


SQL، ڇا آسان ٿي سگهي ٿو؟ اسان مان هر هڪ هڪ سادي درخواست لکي سگهي ٿو - اسان ٽائپ ڪريون ٿا چونڊيو، پوءِ گهربل ڪالمن کي لسٽ ڪريو کان, ٽيبل جو نالو، ڪجهه شرطن ۾ جتي ۽ اهو سڀ ڪجهه آهي - مفيد ڊيٽا اسان جي کيسي ۾ آهي، ۽ (تقريبا) بغير ڪنهن جي ڊي بي ايم ايس هن وقت هود هيٺ آهي (يا شايد ). نتيجي طور، تقريبن ڪنهن به ڊيٽا جي ماخذ سان ڪم ڪرڻ (لاڳاپيل ۽ ائين نه) عام ڪوڊ جي نقطي نظر کان سمجهي سگهجي ٿو (سڀني سان اهو مطلب آهي - ورزن ڪنٽرول، ڪوڊ جائزو، جامد تجزيو، آٽو ٽيسٽ، ۽ اهو سڀ ڪجهه آهي). ۽ اهو لاڳو ٿئي ٿو نه رڳو ڊيٽا پاڻ تي، اسڪيمن ۽ لڏپلاڻ، پر عام طور تي اسٽوريج جي سڄي زندگي تي. هن آرٽيڪل ۾ اسان روزمره جي ڪمن بابت ڳالهائينداسين ۽ مختلف ڊيٽابيس سان ڪم ڪرڻ جي مسئلن کي "ڊيٽابيس طور ڪوڊ" جي لينس هيٺ.
۽ اچو ته صحيح کان شروع ڪريون . "SQL بمقابلہ ORM" قسم جي پهرين جنگين کي واپس محسوس ڪيو ويو .
آبجیکٹ-رابطي وارو نقشو
ORM حامي روايتي طور تي قدر ڪن ٿا رفتار ۽ ترقي جي آسانيءَ، DBMS کان آزادي ۽ صاف ڪوڊ. اسان مان گھڻن لاء، ڊيٽابيس سان ڪم ڪرڻ لاء ڪوڊ (۽ اڪثر ڪري ڊيٽابيس پاڻ)
اهو عام طور تي ڪجهه هن وانگر ڏسڻ ۾ اچي ٿو ...
@Entity
@Table(name = "stock", catalog = "maindb", uniqueConstraints = {
@UniqueConstraint(columnNames = "STOCK_NAME"),
@UniqueConstraint(columnNames = "STOCK_CODE") })
public class Stock implements java.io.Serializable {
@Id
@GeneratedValue(strategy = IDENTITY)
@Column(name = "STOCK_ID", unique = true, nullable = false)
public Integer getStockId() {
return this.stockId;
}
...ماڊل هوشيار تشريحن سان ٽنگيو ويو آهي، ۽ پردي جي پويان ڪٿي به هڪ دلير ORM ڪجهه SQL ڪوڊ ٺاهي ۽ ان تي عمل ڪري ٿو. رستي جي ذريعي، ڊولپر پنهنجو پاڻ کي پنهنجي ڊيٽابيس کان پاڻ کي الڳ ڪرڻ جي ڪوشش ڪري رهيا آهن ڪلوميٽرن جي تجزين سان، جيڪو ڪجهه اشارو ڪري ٿو. .
رڪاوٽن جي ٻئي پاسي، خالص "هٿ سان ٺهيل" SQL جا پيروڪار نوٽ ڪن ٿا ته انهن جي ڊي بي ايم ايس مان سڀني جوس کي نچوض ڪرڻ جي صلاحيت بغير اضافي تہن ۽ خلاصن جي. نتيجي طور، "ڊيٽا سينٽرڪ" منصوبا ظاهر ٿيندا آهن، جتي خاص طور تي تربيت يافته ماڻهو ڊيٽابيس ۾ شامل هوندا آهن (اهي پڻ آهن "بنيادي پرست"، اهي پڻ "بنيادي پرست" آهن، اهي پڻ آهن "basdeners" وغيره.)، ۽ ڊولپر. تفصيل ۾ وڃڻ کان سواءِ، صرف تيار ٿيل نظرين ۽ ذخيرو ٿيل طريقن کي ”ڇڏيو“ ڏيڻو پوندو.
