

Acum câteva luni - public la PostgreSQL.
L-ați folosit deja de peste 6000 de ori, dar o caracteristică la îndemână care poate să fi trecut neobservată este indicii structurale, care arată cam așa:
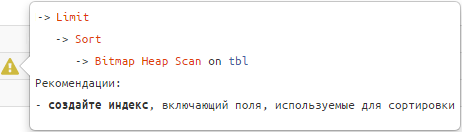
Ascultă-le și cererile tale vor „deveni netede și mătăsoase”. 🙂
Dar, serios, multe situații care fac o solicitare lentă și amantă de resurse sunt tipice și pot fi recunoscute după structura și datele planului.
În acest caz, fiecare dezvoltator individual nu trebuie să caute singur o opțiune de optimizare, bazându-se doar pe experiența sa - îi putem spune ce se întâmplă aici, care ar putea fi motivul și cum să abordezi o soluție. Asta am făcut.

Să aruncăm o privire mai atentă asupra acestor cazuri - cum sunt definite și la ce recomandări conduc.
Pentru a vă scufunda mai bine în subiect, puteți asculta mai întâi blocul corespunzător din , și abia apoi treceți la o analiză detaliată a fiecărui exemplu:

#1: indexul „subsortare”
Cand
Afișați cea mai recentă factură pentru clientul „LLC Kolokolchik”.
Cum să identifici
-> Limit
-> Sort
-> Index [Only] Scan [Backward] | Bitmap Heap Scan
Recomandări
Index folosit extindeți cu câmpuri de sortare.
Exemplu:
CREATE TABLE tbl AS
SELECT
generate_series(1, 100000) pk -- 100K "фактов"
, (random() * 1000)::integer fk_cli; -- 1K разных внешних ключей
CREATE INDEX ON tbl(fk_cli); -- индекс для foreign key
SELECT
*
FROM
tbl
WHERE
fk_cli = 1 -- отбор по конкретной связи
ORDER BY
pk DESC -- хотим всего одну "последнюю" запись
LIMIT 1; 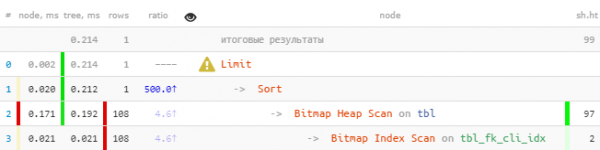
Puteți observa imediat că din index au fost scăzute peste 100 de înregistrări, care apoi au fost toate sortate, iar apoi a rămas singura.
Corectarea:
DROP INDEX tbl_fk_cli_idx;
CREATE INDEX ON tbl(fk_cli, pk DESC); -- добавили ключ сортировки

Chiar și pe o probă atât de primitivă - De 8.5 ori mai rapid și de 33 de ori mai puține citiri. Cu cât aveți mai multe „fapte” pentru fiecare valoare, cu atât efectul este mai evident fk.
Observ că un astfel de index va funcționa ca un index „prefix” nu mai rău decât înainte pentru alte interogări cu fk, unde sortați după pk nu a fost și nu există (puteți citi mai multe despre asta ). Inclusiv, va oferi normal suport explicit pentru chei externe pe acest domeniu.
#2: intersecție index (BitmapAnd)
Cand
Afișați toate acordurile pentru clientul „LLC Kolokolchik”, încheiate în numele „NAO Buttercup”.
Cum să identifici
-> BitmapAnd
-> Bitmap Index Scan
-> Bitmap Index ScanRecomandări
crea indice compozit prin câmpuri din ambele originale sau extinde unul dintre cele existente cu câmpuri din al doilea.
