

Articolul discută mai multe moduri de a determina ecuația matematică a unei linii de regresie simple (pereche).
Toate metodele de rezolvare a ecuației discutate aici se bazează pe metoda celor mai mici pătrate. Să notăm metodele după cum urmează:
- Soluție analitică
- Coborâre în gradient
- Coborarea gradientului stocastic
Pentru fiecare metodă de rezolvare a ecuației unei linii drepte, articolul oferă diverse funcții, care sunt împărțite în principal în cele care sunt scrise fără a utiliza biblioteca NumPy și cele care folosesc pentru calcule NumPy. Se crede că utilizarea pricepută NumPy va reduce costurile de calcul.
Tot codul dat în articol este scris în limba piton 2.7 folosind Jupiter Notebook. Codul sursă și fișierul cu date eșantion sunt postate pe
Articolul se adresează mai mult atât începătorilor, cât și celor care au început deja să stăpânească treptat studiul unei secțiuni foarte ample în inteligența artificială - învățarea automată.
Pentru a ilustra materialul, folosim un exemplu foarte simplu.
Condiții de exemplu
Avem cinci valori care caracterizează dependența Y din X (Tabelul nr. 1):
Tabelul nr. 1 „Condiții exemplu”

Vom presupune că valorile  este luna anului și
este luna anului și  - venituri luna aceasta. Cu alte cuvinte, veniturile depind de luna anului și
- venituri luna aceasta. Cu alte cuvinte, veniturile depind de luna anului și  - singurul semn de care depind veniturile.
- singurul semn de care depind veniturile.
Exemplul este așa și așa, atât din punctul de vedere al dependenței condiționate a veniturilor de luna anului, cât și din punctul de vedere al numărului de valori - sunt foarte puține. Cu toate acestea, o astfel de simplificare va face posibil, după cum se spune, să se explice, nu întotdeauna cu ușurință, materialul pe care îl asimilează începătorii. Și, de asemenea, simplitatea numerelor va permite celor care doresc să rezolve exemplul pe hârtie fără costuri semnificative ale forței de muncă.
Să presupunem că dependența dată în exemplu poate fi aproximată destul de bine prin ecuația matematică a unei linii de regresie simple (pereche) de forma:

unde  este luna în care a fost primit venitul,
este luna în care a fost primit venitul,  — veniturile aferente lunii,
— veniturile aferente lunii,  и
и  sunt coeficienții de regresie ai dreptei estimate.
sunt coeficienții de regresie ai dreptei estimate.
Rețineți că coeficientul  adesea numită panta sau gradientul liniei estimate; reprezintă suma cu care
adesea numită panta sau gradientul liniei estimate; reprezintă suma cu care  când se schimbă
când se schimbă  .
.
Evident, sarcina noastră din exemplu este să selectăm astfel de coeficienți în ecuație  и
и  , la care abaterile veniturilor noastre calculate valorează lunar de la răspunsurile adevărate, i.e. valorile prezentate în eșantion vor fi minime.
, la care abaterile veniturilor noastre calculate valorează lunar de la răspunsurile adevărate, i.e. valorile prezentate în eșantion vor fi minime.
Metoda celor mai mici pătrate
Conform metodei celor mai mici pătrate, abaterea trebuie calculată prin pătrat. Această tehnică vă permite să evitați anularea reciprocă a abaterilor dacă au semne opuse. De exemplu, dacă într-un caz, abaterea este +5 (plus cinci), iar în celălalt -5 (minus cinci), apoi suma abaterilor se va anula reciproc și se va ridica la 0 (zero). Este posibil să nu pătrați abaterea, ci să folosiți proprietatea modulului și atunci toate abaterile vor fi pozitive și se vor acumula. Nu ne vom opri în detaliu asupra acestui punct, ci pur și simplu indicăm că, pentru comoditatea calculelor, se obișnuiește să pătrați abaterea.
Așa arată formula cu care vom determina cea mai mică sumă a abaterilor pătrate (erori):

unde  este o funcție de aproximare a răspunsurilor adevărate (adică venitul pe care l-am calculat),
este o funcție de aproximare a răspunsurilor adevărate (adică venitul pe care l-am calculat),
 sunt răspunsurile adevărate (venituri furnizate în eșantion),
sunt răspunsurile adevărate (venituri furnizate în eșantion),
 este indicele eșantionului (numărul lunii în care este determinată abaterea)
este indicele eșantionului (numărul lunii în care este determinată abaterea)
Să diferențiem funcția, să definim ecuațiile diferențiale parțiale și să fim gata să trecem la soluția analitică. Dar mai întâi, să facem o scurtă excursie despre ce este diferențierea și să ne amintim semnificația geometrică a derivatei.
Diferenţiere
Diferențierea este operația de găsire a derivatei unei funcții.
La ce se folosește derivatul? Derivata unei functii caracterizeaza rata de schimbare a functiei si ne spune directia acesteia. Dacă derivata la un punct dat este pozitivă, atunci funcția crește, în caz contrar, funcția scade. Și cu cât valoarea derivatei absolute este mai mare, cu atât este mai mare rata de modificare a valorilor funcției, precum și cu atât mai abruptă panta graficului funcției.
De exemplu, în condițiile unui sistem de coordonate carteziene, valoarea derivatei în punctul M(0,0) este egală cu +25 înseamnă că la un punct dat, când valoarea este deplasată  la dreapta printr-o unitate convențională, valoare
la dreapta printr-o unitate convențională, valoare  crește cu 25 de unități convenționale. Pe grafic pare o creștere destul de abruptă a valorilor
crește cu 25 de unități convenționale. Pe grafic pare o creștere destul de abruptă a valorilor  dintr-un punct dat.
dintr-un punct dat.
Alt exemplu. Valoarea derivatei este egală -0,1 înseamnă că atunci când este deplasat  pe o unitate convențională, valoare
pe o unitate convențională, valoare  scade cu doar 0,1 unitate convențională. În același timp, pe graficul funcției, putem observa o pantă descendentă abia vizibilă. Făcând o analogie cu un munte, parcă coborâm foarte încet o pantă blândă dintr-un munte, spre deosebire de exemplul anterior, unde a trebuit să urcăm vârfuri foarte abrupte :)
scade cu doar 0,1 unitate convențională. În același timp, pe graficul funcției, putem observa o pantă descendentă abia vizibilă. Făcând o analogie cu un munte, parcă coborâm foarte încet o pantă blândă dintr-un munte, spre deosebire de exemplul anterior, unde a trebuit să urcăm vârfuri foarte abrupte :)
Astfel, după diferențierea funcției  prin cote
prin cote  и
и  , definim ecuații cu diferențe parțiale de ordinul 1. După determinarea ecuațiilor, vom primi un sistem de două ecuații, prin rezolvarea cărora vom putea selecta astfel de valori ale coeficienților
, definim ecuații cu diferențe parțiale de ordinul 1. După determinarea ecuațiilor, vom primi un sistem de două ecuații, prin rezolvarea cărora vom putea selecta astfel de valori ale coeficienților  и
и  , la care valorile derivatelor corespunzătoare în anumite puncte se modifică cu o cantitate foarte, foarte mică, iar în cazul unei soluții analitice nu se modifică deloc. Cu alte cuvinte, funcția de eroare la coeficienții găsiți va atinge un minim, deoarece valorile derivatelor parțiale în aceste puncte vor fi egale cu zero.
