

O artigo discute várias maneiras de determinar a equação matemática de uma linha de regressão simples (emparelhado).
Todos os métodos de resolução da equação discutida aqui são baseados no método dos mínimos quadrados. Vamos denotar os métodos da seguinte forma:
- Solução analítica
- Gradiente descendente
- Descida gradiente estocástica
Para cada método de resolução da equação de uma reta, o artigo fornece diversas funções, que se dividem principalmente naquelas que são escritas sem o uso da biblioteca NumPy e aqueles que usam para cálculos NumPy. Acredita-se que o uso habilidoso NumPy reduzirá os custos de computação.
Todo o código fornecido no artigo está escrito na linguagem python-2.7 usando Caderno Jupyter. O código-fonte e o arquivo com dados de amostra estão publicados em
O artigo é mais voltado tanto para iniciantes quanto para aqueles que já começaram gradativamente a dominar o estudo de uma seção muito ampla da inteligência artificial - o aprendizado de máquina.
Para ilustrar o material, usamos um exemplo muito simples.
Condições de exemplo
Temos cinco valores que caracterizam a dependência Y de X (Tabela nº 1):
Tabela No. 1 “Exemplo de condições”

Vamos supor que os valores  é o mês do ano e
é o mês do ano e  – receita este mês. Em outras palavras, a receita depende do mês do ano, e
– receita este mês. Em outras palavras, a receita depende do mês do ano, e  - o único sinal do qual depende a receita.
- o único sinal do qual depende a receita.
O exemplo é razoável, tanto do ponto de vista da dependência condicional da receita do mês do ano, como do ponto de vista do número de valores - são muito poucos. Porém, tal simplificação permitirá, como dizem, explicar, nem sempre com facilidade, o material que os iniciantes assimilam. E também a simplicidade dos números permitirá a quem quiser resolver o exemplo no papel sem custos de mão-de-obra significativos.
Suponhamos que a dependência dada no exemplo possa ser muito bem aproximada pela equação matemática de uma linha de regressão simples (emparelhado) da forma:

onde  é o mês em que a receita foi recebida,
é o mês em que a receita foi recebida,  — receitas correspondentes ao mês,
— receitas correspondentes ao mês,  и
и  são os coeficientes de regressão da reta estimada.
são os coeficientes de regressão da reta estimada.
Observe que o coeficiente  frequentemente chamada de inclinação ou gradiente da linha estimada; representa o valor pelo qual o
frequentemente chamada de inclinação ou gradiente da linha estimada; representa o valor pelo qual o  quando isso muda
quando isso muda  .
.
Obviamente, nossa tarefa no exemplo é selecionar tais coeficientes na equação  и
и  , em que os desvios de nossos valores de receita calculados por mês em relação às respostas verdadeiras, ou seja, os valores apresentados na amostra serão mínimos.
, em que os desvios de nossos valores de receita calculados por mês em relação às respostas verdadeiras, ou seja, os valores apresentados na amostra serão mínimos.
Método dos mínimos quadrados
De acordo com o método dos mínimos quadrados, o desvio deve ser calculado elevando-o ao quadrado. Esta técnica permite evitar o cancelamento mútuo de desvios caso tenham sinais opostos. Por exemplo, se num caso o desvio for +5 (mais cinco), e no outro -5 (menos cinco), então a soma dos desvios se anulará e totalizará 0 (zero). Você não precisa elevar o desvio ao quadrado, mas use a propriedade do módulo e então todos os desvios serão positivos e se acumularão. Não nos deteremos neste ponto em detalhes, mas simplesmente indicaremos que, para comodidade dos cálculos, costuma-se quadrar o desvio.
Esta é a aparência da fórmula com a qual determinaremos a menor soma dos desvios quadrados (erros):

onde  é uma função da aproximação das respostas verdadeiras (ou seja, a receita que calculamos),
é uma função da aproximação das respostas verdadeiras (ou seja, a receita que calculamos),
 são as respostas verdadeiras (receitas fornecidas na amostra),
são as respostas verdadeiras (receitas fornecidas na amostra),
 é o índice amostral (número do mês em que o desvio é determinado)
é o índice amostral (número do mês em que o desvio é determinado)
Vamos diferenciar a função, definir as equações diferenciais parciais e estar prontos para passar à solução analítica. Mas primeiro, vamos fazer uma breve excursão sobre o que é diferenciação e lembrar o significado geométrico da derivada.
Diferenciação
A diferenciação é a operação de encontrar a derivada de uma função.
Para que é usada a derivada? A derivada de uma função caracteriza a taxa de variação da função e nos diz sua direção. Se a derivada em um determinado ponto for positiva, então a função aumenta; caso contrário, a função diminui. E quanto maior o valor da derivada absoluta, maior será a taxa de variação dos valores da função, bem como mais acentuada será a inclinação do gráfico da função.
Por exemplo, nas condições de um sistema de coordenadas cartesianas, o valor da derivada no ponto M(0,0) é igual a +25 significa que em um determinado ponto, quando o valor é deslocado  à direita por uma unidade convencional, valor
à direita por uma unidade convencional, valor  aumenta em 25 unidades convencionais. No gráfico parece um aumento bastante acentuado nos valores
aumenta em 25 unidades convencionais. No gráfico parece um aumento bastante acentuado nos valores  a partir de um determinado ponto.
a partir de um determinado ponto.
Outro exemplo. O valor da derivada é igual -0,1 significa que quando deslocado  por unidade convencional, valor
por unidade convencional, valor  diminui em apenas 0,1 unidade convencional. Ao mesmo tempo, no gráfico da função, podemos observar uma inclinação descendente quase imperceptível. Fazendo uma analogia com uma montanha, é como se descêssemos muito lentamente uma encosta suave de uma montanha, ao contrário do exemplo anterior, onde tivemos que subir picos muito íngremes :)
diminui em apenas 0,1 unidade convencional. Ao mesmo tempo, no gráfico da função, podemos observar uma inclinação descendente quase imperceptível. Fazendo uma analogia com uma montanha, é como se descêssemos muito lentamente uma encosta suave de uma montanha, ao contrário do exemplo anterior, onde tivemos que subir picos muito íngremes :)
Assim, depois de derivar a função  por probabilidades
por probabilidades  и
и  , definimos equações diferenciais parciais de 1ª ordem. Após determinar as equações, receberemos um sistema de duas equações, resolvendo as quais poderemos selecionar tais valores dos coeficientes
, definimos equações diferenciais parciais de 1ª ordem. Após determinar as equações, receberemos um sistema de duas equações, resolvendo as quais poderemos selecionar tais valores dos coeficientes  и
и  , no qual os valores das derivadas correspondentes em determinados pontos mudam em uma quantidade muito, muito pequena e, no caso de uma solução analítica, não mudam em nada. Ou seja, a função erro nos coeficientes encontrados atingirá um mínimo, pois os valores das derivadas parciais nesses pontos serão iguais a zero.
