registros..
O exemplo mais "realista" é deduzir. 20 tarefas mais antigas, listado na lista de funcionários (Por exemplo, dentro de um único departamento). Para diversos painéis de gestão com breves resumos das áreas de trabalho, um tema semelhante costuma ser necessário.

Neste artigo, vamos considerar a implementação de uma solução "ingênua" para esse problema no PostgreSQL, uma solução "mais inteligente" e um algoritmo muito complexo. "Loop" em SQL com uma condição de saída baseada nos dados encontrados., o que pode ser útil tanto para o desenvolvimento geral quanto para aplicação em outros casos semelhantes.
Vamos pegar um conjunto de dados de teste de Para evitar que os registros de saída "saltem" de um momento para outro quando os valores classificados coincidirem, Vamos expandir o índice de assuntos adicionando uma chave primária.Isso tornará o item único imediatamente e garantirá uma ordem de classificação clara:
CREATE INDEX ON task(owner_id, task_date, id);
-- а старый - удалим
DROP INDEX task_owner_id_task_date_idx;Está escrito exatamente como soa.
Primeiro, vamos esboçar a versão mais simples da solicitação, passando os IDs dos artistas. :
SELECT
*
FROM
task
WHERE
owner_id = ANY('{1,2,4,8,16,32,64,128,256,512}'::integer[])
ORDER BY
task_date, id
LIMIT 20; 
É um pouco triste - nós só tínhamos encomendado 20 discos e a Index Scan os devolveu. Linhas 960, que depois teve de ser organizado... Vamos tentar ler menos.
desaninhar + ARRAY
A primeira consideração que nos ajudará é se precisamos apenas 20 classificados registros, então basta ler não mais que 20 classificados na mesma ordem para cada um chave. Felizmente, índice adequado (owner_id, task_date, id) nós temos.
Vamos usar o mesmo mecanismo de extração e "desdobramento em colunas". entrada de tabela integral, como em Também aplicaremos a função de recolhimento em um array. ARRAY():
WITH T AS (
SELECT
unnest(ARRAY(
SELECT
t
FROM
task t
WHERE
owner_id = unnest
ORDER BY
task_date, id
LIMIT 20 -- ограничиваем тут...
)) r
FROM
unnest('{1,2,4,8,16,32,64,128,256,512}'::integer[])
)
SELECT
(r).*
FROM
T
ORDER BY
(r).task_date, (r).id
LIMIT 20; -- ... и тут - тоже 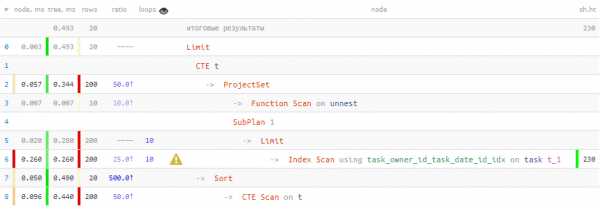
Ah, isso é muito melhor! 40% mais rápido e com 4.5 vezes menos dados Eu tive que ler.