, la care valorile derivatelor corespunzătoare în anumite puncte se modifică cu o cantitate foarte, foarte mică, iar în cazul unei soluții analitice nu se modifică deloc. Cu alte cuvinte, funcția de eroare la coeficienții găsiți va atinge un minim, deoarece valorile derivatelor parțiale în aceste puncte vor fi egale cu zero.
Deci, conform regulilor de diferențiere, ecuația cu derivate parțiale de ordinul I în raport cu coeficientul  va lua forma:
va lua forma:

Ecuație cu derivate parțiale de ordinul 1 în raport cu  va lua forma:
va lua forma:

Ca rezultat, am primit un sistem de ecuații care are o soluție analitică destul de simplă:
începe{ecuația*}
începe{cazuri}
na + bsumlimits_{i=1}^nx_i — sumlimits_{i=1}^ny_i = 0
sumlimits_{i=1}^nx_i(a +bsumlimits_{i=1}^nx_i — sumlimits_{i=1}^ny_i) = 0
sfârșit{cazuri}
sfârșit{ecuația*}
Înainte de a rezolva ecuația, să preîncărcăm, să verificăm dacă încărcarea este corectă și să formatăm datele.
Încărcarea și formatarea datelor
Trebuie remarcat faptul că, datorită faptului că pentru soluția analitică, și ulterior pentru coborârea gradientului și gradientului stocastic, vom folosi codul în două variante: folosind biblioteca NumPy și fără a-l folosi, atunci vom avea nevoie de formatarea adecvată a datelor (vezi cod).
Cod de încărcare și procesare a datelor
# импортируем все нужные нам библиотеки
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import math
import pylab as pl
import random
# графики отобразим в Jupyter
%matplotlib inline
# укажем размер графиков
from pylab import rcParams
rcParams['figure.figsize'] = 12, 6
# отключим предупреждения Anaconda
import warnings
warnings.simplefilter('ignore')
# загрузим значения
table_zero = pd.read_csv('data_example.txt', header=0, sep='t')
# посмотрим информацию о таблице и на саму таблицу
print table_zero.info()
print '********************************************'
print table_zero
print '********************************************'
# подготовим данные без использования NumPy
x_us = []
[x_us.append(float(i)) for i in table_zero['x']]
print x_us
print type(x_us)
print '********************************************'
y_us = []
[y_us.append(float(i)) for i in table_zero['y']]
print y_us
print type(y_us)
print '********************************************'
# подготовим данные с использованием NumPy
x_np = table_zero[['x']].values
print x_np
print type(x_np)
print x_np.shape
print '********************************************'
y_np = table_zero[['y']].values
print y_np
print type(y_np)
print y_np.shape
print '********************************************'Vizualizare
Acum, după ce, în primul rând, am încărcat datele, în al doilea rând, am verificat corectitudinea încărcării și în final am formatat datele, vom efectua prima vizualizare. Metoda folosită des pentru aceasta este pereche bibliotecă SEABORN. În exemplul nostru, din cauza numărului limitat, nu are rost să folosiți biblioteca SEABORN. Vom folosi biblioteca obișnuită matplotlib și uită-te doar la graficul de dispersie.
Cod Scatterplot
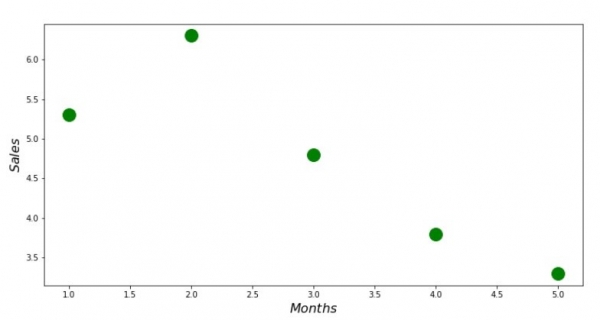
print 'График №1 "Зависимость выручки от месяца года"'
plt.plot(x_us,y_us,'o',color='green',markersize=16)
plt.xlabel('$Months$', size=16)
plt.ylabel('$Sales$', size=16)
plt.show()Graficul nr. 1 „Dependența veniturilor de luna anului”
Soluție analitică
Să folosim cele mai comune instrumente în piton și rezolvați sistemul de ecuații:
începe{ecuația*}
începe{cazuri}
na + bsumlimits_{i=1}^nx_i — sumlimits_{i=1}^ny_i = 0
sumlimits_{i=1}^nx_i(a +bsumlimits_{i=1}^nx_i — sumlimits_{i=1}^ny_i) = 0
sfârșit{cazuri}
sfârșit{ecuația*}
După regula lui Cramer vom găsi determinantul general, precum și determinanții prin  și
și  , după care, împărțind determinantul la
, după care, împărțind determinantul la  la determinantul general - găsiți coeficientul
la determinantul general - găsiți coeficientul  , în mod similar găsim coeficientul
, în mod similar găsim coeficientul  .
.
Cod soluție analitică
# определим функцию для расчета коэффициентов a и b по правилу Крамера
def Kramer_method (x,y):
# сумма значений (все месяца)
sx = sum(x)
# сумма истинных ответов (выручка за весь период)
sy = sum(y)
# сумма произведения значений на истинные ответы
list_xy = []
[list_xy.append(x[i]*y[i]) for i in range(len(x))]
sxy = sum(list_xy)
# сумма квадратов значений
list_x_sq = []
[list_x_sq.append(x[i]**2) for i in range(len(x))]
sx_sq = sum(list_x_sq)
# количество значений
n = len(x)
# общий определитель
det = sx_sq*n - sx*sx
# определитель по a
det_a = sx_sq*sy - sx*sxy
# искомый параметр a
a = (det_a / det)
# определитель по b
det_b = sxy*n - sy*sx
# искомый параметр b
b = (det_b / det)
# контрольные значения (прооверка)
check1 = (n*b + a*sx - sy)
check2 = (b*sx + a*sx_sq - sxy)
return [round(a,4), round(b,4)]
# запустим функцию и запишем правильные ответы
ab_us = Kramer_method(x_us,y_us)
a_us = ab_us[0]
b_us = ab_us[1]
print ' 33[1m' + ' 33[4m' + "Оптимальные значения коэффициентов a и b:" + ' 33[0m'
print 'a =', a_us
print 'b =', b_us
print
# определим функцию для подсчета суммы квадратов ошибок
def errors_sq_Kramer_method(answers,x,y):
list_errors_sq = []
for i in range(len(x)):
err = (answers[0] + answers[1]*x[i] - y[i])**2
list_errors_sq.append(err)
return sum(list_errors_sq)
# запустим функцию и запишем значение ошибки
error_sq = errors_sq_Kramer_method(ab_us,x_us,y_us)
print ' 33[1m' + ' 33[4m' + "Сумма квадратов отклонений" + ' 33[0m'
print error_sq
print
# замерим время расчета
# print ' 33[1m' + ' 33[4m' + "Время выполнения расчета суммы квадратов отклонений:" + ' 33[0m'
# % timeit error_sq = errors_sq_Kramer_method(ab,x_us,y_us)Iată ce avem:

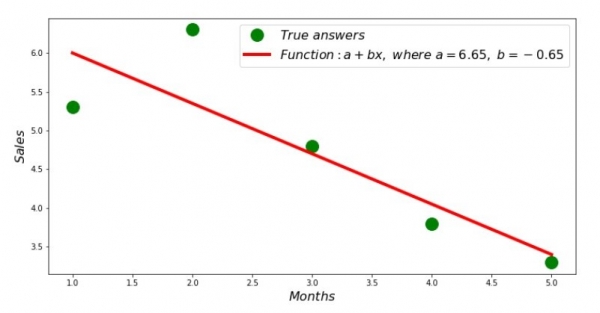
Deci, s-au găsit valorile coeficienților, s-a stabilit suma abaterilor pătrate. Să trasăm o linie dreaptă pe histograma de împrăștiere în conformitate cu coeficienții găsiți.
