

В falamos sobre previsão de séries temporais. Uma continuação lógica seria um artigo sobre identificação de anomalias.
Aplicação
A detecção de anomalias é usada em áreas como:
1) Previsão de quebras de equipamentos
Assim, em 2010, as centrífugas iranianas foram atacadas pelo vírus Stuxnet, que colocou o equipamento em funcionamento não ideal e desativou alguns dos equipamentos devido ao desgaste acelerado.
Se algoritmos de detecção de anomalias tivessem sido utilizados no equipamento, a situação de falha poderia ter sido evitada.

A busca por anomalias no funcionamento de equipamentos é utilizada não só na indústria nuclear, mas também na metalurgia e na operação de turbinas de aeronaves. E em outras áreas onde o uso de diagnósticos preditivos é mais barato do que possíveis perdas devido a uma avaria imprevisível.
2) Previsão de fraude
Se o dinheiro for retirado do cartão que você usa em Podolsk, na Albânia, as transações poderão precisar ser verificadas posteriormente.
3) Identificação de padrões anormais de consumo
Se alguns clientes apresentarem comportamento anormal, pode haver um problema do qual você não tem conhecimento.
4) Identificação de demanda e carga anormais
Se as vendas numa loja FMCG caíram abaixo do intervalo de confiança da previsão, vale a pena descobrir a razão do que está a acontecer.
Abordagens para identificar anomalias
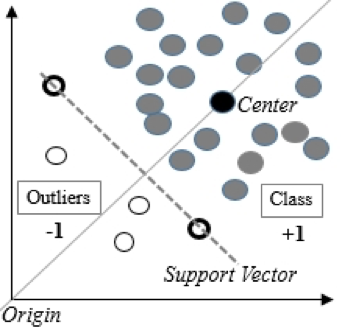
1) Máquina de vetores de suporte com SVM de uma classe e uma classe
Adequado quando os dados no conjunto de treinamento seguem uma distribuição normal, mas o conjunto de teste contém anomalias.
A máquina de vetores de suporte de classe única constrói uma superfície não linear em torno da origem. É possível definir um limite para o qual os dados são considerados anômalos.
Com base na experiência de nossa equipe DATA4, o One-Class SVM é o algoritmo mais comumente usado para resolver o problema de localização de anomalias.
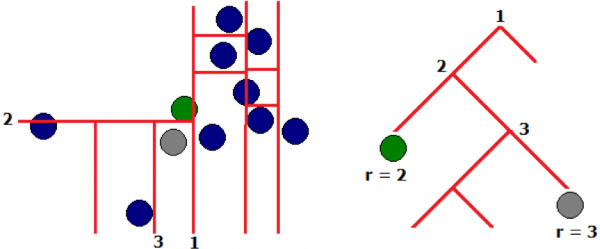
2) Método de floresta isolada
Com o método “aleatório” de construção de árvores, as emissões entrarão nas folhas nos estágios iniciais (a uma profundidade rasa da árvore), ou seja, as emissões são mais fáceis de “isolar”. O isolamento de valores anômalos ocorre nas primeiras iterações do algoritmo.
3) Envelope elíptico e métodos estatísticos
Usado quando os dados são normalmente distribuídos. Quanto mais próxima a medição estiver da cauda da mistura de distribuições, mais anômalo será o valor.
Outros métodos estatísticos também podem ser incluídos nesta classe.
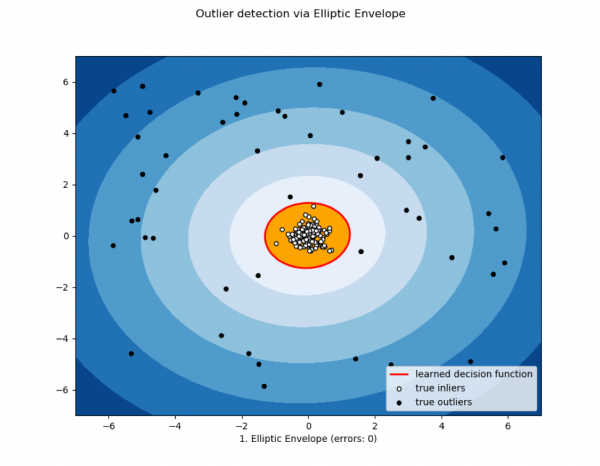
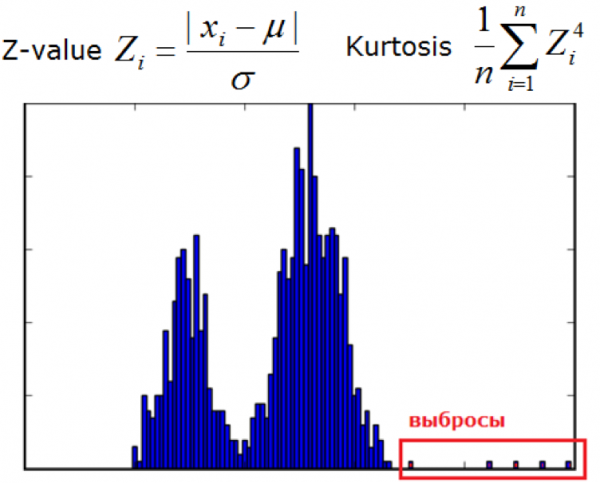
Imagem de dyakonov.org
4) Métodos métricos
Os métodos incluem algoritmos como k-vizinhos mais próximos, k-vizinho mais próximo, ABOD (detecção de outlier baseada em ângulo) ou LOF (fator de outlier local).
