


منهنجي تقريرن جي بنياد تي Highload++ ۽ DataFest Minsk 2019 تي.
اڄ ڪيترن ئي لاء، ميل آن لائن زندگي جو هڪ لازمي حصو آهي. ان جي مدد سان، اسان ڪاروباري خط و ڪتابت ڪندا آهيون، ماليات، هوٽل جي بکنگ، آرڊر ڏيڻ ۽ گهڻو ڪجهه سان لاڳاپيل هر قسم جي اهم معلومات کي ذخيرو ڪندا آهيون. 2018 جي وچ ۾، اسان ميل ڊولپمينٽ لاءِ پراڊڪٽ جي حڪمت عملي تيار ڪئي. جديد ميل ڇا هجڻ گهرجي؟
ميل ضرور هوندو هوشيار، اهو آهي، صارفين کي معلومات جي وڌندڙ مقدار کي نيويگيٽ ڪرڻ ۾ مدد ڪندي: فلٽر، ساخت ۽ ان کي تمام آسان طريقي سان مهيا ڪريو. هوءَ ضرور هوندي مفيد, توهان کي توهان جي ميل باڪس ۾ مختلف ڪمن کي حل ڪرڻ جي اجازت ڏئي ٿي، مثال طور، ڏنڊ ادا ڪريو (هڪ فنڪشن جيڪو، بدقسمتي سان، مان استعمال ڪريان ٿو). ۽ ساڳئي وقت، يقينا، ميل لازمي طور تي معلومات جي حفاظت، اسپام کي ختم ڪرڻ ۽ هيڪنگ جي خلاف تحفظ فراهم ڪرڻ گهرجي، اهو آهي. محفوظ.
اهي علائقا ڪيترن ئي اهم مسئلن جي وضاحت ڪن ٿا، جن مان ڪيترائي مؤثر طريقي سان حل ڪري سگهجن ٿا مشين سکيا استعمال ڪندي. هتي حڪمت عملي جي حصي طور ترقي يافته اڳ ۾ موجود خاصيتن جا مثال آهن - هڪ هر هدايت لاءِ.
- سمورو جواب. ميل ۾ سمارٽ جواب جي خصوصيت آهي. عصبي نيٽ ورڪ خط جي متن جو تجزيو ڪري ٿو، ان جي معنيٰ ۽ مقصد کي سمجھي ٿو، ۽ نتيجي طور ٽي سڀ کان مناسب جوابي آپشن پيش ڪري ٿو: مثبت، منفي ۽ غير جانبدار. هي خطن جو جواب ڏيڻ وقت وقت بچائڻ ۾ مدد ڪري ٿو، ۽ اڪثر ڪري غير معياري ۽ مزاحيه انداز ۾ جواب ڏيو.
- گروپنگ اي ميلونآن لائن اسٽورن ۾ آرڊر سان لاڳاپيل. اسان اڪثر ڪري آن لائن خريداري ڪندا آهيون، ۽، ضابطي جي طور تي، اسٽور هر آرڊر لاءِ ڪيترائي اي ميل موڪلي سگھن ٿا. مثال طور، AliExpress کان، سڀ کان وڏي خدمت، ھڪڙي آرڊر لاءِ گھڻا اکر ايندا آھن، ۽ اسان حساب ڪيو ته ٽرمينل صورت ۾ انھن جو تعداد 29 تائين پھچي سگھي ٿو. تنھنڪري، Named Entity Recognition ماڊل استعمال ڪندي، اسان آرڊر نمبر ڪڍون ٿا. ۽ متن مان ٻي معلومات ۽ سڀني اکرن کي ھڪڙي سلسلي ۾ گروپ ڪريو. اسان آرڊر بابت بنيادي معلومات هڪ الڳ باڪس ۾ پڻ ڏيکاريون ٿا، جيڪو هن قسم جي اي ميل سان ڪم ڪرڻ آسان بڻائي ٿو.

- فشنگ مخالف. فشنگ خاص طور تي خطرناڪ فريب واري قسم جي اي ميل آهي، جنهن جي مدد سان حملي آور مالي معلومات حاصل ڪرڻ جي ڪوشش ڪندا آهن (جنهن ۾ صارف جا بئنڪ ڪارڊ شامل آهن) ۽ لاگ ان. اھڙا اکر اصل جي نقل ڪن ٿا جيڪي خدمت پاران موڪليا ويا آھن، بشمول بصري طور تي. تنهن ڪري، ڪمپيوٽر ويزن جي مدد سان، اسان وڏين ڪمپنين جي خطن جي لوگو ۽ ڊيزائن جي انداز کي سڃاڻون ٿا (مثال طور، Mail.ru، Sber، Alfa) ۽ ان کي اسان جي اسپام ۽ فشنگ جي درجه بندي ۾ متن ۽ ٻين خاصيتن سان گڏ حساب ۾ رکون ٿا. .
مشيني سکيا
عام طور تي اي ميل ۾ مشين لرننگ بابت ٿورو. ٽپال هڪ تمام گهڻي لوڊ ٿيل سسٽم آهي: هر روز سراسري طور تي 1,5 بلين خط اسان جي سرورن مان 30 ملين DAU استعمال ڪندڙن لاءِ گذري ٿو. اٽڪل 30 مشين لرننگ سسٽم سڀني ضروري ڪمن ۽ خاصيتن جي حمايت ڪن ٿا.
هر خط هڪ پوري درجه بندي پائپ لائن ذريعي وڃي ٿو. پهرين اسان اسپام کي ڪٽي ڇڏيو ۽ سٺيون اي ميلون ڇڏي ڏيو. صارفين اڪثر ڪري اينٽي اسپام جي ڪم کي نوٽيس نه ڪندا آهن، ڇاڪاڻ ته 95-99٪ اسپام به مناسب فولڊر ۾ ختم نه ڪندا آهن. اسپام جي سڃاڻپ اسان جي سسٽم جو هڪ اهم حصو آهي، ۽ سڀ کان وڌيڪ ڏکيو آهي، ڇاڪاڻ ته مخالف اسپام جي ميدان ۾ دفاعي ۽ حملي واري نظام جي وچ ۾ مسلسل موافقت آهي، جيڪو اسان جي ٽيم لاء هڪ مسلسل انجنيئرنگ چئلينج فراهم ڪري ٿو.