Materialização de registros de tabela via CTEGostaria de chamar a sua atenção para o fato de que em alguns casos Tentar trabalhar imediatamente com os campos do registro após procurá-lo em uma subconsulta, sem "envolvê-lo" em uma CTE, pode levar a... "multiplicação" de InitPlan proporcional ao número desses mesmos campos:
SELECT
((
SELECT
t
FROM
task t
WHERE
owner_id = 1
ORDER BY
task_date, id
LIMIT 1
).*);Result (cost=4.77..4.78 rows=1 width=16) (actual time=0.063..0.063 rows=1 loops=1)
Buffers: shared hit=16
InitPlan 1 (returns $0)
-> Limit (cost=0.42..1.19 rows=1 width=48) (actual time=0.031..0.032 rows=1 loops=1)
Buffers: shared hit=4
-> Index Scan using task_owner_id_task_date_id_idx on task t (cost=0.42..387.57 rows=500 width=48) (actual time=0.030..0.030 rows=1 loops=1)
Index Cond: (owner_id = 1)
Buffers: shared hit=4
InitPlan 2 (returns $1)
-> Limit (cost=0.42..1.19 rows=1 width=48) (actual time=0.008..0.009 rows=1 loops=1)
Buffers: shared hit=4
-> Index Scan using task_owner_id_task_date_id_idx on task t_1 (cost=0.42..387.57 rows=500 width=48) (actual time=0.008..0.008 rows=1 loops=1)
Index Cond: (owner_id = 1)
Buffers: shared hit=4
InitPlan 3 (returns $2)
-> Limit (cost=0.42..1.19 rows=1 width=48) (actual time=0.008..0.008 rows=1 loops=1)
Buffers: shared hit=4
-> Index Scan using task_owner_id_task_date_id_idx on task t_2 (cost=0.42..387.57 rows=500 width=48) (actual time=0.008..0.008 rows=1 loops=1)
Index Cond: (owner_id = 1)
Buffers: shared hit=4"
InitPlan 4 (returns $3)
-> Limit (cost=0.42..1.19 rows=1 width=48) (actual time=0.009..0.009 rows=1 loops=1)
Buffers: shared hit=4
-> Index Scan using task_owner_id_task_date_id_idx on task t_3 (cost=0.42..387.57 rows=500 width=48) (actual time=0.009..0.009 rows=1 loops=1)
Index Cond: (owner_id = 1)
Buffers: shared hit=4
O mesmo registro foi "pesquisado" 4 vezes... Até o PostgreSQL 11, esse comportamento era encontrado regularmente, e a solução era "envolvê-lo" em uma CTE, o que representa um limite absoluto para o otimizador nessas versões.
Acumulador recursivo
Na versão anterior, lemos em total Linhas 200 Em prol dos 20 necessários. Não mais 960, mas até menos - será possível?
Vamos tentar usar o conhecimento que precisamos. xnumx total registros. Ou seja, vamos iterar a leitura dos dados somente até atingirmos o número necessário.
Passo 1: Lista inicial
Obviamente, nossa lista "alvo" de 20 registros deve começar com o "primeiro" registro para uma de nossas chaves owner_id. Então, vamos primeiro encontrar esses registros. "o primeiro de todos" para cada uma das teclas e adicione-o à lista, ordenando-o na ordem desejada - (data_da_tarefa, id).
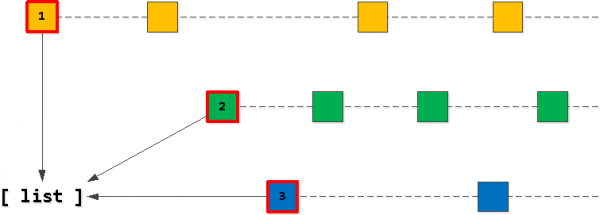
Passo 2: Encontre os registros "seguintes"
Agora, se pegarmos o primeiro item da nossa lista e começarmos "Dê um passo" adiante no índice. Com a chave owner_id preservada, todos os registros encontrados serão exatamente os próximos na seleção resultante. Claro, apenas até cruzarmos a chave aplicada O segundo item da lista.
Se por acaso "cruzarmos" a segunda entrada, então A última entrada lida deve ser adicionada à lista em vez da primeira. (com o mesmo owner_id), após o que reordenamos a lista novamente.
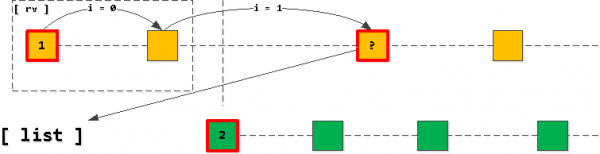
Ou seja, sempre acabamos com o fato de que a lista não tem mais do que uma entrada para cada uma das chaves (se as entradas acabarem e não as tivermos "riscado", a primeira entrada simplesmente desaparecerá da lista e nada será adicionado), e elas sempre resolvido em ordem crescente da chave do aplicativo (task_date, id).
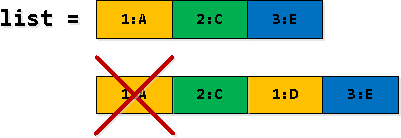
Etapa 3: Filtrar e expandir os registros
Em algumas das linhas de nossa seleção recursiva, alguns registros rv Entradas duplicadas — primeiro encontramos entradas como "cruzando o limite da segunda entrada da lista" e, em seguida, as substituímos como a primeira entrada da lista. Portanto, a primeira ocorrência precisa ser filtrada.
