

Vă sugerez să citiți transcrierea prelegerii „Hadoop. ZooKeeper” din seria „Metode pentru procesarea distribuită a volumelor mari de date în Hadoop”
Ce este ZooKeeper, locul său în ecosistemul Hadoop. Neadevăruri despre calculul distribuit. Diagrama unui sistem distribuit standard. Dificultate în coordonarea sistemelor distribuite. Probleme tipice de coordonare. Principiile din spatele designului ZooKeeper. Model de date ZooKeeper. steaguri znode. Sesiuni. Client API. Primitive (configurare, apartenență la grup, încuietori simple, alegere lider, blocare fără efect de turmă). Arhitectura ZooKeeper. ZooKeeper DB. ZAB. Handler de cereri.


Astăzi vom vorbi despre ZooKeeper. Acest lucru este foarte util. Acesta, ca orice produs Apache Hadoop, are un logo. Înfățișează un bărbat.
Înainte de aceasta, am vorbit în principal despre modul în care datele pot fi procesate acolo, cum să le stocăm, adică cum să le folosim cumva și să lucram cu ele cumva. Și astăzi aș vrea să vorbesc puțin despre construirea de aplicații distribuite. Și ZooKeeper este unul dintre acele lucruri care vă permite să simplificați această chestiune. Acesta este un fel de serviciu care este destinat unui fel de coordonare a interacțiunii proceselor în sistemele distribuite, în aplicațiile distribuite.
Nevoia de astfel de aplicații devine din ce în ce mai mare pe zi ce trece, despre asta se referă cursul nostru. Pe de o parte, MapReduce și acest cadru gata făcut vă permit să nivelați această complexitate și să eliberați programatorul de la scrierea de primitive, cum ar fi interacțiunea și coordonarea proceselor. Dar, pe de altă parte, nimeni nu garantează că acest lucru nu va trebui făcut oricum. MapReduce sau alte cadre gata făcute nu înlocuiesc întotdeauna complet unele cazuri care nu pot fi implementate folosind aceasta. Inclusiv MapReduce în sine și o grămadă de alte proiecte Apache; acestea, de fapt, sunt, de asemenea, aplicații distribuite. Și pentru a face scrisul mai ușor, au scris ZooKeeper.
Ca toate aplicațiile legate de Hadoop, a fost dezvoltat de Yahoo! Acum este și o aplicație oficială Apache. Nu este la fel de activ dezvoltat ca HBase. Dacă mergi la JIRA HBase, atunci în fiecare zi există o grămadă de rapoarte de erori, o grămadă de propuneri pentru a optimiza ceva, adică viața în proiect se desfășoară în mod constant. Și ZooKeeper, pe de o parte, este un produs relativ simplu, iar pe de altă parte, acest lucru îi asigură fiabilitatea. Și este destul de ușor de utilizat, motiv pentru care a devenit un standard în aplicațiile din ecosistemul Hadoop. Așa că m-am gândit că ar fi util să-l revizuiesc pentru a înțelege cum funcționează și cum să-l folosească.
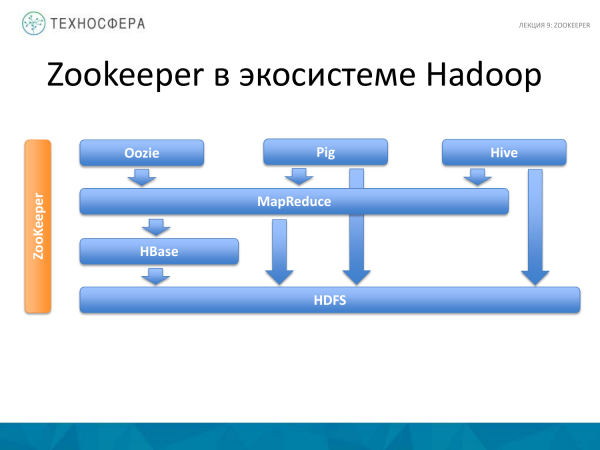
Aceasta este o poză dintr-o prelegere pe care am avut-o. Putem spune că este ortogonal la tot ceea ce am considerat până acum. Și tot ceea ce este indicat aici, într-o măsură sau alta, funcționează cu ZooKeeper, adică este un serviciu care folosește toate aceste produse. Nici HDFS, nici MapReduce nu își scriu propriile servicii similare care ar funcționa în mod special pentru ei. În consecință, se folosește ZooKeeper. Și acest lucru simplifică dezvoltarea și unele lucruri legate de erori.

