


Dacă administrați o infrastructură virtuală bazată pe VMware vSphere (sau orice altă stivă de tehnologie), probabil că auziți adesea plângeri de la utilizatori: „Mașina virtuală este lentă!” În această serie de articole voi analiza valorile de performanță și vă voi spune ce și de ce încetinește și cum să mă asigur că nu încetinește.
Voi lua în considerare următoarele aspecte ale performanței mașinii virtuale:
- CPU,
- BERBEC,
- DISC,
- Reţea.
Voi începe cu procesorul.
Pentru a analiza performanța vom avea nevoie de:
- Contoare de performanță vCenter – contoare de performanță, ale căror grafice pot fi vizualizate prin vSphere Client. Informațiile despre aceste contoare sunt disponibile în orice versiune a clientului (client „gros” în C#, client web în Flex și client web în HTML5). În aceste articole vom folosi capturi de ecran de la clientul C#, doar pentru că arată mai bine în miniatură :)
- ESXTOP – un utilitar care rulează din linia de comandă ESXi. Cu ajutorul acestuia, puteți obține valorile contoarelor de performanță în timp real sau puteți încărca aceste valori pentru o anumită perioadă într-un fișier .csv pentru analize ulterioare. În continuare, vă voi spune mai multe despre acest instrument și vă voi oferi mai multe link-uri utile către documentație și articole pe acest subiect.
Un pic de teorie
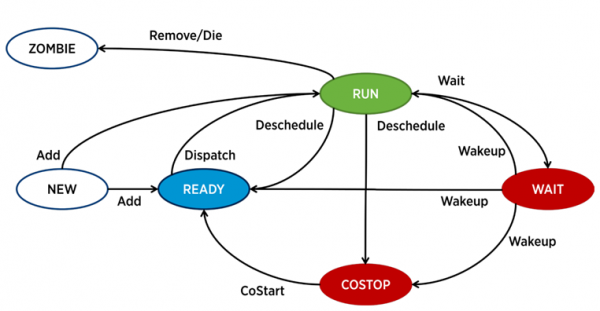
În ESXi, un proces separat – lumea în terminologia VMware – este responsabil pentru funcționarea fiecărui vCPU (nucleu de mașină virtuală). Există și procese de service, dar din punctul de vedere al analizei performanței VM sunt mai puțin interesante.
Un proces în ESXi poate fi în una dintre cele patru stări:
- Alerga – procesul efectuează unele lucrări utile.
- Așteaptă – procesul nu lucrează (inactiv) sau așteaptă intrare/ieșire.
- Costop – o condiție care apare în mașinile virtuale multi-core. Apare atunci când planificatorul CPU hypervisor (ESXi CPU Scheduler) nu poate programa execuția simultană a tuturor nucleelor de mașină virtuală active pe nucleele serverului fizic. În lumea fizică, toate nucleele procesorului funcționează în paralel, sistemul de operare invitat din interiorul VM se așteaptă la un comportament similar, astfel încât hipervizorul trebuie să încetinească nucleele VM care au capacitatea de a-și termina ciclul de ceas mai repede. În versiunile moderne ale ESXi, programatorul CPU utilizează un mecanism numit co-programare relaxată: hypervisorul ia în considerare decalajul dintre cel mai „rapid” și cel mai „lent” nucleu al mașinii virtuale (înclinat). Dacă decalajul depășește un anumit prag, miezul rapid intră în starea costop. Dacă nucleele VM petrec mult timp în această stare, poate cauza probleme de performanță.
- Gata – procesul intră în această stare când hypervisorul nu este în măsură să aloce resurse pentru execuția sa. Valorile ridicate de pregătire pot cauza probleme de performanță a VM.
Contoare de performanță CPU de bază ale mașinii virtuale
Utilizare CPU, %. Afișează procentul de utilizare a procesorului pentru o anumită perioadă.
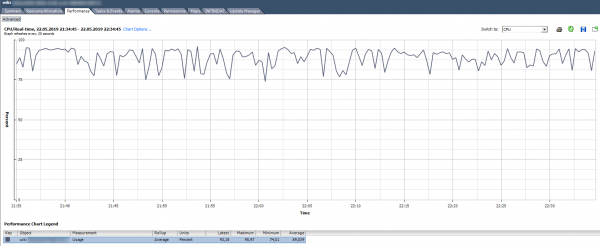
Cum să analizăm? Dacă o VM folosește constant CPU la 90% sau există vârfuri de până la 100%, atunci avem probleme. Problemele pot fi exprimate nu numai în funcționarea „lentă” a aplicației în interiorul VM, ci și în inaccesibilitatea VM-ului în rețea. Dacă sistemul de monitorizare arată că VM-ul cade periodic, acordați atenție vârfurilor din graficul de utilizare a CPU.