Exemplu:
CREATE TABLE tbl AS
SELECT
generate_series(1, 100000) pk -- 100K "фактов"
, (random() * 100)::integer fk_org -- 100 разных внешних ключей
, (random() * 1000)::integer fk_cli; -- 1K разных внешних ключей
CREATE INDEX ON tbl(fk_org); -- индекс для foreign key
CREATE INDEX ON tbl(fk_cli); -- индекс для foreign key
SELECT
*
FROM
tbl
WHERE
(fk_org, fk_cli) = (1, 999); -- отбор по конкретной паре 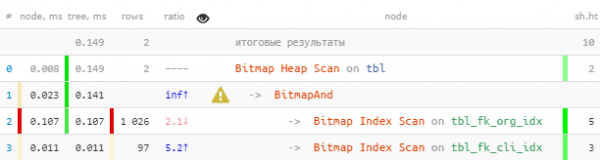
Corectarea:
DROP INDEX tbl_fk_org_idx;
CREATE INDEX ON tbl(fk_org, fk_cli);

Beneficiul aici este mai mic, deoarece Scanarea Bitmap Heap este destul de eficientă de la sine. Dar oricum De 7 ori mai rapid și de 2.5 de ori mai puține citiri.
#3: Îmbinați indici (BitmapOr)
Cand
Afișați primele 20 cele mai vechi „noi” sau solicitări nealocate pentru procesare, cu prioritate pe ale dvs.
Cum să identifici
-> BitmapOr
-> Bitmap Index Scan
-> Bitmap Index ScanRecomandări
Использовать UNIRE [TOATE] pentru a combina subinterogări pentru fiecare dintre blocurile SAU de condiții.
Exemplu:
CREATE TABLE tbl AS
SELECT
generate_series(1, 100000) pk -- 100K "фактов"
, CASE
WHEN random() < 1::real/16 THEN NULL -- с вероятностью 1:16 запись "ничья"
ELSE (random() * 100)::integer -- 100 разных внешних ключей
END fk_own;
CREATE INDEX ON tbl(fk_own, pk); -- индекс с "вроде как подходящей" сортировкой
SELECT
*
FROM
tbl
WHERE
fk_own = 1 OR -- свои
fk_own IS NULL -- ... или "ничьи"
ORDER BY
pk
, (fk_own = 1) DESC -- сначала "свои"
LIMIT 20;
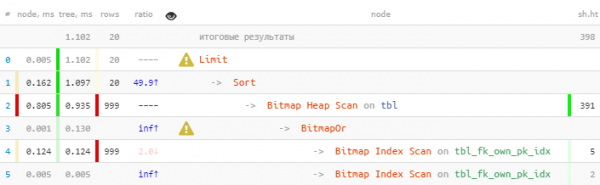
Corectarea:
(
SELECT
*
FROM
tbl
WHERE
fk_own = 1 -- сначала "свои" 20
ORDER BY
pk
LIMIT 20
)
UNION ALL
(
SELECT
*
FROM
tbl
WHERE
fk_own IS NULL -- потом "ничьи" 20
ORDER BY
pk
LIMIT 20
)
LIMIT 20; -- но всего - 20, больше и не надо 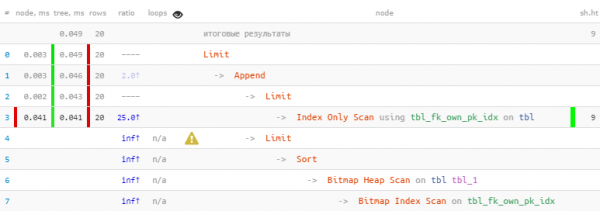
Am profitat de faptul că toate cele 20 de înregistrări necesare au fost primite imediat în primul bloc, așa că cel de-al doilea, cu mai „costisitor” Bitmap Heap Scan, nici măcar nu a fost executat - până la urmă De 22 de ori mai rapid, de 44 de ori mai puține citiri!
O poveste mai detaliată despre această metodă de optimizare folosind exemple specifice pot fi citite în articole и .
Varianta generalizata selecție ordonată pe baza mai multor chei (și nu doar perechea const/NULL) este discutată în articol .
#4: Citim o mulțime de lucruri inutile
Cand
De regulă, apare atunci când doriți să „atașați un alt filtru” unei cereri deja existente.
