

Muito provavelmente, hoje ninguém pergunta por que é necessário coletar métricas de serviço. O próximo passo lógico é configurar um alerta para as métricas coletadas, que avisará sobre eventuais desvios nos dados nos canais mais convenientes para você (mail, Slack, Telegram). No serviço de reserva de hotel online todas as métricas de nossos serviços são inseridas no InfluxDB e exibidas no Grafana, e alertas básicos também são configurados lá. Para tarefas como “você precisa calcular algo e comparar com isso”, usamos o Kapacitor.

Kapacitor faz parte da pilha TICK que pode processar métricas do InfluxDB. Ele pode conectar várias medições (juntar), calcular algo útil a partir dos dados recebidos, escrever o resultado de volta no InfluxDB, enviar um alerta para Slack/Telegram/mail.
A pilha inteira é legal e detalhada , mas sempre haverá coisas úteis que não estão explicitamente indicadas nos manuais. Neste artigo, decidi coletar algumas dicas úteis e não óbvias (a sintaxe básica do TICKscipt é descrita ) e mostre como eles podem ser aplicados usando um exemplo de solução de um de nossos problemas.
Vamos lá!
float e int, erros de cálculo
Um problema absolutamente padrão, resolvido através de castas:
var alert_float = 5.0
var alert_int = 10
data|eval(lambda: float("value") > alert_float OR float("value") < float("alert_int"))
Usando padrão()
Se uma tag/campo não for preenchido, ocorrerão erros de cálculo:
|default()
.tag('status', 'empty')
.field('value', 0)
preencha a junção (interna vs externa)
Por padrão, join descartará pontos onde não há dados (internos).
Com fill('null'), uma junção externa será realizada, após a qual você precisa fazer um default() e preencher os valores vazios:
var data = res1
|join(res2)
.as('res1', 'res2)
.fill('null')
|default()
.field('res1.value', 0.0)
.field('res2.value', 100.0)
Ainda há uma nuance aqui. No exemplo acima, se uma das séries (res1 ou res2) estiver vazia, a série resultante (dados) também estará vazia. Existem vários tickets sobre este tópico no Github (, , ) – estamos aguardando soluções e sofrendo um pouco.
Usando condições em cálculos (se estiver em lambda)
|eval(lambda: if("value" > 0, true, false)
Últimos cinco minutos do pipeline para o período
Por exemplo, você precisa comparar os valores dos últimos cinco minutos com os da semana anterior. Você pode pegar dois lotes de dados em dois lotes separados ou extrair parte dos dados de um período maior:
|where(lambda: duration((unixNano(now()) - unixNano("time"))/1000, 1u) < 5m)
Uma alternativa para os últimos cinco minutos seria usar um BarrierNode, que corta os dados antes do tempo especificado:
|barrier()
.period(5m)
Exemplos de uso de modelos Go em mensagens
Os modelos correspondem ao formato do pacote Abaixo estão alguns quebra-cabeças encontrados com frequência.
se mais
Colocamos as coisas em ordem e não acionamos as pessoas com texto mais uma vez:
|alert()
...
.message(
'{{ if eq .Level "OK" }}It is ok now{{ else }}Chief, everything is broken{{end}}'
)
Dois dígitos após a vírgula na mensagem
Melhorando a legibilidade da mensagem:
|alert()
...
.message(
'now value is {{ index .Fields "value" | printf "%0.2f" }}'
)
Expandindo variáveis na mensagem
Exibimos mais informações na mensagem para responder à pergunta “Por que está gritando”?
var warnAlert = 10
|alert()
...
.message(
'Today value less then '+string(warnAlert)+'%'
)
Identificador de alerta exclusivo
Isso é necessário quando há mais de um grupo nos dados, caso contrário será gerado apenas um alerta:
|alert()
...
.id('{{ index .Tags "myname" }}/{{ index .Tags "myfield" }}')
Manipulador personalizado
A grande lista de manipuladores inclui exec, que permite executar seu script com os parâmetros passados (stdin) - criatividade e nada mais!
Um de nossos costumes é um pequeno script Python para enviar notificações ao Slack.
A princípio, queríamos enviar uma imagem de grafana protegida por autorização em uma mensagem. Depois, escreva OK no tópico para o alerta anterior do mesmo grupo, e não como uma mensagem separada. Um pouco mais tarde - acrescente à mensagem o erro mais comum dos últimos X minutos.
Um tópico separado é a comunicação com outros serviços e quaisquer ações iniciadas por um alerta (somente se o seu monitoramento funcionar bem o suficiente).
Um exemplo de descrição de manipulador, onde slack_handler.py é nosso script escrito por nós mesmos:
topic: slack_graph
id: slack_graph.alert
match: level() != INFO AND changed() == TRUE
kind: exec
options:
prog: /sbin/slack_handler.py
args: ["-c", "CHANNELID", "--graph", "--search"]
Como depurar?