, no qual os valores das derivadas correspondentes em determinados pontos mudam em uma quantidade muito, muito pequena e, no caso de uma solução analítica, não mudam em nada. Ou seja, a função erro nos coeficientes encontrados atingirá um mínimo, pois os valores das derivadas parciais nesses pontos serão iguais a zero.
Assim, de acordo com as regras de diferenciação, a equação da derivada parcial de 1ª ordem em relação ao coeficiente  assumirá a forma:
assumirá a forma:

Equação derivada parcial de 1ª ordem em relação a  assumirá a forma:
assumirá a forma:

Como resultado, obtivemos um sistema de equações que possui uma solução analítica bastante simples:
começar{equação*}
começar{casos}
na + bsumlimits_{i=1}^nx_i — sumlimits_{i=1}^ny_i = 0
somalimits_{i=1}^nx_i(a +bsumlimits_{i=1}^nx_i — somalimits_{i=1}^ny_i) = 0
fim{casos}
fim{equação*}
Antes de resolver a equação, vamos pré-carregar, verificar se o carregamento está correto e formatar os dados.
Carregando e formatando dados
Ressalta-se que devido ao fato de que para a solução analítica, e posteriormente para gradiente e descida gradiente estocástica, utilizaremos o código em duas variações: utilizando a biblioteca NumPy e sem usá-lo, precisaremos de formatação de dados apropriada (ver código).
Código de carregamento e processamento de dados
# импортируем все нужные нам библиотеки
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import math
import pylab as pl
import random
# графики отобразим в Jupyter
%matplotlib inline
# укажем размер графиков
from pylab import rcParams
rcParams['figure.figsize'] = 12, 6
# отключим предупреждения Anaconda
import warnings
warnings.simplefilter('ignore')
# загрузим значения
table_zero = pd.read_csv('data_example.txt', header=0, sep='t')
# посмотрим информацию о таблице и на саму таблицу
print table_zero.info()
print '********************************************'
print table_zero
print '********************************************'
# подготовим данные без использования NumPy
x_us = []
[x_us.append(float(i)) for i in table_zero['x']]
print x_us
print type(x_us)
print '********************************************'
y_us = []
[y_us.append(float(i)) for i in table_zero['y']]
print y_us
print type(y_us)
print '********************************************'
# подготовим данные с использованием NumPy
x_np = table_zero[['x']].values
print x_np
print type(x_np)
print x_np.shape
print '********************************************'
y_np = table_zero[['y']].values
print y_np
print type(y_np)
print y_np.shape
print '********************************************'Visualização
Agora, depois de termos, em primeiro lugar, carregado os dados, em segundo lugar, verificado a exatidão do carregamento e finalmente formatado os dados, faremos a primeira visualização. O método frequentemente usado para isso é gráfico de pares Biblioteca marinho. No nosso exemplo, devido ao número limitado, não faz sentido usar a biblioteca marinho. Usaremos a biblioteca normal matplotlib e basta olhar para o gráfico de dispersão.
Código do gráfico de dispersão
print 'График №1 "Зависимость выручки от месяца года"'
plt.plot(x_us,y_us,'o',color='green',markersize=16)
plt.xlabel('$Months$', size=16)
plt.ylabel('$Sales$', size=16)
plt.show()Gráfico nº 1 “Dependência da receita do mês do ano”
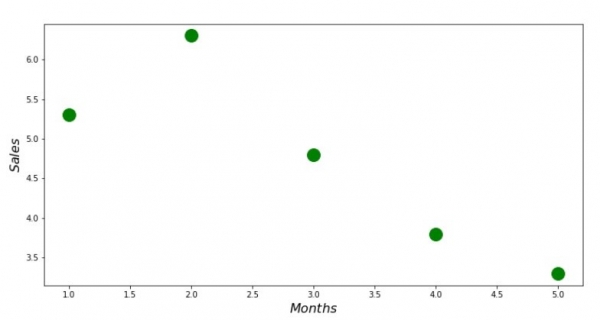
Solução analítica
Vamos usar as ferramentas mais comuns em python e resolva o sistema de equações:
começar{equação*}
começar{casos}
na + bsumlimits_{i=1}^nx_i — sumlimits_{i=1}^ny_i = 0
somalimits_{i=1}^nx_i(a +bsumlimits_{i=1}^nx_i — somalimits_{i=1}^ny_i) = 0
fim{casos}
fim{equação*}
De acordo com a regra de Cramer encontraremos o determinante geral, bem como os determinantes por  e
e  , após o que, dividindo o determinante por
, após o que, dividindo o determinante por  para o determinante geral - encontre o coeficiente
para o determinante geral - encontre o coeficiente  , da mesma forma encontramos o coeficiente
, da mesma forma encontramos o coeficiente  .
.
Código da solução analítica
# определим функцию для расчета коэффициентов a и b по правилу Крамера
def Kramer_method (x,y):
# сумма значений (все месяца)
sx = sum(x)
# сумма истинных ответов (выручка за весь период)
sy = sum(y)
# сумма произведения значений на истинные ответы
list_xy = []
[list_xy.append(x[i]*y[i]) for i in range(len(x))]
sxy = sum(list_xy)
# сумма квадратов значений
list_x_sq = []
[list_x_sq.append(x[i]**2) for i in range(len(x))]
sx_sq = sum(list_x_sq)
# количество значений
n = len(x)
# общий определитель
det = sx_sq*n - sx*sx
# определитель по a
det_a = sx_sq*sy - sx*sxy
# искомый параметр a
a = (det_a / det)
# определитель по b
det_b = sxy*n - sy*sx
# искомый параметр b
b = (det_b / det)
# контрольные значения (прооверка)
check1 = (n*b + a*sx - sy)
check2 = (b*sx + a*sx_sq - sxy)
return [round(a,4), round(b,4)]
# запустим функцию и запишем правильные ответы
ab_us = Kramer_method(x_us,y_us)
a_us = ab_us[0]
b_us = ab_us[1]
print ' 33[1m' + ' 33[4m' + "Оптимальные значения коэффициентов a и b:" + ' 33[0m'
print 'a =', a_us
print 'b =', b_us
print
# определим функцию для подсчета суммы квадратов ошибок
def errors_sq_Kramer_method(answers,x,y):
list_errors_sq = []
for i in range(len(x)):
err = (answers[0] + answers[1]*x[i] - y[i])**2
list_errors_sq.append(err)
return sum(list_errors_sq)
# запустим функцию и запишем значение ошибки
error_sq = errors_sq_Kramer_method(ab_us,x_us,y_us)
print ' 33[1m' + ' 33[4m' + "Сумма квадратов отклонений" + ' 33[0m'
print error_sq
print
# замерим время расчета
# print ' 33[1m' + ' 33[4m' + "Время выполнения расчета суммы квадратов отклонений:" + ' 33[0m'
# % timeit error_sq = errors_sq_Kramer_method(ab,x_us,y_us)Aqui está o que temos:

Assim, encontrados os valores dos coeficientes, foi estabelecida a soma dos quadrados dos desvios. Desenhe uma linha reta no histograma de dispersão de acordo com os coeficientes encontrados.