Codul liniei de regresie
# определим функцию для формирования массива рассчетных значений выручки
def sales_count(ab,x,y):
line_answers = []
[line_answers.append(ab[0]+ab[1]*x[i]) for i in range(len(x))]
return line_answers
# построим графики
print 'Грфик№2 "Правильные и расчетные ответы"'
plt.plot(x_us,y_us,'o',color='green',markersize=16, label = '$True$ $answers$')
plt.plot(x_us, sales_count(ab_us,x_us,y_us), color='red',lw=4,
label='$Function: a + bx,$ $where$ $a='+str(round(ab_us[0],2))+',$ $b='+str(round(ab_us[1],2))+'$')
plt.xlabel('$Months$', size=16)
plt.ylabel('$Sales$', size=16)
plt.legend(loc=1, prop={'size': 16})
plt.show()Graficul nr. 2 „Răspunsuri corecte și calculate”
Puteți să vă uitați la graficul de abatere pentru fiecare lună. În cazul nostru, nu vom obține nicio valoare practică semnificativă din aceasta, dar ne vom satisface curiozitatea cu privire la cât de bine caracterizează ecuația de regresie liniară simplă dependența veniturilor de luna anului.
Cod grafic de abateri
# определим функцию для формирования массива отклонений в процентах
def error_per_month(ab,x,y):
sales_c = sales_count(ab,x,y)
errors_percent = []
for i in range(len(x)):
errors_percent.append(100*(sales_c[i]-y[i])/y[i])
return errors_percent
# построим график
print 'График№3 "Отклонения по-месячно, %"'
plt.gca().bar(x_us, error_per_month(ab_us,x_us,y_us), color='brown')
plt.xlabel('Months', size=16)
plt.ylabel('Calculation error, %', size=16)
plt.show()Graficul nr. 3 „Abateri, %”
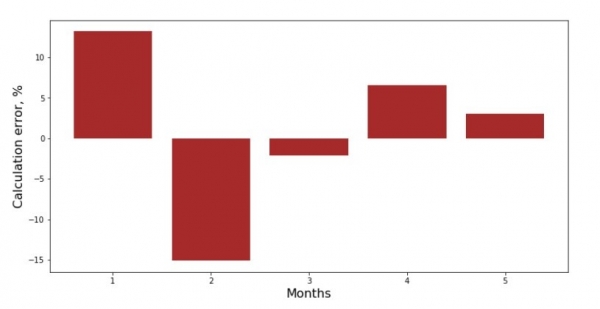
Nu perfect, dar ne-am îndeplinit sarcina.
Să scriem o funcție care, pentru a determina coeficienții  и
и  folosește biblioteca NumPy, mai precis, vom scrie două funcții: una folosind o matrice pseudoinversă (nu este recomandată în practică, deoarece procesul este complex și instabil din punct de vedere computațional), cealaltă folosind o ecuație matriceală.
folosește biblioteca NumPy, mai precis, vom scrie două funcții: una folosind o matrice pseudoinversă (nu este recomandată în practică, deoarece procesul este complex și instabil din punct de vedere computațional), cealaltă folosind o ecuație matriceală.
Cod soluție analitică (NumPy)
# для начала добавим столбец с не изменяющимся значением в 1.
# Данный столбец нужен для того, чтобы не обрабатывать отдельно коэффицент a
vector_1 = np.ones((x_np.shape[0],1))
x_np = table_zero[['x']].values # на всякий случай приведем в первичный формат вектор x_np
x_np = np.hstack((vector_1,x_np))
# проверим то, что все сделали правильно
print vector_1[0:3]
print x_np[0:3]
print '***************************************'
print
# напишем функцию, которая определяет значения коэффициентов a и b с использованием псевдообратной матрицы
def pseudoinverse_matrix(X, y):
# задаем явный формат матрицы признаков
X = np.matrix(X)
# определяем транспонированную матрицу
XT = X.T
# определяем квадратную матрицу
XTX = XT*X
# определяем псевдообратную матрицу
inv = np.linalg.pinv(XTX)
# задаем явный формат матрицы ответов
y = np.matrix(y)
# находим вектор весов
return (inv*XT)*y
# запустим функцию
ab_np = pseudoinverse_matrix(x_np, y_np)
print ab_np
print '***************************************'
print
# напишем функцию, которая использует для решения матричное уравнение
def matrix_equation(X,y):
a = np.dot(X.T, X)
b = np.dot(X.T, y)
return np.linalg.solve(a, b)
# запустим функцию
ab_np = matrix_equation(x_np,y_np)
print ab_npSă comparăm timpul petrecut la determinarea coeficienților  и
и  , în conformitate cu cele 3 metode prezentate.
, în conformitate cu cele 3 metode prezentate.
Cod pentru calcularea timpului de calcul
print ' 33[1m' + ' 33[4m' + "Время выполнения расчета коэффициентов без использования библиотеки NumPy:" + ' 33[0m'
% timeit ab_us = Kramer_method(x_us,y_us)
print '***************************************'
print
print ' 33[1m' + ' 33[4m' + "Время выполнения расчета коэффициентов с использованием псевдообратной матрицы:" + ' 33[0m'
%timeit ab_np = pseudoinverse_matrix(x_np, y_np)
print '***************************************'
print
print ' 33[1m' + ' 33[4m' + "Время выполнения расчета коэффициентов с использованием матричного уравнения:" + ' 33[0m'
%timeit ab_np = matrix_equation(x_np, y_np)
Cu o cantitate mică de date, apare o funcție „autoscrisă”, care găsește coeficienții folosind metoda lui Cramer.
