


Întâlnim în mod regulat baza de date Apache Cassandra și nevoia de a o opera într-o infrastructură bazată pe Kubernetes. În acest material, vom împărtăși viziunea noastră cu privire la pașii necesari, criteriile și soluțiile existente (inclusiv o prezentare generală a operatorilor) pentru migrarea Cassandra la K8s.
„Cine poate conduce o femeie poate conduce și statul”
Cine este Cassandra? Este un sistem de stocare distribuit conceput pentru a gestiona volume mari de date, asigurând în același timp o disponibilitate ridicată fără un singur punct de defecțiune. Proiectul nu are nevoie de o introducere lungă, așa că voi oferi doar principalele caracteristici ale Cassandrei care vor fi relevante în contextul unui articol specific:
- Cassandra este scrisă în Java.
- Topologia Cassandra include mai multe niveluri:
- Nod - o instanță Cassandra implementată;
- Rack este un grup de instanțe Cassandra, unite printr-o anumită caracteristică, situate în același centru de date;
- Datacenter - o colecție de toate grupurile de instanțe Cassandra situate într-un singur centru de date;
- Clusterul este o colecție a tuturor centrelor de date.
- Cassandra folosește o adresă IP pentru a identifica un nod.
- Pentru a accelera operațiunile de scriere și citire, Cassandra stochează unele dintre date în RAM.
Acum - la potențiala mutare reală la Kubernetes.
Lista de verificare pentru transfer
Vorbind despre migrarea Cassandrei către Kubernetes, sperăm că odată cu mutarea va deveni mai convenabil de gestionat. Ce va fi necesar pentru asta, ce va ajuta cu asta?
1. Stocarea datelor
După cum a fost deja clarificat, Cassanda stochează o parte din date în RAM - în Memtable. Dar există o altă parte a datelor care este salvată pe disc - sub formă SSTable. La aceste date se adaugă o entitate Jurnal de comitere — înregistrări ale tuturor tranzacțiilor, care sunt, de asemenea, salvate pe disc.
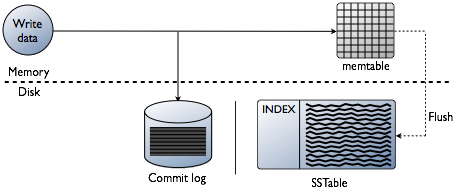
Scrieți diagrama tranzacției în Cassandra
În Kubernetes, putem folosi PersistentVolume pentru a stoca date. Datorită mecanismelor dovedite, lucrul cu date în Kubernetes devine mai ușor în fiecare an.
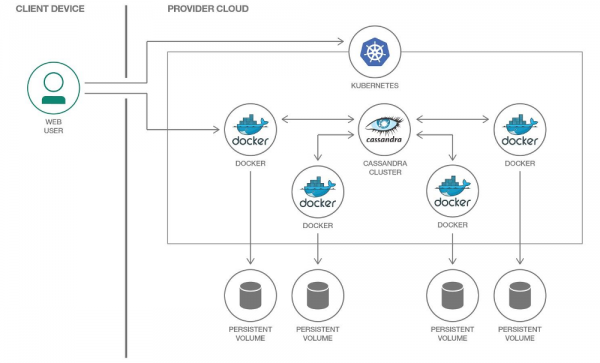
Vom aloca propriul nostru volum persistent fiecărei capsule Cassandra
Este important de menționat că Cassandra în sine implică replicarea datelor, oferind mecanisme încorporate pentru aceasta. Prin urmare, dacă construiți un cluster Cassandra dintr-un număr mare de noduri, atunci nu este nevoie să utilizați sisteme distribuite precum Ceph sau GlusterFS pentru stocarea datelor. În acest caz, ar fi logic să stocați date pe discul gazdă folosind sau montaj hostPath.
O altă întrebare este dacă doriți să creați un mediu separat pentru dezvoltatori pentru fiecare ramură a caracteristicilor. În acest caz, abordarea corectă ar fi să ridicați un nod Cassandra și să stocați datele într-o stocare distribuită, de exemplu. Ceph și GlusterFS menționate vor fi opțiunile tale. Apoi, dezvoltatorul va fi sigur că nu va pierde datele de testare chiar dacă unul dintre nodurile clusterului Kuberntes este pierdut.
2. Monitorizare
Alegerea practic de necontestat pentru implementarea monitorizării în Kubernetes este Prometheus (Am vorbit despre asta în detaliu în ). Cum se descurcă Cassandra cu exportatorii de metrici pentru Prometheus? Și, ce este și mai important, cu tablouri de bord potrivite pentru Grafana?
