

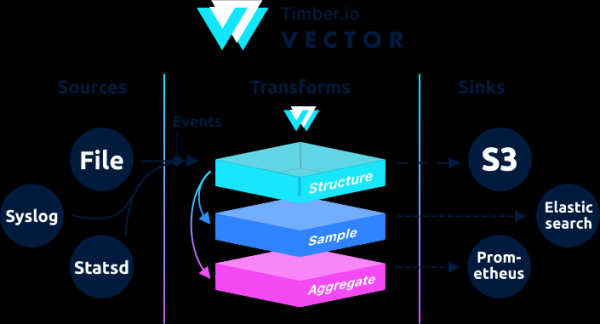
, conceput pentru a colecta, transforma și trimite date de jurnal, valori și evenimente.
→
Fiind scrisă în limbajul Rust, se caracterizează prin performanță ridicată și consum redus de RAM în comparație cu analogii săi. În plus, se acordă multă atenție funcțiilor legate de corectitudine, în special, capacitatea de a salva evenimentele netrimise într-un buffer de pe disc și de a roti fișierele.
Din punct de vedere arhitectural, Vector este un router de evenimente care primește mesaje de la unul sau mai multe surse, aplicând opțional peste aceste mesaje transformăriși trimiterea acestora către unul sau mai multe drenuri.
Vector este un înlocuitor pentru filebeat și logstash, poate acționa în ambele roluri (primire și trimite jurnale), mai multe detalii despre ele .
Dacă în Logstash lanțul este construit ca intrare → filtru → ieșire, atunci în Vector este → →
Exemple se găsesc în documentație.
Această instrucțiune este o instrucțiune revizuită de la . Instrucțiunile originale conțin procesarea geoip. La testarea geoip dintr-o rețea internă, vector a dat o eroare.
Aug 05 06:25:31.889 DEBUG transform{name=nginx_parse_rename_fields type=rename_fields}: vector::transforms::rename_fields: Field did not exist field=«geoip.country_name» rate_limit_secs=30Dacă cineva trebuie să proceseze geoip, atunci consultați instrucțiunile originale de la .
Vom configura combinația Nginx (Jurnalele de acces) → Vector (Client | Filebeat) → Vector (Server | Logstash) → separat în Clickhouse și separat în Elasticsearch. Vom instala 4 servere. Deși îl poți ocoli cu 3 servere.
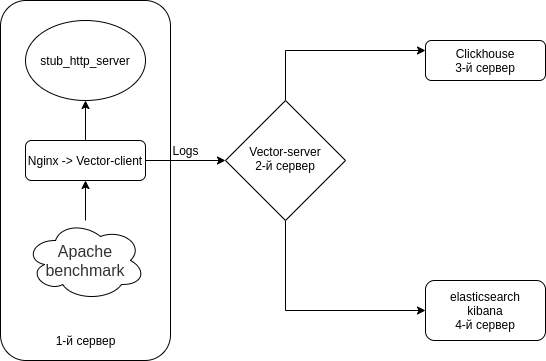
Schema este cam asa.
Dezactivează Selinux pe toate serverele tale
sed -i 's/^SELINUX=.*/SELINUX=disabled/g' /etc/selinux/config
rebootInstalăm un emulator de server HTTP + utilitare pe toate serverele
Vom folosi ca emulator de server HTTP din
Nodejs-stub-server nu are un rpm. creați rpm pentru el. rpm va fi construit folosind
Adăugați depozitul antonpatsev/nodejs-stub-server
yum -y install yum-plugin-copr epel-release
yes | yum copr enable antonpatsev/nodejs-stub-serverInstalați nodejs-stub-server, benchmark Apache și multiplexor de terminale de ecran pe toate serverele
yum -y install stub_http_server screen mc httpd-tools screenAm corectat timpul de răspuns stub_http_server în fișierul /var/lib/stub_http_server/stub_http_server.js, astfel încât să existe mai multe jurnale.
