

Um cenário comum em todos os aplicativos conhecidos é a busca de dados com base em critérios específicos e sua exibição em um formato legível. Isso também pode incluir recursos adicionais de classificação, agrupamento e paginação. Embora essa tarefa seja trivial em conceito, muitos desenvolvedores cometem diversos erros ao resolvê-la, o que acaba impactando o desempenho. Vamos explorar várias soluções para esse problema e formular recomendações para a escolha da implementação mais eficaz.

Opção de paginação nº 1
A opção mais simples que me vem à mente é uma exibição paginada dos resultados da pesquisa em seu formato mais clássico.
Vamos supor que o aplicativo utilize um banco de dados relacional. Nesse caso, para exibir informações nesse formato, você precisará executar duas consultas SQL:
- Obter linhas da página atual.
- Calcule o número total de linhas que correspondem aos critérios de pesquisa - isso é necessário para exibir as páginas.
Vamos analisar a primeira consulta usando um banco de dados MS SQL de teste como exemplo. Para o Server 2016. Para isso, usaremos a tabela Sales.SalesOrderHeader:
SELECT * FROM Sales.SalesOrderHeader
ORDER BY OrderDate DESC
OFFSET 0 ROWS
FETCH NEXT 50 ROWS ONLY
A consulta acima retornará os 50 primeiros pedidos da lista, ordenados por data de adição em ordem decrescente; em outras palavras, os 50 pedidos mais recentes.
O processo é executado rapidamente no banco de dados de teste, mas vamos analisar o plano de execução e as estatísticas de E/S:
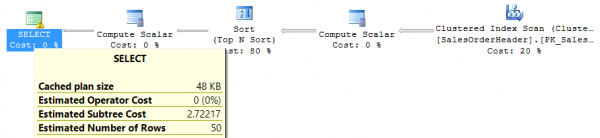
Table 'SalesOrderHeader'. Scan count 1, logical reads 698, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.Você pode obter estatísticas de E/S para cada consulta executando o comando SET STATISTICS IO ON no ambiente de execução da consulta.
Como mostra o plano de execução, a operação que mais consome recursos é a ordenação de todas as linhas da tabela de origem por data de inserção. O problema é que quanto mais linhas a tabela tiver, mais difícil se torna o processo de ordenação. Na prática, essas situações devem ser evitadas, então vamos adicionar um índice na data de inserção e ver se o consumo de recursos muda:
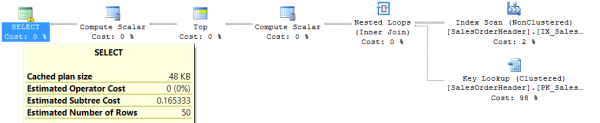
Table 'SalesOrderHeader'. Scan count 1, logical reads 165, physical reads 0, read-ahead reads 5, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Claramente, houve uma grande melhora. Mas será que todos os problemas foram resolvidos? Vamos alterar a consulta para buscar pedidos com valor total de produtos superior a US$ 100:
SELECT * FROM Sales.SalesOrderHeader
WHERE SubTotal > 100
ORDER BY OrderDate DESC
OFFSET 0 ROWS
FETCH NEXT 50 ROWS ONLY

Table 'SalesOrderHeader'. Scan count 1, logical reads 1081, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.Temos uma situação curiosa: o plano de consulta não é muito pior que o anterior, mas o número real de leituras lógicas é quase o dobro em comparação com uma varredura completa da tabela. Existe uma solução: se convertermos o índice existente em um índice composto e adicionarmos o preço total dos produtos como o segundo campo, obteremos novamente 165 leituras lógicas.
CREATE INDEX IX_SalesOrderHeader_OrderDate_SubTotal on Sales.SalesOrderHeader(OrderDate, SubTotal);
Essa série de exemplos poderia continuar indefinidamente, mas os dois pontos principais que quero destacar aqui são:
- Adicionar novos critérios ou alterar a ordem de classificação de uma consulta de pesquisa pode afetar significativamente a velocidade de execução.
- Mas se precisarmos ler apenas uma parte dos dados, e não todos os resultados que correspondem aos termos de pesquisa, existem muitas maneiras de otimizar essa consulta.