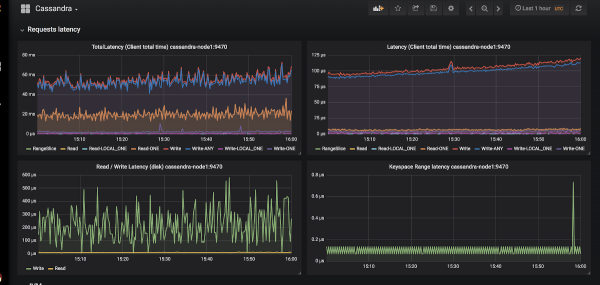
Un exemplu de apariție a graficelor în Grafana pentru Cassandra
Există doar doi exportatori: и .
Pe primul l-am ales singuri pentru că:
- JMX Exporter crește și se dezvoltă, în timp ce Cassandra Exporter nu a reușit să obțină suficient sprijin comunitar. Cassandra Exporter încă nu acceptă majoritatea versiunilor de Cassandra.
- Îl puteți rula ca javaagent adăugând un steag
-javaagent:<plugin-dir-name>/cassandra-exporter.jar=--listen=:9180. - Există unul pentru el , care este incompatibil cu Cassandra Exporter.
3. Selectarea primitivelor Kubernetes
Conform structurii de mai sus a clusterului Cassandra, să încercăm să traducem tot ceea ce este descris acolo în terminologia Kubernetes:
- Nodul Cassandra → Pod
- Cassandra Rack → StatefulSet
- Cassandra Datacenter → pool din StatefulSets
- Cassandra Cluster → ???
Se pare că lipsește o entitate suplimentară pentru a gestiona întregul cluster Cassandra deodată. Dar dacă ceva nu există, îl putem crea! Kubernetes are un mecanism de definire a propriilor resurse în acest scop - .
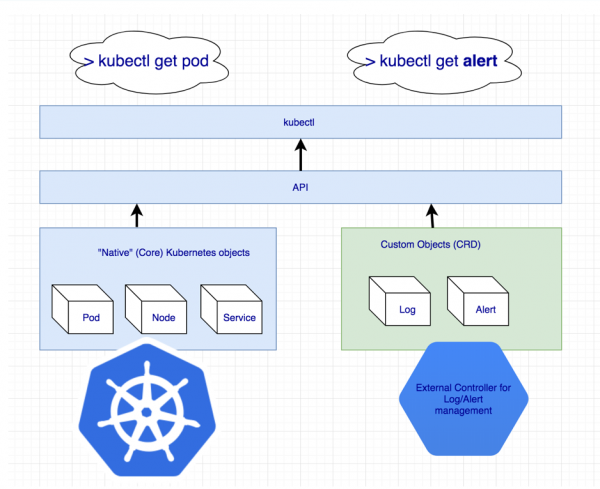
Declararea resurselor suplimentare pentru jurnalele și alertele
Dar Custom Resource în sine nu înseamnă nimic: la urma urmei, necesită controlor. Este posibil să aveți nevoie să căutați ajutor ...
4. Identificarea păstăilor
În paragraful de mai sus, am convenit că un nod Cassandra va fi egal cu un pod în Kubernetes. Dar adresele IP ale podurilor vor fi diferite de fiecare dată. Iar identificarea unui nod în Cassandra se bazează pe adresa IP... Se dovedește că după fiecare îndepărtare a unui pod, clusterul Cassandra va adăuga un nou nod.
Există o cale de ieșire, și nu doar una:
- Putem păstra înregistrări după identificatori de gazdă (UUID-uri care identifică în mod unic instanțele Cassandra) sau după adrese IP și le stocăm pe toate în unele structuri/tabele. Metoda are două dezavantaje principale:
- Riscul ca o condiție de cursă să apară dacă două noduri cad simultan. După creștere, nodurile Cassandra vor solicita simultan o adresă IP de la masă și vor concura pentru aceeași resursă.
- Dacă un nod Cassandra și-a pierdut datele, nu îl vom mai putea identifica.
- A doua soluție pare un mic hack, dar totuși: putem crea un Serviciu cu ClusterIP pentru fiecare nod Cassandra. Probleme cu această implementare:
- Dacă există o mulțime de noduri într-un cluster Cassandra, va trebui să creăm o mulțime de Servicii.
- Caracteristica ClusterIP este implementată prin iptables. Acest lucru poate deveni o problemă dacă clusterul Cassandra are multe (1000... sau chiar 100?) noduri. Cu toate că poate rezolva această problemă.
- A treia soluție este să utilizați o rețea de noduri pentru nodurile Cassandra în loc de o rețea dedicată de poduri, activând setarea
hostNetwork: true. Această metodă impune anumite limitări:- Pentru a înlocui unitățile. Este necesar ca noul nod să aibă aceeași adresă IP ca și cel precedent (în nori precum AWS, GCP acest lucru este aproape imposibil de realizat);
- Folosind o rețea de noduri de cluster, începem să concuram pentru resursele rețelei. Prin urmare, plasarea mai multor pod cu Cassandra pe un singur nod de cluster va fi problematică.