ڇا جيڪڏهن اسان وٽ ٻنهي دنيان جو بهترين هجي ها؟ اهو ڪيئن ڪيو ويو آهي هڪ شاندار اوزار ۾ زندگي جي تصديق ڪندڙ نالي سان . مان پنهنجي مفت ترجمي ۾ عام تصور مان ٻه لائينون ڏيندس، ۽ توهان ان سان وڌيڪ تفصيل سان واقف ٿي سگهو ٿا .
Clojure DSLs ٺاهڻ لاءِ هڪ بهترين ٻولي آهي، پر SQL پاڻ هڪ بهترين DSL آهي، ۽ اسان کي ڪنهن ٻئي جي ضرورت ناهي. S-expressions عظيم آهن، پر اهي هتي ڪا به نئين شيءِ شامل نه ڪندا آهن. نتيجي طور، اسان بریکٹس جي خاطري حاصل ڪندا آهيون. متفق نه آهيو؟ پوءِ ان لمحي جو انتظار ڪريو جڏهن ڊيٽابيس تي خلاصو لڪائڻ شروع ٿئي ۽ توهان فنڪشن سان وڙهڻ شروع ڪيو (raw-sql)
پوء مون کي ڇا ڪرڻ گهرجي؟ اچو ته SQL کي باقاعده SQL طور ڇڏي ڏيو - ھڪڙي فائل في درخواست:
-- name: users-by-country
select *
from users
where country_code = :country_code... ۽ پوء هن فائل کي پڙهو، ان کي باقاعده ڪلوجور فنڪشن ۾ تبديل ڪريو:
(defqueries "some/where/users_by_country.sql"
{:connection db-spec})
;;; A function with the name `users-by-country` has been created.
;;; Let's use it:
(users-by-country {:country_code "GB"})
;=> ({:name "Kris" :country_code "GB" ...} ...)"SQL بذات خود، ڪلوجور بذات خود" اصول تي عمل ڪندي، توهان حاصل ڪندا:
- ڪو نحوي تعجب ناهي. توهان جو ڊيٽابيس (جهڙوڪ ڪنهن ٻئي وانگر) 100٪ SQL معيار سان مطابقت ناهي - پر اهو Yesql لاءِ ڪوئي فرق نٿو رکي. توھان ڪڏھن به وقت ضايع نه ڪندا آھيو وقت جو شڪار ڪمن لاءِ SQL برابر نحو سان. توهان کي ڪڏهن به فنڪشن ڏانهن واپس نه وڃڻو پوندو (raw-sql "some('funky'::SYNTAX)")).
- بهترين ايڊيٽر سپورٽ. توھان جي ايڊيٽر وٽ اڳ ۾ ئي شاندار SQL سپورٽ آھي. SQL کي SQL طور محفوظ ڪرڻ سان توھان ان کي استعمال ڪري سگھو ٿا.
- ٽيم مطابقت. توهان جا DBAs پڙهي ۽ لکي سگھن ٿا SQL جيڪو توهان استعمال ڪندا آهيو توهان جي ڪلوجور پروجيڪٽ ۾.
- آسان ڪارڪردگي ٽيوننگ. هڪ مشڪل سوال لاءِ منصوبو ٺاهڻ جي ضرورت آهي؟ اهو مسئلو ناهي جڏهن توهان جو سوال باقاعده SQL آهي.
- سوالن کي ٻيهر استعمال ڪندي. انهن ساڳين SQL فائلن کي ٻين پروجيڪٽس ۾ ڇڪيو ۽ ڇڏي ڏيو ڇاڪاڻ ته اهو صرف سادو پراڻو SQL آهي - بس ان کي شيئر ڪريو.
منهنجي خيال ۾، اهو خيال تمام ٿڌو آهي ۽ ساڳئي وقت بلڪل سادو آهي، جنهن جي مهرباني، منصوبي ڪيترن ئي حاصل ڪئي آهي مختلف ٻولين ۾. ۽ اسان اڳتي ڪوشش ڪنداسين SQL ڪوڊ کي الڳ ڪرڻ جو ساڳيو فلسفو هر شيءِ کان پري ORM کان پري.
