

Să reamintim că Elastic Stack se bazează pe baza de date non-relațională Elasticsearch, interfața web Kibana și colectori și procesoare de date (cel mai faimos Logstash, diverse Beats, APM și altele). Una dintre completările frumoase la întregul pachet de produse listate este analiza datelor folosind algoritmi de învățare automată. În articol înțelegem care sunt acești algoritmi. Te rog sub cat.
Învățarea automată este o caracteristică plătită a shareware-ului Elastic Stack și este inclusă în X-Pack. Pentru a începe să-l utilizați, trebuie doar să activați perioada de încercare de 30 de zile după instalare. După expirarea perioadei de probă, puteți solicita asistență pentru a o prelungi sau pentru a cumpăra un abonament. Costul unui abonament este calculat nu în funcție de volumul de date, ci de numărul de noduri utilizate. Nu, volumul de date, desigur, afectează numărul de noduri necesare, dar totuși această abordare a licențierii este mai umană în raport cu bugetul companiei. Dacă nu este nevoie de productivitate ridicată, puteți economisi bani.
ML în Elastic Stack este scris în C++ și rulează în afara JVM-ului, în care rulează Elasticsearch însuși. Adică, procesul (apropo, se numește autodetect) consumă tot ceea ce JVM-ul nu înghite. Pe un stand demonstrativ, acest lucru nu este atât de critic, dar într-un mediu de producție este important să se aloce noduri separate pentru sarcinile ML.
Algoritmii de învățare automată se împart în două categorii - и . În Elastic Stack, algoritmul se află în categoria „nesupravegheat”. De Puteți vedea aparatul matematic al algoritmilor de învățare automată.
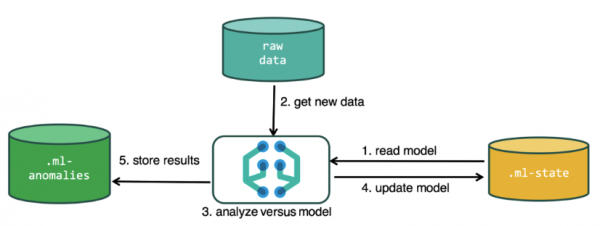
Pentru a efectua analiza, algoritmul de învățare automată folosește datele stocate în indecșii Elasticsearch. Puteți crea sarcini pentru analiză atât din interfața Kibana, cât și prin API. Dacă faci asta prin Kibana, atunci nu trebuie să știi unele lucruri. De exemplu, indecși suplimentari pe care algoritmul îi folosește în timpul funcționării sale.
Indici suplimentari utilizați în procesul de analiză.ml-state — informații despre modelele statistice (setări de analiză);
.ml-anomalies-* — rezultate ale algoritmilor ML;
.ml-notifications — setări pentru notificări bazate pe rezultatele analizei.
Structura de date din baza de date Elasticsearch constă din indecși și documente stocate în acestea. În comparație cu o bază de date relațională, un index poate fi comparat cu o schemă de bază de date, iar un document cu o înregistrare dintr-un tabel. Această comparație este condiționată și este oferită pentru a simplifica înțelegerea altor materiale pentru cei care au auzit doar despre Elasticsearch.
Aceeași funcționalitate este disponibilă prin API ca și prin interfața web, așa că pentru claritate și înțelegere a conceptelor, vom arăta cum să o configurați prin Kibana. În meniul din stânga există o secțiune Machine Learning unde puteți crea un nou job. În interfața Kibana arată ca imaginea de mai jos. Acum vom analiza fiecare tip de sarcină și vom arăta tipurile de analiză care pot fi construite aici.
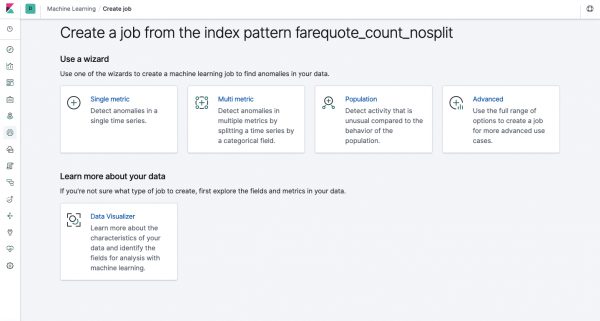
Single Metric - analiza unei valori, Multi Metric - analiza a două sau mai multe valori. În ambele cazuri, fiecare metrică este analizată într-un mediu izolat, de ex. algoritmul nu ia în considerare comportamentul metricilor analizate în paralel, așa cum ar putea părea în cazul Multi Metric. Pentru a efectua calcule ținând cont de corelarea diferitelor metrici, puteți utiliza Analiza populației. Și Advanced ajustează algoritmii cu opțiuni suplimentare pentru anumite sarcini.