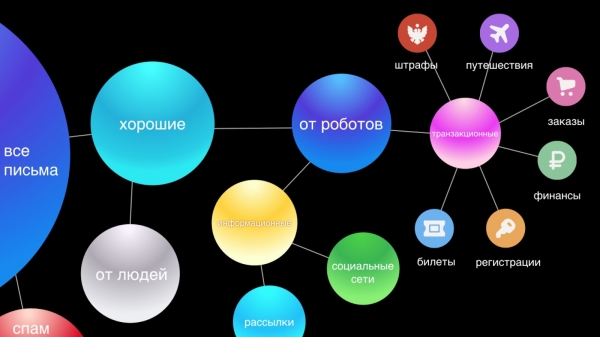
اڳيون، اسان ماڻهن ۽ روبوٽس کان خط الڳ ڪريون ٿا. ماڻهن کان اي ميلون سڀ کان اهم آهن، تنهنڪري اسان انهن لاءِ سمارٽ جواب جھڙا خاصيتون مهيا ڪندا آهيون. روبوٽس کان خط ٻن حصن ۾ ورهايل آهن: ٽرانزيڪشنل - اهي اهم خط آهن خدمتن مان، مثال طور، خريداري جي تصديق يا هوٽل رزرويشن، ماليات، ۽ معلوماتي - اهي ڪاروبار اشتهارن، رعايتون آهن.
اسان يقين رکون ٿا ته ٽرانزيڪشنل اي ميلون ذاتي خط و ڪتابت جي اهميت ۾ برابر آهن. انهن کي هٿ ۾ هجڻ گهرجي، ڇاڪاڻ ته اسان کي اڪثر جلدي جلدي آرڊر يا هوائي ٽڪيٽ جي بکنگ بابت معلومات ڳولڻ جي ضرورت آهي، ۽ اسان انهن خطن جي ڳولا ۾ وقت گذاريندا آهيون. تنهن ڪري، سهولت لاءِ، اسان پاڻمرادو انهن کي ڇهن مکيه ڀاڱن ۾ ورهايون ٿا: سفر، آرڊر، فنانس، ٽڪيٽون، رجسٽريشنون ۽، آخرڪار، ڏنڊ.
معلوماتي خط سڀ کان وڏو ۽ شايد گهٽ اهم گروپ آهن، جن کي فوري جواب جي ضرورت ناهي، ڇو ته صارف جي زندگي ۾ ڪا به اهم تبديلي نه ايندي جيڪڏهن هو اهڙو خط نه پڙهي. اسان جي نئين انٽرفيس ۾، اسان انهن کي ٻن موضوعن ۾ ٽوڙيو ٿا: سماجي نيٽ ورڪ ۽ نيوز ليٽر، اهڙيء طرح انباڪس کي صاف ڪرڻ ۽ صرف اهم پيغامن کي ڏسڻ ۾ ڇڏيندي.
آپريشن
سسٽم جو هڪ وڏو تعداد آپريشن ۾ تمام گهڻيون مشڪلاتون پيدا ڪري ٿو. آخرڪار، ماڊل وقت سان گڏ، ڪنهن به سافٽ ويئر وانگر، خراب ٿي ويندا آهن: خاصيتون ڀڃندا آهن، مشينون ناڪام ٿينديون آهن، ڪوڊ خراب ٿي ويندو آهي. اضافي طور تي، ڊيٽا مسلسل تبديل ٿي رهي آهي: نوان شامل ڪيا ويا آهن، صارف جي رويي جي نمونن کي تبديل ڪيو ويو آهي، وغيره، تنهنڪري هڪ ماڊل مناسب سپورٽ کان سواء خراب ۽ خراب وقت سان ڪم ڪندو.
اسان کي اهو نه وسارڻ گهرجي ته مشيني سکيا جو وڌيڪ گہرا استعمال ڪندڙن جي زندگين ۾ داخل ٿئي ٿو، اوترو وڌيڪ اثر انهن جو ماحولياتي نظام تي آهي، ۽ نتيجي طور، وڌيڪ مالي نقصان يا منافعو مارڪيٽ رانديگرن کي ملي سگهي ٿو. تنهن ڪري، علائقن جي وڌندڙ تعداد ۾، رانديگرن کي ML الگورتھم جي ڪم کي ترتيب ڏئي رهيا آهن (کلاسڪ مثال اشتهارن، ڳولا ۽ اڳ ۾ ئي ذڪر ڪيل اينٽي اسپام).
انهي سان گڏ، مشين سکيا جي ڪمن ۾ هڪ خاصيت آهي: سسٽم ۾ ڪا به، معمولي تبديلي به ماڊل سان تمام گهڻو ڪم پيدا ڪري سگهي ٿي: ڊيٽا سان ڪم ڪرڻ، ٻيهر تربيت، ترتيب ڏيڻ، جيڪو هفتي يا مهينا وٺي سگھي ٿو. تنهن ڪري، تيزيءَ سان ماحول جنهن ۾ توهان جا ماڊل هلن ٿا تبديليون، انهن کي برقرار رکڻ لاءِ وڌيڪ ڪوشش جي ضرورت آهي. هڪ ٽيم تمام گهڻو سسٽم ٺاهي سگهي ٿي ۽ ان بابت خوش ٿي سگهي ٿي، پر پوءِ ان کي برقرار رکڻ لاءِ تقريباً سمورا وسيلا خرچ ڪري ٿي، بغير ڪنهن نئين ڪم ڪرڻ جي. اسان هڪ ڀيرو اينٽي اسپام ٽيم ۾ اهڙي صورتحال سان منهن ڪيو. ۽ انهن اهو واضح نتيجو ڪيو ته سپورٽ کي خودڪار ڪرڻ جي ضرورت آهي.
خودڪار
ڇا خودڪار ٿي سگهي ٿو؟ تقريبن سڀ ڪجهه، حقيقت ۾. مون چار علائقن جي نشاندهي ڪئي آهي جيڪي مشين لرننگ انفراسٽرڪچر کي بيان ڪن ٿا:
- ڊيٽا گڏ ڪرڻ؛
- اضافي تربيت؛
- لڳائڻ؛
- جانچ ۽ نگراني.
جيڪڏهن ماحول غير مستحڪم ۽ مسلسل تبديل ٿي رهيو آهي، ته پوء ماڊل جي چوڌاري سڄو انفراسٹرڪچر پاڻ کي ماڊل کان وڌيڪ اهم آهي. اهو ٿي سگهي ٿو هڪ سٺو پراڻو لڪير ڪلاسيفائير، پر جيڪڏهن توهان ان کي صحيح فيچر ڏيو ٿا ۽ صارفين کان سٺي موٽ حاصل ڪريو ٿا، ته اهو تمام گھنٽي ۽ سيٽين سان گڏ اسٽيٽ آف دي-آرٽ ماڊلز کان گهڻو بهتر ڪم ڪندو.
