


Este 2019 și încă nu avem o soluție standard pentru agregarea jurnalelor în Kubernetes. În acest articol, am dori, folosind exemple din practica reală, să împărtășim căutările noastre, problemele întâlnite și soluțiile acestora.
Cu toate acestea, mai întâi, voi face o rezervare conform căreia diferiți clienți înțeleg lucruri foarte diferite prin colectarea jurnalelor:
- cineva vrea să vadă jurnalele de securitate și de audit;
- cineva - înregistrarea centralizată a întregii infrastructuri;
- iar pentru unii, este suficient să colectați doar jurnalele de aplicații, excluzând, de exemplu, echilibratorii.
Mai jos este tăierea de mai jos despre modul în care am implementat diverse „liste de dorințe” și ce dificultăți am întâmpinat.
Teorie: despre instrumentele de logare
Context despre componentele unui sistem de logare
Logarea a parcurs un drum lung, în urma căruia au fost dezvoltate metodologii de colectare și analiză a jurnalelor, ceea ce folosim astăzi. În anii 1950, Fortran a introdus un analog al fluxurilor de intrare/ieșire standard, care l-a ajutat pe programator să-și depaneze programul. Acestea au fost primele jurnale de computer care au ușurat viața programatorilor din acele vremuri. Astăzi vedem în ele prima componentă a sistemului de logare - sursă sau „producător” de bușteni.
Informatica nu a stat pe loc: au aparut retelele de calculatoare, primele clustere... Au inceput sa functioneze sisteme complexe formate din mai multe calculatoare. Acum, administratorii de sistem au fost forțați să colecteze jurnalele de pe mai multe mașini și, în cazuri speciale, puteau adăuga mesaje ale nucleului sistemului de operare în cazul în care aveau nevoie să investigheze o defecțiune a sistemului. Pentru a descrie sistemele centralizate de colectare a jurnalelor, la începutul anilor 2000 a fost publicat , care a standardizat remote_syslog. Așa a apărut o altă componentă importantă: colector de bușteni si depozitarea acestora.
Odată cu creșterea volumului de jurnale și introducerea pe scară largă a tehnologiilor web, a apărut întrebarea ce jurnale trebuie să fie afișate în mod convenabil utilizatorilor. Instrumentele simple de consolă (awk/sed/grep) au fost înlocuite cu altele mai avansate vizualizatoare de jurnal - a treia componentă.
Din cauza creșterii volumului de bușteni, altceva a devenit clar: sunt necesari bușteni, dar nu toți. Iar buștenii diferiți necesită niveluri diferite de conservare: unele se pot pierde într-o zi, în timp ce altele trebuie păstrate timp de 5 ani. Deci, o componentă pentru filtrarea și rutarea fluxurilor de date a fost adăugată sistemului de înregistrare - să o numim filtru.
De asemenea, stocarea a făcut un salt major: de la fișiere obișnuite la baze de date relaționale și apoi la stocarea orientată spre documente (de exemplu, Elasticsearch). Deci depozitul a fost separat de colector.
În cele din urmă, însuși conceptul de jurnal s-a extins la un fel de flux abstract de evenimente pe care dorim să-l păstrăm pentru istorie. Sau mai bine zis, in cazul in care trebuie sa faci o investigatie sau sa intocmesti un raport analitic...
Drept urmare, într-o perioadă relativ scurtă de timp, colectarea jurnalelor s-a dezvoltat într-un subsistem important, care poate fi numit pe bună dreptate una dintre subsecțiunile din Big Data.
Dacă cândva imprimările obișnuite puteau fi suficiente pentru un „sistem de înregistrare”, acum situația s-a schimbat mult.
Kubernetes și jurnalele
Când Kubernetes a ajuns la infrastructură, problema deja existentă a colectării jurnalelor nu a ocolit-o nici. În unele privințe, a devenit și mai dureros: gestionarea platformei de infrastructură nu a fost doar simplificată, ci și complicată în același timp. Multe servicii vechi au început să migreze la microservicii. În contextul jurnalelor, acest lucru se reflectă în numărul tot mai mare de surse de jurnal, ciclul lor de viață special și necesitatea de a urmări relațiile tuturor componentelor sistemului prin jurnalele...