Există o alarmă standard care arată încărcarea CPU a mașinii virtuale:

Ce să fac? Dacă utilizarea procesorului unui VM trece în mod constant prin acoperiș, atunci vă puteți gândi la creșterea numărului de vCPU-uri (din păcate, acest lucru nu ajută întotdeauna) sau la mutarea VM-ului pe un server cu procesoare mai puternice.
Utilizarea CPU în MHz
În graficele de pe vCenter Utilizare în % puteți vedea doar pentru întreaga mașină virtuală; nu există grafice pentru nuclee individuale (în Esxtop există valori % pentru nuclee). Pentru fiecare nucleu puteți vedea Utilizare în MHz.
Cum să analizăm? Se întâmplă ca o aplicație să nu fie optimizată pentru o arhitectură multi-core: folosește doar un nucleu 100%, iar restul sunt inactiv fără încărcare. De exemplu, cu setările implicite de backup, MS SQL începe procesul doar pe un singur nucleu. Drept urmare, backup-ul încetinește nu din cauza vitezei lente a discurilor (de asta s-a plâns inițial utilizatorul), ci pentru că procesorul nu poate face față. Problema a fost rezolvată prin modificarea parametrilor: backup-ul a început să ruleze în paralel în mai multe fișiere (respectiv, în mai multe procese).
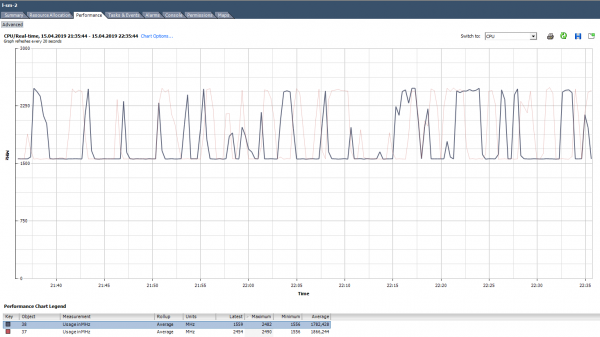
Un exemplu de sarcină neuniformă pe miezuri.
Există, de asemenea, o situație (ca în graficul de mai sus) când miezurile sunt încărcate neuniform și unele dintre ele au vârfuri de 100%. Ca și în cazul încărcării unui singur nucleu, alarma pentru Utilizarea CPU nu va funcționa (este pentru întregul VM), dar vor exista probleme de performanță.
Ce să fac? Dacă software-ul dintr-o mașină virtuală încarcă nucleele inegal (folosește doar un nucleu sau o parte din nuclee), nu are rost să le creștem numărul. În acest caz, este mai bine să mutați VM-ul pe un server cu procesoare mai puternice.
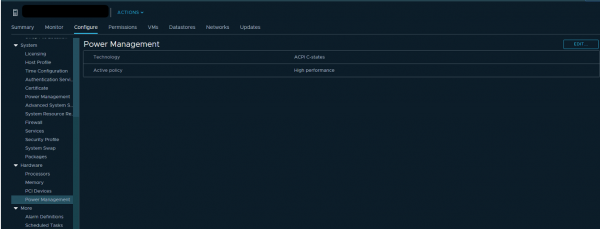
De asemenea, puteți încerca să verificați setările de consum de energie din BIOS-ul serverului. Mulți administratori activează modul de înaltă performanță în BIOS și, prin urmare, dezactivează tehnologiile de economisire a energiei C-states și P-states. Procesoarele Intel moderne folosesc tehnologia Turbo Boost, care crește frecvența nucleelor de procesor individuale în detrimentul altor nuclee. Dar funcționează numai atunci când tehnologiile de economisire a energiei sunt activate. Dacă le dezactivăm, procesorul nu poate reduce consumul de energie al nucleelor care nu sunt încărcate.
VMware recomandă să nu dezactivați tehnologiile de economisire a energiei de pe servere, ci să alegeți moduri care lasă gestionarea energiei pe seama hypervisorului cât mai mult posibil. În acest caz, în setările de consum de energie pentru hypervisor, trebuie să selectați Performanță ridicată.
