

A NVIDIA divulgou o código-fonte do seu sistema de aprendizado de máquina SPADE (GauGAN), que sintetiza paisagens realistas a partir de esboços, bem como modelos não treinados relacionados. O sistema foi demonstrado em março na conferência GTC 2019, mas o código só foi liberado ontem. O trabalho é de código aberto sob a licença Creative Commons Atribuição-NãoComercial-CompartilhaIgual 4.0 (CC BY-NC-SA 4.0), que permite apenas uso não comercial. O código foi escrito em Python usando o framework PyTorch.

Os esboços são apresentados como um mapa segmentado que define a localização aproximada dos objetos na cena. A natureza dos objetos gerados é definida por meio de marcadores de cor. Por exemplo, o azul representa o céu, o azul representa a água, o verde escuro representa as árvores, o verde claro representa a grama, o marrom claro representa as rochas, o marrom escuro representa as montanhas, o cinza representa a neve, uma linha marrom representa uma estrada e uma linha azul representa um rio. Além disso, o estilo geral da composição e a hora do dia são determinados com base na seleção de imagens de referência. Essa ferramenta para criação de mundos virtuais pode ser útil para uma ampla gama de profissionais, desde arquitetos e urbanistas até desenvolvedores de jogos e paisagistas.
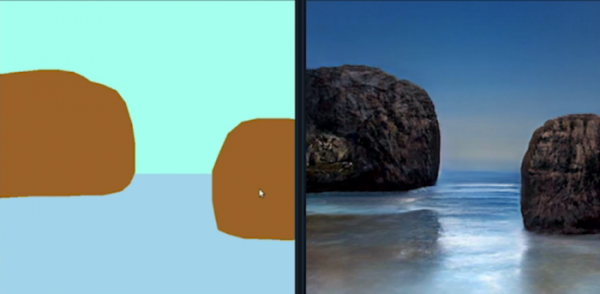
Os objetos são sintetizados por uma rede neural generativa adversarial (GAN), que cria imagens realistas com base em um mapa segmentado esquemático, utilizando detalhes de um modelo pré-treinado com milhões de fotografias. Ao contrário dos sistemas de síntese de imagens desenvolvidos anteriormente, o método proposto baseia-se em uma transformação espacial adaptativa seguida por uma transformação baseada em aprendizado de máquina. O processamento do mapa segmentado, em vez de marcação semântica, permite uma correspondência precisa do resultado e o controle do estilo.
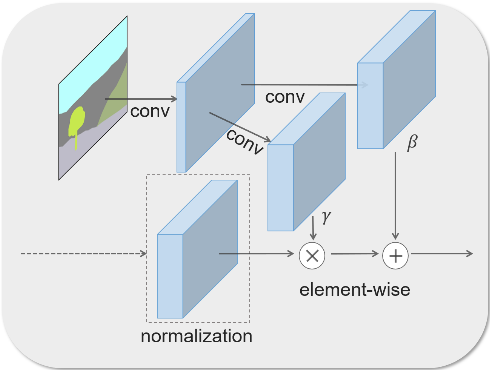
Para alcançar o realismo, duas redes neurais competem entre si: um gerador e um discriminador. O gerador gera imagens a partir da mistura de elementos de fotografias reais, e o discriminador identifica possíveis desvios das imagens reais. Como resultado, forma-se um feedback, a partir do qual o gerador passa a compor amostras cada vez melhores até que o discriminador deixe de distingui-las das reais.

Fonte: opennet.ru