De unde vin toate astea? S-ar părea că am lansat două aplicații în paralel pe computere diferite, le-am conectat cu un șir sau într-o plasă și totul funcționează. Dar problema este că rețeaua nu este de încredere și, dacă ai observat traficul sau te-ai uitat la ce se întâmplă acolo la un nivel scăzut, cum interacționează clienții în rețea, poți vedea adesea că unele pachete sunt pierdute sau retrimise. Nu degeaba au fost inventate protocoalele TCP, care vă permit să stabiliți o anumită sesiune și să garantați livrarea mesajelor. Dar, în orice caz, nici măcar TCP nu te poate salva întotdeauna. Totul are un timeout. Rețeaua poate cădea pur și simplu pentru o perioadă. S-ar putea să clipească. Și toate acestea duc la faptul că nu vă puteți baza pe rețeaua fiabilă. Aceasta este principala diferență față de scrierea de aplicații paralele care rulează pe un singur computer sau pe un supercomputer, unde nu există rețea, unde există o magistrală de schimb de date mai fiabilă în memorie. Și aceasta este o diferență fundamentală.
Printre altele, atunci când utilizați Rețeaua, există întotdeauna o anumită latență. De asemenea, discul îl are, dar Rețeaua are mai mult. Latența este un anumit timp de întârziere, care poate fi fie mic, fie destul de semnificativ.
Topologia rețelei se schimbă. Ce este topologia - aceasta este amplasarea echipamentului nostru de rețea. Sunt centre de date, sunt rafturi care stau acolo, sunt lumânări. Toate acestea pot fi reconectate, mutate etc. Toate acestea trebuie luate în considerare. Numele IP se schimbă, se schimbă rutarea prin care circulă traficul nostru. De asemenea, trebuie luat în considerare.
Rețeaua se poate schimba și în ceea ce privește echipamentul. Din practică, pot spune că inginerilor noștri de rețea le place foarte mult să actualizeze periodic ceva despre lumânări. Dintr-o dată a apărut un nou firmware și nu au fost deosebit de interesați de un cluster Hadoop. Au propria lor slujbă. Pentru ei, principalul lucru este că rețeaua funcționează. În consecință, vor să reîncarce ceva acolo, să facă o clipire pe hardware-ul lor, iar hardware-ul se schimbă periodic. Toate acestea trebuie oarecum luate în considerare. Toate acestea afectează aplicația noastră distribuită.
De obicei, oamenii care încep să lucreze cu cantități mari de date din anumite motive cred că Internetul este nelimitat. Dacă există un fișier de mai mulți teraocteți acolo, atunci îl puteți duce pe server sau computer și îl puteți deschide folosind pisică si priveste. O altă eroare este în sevă uita-te la busteni. Nu face niciodată asta pentru că este rău. Pentru că Vim încearcă să tamponeze totul, să încarce totul în memorie, mai ales când începem să ne mișcăm prin acest jurnal și să căutăm ceva. Acestea sunt lucruri care sunt uitate, dar care merită luate în considerare.