IDE ۽ DB مينيجرز
اچو ته هڪ سادي روزاني ڪم سان شروع ڪريون. گهڻو ڪري اسان کي ڊيٽابيس ۾ ڪجهه شيون ڳولڻو پوندو، مثال طور، اسڪيما ۾ ٽيبل ڳوليو ۽ ان جي ساخت جو مطالعو ڪريو (ڪهڙا ڪالم، ڪي، انڊيڪس، رڪاوٽون، وغيره استعمال ڪيا ويا آهن). ۽ ڪنهن به گرافڪ IDE يا ٿورڙي ڊي بي مئنيجر کان، سڀ کان پهريان، اسان کي انهن صلاحيتن جي توقع آهي. انهي ڪري ته اهو تيز آهي ۽ توهان کي اڌ ڪلاڪ انتظار ڪرڻ جي ضرورت ناهي جيستائين ضروري معلومات سان ونڊو ٺهي وڃي (خاص طور تي ريموٽ ڊيٽابيس سان سست ڪنيڪشن سان)، ۽ ساڳئي وقت، حاصل ڪيل معلومات تازي ۽ لاڳاپيل آهي، ۽ نه ڪيش ٿيل فضول. ان کان علاوه، وڌيڪ پيچيده ۽ وڏو ڊيٽابيس ۽ انهن جو وڏو تعداد، اهو ڪرڻ وڌيڪ ڏکيو آهي.
پر عام طور تي مان مائوس کي اڇليندو آهيان ۽ صرف ڪوڊ لکندو آهيان. اچو ته توهان کي اهو معلوم ڪرڻو پوندو ته ڪهڙيون جدول (۽ ڪهڙيون ملڪيتون) "HR" اسڪيما ۾ شامل آهن. گھڻن DBMSs ۾، مطلوب نتيجو حاصل ڪري سگھجي ٿو ھن سادي سوال سان information_schema:
select table_name
, ...
from information_schema.tables
where schema = 'HR'ڊيٽابيس کان ڊيٽابيس تائين، اهڙي حوالن جي جدولن جو مواد هر DBMS جي صلاحيتن جي لحاظ کان مختلف آهي. ۽، مثال طور، MySQL لاءِ، ساڳئي حوالن واري ڪتاب مان توھان حاصل ڪري سگھوٿا ٽيبل پيٽرولز لاءِ مخصوص ھن DBMS:
select table_name
, storage_engine -- Используемый "движок" ("MyISAM", "InnoDB" etc)
, row_format -- Формат строки ("Fixed", "Dynamic" etc)
, ...
from information_schema.tables
where schema = 'HR'Oracle ڄاڻ نه ٿو ڄاڻن_ اسڪيما، پر اهو آهي ، ۽ ڪوبه وڏو مسئلو پيدا نه ٿيو:
select table_name
, pct_free -- Минимум свободного места в блоке данных (%)
, pct_used -- Минимум используемого места в блоке данных (%)
, last_analyzed -- Дата последнего сбора статистики
, ...
from all_tables
where owner = 'HR'ڪلڪ هائوس ڪو به استثنا نه آهي:
select name
, engine -- Используемый "движок" ("MergeTree", "Dictionary" etc)
, ...
from system.tables
where database = 'HR'ڪجهه اهڙو ئي ڪري سگهجي ٿو Cassandra ۾ (جنهن ۾ اسڪيما جي بدران ٽيبل ۽ ڪي اسپيس بدران ڪالمن فيملي آهن):
select columnfamily_name
, compaction_strategy_class -- Стратегия сборки мусора
, gc_grace_seconds -- Время жизни мусора
, ...
from system.schema_columnfamilies
where keyspace_name = 'HR'ٻين ڪيترن ئي ڊيٽابيسن لاءِ، توهان پڻ ساڳيون سوالن سان گڏ اچي سگهو ٿا (جيتوڻيڪ مونگو وٽ آهي ، جنهن ۾ سسٽم ۾ سڀني مجموعن بابت معلومات شامل آهي).
