

Astăzi, există soluții gata făcute (proprietate) pentru monitorizarea fluxurilor IP(TS), de exemplu и , au un set destul de bogat de funcții și de obicei operatorii mari care se ocupă de servicii TV au astfel de soluții. Acest articol descrie o soluție bazată pe un proiect open source , conceput pentru controlul minim al fluxurilor IP(TS) prin contorul CC (contor de continuitate) și rata de biți. O posibilă aplicație este controlul pierderii de pachete sau a întregului flux printr-un canal L2 închiriat (care nu poate fi monitorizat în mod normal, de exemplu, citind contoare de pierderi în cozi).
Foarte pe scurt despre TSDuck
TSDuck este un software cu sursă deschisă (licență BSD cu două clauze) (un set de utilități de consolă și o bibliotecă pentru dezvoltarea de utilități sau plugin-uri personalizate) pentru manipularea fluxurilor TS. Ca intrare, poate funcționa cu IP (multicast/unicast), http, hls, tunere dvb, demodulator dektec dvb-asi, există un generator intern TS-stream și citire din fișiere. Ieșirea poate fi scrisă într-un fișier, IP (multicast/unicast), hls, dektec dvb-asi și modulatoare HiDes, playere (mplayer, vlc, xine) și drop. Diferite procesoare de trafic pot fi incluse între intrare și ieșire, de exemplu, remaparea PID, codificarea / decriptarea, analiza contorului CC, calculul ratei de biți și alte operațiuni tipice pentru fluxurile TS.
În acest articol vor fi folosite ca intrare fluxurile IP (multicast), procesoarele bitrate_monitor (din denumire se vede clar ce este) și continuitatea (analiza contoarelor CC). Puteți înlocui cu ușurință IP multicast cu un alt tip de intrare acceptat de TSDuck.
Există TSDuck pentru cele mai recente sisteme de operare. Pentru Debian Nu există niciunul, dar am reușit să-l asamblez fără probleme. debian 8 și debian 10.
În continuare, se folosește versiunea TSDuck 3.19-1520, iar sistemul de operare este Linux (folosit pentru prepararea soluției) debian 10, pentru utilizare reală - CentOS 7)
Pregătirea TSDuck și OS
Înainte de a monitoriza fluxurile reale, trebuie să vă asigurați că TSDuck funcționează corect și că nu există picături la nivelul plăcii de rețea sau al sistemului de operare (socket). Acest lucru este necesar pentru a nu ghici mai târziu unde au avut loc picăturile - în rețea sau „în interiorul serverului”. Puteți verifica picăturile la nivelul plăcii de rețea cu comanda ethtool -S ethX, reglarea se face de același ethtool (de obicei, trebuie să creșteți bufferul RX (-G) și uneori să dezactivați unele descarcări (-K)). Ca recomandare generală, se poate recomanda utilizarea unui port separat pentru recepționarea traficului analizat, dacă este posibil, acest lucru minimizează falsele pozitive asociate cu faptul că scăderea s-a produs exact pe portul analizorului din cauza prezenței altor trafic. Dacă acest lucru nu este posibil (se folosește un mini-calculator/NUC cu un port), atunci este foarte de dorit să se configureze prioritizarea traficului analizat în raport cu restul de pe dispozitivul la care este conectat analizorul. În ceea ce privește mediile virtuale, aici trebuie să fii atent și să poți găsi picături de pachete începând de la un port fizic și terminând cu o aplicație în interiorul unei mașini virtuale.
Generarea și recepția unui flux în interiorul gazdei
Ca prim pas în pregătirea TSDuck, vom genera și primi trafic într-o singură gazdă folosind netns.
Pregătirea mediului:
ip netns add P #создаём netns P, в нём будет происходить анализ трафика
ip link add type veth #создаём veth-пару - veth0 оставляем в netns по умолчанию (в этот интерфейс будет генерироваться трафик)
ip link set dev veth1 netns P #veth1 - помещаем в netns P (на этом интерфейсе будет приём трафика)
ip netns exec P ifconfig veth1 192.0.2.1/30 up #поднимаем IP на veth1, не имеет значения какой именно
ip netns exec P ip ro add default via 192.0.2.2 #настраиваем маршрут по умолчанию внутри nents P
sysctl net.ipv6.conf.veth0.disable_ipv6=1 #отключаем IPv6 на veth0 - это делается для того, чтобы в счётчик TX не попадал посторонний мусор
ifconfig veth0 up #поднимаем интерфейс veth0
ip route add 239.0.0.1 dev veth0 #создаём маршрут, чтобы ОС направляла трафик к 239.0.0.1 в сторону veth0Mediul este pregătit. Începem analizatorul de trafic:
ip netns exec P tsp --realtime -t
-I ip 239.0.0.1:1234
-P continuity
-P bitrate_monitor -p 1 -t 1
-O dropunde „-p 1 -t 1” înseamnă că trebuie să calculați rata de biți în fiecare secundă și să afișați informații despre rata de biți în fiecare secundă
Pornim generatorul de trafic cu o viteză de 10Mbps:
tsp -I craft
-P regulate -b 10000000
-O ip -p 7 -e --local-port 6000 239.0.0.1:1234unde "-p 7 -e" înseamnă că trebuie să împachetați 7 pachete TS într-un pachet IP și să o faceți din greu (-e), adică. așteptați întotdeauna 1 pachete TS de la ultimul procesor înainte de a trimite un pachet IP.