تبصرو لوپ
هي چڪر گڏ ڪري ٿو ڊيٽا گڏ ڪرڻ، اضافي تربيت ۽ تعیناتي - حقيقت ۾، سڄو ماڊل تازه ڪاري چڪر. اهو ڇو ضروري آهي؟ ميل ۾ رجسٽريشن شيڊول ڏسو:
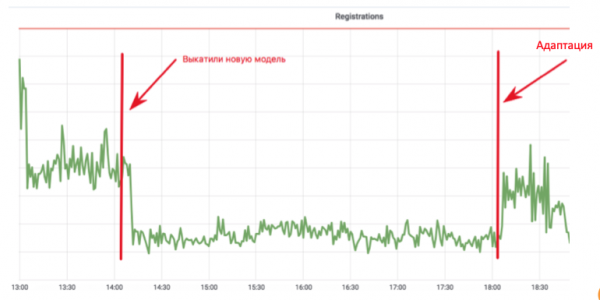
هڪ مشين لرننگ ڊولپر هڪ اينٽي بوٽ ماڊل لاڳو ڪيو آهي جيڪو بوٽس کي اي ميل ۾ رجسٽر ٿيڻ کان روڪي ٿو. گراف هڪ قدر ڏانهن وڌي ٿو جتي صرف حقيقي استعمال ڪندڙ رهن ٿا. هر شي عظيم آهي! پر چار ڪلاڪ گذري ويندا آهن، بوٽ انهن جي اسڪرپٽ کي ٽائيڪ ڪندا آهن، ۽ هر شيء معمول تي موٽندي آهي. هن عمل ۾، ڊولپر هڪ مهينو خرچ ڪيو خاصيتون شامل ڪرڻ ۽ ماڊل کي ٻيهر تربيت ڏيڻ، پر اسپامر چار ڪلاڪن ۾ ترتيب ڏيڻ جي قابل هو.
ايتري قدر ڏکوئيندڙ نه ٿيڻ جي لاءِ ۽ هر شيءِ کي بعد ۾ ٻيهر ڪرڻ نه گهرجي، اسان کي شروعات ۾ سوچڻو پوندو ته راءِ ڏيڻ وارو لوپ ڪهڙو نظر ايندو ۽ جيڪڏهن ماحول بدلجي ٿو ته اسان ڇا ڪنداسين. اچو ته ڊيٽا گڏ ڪرڻ سان شروع ڪريون - هي اسان جي الگورتھم لاءِ تيل آهي.
ڊيٽا گڏ ڪرڻ
اهو واضح آهي ته جديد نيورل نيٽ ورڪن لاء، وڌيڪ ڊيٽا، بهتر، ۽ اهي آهن، حقيقت ۾، پيداوار جي استعمال ڪندڙن پاران ٺاهيل. صارف ڊيٽا کي نشانو بڻائڻ سان اسان جي مدد ڪري سگھن ٿا، پر اسان ان کي غلط استعمال نٿا ڪري سگھون، ڇو ته ڪنھن وقت صارف توھان جي ماڊلز کي مڪمل ڪندي ٿڪجي پوندا ۽ ٻئي پراڊڪٽ ڏانھن سوئچ ڪندا.
سڀ کان وڌيڪ عام غلطين مان هڪ (هتي مان هڪ حوالو ڏيان ٿو اينڊريو اين جي) ٽيسٽ ڊيٽا سيٽ تي ميٽرڪس تي تمام گهڻو ڌيان ڏنو ويو آهي، ۽ صارف جي راء تي نه، جيڪو اصل ۾ ڪم جي معيار جو بنيادي ماپ آهي، ڇاڪاڻ ته اسان ٺاهي رهيا آهيون. استعمال ڪندڙ لاء هڪ پيداوار. جيڪڏهن صارف سمجهي نه ٿو يا ماڊل جي ڪم کي پسند نٿو ڪري، پوء هر شيء برباد ٿي وئي آهي.
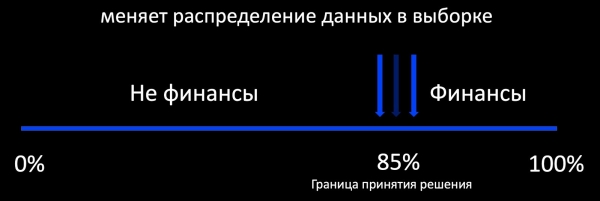
تنهن ڪري، صارف کي هميشه ووٽ ڏيڻ جي قابل هجڻ گهرجي ۽ راء لاء هڪ اوزار ڏنو وڃي. جيڪڏهن اسان سمجهون ٿا ته فنانس سان لاڳاپيل هڪ خط ميل باڪس ۾ اچي ويو آهي، اسان کي ان کي "فنانس" جو نشان ڏيڻو پوندو ۽ هڪ بٽڻ ڪڍڻو پوندو جنهن تي صارف ڪلڪ ڪري سگهي ٿو ۽ چوي ٿو ته اهو فنانس ناهي.
موٽ جي معيار
اچو ته صارف جي راء جي معيار بابت ڳالهايو. پهرين، توهان ۽ استعمال ڪندڙ هڪ تصور ۾ مختلف معنائون رکي سگهو ٿا. مثال طور، توهان ۽ توهان جا پراڊڪٽ مئنيجر سمجهن ٿا ته ”فنانس“ جو مطلب آهي بئنڪ جا خط، ۽ صارف سمجهي ٿو ته ڏاڏي جو خط هن جي پينشن بابت پڻ فنانس ڏانهن اشارو ڪري ٿو. ٻيو، اهڙا صارف آهن جيڪي بغير ڪنهن منطق کان بغير بٽڻ کي دٻائڻ پسند ڪن ٿا. ٽيون، صارف پنهنجي نتيجن ۾ تمام گهڻي غلطي ڪري سگهي ٿو. اسان جي مشق مان هڪ شاندار مثال هڪ طبقي جي عمل کي لاڳو ڪرڻ آهي ، هڪ تمام مضحکہ خیز قسم جو اسپام جتي صارف کي چيو ويو آهي ته آفريڪا ۾ اوچتو مليل ڏورانهن مائٽن کان ڪيترائي ملين ڊالر وٺي. هن درجي بندي کي لاڳو ڪرڻ کان پوء، اسان چيڪ ڪيو "اسپام نه" انهن اي ميلن تي ڪلڪ ڪيو، ۽ اهو ظاهر ٿيو ته انهن مان 80٪ رسيل نائجريائي اسپام هئا، جنهن مان اهو ظاهر ٿئي ٿو ته استعمال ڪندڙ انتهائي غلط ٿي سگهن ٿا.