Código de linha de regressão
# определим функцию для формирования массива рассчетных значений выручки
def sales_count(ab,x,y):
line_answers = []
[line_answers.append(ab[0]+ab[1]*x[i]) for i in range(len(x))]
return line_answers
# построим графики
print 'Грфик№2 "Правильные и расчетные ответы"'
plt.plot(x_us,y_us,'o',color='green',markersize=16, label = '$True$ $answers$')
plt.plot(x_us, sales_count(ab_us,x_us,y_us), color='red',lw=4,
label='$Function: a + bx,$ $where$ $a='+str(round(ab_us[0],2))+',$ $b='+str(round(ab_us[1],2))+'$')
plt.xlabel('$Months$', size=16)
plt.ylabel('$Sales$', size=16)
plt.legend(loc=1, prop={'size': 16})
plt.show()Gráfico nº 2 “Respostas corretas e calculadas”
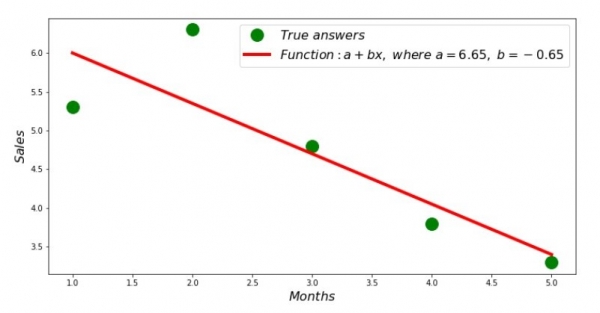
Você pode ver o gráfico de desvio para cada mês. No nosso caso, não derivaremos dela nenhum valor prático significativo, mas satisfaremos a nossa curiosidade sobre quão bem a equação de regressão linear simples caracteriza a dependência da receita do mês do ano.
Código do gráfico de desvio
# определим функцию для формирования массива отклонений в процентах
def error_per_month(ab,x,y):
sales_c = sales_count(ab,x,y)
errors_percent = []
for i in range(len(x)):
errors_percent.append(100*(sales_c[i]-y[i])/y[i])
return errors_percent
# построим график
print 'График№3 "Отклонения по-месячно, %"'
plt.gca().bar(x_us, error_per_month(ab_us,x_us,y_us), color='brown')
plt.xlabel('Months', size=16)
plt.ylabel('Calculation error, %', size=16)
plt.show()Gráfico nº 3 “Desvios,%”
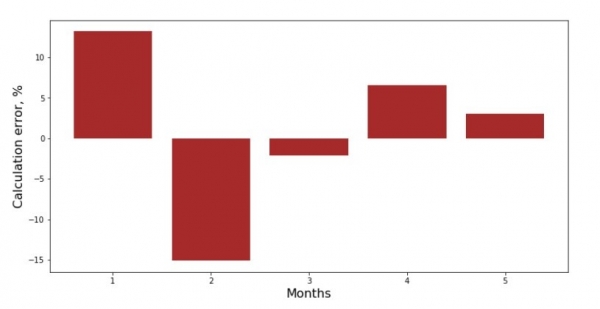
Não é perfeito, mas concluímos nossa tarefa.
Vamos escrever uma função que, para determinar os coeficientes  и
и  usa a biblioteca NumPy, mais precisamente, escreveremos duas funções: uma usando uma matriz pseudoinversa (não recomendada na prática, pois o processo é computacionalmente complexo e instável), a outra usando uma equação matricial.
usa a biblioteca NumPy, mais precisamente, escreveremos duas funções: uma usando uma matriz pseudoinversa (não recomendada na prática, pois o processo é computacionalmente complexo e instável), a outra usando uma equação matricial.
Código da solução analítica (NumPy)
# для начала добавим столбец с не изменяющимся значением в 1.
# Данный столбец нужен для того, чтобы не обрабатывать отдельно коэффицент a
vector_1 = np.ones((x_np.shape[0],1))
x_np = table_zero[['x']].values # на всякий случай приведем в первичный формат вектор x_np
x_np = np.hstack((vector_1,x_np))
# проверим то, что все сделали правильно
print vector_1[0:3]
print x_np[0:3]
print '***************************************'
print
# напишем функцию, которая определяет значения коэффициентов a и b с использованием псевдообратной матрицы
def pseudoinverse_matrix(X, y):
# задаем явный формат матрицы признаков
X = np.matrix(X)
# определяем транспонированную матрицу
XT = X.T
# определяем квадратную матрицу
XTX = XT*X
# определяем псевдообратную матрицу
inv = np.linalg.pinv(XTX)
# задаем явный формат матрицы ответов
y = np.matrix(y)
# находим вектор весов
return (inv*XT)*y
# запустим функцию
ab_np = pseudoinverse_matrix(x_np, y_np)
print ab_np
print '***************************************'
print
# напишем функцию, которая использует для решения матричное уравнение
def matrix_equation(X,y):
a = np.dot(X.T, X)
b = np.dot(X.T, y)
return np.linalg.solve(a, b)
# запустим функцию
ab_np = matrix_equation(x_np,y_np)
print ab_npVamos comparar o tempo gasto na determinação dos coeficientes  и
и  , de acordo com os 3 métodos apresentados.
, de acordo com os 3 métodos apresentados.
Código para calcular o tempo de cálculo
print ' 33[1m' + ' 33[4m' + "Время выполнения расчета коэффициентов без использования библиотеки NumPy:" + ' 33[0m'
% timeit ab_us = Kramer_method(x_us,y_us)
print '***************************************'
print
print ' 33[1m' + ' 33[4m' + "Время выполнения расчета коэффициентов с использованием псевдообратной матрицы:" + ' 33[0m'
%timeit ab_np = pseudoinverse_matrix(x_np, y_np)
print '***************************************'
print
print ' 33[1m' + ' 33[4m' + "Время выполнения расчета коэффициентов с использованием матричного уравнения:" + ' 33[0m'
%timeit ab_np = matrix_equation(x_np, y_np)
Com uma pequena quantidade de dados, sai na frente uma função “autoescrita”, que encontra os coeficientes usando o método de Cramer.