5. Backup-uri
Dorim să salvăm o versiune completă a datelor unui singur nod Cassandra într-un program. Kubernetes oferă o caracteristică convenabilă de utilizare , dar aici însăși Cassandra ne pune o spiță în roți.
Permiteți-mi să vă reamintesc că Cassandra stochează unele dintre date în memorie. Pentru a face o copie de rezervă completă, aveți nevoie de date din memorie (Memtables) mutați pe disc (SSTables). În acest moment, nodul Cassandra încetează să accepte conexiuni, oprindu-se complet din cluster.
După aceasta, copia de rezervă este eliminată (instantaneu) și schema este salvată (keyspace). Și apoi se dovedește că doar o copie de rezervă nu ne oferă nimic: trebuie să salvăm identificatorii de date pentru care nodul Cassandra a fost responsabil - acestea sunt simboluri speciale.
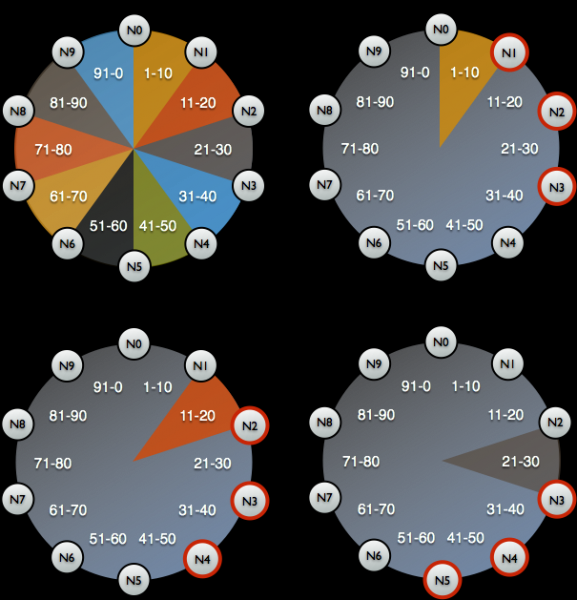
Distribuție de jetoane pentru a identifica de ce date sunt responsabile nodurile Cassandra
Un exemplu de script pentru a face o copie de rezervă Cassandra de la Google în Kubernetes poate fi găsit la . Singurul punct de care scriptul nu ia în considerare este resetarea datelor la nod înainte de a face instantaneul. Adică, backup-ul nu se efectuează pentru starea curentă, ci pentru o stare puțin mai devreme. Dar acest lucru ajută să nu scoateți nodul din funcțiune, ceea ce pare foarte logic.
set -eu
if [[ -z "$1" ]]; then
info "Please provide a keyspace"
exit 1
fi
KEYSPACE="$1"
result=$(nodetool snapshot "${KEYSPACE}")
if [[ $? -ne 0 ]]; then
echo "Error while making snapshot"
exit 1
fi
timestamp=$(echo "$result" | awk '/Snapshot directory: / { print $3 }')
mkdir -p /tmp/backup
for path in $(find "/var/lib/cassandra/data/${KEYSPACE}" -name $timestamp); do
table=$(echo "${path}" | awk -F "[/-]" '{print $7}')
mkdir /tmp/backup/$table
mv $path /tmp/backup/$table
done
tar -zcf /tmp/backup.tar.gz -C /tmp/backup .
nodetool clearsnapshot "${KEYSPACE}"Un exemplu de script bash pentru a face o copie de rezervă de la un nod Cassandra
Soluții gata pentru Cassandra în Kubernetes
Ce se utilizează în prezent pentru a implementa Cassandra în Kubernetes și care dintre acestea se potrivește cel mai bine cerințelor date?
1. Soluții bazate pe diagrame StatefulSet sau Helm
Utilizarea funcțiilor de bază StatefulSets pentru a rula un cluster Cassandra este o opțiune bună. Folosind graficul Helm și șabloanele Go, puteți oferi utilizatorului o interfață flexibilă pentru implementarea Cassandra.
Acest lucru funcționează de obicei bine... până când se întâmplă ceva neașteptat, cum ar fi o defecțiune a nodului. Instrumentele standard Kubernetes pur și simplu nu pot lua în considerare toate caracteristicile descrise mai sus. În plus, această abordare este foarte limitată în ceea ce privește cât de mult poate fi extinsă pentru utilizări mai complexe: înlocuirea nodurilor, backup, recuperare, monitorizare etc.
Reprezentanți:
- ;
- .
Ambele grafice sunt la fel de bune, dar fac obiectul problemelor descrise mai sus.