Unică metrică
Analizarea modificărilor într-o singură valoare este cel mai simplu lucru care se poate face aici. După ce faceți clic pe Creare job, algoritmul va căuta anomalii.
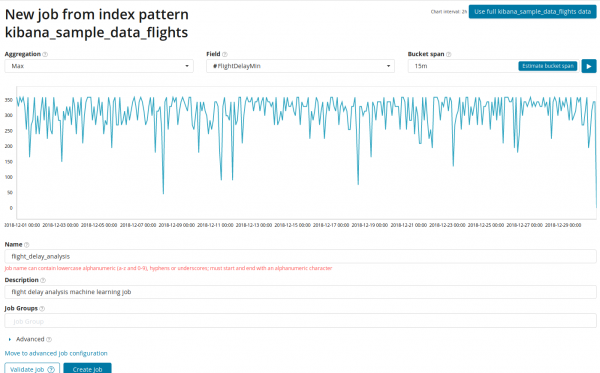
În domeniul agregare puteți alege o abordare pentru căutarea anomaliilor. De exemplu, când Min valorile sub valorile tipice vor fi considerate anormale. Mânca Max, mare medie, scăzută, medie, distinct si altii. Pot fi găsite descrieri ale tuturor funcțiilor .
În domeniul Câmp indică câmpul numeric din document pe care vom efectua analiza.
În domeniul — granularitatea intervalelor pe linia temporală de-a lungul căreia va fi efectuată analiza. Puteți avea încredere în automatizare sau puteți alege manual. Imaginea de mai jos este un exemplu de granularitate prea scăzută - este posibil să ratați anomalia. Folosind această setare, puteți modifica sensibilitatea algoritmului la anomalii.
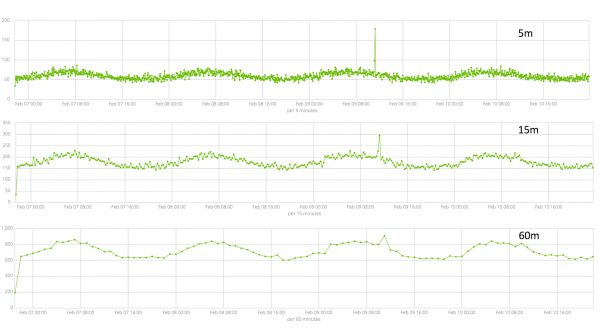
Durata datelor colectate este un lucru cheie care afectează eficacitatea analizei. În timpul analizei, algoritmul identifică intervalele repetate, calculează intervalele de încredere (linii de bază) și identifică anomalii - abateri atipice de la comportamentul obișnuit al metricii. Doar de exemplu:
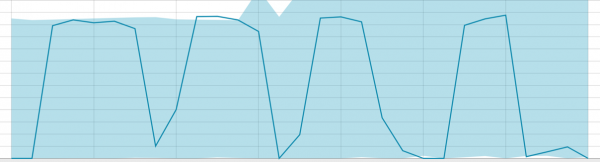
Linii de bază cu o mică parte de date:
Când algoritmul are ceva de învățat, linia de bază arată astfel:
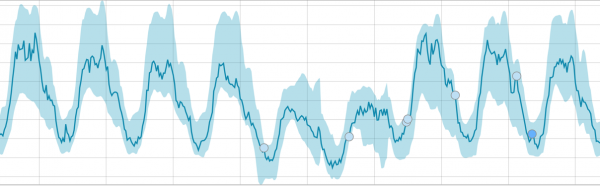
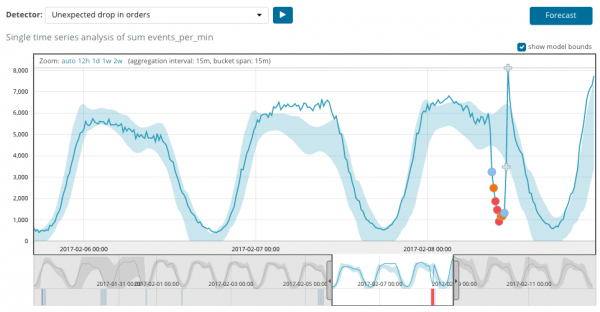
După începerea sarcinii, algoritmul determină abateri anormale de la normă și le ierarhizează în funcție de probabilitatea unei anomalii (culoarea etichetei corespunzătoare este indicată în paranteze):
Avertisment (albastru): mai puțin de 25
Minor (galben): 25-50
Major (portocaliu): 50-75
Critic (roșu): 75-100
Graficul de mai jos prezintă un exemplu de anomalii găsite.