„Și tu nu ai același, dar cu nasturi de perle? " filmul „Brațul de diamant”
De exemplu, modificând sarcina de mai sus, afișați primele 20 de cereri „critice” cele mai vechi pentru procesare, indiferent de scopul lor.
Cum să identifici
-> Seq Scan | Bitmap Heap Scan | Index [Only] Scan [Backward]
&& 5 × rows < RRbF -- отфильтровано >80% прочитанного
&& loops × RRbF > 100 -- и при этом больше 100 записей суммарно
Recomandări
Creați [mai] specializate index cu condiția WHERE sau includeți câmpuri suplimentare în index.
Dacă starea filtrului este „static” pentru scopurile dvs. - adică nu presupune extindere listă de valori în viitor - este mai bine să utilizați un indice WHERE. Diverse stări boolean/enum se încadrează bine în această categorie.
Dacă starea de filtrare poate lua înțelesuri diferite, atunci este mai bine să extindeți indexul cu aceste câmpuri - ca în situația cu BitmapAnd de mai sus.
Exemplu:
CREATE TABLE tbl AS
SELECT
generate_series(1, 100000) pk -- 100K "фактов"
, CASE
WHEN random() < 1::real/16 THEN NULL
ELSE (random() * 100)::integer -- 100 разных внешних ключей
END fk_own
, (random() < 1::real/50) critical; -- 1:50, что заявка "критичная"
CREATE INDEX ON tbl(pk);
CREATE INDEX ON tbl(fk_own, pk);
SELECT
*
FROM
tbl
WHERE
critical
ORDER BY
pk
LIMIT 20; 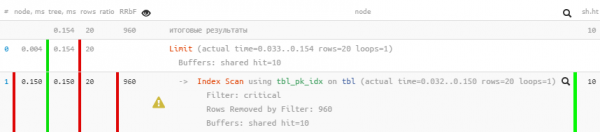
Corectarea:
CREATE INDEX ON tbl(pk)
WHERE critical; -- добавили "статичное" условие фильтрации

După cum puteți vedea, filtrarea a dispărut complet din plan, iar cererea a devenit de 5 ori mai rapid.
#5: masă rară
Cand
Diverse încercări de a crea propria coadă de procesare a sarcinilor, când un număr mare de actualizări/ștergeri de înregistrări de pe tabel duc la situația unui număr mare de înregistrări „moarte”.
Cum să identifici
-> Seq Scan | Bitmap Heap Scan | Index [Only] Scan [Backward]
&& loops × (rows + RRbF) < (shared hit + shared read) × 8
-- прочитано больше 1KB на каждую запись
&& shared hit + shared read > 64
Recomandări
Efectuați manual în mod regulat VACUUM [PLET] sau să realizeze un antrenament suficient de frecvent prin reglarea fină a parametrilor acestuia, inclusiv .
În cele mai multe cazuri, astfel de probleme sunt cauzate de compoziția slabă a interogărilor atunci când apelați din logica de afaceri, cum ar fi cele discutate în .
Dar trebuie să înțelegeți că chiar și VACUUM FULL poate să nu vă ajute întotdeauna. Pentru astfel de cazuri, merită să vă familiarizați cu algoritmul din articol .
#6: Citirea de la „mijlocul” indexului
Cand
Se pare că am citit puțin și totul a fost indexat și nu am filtrat pe nimeni în exces - dar totuși citim mult mai multe pagini decât ne-am dori.
Cum să identifici
-> Index [Only] Scan [Backward]
&& loops × (rows + RRbF) < (shared hit + shared read) × 8
-- прочитано больше 1KB на каждую запись
&& shared hit + shared read > 64
Recomandări
Aruncați o privire atentă asupra structurii indexului utilizat și a câmpurilor cheie specificate în interogare - cel mai probabil o parte a indexului nu este setată. Cel mai probabil va trebui să creați un index similar, dar fără câmpurile de prefix sau .