Este mai ușor să scrieți un program care rulează pe un computer cu un procesor.
Când sistemul nostru crește, dorim să paralelizăm totul și să îl paralelizăm nu numai pe un computer, ci și pe un cluster. Apare întrebarea: cum să coordonăm această problemă? Este posibil ca aplicațiile noastre să nu interacționeze între ele, dar am rulat mai multe procese în paralel pe mai multe servere. Și cum să monitorizezi că totul merge bine pentru ei? De exemplu, trimit ceva prin Internet. Ei trebuie să scrie despre starea lor undeva, de exemplu, într-un fel de bază de date sau jurnal, apoi agrega acest jurnal și apoi îl analizează undeva. În plus, trebuie să ținem cont de faptul că procesul a funcționat și a funcționat, dintr-o dată a apărut o eroare în el sau s-a prăbușit, apoi cât de repede vom afla despre asta?
Este clar că toate acestea pot fi monitorizate rapid. Acest lucru este, de asemenea, bun, dar monitorizarea este un lucru limitat care vă permite să monitorizați unele lucruri la cel mai înalt nivel.
Când dorim ca procesele noastre să înceapă să interacționeze între ele, de exemplu, să ne trimitem unele date, atunci apare și întrebarea - cum se va întâmpla acest lucru? Va exista un fel de condiție de cursă, se vor suprascrie reciproc, vor ajunge datele corect, se va pierde ceva pe parcurs? Trebuie să dezvoltăm un fel de protocol etc.
Coordonarea tuturor acestor procese nu este un lucru banal. Și îl obligă pe dezvoltator să coboare la un nivel și mai jos și să scrie sisteme fie de la zero, fie nu chiar de la zero, dar acest lucru nu este atât de simplu.
Dacă vii cu un algoritm criptografic sau chiar îl implementezi, atunci aruncă-l imediat, pentru că cel mai probabil nu va funcționa pentru tine. Cel mai probabil va conține o grămadă de erori pe care ați uitat să le furnizați. Nu-l utilizați niciodată pentru ceva grav, deoarece cel mai probabil va fi instabil. Pentru că toți algoritmii care există au fost testați de timp de foarte mult timp. Este deranjat de comunitate. Acesta este un subiect separat. Și aici este la fel. Dacă este posibil să nu implementați singuri un fel de sincronizare a procesului, atunci este mai bine să nu faceți acest lucru, deoarece este destul de complicat și vă conduce pe calea șubredă a căutării constante a erorilor.
Astăzi vorbim despre ZooKeeper. Pe de o parte, este un cadru, pe de altă parte, este un serviciu care ușurează viața dezvoltatorului și simplifică cât mai mult implementarea logicii și coordonarea proceselor noastre.
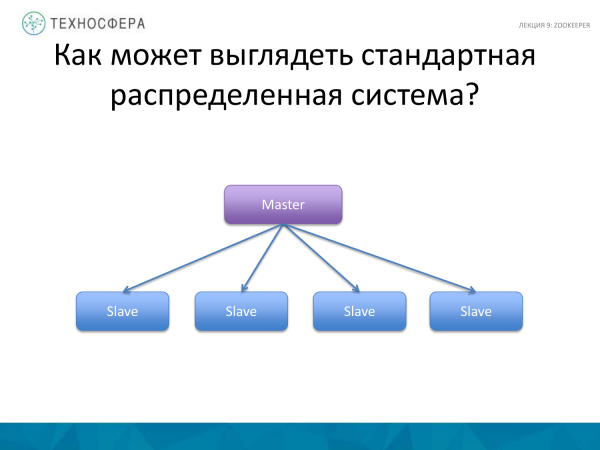
Să ne amintim cum ar putea arăta un sistem distribuit standard. Despre asta am vorbit - HDFS, HBase. Există un proces Master care gestionează procesele lucrătorilor și sclavi. El este responsabil pentru coordonarea și distribuirea sarcinilor, repornirea lucrătorilor, lansarea altora noi și distribuirea încărcăturii.
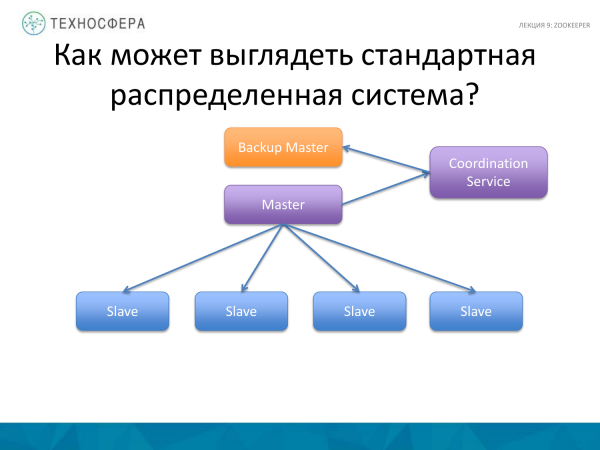
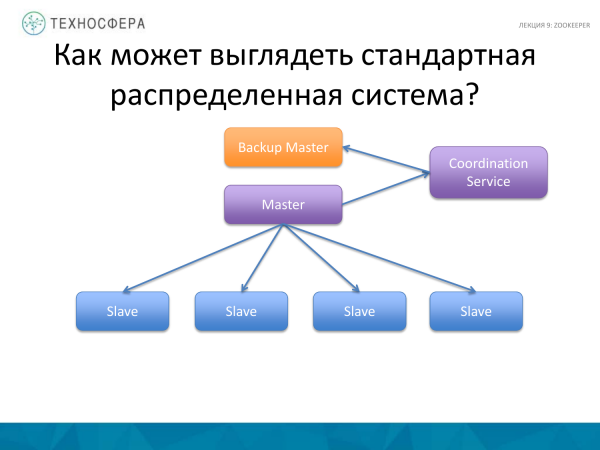
Un lucru mai avansat este Serviciul de coordonare, adică mutați însăși sarcina de coordonare într-un proces separat, plus rulați un fel de backup sau de rezervă în paralel, deoarece Master-ul poate eșua. Și dacă Maestrul cade, atunci sistemul nostru nu va funcționa. Executăm backup. Unele state spun că Masterul trebuie să fie replicat în backup. Aceasta poate fi încredințată și Serviciului de coordonare. Dar în această diagramă, Maestrul însuși este responsabil pentru coordonarea lucrătorilor; aici serviciul coordonează activitățile de replicare a datelor.
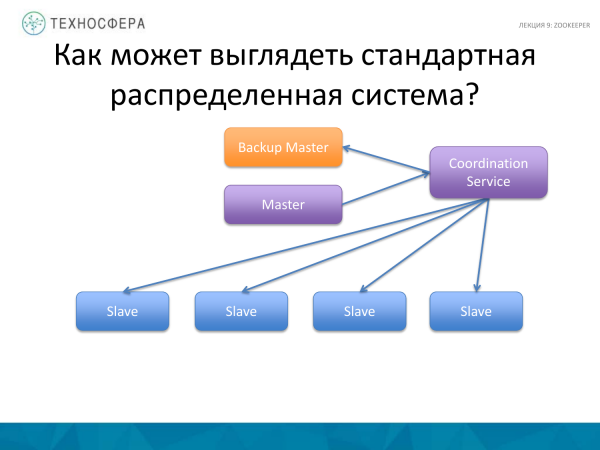
O opțiune mai avansată este atunci când toată coordonarea este gestionată de serviciul nostru, așa cum se face de obicei. El își asumă responsabilitatea pentru a se asigura că totul funcționează. Și dacă ceva nu funcționează, aflăm despre asta și încercăm să ocolim această situație. În orice caz, rămânem cu un Maestru care interacționează cumva cu sclavii și poate trimite date, informații, mesaje etc prin intermediul unor servicii.
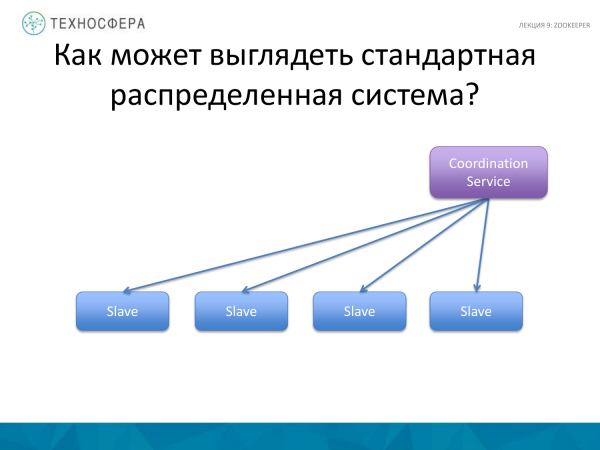
Există o schemă și mai avansată, atunci când nu avem un Master, toate nodurile sunt master slave, diferite în comportamentul lor. Dar ei încă trebuie să interacționeze între ei, așa că mai există ceva serviciu pentru a coordona aceste acțiuni. Probabil, Cassandra, care lucrează pe acest principiu, se potrivește acestei scheme.
Este dificil de spus care dintre aceste scheme funcționează mai bine. Fiecare are propriile sale avantaje și dezavantaje.
Și nu trebuie să-ți fie frică de unele lucruri cu Maestrul, pentru că, așa cum arată practica, el nu este atât de susceptibil de a sluji în mod constant. Principalul lucru aici este să alegeți soluția potrivită pentru găzduirea acestui serviciu pe un nod puternic separat, astfel încât să aibă suficiente resurse, astfel încât, dacă este posibil, utilizatorii să nu aibă acces acolo, astfel încât să nu distrugă accidental acest proces. Dar, în același timp, într-o astfel de schemă este mult mai ușor să gestionezi lucrătorii din procesul Master, adică această schemă este mai simplă din punct de vedere al implementării.
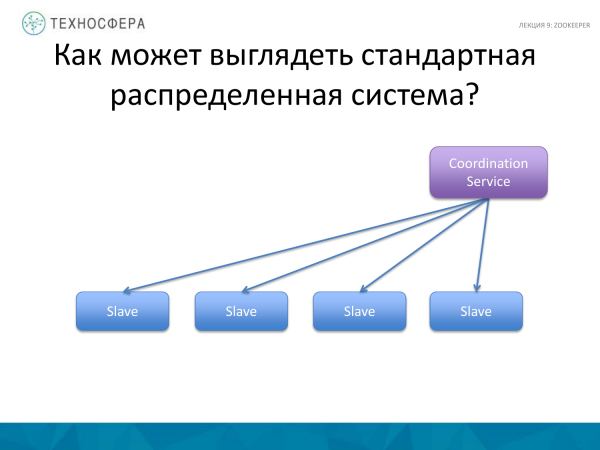
Și această schemă (mai sus) este probabil mai complexă, dar mai fiabilă.