Privind în perspectivă, pot afirma că acum, din păcate, nu există nicio opțiune de înregistrare standardizată pentru Kubernetes care să se compare favorabil cu toate celelalte. Cele mai populare scheme din comunitate sunt următoarele:
- cineva derulează teancul EFK (Elasticsearch, Fluentd, Kibana);
- cineva încearcă cel recent lansat sau utilizări ;
- ne (și poate nu numai noi?..) Sunt în mare parte mulțumit de propria mea dezvoltare - ...
De regulă, folosim următoarele pachete în clusterele K8s (pentru soluții auto-găzduite):
- ;
- .
Cu toate acestea, nu mă voi opri asupra instrucțiunilor pentru instalarea și configurarea lor. În schimb, mă voi concentra pe deficiențele lor și pe concluzii mai globale despre situația cu jurnalele în general.
Exersați cu jurnalele în K8-uri

„Bușteni de zi cu zi”, câți dintre voi sunteți acolo?...
Colectarea centralizată a buștenilor dintr-o infrastructură destul de mare necesită resurse considerabile, care vor fi cheltuite pentru colectarea, stocarea și procesarea buștenilor. Pe parcursul derulării diferitelor proiecte, ne-am confruntat cu diverse cerințe și probleme operaționale care decurg din acestea.
Să încercăm ClickHouse
Să ne uităm la o stocare centralizată pe un proiect cu o aplicație care generează loguri destul de activ: mai mult de 5000 de linii pe secundă. Să începem să lucrăm cu jurnalele lui, adăugându-le la ClickHouse.
De îndată ce este nevoie de timp real maxim, serverul cu 4 nuclee cu ClickHouse va fi deja supraîncărcat pe subsistemul de disc:
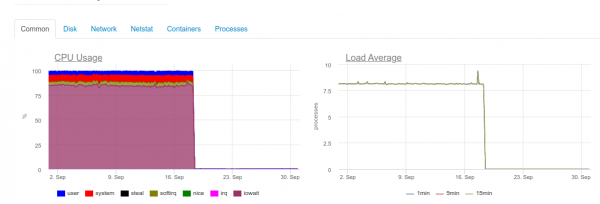
Acest tip de încărcare se datorează faptului că încercăm să scriem în ClickHouse cât mai repede posibil. Și baza de date reacționează la aceasta cu o încărcare crescută a discului, ceea ce poate provoca următoarele erori:
DB::Exception: Too many parts (300). Merges are processing significantly slower than inserts
Fapt este că în ClickHouse (ele conțin date de jurnal) au propriile lor dificultăți în timpul operațiunilor de scriere. Datele inserate în ele generează o partiție temporară, care este apoi îmbinată cu tabelul principal. Ca urmare, înregistrarea se dovedește a fi foarte solicitantă pe disc și este, de asemenea, supusă limitării despre care am primit notificarea mai sus: nu pot fi îmbinate mai mult de 1 de subpartiții într-o secundă (de fapt, aceasta este 300 de inserții). pe secunda).
Pentru a evita acest comportament, în bucăți cât mai mari și nu mai mult de 1 dată la 2 secunde. Cu toate acestea, scrierea în rafale mari sugerează că ar trebui să scriem mai rar în ClickHouse. Acest lucru, la rândul său, poate duce la o depășire a tamponului și la pierderea buștenilor. Soluția este creșterea buffer-ului Fluentd, dar apoi va crește și consumul de memorie.
Nota: Un alt aspect problematic al soluției noastre cu ClickHouse a fost legat de faptul că partiționarea în cazul nostru (loghouse) este implementată prin tabele externe conectate . Acest lucru duce la faptul că, atunci când se eșantionează intervale de timp mari, este necesară o memorie RAM excesivă, deoarece metatabelul iterează prin toate partițiile - chiar și cele care, evident, nu conțin datele necesare. Cu toate acestea, acum această abordare poate fi declarată în siguranță învechită pentru versiunile actuale de ClickHouse (c ).