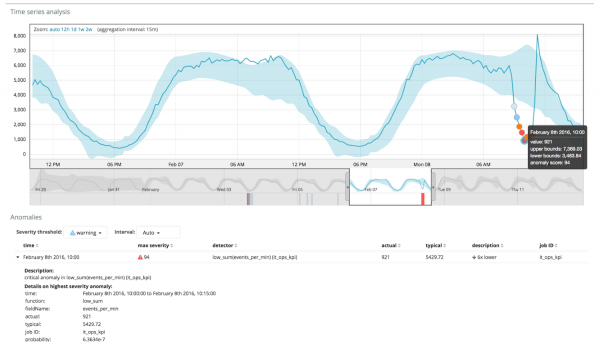
Aici puteți vedea numărul 94, care indică probabilitatea unei anomalii. Este clar că, din moment ce valoarea este aproape de 100, înseamnă că avem o anomalie. Coloana de sub grafic arată probabilitatea peiorativ de mică ca 0.000063634% din valoarea metricii să apară acolo.
Pe lângă căutarea anomaliilor, puteți rula prognoza în Kibana. Acest lucru se face simplu și din aceeași vedere cu anomalii - buton Prognoză în colțul din dreapta sus.
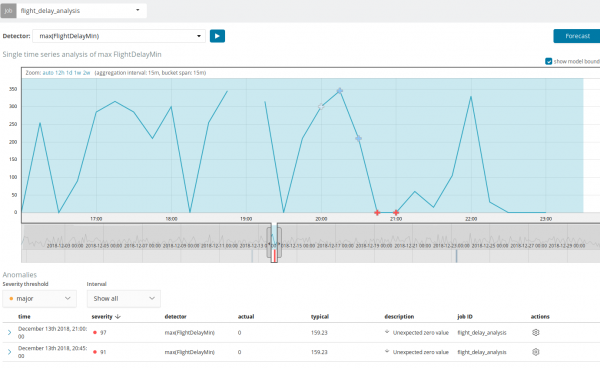
Prognoza se face cu maxim 8 saptamani inainte. Chiar dacă vrei cu adevărat, nu mai este posibil prin design.
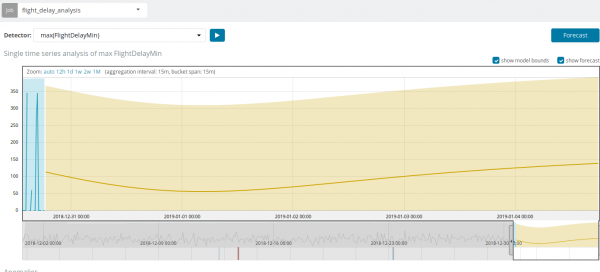
În unele situații, prognoza va fi foarte utilă, de exemplu, atunci când se monitorizează încărcarea utilizatorilor pe infrastructură.
Multimetrică
Să trecem la următoarea caracteristică ML din Elastic Stack - analizând mai multe valori într-un singur lot. Dar asta nu înseamnă că dependența unei metrici de alta va fi analizată. Este la fel ca o singură măsură, dar cu mai multe valori pe un ecran pentru o comparație ușoară a impactului uneia asupra altuia. Vom vorbi despre analiza dependenței unei valori față de alta în secțiunea Populație.
După ce faceți clic pe pătratul cu Multi Metric, va apărea o fereastră cu setări. Să le privim mai detaliat.
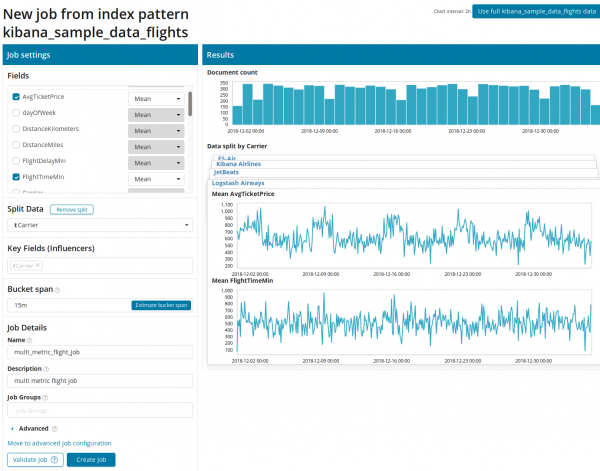
Mai întâi trebuie să selectați câmpurile pentru analiză și agregarea datelor pe acestea. Opțiunile de agregare de aici sunt aceleași ca pentru Valoarea unică (Max, mare medie, scăzută, medie, distinct si altii). În plus, dacă se dorește, datele sunt împărțite într-unul dintre câmpuri (câmp Împărțiți datele). În exemplu, am făcut acest lucru pe câmp OriginAirportID. Observați că graficul de valori din dreapta este acum prezentat ca mai multe grafice.