۽ اچو ته اهو نه وساريو ته بٽڻن کي ڪلڪ ڪري سگهجي ٿو نه رڳو ماڻهن طرفان، پر پڻ سڀني قسمن جي بوٽن طرفان جيڪي برائوزر هجڻ جو مظاهرو ڪن ٿا. تنهنڪري خام راءِ سکڻ لاءِ سٺو ناهي. توهان هن معلومات سان ڇا ڪري سگهو ٿا؟
اسان ٻه طريقا استعمال ڪندا آهيون:
- ڳنڍيل ايم ايل کان موٽ. مثال طور، اسان وٽ هڪ آن لائن اينٽي باٽ سسٽم آهي، جيڪو، جيئن مون ذڪر ڪيو آهي، محدود تعداد جي نشانين جي بنياد تي تڪڙو فيصلو ڪري ٿو. ۽ ھڪڙو ٻيو، سست سسٽم آھي جيڪو حقيقت کان پوء ڪم ڪري ٿو. اهو استعمال ڪندڙ، سندس رويي، وغيره بابت وڌيڪ ڊيٽا آهي. نتيجي طور، سڀ کان وڌيڪ ڄاڻايل فيصلو ڪيو ويو آهي؛ ان جي مطابق، ان جي اعلي درستگي ۽ مڪمل آهي. توھان انھن سسٽم جي آپريشن ۾ فرق کي سڌو ڪري سگھو ٿا پھريون ھڪڙي کي تربيتي ڊيٽا جي طور تي. اهڙيء طرح، هڪ سادي نظام هميشه هڪ کان وڌيڪ پيچيده هڪ جي ڪارڪردگي سان رجوع ڪرڻ جي ڪوشش ڪندو.
- ڪلڪ ڪريو درجه بندي. توهان آساني سان هر صارف جي ڪلڪ کي درجه بندي ڪري سگهو ٿا، ان جي صحيحيت ۽ استعمال جو اندازو لڳائي سگهو ٿا. اسان اهو ڪندا آهيون اينٽي اسپام ميل ۾، استعمال ڪندڙ جي خاصيتن کي استعمال ڪندي، هن جي تاريخ، موڪليندڙ خاصيتون، متن پاڻ ۽ درجه بندي جو نتيجو. نتيجي طور، اسان هڪ خودڪار سسٽم حاصل ڪندا آهيون جيڪو صارف جي راء جي تصديق ڪري ٿو. ۽ جيئن ته ان کي تمام گهڻو گهٽ retrained ڪرڻ جي ضرورت آهي، ان جو ڪم ٻين سڀني نظام لاء بنياد بڻجي سگهي ٿو. هن ماڊل ۾ بنيادي ترجيح صحت واري آهي، ڇاڪاڻ ته غلط ڊيٽا تي ماڊل جي تربيت نتيجن سان ڀريل آهي.
جڏهن اسان ڊيٽا کي صاف ڪري رهيا آهيون ۽ اسان جي ايم ايل سسٽم کي وڌيڪ تربيت ڏئي رهيا آهيون، اسان کي صارفين جي باري ۾ نه وسارڻ گهرجي، ڇاڪاڻ ته اسان لاء، گراف تي هزارين، لکين غلطيون انگ اکر آهن، ۽ صارف لاء، هر بگ هڪ سانحو آهي. انهي حقيقت کان علاوه صارف کي ڪنهن به صورت ۾ توهان جي پيداوار ۾ توهان جي غلطي سان گڏ رهڻ گهرجي، راء حاصل ڪرڻ کان پوء، هن کي اميد آهي ته اهڙي صورتحال مستقبل ۾ ختم ٿي ويندي. تنهن ڪري، اهو هميشه لائق آهي ته صارفين کي نه رڳو ووٽ ڏيڻ جو موقعو ڏيو، پر ايم ايل سسٽم جي رويي کي درست ڪرڻ لاء، ٺاهي، مثال طور، هر راء جي ڪلڪ لاء ذاتي هوريسٽ؛ ميل جي صورت ۾، اهو ٿي سگهي ٿو فلٽر ڪرڻ جي صلاحيت هن صارف لاءِ موڪليندڙ ۽ عنوان طرفان اهڙا اکر.
توهان کي پڻ ڪجهه رپورٽن جي بنياد تي ماڊل ٺاهڻ جي ضرورت آهي يا نيم-خودڪار يا دستي موڊ ۾ سپورٽ ڪرڻ لاءِ درخواستون ته جيئن ٻيا استعمال ڪندڙ ساڳين مسئلن جو شڪار نه ٿين.
سکيا لاءِ هوريسٽ
انهن ۾ ٻه مسئلا آهن هيرسٽسٽس ۽ ڪرچس. پهرين ڳالهه اها آهي ته ڪچين جي وڌندڙ تعداد کي برقرار رکڻ ڏکيو آهي، انهن جي معيار ۽ ڪارڪردگي کي ڊگهي عرصي دوران ڇڏي ڏيو. ٻيو مسئلو اهو آهي ته غلطي بار بار نه ٿي سگهي ٿي، ۽ ماڊل کي وڌيڪ تربيت ڏيڻ لاء ڪجهه ڪلڪ ڪافي نه هوندا. اهو لڳي ٿو ته اهي ٻه غير لاڳاپيل اثرات خاص طور تي غير جانبدار ٿي سگهن ٿيون جيڪڏهن هيٺين طريقي سان لاڳو ڪيو وڃي.
- اسان هڪ عارضي ڪرچ ٺاهيندا آهيون.
- اسان ان مان ڊيٽا موڪليندا آهيون ماڊل ڏانهن، اهو باقاعده پاڻ کي اپڊيٽ ڪري ٿو، بشمول حاصل ڪيل ڊيٽا تي. هتي، يقينا، اهو ضروري آهي ته هوريسٽسٽس کي اعلي درستگي حاصل آهي جيئن ته ٽريننگ سيٽ ۾ ڊيٽا جي معيار کي گهٽائڻ نه گهرجي.
- پوءِ اسان مانيٽرنگ کي سيٽ ڪريون ٿا ڪچري کي ٽاريڻ لاءِ، ۽ جيڪڏهن ڪجهه وقت کان پوءِ ڪرچ ڪم نه ڪري ۽ مڪمل نموني سان ڍڪيل هجي ته پوءِ توهان ان کي محفوظ طور تي هٽائي سگهو ٿا. هاڻي اهو مسئلو ٻيهر ٿيڻ جو امڪان ناهي.
تنهنڪري ڪچين جي فوج تمام مفيد آهي. بنيادي شيء اها آهي ته انهن جي خدمت تڪڙو آهي ۽ مستقل ناهي.
اضافي تربيت
Retraining نئين ڊيٽا شامل ڪرڻ جو عمل آهي جيڪو صارفين يا ٻين سسٽم جي موٽ جي نتيجي ۾ حاصل ڪيو ويو آهي، ۽ ان تي موجوده ماڊل کي تربيت ڏيڻ. اضافي تربيت سان ڪيترائي مسئلا ٿي سگھن ٿا:
- ماڊل شايد اضافي تربيت جي حمايت نه ڪري سگھي، پر صرف شروعات کان سکيو.