Ca urmare, devine clar că nu fiecare proiect are suficiente resurse pentru a colecta jurnalele în timp real în ClickHouse (mai precis, distribuția lor nu va fi adecvată). În plus, va trebui să utilizați acumulator, la care vom reveni mai târziu. Cazul descris mai sus este real. Și la acel moment nu am putut oferi o soluție fiabilă și stabilă care să se potrivească clientului și să ne permită să colectăm bușteni cu întârziere minimă...
Dar Elasticsearch?
Elasticsearch este cunoscut pentru a gestiona sarcini grele. Să încercăm în același proiect. Acum încărcarea arată astfel:
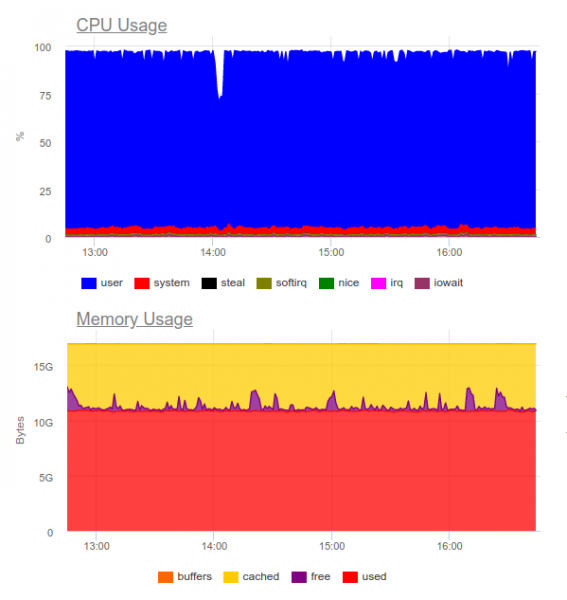
Elasticsearch a reușit să digeră fluxul de date, totuși, scrierea unor astfel de volume pe acesta utilizează foarte mult procesorul. Acest lucru se decide prin organizarea unui cluster. Din punct de vedere tehnic, aceasta nu este o problemă, dar se dovedește că doar pentru a opera sistemul de colectare a jurnalelor folosim deja aproximativ 8 nuclee și avem o componentă suplimentară foarte încărcată în sistem...
Concluzia: această opțiune poate fi justificată, dar numai dacă proiectul este mare și managementul său este pregătit să cheltuiască resurse semnificative pe un sistem centralizat de înregistrare.
Atunci apare o întrebare firească:
Ce loguri sunt cu adevărat necesare?
 Să încercăm să schimbăm abordarea în sine: jurnalele ar trebui să fie simultan informative și nu să acopere fiecare eveniment din sistem.
Să încercăm să schimbăm abordarea în sine: jurnalele ar trebui să fie simultan informative și nu să acopere fiecare eveniment din sistem.
Să presupunem că avem un magazin online de succes. Ce loguri sunt importante? Colectarea cât mai multor informații posibil, de exemplu, de la un gateway de plată, este o idee grozavă. Dar nu toate jurnalele din serviciul de tăiere a imaginilor din catalogul de produse sunt critice pentru noi: sunt suficiente doar erorile și monitorizarea avansată (de exemplu, procentul de 500 de erori pe care îl generează această componentă).
Deci am ajuns la concluzia că înregistrarea centralizată nu este întotdeauna justificată. De foarte multe ori clientul dorește să colecteze toate jurnalele într-un singur loc, deși, de fapt, din întregul jurnal, sunt necesare doar 5% condiționate din mesajele critice pentru afacere:
- Uneori este suficient să configurați, să zicem, doar dimensiunea jurnalului de container și a colectorului de erori (de exemplu, Sentry).
- O notificare de eroare și un jurnal local mare în sine pot fi adesea suficiente pentru a investiga incidentele.