Dacă aveți VM-uri individuale (sau nuclee VM) în infrastructură care necesită o frecvență crescută a procesorului, ajustarea corectă a consumului de energie le poate îmbunătăți semnificativ performanța.
Procesor gata
Dacă miezul VM (vCPU) este în starea Gata, nu efectuează o muncă utilă. Această condiție apare atunci când hypervisorul nu găsește un nucleu fizic liber căruia i se poate aloca procesul vCPU al mașinii virtuale.
Cum să analizăm? De obicei, dacă nucleele unei mașini virtuale sunt în starea Pregătit mai mult de 10% din timp, veți observa probleme de performanță. Mai simplu spus, mai mult de 10% din timp VM-ul așteaptă ca resursele fizice să devină disponibile.
În vCenter puteți vizualiza 2 contoare legate de CPU Ready:
- pregătire,
- Gata.
Valorile ambelor contoare pot fi vizualizate atât pentru întregul VM, cât și pentru nuclee individuale.
Pregătirea arată valoarea imediat ca procent, dar numai în timp real (date pentru ultima oră, interval de măsurare 20 de secunde). Este mai bine să utilizați acest contor numai pentru a căuta probleme „fierbinte pe călcâie”.
Valorile contorului gata pot fi vizualizate și din perspectivă istorică. Acest lucru este util pentru stabilirea tiparelor și pentru o analiză mai profundă a problemei. De exemplu, dacă o mașină virtuală începe să întâmpine probleme de performanță la un anumit moment, puteți compara intervalele valorii CPU Ready cu sarcina totală de pe serverul pe care rulează această VM și să luați măsuri pentru a reduce sarcina (dacă DRS eșuează).
Ready, spre deosebire de Readiness, este afișat nu în procente, ci în milisecunde. Acesta este un contor de tip Summation, adică arată cât timp în timpul perioadei de măsurare nucleul VM a fost în starea Ready. Puteți converti această valoare într-un procent folosind o formulă simplă:
(Valoarea de însumare a CPU gata / (intervalul de actualizare implicit al diagramei în secunde * 1000)) * 100 = CPU gata %
De exemplu, pentru VM din graficul de mai jos, valoarea maximă Ready pentru întreaga mașină virtuală va fi după cum urmează:

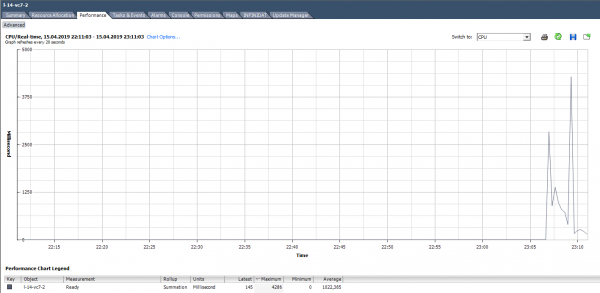
Când calculați procentul Ready, ar trebui să acordați atenție două puncte:
- Valoarea Ready pentru întreaga VM este suma Ready în nuclee.
- Interval de măsurare. Pentru timp real este de 20 de secunde și, de exemplu, pe graficele zilnice este de 300 de secunde.
Cu depanarea activă, aceste puncte simple pot fi ușor ratate și timp prețios poate fi pierdut pentru a rezolva probleme inexistente.
Să calculăm Ready pe baza datelor din graficul de mai jos. (324474/(20*1000))*100 = 1622% pentru întreaga VM. Dacă te uiți la nuclee, nu este atât de înfricoșător: 1622/64 = 25% pe miez. În acest caz, captura este destul de ușor de observat: valoarea Ready este nerealistă. Dar dacă vorbim de 10-20% pentru întregul VM cu mai multe nuclee, atunci pentru fiecare nucleu valoarea poate fi în intervalul normal.
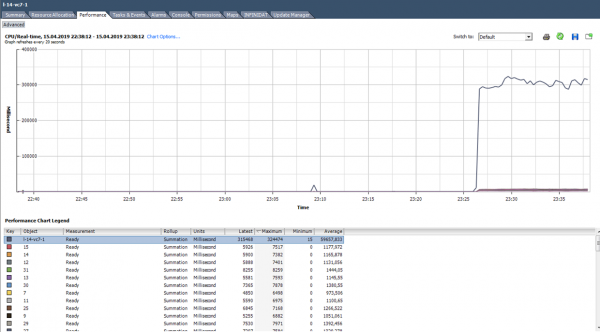
Ce să fac? O valoare ridicată Ready indică faptul că serverul nu are suficiente resurse de procesor pentru funcționarea normală a mașinilor virtuale. Într-o astfel de situație, tot ce rămâne este să reduceți supraabonamentul prin procesor (vCPU:pCPU). Evident, acest lucru poate fi realizat prin reducerea parametrilor mașinilor virtuale existente sau prin migrarea unei părți a mașinilor virtuale pe alte servere.
