

Dragă comunitate, Acest articol se va concentra pe stocarea și preluarea eficientă a sute de milioane de fișiere mici. În această etapă, soluția finală este propusă pentru sistemele de fișiere compatibile cu POSIX, cu suport complet pentru încuietori, inclusiv încuietori cluster, și aparent chiar fără cârje.
Așa că am scris propriul meu server personalizat în acest scop.
În timpul implementării acestei sarcini, am reușit să rezolvăm problema principală și, în același timp, să realizăm economii de spațiu pe disc și RAM, pe care sistemul nostru de fișiere în cluster le consuma fără milă. De fapt, un astfel de număr de fișiere este dăunător pentru orice sistem de fișiere în cluster.
Ideea este următoarea:
Cu cuvinte simple, fișierele mici sunt încărcate prin server, sunt salvate direct în arhivă și, de asemenea, citite din aceasta, iar fișierele mari sunt plasate unul lângă altul. Schema: 1 folder = 1 arhiva, in total avem cateva milioane de arhive cu fisiere mici, si nu cateva sute de milioane de fisiere. Și toate acestea sunt implementate complet, fără scripturi sau introducerea fișierelor în arhive tar/zip.
Voi încerca să fiu scurt, îmi cer scuze anticipat dacă postarea este lungă.
Totul a început cu faptul că nu am putut găsi un server potrivit în lume care să poată salva datele primite prin protocolul HTTP direct în arhive, fără dezavantajele inerente arhivelor convenționale și stocării obiectelor. Iar motivul căutării a fost clusterul Origin de 10 servere care crescuseră la scară mare, în care se acumulaseră deja 250,000,000 de fișiere mici, iar tendința de creștere nu avea să se oprească.
Pentru cei cărora nu le place să citească articole, puțină documentare este mai ușoară:
и .
Și docker în același timp, acum există o opțiune numai cu nginx în interior pentru orice eventualitate:
docker run -d --restart=always -e host=localhost -e root=/var/storage
-v /var/storage:/var/storage --name wzd -p 80:80 eltaline/wzdUrmător:
Dacă există o mulțime de fișiere, sunt necesare resurse semnificative, iar partea cea mai gravă este că unele dintre ele sunt irosite. De exemplu, atunci când utilizați un sistem de fișiere în cluster (în acest caz, MooseFS), fișierul, indiferent de dimensiunea reală, ocupă întotdeauna cel puțin 64 KB. Adică, pentru fișierele de 3, 10 sau 30 KB, sunt necesari 64 KB pe disc. Dacă există un sfert de miliard de fișiere, pierdem de la 2 la 10 terabytes. Nu va fi posibil să se creeze fișiere noi la infinit, deoarece MooseFS are o limitare: nu mai mult de 1 miliard cu o copie a fiecărui fișier.
Pe măsură ce numărul de fișiere crește, este nevoie de multă memorie RAM pentru metadate. Descărcările frecvente de metadate mari contribuie, de asemenea, la uzura unităților SSD.
serverul wZD. Punem lucrurile în ordine pe discuri.
Serverul este scris în Go. În primul rând, trebuia să reduc numărul de fișiere. Cum să o facă? Datorită arhivării, dar în acest caz fără compresie, deoarece fișierele mele sunt doar imagini comprimate. BoltDB a venit în ajutor, care încă trebuia eliminat din deficiențele sale, acest lucru se reflectă în documentație.
În total, în loc de un sfert de miliard de dosare, în cazul meu au rămas doar 10 milioane de arhive Bolt. Dacă aș avea ocazia să schimb structura actuală a fișierelor de director, ar fi posibil să o reduc la aproximativ 1 milion de fișiere.
Toate fișierele mici sunt împachetate în arhive Bolt, care primesc automat numele directoarelor în care se află, iar toate fișierele mari rămân lângă arhive; nu are rost să le împachetați, acest lucru este personalizabil. Cele mici sunt arhivate, cele mari sunt lăsate neschimbate. Serverul funcționează transparent cu ambele.