- فطرت جي ڪتاب ۾ ڪٿي به اهو نه لکيو ويو آهي ته اضافي تربيت ضرور پيداوار ۾ ڪم جي معيار کي بهتر بڻائي سگهندي. گهڻو ڪري سامهون اچي ٿو، اهو آهي، صرف خراب ٿيڻ ممڪن آهي.
- تبديليون غير متوقع ٿي سگهن ٿيون. هي هڪ بلڪه نازڪ نقطو آهي جنهن کي اسان پاڻ لاءِ سڃاڻي چڪا آهيون. جيتوڻيڪ جيڪڏهن هڪ A/B ٽيسٽ ۾ هڪ نئون نمونو ساڳيو نتيجو ڏيکاري ٿو موجوده هڪ جي مقابلي ۾، ان جو مطلب اهو ناهي ته اهو هڪجهڙائي سان ڪم ڪندو. انهن جو ڪم صرف هڪ سيڪڙو ۾ مختلف ٿي سگهي ٿو، جيڪي نئين غلطيون آڻي سگهن ٿيون يا پراڻيون جيڪي اڳ ۾ ئي درست ڪيون ويون آهن واپس آڻين. ٻئي اسان ۽ استعمال ڪندڙ اڳ ۾ ئي ڄاڻون ٿا ته موجوده غلطين سان ڪيئن رهڻو آهي، ۽ جڏهن نئين غلطين جو هڪ وڏو تعداد پيدا ٿئي ٿو، صارف شايد اهو نه سمجهي سگهي ٿو ته ڇا ٿي رهيو آهي، ڇاڪاڻ ته هو اڳڪٿي واري رويي جي توقع ڪري ٿو.
تنهن ڪري، اضافي تربيت ۾ سڀ کان اهم شيء اهو آهي ته ماڊل بهتر ٿي چڪو آهي، يا گهٽ ۾ گهٽ خراب ناهي.
پهرين شيء جيڪا ذهن ۾ اچي ٿي جڏهن اسان اضافي تربيت جي باري ۾ ڳالهايون ٿا فعال سکيا وارو طريقو. هن جو مطلب ڇا آهي؟ مثال طور، درجه بندي ڪندڙ اهو طئي ڪري ٿو ته ڇا هڪ اي ميل فنانس سان لاڳاپيل آهي، ۽ ان جي فيصلي جي حد جي چوڌاري اسان ليبل ٿيل مثالن جو هڪ نمونو شامل ڪندا آهيون. اهو سٺو ڪم ڪري ٿو، مثال طور، اشتهارن ۾، جتي تمام گهڻو موٽ آهي ۽ توهان ماڊل کي آن لائن ٽريننگ ڪري سگهو ٿا. ۽ جيڪڏهن ٿورڙي راءِ آهي، ته پوءِ اسان حاصل ڪندا آهيون انتهائي باصلاحيت نموني پيداواري ڊيٽا جي ورڇ جي حوالي سان، جنهن جي بنياد تي آپريشن دوران ماڊل جي رويي جو اندازو لڳائڻ ناممڪن آهي.
حقيقت ۾، اسان جو مقصد پراڻن نمونن کي محفوظ ڪرڻ، اڳ ۾ ئي ڄاڻايل ماڊل، ۽ نوان حاصل ڪرڻ آهي. تسلسل هتي اهم آهي. ماڊل، جنهن کي اسان اڪثر ڪري ٻاهر نڪرڻ لاء وڏي تڪليف ورتي، اڳ ۾ ئي ڪم ڪري رهيو آهي، تنهنڪري اسان ان جي ڪارڪردگي تي ڌيان ڏئي سگهون ٿا.
ميل ۾ مختلف ماڊل استعمال ڪيا ويا آهن: وڻ، لڪير، نيورل نيٽ ورڪ. هر هڪ لاءِ اسان پنهنجو پنهنجو اضافي تربيتي الگورتھم ٺاهيندا آهيون. اضافي تربيت جي عمل ۾، اسان نه رڳو نئين ڊيٽا حاصل ڪندا آهيون، پر اڪثر نيون خاصيتون پڻ، جن کي اسين هيٺ ڏنل سڀني الگورتھم ۾ حساب ۾ آڻينداسين.
لائين ماڊلز
اچو ته اسان وٽ لوجسٽڪ ريگريشن آهي. اسان ھيٺ ڏنل اجزاء مان نقصان جو نمونو ٺاھيو ٿا:
- نئين ڊيٽا تي LogLoss؛
- اسان نئين خاصيتن جي وزن کي باقاعده ڪريون ٿا (اسان پراڻين کي هٿ نه ٿا ڪريون)؛
- پراڻن نمونن کي محفوظ ڪرڻ لاءِ اسان پراڻي ڊيٽا مان پڻ سکندا آهيون؛
- ۽، شايد، سڀ کان اهم شيء: اسان هارمونڪ ريگيولرائيزيشن شامل ڪندا آهيون، جيڪا ضمانت ڏئي ٿي ته وزن گهڻو ڪري تبديل نه ٿيندو پراڻي ماڊل جي ڀيٽ ۾ معمول مطابق.
جيئن ته هر نقصان جي جزن ۾ ڪوفيفينٽ هوندا آهن، اسان پنهنجي ڪم لاءِ بهتر قدر چونڊي سگھون ٿا پار-تصديق ذريعي يا پيداوار جي گهرجن جي بنياد تي.
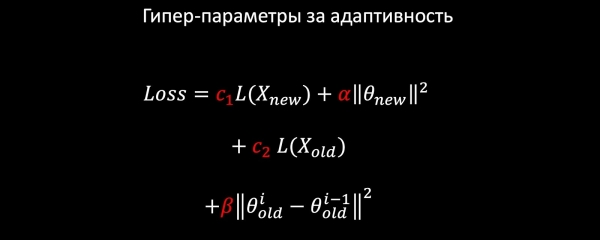
درجا
اچو ته فيصلي جي وڻ ڏانهن وڃو. اسان وڻن جي اضافي تربيت لاءِ هيٺيون الگورتھم مرتب ڪيو آهي:
- پيداوار 100-300 وڻن جو هڪ ٻيلو هلندو آهي، جيڪو هڪ پراڻي ڊيٽا سيٽ تي تربيت ڏني وئي آهي.
- آخر ۾ اسان M = 5 ٽڪر ڪڍيون ٿا ۽ 2M = 10 نوان شامل ڪريون ٿا، پوري ڊيٽا سيٽ تي تربيت يافته، پر نئين ڊيٽا لاءِ وڏي وزن سان، جيڪا قدرتي طور تي ماڊل ۾ وڌندڙ تبديلي جي ضمانت ڏئي ٿي.