Agora você pode passar para outras maneiras de encontrar coeficientes  и
и  .
.
Gradiente descendente
Primeiro, vamos definir o que é um gradiente. Simplificando, o gradiente é um segmento que indica a direção de crescimento máximo de uma função. Por analogia com a escalada de uma montanha, onde o gradiente enfrenta é onde está a subida mais íngreme até o topo da montanha. Desenvolvendo o exemplo da montanha, lembramos que na verdade precisamos da descida mais íngreme para chegar o mais rápido possível à baixada, ou seja, o mínimo - o local onde a função não aumenta nem diminui. Neste ponto a derivada será igual a zero. Portanto, não precisamos de um gradiente, mas sim de um antigradiente. Para encontrar o antigradiente basta multiplicar o gradiente por -1 (menos um).
Prestemos atenção ao fato de que uma função pode ter vários mínimos, e tendo descido a um deles utilizando o algoritmo proposto a seguir, não conseguiremos encontrar outro mínimo, que pode ser inferior ao encontrado. Vamos relaxar, isso não é uma ameaça para nós! No nosso caso estamos lidando com um único mínimo, já que nossa função  no gráfico é uma parábola regular. E como todos deveríamos saber muito bem no nosso curso escolar de matemática, uma parábola tem apenas um mínimo.
no gráfico é uma parábola regular. E como todos deveríamos saber muito bem no nosso curso escolar de matemática, uma parábola tem apenas um mínimo.
Depois descobrimos porque precisávamos de um gradiente, e também que o gradiente é um segmento, ou seja, um vetor com determinadas coordenadas, que são precisamente os mesmos coeficientes  и
и  podemos implementar a descida gradiente.
podemos implementar a descida gradiente.
Antes de começar, sugiro ler apenas algumas frases sobre o algoritmo de descida:
- Determinamos de forma pseudo-aleatória as coordenadas dos coeficientes
 и . Em nosso exemplo, determinaremos coeficientes próximos de zero. Esta é uma prática comum, mas cada caso pode ter sua própria prática.
и . Em nosso exemplo, determinaremos coeficientes próximos de zero. Esta é uma prática comum, mas cada caso pode ter sua própria prática. - Da coordenada subtraia o valor da derivada parcial de 1ª ordem no ponto . Portanto, se a derivada for positiva, a função aumenta. Portanto, ao subtrair o valor da derivada, avançaremos na direção oposta ao crescimento, ou seja, na direção de descida. Se a derivada for negativa, então a função neste ponto diminui e subtraindo o valor da derivada nos movemos na direção de descida.
- Realizamos uma operação semelhante com a coordenada : subtraia o valor da derivada parcial no ponto .
- Para não pular o mínimo e voar para o espaço profundo, é necessário definir o tamanho do passo na direção da descida. Em geral, você poderia escrever um artigo inteiro sobre como definir o degrau corretamente e como alterá-lo durante o processo de descida para reduzir custos computacionais. Mas agora temos uma tarefa um pouco diferente pela frente, e estabeleceremos o tamanho do passo usando o método científico de “cutucar” ou, como dizem na linguagem comum, empiricamente.
- Assim que estivermos nas coordenadas fornecidas и subtrair os valores das derivadas, obtemos novas coordenadas и . Damos o próximo passo (subtração), já a partir das coordenadas calculadas. E assim o ciclo recomeça continuamente, até que a convergência necessária seja alcançada.
 и
и  . Em nosso exemplo, determinaremos coeficientes próximos de zero. Esta é uma prática comum, mas cada caso pode ter sua própria prática.
. Em nosso exemplo, determinaremos coeficientes próximos de zero. Esta é uma prática comum, mas cada caso pode ter sua própria prática. subtraia o valor da derivada parcial de 1ª ordem no ponto
subtraia o valor da derivada parcial de 1ª ordem no ponto  . Portanto, se a derivada for positiva, a função aumenta. Portanto, ao subtrair o valor da derivada, avançaremos na direção oposta ao crescimento, ou seja, na direção de descida. Se a derivada for negativa, então a função neste ponto diminui e subtraindo o valor da derivada nos movemos na direção de descida.
. Portanto, se a derivada for positiva, a função aumenta. Portanto, ao subtrair o valor da derivada, avançaremos na direção oposta ao crescimento, ou seja, na direção de descida. Se a derivada for negativa, então a função neste ponto diminui e subtraindo o valor da derivada nos movemos na direção de descida.  : subtraia o valor da derivada parcial no ponto
: subtraia o valor da derivada parcial no ponto  .
. и
и  subtrair os valores das derivadas, obtemos novas coordenadas
subtrair os valores das derivadas, obtemos novas coordenadas  и
и  . Damos o próximo passo (subtração), já a partir das coordenadas calculadas. E assim o ciclo recomeça continuamente, até que a convergência necessária seja alcançada.
. Damos o próximo passo (subtração), já a partir das coordenadas calculadas. E assim o ciclo recomeça continuamente, até que a convergência necessária seja alcançada.Todos! Agora estamos prontos para partir em busca do desfiladeiro mais profundo da Fossa das Marianas. Vamos começar.
Código para descida gradiente
# напишем функцию градиентного спуска без использования библиотеки NumPy.
# Функция на вход принимает диапазоны значений x,y, длину шага (по умолчанию=0,1), допустимую погрешность(tolerance)
def gradient_descent_usual(x_us,y_us,l=0.1,tolerance=0.000000000001):
# сумма значений (все месяца)
sx = sum(x_us)
# сумма истинных ответов (выручка за весь период)
sy = sum(y_us)
# сумма произведения значений на истинные ответы
list_xy = []
[list_xy.append(x_us[i]*y_us[i]) for i in range(len(x_us))]
sxy = sum(list_xy)
# сумма квадратов значений
list_x_sq = []
[list_x_sq.append(x_us[i]**2) for i in range(len(x_us))]
sx_sq = sum(list_x_sq)
# количество значений
num = len(x_us)
# начальные значения коэффициентов, определенные псевдослучайным образом
a = float(random.uniform(-0.5, 0.5))
b = float(random.uniform(-0.5, 0.5))
# создаем массив с ошибками, для старта используем значения 1 и 0
# после завершения спуска стартовые значения удалим
errors = [1,0]
# запускаем цикл спуска
# цикл работает до тех пор, пока отклонение последней ошибки суммы квадратов от предыдущей, не будет меньше tolerance
while abs(errors[-1]-errors[-2]) > tolerance:
a_step = a - l*(num*a + b*sx - sy)/num
b_step = b - l*(a*sx + b*sx_sq - sxy)/num
a = a_step
b = b_step
ab = [a,b]
errors.append(errors_sq_Kramer_method(ab,x_us,y_us))
return (ab),(errors[2:])
# запишем массив значений
list_parametres_gradient_descence = gradient_descent_usual(x_us,y_us,l=0.1,tolerance=0.000000000001)
print ' 33[1m' + ' 33[4m' + "Значения коэффициентов a и b:" + ' 33[0m'
print 'a =', round(list_parametres_gradient_descence[0][0],3)
print 'b =', round(list_parametres_gradient_descence[0][1],3)
print
print ' 33[1m' + ' 33[4m' + "Сумма квадратов отклонений:" + ' 33[0m'
print round(list_parametres_gradient_descence[1][-1],3)
print
print ' 33[1m' + ' 33[4m' + "Количество итераций в градиентном спуске:" + ' 33[0m'
print len(list_parametres_gradient_descence[1])
print
Mergulhamos até o fundo da Fossa das Marianas e lá encontramos todos os mesmos valores de coeficiente  и
и  , que é exatamente o que era de se esperar.