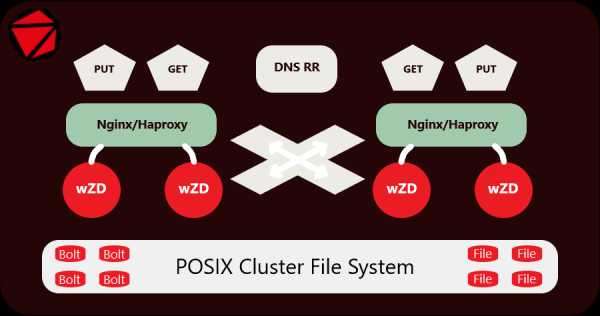
Arhitectura și caracteristicile serverului wZD.

Serverul funcționează sub controlul sistemelor de operare Linux, BSD, Solaris și OSX. Am testat doar arhitectura AMD64 sub Linux, dar ar trebui să funcționeze și pentru ARM64, PPC64, MIPS64.
Caracteristici principale:
- Multithreading;
- Multiserver, oferind toleranță la erori și echilibrare a sarcinii;
- Transparență maximă pentru utilizator sau dezvoltator;
- Metode HTTP acceptate: GET, HEAD, PUT și DELETE;
- Controlul comportamentului de citire și scriere prin anteturile clientului;
- Suport pentru gazde virtuale flexibile;
- Sprijină integritatea datelor CRC la scriere/citire;
- Buffere semi-dinamice pentru un consum minim de memorie și reglare optimă a performanței rețelei;
- Compactarea datelor amânată;
- În plus, un arhivator multi-thread wZA este oferit pentru migrarea fișierelor fără a opri serviciul.
Experiență reală:
Am dezvoltat și testat serverul și arhivatorul pe date live de destul de mult timp, acum funcționează cu succes pe un cluster care include 250,000,000 de fișiere mici (imagini) situate în 15,000,000 de directoare pe unități SATA separate. Un cluster de 10 servere este un server Origin instalat în spatele unei rețele CDN. Pentru a-l deservi, sunt folosite 2 servere Nginx + 2 servere wZD.
Pentru cei care decid să folosească acest server, ar fi înțelept să planifice structura directorului, dacă este cazul, înainte de utilizare. Permiteți-mi să fac o rezervare imediat că serverul nu are scopul de a înghesui totul într-o arhivă 1 Bolt.
Test de performanta:
Cu cât dimensiunea fișierului arhivat este mai mică, cu atât se efectuează operațiunile GET și PUT mai rapide pe acesta. Să comparăm timpul total pentru scrierea clientului HTTP în fișierele obișnuite și arhivele Bolt, precum și pentru citire. Se compară lucrul cu fișiere de dimensiuni de 32 KB, 256 KB, 1024 KB, 4096 KB și 32768 KB.
Când lucrați cu arhivele Bolt, se verifică integritatea datelor fiecărui fișier (se folosește CRC), înainte de înregistrare și, de asemenea, după înregistrare, are loc citirea și recalcularea din mers, acest lucru introduce în mod natural întârzieri, dar principalul lucru este securitatea datelor.
Am efectuat teste de performanță pe unități SSD, deoarece testele pe unități SATA nu arată o diferență clară.
Grafice bazate pe rezultatele testării:
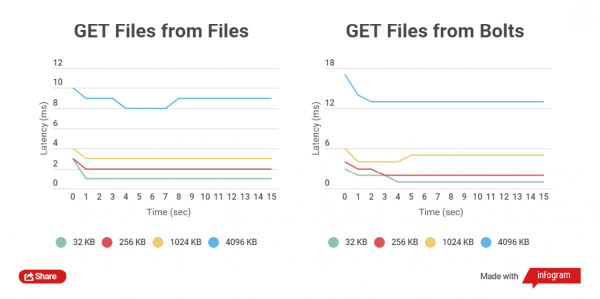
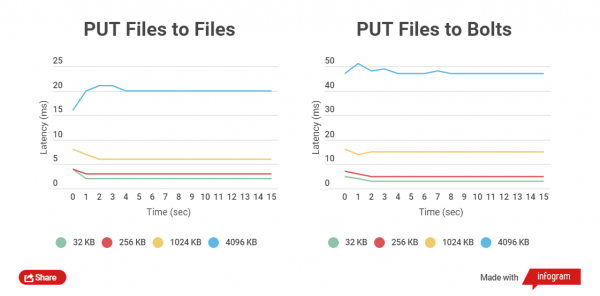
După cum puteți vedea, pentru fișierele mici, diferența de timp de citire și scriere între fișierele arhivate și cele nearhivate este mică.