ظاهر آهي، وقت سان گڏ، وڻن جو تعداد تمام گهڻو وڌي ٿو، ۽ وقت کي پورو ڪرڻ لاء انهن کي وقتي طور تي گهٽايو وڃي. ائين ڪرڻ لاءِ، اسان استعمال ڪريون ٿا ھاڻي عام علم جي تذليل (KD). ان جي آپريشن جي اصول جي باري ۾ مختصر طور.
- اسان وٽ موجوده "پيچيده" ماڊل آهي. اسان ان کي ٽريننگ ڊيٽا سيٽ تي هلائيندا آهيون ۽ حاصل ڪريون ٿا ڪلاس جي امڪاني ورهاست جي پيداوار تي.
- اڳيون، اسان شاگردن جي ماڊل کي تربيت ڏيون ٿا (هن صورت ۾ گهٽ وڻن سان ماڊل) ماڊل جي نتيجن کي ورجائي ڪلاس جي تقسيم کي ٽارگيٽ متغير طور استعمال ڪندي.
- هتي اهو نوٽ ڪرڻ ضروري آهي ته اسان ڊيٽا سيٽ مارڪ اپ کي ڪنهن به طريقي سان استعمال نٿا ڪريون، ۽ ان ڪري اسان پنهنجي مرضي مطابق ڊيٽا استعمال ڪري سگهون ٿا. يقينن، اسان شاگردن جي ماڊل لاءِ تربيتي نموني طور جنگي وهڪرو مان ڊيٽا جو نمونو استعمال ڪريون ٿا. اهڙيء طرح، ٽريننگ سيٽ اسان کي ماڊل جي درستگي کي يقيني بڻائڻ جي اجازت ڏئي ٿو، ۽ وهڪرو نموني پيداوار جي تقسيم تي ساڳئي ڪارڪردگي جي ضمانت ڏئي ٿي، ٽريننگ سيٽ جي تعصب لاء معاوضي.
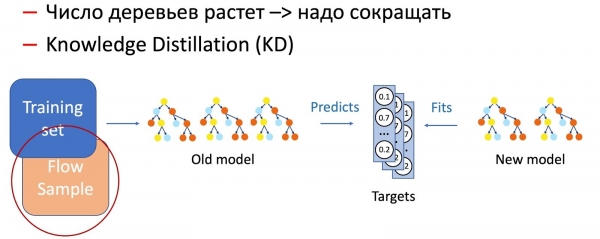
انهن ٻن طريقن جو ميلاپ (وڻ شامل ڪرڻ ۽ وقتي طور تي انهن جي تعداد کي نالج ڊيسٽليشن استعمال ڪندي گھٽائڻ) نئين نمونن جي تعارف ۽ مڪمل تسلسل کي يقيني بڻائي ٿو.
KD جي مدد سان، اسان ماڊل فيچرز تي مختلف آپريشن پڻ ڪندا آھيون، جھڙوڪ خصوصيتن کي ختم ڪرڻ ۽ خالن تي ڪم ڪرڻ. اسان جي حالت ۾، اسان وٽ ڪيترائي اهم شمارياتي خاصيتون آهن (موڪلندڙن، ٽيڪسٽ هيشز، URLs، وغيره) جيڪي ڊيٽابيس ۾ ذخيرو ٿيل آهن، جيڪي ناڪام ٿيڻ جي ڪوشش ڪندا آهن. ماڊل، يقينا، واقعن جي اهڙي ترقي لاء تيار ناهي، ڇو ته ناڪامي حالتن جي تربيت جي سيٽ ۾ نه ٿينديون آهن. اهڙين حالتن ۾، اسان KD ۽ واڌاري جي ٽيڪنڪ کي گڏ ڪريون ٿا: جڏهن ڊيٽا جي هڪ حصي لاءِ ٽريننگ ڪريون ٿا، اسان ضروري خصوصيتن کي هٽائي يا ري سيٽ ڪريون ٿا، ۽ اسان اصل ليبل (موجوده ماڊل جا آئوٽ پُٽ) وٺون ٿا، ۽ شاگرد ماڊل ان ورڇ کي ورجائڻ سکي ٿو. .
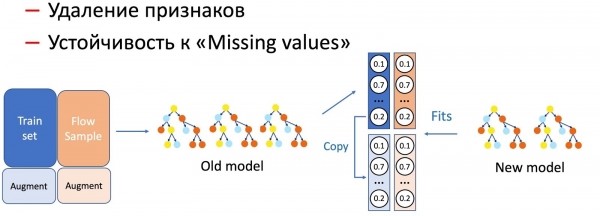
اسان محسوس ڪيو ته وڌيڪ سنگين نموني جي ڦيرڦار ٿئي ٿي، ڌاڳو نموني جو وڏو سيڪڙو گهربل.
خصوصيت کي ختم ڪرڻ، آسان ترين آپريشن، وهڪري جي صرف هڪ ننڍڙي حصي جي ضرورت آهي، ڇاڪاڻ ته صرف ٻه خاصيتون تبديل ٿيون، ۽ موجوده ماڊل ساڳئي سيٽ تي تربيت ڪئي وئي - فرق گهٽ ۾ گهٽ آهي. ماڊل کي آسان ڪرڻ لاءِ (وڻن جي تعداد کي ڪيترائي ڀيرا گھٽائڻ)، 50 کان 50 اڳ ۾ ئي گھربل آھي. ۽ اھم شمارياتي خصوصيتن کي ڇڏڻ لاءِ جيڪي ماڊل جي ڪارڪردگيءَ تي سخت اثر انداز ٿين ٿيون، ان لاءِ اڃا به وڌيڪ وهڪري جي ضرورت آھي. سڀني قسمن جي اکرن تي نئين اوميشن-مزاحمتي ماڊل.
فاسٽ ٽيڪسٽ
اچو ته FastText ڏانهن وڃو. مان توهان کي ياد ڏياران ٿو ته هڪ لفظ جي نمائندگي (Embedding) لفظ جي سرايت جي مجموعن تي مشتمل آهي ۽ ان جي سڀني اکر N-grams، عام طور تي ٽرگرام. جيئن ته اتي ڪافي ٽريگرام ٿي سگھي ٿو، بالٽ هشنگ استعمال ڪيو ويندو آھي، اھو آھي، سڄي جڳھ کي ھڪڙي مقرر ڪيل ھش ميپ ۾ تبديل ڪرڻ. نتيجي طور، وزن ميٽرڪس حاصل ڪئي وئي آھي اندروني پرت جي طول و عرض سان في نمبر لفظن + بالٽ.