A temida pergunta final
WITH RECURSIVE T AS (
-- #1 : заносим в список "первые" записи по каждому из ключей набора
WITH wrap AS ( -- "материализуем" record'ы, чтобы обращение к полям не вызывало умножения InitPlan/SubPlan
WITH T AS (
SELECT
(
SELECT
r
FROM
task r
WHERE
owner_id = unnest
ORDER BY
task_date, id
LIMIT 1
) r
FROM
unnest('{1,2,4,8,16,32,64,128,256,512}'::integer[])
)
SELECT
array_agg(r ORDER BY (r).task_date, (r).id) list -- сортируем список в нужном порядке
FROM
T
)
SELECT
list
, list[1] rv
, FALSE not_cross
, 0 size
FROM
wrap
UNION ALL
-- #2 : вычитываем записи 1-го по порядку ключа, пока не перешагнем через запись 2-го
SELECT
CASE
-- если ничего не найдено для ключа 1-й записи
WHEN X._r IS NOT DISTINCT FROM NULL THEN
T.list[2:] -- убираем ее из списка
-- если мы НЕ пересекли прикладной ключ 2-й записи
WHEN X.not_cross THEN
T.list -- просто протягиваем тот же список без модификаций
-- если в списке уже нет 2-й записи
WHEN T.list[2] IS NULL THEN
-- просто возвращаем пустой список
'{}'
-- пересортировываем словарь, убирая 1-ю запись и добавляя последнюю из найденных
ELSE (
SELECT
coalesce(T.list[2] || array_agg(r ORDER BY (r).task_date, (r).id), '{}')
FROM
unnest(T.list[3:] || X._r) r
)
END
, X._r
, X.not_cross
, T.size + X.not_cross::integer
FROM
T
, LATERAL(
WITH wrap AS ( -- "материализуем" record
SELECT
CASE
-- если все-таки "перешагнули" через 2-ю запись
WHEN NOT T.not_cross
-- то нужная запись - первая из спписка
THEN T.list[1]
ELSE ( -- если не пересекли, то ключ остался как в предыдущей записи - отталкиваемся от нее
SELECT
_r
FROM
task _r
WHERE
owner_id = (rv).owner_id AND
(task_date, id) > ((rv).task_date, (rv).id)
ORDER BY
task_date, id
LIMIT 1
)
END _r
)
SELECT
_r
, CASE
-- если 2-й записи уже нет в списке, но мы хоть что-то нашли
WHEN list[2] IS NULL AND _r IS DISTINCT FROM NULL THEN
TRUE
ELSE -- ничего не нашли или "перешагнули"
coalesce(((_r).task_date, (_r).id) < ((list[2]).task_date, (list[2]).id), FALSE)
END not_cross
FROM
wrap
) X
WHERE
T.size < 20 AND -- ограничиваем тут количество
T.list IS DISTINCT FROM '{}' -- или пока список не кончился
)
-- #3 : "разворачиваем" записи - порядок гарантирован по построению
SELECT
(rv).*
FROM
T
WHERE
not_cross; -- берем только "непересекающие" записи 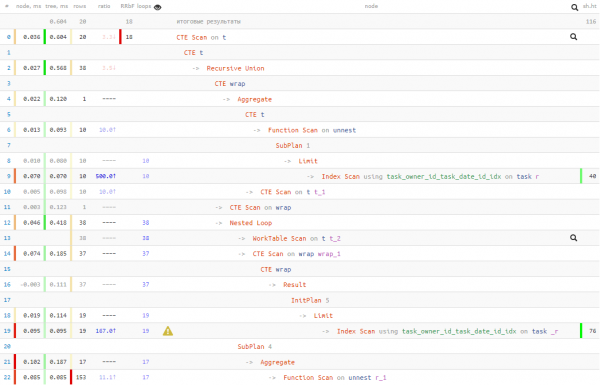
Então nós Negociou 50% das leituras de dados por 20% do tempo de execução.Ou seja, se você tiver motivos para acreditar que a leitura pode ser lenta (por exemplo, os dados geralmente não estão em cache e precisam ser recuperados do disco), esse método pode reduzir sua dependência da leitura.
Em qualquer caso, o tempo de execução foi melhor do que com a primeira opção "ingênua". Mas qual dessas três opções usar fica a seu critério.
Fonte: habr.com