Co-oprire
Cum să analizăm? Acest contor este, de asemenea, de tipul Sumare și este convertit în procente în același mod ca Gata:
(Valoarea de însumare a co-stop CPU / (interval de actualizare implicit al diagramei în secunde * 1000)) * 100 = % co-stop CPU
Aici trebuie să acordați atenție și numărului de nuclee de pe VM și intervalului de măsurare.
În starea costop, nucleul nu efectuează lucrări utile. Odată cu selecția corectă a dimensiunii VM și a încărcării normale pe server, contorul de co-stop ar trebui să fie aproape de zero.
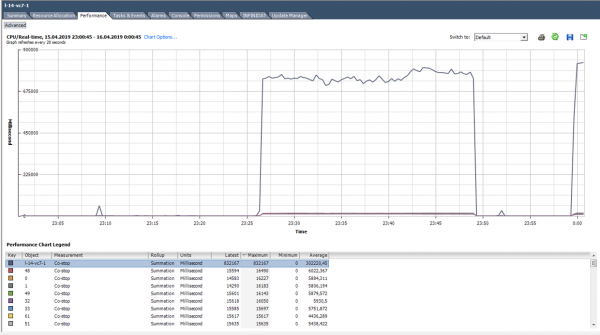
În acest caz, sarcina este clar anormală :)
Ce să fac? Dacă mai multe VM cu un număr mare de nuclee rulează pe un hypervisor și există o supraabonare pe CPU, atunci contorul de co-stop poate crește, ceea ce va duce la probleme cu performanța acestor VM.
De asemenea, co-stop va crește dacă nucleele active ale unei VM folosesc fire de execuție pe un nucleu de server fizic cu hyper-treading activat. Această situație poate apărea, de exemplu, dacă VM-ul are mai multe nuclee decât cele disponibile fizic pe serverul pe care rulează sau dacă setarea „preferHT” este activată pentru VM. Puteți citi despre această setare .
Pentru a evita problemele cu performanța VM din cauza co-stopului ridicat, selectați dimensiunea VM în conformitate cu recomandările producătorului software-ului care rulează pe această VM și capabilitățile serverului fizic pe care rulează VM.
Nu adăugați nuclee în rezervă; acest lucru poate cauza probleme de performanță nu numai pentru VM în sine, ci și pentru vecinii săi de pe server.
Alte valori utile pentru CPU
Alerga – cât timp (ms) în timpul perioadei de măsurare vCPU a fost în starea RUN, adică a efectuat de fapt o muncă utilă.
Idle – cât timp (ms) în timpul perioadei de măsurare vCPU a fost în stare de inactivitate. Valorile mari Idle nu sunt o problemă, vCPU-ul pur și simplu nu a avut „nimic de făcut”.
Așteaptă – cât timp (ms) în timpul perioadei de măsurare vCPU a fost în starea de așteptare. Deoarece IDLE este inclus în acest contor, valorile mari de așteptare nu indică nici o problemă. Dar dacă Wait IDLE este scăzut atunci când Wait este mare, înseamnă că VM-ul aștepta finalizarea operațiunilor I/O, iar acest lucru, la rândul său, poate indica o problemă cu performanța hard disk-ului sau a oricăror dispozitive virtuale ale VM.
Limitat maxim – cât timp (ms) în timpul perioadei de măsurare vCPU a fost în starea Ready din cauza limitei de resurse setate. Dacă performanța este inexplicabil de scăzută, atunci este util să verificați valoarea acestui contor și limita CPU în setările VM. VM-urile pot avea într-adevăr limite de care nu le cunoașteți. De exemplu, acest lucru se întâmplă atunci când o VM a fost clonată dintr-un șablon pe care a fost setată limita CPU.
Schimbați așteptați – cât timp în timpul perioadei de măsurare vCPU a așteptat o operație cu VMkernel Swap. Dacă valorile acestui contor sunt peste zero, atunci VM-ul are cu siguranță probleme de performanță. Despre SWAP vom vorbi mai multe în articolul despre contoarele RAM.