2. Soluții bazate pe Kubernetes Operator
Astfel de opțiuni sunt mai interesante deoarece oferă oportunități ample de gestionare a clusterului. Pentru proiectarea unui operator Cassandra, ca orice altă bază de date, un model bun arată ca Sidecar <-> Controller <-> CRD:
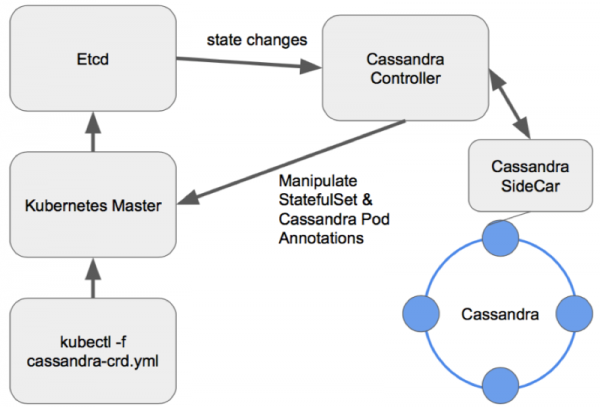
Schema de gestionare a nodurilor într-un operator Cassandra bine proiectat
Să ne uităm la operatorii existenți.
1. Cassandra-operator de la instaclustr
- Pregătire: Alfa
- Licență: Apache 2.0
- Implementat în: Java
Acesta este într-adevăr un proiect foarte promițător și în curs de dezvoltare activ de la o companie care oferă implementări gestionate de Cassandra. După cum este descris mai sus, folosește un container sidecar care acceptă comenzi prin HTTP. Scris în Java, uneori îi lipsește funcționalitatea mai avansată a bibliotecii client-go. De asemenea, operatorul nu acceptă rafturi diferite pentru un centru de date.
Operatorul are însă avantaje precum suport pentru monitorizare, managementul clusterelor la nivel înalt folosind CRD și chiar documentație pentru realizarea de copii de siguranță.
2. Navigator de la Jetstack
- Pregătire: Alfa
- Licență: Apache 2.0
- Implementat în: Golang
O declarație concepută pentru a implementa DB-as-a-Service. În prezent, acceptă două baze de date: Elasticsearch și Cassandra. Are soluții atât de interesante precum controlul accesului la baza de date prin RBAC (pentru aceasta are propriul navigator-apiserver separat). Un proiect interesant la care ar merita să-l aruncăm mai atent, dar ultimul angajament a fost făcut în urmă cu un an și jumătate, ceea ce îi reduce clar potențialul.
3. Cassandra-operator de vgkowski
- Pregătire: Alfa
- Licență: Apache 2.0
- Implementat în: Golang
Nu l-au considerat „serios”, deoarece ultimul comit în depozit a fost acum mai bine de un an. Dezvoltarea operatorului este abandonată: cea mai recentă versiune de Kubernetes raportată ca fiind acceptată este 1.9.
4. Cassandra-operator de Rook
- Pregătire: Alfa
- Licență: Apache 2.0
- Implementat în: Golang
Un operator a cărui dezvoltare nu progresează atât de repede pe cât ne-am dori. Are o structură CRD bine gândită pentru managementul clusterului, rezolvă problema identificării nodurilor folosind Service with ClusterIP (același „hack”)... dar asta e tot pentru moment. În prezent, nu există nicio monitorizare sau backup din cutie (apropo, suntem pentru monitorizare ). Un punct interesant este că puteți implementa și ScyllaDB folosind acest operator.
NB: Am folosit acest operator cu mici modificări într-unul dintre proiectele noastre. Nu au fost observate probleme în munca operatorului pe toată perioada de funcționare (~4 luni de funcționare).
5. CassKop de la Orange
- Pregătire: Alfa
- Licență: Apache 2.0
- Implementat în: Golang
Cel mai tânăr operator de pe listă: primul comit a fost făcut pe 23 mai 2019. Deja acum are în arsenalul său un număr mare de caracteristici din lista noastră, despre care mai multe detalii pot fi găsite în depozitul de proiect. Operatorul este construit pe baza popularului operator-sdk. Suportă monitorizarea din cutie. Principala diferență față de alți operatori este utilizarea , implementat în Python și utilizat pentru comunicarea între nodurile Cassandra.
Constatări
Numărul de abordări și opțiuni posibile pentru portarea Cassandra la Kubernetes vorbește de la sine: subiectul este solicitat.
În această etapă, puteți încerca oricare dintre cele de mai sus pe propriul risc și risc: niciunul dintre dezvoltatori nu garantează funcționarea 100% a soluției lor într-un mediu de producție. Dar deja, multe produse par promițătoare de încercat să fie folosite în bancurile de dezvoltare.
Cred că în viitor această femeie de pe navă va veni de folos!
PS
Citește și pe blogul nostru:
- «»;
- «»;
- «»;
- «".
Sursa: www.habr.com