Acum puteți trece la alte moduri de a găsi coeficienți  и
и  .
.
Coborâre în gradient
Mai întâi, să definim ce este un gradient. Mai simplu spus, gradientul este un segment care indică direcția de creștere maximă a unei funcții. Prin analogie cu urcarea pe un munte, acolo unde se confruntă cu panta este cea mai abruptă urcare spre vârful muntelui. Dezvoltând exemplul cu muntele, ne amintim că de fapt avem nevoie de cea mai abruptă coborâre pentru a ajunge cât mai repede la câmpie, adică la minim - locul în care funcția nu crește sau scade. În acest moment, derivata va fi egală cu zero. Prin urmare, nu avem nevoie de un gradient, ci de un antigradient. Pentru a găsi antigradientul trebuie doar să înmulțiți gradientul cu -1 (minus unu).
Să fim atenți la faptul că o funcție poate avea mai multe minime, iar coborând într-una dintre ele folosind algoritmul propus mai jos, nu vom putea găsi un alt minim, care poate fi mai mic decât cel găsit. Să ne relaxăm, aceasta nu este o amenințare pentru noi! În cazul nostru avem de-a face cu un singur minim, din moment ce funcția noastră  pe grafic este o parabolă regulată. Și așa cum ar trebui să știm cu toții foarte bine din cursul nostru de matematică de la școală, o parabolă are doar un minim.
pe grafic este o parabolă regulată. Și așa cum ar trebui să știm cu toții foarte bine din cursul nostru de matematică de la școală, o parabolă are doar un minim.
După ce am aflat de ce avem nevoie de un gradient și, de asemenea, că gradientul este un segment, adică un vector cu coordonate date, care sunt exact aceiași coeficienți  и
и  putem implementa coborârea în gradient.
putem implementa coborârea în gradient.
Înainte de a începe, vă sugerez să citiți doar câteva propoziții despre algoritmul de coborâre:
- Determinăm într-o manieră pseudo-aleatoare coordonatele coeficienților
 и . În exemplul nostru, vom defini coeficienți aproape de zero. Aceasta este o practică comună, dar fiecare caz poate avea propria sa practică.
и . În exemplul nostru, vom defini coeficienți aproape de zero. Aceasta este o practică comună, dar fiecare caz poate avea propria sa practică. - Din coordonate scădeți valoarea derivatei parțiale de ordinul I la punctul respectiv . Deci, dacă derivata este pozitivă, atunci funcția crește. Prin urmare, prin scăderea valorii derivatei, ne vom deplasa în direcția opusă creșterii, adică în direcția coborârii. Dacă derivata este negativă, atunci funcția în acest punct scade și prin scăderea valorii derivatei ne deplasăm în direcția de coborâre.
- Efectuăm o operațiune similară cu coordonatele : scade valoarea derivatei parțiale la punct .
- Pentru a nu sări peste minim și a zbura în spațiul adânc, este necesar să setați dimensiunea pasului în direcția de coborâre. În general, ai putea scrie un articol întreg despre cum să setezi corect pasul și cum să-l schimbi în timpul procesului de coborâre pentru a reduce costurile de calcul. Dar acum avem o sarcină puțin diferită în față și vom stabili dimensiunea pasului folosind metoda științifică a „poke” sau, după cum se spune în limbajul comun, empiric.
- Odată ce suntem de la coordonatele date и scădeți valorile derivatelor, obținem coordonate noi и . Facem următorul pas (scădere), deja din coordonatele calculate. Și astfel ciclul începe din nou și din nou, până când se obține convergența necesară.
 и
и  . În exemplul nostru, vom defini coeficienți aproape de zero. Aceasta este o practică comună, dar fiecare caz poate avea propria sa practică.
. În exemplul nostru, vom defini coeficienți aproape de zero. Aceasta este o practică comună, dar fiecare caz poate avea propria sa practică. scădeți valoarea derivatei parțiale de ordinul I la punctul respectiv
scădeți valoarea derivatei parțiale de ordinul I la punctul respectiv  . Deci, dacă derivata este pozitivă, atunci funcția crește. Prin urmare, prin scăderea valorii derivatei, ne vom deplasa în direcția opusă creșterii, adică în direcția coborârii. Dacă derivata este negativă, atunci funcția în acest punct scade și prin scăderea valorii derivatei ne deplasăm în direcția de coborâre.
. Deci, dacă derivata este pozitivă, atunci funcția crește. Prin urmare, prin scăderea valorii derivatei, ne vom deplasa în direcția opusă creșterii, adică în direcția coborârii. Dacă derivata este negativă, atunci funcția în acest punct scade și prin scăderea valorii derivatei ne deplasăm în direcția de coborâre.  : scade valoarea derivatei parțiale la punct
: scade valoarea derivatei parțiale la punct  .
. и
и  scădeți valorile derivatelor, obținem coordonate noi
scădeți valorile derivatelor, obținem coordonate noi  и
и  . Facem următorul pas (scădere), deja din coordonatele calculate. Și astfel ciclul începe din nou și din nou, până când se obține convergența necesară.
. Facem următorul pas (scădere), deja din coordonatele calculate. Și astfel ciclul începe din nou și din nou, până când se obține convergența necesară.Toate! Acum suntem pregătiți să plecăm în căutarea celui mai adânc defileu al șanțului Marianei. Să începem.
Cod pentru coborâre în gradient
# напишем функцию градиентного спуска без использования библиотеки NumPy.
# Функция на вход принимает диапазоны значений x,y, длину шага (по умолчанию=0,1), допустимую погрешность(tolerance)
def gradient_descent_usual(x_us,y_us,l=0.1,tolerance=0.000000000001):
# сумма значений (все месяца)
sx = sum(x_us)
# сумма истинных ответов (выручка за весь период)
sy = sum(y_us)
# сумма произведения значений на истинные ответы
list_xy = []
[list_xy.append(x_us[i]*y_us[i]) for i in range(len(x_us))]
sxy = sum(list_xy)
# сумма квадратов значений
list_x_sq = []
[list_x_sq.append(x_us[i]**2) for i in range(len(x_us))]
sx_sq = sum(list_x_sq)
# количество значений
num = len(x_us)
# начальные значения коэффициентов, определенные псевдослучайным образом
a = float(random.uniform(-0.5, 0.5))
b = float(random.uniform(-0.5, 0.5))
# создаем массив с ошибками, для старта используем значения 1 и 0
# после завершения спуска стартовые значения удалим
errors = [1,0]
# запускаем цикл спуска
# цикл работает до тех пор, пока отклонение последней ошибки суммы квадратов от предыдущей, не будет меньше tolerance
while abs(errors[-1]-errors[-2]) > tolerance:
a_step = a - l*(num*a + b*sx - sy)/num
b_step = b - l*(a*sx + b*sx_sq - sxy)/num
a = a_step
b = b_step
ab = [a,b]
errors.append(errors_sq_Kramer_method(ab,x_us,y_us))
return (ab),(errors[2:])
# запишем массив значений
list_parametres_gradient_descence = gradient_descent_usual(x_us,y_us,l=0.1,tolerance=0.000000000001)
print ' 33[1m' + ' 33[4m' + "Значения коэффициентов a и b:" + ' 33[0m'
print 'a =', round(list_parametres_gradient_descence[0][0],3)
print 'b =', round(list_parametres_gradient_descence[0][1],3)
print
print ' 33[1m' + ' 33[4m' + "Сумма квадратов отклонений:" + ' 33[0m'
print round(list_parametres_gradient_descence[1][-1],3)
print
print ' 33[1m' + ' 33[4m' + "Количество итераций в градиентном спуске:" + ' 33[0m'
print len(list_parametres_gradient_descence[1])
print
Ne-am scufundat până la fundul șanțului Marianei și acolo am găsit toate aceleași valori ale coeficientului  и
и  , care este exact ceea ce era de așteptat.