يقينن، هن طريقي سان توهان معلومات حاصل ڪري سگهو ٿا نه رڳو ٽيبل بابت، پر عام طور تي ڪنهن به شيء بابت. وقت بوقت، مهربان ماڻهو مختلف ڊيٽابيس لاءِ اهڙا ڪوڊ شيئر ڪندا آهن، مثال طور، هيبرا آرٽيڪلز جي سيريز ۾ ”پوسٽ گري ايس ايس ايل ڊيٽابيس کي دستاويز ڪرڻ جا ڪم“ (, , ). يقينن، سوالن جي هن سڄي جبل کي منهنجي ذهن ۾ رکڻ ۽ انهن کي مسلسل ٽائپ ڪرڻ هڪ اهڙي خوشي جي ڳالهه آهي، تنهنڪري منهنجي پسنديده IDE/ايڊيٽر ۾ مون وٽ اڪثر استعمال ٿيندڙ سوالن لاءِ اڳواٽ تيار ڪيل سٽون آهن، ۽ باقي اهو آهي ته ٽائپ ڪرڻ لاءِ. ٽيمپليٽ ۾ اعتراض جا نالا.
نتيجي طور، نيويگيٽ ڪرڻ ۽ شين جي ڳولا جو هي طريقو گهڻو وڌيڪ لچڪدار آهي، گهڻو وقت بچائيندو آهي، ۽ توهان کي فارم ۾ بلڪل معلومات حاصل ڪرڻ جي اجازت ڏئي ٿي جنهن ۾ اهو هاڻي ضروري آهي (مثال طور، پوسٽ ۾ بيان ڪيو ويو آهي. ).
شين سان آپريشن
ضروري شيون ڳولڻ ۽ اڀياس ڪرڻ کان پوء، اهو وقت آهي انهن سان ڪجهه مفيد ڪم ڪرڻ جو. قدرتي طور تي، توهان جي آڱرين کي ڪيبورڊ تان کڻڻ کان سواء.
اهو ڪو راز ناهي ته صرف هڪ ٽيبل کي حذف ڪرڻ لڳ ڀڳ سڀني ڊيٽابيس ۾ ساڳيو نظر ايندو:
drop table hr.personsپر ٽيبل جي ٺهڻ سان اهو وڌيڪ دلچسپ ٿيندو. تقريبن ڪنهن به DBMS (بشمول ڪيترائي NoSQL) هڪ فارم يا ٻئي ۾ "ٽيبل ٺاهي" ڪري سگهن ٿا، ۽ ان جو مکيه حصو به ٿورو مختلف هوندو (نالو، ڪالمن جي فهرست، ڊيٽا جا قسم)، پر ٻيون تفصيلون ڊرامائي طور تي مختلف ٿي سگهن ٿيون ۽ انحصار ڪري سگهن ٿيون. هڪ مخصوص DBMS جي اندروني ڊوائيس ۽ صلاحيتون. منهنجو پسنديده مثال اهو آهي ته Oracle دستاويزن ۾ صرف "ننگا" BNFs آهن "ٺاهيل ٽيبل" نحو لاءِ . ٻيا ڊي بي ايم ايس ۾ وڌيڪ معمولي صلاحيتون آهن، پر انهن مان هر هڪ ۾ ٽيبل ٺاهڻ لاءِ ڪيتريون ئي دلچسپ ۽ منفرد خاصيتون آهن (, , , ). اهو ممڪن ناهي ته ڪنهن ٻئي IDE (خاص طور تي هڪ آفاقي) مان ڪو به گرافڪ "جادوگر" انهن سڀني صلاحيتن کي مڪمل طور تي ڍڪڻ جي قابل هوندو، ۽ جيتوڻيڪ اهو ٿي سگهي ٿو، اهو دل جي بيوقوف لاء هڪ تماشو نه هوندو. ساڳئي وقت، صحيح ۽ بروقت لکيل بيان ٽيبل ٺاهيو توهان کي انهن سڀني کي آساني سان استعمال ڪرڻ جي اجازت ڏيندو، اسٽوريج ۽ توهان جي ڊيٽا تائين رسائي کي قابل اعتماد، بهتر ۽ ممڪن طور تي آرام سان.