var max_sleep = 10;Să lansăm stub_http_server.
systemctl start stub_http_server
systemctl enable stub_http_serverpe serverul 3
ClickHouse utilizează setul de instrucțiuni SSE 4.2, așa că, dacă nu se specifică altfel, suportul pentru acesta în procesorul utilizat devine o cerință suplimentară de sistem. Iată comanda pentru a verifica dacă procesorul actual acceptă SSE 4.2:
grep -q sse4_2 /proc/cpuinfo && echo "SSE 4.2 supported" || echo "SSE 4.2 not supported"Mai întâi trebuie să conectați depozitul oficial:
sudo yum install -y yum-utils
sudo rpm --import https://repo.clickhouse.tech/CLICKHOUSE-KEY.GPG
sudo yum-config-manager --add-repo https://repo.clickhouse.tech/rpm/stable/x86_64Pentru a instala pachete trebuie să rulați următoarele comenzi:
sudo yum install -y clickhouse-server clickhouse-clientPermite clickhouse-server să asculte placa de rețea în fișierul /etc/clickhouse-server/config.xml
<listen_host>0.0.0.0</listen_host>Schimbarea nivelului de înregistrare de la urmărire la depanare
depana
Setări standard de compresie:
min_compress_block_size 65536
max_compress_block_size 1048576Pentru a activa compresia Zstd, a fost sfătuit să nu atingeți configurația, ci mai degrabă să utilizați DDL.
Nu am putut găsi cum să folosesc compresia zstd prin DDL în Google. Așa că l-am lăsat așa cum este.
Colegii care folosesc compresia zstd în Clickhouse, vă rugăm să împărtășiți instrucțiunile.
Pentru a porni serverul ca demon, rulați:
service clickhouse-server startAcum să trecem la configurarea Clickhouse
Du-te la Clickhouse
clickhouse-client -h 172.26.10.109 -m172.26.10.109 — IP-ul serverului pe care este instalat Clickhouse.
Să creăm o bază de date vectorială
CREATE DATABASE vector;Să verificăm dacă baza de date există.
show databases;Creați un tabel vector.logs.
/* Это таблица где хранятся логи как есть */
CREATE TABLE vector.logs
(
`node_name` String,
`timestamp` DateTime,
`server_name` String,
`user_id` String,
`request_full` String,
`request_user_agent` String,
`request_http_host` String,
`request_uri` String,
`request_scheme` String,
`request_method` String,
`request_length` UInt64,
`request_time` Float32,
`request_referrer` String,
`response_status` UInt16,
`response_body_bytes_sent` UInt64,
`response_content_type` String,
`remote_addr` IPv4,
`remote_port` UInt32,
`remote_user` String,
`upstream_addr` IPv4,
`upstream_port` UInt32,
`upstream_bytes_received` UInt64,
`upstream_bytes_sent` UInt64,
`upstream_cache_status` String,
`upstream_connect_time` Float32,
`upstream_header_time` Float32,
`upstream_response_length` UInt64,
`upstream_response_time` Float32,
`upstream_status` UInt16,
`upstream_content_type` String,
INDEX idx_http_host request_http_host TYPE set(0) GRANULARITY 1
)
ENGINE = MergeTree()
PARTITION BY toYYYYMMDD(timestamp)
ORDER BY timestamp
TTL timestamp + toIntervalMonth(1)
SETTINGS index_granularity = 8192;Verificăm dacă tabelele au fost create. Hai să lansăm clickhouse-client și faceți o cerere.
Să mergem la baza de date vectorială.
use vector;
Ok.