, que é exatamente o que era de se esperar.
Vamos dar mais um mergulho, só que desta vez o nosso veículo de alto mar estará repleto de outras tecnologias, nomeadamente uma biblioteca NumPy.
Código para descida gradiente (NumPy)
# перед тем определить функцию для градиентного спуска с использованием библиотеки NumPy,
# напишем функцию определения суммы квадратов отклонений также с использованием NumPy
def error_square_numpy(ab,x_np,y_np):
y_pred = np.dot(x_np,ab)
error = y_pred - y_np
return sum((error)**2)
# напишем функцию градиентного спуска с использованием библиотеки NumPy.
# Функция на вход принимает диапазоны значений x,y, длину шага (по умолчанию=0,1), допустимую погрешность(tolerance)
def gradient_descent_numpy(x_np,y_np,l=0.1,tolerance=0.000000000001):
# сумма значений (все месяца)
sx = float(sum(x_np[:,1]))
# сумма истинных ответов (выручка за весь период)
sy = float(sum(y_np))
# сумма произведения значений на истинные ответы
sxy = x_np*y_np
sxy = float(sum(sxy[:,1]))
# сумма квадратов значений
sx_sq = float(sum(x_np[:,1]**2))
# количество значений
num = float(x_np.shape[0])
# начальные значения коэффициентов, определенные псевдослучайным образом
a = float(random.uniform(-0.5, 0.5))
b = float(random.uniform(-0.5, 0.5))
# создаем массив с ошибками, для старта используем значения 1 и 0
# после завершения спуска стартовые значения удалим
errors = [1,0]
# запускаем цикл спуска
# цикл работает до тех пор, пока отклонение последней ошибки суммы квадратов от предыдущей, не будет меньше tolerance
while abs(errors[-1]-errors[-2]) > tolerance:
a_step = a - l*(num*a + b*sx - sy)/num
b_step = b - l*(a*sx + b*sx_sq - sxy)/num
a = a_step
b = b_step
ab = np.array([[a],[b]])
errors.append(error_square_numpy(ab,x_np,y_np))
return (ab),(errors[2:])
# запишем массив значений
list_parametres_gradient_descence = gradient_descent_numpy(x_np,y_np,l=0.1,tolerance=0.000000000001)
print ' 33[1m' + ' 33[4m' + "Значения коэффициентов a и b:" + ' 33[0m'
print 'a =', round(list_parametres_gradient_descence[0][0],3)
print 'b =', round(list_parametres_gradient_descence[0][1],3)
print
print ' 33[1m' + ' 33[4m' + "Сумма квадратов отклонений:" + ' 33[0m'
print round(list_parametres_gradient_descence[1][-1],3)
print
print ' 33[1m' + ' 33[4m' + "Количество итераций в градиентном спуске:" + ' 33[0m'
print len(list_parametres_gradient_descence[1])
print
Valores de coeficiente  и
и  imutável.
imutável.
Vejamos como o erro mudou durante a descida do gradiente, ou seja, como a soma dos desvios quadrados mudou a cada passo.
Código para traçar somas de desvios quadrados
print 'График№4 "Сумма квадратов отклонений по-шагово"'
plt.plot(range(len(list_parametres_gradient_descence[1])), list_parametres_gradient_descence[1], color='red', lw=3)
plt.xlabel('Steps (Iteration)', size=16)
plt.ylabel('Sum of squared deviations', size=16)
plt.show()Gráfico nº 4 “Soma dos desvios quadrados durante a descida do gradiente”
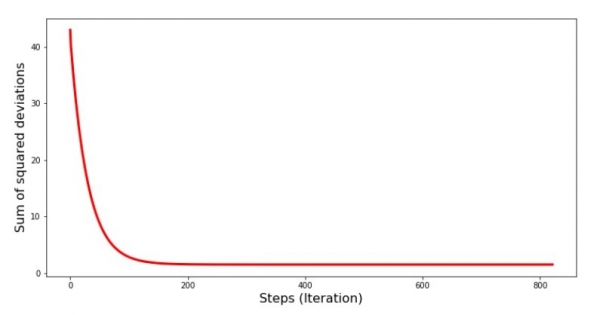
No gráfico vemos que a cada passo o erro diminui, e após um certo número de iterações observamos uma linha quase horizontal.
Finalmente, vamos estimar a diferença no tempo de execução do código:
Código para determinar o tempo de cálculo da descida do gradiente
print ' 33[1m' + ' 33[4m' + "Время выполнения градиентного спуска без использования библиотеки NumPy:" + ' 33[0m'
%timeit list_parametres_gradient_descence = gradient_descent_usual(x_us,y_us,l=0.1,tolerance=0.000000000001)
print '***************************************'
print
print ' 33[1m' + ' 33[4m' + "Время выполнения градиентного спуска с использованием библиотеки NumPy:" + ' 33[0m'
%timeit list_parametres_gradient_descence = gradient_descent_numpy(x_np,y_np,l=0.1,tolerance=0.000000000001)
Talvez estejamos fazendo algo errado, mas novamente é uma função simples “escrita em casa” que não usa a biblioteca NumPy supera o tempo de cálculo de uma função usando a biblioteca NumPy.
Mas não estamos parados, mas sim avançando no estudo de outra maneira interessante de resolver a equação de regressão linear simples. Encontrar!