انهي سان گڏ، ڪيترن ئي ڊي بي ايم ايس جي پنهنجي مخصوص قسم جون شيون آهن جيڪي ٻين ڊي بي ايم ايس ۾ موجود نه آهن. ان کان علاوه، اسان آپريشن ڪري سگھون ٿا نه رڳو ڊيٽابيس جي شين تي، پر خود ڊي بي ايم ايس تي پڻ، مثال طور، "مارڻ" ھڪڙو عمل، ڪجھ ميموري ايريا خالي ڪريو، ٽريڪنگ کي چالو ڪريو، "صرف پڙھڻ" موڊ ڏانھن سوئچ ڪريو، ۽ وڌيڪ.
ھاڻي اچو ته ٿورڙو ٺاھيون
سڀ کان وڌيڪ عام ڪمن مان هڪ آهي ڊيٽابيس جي شين سان هڪ ڊراگرام ٺاهڻ ۽ انهن جي وچ ۾ شيون ۽ ڪنيڪشن کي هڪ خوبصورت تصوير ۾ ڏسڻ. تقريبن ڪنهن به گرافڪ IDE، الڳ "ڪمانڊ لائن" افاديت، خاص گرافڪ اوزار ۽ ماڊلرز اهو ڪري سگهن ٿا. اهي توهان جي لاءِ ڪجهه ٺاهيندا “جيترو بهتر اهي ڪري سگهن ٿا” ۽ توهان هن عمل کي ٿورو ئي اثر انداز ڪري سگهو ٿا صرف ڪنفيگريشن فائل ۾ ڪجهه پيرا ميٽرز جي مدد سان يا انٽرفيس ۾ چيڪ بڪس.
پر اهو مسئلو تمام آسان، وڌيڪ لچڪدار ۽ خوبصورت حل ڪري سگهجي ٿو، ۽ يقينا، ڪوڊ جي مدد سان. ڪنهن به پيچيدگيءَ جا ڊاگرام ٺاهڻ لاءِ، اسان وٽ ڪيترائي خاص مارڪ اپ ٻوليون (DOT، GraphML وغيره) آهن ۽ انهن لاءِ ايپليڪيشنن جو هڪ مڪمل پکيڙ (GraphViz، PlantUML، Mermaid) جيڪي اهڙيون هدايتون پڙهي سگهن ٿا ۽ انهن کي مختلف فارميٽ ۾ تصور ڪري سگهن ٿا. . خير، اسان اڳ ۾ ئي ڄاڻون ٿا ته شيون ۽ انهن جي وچ ۾ رابطن بابت معلومات ڪيئن حاصل ڪجي.
هتي هڪ ننڍڙو مثال آهي ته اهو ڪيئن نظر اچي سگهي ٿو، استعمال ڪندي PlantUML ۽ (کاٻي پاسي هڪ SQL سوال آهي جيڪو پلانٽ يو ايم ايل لاءِ گهربل هدايتون ٺاهيندو، ۽ ساڄي پاسي نتيجو آهي):
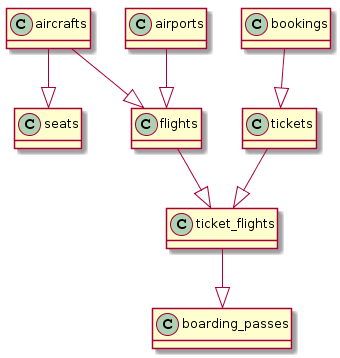
select '@startuml'||chr(10)||'hide methods'||chr(10)||'hide stereotypes' union all
select distinct ccu.table_name || ' --|> ' ||
tc.table_name as val
from table_constraints as tc
join key_column_usage as kcu
on tc.constraint_name = kcu.constraint_name
join constraint_column_usage as ccu
on ccu.constraint_name = tc.constraint_name
where tc.constraint_type = 'FOREIGN KEY'
and tc.table_name ~ '.*' union all
select '@enduml'۽ جيڪڏھن توھان ٿوري ڪوشش ڪريو، پوء بنياد تي توھان حاصل ڪري سگھوٿا ھڪڙي حقيقي ER ڊاگرام سان بلڪل ملندڙ جلندڙ:
SQL سوال ٿورڙو وڌيڪ پيچيده آھي
-- Шапка
select '@startuml
!define Table(name,desc) class name as "desc" << (T,#FFAAAA) >>
!define primary_key(x) <b>x</b>
!define unique(x) <color:green>x</color>
!define not_null(x) <u>x</u>
hide methods
hide stereotypes'
union all
-- Таблицы