0 rows in set. Elapsed: 0.001 sec.Să ne uităm la tabele.
show tables;
┌─name────────────────┐
│ logs │
└─────────────────────┘Instalarea elasticsearch pe al 4-lea server pentru a trimite aceleași date către Elasticsearch pentru comparație cu Clickhouse
Adăugați o cheie publică rpm
rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearchSă creăm 2 depozite:
/etc/yum.repos.d/elasticsearch.repo
[elasticsearch]
name=Elasticsearch repository for 7.x packages
baseurl=https://artifacts.elastic.co/packages/7.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=0
autorefresh=1
type=rpm-md/etc/yum.repos.d/kibana.repo
[kibana-7.x]
name=Kibana repository for 7.x packages
baseurl=https://artifacts.elastic.co/packages/7.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=1
autorefresh=1
type=rpm-mdInstalați elasticsearch și kibana
yum install -y kibana elasticsearchDeoarece va fi într-o singură copie, trebuie să adăugați următoarele în fișierul /etc/elasticsearch/elasticsearch.yml:
discovery.type: single-nodePentru ca acel vector să poată trimite date către elasticsearch de pe alt server, să schimbăm network.host.
network.host: 0.0.0.0Pentru a vă conecta la kibana, modificați parametrul server.host în fișierul /etc/kibana/kibana.yml
server.host: "0.0.0.0"Vechi și includeți elasticsearch în autostart
systemctl enable elasticsearch
systemctl start elasticsearchși kibana
systemctl enable kibana
systemctl start kibanaConfigurarea Elasticsearch pentru modul cu un singur nod 1 fragment, 0 replică. Cel mai probabil veți avea un cluster cu un număr mare de servere și nu trebuie să faceți acest lucru.
Pentru indexuri viitoare, actualizați șablonul implicit:
curl -X PUT http://localhost:9200/_template/default -H 'Content-Type: application/json' -d '{"index_patterns": ["*"],"order": -1,"settings": {"number_of_shards": "1","number_of_replicas": "0"}}' Instalare ca înlocuitor pentru Logstash pe serverul 2
yum install -y https://packages.timber.io/vector/0.9.X/vector-x86_64.rpm mc httpd-tools screenSă setăm Vector ca înlocuitor pentru Logstash. Editarea fișierului /etc/vector/vector.toml
# /etc/vector/vector.toml
data_dir = "/var/lib/vector"
[sources.nginx_input_vector]
# General
type = "vector"
address = "0.0.0.0:9876"
shutdown_timeout_secs = 30
[transforms.nginx_parse_json]
inputs = [ "nginx_input_vector" ]
type = "json_parser"
[transforms.nginx_parse_add_defaults]
inputs = [ "nginx_parse_json" ]
type = "lua"
version = "2"
hooks.process = """
function (event, emit)
function split_first(s, delimiter)
result = {};
for match in (s..delimiter):gmatch("(.-)"..delimiter) do
table.insert(result, match);
end
return result[1];
end
function split_last(s, delimiter)
result = {};
for match in (s..delimiter):gmatch("(.-)"..delimiter) do
table.insert(result, match);
end
return result[#result];
end
event.log.upstream_addr = split_first(split_last(event.log.upstream_addr, ', '), ':')
event.log.upstream_bytes_received = split_last(event.log.upstream_bytes_received, ', ')
event.log.upstream_bytes_sent = split_last(event.log.upstream_bytes_sent, ', ')
event.log.upstream_connect_time = split_last(event.log.upstream_connect_time, ', ')
event.log.upstream_header_time = split_last(event.log.upstream_header_time, ', ')
event.log.upstream_response_length = split_last(event.log.upstream_response_length, ', ')
event.log.upstream_response_time = split_last(event.log.upstream_response_time, ', ')
event.log.upstream_status = split_last(event.log.upstream_status, ', ')
if event.log.upstream_addr == "" then
event.log.upstream_addr = "127.0.0.1"
end
if (event.log.upstream_bytes_received == "-" or event.log.upstream_bytes_received == "") then