, care este exact ceea ce era de așteptat.
Să facem o altă scufundare, doar că de această dată, vehiculul nostru de adâncime va fi umplut cu alte tehnologii, și anume o bibliotecă NumPy.
Cod pentru coborâre în gradient (NumPy)
# перед тем определить функцию для градиентного спуска с использованием библиотеки NumPy,
# напишем функцию определения суммы квадратов отклонений также с использованием NumPy
def error_square_numpy(ab,x_np,y_np):
y_pred = np.dot(x_np,ab)
error = y_pred - y_np
return sum((error)**2)
# напишем функцию градиентного спуска с использованием библиотеки NumPy.
# Функция на вход принимает диапазоны значений x,y, длину шага (по умолчанию=0,1), допустимую погрешность(tolerance)
def gradient_descent_numpy(x_np,y_np,l=0.1,tolerance=0.000000000001):
# сумма значений (все месяца)
sx = float(sum(x_np[:,1]))
# сумма истинных ответов (выручка за весь период)
sy = float(sum(y_np))
# сумма произведения значений на истинные ответы
sxy = x_np*y_np
sxy = float(sum(sxy[:,1]))
# сумма квадратов значений
sx_sq = float(sum(x_np[:,1]**2))
# количество значений
num = float(x_np.shape[0])
# начальные значения коэффициентов, определенные псевдослучайным образом
a = float(random.uniform(-0.5, 0.5))
b = float(random.uniform(-0.5, 0.5))
# создаем массив с ошибками, для старта используем значения 1 и 0
# после завершения спуска стартовые значения удалим
errors = [1,0]
# запускаем цикл спуска
# цикл работает до тех пор, пока отклонение последней ошибки суммы квадратов от предыдущей, не будет меньше tolerance
while abs(errors[-1]-errors[-2]) > tolerance:
a_step = a - l*(num*a + b*sx - sy)/num
b_step = b - l*(a*sx + b*sx_sq - sxy)/num
a = a_step
b = b_step
ab = np.array([[a],[b]])
errors.append(error_square_numpy(ab,x_np,y_np))
return (ab),(errors[2:])
# запишем массив значений
list_parametres_gradient_descence = gradient_descent_numpy(x_np,y_np,l=0.1,tolerance=0.000000000001)
print ' 33[1m' + ' 33[4m' + "Значения коэффициентов a и b:" + ' 33[0m'
print 'a =', round(list_parametres_gradient_descence[0][0],3)
print 'b =', round(list_parametres_gradient_descence[0][1],3)
print
print ' 33[1m' + ' 33[4m' + "Сумма квадратов отклонений:" + ' 33[0m'
print round(list_parametres_gradient_descence[1][-1],3)
print
print ' 33[1m' + ' 33[4m' + "Количество итераций в градиентном спуске:" + ' 33[0m'
print len(list_parametres_gradient_descence[1])
print
Valorile coeficientului  и
и  neschimbabil.
neschimbabil.
Să vedem cum s-a schimbat eroarea în timpul coborârii gradientului, adică cum s-a schimbat suma abaterilor pătrate cu fiecare pas.
Cod pentru trasarea sumelor abaterilor pătrate
print 'График№4 "Сумма квадратов отклонений по-шагово"'
plt.plot(range(len(list_parametres_gradient_descence[1])), list_parametres_gradient_descence[1], color='red', lw=3)
plt.xlabel('Steps (Iteration)', size=16)
plt.ylabel('Sum of squared deviations', size=16)
plt.show()Graficul nr. 4 „Suma abaterilor pătrate în timpul coborârii gradientului”
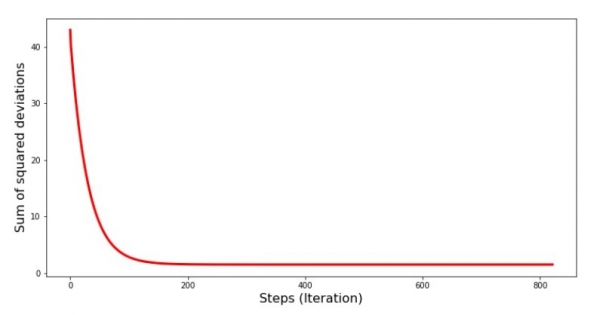
Pe grafic vedem ca cu fiecare pas eroarea scade, iar dupa un anumit numar de iteratii observam o linie aproape orizontala.
În cele din urmă, să estimăm diferența de timp de execuție a codului:
Cod pentru a determina timpul de calcul al coborârii gradientului
print ' 33[1m' + ' 33[4m' + "Время выполнения градиентного спуска без использования библиотеки NumPy:" + ' 33[0m'
%timeit list_parametres_gradient_descence = gradient_descent_usual(x_us,y_us,l=0.1,tolerance=0.000000000001)
print '***************************************'
print
print ' 33[1m' + ' 33[4m' + "Время выполнения градиентного спуска с использованием библиотеки NumPy:" + ' 33[0m'
%timeit list_parametres_gradient_descence = gradient_descent_numpy(x_np,y_np,l=0.1,tolerance=0.000000000001)
Poate că facem ceva greșit, dar din nou este o funcție simplă „scrisă acasă” care nu folosește biblioteca NumPy depășește timpul de calcul al unei funcții folosind biblioteca NumPy.
Dar nu stăm nemișcați, ci ne îndreptăm spre studierea unei alte modalități interesante de a rezolva ecuația de regresie liniară simplă. Intalneste-ne!
Coborarea gradientului stocastic
Pentru a înțelege rapid principiul de funcționare al coborârii gradientului stocastic, este mai bine să determinați diferențele sale față de coborârea gradientului obișnuit. Noi, în cazul coborârii gradientului, în ecuațiile derivatelor lui  и
и  au folosit sumele valorilor tuturor caracteristicilor și răspunsurile adevărate disponibile în eșantion (adică sumele tuturor
au folosit sumele valorilor tuturor caracteristicilor și răspunsurile adevărate disponibile în eșantion (adică sumele tuturor  и
и  ). În coborârea gradientului stocastic, nu vom folosi toate valorile prezente în eșantion, ci, în schimb, selectăm pseudo-aleatoriu așa-numitul indice al eșantionului și folosim valorile acestuia.