select format('Table(%s, "%s n information about %s") {'||chr(10), table_name, table_name, table_name) ||
(select string_agg(column_name || ' ' || upper(udt_name), chr(10))
from information_schema.columns
where table_schema = 'public'
and table_name = t.table_name) || chr(10) || '}'
from information_schema.tables t
where table_schema = 'public'
union all
-- Связи между таблицами
select distinct ccu.table_name || ' "1" --> "0..N" ' || tc.table_name || format(' : "A %s may haven many %s"', ccu.table_name, tc.table_name)
from information_schema.table_constraints as tc
join information_schema.key_column_usage as kcu on tc.constraint_name = kcu.constraint_name
join information_schema.constraint_column_usage as ccu on ccu.constraint_name = tc.constraint_name
where tc.constraint_type = 'FOREIGN KEY'
and ccu.constraint_schema = 'public'
and tc.table_name ~ '.*'
union all
-- Подвал
select '@enduml'
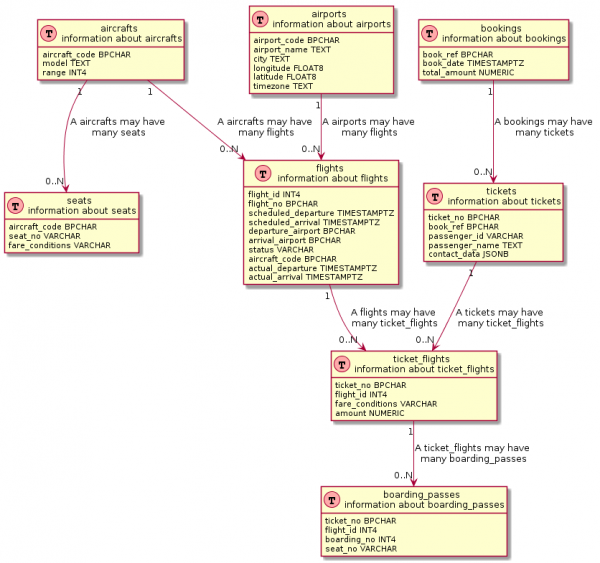
جيڪڏهن توهان ويجهڙائي سان ڏسندا آهيو، هود جي هيٺان ڪيترائي بصري اوزار پڻ ساڳيون سوالن کي استعمال ڪندا آهن. سچ، اهي درخواستون عام طور تي گهڻيون آهن انهن جي ڪنهن به ترميم جو ذڪر نه ڪرڻ.
ميٽرڪ ۽ نگراني
اچو ته هڪ روايتي پيچيده موضوع ڏانهن وڃو - ڊيٽابيس ڪارڪردگي جي نگراني. مون کي هڪ ننڍڙي سچي ڪهاڻي ياد آهي جيڪا مون کي ”منهنجي هڪ دوست“ ٻڌائي هئي. هڪ ٻئي منصوبي تي اتي هڪ خاص طاقتور DBA رهندو هو، ۽ ڪجهه ڊولپرز هن کي ذاتي طور تي ڄاڻن ٿا، يا ڪڏهن به کيس ذاتي طور تي ڏٺو هو (ان حقيقت جي باوجود، افواهون موجب، هن ايندڙ عمارت ۾ ڪم ڪيو). ڪلاڪ "X" تي، جڏهن هڪ وڏي پرچون ڪندڙ جو پوڊڪشن سسٽم هڪ ڀيرو ٻيهر "خراب محسوس ڪرڻ" شروع ڪيو، هن خاموشيء سان Oracle انٽرپرائز مئنيجر کان گرافس جا اسڪرين شاٽ موڪليا، جن تي هن نازڪ هنڌن کي احتياط سان نمايان ڪيو، "سمجهڻ" لاء ڳاڙهي مارڪر سان. هي، ان کي نرمي سان رکڻ لاء، گهڻو مدد نه ڪيو). ۽ هن "فوٽو ڪارڊ" جي بنياد تي مون کي علاج ڪرڻو پيو. ساڳئي وقت، ڪنهن کي به قيمتي (لفظ جي ٻنهي معنائن ۾) انٽرنيشنل مئنيجر تائين رسائي نه هئي، ڇاڪاڻ ته سسٽم پيچيده ۽ مهانگو آهي، اوچتو "ڊولپرز ڪنهن شيء تي ٿڪايو ۽ هر شيء کي ٽوڙي ڇڏيو." تنهن ڪري، ڊولپرز "تجرباتي طور تي" بريڪن جو هنڌ ۽ سبب ڳولي ورتو ۽ هڪ پيچ جاري ڪيو. جيڪڏهن ڊي بي اي جو خطرناڪ خط ويجهي مستقبل ۾ ٻيهر نه آيو ته پوءِ هرڪو راحت جو ساهه کڻندو ۽ پنهنجي موجوده ڪمن ڏانهن موٽندو (نئين خط تائين).