event.log.upstream_bytes_received = "0"
end
if (event.log.upstream_bytes_sent == "-" or event.log.upstream_bytes_sent == "") then
event.log.upstream_bytes_sent = "0"
end
if event.log.upstream_cache_status == "" then
event.log.upstream_cache_status = "DISABLED"
end
if (event.log.upstream_connect_time == "-" or event.log.upstream_connect_time == "") then
event.log.upstream_connect_time = "0"
end
if (event.log.upstream_header_time == "-" or event.log.upstream_header_time == "") then
event.log.upstream_header_time = "0"
end
if (event.log.upstream_response_length == "-" or event.log.upstream_response_length == "") then
event.log.upstream_response_length = "0"
end
if (event.log.upstream_response_time == "-" or event.log.upstream_response_time == "") then
event.log.upstream_response_time = "0"
end
if (event.log.upstream_status == "-" or event.log.upstream_status == "") then
event.log.upstream_status = "0"
end
emit(event)
end
"""
[transforms.nginx_parse_remove_fields]
inputs = [ "nginx_parse_add_defaults" ]
type = "remove_fields"
fields = ["data", "file", "host", "source_type"]
[transforms.nginx_parse_coercer]
type = "coercer"
inputs = ["nginx_parse_remove_fields"]
types.request_length = "int"
types.request_time = "float"
types.response_status = "int"
types.response_body_bytes_sent = "int"
types.remote_port = "int"
types.upstream_bytes_received = "int"
types.upstream_bytes_send = "int"
types.upstream_connect_time = "float"
types.upstream_header_time = "float"
types.upstream_response_length = "int"
types.upstream_response_time = "float"
types.upstream_status = "int"
types.timestamp = "timestamp"
[sinks.nginx_output_clickhouse]
inputs = ["nginx_parse_coercer"]
type = "clickhouse"
database = "vector"
healthcheck = true
host = "http://172.26.10.109:8123" # Адрес Clickhouse
table = "logs"
encoding.timestamp_format = "unix"
buffer.type = "disk"
buffer.max_size = 104900000
buffer.when_full = "block"
request.in_flight_limit = 20
[sinks.elasticsearch]
type = "elasticsearch"
inputs = ["nginx_parse_coercer"]
compression = "none"
healthcheck = true
# 172.26.10.116 - сервер где установен elasticsearch
host = "http://172.26.10.116:9200"
index = "vector-%Y-%m-%d"Puteți ajusta secțiunea transforms.nginx_parse_add_defaults.
Ca folosește aceste configurații pentru un CDN mic și pot exista mai multe valori în amonte_*
De exemplu:
"upstream_addr": "128.66.0.10:443, 128.66.0.11:443, 128.66.0.12:443"
"upstream_bytes_received": "-, -, 123"
"upstream_status": "502, 502, 200"Dacă aceasta nu este situația dvs., atunci această secțiune poate fi simplificată
Să creăm setări de serviciu pentru systemd /etc/systemd/system/vector.service
# /etc/systemd/system/vector.service
[Unit]
Description=Vector
After=network-online.target
Requires=network-online.target
[Service]
User=vector
Group=vector
ExecStart=/usr/bin/vector
ExecReload=/bin/kill -HUP $MAINPID
Restart=no
StandardOutput=syslog
StandardError=syslog
SyslogIdentifier=vector
[Install]
WantedBy=multi-user.targetDupă crearea tabelelor, puteți rula Vector
systemctl enable vector
systemctl start vectorJurnalele vectoriale pot fi vizualizate astfel:
journalctl -f -u vectorAr trebui să existe astfel de intrări în jurnale
INFO vector::topology::builder: Healthcheck: Passed.
INFO vector::topology::builder: Healthcheck: Passed.Pe client (server web) - primul server
Pe serverul cu nginx, trebuie să dezactivați ipv6, deoarece tabelul de jurnalele din clickhouse folosește câmpul upstream_addr IPv4, deoarece nu folosesc ipv6 în rețea. Dacă ipv6 nu este dezactivat, vor apărea erori:
DB::Exception: Invalid IPv4 value.: (while read the value of key upstream_addr)Poate cititorii, adăugați suport ipv6.