- Am avut proiecte care s-au descurcat cu teste exclusiv funcționale și sisteme de colectare a erorilor. Dezvoltatorul nu a avut nevoie de jurnalele ca atare - au văzut totul de la urmele erorilor.
Ilustrație din viață
O altă poveste poate servi drept exemplu bun. Am primit o solicitare de la echipa de securitate a unuia dintre clienții noștri care folosea deja o soluție comercială care a fost dezvoltată cu mult înainte de introducerea Kubernetes.
A fost necesar să „facem prieteni” cu sistemul centralizat de colectare a jurnalelor cu senzorul de detectare a problemelor corporative - QRadar. Acest sistem poate primi jurnalele prin protocolul syslog și le poate prelua de pe FTP. Cu toate acestea, nu a fost imediat posibilă integrarea acestuia cu pluginul remote_syslog pentru fluentd (după cum s-a dovedit, ). Problemele cu configurarea QRadar s-au dovedit a fi de partea echipei de securitate a clientului.
Ca urmare, o parte din jurnalele critice pentru afaceri au fost încărcate pe FTP QRadar, iar cealaltă parte a fost redirecționată prin syslog la distanță direct de la noduri. Pentru asta chiar am scris - poate că va ajuta pe cineva să rezolve o problemă similară... Datorită schemei rezultate, clientul însuși a primit și a analizat jurnalele critice (folosind instrumentele sale preferate) și am reușit să reducem costul sistemului de înregistrare, economisind doar luna trecuta.
Un alt exemplu este destul de indicativ pentru ceea ce nu trebuie făcut. Unul dintre clienții noștri pentru procesare fiecare evenimente venite de la utilizator, realizate multilinie ieșire nestructurată informații din jurnal. După cum ați putea ghici, astfel de jurnale erau extrem de incomod de citit și de stocat.
Criterii pentru bușteni
Astfel de exemple duc la concluzia că, pe lângă alegerea unui sistem de colectare a buștenilor, trebuie proiectează, de asemenea, jurnalele în sine! Care sunt cerințele aici?
- Jurnalele trebuie să fie în format care poate fi citit de mașină (de exemplu, JSON).
- Jurnalele ar trebui să fie compacte și cu capacitatea de a schimba gradul de înregistrare pentru a depana eventualele probleme. În același timp, în mediile de producție ar trebui să rulați sisteme cu un nivel de înregistrare ca avertizare sau Eroare.
- Jurnalele trebuie normalizate, adică într-un obiect jurnal, toate liniile trebuie să aibă același tip de câmp.
Buștenii nestructurați pot duce la probleme cu încărcarea buștenilor în depozit și la oprirea completă a procesării acestora. Ca o ilustrare, iată un exemplu cu eroarea 400, pe care mulți l-au întâlnit cu siguranță în jurnalele fluentd:
2019-10-29 13:10:43 +0000 [warn]: dump an error event: error_class=Fluent::Plugin::ElasticsearchErrorHandler::ElasticsearchError error="400 - Rejected by Elasticsearch"
Eroarea înseamnă că trimiteți un câmp al cărui tip este instabil la index cu o mapare gata făcută. Cel mai simplu exemplu este un câmp din jurnalul nginx cu o variabilă $upstream_status. Poate conține fie un număr, fie un șir. De exemplu:
{ "ip": "1.2.3.4", "http_user": "-", "request_id": "17ee8a579e833b5ab9843a0aca10b941", "time": "29/Oct/2019:16:18:57 +0300", "method": "GET", "uri": "/staffs/265.png", "protocol": "HTTP/1.1", "status": "200", "body_size": "906", "referrer": "https://example.com/staff", "user_agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.70 Safari/537.36", "request_time": "0.001", "cache_status": "-", "upstream_response_time": "0.001, 0.007", "upstream_addr": "127.0.0.1:9000", "upstream_status": "200", "upstream_response_length": "906", "location": "staff"}
{ "ip": "1.2.3.4", "http_user": "-", "request_id": "47fe42807f2a7d8d5467511d7d553a1b", "time": "29/Oct/2019:16:18:57 +0300", "method": "GET", "uri": "/staff", "protocol": "HTTP/1.1", "status": "200", "body_size": "2984", "referrer": "-", "user_agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.70 Safari/537.36", "request_time": "0.010", "cache_status": "-", "upstream_response_time": "0.001, 0.007", "upstream_addr": "10.100.0.10:9000, 10.100.0.11:9000", "upstream_status": "404, 200", "upstream_response_length": "0, 2984", "location": "staff"}
Jurnalele arată că serverul 10.100.0.10 a răspuns cu o eroare 404 și cererea a fost trimisă la o altă stocare de conținut. Ca rezultat, valoarea din jurnale a devenit astfel:
"upstream_response_time": "0.001, 0.007"
Această situație este atât de comună, încât merită chiar să fie separată .