Problema principală este eșecurile parțiale. De exemplu, atunci când trimitem un mesaj prin Rețea, are loc un fel de accident, iar cel care a trimis mesajul nu va ști dacă mesajul său a fost primit și ce s-a întâmplat de partea receptorului, nu va ști dacă mesajul a fost procesat corect , adică nu va primi nicio confirmare.
În consecință, trebuie să procesăm această situație. Și cel mai simplu lucru este să retrimitem acest mesaj și să așteptăm până când primim un răspuns. În acest caz, nu se ia în considerare dacă starea receptorului s-a schimbat. Este posibil să trimitem un mesaj și să adăugăm aceleași date de două ori.
ZooKeeper oferă modalități de a face față unor astfel de refuzuri, ceea ce ne face și viața mai ușoară.

După cum am menționat puțin mai devreme, acest lucru este similar cu scrierea de programe cu mai multe fire, dar principala diferență este că în aplicațiile distribuite pe care le construim pe diferite mașini, singura modalitate de a comunica este rețeaua. În esență, aceasta este o arhitectură de nimic comun. Fiecare proces sau serviciu care rulează pe o singură mașină are propria memorie, propriul disc, propriul procesor, pe care nu le împărtășește cu nimeni.
Dacă scriem un program cu mai multe fire pe un computer, atunci putem folosi memoria partajată pentru a face schimb de date. Avem o schimbare de context acolo, procesele se pot schimba. Acest lucru afectează performanța. Pe de o parte, nu există așa ceva în programul de pe un cluster, dar există probleme cu Rețeaua.

În consecință, principalele probleme care apar la scrierea sistemelor distribuite sunt configurația. Scriem un fel de aplicație. Dacă este simplu, atunci codificăm tot felul de numere în cod, dar acest lucru este incomod, deoarece dacă decidem că în loc de un timeout de jumătate de secundă vrem un timeout de o secundă, atunci trebuie să recompilăm aplicația și derulează totul din nou. Este un lucru când este pe o singură mașină, când îl poți reporni, dar când avem multe mașini, trebuie să copiem constant totul. Trebuie să încercăm să facem aplicația configurabilă.
Aici vorbim despre configurația statică pentru procesele de sistem. Aceasta nu este în totalitate, poate din punct de vedere al sistemului de operare, poate fi o configurație statică pentru procesele noastre, adică aceasta este o configurație care nu poate fi pur și simplu preluată și actualizată.
Există și o configurație dinamică. Aceștia sunt parametrii pe care vrem să îi modificăm din mers, astfel încât să fie preluați acolo.
Care este problema aici? Am actualizat configurația, am lansat-o, deci ce? Problema poate fi că, pe de o parte, am lansat configurația, dar am uitat de lucrul nou, configurația a rămas acolo. În al doilea rând, în timp ce lansam, configurația a fost actualizată în unele locuri, dar nu în altele. Și unele procese ale aplicației noastre care rulează pe o singură mașină au fost repornite cu o nouă configurație și undeva cu una veche. Acest lucru poate duce la incompatibilitatea aplicației noastre distribuite din perspectiva configurării. Această problemă este comună. Pentru o configurație dinamică, este mai relevant pentru că implică faptul că poate fi schimbat din mers.
O altă problemă este apartenența la grup. Avem întotdeauna un set de muncitori, vrem mereu să știm care dintre ei este în viață, care dintre ei este mort. Dacă există un Maestru, atunci el trebuie să înțeleagă care lucrători pot fi redirecționați către clienți, astfel încât aceștia să execute calcule sau să lucreze cu date și care nu. O problemă care apare constant este că trebuie să știm cine lucrează în clusterul nostru.
O altă problemă tipică sunt alegerile pentru lideri, când vrem să știm cine este la conducere. Un exemplu este replicarea, când avem un proces care primește operațiuni de scriere și apoi le reproduce printre alte procese. El va fi lider, toți ceilalți îl vor asculta, îl vor urma. Este necesar să alegeți un proces astfel încât să fie clar pentru toată lumea, astfel încât să nu se dovedească că doi lideri sunt selectați.
Există, de asemenea, acces care se exclud reciproc. Problema aici este mai complexă. Există un astfel de lucru ca un mutex, atunci când scrieți programe cu mai multe fire și doriți ca accesul la o resursă, de exemplu, o celulă de memorie, să fie limitat și efectuat de un singur fir. Aici resursa ar putea fi ceva mai abstract. Și diferite aplicații de la diferite noduri ale rețelei noastre ar trebui să primească doar acces exclusiv la o anumită resursă, și nu pentru ca toată lumea să o poată schimba sau să scrie ceva acolo. Acestea sunt așa-numitele încuietori.
ZooKeeper vă permite să rezolvați toate aceste probleme într-o măsură sau alta. Și voi arăta cu exemple cum vă permite să faceți acest lucru.

Nu există primitive de blocare. Când începem să folosim ceva, această primitivă nu va aștepta să apară vreun eveniment. Cel mai probabil, acest lucru va funcționa asincron, permițând astfel proceselor să nu se blocheze în timp ce așteaptă ceva. Acesta este un lucru foarte util.
Toate cererile clientului sunt procesate în ordinea cozii generale.
Și clienții au posibilitatea de a primi notificări despre schimbările într-o anumită stare, despre modificările datelor, înainte ca clientul să vadă el însuși datele modificate.