Descida gradiente estocástica
Para compreender rapidamente o princípio de operação da descida gradiente estocástica, é melhor determinar suas diferenças em relação à descida gradiente comum. Nós, no caso do gradiente descendente, nas equações das derivadas de  и
и  usou as somas dos valores de todos os recursos e respostas verdadeiras disponíveis na amostra (ou seja, as somas de todos
usou as somas dos valores de todos os recursos e respostas verdadeiras disponíveis na amostra (ou seja, as somas de todos  и
и  ). Na descida gradiente estocástica, não usaremos todos os valores presentes na amostra, mas em vez disso, selecionaremos pseudo-aleatoriamente o chamado índice de amostra e usaremos seus valores.
). Na descida gradiente estocástica, não usaremos todos os valores presentes na amostra, mas em vez disso, selecionaremos pseudo-aleatoriamente o chamado índice de amostra e usaremos seus valores.
Por exemplo, se o índice for determinado como o número 3 (três), então tomamos os valores  и
и  , então substituímos os valores nas equações derivadas e determinamos novas coordenadas. Então, tendo determinado as coordenadas, determinamos novamente pseudo-aleatoriamente o índice da amostra, substituímos os valores correspondentes ao índice nas equações diferenciais parciais e determinamos as coordenadas de uma nova maneira
, então substituímos os valores nas equações derivadas e determinamos novas coordenadas. Então, tendo determinado as coordenadas, determinamos novamente pseudo-aleatoriamente o índice da amostra, substituímos os valores correspondentes ao índice nas equações diferenciais parciais e determinamos as coordenadas de uma nova maneira  и
и  etc. até que a convergência fique verde. À primeira vista, pode não parecer que isso funcione, mas funciona. É verdade que vale ressaltar que o erro não diminui a cada passo, mas certamente há uma tendência.
etc. até que a convergência fique verde. À primeira vista, pode não parecer que isso funcione, mas funciona. É verdade que vale ressaltar que o erro não diminui a cada passo, mas certamente há uma tendência.
Quais são as vantagens da descida gradiente estocástica em relação à convencional? Se o tamanho da nossa amostra for muito grande e medido em dezenas de milhares de valores, será muito mais fácil processar, digamos, milhares deles aleatoriamente, em vez de toda a amostra. É aqui que entra em jogo a descida gradiente estocástica. No nosso caso, é claro, não notaremos muita diferença.
Vejamos o código.
Código para descida gradiente estocástica
# определим функцию стох.град.шага
def stoch_grad_step_usual(vector_init, x_us, ind, y_us, l):
# выбираем значение икс, которое соответствует случайному значению параметра ind
# (см.ф-цию stoch_grad_descent_usual)
x = x_us[ind]
# рассчитывыаем значение y (выручку), которая соответствует выбранному значению x
y_pred = vector_init[0] + vector_init[1]*x_us[ind]
# вычисляем ошибку расчетной выручки относительно представленной в выборке
error = y_pred - y_us[ind]
# определяем первую координату градиента ab
grad_a = error
# определяем вторую координату ab
grad_b = x_us[ind]*error
# вычисляем новый вектор коэффициентов
vector_new = [vector_init[0]-l*grad_a, vector_init[1]-l*grad_b]
return vector_new
# определим функцию стох.град.спуска
def stoch_grad_descent_usual(x_us, y_us, l=0.1, steps = 800):
# для самого начала работы функции зададим начальные значения коэффициентов
vector_init = [float(random.uniform(-0.5, 0.5)), float(random.uniform(-0.5, 0.5))]
errors = []
# запустим цикл спуска
# цикл расчитан на определенное количество шагов (steps)
for i in range(steps):
ind = random.choice(range(len(x_us)))
new_vector = stoch_grad_step_usual(vector_init, x_us, ind, y_us, l)
vector_init = new_vector
errors.append(errors_sq_Kramer_method(vector_init,x_us,y_us))
return (vector_init),(errors)
# запишем массив значений
list_parametres_stoch_gradient_descence = stoch_grad_descent_usual(x_us, y_us, l=0.1, steps = 800)
print ' 33[1m' + ' 33[4m' + "Значения коэффициентов a и b:" + ' 33[0m'
print 'a =', round(list_parametres_stoch_gradient_descence[0][0],3)
print 'b =', round(list_parametres_stoch_gradient_descence[0][1],3)
print
print ' 33[1m' + ' 33[4m' + "Сумма квадратов отклонений:" + ' 33[0m'
print round(list_parametres_stoch_gradient_descence[1][-1],3)
print
print ' 33[1m' + ' 33[4m' + "Количество итераций в стохастическом градиентном спуске:" + ' 33[0m'
print len(list_parametres_stoch_gradient_descence[1])
Observamos cuidadosamente os coeficientes e nos surpreendemos perguntando “Como pode ser isso?” Temos outros valores de coeficiente  и
и  . Talvez a descida gradiente estocástica tenha encontrado parâmetros mais ideais para a equação? Infelizmente não. Basta olhar a soma dos desvios quadrados e ver que com novos valores dos coeficientes o erro é maior. Não temos pressa em nos desesperar. Vamos construir um gráfico da mudança de erro.
. Talvez a descida gradiente estocástica tenha encontrado parâmetros mais ideais para a equação? Infelizmente não. Basta olhar a soma dos desvios quadrados e ver que com novos valores dos coeficientes o erro é maior. Não temos pressa em nos desesperar. Vamos construir um gráfico da mudança de erro.
Código para traçar a soma dos desvios quadrados na descida gradiente estocástica
print 'График №5 "Сумма квадратов отклонений по-шагово"'
plt.plot(range(len(list_parametres_stoch_gradient_descence[1])), list_parametres_stoch_gradient_descence[1], color='red', lw=2)
plt.xlabel('Steps (Iteration)', size=16)
plt.ylabel('Sum of squared deviations', size=16)
plt.show()Gráfico nº 5 “Soma dos desvios quadrados durante a descida gradiente estocástica”
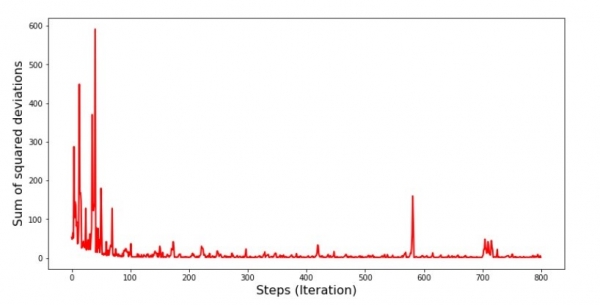
Olhando o cronograma, tudo se encaixa e agora vamos consertar tudo.