Agora vamos passar para a segunda consulta mencionada no início — aquela que conta o número de registros que atendem aos critérios de busca. Vamos usar o mesmo exemplo — buscar por pedidos acima de US$ 100:
SELECT COUNT(1) FROM Sales.SalesOrderHeader
WHERE SubTotal > 100
Dado o índice composto especificado acima, obtemos:
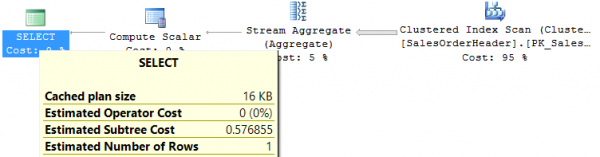
Table 'SalesOrderHeader'. Scan count 1, logical reads 698, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.Não é surpreendente que a consulta percorra todo o índice, já que o campo Subtotal não está na primeira posição, portanto a consulta não pode utilizá-lo. Esse problema é resolvido adicionando outro índice no campo Subtotal, o que resulta em apenas 48 leituras lógicas.
Existem vários outros exemplos de consultas de contagem que podem ser dados, mas a essência permanece a mesma: Obter uma parte dos dados e calcular o valor total são duas solicitações fundamentalmente diferentes.E cada uma requer suas próprias medidas de otimização. Geralmente, é impossível encontrar uma combinação de índices que funcione igualmente bem para ambas as consultas.
Assim, um dos requisitos importantes que devem ser esclarecidos ao desenvolver uma solução de busca desse tipo é se a empresa realmente precisa ver o número total de objetos encontrados. Muitas vezes, não precisa. E navegar por números de página específicos, na minha opinião, é uma solução com um escopo de aplicação muito limitado, já que a maioria dos cenários de paginação envolve "ir para a próxima página".
Opção de paginação nº 2
Vamos supor que os usuários não se importem em saber o número total de objetos encontrados. Vamos tentar simplificar a página de busca:
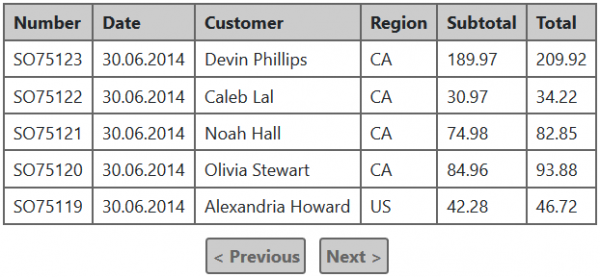
Essencialmente, a única coisa que mudou é que não é mais possível navegar para números de página específicos, e agora a tabela não precisa saber quantas páginas existem para exibi-las. Mas surge a questão: como a tabela sabe se há dados para a próxima página (para que o link "Próximo" possa ser exibido corretamente)?
A resposta é muito simples: você pode ler um registro a mais do banco de dados do que o necessário para exibição, e a presença desse registro "extra" indicará se o próximo lote está disponível. Isso significa que apenas uma consulta será necessária para recuperar uma página de dados, melhorando significativamente o desempenho e facilitando a manutenção dessa funcionalidade. Na minha experiência, eliminar o número total de registros acelerou os resultados em 4 a 5 vezes.
Existem diversas opções de interface de usuário para essa abordagem: comandos "voltar" e "avançar", como no exemplo acima; um botão "carregar mais" que simplesmente adiciona um novo lote aos resultados exibidos; ou "rolagem infinita", que funciona com base no princípio de "carregar mais", mas o sinal para recuperar o próximo lote é o usuário rolar até o final dos resultados exibidos. Seja qual for a solução visual, o princípio de recuperação de dados permanece o mesmo.
As nuances da implementação de paginação
Todos os exemplos de consulta acima usam a abordagem "offset + count", onde a própria consulta especifica a ordem das linhas a serem consultadas e o número de linhas a serem retornadas. Primeiro, vamos analisar a melhor maneira de lidar com a passagem de parâmetros nesse caso. Na prática, observei diversas abordagens:
- O número ordinal da página solicitada (pageIndex), tamanho da página (pageSize).
- O índice do primeiro registro a ser retornado (startIndex), o número máximo de registros no resultado (count).
- O número de sequência do primeiro registro a ser retornado (startIndex), o número de sequência do último registro a ser retornado (endIndex).
À primeira vista, pode parecer tão simples que não faz diferença. Mas isso não é verdade — a segunda opção (startIndex, count) é a mais conveniente e universal. Existem várias razões para isso:
- Para a abordagem de análise de registro "+1" descrita acima, a primeira opção com `pageIndex` e `pageSize` é extremamente inconveniente. Por exemplo, se quisermos exibir 50 registros por página, de acordo com o algoritmo descrito, precisaríamos ler um registro a mais do que o necessário. Se esse "+1" não for implementado no servidor, significa que teríamos que solicitar os registros de 1 a 51 para a primeira página, de 51 a 101 para a segunda e assim por diante. Se definirmos o tamanho da página para 51 e aumentarmos o `pageIndex`, a segunda página retornará os registros de 52 a 102 e assim por diante. Portanto, na primeira opção, a única maneira de implementar corretamente o botão "próxima página" é implementar a análise da linha "extra" no servidor, o que seria uma nuance muito sutil.