ZooKeeper poate funcționa în două moduri. Primul este autonom, pe un singur nod. Acest lucru este convenabil pentru testare. De asemenea, poate funcționa în modul cluster, pe orice număr de noduri. servereDacă avem un cluster cu 100 de mașini, nu trebuie neapărat să ruleze pe 100 de mașini. Este suficient să alocăm câteva mașini unde ZooKeeper poate rula. Și respectă principiul disponibilității ridicate. ZooKeeper stochează o copie completă a datelor pe fiecare instanță care rulează. Voi explica cum face acest lucru mai târziu. Nu fragmentează sau partiționează datele. Pe de o parte, acesta este un dezavantaj, deoarece nu putem stoca prea multe, dar, pe de altă parte, este inutil. Nu este conceput pentru asta; nu este o bază de date.
Datele pot fi stocate în cache pe partea clientului. Acesta este un principiu standard, astfel încât să nu întrerupem serviciul și să nu îl încărcăm cu aceleași solicitări. Un client inteligent știe de obicei despre acest lucru și îl memorează în cache.
De exemplu, ceva s-a schimbat aici. Există un fel de aplicație. A fost ales un nou lider, care este responsabil, de exemplu, de procesarea operațiunilor de scriere. Și vrem să replicăm datele. O soluție este să o puneți într-o buclă. Și ne punem la îndoială constant serviciul - s-a schimbat ceva? A doua opțiune este mai optimă. Acesta este un mecanism de ceas care vă permite să notificați clienții că ceva s-a schimbat. Aceasta este o metodă mai puțin costisitoare din punct de vedere al resurselor și mai convenabilă pentru clienți.

Clientul este utilizatorul care folosește ZooKeeper.
Serverul este procesul ZooKeeper în sine.
Znode este cheia în ZooKeeper. Toate znodele sunt stocate în memorie de către ZooKeeper și sunt organizate sub forma unei diagrame ierarhice, sub forma unui arbore.
Există două tipuri de operații. Prima este actualizarea/scrierea, când o operațiune schimbă starea arborelui nostru. Arborele este comun.
Și este posibil ca clientul să nu finalizeze o cerere și să fie deconectat, dar să poată stabili o sesiune prin care interacționează cu ZooKeeper.

Modelul de date al ZooKeeper seamănă cu un sistem de fișiere. Există o rădăcină standard și apoi am trecut parcă prin directoarele care merg de la rădăcină. Și apoi catalogul de la primul nivel, al doilea nivel. Toate acestea sunt znodes.
Fiecare znode poate stoca unele date, de obicei nu foarte mari, de exemplu, 10 kilobytes. Și fiecare znode poate avea un anumit număr de copii.

Znodes vin în mai multe tipuri. Ele pot fi create. Și când creăm un znode, specificăm tipul căruia ar trebui să aparțină.
Există două tipuri. Primul este steagul efemer. Znode trăiește într-o sesiune. De exemplu, clientul a stabilit o sesiune. Și atâta timp cât această sesiune este vie, va exista. Acest lucru este necesar pentru a nu produce ceva inutil. Acest lucru este potrivit și pentru momentele în care este important pentru noi să stocăm date primitive într-o sesiune.
Al doilea tip este steag secvențial. Crește contorul în drum spre znode. De exemplu, am avut un director cu aplicația 1_5. Și când am creat primul nod, a primit p_1, al doilea - p_2. Și când apelăm această metodă de fiecare dată, trecem calea completă, indicând doar o parte a căii, iar acest număr este automat incrementat deoarece indicăm tipul de nod - secvenţial.
Znode obișnuit. Ea va trăi mereu și va avea numele pe care i-l spunem noi.

Un alt lucru util este steagul ceasului. Dacă îl instalăm, atunci clientul se poate abona la unele evenimente pentru un anumit nod. Vă voi arăta mai târziu cu un exemplu cum se face acest lucru. ZooKeeper însuși notifică clientul că datele de pe nod s-au schimbat. Cu toate acestea, notificările nu garantează că unele date noi au sosit. Pur și simplu spun că ceva s-a schimbat, așa că mai trebuie să comparați datele mai târziu cu apeluri separate.
Și așa cum am spus deja, ordinea datelor este determinată de kilobytes. Nu este nevoie să stocați acolo date text mari, deoarece nu este o bază de date, este un server de coordonare a acțiunilor.

Permiteți-mi să vă povestesc puțin despre sesiuni. Dacă avem mai multe servere, putem trece transparent de la un server la altul. Server, folosind ID-ul sesiunii. Acest lucru este destul de convenabil.
Fiecare sesiune are un fel de timeout. O sesiune este definită dacă clientul trimite ceva către server în timpul acelei sesiuni. Dacă nu a transmis nimic în timpul timeout-ului, sesiunea cade, sau clientul o poate închide singur.

Nu are atât de multe funcții, dar puteți face diferite lucruri cu acest API. Apelul pe care l-am văzut creează un znode și ia trei parametri. Aceasta este calea către znode și trebuie specificată în întregime de la rădăcină. Și, de asemenea, acestea sunt câteva date pe care vrem să le transferăm acolo. Și tipul de steag. Și după creare, întoarce calea către znode.
În al doilea rând, îl puteți șterge. Trucul aici este că al doilea parametru, pe lângă calea către znode, poate specifica versiunea. În consecință, acel znode va fi șters dacă versiunea sa pe care am transferat-o este echivalentă cu cea care există de fapt.
Dacă nu vrem să verificăm această versiune, atunci pur și simplu trecem argumentul „-1”.