Analizorul începe să emită mesajele așteptate:
* 2020/01/03 14:55:44 - bitrate_monitor: 2020/01/03 14:55:44, TS bitrate: 9,970,016 bits/s
* 2020/01/03 14:55:45 - bitrate_monitor: 2020/01/03 14:55:45, TS bitrate: 10,022,656 bits/s
* 2020/01/03 14:55:46 - bitrate_monitor: 2020/01/03 14:55:46, TS bitrate: 9,980,544 bits/sAcum adăugați câteva picături:
ip netns exec P iptables -I INPUT -d 239.0.0.1 -m statistic --mode random --probability 0.001 -j DROPși apar mesaje ca acesta:
* 2020/01/03 14:57:11 - continuity: packet index: 80,745, PID: 0x0000, missing 7 packets
* 2020/01/03 14:57:11 - continuity: packet index: 83,342, PID: 0x0000, missing 7 packets care este de așteptat. Dezactivați pierderea de pachete (ip netns exec P iptables -F) și încercați să creșteți rata de biți a generatorului la 100Mbps. Analizorul raportează o grămadă de erori CC și aproximativ 75 Mbps în loc de 100. Încercăm să ne dăm seama cine este de vină - generatorul nu are timp sau problema nu este în el, pentru asta începem să generăm un număr fix de pachete (700000 pachete TS = 100000 pachete IP):
# ifconfig veth0 | grep TX
TX packets 151825460 bytes 205725459268 (191.5 GiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
# tsp -I craft -c 700000 -P regulate -b 100000000 -P count -O ip -p 7 -e --local-port 6000 239.0.0.1:1234
* count: PID 0 (0x0000): 700,000 packets
# ifconfig veth0 | grep TX
TX packets 151925460 bytes 205861259268 (191.7 GiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0După cum puteți vedea, au fost generate exact 100000 de pachete IP (151925460-151825460). Deci, să ne dăm seama ce se întâmplă cu analizorul, pentru asta verificăm cu contorul RX pe veth1, este strict egal cu contorul TX pe veth0, apoi ne uităm la ce se întâmplă la nivel de socket:
# ip netns exec P cat /proc/net/udp
sl local_address rem_address st tx_queue rx_queue tr tm->when retrnsmt uid timeout inode ref pointer drops
133: 010000EF:04D2 00000000:0000 07 00000000:00000000 00:00000000 00000000 0 0 72338 2 00000000e0a441df 24355 Aici puteți vedea numărul de picături = 24355. În pachetele TS, acesta este 170485 sau 24.36% din 700000, așa că vedem că aceleași 25% din rata de biți pierdută sunt picături în soclul udp. Scăderile într-un socket UDP apar de obicei din cauza lipsei de buffer, uitați-vă la dimensiunea implicită a socket-ului și la dimensiunea maximă a socket-ului:
# sysctl net.core.rmem_default
net.core.rmem_default = 212992
# sysctl net.core.rmem_max
net.core.rmem_max = 212992Astfel, dacă aplicațiile nu solicită în mod explicit o dimensiune de buffer, socket-urile sunt create cu un buffer de 208 KB, dar dacă solicită mai mult, tot nu vor primi ceea ce a fost solicitat. Deoarece puteți seta dimensiunea buffer-ului în tsp pentru intrarea IP (-buffer-size), nu vom atinge dimensiunea implicită a socket-ului, ci vom stabili doar dimensiunea maximă a buffer-ului socket-ului și vom specifica dimensiunea buffer-ului în mod explicit prin argumentele tsp:
sysctl net.core.rmem_max=8388608
ip netns exec P tsp --realtime -t -I ip 239.0.0.1:1234 -b 8388608 -P continuity -P bitrate_monitor -p 1 -t 1 -O dropCu această reglare a tamponului de socket, acum rata de biți raportată este de aproximativ 100 Mbps, nu există erori CC.