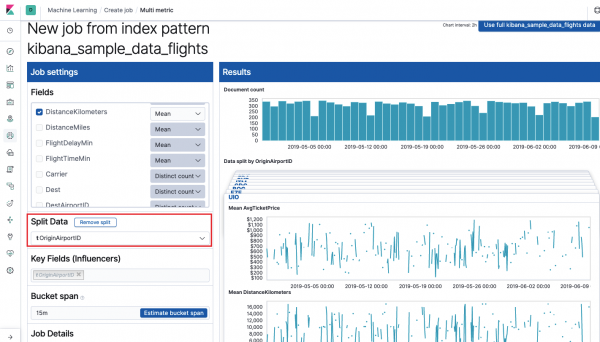
Câmp Domenii cheie (influentori) afectează direct anomaliile detectate. În mod implicit, va exista întotdeauna cel puțin o valoare aici și puteți adăuga altele suplimentare. Algoritmul va ține cont de influența acestor câmpuri atunci când va analiza și va arăta cele mai „influente” valori.
După lansare, ceva de genul acesta va apărea în interfața Kibana.
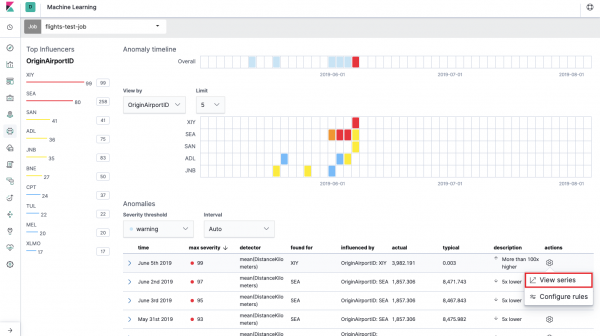
Acesta este așa-numitul harta termică a anomaliilor pentru fiecare valoare de câmp OriginAirportID, pe care l-am indicat în Împărțiți datele. Ca și în cazul Metricului unic, culoarea indică nivelul de abatere anormală. Este convenabil să faceți o analiză similară, de exemplu, pe stațiile de lucru pentru a urmări pe cei cu un număr suspect de mare de autorizații etc. Am scris deja , care poate fi adunat și analizat și aici.
Sub harta termică este o listă de anomalii, din fiecare puteți trece la vizualizarea Metric unic pentru o analiză detaliată.
populație
Pentru a căuta anomalii între corelațiile dintre diferitele valori, Elastic Stack are o analiză specializată a populației. Cu ajutorul acestuia puteți căuta valori anormale în performanța unui server în comparație cu altele atunci când, de exemplu, crește numărul de solicitări către sistemul țintă.
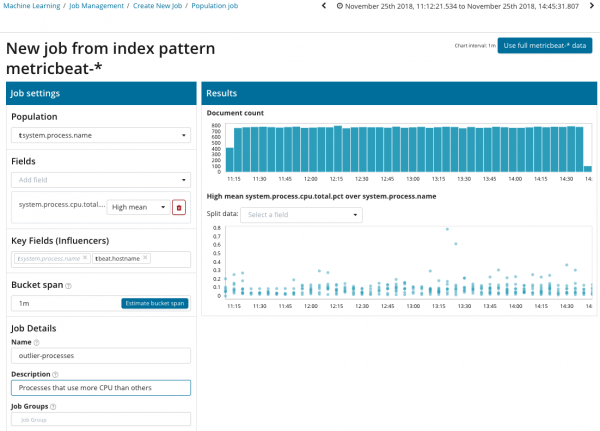
În această ilustrație, câmpul Populație indică valoarea la care se vor raporta valorile analizate. În acest caz, este numele procesului. Ca rezultat, vom vedea cum s-a influențat reciproc sarcina procesorului a fiecărui proces.
Vă rugăm să rețineți că graficul datelor analizate diferă de cazurile cu Single Metric și Multi Metric. Acest lucru a fost realizat în Kibana prin design pentru o percepție îmbunătățită a distribuției valorilor datelor analizate.