În al treilea rând, verifică existența unui znode. Returnează true dacă nodul există, false în caz contrar.
Și apoi apare ceasul de semnalizare, care vă permite să monitorizați acest nod.
Puteți seta acest flag chiar și pe un nod inexistent și puteți primi o notificare când apare. Acest lucru poate fi de asemenea util.
Mai sunt câteva provocări Obțineți date. Este clar că putem primi date prin znode. Puteți folosi și ceasul steagului. În acest caz, nu se va instala dacă nu există un nod. Prin urmare, trebuie să înțelegeți că există și apoi să primiți date.

De asemenea este si SetData. Aici trecem versiunea. Și dacă transmitem asta mai departe, datele de pe nodul znode ale unei anumite versiuni vor fi actualizate.
De asemenea, puteți specifica „-1” pentru a exclude această verificare.
O altă metodă utilă este getChildren. De asemenea, putem obține o listă cu toate nodurile care îi aparțin. Putem monitoriza acest lucru setând supravegherea steagului.
Și metoda sincronizaţi permite ca toate modificările să fie trimise simultan, asigurându-se astfel că acestea sunt salvate și că toate datele au fost complet modificate.
Dacă tragem analogii cu programarea obișnuită, atunci când utilizați metode precum scrierea, care scrie ceva pe disc și după ce vă returnează un răspuns, nu există nicio garanție că ați scris datele pe disc. Și chiar și atunci când sistemul de operare este încrezător că totul a fost scris, există mecanisme în disc în care procesul trece prin straturi de buffere și numai după aceea datele sunt plasate pe disc.

În mare parte sunt folosite apeluri asincrone. Acest lucru permite clientului să lucreze în paralel cu diferite solicitări. Puteți utiliza abordarea sincronă, dar este mai puțin productivă.
Cele două operațiuni despre care am vorbit sunt update/write, care modifică datele. Acestea sunt create, setData, sync, delete. Și citire există, getData, getChildren.
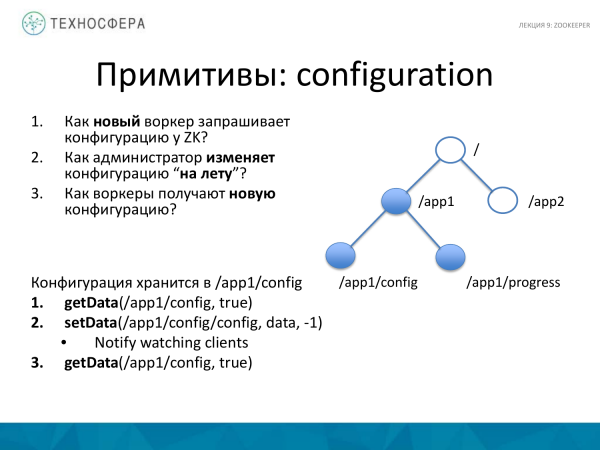
Acum câteva exemple despre cum puteți crea primitive pentru a lucra într-un sistem distribuit. De exemplu, legat de configurarea a ceva. A apărut un nou muncitor. Am adăugat mașina și am început procesul. Și există următoarele trei întrebări. Cum interogează ZooKeeper pentru configurare? Și dacă vrem să schimbăm configurația, cum o schimbăm? Și după ce l-am schimbat, cum îl obțin lucrătorii pe care îi aveam?
ZooKeeper face acest lucru relativ ușor. De exemplu, există arborele nostru znode. Există un nod pentru aplicația noastră aici, creăm un nod suplimentar în el, care conține date din configurație. Aceștia pot fi sau nu parametri separați. Deoarece dimensiunea este mică, dimensiunea configurației este de obicei mică, așa că este foarte posibil să o stocați aici.
Folosești metoda Obțineți date pentru a obține configurația pentru lucrător de la nod. Setați la adevărat. Dacă din anumite motive acest nod nu există, vom fi informați despre el când apare, sau când se schimbă. Dacă vrem să știm că ceva s-a schimbat, atunci îl setăm la adevărat. Și dacă datele din acest nod se schimbă, vom ști despre asta.
SetData. Setăm datele, setăm „-1”, adică nu verificăm versiunea, presupunem că avem întotdeauna o singură configurație, nu trebuie să stocăm multe configurații. Dacă trebuie să stocați mult, va trebui să adăugați un alt nivel. Aici credem că există doar unul, așa că o actualizăm doar pe cea mai recentă, așa că nu verificăm versiunea. În acest moment, toți clienții care s-au abonat anterior primesc o notificare că s-a schimbat ceva în acest nod. Și după ce l-au primit, trebuie să solicite din nou datele. Notificarea este că nu primesc datele în sine, ci doar notificarea modificărilor. După aceasta, trebuie să ceară date noi.
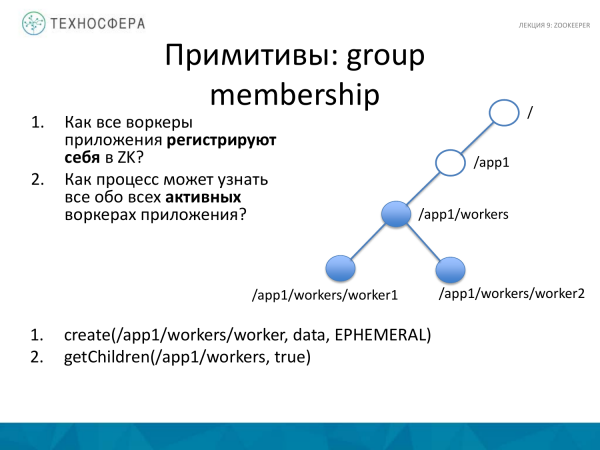
A doua opțiune pentru utilizarea primitivului este membru al grupului. Avem o aplicație distribuită, sunt o grămadă de muncitori și vrem să înțelegem că sunt toți la locul lor. Prin urmare, trebuie să se înregistreze că lucrează în aplicația noastră. Și vrem să aflăm, de asemenea, fie din procesul Master, fie în altă parte, despre toți lucrătorii activi pe care îi avem în prezent.
Cum facem asta? Pentru aplicație, creăm un nod lucrător și adăugăm acolo un subnivel folosind metoda create. Am o eroare pe slide. Aici ai nevoie secventiala specificați, atunci toți lucrătorii vor fi creați unul câte unul. Iar aplicația, solicitând toate datele despre copiii acestui nod, primește toți lucrătorii activi care există.
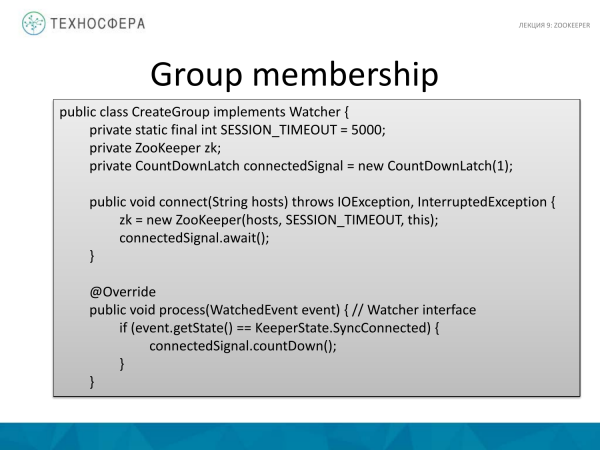