ESXTOP
Dacă contoarele de performanță din vCenter sunt bune pentru analiza datelor istorice, atunci analiza operațională a problemei este mai bine făcută în ESXTOP. Aici, toate valorile sunt prezentate într-o formă gata făcută (nu este nevoie să traduceți nimic), iar perioada minimă de măsurare este de 2 secunde.
Ecranul ESXTOP pentru CPU este apelat cu tasta „c” și arată astfel:

Pentru comoditate, puteți lăsa doar procesele mașinilor virtuale apăsând Shift-V.
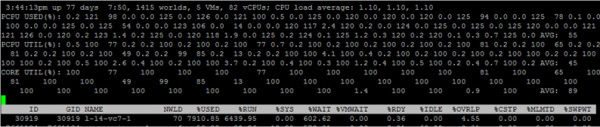
Pentru a vedea valorile pentru nucleele VM individuale, apăsați „e” și introduceți GID-ul VM-ului de interes (30919 în captura de ecran de mai jos):
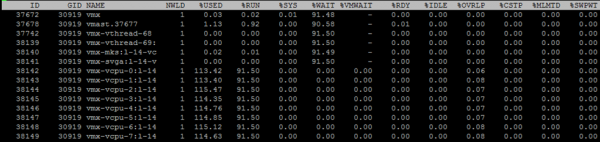
Permiteți-mi să trec pe scurt prin coloanele care sunt prezentate implicit. Coloane suplimentare pot fi adăugate apăsând „f”.
NWLD (număr de lumi) – numărul de procese din grup. Pentru a extinde grupul și a vedea valorile pentru fiecare proces (de exemplu, pentru fiecare nucleu dintr-o VM cu mai multe nuclee), apăsați „e”. Dacă există mai multe procese într-un grup, atunci valorile metricii pentru grup sunt egale cu suma valorilor pentru procesele individuale.
%FOLOSIT – câte cicluri CPU server sunt utilizate de un proces sau un grup de procese.
%ALERGA – cât timp în timpul perioadei de măsurare procesul a fost în starea RUN, adică a făcut o muncă utilă. Diferă de %USED prin faptul că nu ia în considerare hyper-threading, scalarea frecvenței și timpul petrecut pe sarcini de sistem (%SYS).
%SYS – timpul petrecut pe sarcini de sistem, de exemplu: procesarea întreruperii, I/O, operarea în rețea, etc. Valoarea poate fi mare dacă VM-ul are un I/O mare.
%OVRLP – cât timp a petrecut nucleul fizic pe care rulează procesul VM pentru sarcinile altor procese.
Aceste valori se referă între ele, după cum urmează:
%USED = %RUN + %SYS - %OVRLP.
De obicei, valoarea %USED este mai informativă.
%AȘTEPTA – cât timp în timpul perioadei de măsurare procesul a fost în starea de așteptare. Activează IDLE.
%INACTIV – cât timp în timpul perioadei de măsurare procesul a fost în starea IDLE.
%SWPWT – cât timp în timpul perioadei de măsurare vCPU a așteptat o operație cu VMkernel Swap.
%VMWAIT – cât timp în timpul perioadei de măsurare vCPU a fost în starea de așteptare a unui eveniment (de obicei I/O). Nu există un contor similar în vCenter. Valorile ridicate indică probleme cu I/O pe VM.
%WAIT = %VMWAIT + %IDLE + %SWPWT.
Dacă VM-ul nu folosește VMkernel Swap, atunci când se analizează problemele de performanță este recomandabil să se uite la %VMWAIT, deoarece această măsurătoare nu ia în considerare timpul în care VM-ul nu făcea nimic (%IDLE).
%RDY – cât timp în timpul perioadei de măsurare procesul a fost în starea Ready.
%CSTP – cât timp în perioada de măsurare procesul a fost în starea costop.
%MLMTD – cât timp în timpul perioadei de măsurare vCPU a fost în starea Ready din cauza limitei de resurse setate.
%WAIT + %RDY + %CSTP + %RUN = 100% – nucleul VM este întotdeauna în una dintre aceste patru stări.
CPU pe hypervisor
vCenter are, de asemenea, contoare de performanță CPU pentru hypervisor, dar nu sunt nimic interesant - sunt pur și simplu suma contoarelor pentru toate VM-urile de pe server.