Exemplu:
CREATE TABLE tbl AS
SELECT
generate_series(1, 100000) pk -- 100K "фактов"
, (random() * 100)::integer fk_org -- 100 разных внешних ключей
, (random() * 1000)::integer fk_cli; -- 1K разных внешних ключей
CREATE INDEX ON tbl(fk_org, fk_cli); -- все почти как в #2
-- только вот отдельный индекс по fk_cli мы уже посчитали лишним и удалили
SELECT
*
FROM
tbl
WHERE
fk_cli = 999 -- а fk_org не задано, хотя стоит в индексе раньше
LIMIT 20; 
Totul pare să fie în regulă, chiar și conform indexului, dar este cumva suspect - pentru fiecare dintre cele 20 de înregistrări citite, a trebuit să scădem 4 pagini de date, 32 KB per înregistrare - nu este îndrăzneț? Și numele indexului tbl_fk_org_fk_cli_idx provocatoare de gândire.
Corectarea:
CREATE INDEX ON tbl(fk_cli); 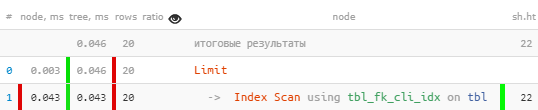
Brusc - De 10 ori mai rapid și de 4 ori mai puțin de citit!
Alte exemple de situații de utilizare ineficientă a indicilor pot fi văzute în articol .
#7: CTE × CTE
Cand
La cerere a marcat CTE „gras”. de la mese diferite și apoi a decis să o facă între ei JOIN.
Cazul este relevant pentru versiunile sub v12 sau solicitările cu WITH MATERIALIZED.
Cum să identifici
-> CTE Scan
&& loops > 10
&& loops × (rows + RRbF) > 10000
-- слишком большое декартово произведение CTE
Recomandări
Analizați cu atenție cererea - și ? Dacă da, atunci aplicați „dicționar” în hstore/json conform modelului descris în .
#8: schimb pe disc (temp scris)
Cand
Procesarea unică (sortarea sau unicizarea) a unui număr mare de înregistrări nu se încadrează în memoria alocată pentru aceasta.
Cum să identifici
-> *
&& temp written > 0Recomandări
Dacă cantitatea de memorie utilizată de operație nu depășește cu mult valoarea specificată a parametrului , merită corectat. Puteți accesa imediat configurația pentru toată lumea, sau puteți trece SET [LOCAL] pentru o anumită cerere/tranzacție.
Exemplu:
SHOW work_mem;
-- "16MB"
SELECT
random()
FROM
generate_series(1, 1000000)
ORDER BY
1; 
Corectarea:
SET work_mem = '128MB'; -- перед выполнением запроса 
Din motive evidente, dacă se folosește doar memoria și nu discul, atunci interogarea va fi executată mult mai rapid. În același timp, o parte din încărcarea de pe HDD este, de asemenea, eliminată.
Dar trebuie să înțelegeți că nu veți putea întotdeauna să alocați multă și multă memorie - pur și simplu nu va fi suficientă pentru toată lumea.
#9: statistici irelevante
Cand
Au turnat multe în baza de date deodată, dar nu au avut timp să o alunge ANALYZE.
Cum să identifici
-> Seq Scan | Bitmap Heap Scan | Index [Only] Scan [Backward]
&& ratio >> 10Recomandări
Realizați-o ANALYZE.
Această situație este descrisă mai detaliat în .
#10: „Ceva a mers prost”
Cand
A existat o așteptare pentru o blocare impusă de o solicitare concurentă sau au existat resurse hardware insuficiente pentru CPU/hypervisor.
Cum să identifici
-> *
&& (shared hit / 8K) + (shared read / 1K) < time / 1000
-- RAM hit = 64MB/s, HDD read = 8MB/s
&& time > 100ms -- читали мало, но слишком долго
Recomandări
Utilizați extern sistem de monitorizare server pentru blocarea sau consumul anormal de resurse. Am vorbit deja despre versiunea noastră de organizare a acestui proces pentru sute de servere и .
Sursa: www.habr.com