În funcție de consumul CPU al aplicației tsp în sine. Față de un procesor i5-4260U de nucleu la 1.40 GHz, analiza fluxului de 10 Mbps va necesita 3-4% CPU, 100 Mbps - 25%, 200 Mbps - 46%. Când setați % pierdere de pachete, sarcina CPU practic nu crește (dar poate scădea).
Pe un hardware mai productiv, a fost posibil să se genereze și să analizeze fluxuri de peste 1 Gb/s fără probleme.
Testare pe plăci de rețea reale
După testarea unei perechi veth, trebuie să luați două gazde sau două porturi ale unei gazde, să conectați porturile unul la celălalt, să porniți generatorul pe unul și analizorul pe al doilea. Nu au fost surprize aici, dar de fapt totul depinde de fier, cu cât este mai slab, cu atât va fi mai interesant aici.
Utilizarea datelor primite de către sistemul de monitorizare (Zabbix)
tsp nu are niciun API care poate fi citit de mașină, cum ar fi SNMP sau similar. Mesajele CC trebuie agregate pentru cel puțin 1 secundă (cu un procent mare de pierdere de pachete, pot exista sute/mii/zeci de mii pe secundă, în funcție de bitrate).
Astfel, pentru a salva atât informațiile, cât și pentru a desena grafice pentru erori CC și bitrate și pentru a face un fel de accidente, pot exista următoarele opțiuni:
- Analizați și agregați (prin CC) rezultatul tsp, adică convertiți-l în forma dorită.
- Finalizați tsp în sine și/sau pluginurile de procesor bitrate_monitor și continuity, astfel încât rezultatul să fie dat într-o formă care poate fi citită de mașină, potrivită pentru sistemul de monitorizare.
- Scrieți cererea dvs. în partea de sus a bibliotecii tsduck.
Evident, opțiunea 1 este cea mai ușoară din punct de vedere al efortului, mai ales având în vedere că tsduck în sine este scris într-un limbaj de nivel scăzut (după standardele moderne) (C++)
Un prototip simplu de analizator bash + agregator a arătat că pe un flux de 10 Mbps și pierderi de pachete de 50% (cel mai rău caz), procesul bash consuma de 3-4 ori mai mult procesor decât procesul tsp în sine. Acest scenariu este inacceptabil. De fapt, o bucată din acest prototip de mai jos
Taitei in partea de sus
#!/usr/bin/env bash
missingPackets=0
ccErrorSeconds=0
regexMissPackets='^* (.+) - continuity:.*missing ([0-9]+) packets$'
missingPacketsTime=""
ip netns exec P tsp --realtime -t -I ip -b 8388608 "239.0.0.1:1234" -O drop -P bitrate_monitor -p 1 -t 1 -P continuity 2>&1 |
while read i
do
#line example:* 2019/12/28 23:41:14 - continuity: packet index: 6,078, PID: 0x0100, missing 5 packets
#line example 2: * 2019/12/28 23:55:11 - bitrate_monitor: 2019/12/28 23:55:11, TS bitrate: 4,272,864 bits/s
if [[ "$i" == *continuity:* ]]
then
if [[ "$i" =~ $regexMissPackets ]]
then
missingPacketsTimeNew="${BASH_REMATCH[1]}" #timestamp (seconds)
if [[ "$missingPacketsTime" != "$missingPacketsTimeNew" ]] #new second with CC error
then
((ccErrorSeconds += 1))
fi
missingPacketsTime=$missingPacketsTimeNew
packets=${BASH_REMATCH[2]} #TS missing packets
((missingPackets += packets))
fi
elif [[ "$i" == *bitrate_monitor:* ]]
then
: #...
fi
donePe lângă faptul că este inacceptabil de lentă, nu există fire normale în bash, joburile bash sunt procese separate și a trebuit să scriu valoarea missingPackets o dată pe secundă pe efectul secundar (când primesc mesaje cu rata de biți care vin în fiecare secundă). Ca urmare, bash a fost lăsat în pace și s-a decis să scrie un wrapper (parser + agregator) în golang. Consumul procesorului de cod golang similar este de 4-5 ori mai mic decât procesul tsp în sine. Accelerarea ambalajului din cauza înlocuirii bash cu golang sa dovedit a fi de aproximativ 16 ori și, în general, rezultatul este acceptabil (încărcarea CPU cu 25% în cel mai rău caz). Fișierul sursă golang este localizat .