Ce zici de fiabilitate?
Există momente când toate jurnalele, fără excepție, sunt vitale. Și cu aceasta, schemele tipice de colectare a jurnalelor pentru K8-uri propuse/discutate mai sus au probleme.
De exemplu, fluentd nu poate colecta bușteni din containere de scurtă durată. Într-unul dintre proiectele noastre, containerul de migrare a bazei de date a trăit mai puțin de 4 secunde și apoi a fost șters - conform adnotării corespunzătoare:
"helm.sh/hook-delete-policy": hook-succeeded
Din acest motiv, jurnalul de execuție a migrației nu a fost inclus în stocare. Politica poate ajuta în acest caz. before-hook-creation.
Un alt exemplu este rotația jurnalului Docker. Să presupunem că există o aplicație care scrie în mod activ în jurnalele. În condiții normale, reușim să procesăm toate jurnalele, dar de îndată ce apare o problemă - de exemplu, așa cum este descris mai sus cu un format incorect - procesarea se oprește, iar Docker rotește fișierul. Rezultatul este că jurnalele critice pentru afaceri se pot pierde.
De asta este important să separați fluxurile de jurnal, înglobând trimiterea celor mai valoroase direct în aplicație pentru a le asigura siguranța. În plus, nu ar fi de prisos să creăm câteva „acumulator” de bușteni, care poate supraviețui unei indisponibilități scurte de stocare salvând în același timp mesajele critice.
În fine, nu trebuie să uităm asta Este important să monitorizați în mod corespunzător orice subsistem. În caz contrar, este ușor să dai peste o situație în care fluentd se află într-o stare CrashLoopBackOff și nu trimite nimic, iar acest lucru promite pierderea de informații importante.
Constatări
În acest articol, nu ne uităm la soluții SaaS precum Datadog. Multe dintre problemele descrise aici au fost deja rezolvate într-un fel sau altul de companiile comerciale specializate în colectarea de busteni, dar nu toată lumea poate folosi SaaS din diverse motive (cele principale sunt costul și conformitatea cu 152-FZ).
Colectarea centralizată a jurnalelor pare la început o sarcină simplă, dar nu este deloc. Este important de reținut că:
- Doar componentele critice trebuie înregistrate în detaliu, în timp ce monitorizarea și colectarea erorilor pot fi configurate pentru alte sisteme.
- Buștenii în producție ar trebui să fie păstrați la minimum pentru a nu adăuga încărcătură inutilă.
- Jurnalele trebuie să fie citite de mașină, normalizate și să aibă un format strict.
- Jurnalele cu adevărat critice ar trebui trimise într-un flux separat, care ar trebui să fie separat de cele principale.
- Merită să luați în considerare un acumulator de bușteni, care vă poate salva de exploziile de sarcină mare și vă poate uniformiza încărcarea depozitului.

Aceste reguli simple, dacă sunt aplicate peste tot, ar permite circuitelor descrise mai sus să funcționeze - chiar dacă le lipsesc componente importante (bateria). Dacă nu respectați astfel de principii, sarcina vă va conduce cu ușurință pe dumneavoastră și pe infrastructura către o altă componentă a sistemului foarte încărcată (și în același timp ineficientă).
PS
Citește și pe blogul nostru:
- «»;
- «»;
- «".
Sursa: www.habr.com