Creați fișierul /etc/sysctl.d/98-disable-ipv6.conf
net.ipv6.conf.all.disable_ipv6 = 1
net.ipv6.conf.default.disable_ipv6 = 1
net.ipv6.conf.lo.disable_ipv6 = 1Aplicarea setărilor
sysctl --systemSă instalăm nginx.
S-a adăugat fișierul de depozit nginx /etc/yum.repos.d/nginx.repo
[nginx-stable]
name=nginx stable repo
baseurl=http://nginx.org/packages/centos/$releasever/$basearch/
gpgcheck=1
enabled=1
gpgkey=https://nginx.org/keys/nginx_signing.key
module_hotfixes=trueInstalați pachetul nginx
yum install -y nginxMai întâi, trebuie să configuram formatul jurnalului în Nginx în fișierul /etc/nginx/nginx.conf
user nginx;
# you must set worker processes based on your CPU cores, nginx does not benefit from setting more than that
worker_processes auto; #some last versions calculate it automatically
# number of file descriptors used for nginx
# the limit for the maximum FDs on the server is usually set by the OS.
# if you don't set FD's then OS settings will be used which is by default 2000
worker_rlimit_nofile 100000;
error_log /var/log/nginx/error.log warn;
pid /var/run/nginx.pid;
# provides the configuration file context in which the directives that affect connection processing are specified.
events {
# determines how much clients will be served per worker
# max clients = worker_connections * worker_processes
# max clients is also limited by the number of socket connections available on the system (~64k)
worker_connections 4000;
# optimized to serve many clients with each thread, essential for linux -- for testing environment
use epoll;
# accept as many connections as possible, may flood worker connections if set too low -- for testing environment
multi_accept on;
}
http {
include /etc/nginx/mime.types;
default_type application/octet-stream;
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
log_format vector escape=json
'{'
'"node_name":"nginx-vector",'
'"timestamp":"$time_iso8601",'
'"server_name":"$server_name",'
'"request_full": "$request",'
'"request_user_agent":"$http_user_agent",'
'"request_http_host":"$http_host",'
'"request_uri":"$request_uri",'
'"request_scheme": "$scheme",'
'"request_method":"$request_method",'
'"request_length":"$request_length",'
'"request_time": "$request_time",'
'"request_referrer":"$http_referer",'
'"response_status": "$status",'
'"response_body_bytes_sent":"$body_bytes_sent",'
'"response_content_type":"$sent_http_content_type",'
'"remote_addr": "$remote_addr",'
'"remote_port": "$remote_port",'
'"remote_user": "$remote_user",'
'"upstream_addr": "$upstream_addr",'
'"upstream_bytes_received": "$upstream_bytes_received",'
'"upstream_bytes_sent": "$upstream_bytes_sent",'
'"upstream_cache_status":"$upstream_cache_status",'
'"upstream_connect_time":"$upstream_connect_time",'
'"upstream_header_time":"$upstream_header_time",'
'"upstream_response_length":"$upstream_response_length",'
'"upstream_response_time":"$upstream_response_time",'
'"upstream_status": "$upstream_status",'
'"upstream_content_type":"$upstream_http_content_type"'
'}';
access_log /var/log/nginx/access.log main;
access_log /var/log/nginx/access.json.log vector; # Новый лог в формате json