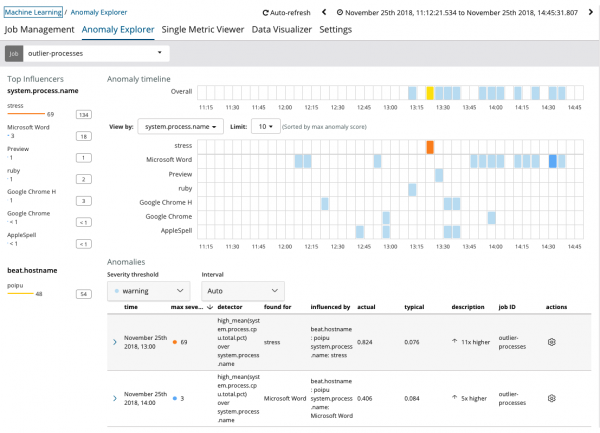
Graficul arată că procesul s-a comportat anormal stres (apropo, generat de un utilitar special) pe server poipu, care a influențat (sau s-a dovedit a fi un influencer) apariția acestei anomalii.
Avansat
Analytics cu reglaj fin. Cu analiza avansată, în Kibana apar setări suplimentare. După ce faceți clic pe tigla Avansat din meniul de creare, apare această fereastră cu file. Tab detalii job Am omis-o intenționat, există setări de bază care nu au legătură directă cu configurarea analizei.
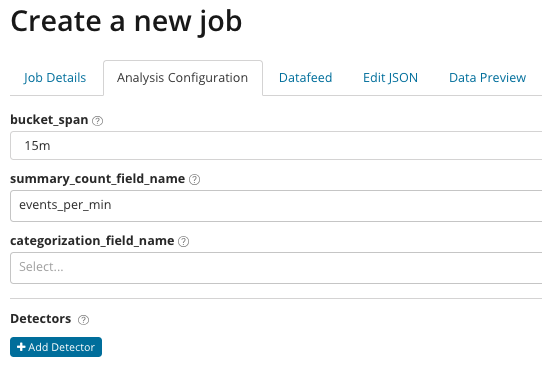
В summary_count_field_name Opțional, puteți specifica numele unui câmp din documentele care conțin valori agregate. În acest exemplu, numărul de evenimente pe minut. ÎN indică numele și valoarea unui câmp din document care conține o valoare variabilă. Folosind masca din acest câmp, puteți împărți datele analizate în subseturi. Acordați atenție butonului Adăugați detector în ilustrația anterioară. Mai jos este rezultatul clicului pe acest buton.
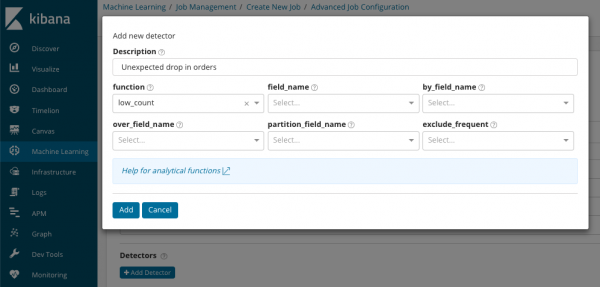
Iată un bloc suplimentar de setări pentru configurarea detectorului de anomalii pentru o anumită sarcină. Intenționăm să discutăm cazuri specifice de utilizare (în special cele de securitate) în articolele următoare. De exemplu, una dintre carcasele demontate. Este asociat cu căutarea valorilor care apar rar și este implementat .
În domeniul funcţie Puteți selecta o funcție specifică pentru a căuta anomalii. Cu exceptia rar, mai sunt câteva funcții interesante - . Ei identifică anomalii în comportamentul metricilor pe parcursul zilei sau, respectiv, pe parcursul săptămânii. Alte funcții de analiză .
В numele domeniului indică domeniul documentului pe care se va efectua analiza. După_nume_câmp poate fi folosit pentru a separa rezultatele analizei pentru fiecare valoare individuală a câmpului documentului specificat aici. Dacă umpleți over_field_name obțineți analiza populației despre care am discutat mai sus. Dacă specificați o valoare în nume_câmp_partiție, apoi pentru acest câmp al documentului se vor calcula linii de bază separate pentru fiecare valoare (valoarea poate fi, de exemplu, numele serverului sau al procesului de pe server). ÎN exclude_frecvent pot alege toate sau nici unul, ceea ce va însemna excluderea (sau includerea) valorilor câmpurilor de document care apar frecvent.
În acest articol, am încercat să dăm o idee cât mai succintă posibil despre capacitățile învățării automate din Elastic Stack; există încă o mulțime de detalii rămase în culise. Spune-ne în comentarii ce cazuri ai reușit să rezolvi folosind Elastic Stack și pentru ce sarcini îl folosești. Pentru a ne contacta, puteți folosi mesaje personale pe Habré sau .
Sursa: www.habr.com