Aceasta este o implementare atât de groaznică a modului în care se poate face acest lucru în codul Java. Să începem de la final, cu metoda principală. Aceasta este clasa noastră, să-i creăm metoda. Ca prim argument folosim host, unde ne conectăm, adică îl setăm ca argument. Iar al doilea argument este numele grupului.
Cum se întâmplă legătura? Acesta este un exemplu simplu de API care este utilizat. Totul este relativ simplu aici. Există o clasă standard ZooKeeper. Îi transmitem gazde. Și setați timeout-ul, de exemplu, la 5 secunde. Și avem un membru numit ConnectedSignal. În esență, creăm un grup de-a lungul căii transmise. Nu scriem date acolo, deși s-ar fi putut scrie ceva. Iar nodul de aici este de tip persistent. În esență, acesta este un nod obișnuit obișnuit care va exista tot timpul. Aici este creată sesiunea. Aceasta este implementarea clientului în sine. Clientul nostru va trimite periodic mesaje care indică faptul că sesiunea este în viață. Și când încheiem sesiunea, sunăm la închidere și gata, sesiunea cade. Asta în cazul în care ni se cade ceva, astfel încât ZooKeeper să afle despre asta și să întrerupă sesiunea.
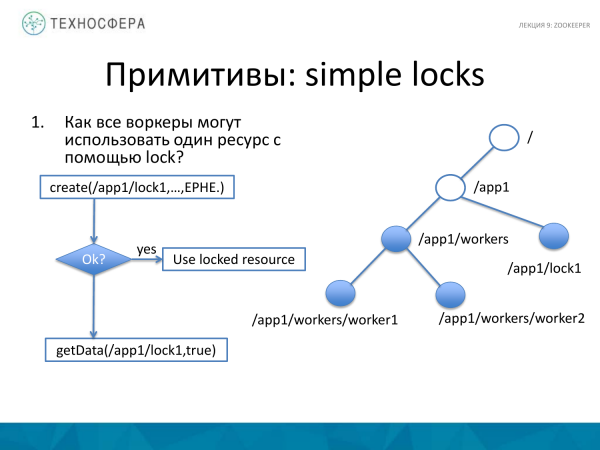
Cum să blochezi o resursă? Aici totul este puțin mai complicat. Avem un set de muncitori, există o resursă pe care vrem să o blocăm. Pentru a face acest lucru, creăm un nod separat, de exemplu, numit lock1. Dacă am reușit să-l creăm, atunci avem un lacăt aici. Și dacă nu am reușit să-l creăm, atunci lucrătorul încearcă să obțină getData de aici și, deoarece nodul a fost deja creat, atunci punem un observator aici și în momentul în care starea acestui nod se schimbă, vom ști despre asta. Și putem încerca să avem timp să o recreăm. Dacă am luat acest nod, am luat acest blocaj, atunci după ce nu mai avem nevoie de blocare, îl vom abandona, deoarece nodul există doar în cadrul sesiunii. În consecință, va dispărea. Și un alt client, în cadrul unei alte sesiuni, va putea lua blocarea pe acest nod, sau mai degrabă, va primi o notificare că ceva s-a schimbat și poate încerca să o facă la timp.
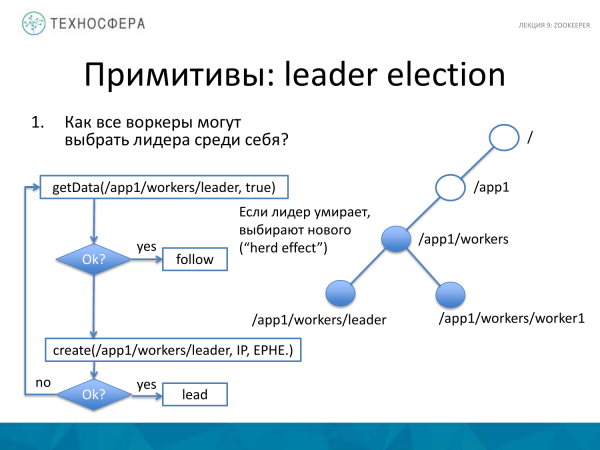
Un alt exemplu despre cum poți alege liderul principal. Acest lucru este puțin mai complicat, dar și relativ simplu. Ce se petrece aici? Există un nod principal care reunește toți lucrătorii. Încercăm să obținem date despre lider. Dacă acest lucru s-a întâmplat cu succes, adică am primit niște date, atunci lucrătorul nostru începe să urmărească acest lider. El crede că există deja un lider.
Dacă liderul a murit dintr-un motiv oarecare, de exemplu, a căzut, atunci încercăm să creăm un nou lider. Și dacă reușim, atunci lucrătorul nostru devine lider. Și dacă cineva în acest moment a reușit să creeze un nou lider, atunci încercăm să înțelegem cine este și apoi să-l urmăm.
Aici apare așa-numitul efect de turmă, adică efectul de turmă, deoarece atunci când un lider moare, cel care este primul în timp va deveni lider.
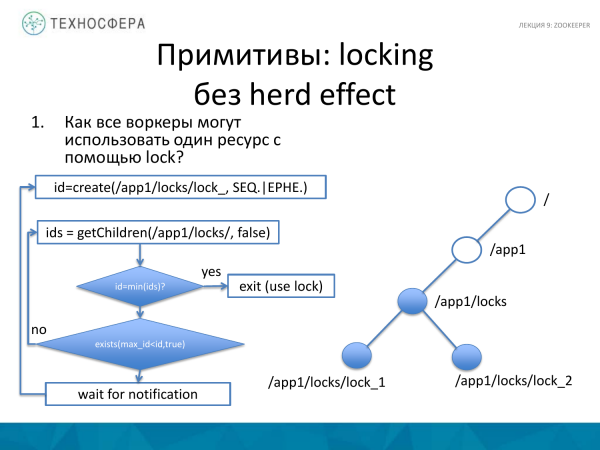
Când capturați o resursă, puteți încerca să utilizați o abordare ușor diferită, care este după cum urmează. De exemplu, vrem să obținem o blocare, dar fără efectul hert. Acesta va consta în faptul că aplicația noastră solicită liste cu toate ID-urile nodurilor pentru un nod deja existent cu blocare. Și dacă înainte de asta nodul pentru care am creat o blocare este cel mai mic din setul pe care l-am primit, atunci aceasta înseamnă că am capturat blocarea. Verificăm dacă am primit lacăt. Ca o verificare, va exista o condiție ca id-ul pe care l-am primit la crearea unei noi blocări să fie minim. Și dacă l-am primit, atunci lucrăm mai departe.
Dacă există un anumit ID care este mai mic decât blocarea noastră, atunci punem un observator pe acest eveniment și așteptăm notificarea până când se schimbă ceva. Adică am primit această lacăt. Și până nu cade, nu vom deveni id-ul minim și nu vom primi blocarea minimă și astfel ne vom putea autentifica. Și dacă această condiție nu este îndeplinită, atunci mergem imediat aici și încercăm să obținem din nou această lacăt, pentru că s-ar putea să se fi schimbat ceva în acest timp.
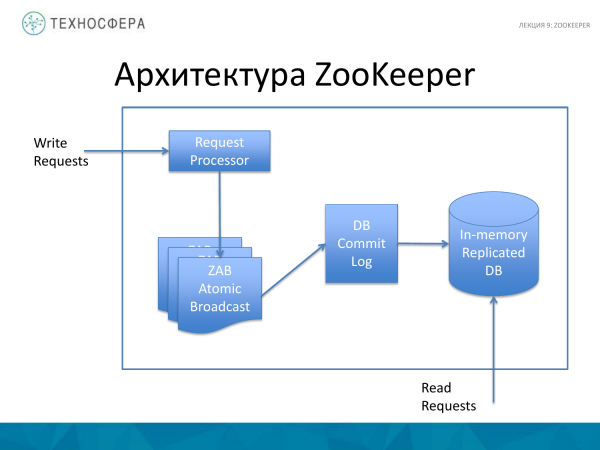
În ce constă ZooKeeper? Sunt 4 lucruri principale. Acesta este procesele de procesare - Solicitare. Și, de asemenea, ZooKeeper Atomic Broadcast. Există un jurnal de comitere în care sunt înregistrate toate operațiunile. Și DB replicat în memorie, adică baza de date în sine în care este stocat întregul arbore.
Este de remarcat faptul că toate operațiunile de scriere trec prin Procesorul de cereri. Și operațiunile de citire merg direct în baza de date în memorie.