). În coborârea gradientului stocastic, nu vom folosi toate valorile prezente în eșantion, ci, în schimb, selectăm pseudo-aleatoriu așa-numitul indice al eșantionului și folosim valorile acestuia.
De exemplu, dacă indicele este determinat a fi numărul 3 (trei), atunci luăm valorile  и
и  , apoi substituim valorile în ecuațiile derivate și determinăm noi coordonate. Apoi, după ce am determinat coordonatele, determinăm din nou pseudo-aleatoriu indicele eșantionului, înlocuim valorile corespunzătoare indicelui în ecuațiile cu diferențe parțiale și determinăm coordonatele într-un mod nou
, apoi substituim valorile în ecuațiile derivate și determinăm noi coordonate. Apoi, după ce am determinat coordonatele, determinăm din nou pseudo-aleatoriu indicele eșantionului, înlocuim valorile corespunzătoare indicelui în ecuațiile cu diferențe parțiale și determinăm coordonatele într-un mod nou  и
и  etc. până când convergența devine verde. La prima vedere, s-ar putea să nu pară că acest lucru ar putea funcționa deloc, dar da. Este adevărat că este de remarcat că eroarea nu scade cu fiecare pas, dar cu siguranță există o tendință.
etc. până când convergența devine verde. La prima vedere, s-ar putea să nu pară că acest lucru ar putea funcționa deloc, dar da. Este adevărat că este de remarcat că eroarea nu scade cu fiecare pas, dar cu siguranță există o tendință.
Care sunt avantajele coborârii gradientului stocastic față de cel convențional? Dacă dimensiunea eșantionului nostru este foarte mare și măsurată în zeci de mii de valori, atunci este mult mai ușor să procesăm, de exemplu, o mie aleatorie dintre ele, mai degrabă decât întregul eșantion. Aici intervine coborârea gradientului stocastic. În cazul nostru, desigur, nu vom observa o mare diferență.
Să ne uităm la cod.
Cod pentru coborârea gradientului stocastic
# определим функцию стох.град.шага
def stoch_grad_step_usual(vector_init, x_us, ind, y_us, l):
# выбираем значение икс, которое соответствует случайному значению параметра ind
# (см.ф-цию stoch_grad_descent_usual)
x = x_us[ind]
# рассчитывыаем значение y (выручку), которая соответствует выбранному значению x
y_pred = vector_init[0] + vector_init[1]*x_us[ind]
# вычисляем ошибку расчетной выручки относительно представленной в выборке
error = y_pred - y_us[ind]
# определяем первую координату градиента ab
grad_a = error
# определяем вторую координату ab
grad_b = x_us[ind]*error
# вычисляем новый вектор коэффициентов
vector_new = [vector_init[0]-l*grad_a, vector_init[1]-l*grad_b]
return vector_new
# определим функцию стох.град.спуска
def stoch_grad_descent_usual(x_us, y_us, l=0.1, steps = 800):
# для самого начала работы функции зададим начальные значения коэффициентов
vector_init = [float(random.uniform(-0.5, 0.5)), float(random.uniform(-0.5, 0.5))]
errors = []
# запустим цикл спуска
# цикл расчитан на определенное количество шагов (steps)
for i in range(steps):
ind = random.choice(range(len(x_us)))
new_vector = stoch_grad_step_usual(vector_init, x_us, ind, y_us, l)
vector_init = new_vector
errors.append(errors_sq_Kramer_method(vector_init,x_us,y_us))
return (vector_init),(errors)
# запишем массив значений
list_parametres_stoch_gradient_descence = stoch_grad_descent_usual(x_us, y_us, l=0.1, steps = 800)
print ' 33[1m' + ' 33[4m' + "Значения коэффициентов a и b:" + ' 33[0m'
print 'a =', round(list_parametres_stoch_gradient_descence[0][0],3)
print 'b =', round(list_parametres_stoch_gradient_descence[0][1],3)
print
print ' 33[1m' + ' 33[4m' + "Сумма квадратов отклонений:" + ' 33[0m'
print round(list_parametres_stoch_gradient_descence[1][-1],3)
print
print ' 33[1m' + ' 33[4m' + "Количество итераций в стохастическом градиентном спуске:" + ' 33[0m'
print len(list_parametres_stoch_gradient_descence[1])
Ne uităm cu atenție la coeficienți și ne surprindem punând întrebarea „Cum poate fi asta?” Avem alte valori ale coeficientului  и
и  . Poate coborârea gradientului stocastic a găsit parametri mai optimi pentru ecuație? Din pacate, nu. Este suficient să privim suma abaterilor pătrate și să vedem că, cu noile valori ale coeficienților, eroarea este mai mare. Nu ne grăbim să disperăm. Să construim un grafic al schimbării erorii.
. Poate coborârea gradientului stocastic a găsit parametri mai optimi pentru ecuație? Din pacate, nu. Este suficient să privim suma abaterilor pătrate și să vedem că, cu noile valori ale coeficienților, eroarea este mai mare. Nu ne grăbim să disperăm. Să construim un grafic al schimbării erorii.
Cod pentru trasarea sumei abaterilor pătrate în coborârea gradientului stocastic
print 'График №5 "Сумма квадратов отклонений по-шагово"'
plt.plot(range(len(list_parametres_stoch_gradient_descence[1])), list_parametres_stoch_gradient_descence[1], color='red', lw=2)
plt.xlabel('Steps (Iteration)', size=16)
plt.ylabel('Sum of squared deviations', size=16)
plt.show()Graficul nr. 5 „Suma abaterilor pătrate în timpul coborârii gradientului stocastic”
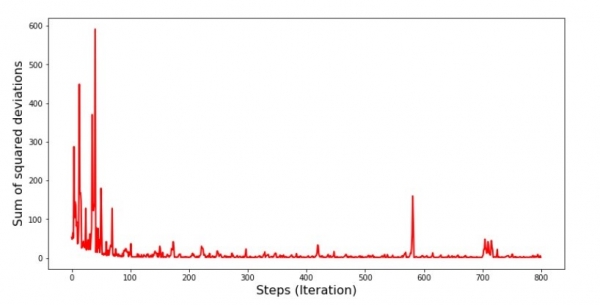
Privind programul, totul cade la locul lui și acum vom remedia totul.
Deci ce s-a întâmplat? S-au întâmplat următoarele. Când selectăm aleatoriu o lună, atunci algoritmul nostru încearcă să reducă eroarea în calcularea veniturilor pentru luna selectată. Apoi selectăm încă o lună și repetăm calculul, dar reducem eroarea pentru a doua lună selectată. Acum amintiți-vă că primele două luni se abate semnificativ de la linia ecuației de regresie liniară simplă. Aceasta înseamnă că atunci când se selectează oricare dintre aceste două luni, prin reducerea erorii fiecăreia dintre ele, algoritmul nostru crește serios eroarea pentru întregul eșantion. Deci ce să fac? Răspunsul este simplu: trebuie să reduceți treapta de coborâre. La urma urmei, prin reducerea pasului de coborâre, eroarea se va opri și „săritul” în sus și în jos. Sau, mai degrabă, eroarea de „săritură” nu se va opri, dar nu o va face atât de repede :) Să verificăm.