اضافي تربيت سان، نوان نشان ظاهر ٿيندا آهن: لفظ ۽ ٽرگرام. Facebook مان معياري پيروي ڪرڻ واري تربيت ۾ ڪجھ به اهم نه ٿيندو. صرف پراڻا وزن ڪراس-انٽروپي سان گڏ نئين ڊيٽا تي ٻيهر تربيت ڏني وئي آهي. اهڙيء طرح، نوان خاصيتون استعمال نه ڪيا ويا آهن؛ يقينا، هن طريقي سان پيداوار ۾ ماڊل جي غير متوقعيت سان لاڳاپيل سڀني مٿين بيان ڪيل نقصانات آهن. ان ڪري اسان FastText کي ٿورو تبديل ڪيو. اسان سڀ نوان وزن (لفظ ۽ ٽرگرام) شامل ڪريون ٿا، پوري ميٽرڪس کي ڪراس-انٽراپي سان وڌايو ۽ لينئر ماڊل سان قياس ڪندي هارمونڪ ريگيولرائيزيشن شامل ڪريون، جيڪا پراڻي وزن ۾ غير معمولي تبديلي جي ضمانت ڏئي ٿي.

اين
Convolutional نيٽ ورڪ ٿورو وڌيڪ پيچيده آهن. جيڪڏهن آخري پرت سي اين اين ۾ مڪمل ٿي ويا آهن، پوء، يقينا، توهان هارمونڪ باقاعده لاڳو ڪري سگهو ٿا ۽ تسلسل جي ضمانت ڏئي سگهو ٿا. پر جيڪڏهن پوري نيٽ ورڪ جي اضافي تربيت جي ضرورت آهي، ته پوء اهڙي ريگيوليشن هاڻي سڀني تہن تي لاڳو نه ٿو ڪري سگهجي. تنهن هوندي، اتي هڪ اختيار آهي ته ٽرينپلٽ نقصان ().
ٽي ڀيرا نقصان
هڪ اينٽي فشنگ ٽاسڪ کي مثال طور استعمال ڪندي، اچو ته عام اصطلاحن ۾ Triplet Loss کي ڏسو. اسان پنهنجو لوگو وٺون ٿا، گڏوگڏ ٻين ڪمپنين جي لوگو جا مثبت ۽ منفي مثال. اسان پهرين جي وچ ۾ فاصلو گھٽائي ڇڏيو ۽ سيڪنڊ جي وچ ۾ فاصلو وڌايو، اسان هن کي ننڍڙي خال سان ڪندا آهيون طبقن جي وڌيڪ جامعيت کي يقيني بڻائڻ لاء.
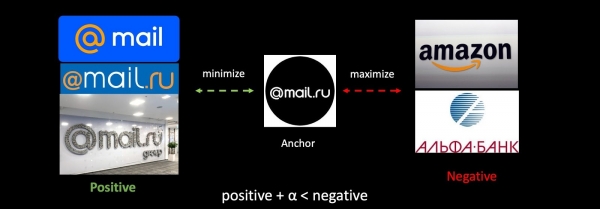
جيڪڏهن اسان نيٽ ورڪ کي وڌيڪ تربيت ڏيون ٿا، ته پوء اسان جي ميٽرڪ اسپيس مڪمل طور تي تبديل ٿي ويندي آهي، ۽ اهو مڪمل طور تي اڳئين سان مطابقت نه رکندو آهي. اهو مسئلن ۾ هڪ سنگين مسئلو آهي جيڪو ویکٹر استعمال ڪن ٿا. هن مسئلي جي چوڌاري حاصل ڪرڻ لاء، اسان ٽريننگ دوران پراڻي ايمبيڊنگ ۾ ملائينداسين.
اسان ٽريننگ سيٽ ۾ نئون ڊيٽا شامل ڪيو آهي ۽ ماڊل جي ٻئي ورزن کي شروع کان تربيت ڏئي رهيا آهيون. ٻئي مرحلي تي، اسان اسان جي نيٽ ورڪ کي وڌيڪ تربيت ڏيون ٿا (Finetuning): پهرين آخري پرت مڪمل ٿئي ٿي، ۽ پوء سڄو نيٽ ورڪ اڻڄاتل آهي. ٽرپلٽس ٺاهڻ جي عمل ۾، اسان صرف تربيتي ماڊل استعمال ڪندي ايمبيڊنگ جو هڪ حصو ڳڻيو، باقي - پراڻي استعمال ڪندي. ان ڪري، اضافي تربيت جي عمل ۾، اسان ميٽرڪ اسپيس v1 ۽ v2 جي مطابقت کي يقيني بڻائيندا آهيون. هارمونڪ ريگولرائزيشن جو هڪ منفرد نسخو.
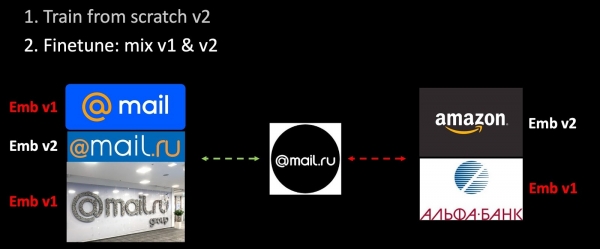
سڄو فن تعمير
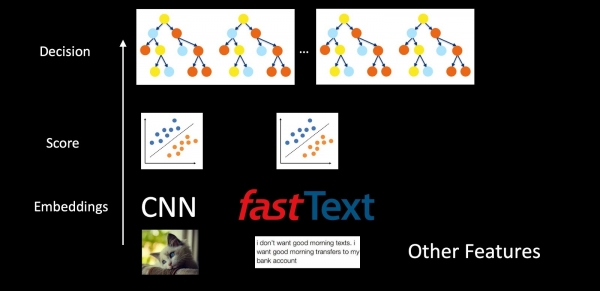
جيڪڏهن اسان هڪ مثال طور antispam استعمال ڪندي سڄي سسٽم تي غور ڪيو، پوء ماڊل الڳ الڳ نه آهن، پر هڪ ٻئي جي اندر اندر رکيل آهن. اسان CNN ۽ فاسٽ ٽيڪسٽ استعمال ڪندي تصويرون، ٽيڪسٽ ۽ ٻيون خاصيتون وٺون ٿا. اڳيون، طبقن کي لاڳو ڪيو ويو آهي سرايت جي چوٽي تي، جيڪي مختلف طبقن لاءِ اسڪور مهيا ڪن ٿا (خطن جا قسم، اسپام، لوگو جي موجودگي). حتمي فيصلي لاءِ نشانيون ۽ نشانيون اڳ ۾ ئي وڻن جي جنگل ۾ داخل ٿي رهيون آهن. هن اسڪيم ۾ انفرادي درجه بندي ڪندڙ اهو ممڪن بڻائي ٿو ته سسٽم جي نتيجن جي بهتر تشريح ڪرڻ ۽ خاص طور تي مسئلن جي صورت ۾ اجزاء کي ٻيهر تربيت ڏيڻ بجاءِ ، سڀني ڊيٽا کي خام فارم ۾ فيصلي واري وڻ ۾ فيڊ ڪرڻ بدران.