پر مانيٽرنگ جو عمل وڌيڪ مزيدار ۽ دوستانه نظر اچي سگهي ٿو، ۽ سڀ کان اهم، هر ڪنهن لاءِ پهچ ۽ شفاف. گهٽ ۾ گهٽ ان جو بنيادي حصو، مکيه مانيٽرنگ سسٽم جي اضافي جي طور تي (جيڪي يقيناً ڪارآمد آهن ۽ ڪيترن ئي ڪيسن ۾ ناقابل واپسي). ڪو به DBMS آزاد ۽ بلڪل مفت آهي ان جي موجوده حالت ۽ ڪارڪردگي بابت معلومات شيئر ڪرڻ لاءِ. ساڳئي "خوني" Oracle DB ۾، ڪارڪردگي بابت تقريبن ڪا به معلومات حاصل ڪري سگهجي ٿي سسٽم جي نظرن کان، پروسيس ۽ سيشن کان وٺي بفر ڪيش جي حالت تائين (مثال طور، ، سيڪشن "مانيٽرنگ"). Postgresql وٽ پڻ سسٽم جي نظرن جو هڪ سڄو گروپ آهي , خاص طور تي جيڪي ڪنهن به DBA جي روزاني زندگيء ۾ ناگزير آهن، جهڙوڪ , , . MySQL وٽ پڻ ان لاءِ هڪ الڳ اسڪيما آهي. . A In Mongo تعمير ٿيل ڪارڪردگي ڊيٽا کي گڏ ڪري ٿو سسٽم گڏ ڪرڻ ۾ .
اهڙيء طرح، هٿياربند ڪجهه قسم جي ميٽرڪ ڪليڪٽر (Telegraf، Metricbeat، Collectd) جيڪي ڪسٽم sql سوالن کي انجام ڏئي سگھن ٿا، انهن ميٽرن جو ذخيرو (InfluxDB، Elasticsearch، Timescaledb) ۽ هڪ بصريزر (Grafana، Kibana)، توهان حاصل ڪري سگهو ٿا ڪافي آسان. ۽ هڪ لچڪدار مانيٽرنگ سسٽم جيڪو ويجهڙائي سان ٻين سسٽم جي وسيع ميٽرڪس سان ضم ڪيو ويندو (حاصل ڪيل، مثال طور، ايپليڪيشن سرور کان، OS کان، وغيره). جيئن، مثال طور، اهو ڪيو ويو آهي pgwatch2، جيڪو استعمال ڪري ٿو InfluxDB + Grafana ميلاپ ۽ سوالن جو هڪ سيٽ سسٽم جي ڏيک لاءِ، جنهن کي پڻ رسائي سگهجي ٿو. .
ڪل
۽ اهو صرف هڪ تقريبن فهرست آهي جيڪو اسان جي ڊيٽابيس سان باقاعده SQL ڪوڊ استعمال ڪندي ڪري سگهجي ٿو. مون کي پڪ آهي ته توهان ڪيترائي وڌيڪ استعمال ڳوليندا، تبصرن ۾ لکندا. ۽ اسان ان بابت ڳالهائينداسين ته ڪيئن (۽ سڀ کان اهم ڇو) هي سڀ خودڪار ڪرڻ ۽ ان کي ايندڙ وقت توهان جي CI / CD پائپ لائن ۾ شامل ڪيو.
جو ذريعو: www.habr.com