Obținem o imagine complet diferită atunci când testăm citirea și scrierea fișierelor cu dimensiunea de 32 MB:
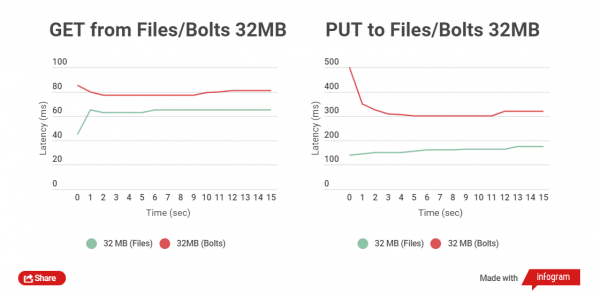
Diferența de timp dintre citirea fișierelor este de 5-25 ms. Cu înregistrarea, lucrurile stau mai rău, diferența este de aproximativ 150 ms. Dar în acest caz nu este nevoie să încărcați fișiere mari; pur și simplu nu are rost să faceți acest lucru; ele pot locui separat de arhive.
*Din punct de vedere tehnic, puteți utiliza acest server pentru sarcini care necesită NoSQL.
Metode de bază de lucru cu serverul wZD:
Încărcarea unui fișier obișnuit:
curl -X PUT --data-binary @test.jpg http://localhost/test/test.jpgÎncărcarea unui fișier în arhiva Bolt (dacă parametrul de server fmaxsize, care determină dimensiunea maximă a fișierului care poate fi inclus în arhivă, nu este depășită; dacă este depășit, fișierul va fi încărcat ca de obicei lângă arhivă):
curl -X PUT -H "Archive: 1" --data-binary @test.jpg http://localhost/test/test.jpgDescărcarea unui fișier (dacă există fișiere cu aceleași nume pe disc și în arhivă, atunci la descărcare, prioritate este dată în mod implicit fișierului dezarhivat):
curl -o test.jpg http://localhost/test/test.jpgDescărcarea unui fișier din arhiva Bolt (forțată):
curl -o test.jpg -H "FromArchive: 1" http://localhost/test/test.jpgDescrierile altor metode sunt în documentație.
Serverul acceptă în prezent doar protocolul HTTP; încă nu funcționează cu HTTPS. Nici metoda POST nu este acceptată (nu s-a decis încă dacă este necesară sau nu).
Cine sapă în codul sursă va găsi butterscotch acolo, nu le place tuturor, dar nu am legat codul principal de funcțiile cadrului web, cu excepția gestionarului de întreruperi, așa că în viitor îl pot rescrie rapid pentru aproape orice. motor.
ToDo:
- Dezvoltarea propriului replicator și distribuitor + geo pentru posibilitatea de utilizare în sisteme mari fără sisteme de fișiere cluster (Totul pentru adulți)
- Posibilitatea de recuperare completă inversă a metadatelor dacă acestea sunt pierdute complet (dacă utilizați un distribuitor)
- Protocol nativ pentru capacitatea de a utiliza conexiuni de rețea persistente și drivere pentru diferite limbaje de programare
- Posibilitati avansate de utilizare a componentei NoSQL
- Compresiuni de diferite tipuri (gzip, zstd, snappy) pentru fișiere sau valori din arhivele Bolt și pentru fișiere obișnuite
- Criptare de diferite tipuri pentru fișierele sau valorile din arhivele Bolt și pentru fișierele obișnuite
- Conversie video întârziată pe partea de server, inclusiv pe GPU
Am de toate, sper sa fie de folos cuiva acest server, licenta BSD-3, dublu drept de autor, intrucat daca nu ar fi fost firma unde lucrez, serverul nu ar fi fost scris. Sunt singurul dezvoltator. V-aș fi recunoscător pentru eventualele erori și solicitări de caracteristici pe care le găsiți.
Sursa: www.habr.com