Então o que aconteceu? Aconteceu o seguinte. Quando selecionamos um mês aleatoriamente, então é para o mês selecionado que nosso algoritmo busca reduzir o erro no cálculo da receita. Depois selecionamos outro mês e repetimos o cálculo, mas reduzimos o erro para o segundo mês selecionado. Agora lembre-se que os primeiros dois meses se desviam significativamente da linha da equação de regressão linear simples. Isso significa que quando qualquer um desses dois meses é selecionado, ao reduzir o erro de cada um deles, nosso algoritmo aumenta seriamente o erro de toda a amostra. Então o que fazer? A resposta é simples: você precisa reduzir o degrau de descida. Afinal, ao reduzir o degrau de descida, o erro também deixará de “saltar” para cima e para baixo. Ou melhor, o erro de “salto” não vai parar, mas não vai parar tão rápido :) Vamos verificar.
Código para executar SGD com incrementos menores
# запустим функцию, уменьшив шаг в 100 раз и увеличив количество шагов соответсвующе
list_parametres_stoch_gradient_descence = stoch_grad_descent_usual(x_us, y_us, l=0.001, steps = 80000)
print ' 33[1m' + ' 33[4m' + "Значения коэффициентов a и b:" + ' 33[0m'
print 'a =', round(list_parametres_stoch_gradient_descence[0][0],3)
print 'b =', round(list_parametres_stoch_gradient_descence[0][1],3)
print
print ' 33[1m' + ' 33[4m' + "Сумма квадратов отклонений:" + ' 33[0m'
print round(list_parametres_stoch_gradient_descence[1][-1],3)
print
print ' 33[1m' + ' 33[4m' + "Количество итераций в стохастическом градиентном спуске:" + ' 33[0m'
print len(list_parametres_stoch_gradient_descence[1])
print 'График №6 "Сумма квадратов отклонений по-шагово"'
plt.plot(range(len(list_parametres_stoch_gradient_descence[1])), list_parametres_stoch_gradient_descence[1], color='red', lw=2)
plt.xlabel('Steps (Iteration)', size=16)
plt.ylabel('Sum of squared deviations', size=16)
plt.show()
Gráfico nº 6 “Soma dos desvios quadrados durante a descida gradiente estocástica (80 mil passos)”
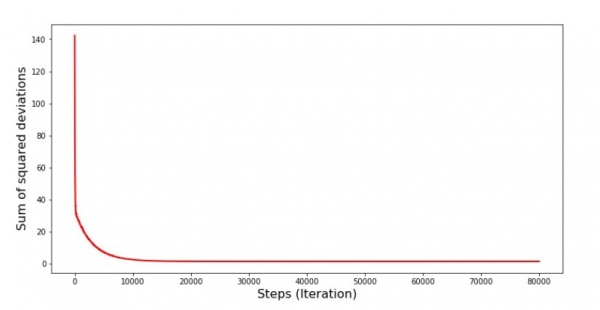
Os coeficientes melhoraram, mas ainda não são os ideais. Hipoteticamente, isso pode ser corrigido desta forma. Selecionamos, por exemplo, nas últimas 1000 iterações os valores dos coeficientes com os quais foi cometido o erro mínimo. É verdade que para isso também teremos que anotar os valores dos próprios coeficientes. Não faremos isso, mas sim ficaremos atentos ao cronograma. Parece suave e o erro parece diminuir uniformemente. Na verdade isso não é verdade. Vejamos as primeiras 1000 iterações e compará-las com as últimas.
Código para gráfico SGD (primeiros 1000 passos)
print 'График №7 "Сумма квадратов отклонений по-шагово. Первые 1000 итераций"'
plt.plot(range(len(list_parametres_stoch_gradient_descence[1][:1000])),
list_parametres_stoch_gradient_descence[1][:1000], color='red', lw=2)
plt.xlabel('Steps (Iteration)', size=16)
plt.ylabel('Sum of squared deviations', size=16)
plt.show()
print 'График №7 "Сумма квадратов отклонений по-шагово. Последние 1000 итераций"'
plt.plot(range(len(list_parametres_stoch_gradient_descence[1][-1000:])),
list_parametres_stoch_gradient_descence[1][-1000:], color='red', lw=2)
plt.xlabel('Steps (Iteration)', size=16)
plt.ylabel('Sum of squared deviations', size=16)
plt.show()Gráfico nº 7 “Soma dos desvios quadrados SGD (primeiros 1000 passos)”
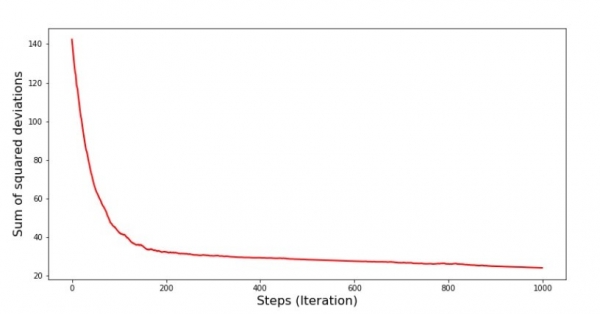
Gráfico nº 8 “Soma dos desvios quadrados SGD (últimos 1000 passos)”
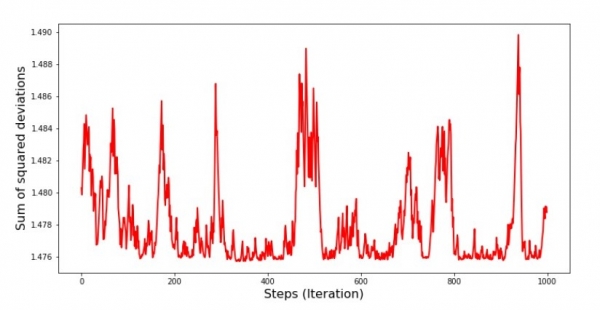
Logo no início da descida, observamos uma diminuição do erro bastante uniforme e acentuada. Nas últimas iterações, vemos que o erro gira e volta do valor de 1,475 e em alguns momentos até se iguala a esse valor ótimo, mas depois ainda sobe... Repito, você pode anotar os valores do coeficientes  и
и  e selecione aqueles para os quais o erro é mínimo. Porém, tivemos um problema mais sério: tivemos que dar 80 mil passos (ver código) para chegar a valores próximos do ideal. E isso já contradiz a ideia de economizar tempo de cálculo com descida gradiente estocástica em relação à descida gradiente. O que pode ser corrigido e melhorado? Não é difícil perceber que nas primeiras iterações estamos descendo com confiança e, portanto, devemos deixar um grande passo nas primeiras iterações e reduzir o passo à medida que avançamos. Não faremos isso neste artigo - já é muito longo. Quem quiser pode pensar por si mesmo como fazer isso, não é difícil :)
e selecione aqueles para os quais o erro é mínimo. Porém, tivemos um problema mais sério: tivemos que dar 80 mil passos (ver código) para chegar a valores próximos do ideal. E isso já contradiz a ideia de economizar tempo de cálculo com descida gradiente estocástica em relação à descida gradiente. O que pode ser corrigido e melhorado? Não é difícil perceber que nas primeiras iterações estamos descendo com confiança e, portanto, devemos deixar um grande passo nas primeiras iterações e reduzir o passo à medida que avançamos. Não faremos isso neste artigo - já é muito longo. Quem quiser pode pensar por si mesmo como fazer isso, não é difícil :)
Agora vamos realizar a descida gradiente estocástica usando a biblioteca NumPy (e não vamos tropeçar nas pedras que identificamos anteriormente)
Código para descida gradiente estocástica (NumPy)
# для начала напишем функцию градиентного шага
def stoch_grad_step_numpy(vector_init, X, ind, y, l):
x = X[ind]
y_pred = np.dot(x,vector_init)