Cod pentru a rula SGD cu incremente mai mici
# запустим функцию, уменьшив шаг в 100 раз и увеличив количество шагов соответсвующе
list_parametres_stoch_gradient_descence = stoch_grad_descent_usual(x_us, y_us, l=0.001, steps = 80000)
print ' 33[1m' + ' 33[4m' + "Значения коэффициентов a и b:" + ' 33[0m'
print 'a =', round(list_parametres_stoch_gradient_descence[0][0],3)
print 'b =', round(list_parametres_stoch_gradient_descence[0][1],3)
print
print ' 33[1m' + ' 33[4m' + "Сумма квадратов отклонений:" + ' 33[0m'
print round(list_parametres_stoch_gradient_descence[1][-1],3)
print
print ' 33[1m' + ' 33[4m' + "Количество итераций в стохастическом градиентном спуске:" + ' 33[0m'
print len(list_parametres_stoch_gradient_descence[1])
print 'График №6 "Сумма квадратов отклонений по-шагово"'
plt.plot(range(len(list_parametres_stoch_gradient_descence[1])), list_parametres_stoch_gradient_descence[1], color='red', lw=2)
plt.xlabel('Steps (Iteration)', size=16)
plt.ylabel('Sum of squared deviations', size=16)
plt.show()
Graficul nr. 6 „Suma abaterilor pătrate în timpul coborârii gradientului stocastic (80 de mii de pași)”
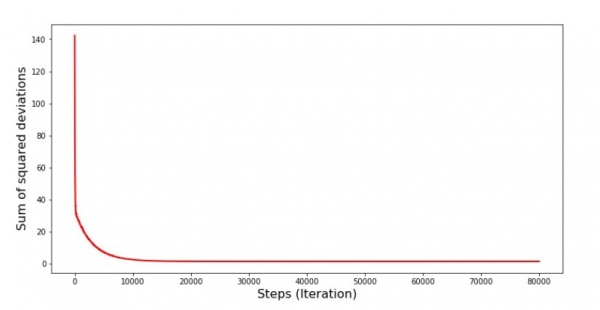
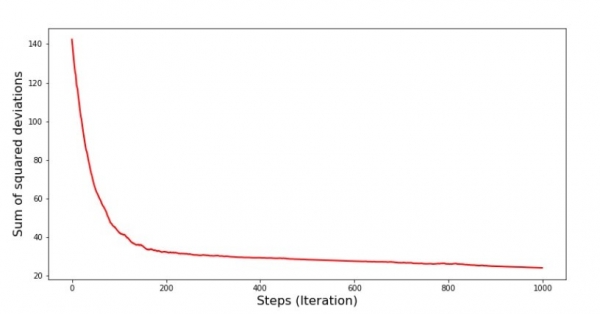
Coeficienții s-au îmbunătățit, dar încă nu sunt ideali. Ipotetic, acest lucru poate fi corectat în acest fel. Selectăm, de exemplu, în ultimele 1000 de iterații valorile coeficienților cu care s-a făcut eroarea minimă. Adevărat, pentru aceasta va trebui, de asemenea, să notăm valorile coeficienților înșiși. Nu vom face asta, ci mai degrabă vom fi atenți la program. Pare neted și eroarea pare să scadă uniform. De fapt, acest lucru nu este adevărat. Să ne uităm la primele 1000 de iterații și să le comparăm cu ultimele.
Cod pentru diagrama SGD (primii 1000 de pași)
print 'График №7 "Сумма квадратов отклонений по-шагово. Первые 1000 итераций"'
plt.plot(range(len(list_parametres_stoch_gradient_descence[1][:1000])),
list_parametres_stoch_gradient_descence[1][:1000], color='red', lw=2)
plt.xlabel('Steps (Iteration)', size=16)
plt.ylabel('Sum of squared deviations', size=16)
plt.show()
print 'График №7 "Сумма квадратов отклонений по-шагово. Последние 1000 итераций"'
plt.plot(range(len(list_parametres_stoch_gradient_descence[1][-1000:])),
list_parametres_stoch_gradient_descence[1][-1000:], color='red', lw=2)
plt.xlabel('Steps (Iteration)', size=16)
plt.ylabel('Sum of squared deviations', size=16)
plt.show()Graficul nr. 7 „Suma abaterilor pătrate SGD (primii 1000 de pași)”
Graficul nr. 8 „Suma abaterilor pătrate SGD (ultimii 1000 de pași)”
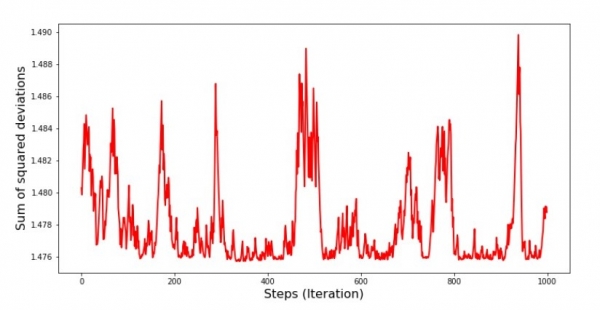
Chiar la începutul coborârii, observăm o scădere destul de uniformă și abruptă a erorii. În ultimele iterații, vedem că eroarea se învârte în jurul valorii de 1,475 și în unele momente chiar egalează această valoare optimă, dar apoi tot crește... Repet, puteți nota valorile coeficienți  и
и  , apoi selectați-le pe cele pentru care eroarea este minimă. Cu toate acestea, am avut o problemă mai serioasă: a trebuit să facem 80 de mii de pași (vezi cod) pentru a obține valori aproape de optime. Și acest lucru contrazice deja ideea economisirii timpului de calcul cu coborârea gradientului stocastic în raport cu coborârea gradientului. Ce poate fi corectat și îmbunătățit? Nu este greu de observat că în primele iterații coborâm cu încredere și, prin urmare, ar trebui să lăsăm un pas mare în primele iterații și să reducem pasul pe măsură ce avansăm. Nu vom face acest lucru în acest articol - este deja prea lung. Cei care doresc se pot gândi singuri cum să facă asta, nu este greu :)
, apoi selectați-le pe cele pentru care eroarea este minimă. Cu toate acestea, am avut o problemă mai serioasă: a trebuit să facem 80 de mii de pași (vezi cod) pentru a obține valori aproape de optime. Și acest lucru contrazice deja ideea economisirii timpului de calcul cu coborârea gradientului stocastic în raport cu coborârea gradientului. Ce poate fi corectat și îmbunătățit? Nu este greu de observat că în primele iterații coborâm cu încredere și, prin urmare, ar trebui să lăsăm un pas mare în primele iterații și să reducem pasul pe măsură ce avansăm. Nu vom face acest lucru în acest articol - este deja prea lung. Cei care doresc se pot gândi singuri cum să facă asta, nu este greu :)
Acum să efectuăm o coborâre stocastică a gradientului folosind biblioteca NumPy (și să nu ne împiedicăm de pietrele pe care le-am identificat mai devreme)
Cod pentru coborârea gradientului stocastic (NumPy)
# для начала напишем функцию градиентного шага
def stoch_grad_step_numpy(vector_init, X, ind, y, l):
x = X[ind]
y_pred = np.dot(x,vector_init)
err = y_pred - y[ind]
grad_a = err
grad_b = x[1]*err
return vector_init - l*np.array([grad_a, grad_b])
# определим функцию стохастического градиентного спуска
def stoch_grad_descent_numpy(X, y, l=0.1, steps = 800):
vector_init = np.array([[np.random.randint(X.shape[0])], [np.random.randint(X.shape[0])]])
errors = []
for i in range(steps):
ind = np.random.randint(X.shape[0])
new_vector = stoch_grad_step_numpy(vector_init, X, ind, y, l)
vector_init = new_vector