sendfile on;
#tcp_nopush on;
keepalive_timeout 65;
#gzip on;
include /etc/nginx/conf.d/*.conf;
}Pentru a nu rupe configurația actuală, Nginx vă permite să aveți mai multe directive access_log
access_log /var/log/nginx/access.log main; # Стандартный лог
access_log /var/log/nginx/access.json.log vector; # Новый лог в формате jsonNu uitați să adăugați o regulă la logrotate pentru jurnalele noi (dacă fișierul jurnal nu se termină cu .log)
Eliminați default.conf din /etc/nginx/conf.d/
rm -f /etc/nginx/conf.d/default.confAdăugați gazda virtuală /etc/nginx/conf.d/vhost1.conf
server {
listen 80;
server_name vhost1;
location / {
proxy_pass http://172.26.10.106:8080;
}
}Adăugați gazda virtuală /etc/nginx/conf.d/vhost2.conf
server {
listen 80;
server_name vhost2;
location / {
proxy_pass http://172.26.10.108:8080;
}
}Adăugați gazda virtuală /etc/nginx/conf.d/vhost3.conf
server {
listen 80;
server_name vhost3;
location / {
proxy_pass http://172.26.10.109:8080;
}
}Adăugați gazda virtuală /etc/nginx/conf.d/vhost4.conf
server {
listen 80;
server_name vhost4;
location / {
proxy_pass http://172.26.10.116:8080;
}
}Adăugați gazde virtuale (172.26.10.106 ip al serverului unde este instalat nginx) la toate serverele în fișierul /etc/hosts:
172.26.10.106 vhost1
172.26.10.106 vhost2
172.26.10.106 vhost3
172.26.10.106 vhost4Și dacă totul este gata atunci
nginx -t
systemctl restart nginxAcum să-l instalăm singuri
yum install -y https://packages.timber.io/vector/0.9.X/vector-x86_64.rpmSă creăm un fișier de setări pentru systemd /etc/systemd/system/vector.service
[Unit]
Description=Vector
After=network-online.target
Requires=network-online.target
[Service]
User=vector
Group=vector
ExecStart=/usr/bin/vector
ExecReload=/bin/kill -HUP $MAINPID
Restart=no
StandardOutput=syslog
StandardError=syslog
SyslogIdentifier=vector
[Install]
WantedBy=multi-user.targetȘi configurați înlocuirea Filebeat în configurația /etc/vector/vector.toml. Adresa IP 172.26.10.108 este adresa IP a serverului de jurnal (Vector-Server)
data_dir = "/var/lib/vector"
[sources.nginx_file]
type = "file"
include = [ "/var/log/nginx/access.json.log" ]
start_at_beginning = false
fingerprinting.strategy = "device_and_inode"
[sinks.nginx_output_vector]
type = "vector"
inputs = [ "nginx_file" ]
address = "172.26.10.108:9876"Nu uitați să adăugați vectorul utilizatorului la grupul corespunzător, astfel încât să poată citi fișierele jurnal. De exemplu, nginx în centos creează jurnale cu drepturi de grup adm.
usermod -a -G adm vectorSă începem serviciul vectorial
systemctl enable vector
systemctl start vectorJurnalele vectoriale pot fi vizualizate astfel:
journalctl -f -u vectorAr trebui să existe o intrare ca aceasta în jurnale
INFO vector::topology::builder: Healthcheck: Passed.Testare stresanta
Testarea este efectuată folosind benchmark Apache.
Pachetul httpd-tools a fost instalat pe toate serverele
Începem testarea folosind benchmark Apache de la 4 servere diferite de pe ecran. Mai întâi, lansăm multiplexorul terminalului de ecran și apoi începem să testăm folosind benchmark-ul Apache. Cum să lucrați cu ecranul pe care îl puteți găsi în .