Opção com saída de log
|log()
.level("error")
.prefix("something")
Assistir (cli): kapacitor -url :9092 logs lvl=erro
Opção com httpOut
Mostra dados no pipeline atual:
|httpOut('something')
Assista (obtenha): :9092/kapacitor/v1/tasks/nome_da_tarefa/alguma coisa
Esquema de execução
- Cada tarefa retorna uma árvore de execução com números úteis no formato .
- Pegue um bloco .
- Cole-o no visualizador, .
Onde mais você pode conseguir um ancinho?
timestamp no influxdb no writeback
Por exemplo, configuramos um alerta para a soma de solicitações por hora (groupBy(1h)) e queremos registrar o alerta que ocorreu no influxdb (para mostrar lindamente o fato do problema no gráfico no grafana).
influxDBOut() escreverá o valor do tempo do alerta no carimbo de data/hora; consequentemente, o ponto no gráfico será escrito antes/depois da chegada do alerta.
Quando a precisão é necessária: contornamos esse problema chamando um manipulador personalizado, que gravará os dados no influxdb com o carimbo de data/hora atual.
docker, construção e implantação
Na inicialização, o kapacitor pode carregar tarefas, modelos e manipuladores do diretório especificado na configuração no bloco [load].
Para criar uma tarefa corretamente, você precisa do seguinte:
- Nome do arquivo – expandido em id/nome do script
- Tipo – fluxo/lote
- dbrp – palavra-chave para indicar em qual banco de dados + política o script é executado (dbrp “supplier.”“autogen”)
Se alguma tarefa em lote não contiver uma linha com dbrp, todo o serviço se recusará a iniciar e escreverá honestamente sobre isso no log.
No cronógrafo, ao contrário, esta linha não deveria existir, ela não é aceita pela interface e gera um erro.
Hack ao construir um contêiner: Dockerfile sai com -1 se houver linhas com //.+dbrp, o que permitirá que você entenda imediatamente o motivo da falha ao montar a construção.
junte-se um a muitos
Tarefa de exemplo: você precisa pegar o percentil 95 do tempo de operação do serviço durante uma semana, comparar cada minuto dos últimos 10 com este valor.
Você não pode fazer uma junção um-para-muitos, a última/média/mediana sobre um grupo de pontos transforma o nó em um fluxo, o erro “não é possível adicionar arestas incompatíveis filhas: lote -> fluxo” será retornado.
O resultado de um lote, como variável em uma expressão lambda, também não é substituído.
Existe a opção de salvar os números necessários do primeiro lote em um arquivo via udf e carregar esse arquivo via sideload.
O que resolvemos com isso?
Temos cerca de 100 fornecedores hoteleiros, cada um deles pode ter diversas conexões, vamos chamar de canal. Existem aproximadamente 300 desses canais, cada um dos canais pode cair. De todas as métricas registradas, monitoraremos a taxa de erros (solicitações e erros).
Por que não grafana?
Os alertas de erro configurados no Grafana têm várias desvantagens. Alguns são críticos, outros para os quais você pode fechar os olhos, dependendo da situação.
Grafana não sabe calcular entre medições + alertas, mas precisamos de uma taxa (solicitações-erros)/solicitações.
Os erros parecem desagradáveis:
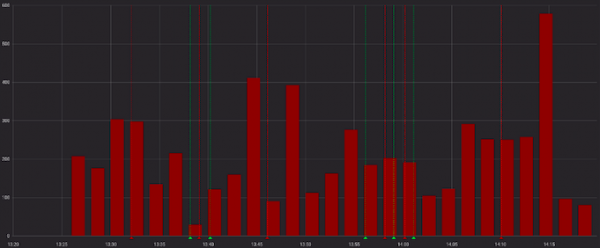
E menos mal quando visto com solicitações bem-sucedidas:
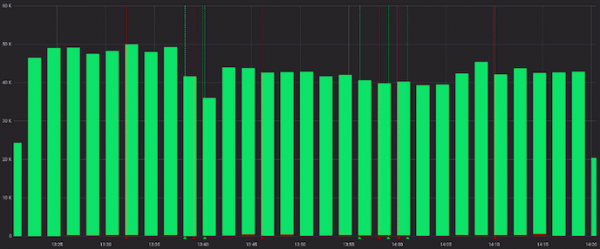
Ok, podemos pré-calcular a tarifa do serviço antes da grafana, e em alguns casos isso vai funcionar. Mas não no nosso, porque... para cada canal a sua própria proporção é considerada “normal” e os alertas funcionam de acordo com valores estáticos (procuramos com os olhos, alteramos se houver alertas frequentes).