err = y_pred - y[ind]
grad_a = err
grad_b = x[1]*err
return vector_init - l*np.array([grad_a, grad_b])
# определим функцию стохастического градиентного спуска
def stoch_grad_descent_numpy(X, y, l=0.1, steps = 800):
vector_init = np.array([[np.random.randint(X.shape[0])], [np.random.randint(X.shape[0])]])
errors = []
for i in range(steps):
ind = np.random.randint(X.shape[0])
new_vector = stoch_grad_step_numpy(vector_init, X, ind, y, l)
vector_init = new_vector
errors.append(error_square_numpy(vector_init,X,y))
return (vector_init), (errors)
# запишем массив значений
list_parametres_stoch_gradient_descence = stoch_grad_descent_numpy(x_np, y_np, l=0.001, steps = 80000)
print ' 33[1m' + ' 33[4m' + "Значения коэффициентов a и b:" + ' 33[0m'
print 'a =', round(list_parametres_stoch_gradient_descence[0][0],3)
print 'b =', round(list_parametres_stoch_gradient_descence[0][1],3)
print
print ' 33[1m' + ' 33[4m' + "Сумма квадратов отклонений:" + ' 33[0m'
print round(list_parametres_stoch_gradient_descence[1][-1],3)
print
print ' 33[1m' + ' 33[4m' + "Количество итераций в стохастическом градиентном спуске:" + ' 33[0m'
print len(list_parametres_stoch_gradient_descence[1])
print
Os valores acabaram sendo quase os mesmos de descer sem usar NumPy. No entanto, isso é lógico.
Vamos descobrir quanto tempo levaram as descidas gradientes estocásticas.
Código para determinação do tempo de cálculo do SGD (80 mil passos)
print ' 33[1m' + ' 33[4m' +
"Время выполнения стохастического градиентного спуска без использования библиотеки NumPy:"
+ ' 33[0m'
%timeit list_parametres_stoch_gradient_descence = stoch_grad_descent_usual(x_us, y_us, l=0.001, steps = 80000)
print '***************************************'
print
print ' 33[1m' + ' 33[4m' +
"Время выполнения стохастического градиентного спуска с использованием библиотеки NumPy:"
+ ' 33[0m'
%timeit list_parametres_stoch_gradient_descence = stoch_grad_descent_numpy(x_np, y_np, l=0.001, steps = 80000)
Quanto mais dentro da floresta, mais escuras são as nuvens: mais uma vez, a fórmula “auto-escrita” mostra o melhor resultado. Tudo isso sugere que deve haver maneiras ainda mais sutis de usar a biblioteca NumPy, o que realmente acelera as operações de computação. Neste artigo não aprenderemos sobre eles. Haverá algo em que pensar no seu tempo livre :)
Vamos resumir
Antes de resumir, gostaria de responder a uma pergunta que muito provavelmente surgiu do nosso caro leitor. Por que, de fato, tanta “tortura” com descidas, por que precisamos subir e descer a montanha (principalmente descer) para encontrar a preciosa planície, se temos em mãos um dispositivo tão poderoso e simples, no forma de solução analítica, que nos teletransporta instantaneamente para o lugar certo?
A resposta a esta pergunta está na superfície. Agora vimos um exemplo muito simples, no qual a verdadeira resposta é  depende de um sinal
depende de um sinal  . Você não vê isso com frequência na vida, então vamos imaginar que temos 2, 30, 50 ou mais signos. Vamos adicionar a isso milhares, ou mesmo dezenas de milhares de valores para cada atributo. Neste caso, a solução analítica pode não resistir ao teste e falhar. Por sua vez, a descida do gradiente e suas variações nos aproximarão lenta mas seguramente do objetivo - o mínimo da função. E não se preocupe com a velocidade - provavelmente veremos maneiras que nos permitirão definir e regular o comprimento do passo (ou seja, a velocidade).
. Você não vê isso com frequência na vida, então vamos imaginar que temos 2, 30, 50 ou mais signos. Vamos adicionar a isso milhares, ou mesmo dezenas de milhares de valores para cada atributo. Neste caso, a solução analítica pode não resistir ao teste e falhar. Por sua vez, a descida do gradiente e suas variações nos aproximarão lenta mas seguramente do objetivo - o mínimo da função. E não se preocupe com a velocidade - provavelmente veremos maneiras que nos permitirão definir e regular o comprimento do passo (ou seja, a velocidade).
E agora o breve resumo real.
Em primeiro lugar, espero que o material apresentado no artigo ajude os “cientistas de dados” iniciantes a entender como resolver equações de regressão linear simples (e não apenas).
Em segundo lugar, examinamos várias maneiras de resolver a equação. Agora, dependendo da situação, podemos escolher aquele que melhor se adapta para resolver o problema.
Terceiro, vimos o poder das configurações adicionais, ou seja, o comprimento do passo de descida gradiente. Este parâmetro não pode ser negligenciado. Conforme observado acima, para reduzir o custo dos cálculos, o comprimento do passo deve ser alterado durante a descida.
Em quarto lugar, no nosso caso, as funções “escritas em casa” mostraram os melhores resultados de tempo para cálculos. Isto provavelmente se deve ao uso não muito profissional dos recursos da biblioteca NumPy. Mas seja como for, a seguinte conclusão surge. Por um lado, às vezes vale a pena questionar opiniões estabelecidas e, por outro lado, nem sempre vale a pena complicar tudo - pelo contrário, às vezes uma forma mais simples de resolver um problema é mais eficaz. E como nosso objetivo era analisar três abordagens para resolver uma equação de regressão linear simples, o uso de funções “auto-escritas” foi suficiente para nós.
Literatura (ou algo parecido)
1. Regressão linear
2. Método dos mínimos quadrados
3. Derivada
4. Gradiente
5. Descida gradiente
6. Biblioteca NumPy
Fonte: habr.com