De la primul server
while true; do ab -H "User-Agent: 1server" -c 100 -n 10 -t 10 http://vhost1/; sleep 1; doneDe la primul server
while true; do ab -H "User-Agent: 2server" -c 100 -n 10 -t 10 http://vhost2/; sleep 1; doneDe la primul server
while true; do ab -H "User-Agent: 3server" -c 100 -n 10 -t 10 http://vhost3/; sleep 1; doneDe la primul server
while true; do ab -H "User-Agent: 4server" -c 100 -n 10 -t 10 http://vhost4/; sleep 1; doneSă verificăm datele din Clickhouse
Du-te la Clickhouse
clickhouse-client -h 172.26.10.109 -mEfectuarea unei interogări SQL
SELECT * FROM vector.logs;
┌─node_name────┬───────────timestamp─┬─server_name─┬─user_id─┬─request_full───┬─request_user_agent─┬─request_http_host─┬─request_uri─┬─request_scheme─┬─request_method─┬─request_length─┬─request_time─┬─request_referrer─┬─response_status─┬─response_body_bytes_sent─┬─response_content_type─┬───remote_addr─┬─remote_port─┬─remote_user─┬─upstream_addr─┬─upstream_port─┬─upstream_bytes_received─┬─upstream_bytes_sent─┬─upstream_cache_status─┬─upstream_connect_time─┬─upstream_header_time─┬─upstream_response_length─┬─upstream_response_time─┬─upstream_status─┬─upstream_content_type─┐
│ nginx-vector │ 2020-08-07 04:32:42 │ vhost1 │ │ GET / HTTP/1.0 │ 1server │ vhost1 │ / │ http │ GET │ 66 │ 0.028 │ │ 404 │ 27 │ │ 172.26.10.106 │ 45886 │ │ 172.26.10.106 │ 0 │ 109 │ 97 │ DISABLED │ 0 │ 0.025 │ 27 │ 0.029 │ 404 │ │
└──────────────┴─────────────────────┴─────────────┴─────────┴────────────────┴────────────────────┴───────────────────┴─────────────┴────────────────┴────────────────┴────────────────┴──────────────┴──────────────────┴─────────────────┴──────────────────────────┴───────────────────────┴───────────────┴─────────────┴─────────────┴───────────────┴───────────────┴─────────────────────────┴─────────────────────┴───────────────────────┴───────────────────────┴──────────────────────┴──────────────────────────┴────────────────────────┴─────────────────┴───────────────────────Aflați dimensiunea meselor în Clickhouse
select concat(database, '.', table) as table,
formatReadableSize(sum(bytes)) as size,
sum(rows) as rows,
max(modification_time) as latest_modification,
sum(bytes) as bytes_size,
any(engine) as engine,
formatReadableSize(sum(primary_key_bytes_in_memory)) as primary_keys_size
from system.parts
where active
group by database, table
order by bytes_size desc;Să aflăm câte bușteni au ocupat în Clickhouse.
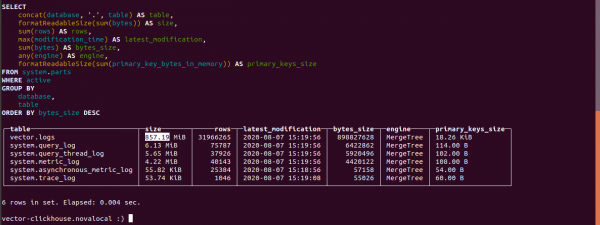
Dimensiunea tabelului de jurnal este de 857.19 MB.
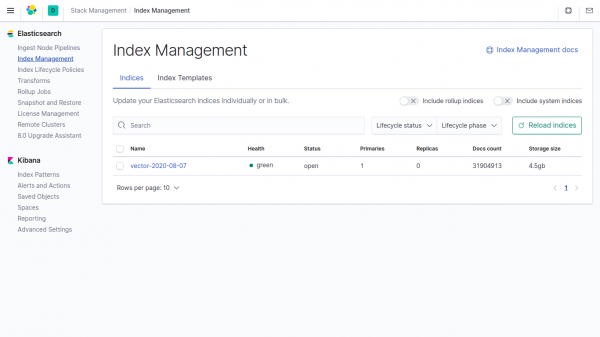
Dimensiunea acelorași date din indexul din Elasticsearch este de 4,5 GB.
Dacă nu specificați date în vector în parametri, Clickhouse ia 4500/857.19 = 5.24 ori mai puțin decât în Elasticsearch.
În vector, câmpul de compresie este utilizat implicit.
Chat Telegram de către
Chat Telegram de către
Chat Telegram de la „"
Sursa: www.habr.com