- A terceira opção não faz sentido algum, já que consultar a maioria dos bancos de dados exigirá o envio de uma contagem, e não do índice do último registro. Subtrair startIndex de endIndex pode ser uma operação aritmética básica, mas é desnecessária neste caso.
Agora devemos descrever as desvantagens de implementar a paginação por meio de “deslocamento + quantidade”:
- Recuperar cada página subsequente será mais custoso e lento do que a anterior, porque o banco de dados ainda precisará percorrer todos os registros "do início", de acordo com os critérios de pesquisa e classificação, e então parar no fragmento necessário.
- Nem todos os SGBDs suportam essa abordagem.
Existem alternativas, mas elas também não são ideais. A primeira dessas abordagens é chamada de "paginação por conjunto de chaves" ou "método de busca". Após receber um bloco de dados, você pode armazenar os valores dos campos do último registro na página e usá-los para recuperar o próximo bloco. Por exemplo, executamos a seguinte consulta:
SELECT * FROM Sales.SalesOrderHeader
ORDER BY OrderDate DESC
OFFSET 0 ROWS
FETCH NEXT 50 ROWS ONLY
E na última entrada, obtivemos o valor da data do pedido '2014-06-29'. Então, para acessar a próxima página, você pode tentar o seguinte:
SELECT * FROM Sales.SalesOrderHeader
WHERE OrderDate < '2014-06-29'
ORDER BY OrderDate DESC
OFFSET 0 ROWS
FETCH NEXT 50 ROWS ONLY
O problema é que OrderDate não é um campo único, e a condição acima provavelmente deixará de fora muitas linhas relevantes. Para tornar essa consulta inequívoca, você precisa adicionar um campo único à condição (vamos supor que 75074 seja o último valor da chave primária da primeira parte):
SELECT * FROM Sales.SalesOrderHeader
WHERE (OrderDate = '2014-06-29' AND SalesOrderID < 75074)
OR (OrderDate < '2014-06-29')
ORDER BY OrderDate DESC, SalesOrderID DESC
OFFSET 0 ROWS
FETCH NEXT 50 ROWS ONLY
Essa opção funcionará corretamente, mas, em geral, será difícil de otimizar, visto que a condição contém um operador OR. Se o valor da chave primária aumentar conforme OrderDate aumenta, a condição pode ser simplificada, deixando apenas o filtro em SalesOrderID. No entanto, se não houver uma correlação estrita entre os valores da chave primária e o campo pelo qual o resultado é ordenado, esse OR será inevitável na maioria dos SGBDs. A exceção que conheço é o PostgreSQL, que oferece suporte completo a comparações de tuplas, e a condição acima pode ser escrita como "WHERE (OrderDate, SalesOrderID) < ('2014-06-29', 75074)". Com uma chave composta contendo esses dois campos, tal consulta deve ser bastante leve.
Uma segunda abordagem alternativa pode ser encontrada, por exemplo, em ou — quando uma solicitação, além dos dados, retorna um identificador especial que pode ser usado para recuperar a próxima porção de dados. Se esse identificador tiver um tempo de vida ilimitado (como no Comsos DB), essa é uma excelente maneira de implementar paginação com transições sequenciais entre páginas (opção nº 2 mencionada acima). Suas possíveis desvantagens: não é compatível com todos os SGBDs; o identificador recuperado para a próxima porção pode ter um tempo de vida limitado, o que geralmente não é adequado para implementar interação com o usuário (como a API de rolagem do Elasticsearch).
Filtração complexa
Vamos complicar ainda mais o problema. Suponhamos que haja uma necessidade de implementar a chamada busca facetada, familiar a todos em lojas online. Os exemplos acima, baseados na tabela de pedidos, não são muito ilustrativos neste caso, então vamos usar a tabela de Produtos do banco de dados AdventureWorks:
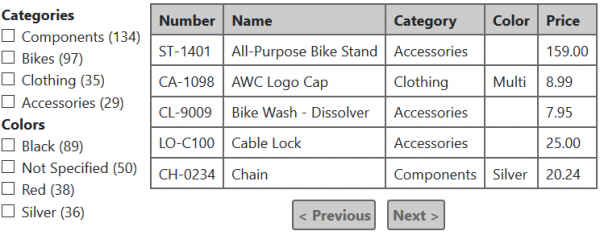
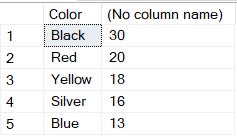
Qual é a ideia por trás da busca facetada? É que, para cada elemento de filtro, é exibido o número de registros que correspondem a esse critério. levando em consideração os filtros selecionados em todas as outras categorias..