errors.append(error_square_numpy(vector_init,X,y))
return (vector_init), (errors)
# запишем массив значений
list_parametres_stoch_gradient_descence = stoch_grad_descent_numpy(x_np, y_np, l=0.001, steps = 80000)
print ' 33[1m' + ' 33[4m' + "Значения коэффициентов a и b:" + ' 33[0m'
print 'a =', round(list_parametres_stoch_gradient_descence[0][0],3)
print 'b =', round(list_parametres_stoch_gradient_descence[0][1],3)
print
print ' 33[1m' + ' 33[4m' + "Сумма квадратов отклонений:" + ' 33[0m'
print round(list_parametres_stoch_gradient_descence[1][-1],3)
print
print ' 33[1m' + ' 33[4m' + "Количество итераций в стохастическом градиентном спуске:" + ' 33[0m'
print len(list_parametres_stoch_gradient_descence[1])
print
Valorile s-au dovedit a fi aproape aceleași ca la coborâre fără utilizare NumPy. Cu toate acestea, acest lucru este logic.
Să aflăm cât timp ne-au luat coborârile în gradient stocastic.
Cod pentru determinarea timpului de calcul SGD (80 mii de pași)
print ' 33[1m' + ' 33[4m' +
"Время выполнения стохастического градиентного спуска без использования библиотеки NumPy:"
+ ' 33[0m'
%timeit list_parametres_stoch_gradient_descence = stoch_grad_descent_usual(x_us, y_us, l=0.001, steps = 80000)
print '***************************************'
print
print ' 33[1m' + ' 33[4m' +
"Время выполнения стохастического градиентного спуска с использованием библиотеки NumPy:"
+ ' 33[0m'
%timeit list_parametres_stoch_gradient_descence = stoch_grad_descent_numpy(x_np, y_np, l=0.001, steps = 80000)
Cu cât mai departe în pădure, cu atât norii sunt mai întunecați: din nou, formula „autoscrisă” arată cel mai bun rezultat. Toate acestea sugerează că trebuie să existe modalități și mai subtile de a folosi biblioteca NumPy, care accelerează cu adevărat operațiunile de calcul. În acest articol nu vom afla despre ele. Va fi ceva la care să te gândești în timpul tău liber :)
Rezumăm
Înainte de a rezuma, aș dori să răspund la o întrebare care, cel mai probabil, a apărut de la dragul nostru cititor. De ce, de fapt, o asemenea „tortură” cu coborâri, de ce trebuie să mergem în sus și în jos pe munte (mai ales în jos) pentru a găsi pământul prețuit, dacă avem în mâinile noastre un dispozitiv atât de puternic și simplu, în forma unei soluții analitice, care ne teleportează instantaneu în locul potrivit?
Răspunsul la această întrebare se află la suprafață. Acum ne-am uitat la un exemplu foarte simplu, în care răspunsul adevărat este  depinde de un semn
depinde de un semn  . Nu vezi asta des în viață, așa că să ne imaginăm că avem 2, 30, 50 sau mai multe semne. Să adăugăm la aceasta mii sau chiar zeci de mii de valori pentru fiecare atribut. În acest caz, soluția analitică poate să nu reziste testului și să eșueze. La rândul său, coborârea în gradient și variațiile sale ne vor aduce încet, dar sigur, mai aproape de obiectiv - minimul funcției. Și nu vă faceți griji cu privire la viteză - probabil că vom analiza modalități care ne vor permite să setăm și să reglam lungimea pasului (adică viteza).
. Nu vezi asta des în viață, așa că să ne imaginăm că avem 2, 30, 50 sau mai multe semne. Să adăugăm la aceasta mii sau chiar zeci de mii de valori pentru fiecare atribut. În acest caz, soluția analitică poate să nu reziste testului și să eșueze. La rândul său, coborârea în gradient și variațiile sale ne vor aduce încet, dar sigur, mai aproape de obiectiv - minimul funcției. Și nu vă faceți griji cu privire la viteză - probabil că vom analiza modalități care ne vor permite să setăm și să reglam lungimea pasului (adică viteza).
Și acum rezumatul propriu-zis.
În primul rând, sper că materialul prezentat în articol îi va ajuta pe „oamenii de știință de date” începători să înțeleagă cum să rezolve ecuații de regresie liniară simple (și nu numai).
În al doilea rând, am analizat mai multe moduri de a rezolva ecuația. Acum, în funcție de situație, îl putem alege pe cel mai potrivit pentru a rezolva problema.
În al treilea rând, am văzut puterea setărilor suplimentare, și anume lungimea pasului de coborâre a gradientului. Acest parametru nu poate fi neglijat. După cum sa menționat mai sus, pentru a reduce costul calculelor, lungimea pasului ar trebui modificată în timpul coborârii.
În al patrulea rând, în cazul nostru, funcțiile „scrise acasă” au arătat cele mai bune rezultate de timp pentru calcule. Acest lucru se datorează probabil că nu este cea mai profesională utilizare a capacităților bibliotecii NumPy. Dar oricum ar fi, concluzia care urmează se sugerează de la sine. Pe de o parte, uneori merită să puneți la îndoială opiniile stabilite, iar pe de altă parte, nu merită întotdeauna să complicați totul - dimpotrivă, uneori o modalitate mai simplă de a rezolva o problemă este mai eficientă. Și din moment ce scopul nostru a fost să analizăm trei abordări pentru rezolvarea unei ecuații de regresie liniară simplă, utilizarea funcțiilor „auto-scrise” a fost suficientă pentru noi.
Literatura (sau ceva de genul asta)
1. Regresia liniară
2. Metoda celor mai mici pătrate
3. Derivat
4. Gradient
5. Coborâre în gradient
6. Biblioteca NumPy
Sursa: www.habr.com