Rulați wrapper
Pentru a porni wrapper-ul, a fost creat cel mai simplu șablon de serviciu pentru systemd (). Wrapper-ul în sine ar trebui să fie compilat într-un fișier binar (go build tsduck-stat.go) situat în /opt/tsduck-stat/. Se presupune că utilizați golang cu suport pentru ceas monoton (>=1.9).
Pentru a crea o instanță a serviciului, trebuie să executați comanda systemctl enable tsduck-stat@239.0.0.1:1234, apoi să îl porniți folosind comanda systemctl start tsduck-stat@239.0.0.1:1234.
Descoperire de la Zabbix
Pentru ca zabbix să poată descoperi serviciile care rulează, este gata (discovery.sh), în formatul necesar pentru descoperirea Zabbix, se presupune că se află în același loc - în /opt/tsduck-stat. Pentru a rula descoperirea prin zabbix-agent, trebuie să adăugați în directorul de configurare zabbix-agent pentru a adăuga parametrul utilizator.
Șablon Zabbix
(tsduck_stat_template.xml) conține regula de descoperire automată, prototipuri de articole, grafice și declanșatoare.
Scurtă listă de verificare (ei bine, ce se întâmplă dacă cineva decide să o folosească)
- Asigurați-vă că tsp nu aruncă pachete în condiții „ideale” (generatorul și analizorul sunt conectate direct), dacă există picături, consultați paragraful 2 sau textul articolului despre această problemă.
- Faceți reglarea bufferului maxim de socket (net.core.rmem_max=8388608).
- Compilați tsduck-stat.go (mergeți să construiți tsduck-stat.go).
- Puneți șablonul de serviciu în /lib/systemd/system.
- Porniți serviciile cu systemctl, verificați dacă contoarele au început să apară (grep "" /dev/shm/tsduck-stat/*). Numărul de servicii după numărul de fluxuri multicast. Aici poate fi necesar să creați o rută către grupul multicast, poate să dezactivați rp_filter sau să creați o rută către ip-ul sursă.
- Rulați discovery.sh, asigurați-vă că generează json.
- Adăugați configurația agentului zabbix, reporniți agentul zabbix.
- Încărcați șablonul în zabbix, aplicați-l pe gazda care este monitorizată și agentul zabbix este instalat, așteptați aproximativ 5 minute, vedeți dacă există elemente noi, grafice și declanșatoare.
Rezultat
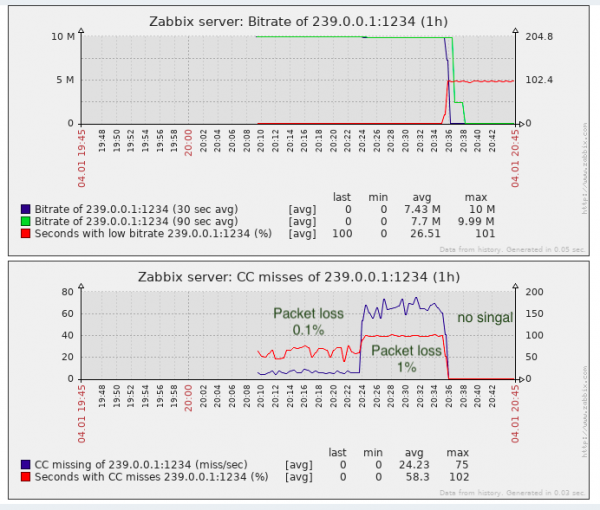
Pentru sarcina de a detecta pierderile de pachete, este aproape suficient, cel puțin este mai bine decât fără monitorizare.
Într-adevăr, „pierderile” CC pot apărea la îmbinarea fragmentelor video (din câte știu, așa se fac inserțiile la centrele TV locale din Federația Rusă, adică fără a recalcula contorul CC), acest lucru trebuie reținut. Soluțiile proprietare ocolesc parțial această problemă prin detectarea etichetelor SCTE-35 (dacă sunt adăugate de generatorul de flux).
În ceea ce privește monitorizarea calității transportului, există o lipsă a monitorizării jitter (IAT). Echipamentele TV (fie ele modulatoare sau dispozitive finale) au cerințe pentru acest parametru și nu este întotdeauna posibilă umflarea jitbuffer-ului la infinit. Iar jitter-ul poate pluti atunci când echipamentele cu buffere mari sunt utilizate în tranzit și QoS nu este configurat sau nu este suficient de bine configurat pentru a transmite un astfel de trafic în timp real.
Sursa: www.habr.com