Por exemplo, se selecionarmos a categoria Bicicletas e a cor Preta neste exemplo, a tabela exibirá apenas bicicletas pretas, mas:
- Para cada critério no grupo "Categorias", o número de produtos dessa categoria será exibido em preto.
- Para cada critério no grupo "Cores", será exibido o número de bicicletas dessa cor.
Segue um exemplo da saída para essas condições:
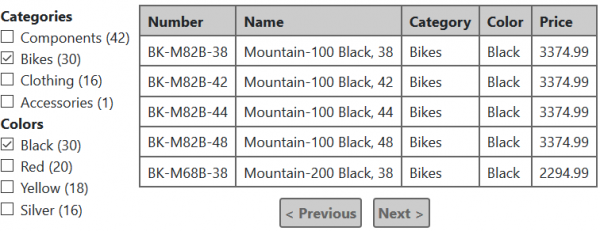
Se você também selecionar a categoria "Roupas", a tabela exibirá as roupas pretas disponíveis. A quantidade de produtos pretos na seção "Cores" também será recalculada de acordo com as novas condições, mas nada mudará na seção "Categorias". Espero que esses exemplos sejam suficientes para entender o algoritmo de busca facetada.
Agora, vamos imaginar como isso poderia ser implementado em um banco de dados relacional. Cada grupo de critérios, como Categoria e Cor, exigiria uma consulta separada:
SELECT pc.ProductCategoryID, pc.Name, COUNT(1) FROM Production.Product p
INNER JOIN Production.ProductSubcategory ps ON p.ProductSubcategoryID = ps.ProductSubcategoryID
INNER JOIN Production.ProductCategory pc ON ps.ProductCategoryID = pc.ProductCategoryID
WHERE p.Color = 'Black'
GROUP BY pc.ProductCategoryID, pc.Name
ORDER BY COUNT(1) DESC
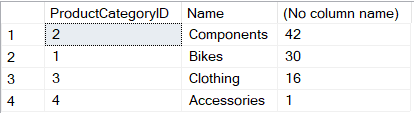
SELECT Color, COUNT(1) FROM Production.Product p
INNER JOIN Production.ProductSubcategory ps ON p.ProductSubcategoryID = ps.ProductSubcategoryID
WHERE ps.ProductCategoryID = 1 --Bikes
GROUP BY Color
ORDER BY COUNT(1) DESC
Qual o problema dessa solução? É simples: ela não é escalável. Cada seção de filtro exige uma consulta separada para calcular as quantidades, e essas consultas não são fáceis de executar. Em lojas online, algumas categorias podem ter dezenas de seções de filtro, o que pode representar um sério desafio de desempenho.
Normalmente, após essas declarações, me são oferecidas algumas soluções, a saber:
- Combine todos os cálculos de quantidade em uma única consulta. Tecnicamente, isso é possível usando a palavra-chave UNION, mas não melhorará muito o desempenho — o banco de dados ainda terá que executar cada fragmento do zero.
- Armazenar em cache as quantidades. Essa é a sugestão que recebo quase sempre que descrevo o problema. O problema é que, geralmente, é impossível. Digamos que temos 10 facetas, cada uma com 5 valores. Essa é uma situação bem "modesta" comparada ao que se vê, por exemplo, em lojas online. A seleção de um elemento de uma faceta afeta as quantidades em outras 9; em outras palavras, as quantidades podem ser diferentes para cada combinação de critérios. No nosso exemplo, existem 50 critérios que o usuário pode selecionar, o que significa que existem 250 combinações possíveis. Preencher um array de dados desse tamanho não exigiria memória nem tempo. Pode-se argumentar que nem todas as combinações são realistas e que o usuário raramente seleciona mais de 5 a 10 critérios. Sim, o carregamento lento (lazy loading) e o armazenamento em cache apenas das quantidades que já foram selecionadas são possíveis, mas quanto mais opções existirem, menos eficaz será esse cache e mais perceptíveis serão os problemas de tempo de resposta (especialmente se o conjunto de dados mudar com frequência).