Estes são exemplos de “normal” para diferentes canais:


Ignoramos o ponto anterior e assumimos que o quadro “normal” é semelhante para todos os fornecedores. Agora está tudo bem e podemos conviver com alertas no grafana?
Podemos, mas realmente não queremos, porque temos que escolher uma das opções:
a) fazer muitos gráficos para cada canal separadamente (e acompanhá-los dolorosamente)
b) deixar um gráfico com todos os canais (e se perder nas linhas coloridas e nos alertas personalizados)

Como você fez isso?
Novamente, há um bom exemplo inicial na documentação (), podem ser observados ou tomados como base em problemas semelhantes.
O que fizemos no final:
- junte duas séries em poucas horas, agrupando por canais;
- preencher a série por grupo se não houver dados;
- comparar a mediana dos últimos 10 minutos com os dados anteriores;
- gritamos se encontramos alguma coisa;
- escrevemos as taxas calculadas e alertas que ocorreram no influxdb;
- envie uma mensagem útil para o Slack.
Na minha opinião, conseguimos alcançar tudo o que queríamos no final (e até um pouco mais com manipuladores personalizados) da maneira mais bonita possível.
Você pode olhar em github.com и o script resultante.
Um exemplo do código resultante:
dbrp "supplier"."autogen"
var name = 'requests.rate'
var grafana_dash = 'pczpmYZWU/mydashboard'
var grafana_panel = '26'
var period = 8h
var todayPeriod = 10m
var every = 1m
var warnAlert = 15
var warnReset = 5
var reqQuery = 'SELECT sum("count") AS value FROM "supplier"."autogen"."requests"'
var errQuery = 'SELECT sum("count") AS value FROM "supplier"."autogen"."errors"'
var prevErr = batch
|query(errQuery)
.period(period)
.every(every)
.groupBy(1m, 'channel', 'supplier')
var prevReq = batch
|query(reqQuery)
.period(period)
.every(every)
.groupBy(1m, 'channel', 'supplier')
var rates = prevReq
|join(prevErr)
.as('req', 'err')
.tolerance(1m)
.fill('null')
// заполняем значения нулями, если их не было
|default()
.field('err.value', 0.0)
.field('req.value', 0.0)
// if в lambda: считаем рейт, только если ошибки были
|eval(lambda: if("err.value" > 0, 100.0 * (float("req.value") - float("err.value")) / float("req.value"), 100.0))
.as('rate')
// записываем посчитанные значения в инфлюкс
rates
|influxDBOut()
.quiet()
.create()
.database('kapacitor')
.retentionPolicy('autogen')
.measurement('rates')
// выбираем данные за последние 10 минут, считаем медиану
var todayRate = rates
|where(lambda: duration((unixNano(now()) - unixNano("time")) / 1000, 1u) < todayPeriod)
|median('rate')
.as('median')
var prevRate = rates
|median('rate')
.as('median')
var joined = todayRate
|join(prevRate)
.as('today', 'prev')
|httpOut('join')
var trigger = joined
|alert()
.warn(lambda: ("prev.median" - "today.median") > warnAlert)
.warnReset(lambda: ("prev.median" - "today.median") < warnReset)
.flapping(0.25, 0.5)
.stateChangesOnly()
// собираем в message ссылку на график дашборда графаны
.message(
'{{ .Level }}: {{ index .Tags "channel" }} err/req ratio ({{ index .Tags "supplier" }})
{{ if eq .Level "OK" }}It is ok now{{ else }}
'+string(todayPeriod)+' median is {{ index .Fields "today.median" | printf "%0.2f" }}%, by previous '+string(period)+' is {{ index .Fields "prev.median" | printf "%0.2f" }}%{{ end }}
http://grafana.ostrovok.in/d/'+string(grafana_dash)+
'?var-supplier={{ index .Tags "supplier" }}&var-channel={{ index .Tags "channel" }}&panelId='+string(grafana_panel)+'&fullscreen&tz=UTC%2B03%3A00'
)
.id('{{ index .Tags "name" }}/{{ index .Tags "channel" }}')
.levelTag('level')
.messageField('message')
.durationField('duration')
.topic('slack_graph')
// "today.median" дублируем как "value", также пишем в инфлюкс остальные филды алерта (keep)
trigger
|eval(lambda: "today.median")
.as('value')
.keep()
|influxDBOut()
.quiet()
.create()
.database('kapacitor')
.retentionPolicy('autogen')
.measurement('alerts')
.tag('alertName', name)
E qual é a conclusão?
Kapacitor é ótimo para realizar alertas de monitoramento com vários agrupamentos, realizar cálculos adicionais com base em métricas já registradas, executar ações personalizadas e executar scripts (udf).
A barreira de entrada não é muito alta - experimente se a grafana ou outras ferramentas não satisfizerem totalmente os seus desejos.
Fonte: habr.com