Adequado se a distância entre os valores nas características for equivalente ou normalizada (para não medir jibóia em papagaios).
O algoritmo de k-vizinhos mais próximos assume que os valores normais estão localizados em uma determinada região do espaço multidimensional, e a distância às anomalias será maior do que ao hiperplano de separação.
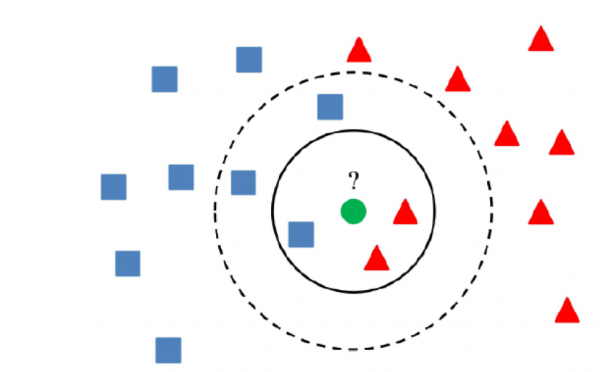
5) Métodos de cluster
A essência dos métodos de cluster é que se um valor estiver mais do que uma certa distância dos centros do cluster, o valor pode ser considerado anômalo.
O principal é utilizar um algoritmo que agrupe corretamente os dados, o que depende da tarefa específica.
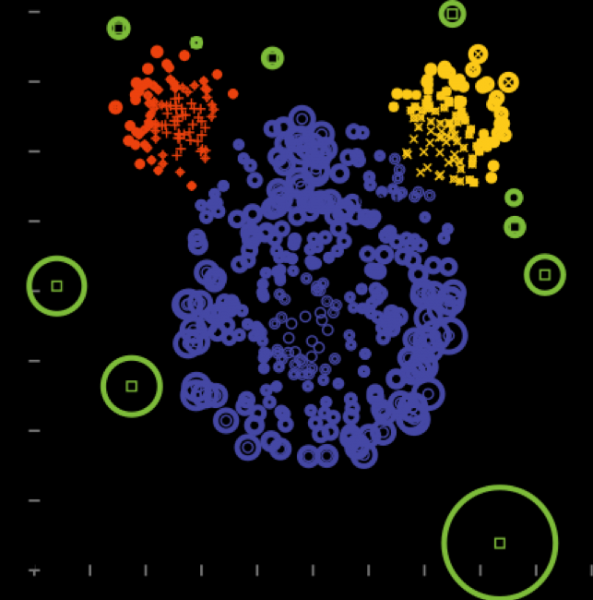
6) Método dos componentes principais
Adequado onde as direções de maior mudança na dispersão são destacadas.
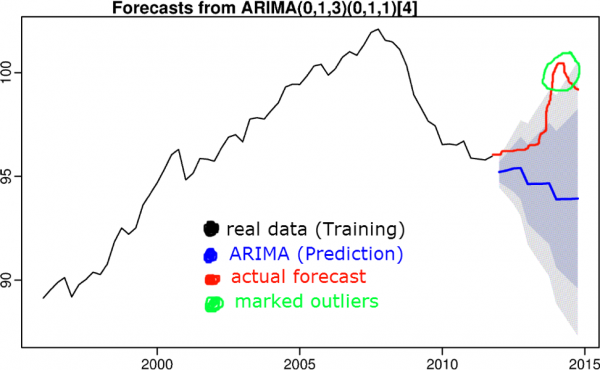
7) Algoritmos baseados em previsão de séries temporais
A ideia é que se um valor estiver fora do intervalo de confiança da predição, o valor será considerado anômalo. Para prever uma série temporal, são usados algoritmos como suavização tripla, S(ARIMA), boosting, etc.
Algoritmos de previsão de série temporal foram discutidos no artigo anterior.
8) Aprendizagem supervisionada (regressão, classificação)
Se os dados permitirem, utilizamos algoritmos que vão desde regressão linear até redes recorrentes. Vamos medir a diferença entre a previsão e o valor real e concluir até que ponto os dados se desviam da norma. É importante que o algoritmo tenha capacidade de generalização suficiente e que o conjunto de treinamento não contenha valores anômalos.
9) Testes de modelo
Vamos abordar o problema de busca de anomalias como um problema de busca de recomendações. Vamos decompor nossa matriz de recursos usando SVD ou máquinas de fatoração e considerar os valores na nova matriz que são significativamente diferentes dos originais como anômalos.
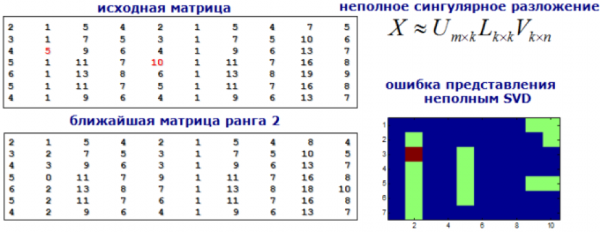
Imagem de dyakonov.org
Conclusão
Neste artigo, revisamos as principais abordagens para detecção de anomalias.
Encontrar anomalias pode, em muitos aspectos, ser chamado de arte. Não existe um algoritmo ou abordagem ideal, cuja utilização resolva todos os problemas. Mais frequentemente, um conjunto de métodos é usado para resolver um caso específico. A detecção de anomalias é realizada usando máquinas de vetores de suporte de classe única, isolando florestas, métodos métricos e de cluster, bem como usando componentes principais e previsão de séries temporais.
Se você conhece outros métodos, escreva sobre eles nos comentários do artigo.
Fonte: habr.com