Felizmente, esse problema já conta com soluções bastante eficazes que funcionam de forma previsível em grandes volumes de dados. Para qualquer uma dessas opções, faz sentido dividir o recálculo dos filtros e a recuperação da página de resultados em duas requisições paralelas ao servidor e organizar a interface do usuário de forma que o carregamento dos dados dos filtros não interfira na exibição dos resultados da busca.
- Recalcular todos os resultados dos filtros com a menor frequência possível. Por exemplo, evite recalcular tudo sempre que os critérios de busca forem alterados. Em vez disso, encontre o número total de resultados que correspondem aos critérios atuais e solicite ao usuário que os exiba — "1425 registros encontrados, exibir?". O usuário pode continuar alterando os critérios de busca ou clicar no botão "Exibir". Somente neste último caso todas as consultas para recuperar resultados e recalcular as quantidades em todos os filtros serão executadas. No entanto, como você pode ver, isso exige lidar com a consulta para o número total de resultados e sua otimização. Essa abordagem é comum em muitas pequenas lojas online. Obviamente, não é a solução definitiva para esse problema, mas em casos simples pode ser um bom meio-termo.
- Utilize um mecanismo de busca para pesquisar resultados e calcular facetas, como Solr, ElasticSearch, Sphinx e outros. Todos eles são projetados para construir "facetas" e fazem isso de forma bastante eficiente graças a um índice invertido. Como os mecanismos de busca são estruturados, por que são mais eficientes do que bancos de dados de uso geral nesses casos, quais práticas e armadilhas existem – este é o tema de um artigo separado. Aqui, quero ressaltar que um mecanismo de busca não pode substituir o data warehouse principal; ele é usado como um complemento: quaisquer alterações no banco de dados principal que sejam relevantes para a busca são sincronizadas com o índice de busca; o mecanismo de busca geralmente interage apenas com o próprio mecanismo de busca e não acessa o banco de dados principal. Um dos pontos mais importantes aqui é como organizar essa sincronização de forma confiável. Tudo depende dos requisitos de "tempo de resposta". Se o tempo entre uma alteração no banco de dados principal e sua "manifestação" na busca não for crítico, você pode criar um serviço que busca registros alterados recentemente a cada poucos minutos e os indexa. Se o tempo de resposta mínimo possível for necessário, você pode implementar algo como Para enviar atualizações ao serviço de busca.
Descobertas
- Implementar paginação no servidor é uma complicação significativa e só faz sentido para conjuntos de dados que crescem rapidamente ou que são simplesmente grandes. Não existe uma resposta definitiva para determinar se um conjunto de dados é "grande" ou "de crescimento rápido", mas eu usaria esta abordagem:
- Se receber uma coleta completa de dados, levando em consideração o tempo do servidor e a transmissão de rede, normalmente atende aos requisitos de desempenho, não há motivo para implementar paginação no lado do servidor.
- É possível que não se esperem problemas de desempenho em um futuro próximo, visto que os dados são pequenos, mas a coleção está em constante crescimento. Se um determinado conjunto de dados puder deixar de atender aos requisitos anteriores no futuro, é melhor implementar a paginação desde o início.
- Se a sua empresa não tem uma exigência estrita de mostrar o número total de resultados ou números de página, e o seu sistema não possui um mecanismo de busca, é melhor ignorar essas etapas e considerar a opção nº 2.
- Se houver uma necessidade clara de pesquisa facetada, você tem duas opções sem sacrificar o desempenho:
- Não recalcule todas as quantidades a cada alteração nos critérios de pesquisa.
- Utilize um mecanismo de busca como Solr, ElasticSearch, Sphinx, entre outros. No entanto, é importante compreender que ele não pode substituir o banco de dados principal e deve ser usado como um complemento ao armazenamento principal para solucionar problemas de busca.
- Além disso, no caso da busca facetada, faz sentido dividir a recuperação da página de resultados da busca e a contagem dos resultados em duas requisições paralelas. Contar os resultados pode levar mais tempo do que recuperá-los, enquanto os resultados são mais importantes para o usuário.
- Se você utiliza um banco de dados SQL para pesquisa, quaisquer alterações de código relacionadas a essa área devem ser exaustivamente testadas quanto ao desempenho em um volume de dados apropriado (maior que o volume do banco de dados em produção). Também é recomendável monitorar os tempos de execução das consultas em todas as instâncias do banco de dados, especialmente na instância em produção. Mesmo que os planos de consulta tenham funcionado bem durante o desenvolvimento, a situação pode mudar significativamente à medida que o volume de dados aumenta.
Fonte: habr.com