Baza de date în sine este complet replicată. Toate instanțele ZooKeeper stochează o copie completă a datelor.
Pentru a restabili baza de date după un accident, există un jurnal de comitere. Practica standard este ca înainte ca datele să intre în memorie, acestea să fie scrise acolo, astfel încât, în cazul în care se blochează, acest jurnal poate fi redat și starea sistemului poate fi restaurată. Și sunt folosite și instantanee periodice ale bazei de date.

ZooKeeper Atomic Broadcast este un lucru care este folosit pentru a menține datele replicate.
ZAB selectează intern un lider din punctul de vedere al nodului ZooKeeper. Alte noduri devin adepții ei și se așteaptă la unele acțiuni de la ea. Dacă primesc înscrieri, le transmit pe toate liderului. Mai întâi efectuează o operațiune de scriere și apoi trimite un mesaj despre ceea ce s-a schimbat urmăritorilor săi. Aceasta, de fapt, trebuie efectuată atomic, adică operațiunea de înregistrare și difuzare a întregului lucru trebuie efectuată atomic, garantând astfel consistența datelor.
 Procesează doar cererile de scriere. Sarcina sa principală este să transforme operația într-o actualizare tranzacțională. Aceasta este o cerere special generată.
Procesează doar cererile de scriere. Sarcina sa principală este să transforme operația într-o actualizare tranzacțională. Aceasta este o cerere special generată.
Și aici este de remarcat faptul că idempotenta actualizărilor pentru aceeași operațiune este garantată. Ce este? Acest lucru, dacă este executat de două ori, va avea aceeași stare, adică cererea în sine nu se va schimba. Și acest lucru trebuie făcut astfel încât, în caz de blocare, să puteți reporni operațiunea, anulând astfel modificările care au căzut în acest moment. În acest caz, starea sistemului va deveni aceeași, adică nu ar trebui să fie cazul ca o serie de aceleași, de exemplu, procese de actualizare, să ducă la stări finale diferite ale sistemului.








Sursa: www.habr.com