Cel mai convenabil mod de a vizualiza starea CPU pe server este în fila Rezumat:

Pentru server, precum și pentru mașina virtuală, există o alarmă standard:
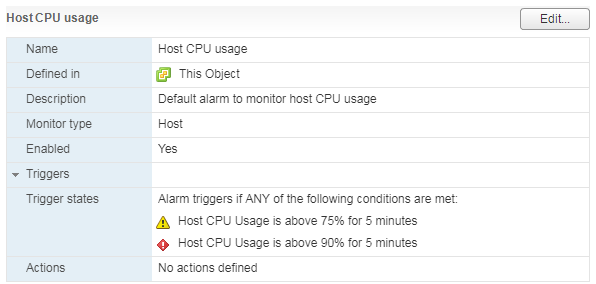
Când încărcarea procesorului serverului este mare, VM-urile care rulează pe acesta încep să întâmpine probleme de performanță.
În ESXTOP, datele de încărcare a procesorului serverului sunt prezentate în partea de sus a ecranului. În plus față de încărcarea standard a procesorului, care nu este foarte informativă pentru hipervizori, există încă trei metrici:
CORE UTIL(%) – încărcarea nucleului serverului fizic. Acest contor arată cât timp a lucrat miezul în timpul perioadei de măsurare.
PCPU UTIL(%) – dacă hyper-threading este activat, atunci există două fire de execuție (PCPU) per nucleu fizic. Această măsurătoare arată cât timp a durat fiecare fir pentru a finaliza munca.
PCPU UTILIZAT(%) – la fel ca PCPU UTIL(%), dar ia în considerare scalarea frecvenței (fie reducerea frecvenței de bază în scopuri de economisire a energiei, fie creșterea frecvenței de bază datorită tehnologiei Turbo Boost) și hyper-threading.
PCPU_USED% = PCPU_UTIL% * frecvența de bază efectivă / frecvența de bază nominală.
În această captură de ecran, pentru unele nuclee, datorită Turbo Boost, valoarea USED este mai mare de 100%, deoarece frecvența nucleului este mai mare decât cea nominală.
Câteva cuvinte despre cum se ține cont de hiper-threading. Dacă procesele sunt executate 100% din timp pe ambele fire ale nucleului fizic al serverului, în timp ce nucleul funcționează la frecvența nominală, atunci:
- CORE UTIL pentru nucleu va fi 100%,
- PCPU UTIL pentru ambele fire va fi 100%,
- PCPU UTILIZAT pentru ambele fire va fi de 50%.
Dacă ambele fire nu au funcționat 100% din timp în perioada de măsurare, atunci în acele perioade în care firele au funcționat în paralel, PCPU-ul UTILIZAT pentru nuclee este împărțit la jumătate.
ESXTOP are, de asemenea, un ecran cu parametrii de consum de energie al procesorului serverului. Aici puteți vedea dacă serverul folosește tehnologii de economisire a energiei: stări C și stări P. Apelat cu tasta „p”:

Probleme comune de performanță a procesorului
În cele din urmă, voi trece peste cauzele tipice ale problemelor cu performanța procesorului VM și voi oferi scurte sfaturi pentru rezolvarea acestora:
Viteza ceasului de bază nu este suficientă. Dacă nu este posibil să vă actualizați VM-ul la nuclee mai puternice, puteți încerca să modificați setările de putere pentru a face Turbo Boost să funcționeze mai eficient.
Dimensiune incorectă a VM (prea multe/puține nuclee). Dacă instalați câteva nuclee, va exista o sarcină mare a CPU pe VM. Dacă sunt multe, prindeți un co-stop mare.
Supraabonament mare de CPU pe server. Dacă VM-ul are un Ready ridicat, reduceți supraabonamentul CPU.
Topologie NUMA incorectă pe VM-uri mari. Topologia NUMA văzută de VM (vNUMA) trebuie să se potrivească cu topologia NUMA a serverului (pNUMA). Diagnosticele și posibilele soluții la această problemă sunt scrise, de exemplu, în carte . Dacă nu doriți să aprofundați și nu aveți restricții de licențiere pentru sistemul de operare instalat pe VM, creați multe socket-uri virtuale pe VM, câte un nucleu la un moment dat. nu vei pierde mare lucru :)
Asta e tot pentru mine despre procesor. Întreabă întrebări. În partea următoare voi vorbi despre RAM.
Link-uri utile
Sursa: www.habr.com