نتيجي طور، اسان هر سطح تي تسلسل جي ضمانت ڏيون ٿا. CNN ۽ فاسٽ ٽيڪسٽ ۾ هيٺئين سطح تي اسان هارمونڪ ريگولرائيزيشن استعمال ڪندا آهيون، وچ ۾ درجه بندي ڪندڙن لاءِ اسان امڪاني تقسيم جي تسلسل لاءِ هارمونڪ ريگولرائيزيشن ۽ ريٽ ڪليبريشن پڻ استعمال ڪندا آهيون. خير، وڻن جي واڌ ويجهه سان تربيت ڪئي ويندي آهي يا علم وسعت کي استعمال ڪندي.
عام طور تي، اهڙي نسٽڊ مشين لرننگ سسٽم کي برقرار رکڻ عام طور تي هڪ درد هوندو آهي، ڇاڪاڻ ته هيٺين سطح تي ڪو به جزو مٿي جي سڄي سسٽم کي اپڊيٽ ڪري ٿو. پر جيئن ته اسان جي سيٽ اپ ۾ هر جزو ٿورڙو تبديل ٿئي ٿو ۽ پوئين هڪ سان مطابقت رکي ٿو، سڄي سسٽم کي مڪمل ڍانچي کي ٻيهر تربيت ڏيڻ جي ضرورت کان سواء ٽڪرا ٽڪرا اپڊيٽ ڪري سگهجي ٿو، جيڪا ان کي بغير ڪنهن سنجيده اوور هيڊ جي سپورٽ ڪرڻ جي اجازت ڏئي ٿي.
مقرر ڪرڻ
اسان ڊيٽا گڏ ڪرڻ ۽ مختلف قسم جي ماڊلز جي اضافي تربيت تي بحث ڪيو آهي، تنهنڪري اسان انهن کي پيداوار جي ماحول ۾ ترتيب ڏيڻ تي اڳتي وڌي رهيا آهيون.
A/B جاچ
جيئن مون اڳ ۾ چيو آهي، ڊيٽا گڏ ڪرڻ جي عمل ۾، اسان عام طور تي هڪ باصلاحيت نموني حاصل ڪندا آهيون، جنهن مان ماڊل جي پيداوار جي ڪارڪردگي جو اندازو لڳائڻ ناممڪن آهي. تنهن ڪري، جڏهن ترتيب ڏيڻ، ماڊل کي اڳئين ورزن سان مقابلو ڪرڻ گهرجي انهي کي سمجهڻ لاء ته شيون اصل ۾ ڪيئن ٿي رهيون آهن، اهو آهي، A/B ٽيسٽ کي منظم ڪريو. حقيقت ۾، چارٽ ڪڍڻ ۽ تجزيو ڪرڻ جو عمل ڪافي معمولي آهي ۽ آساني سان خودڪار ٿي سگهي ٿو. اسان پنھنجي ماڊلز کي بتدريج 5٪، 30٪، 50٪ ۽ 100٪ استعمال ڪندڙن تائين پھچائيندا آھيون، جڏھن ته ماڊل جي جوابن ۽ صارفن جي راءِ تي موجود مڙني ميسرن کي گڏ ڪندي. ڪجھ سنجيده آئوٽليرز جي صورت ۾، اسان خودڪار طريقي سان ماڊل کي واپس آڻينداسين، ۽ ٻين ڪيسن لاء، ڪافي تعداد ۾ صارف جي ڪلڪن کي گڏ ڪري، اسان فيصد کي وڌائڻ جو فيصلو ڪيو. نتيجي طور، اسان نئين ماڊل کي مڪمل طور تي خودڪار طريقي سان استعمال ڪندڙن جي 50٪ تائين آڻينداسين، ۽ سڄي سامعين لاء رول آئوٽ هڪ شخص طرفان منظور ڪيو ويندو، جيتوڻيڪ اهو قدم خودڪار ٿي سگهي ٿو.
بهرحال، A/B جاچ واري عمل کي بهتر ڪرڻ لاءِ ڪمرو پيش ڪري ٿو. حقيقت اها آهي ته ڪو به A/B ٽيسٽ تمام ڊگهو هوندو آهي (اسان جي صورت ۾ اهو 6 کان 24 ڪلاڪن تائين وٺندو آهي راءِ جي مقدار جي لحاظ سان)، جيڪو ان کي ڪافي مهانگو ۽ محدود وسيلن سان ڪري ٿو. ان کان علاوه، ٽيسٽ لاءِ وهڪري جو ڪافي تيز فيصد لازمي طور تي A/B ٽيسٽ جي مجموعي وقت کي تيز ڪرڻ جي ضرورت آهي (مئٽرڪ کي ننڍي فيصد تي ويجهڙائي ڪرڻ لاءِ شمارياتي لحاظ کان اهم نموني کي ڀرتي ڪرڻ تمام ڊگهو وقت وٺي سگھي ٿو)، جنهن ڪري A/B سلاٽ جو تعداد انتهائي محدود. ظاهر آهي، اسان کي صرف سڀ کان وڌيڪ پرعزم ماڊلز کي جانچڻ جي ضرورت آهي، جن مان اسان کي اضافي تربيتي عمل دوران گهڻو ڪجهه ملي ٿو.
هن مسئلي کي حل ڪرڻ لاءِ، اسان هڪ الڳ درجه بندي کي تربيت ڏني جيڪا A/B ٽيسٽ جي ڪاميابي جي اڳڪٿي ڪري ٿي. هن کي ڪرڻ لاءِ، اسان وٺون ٿا فيصلا سازي جا انگ اکر، درستي، يادگيري ۽ ٻيا ميٽرڪ ٽريننگ سيٽ تي، ملتوي ڪيل هڪ تي، ۽ نموني تي اسٽريم مان فيچرز طور. اسان پڻ ماڊل جي مقابلي ۾ موجوده ھڪڙي سان پيداوار ۾، ھيورسٽڪس سان، ۽ ماڊل جي پيچيدگي کي حساب ۾ رکون ٿا. انهن سڀني خاصيتن کي استعمال ڪندي، ٽيسٽ جي تاريخ تي تربيت حاصل ڪندڙ هڪ درجي بندي ڪندڙ اميدوارن جي ماڊلز جو جائزو وٺي ٿو، اسان جي صورت ۾ اهي وڻن جا ٻيلا آهن، ۽ فيصلو ڪري ٿو ته A/B ٽيسٽ ۾ ڪهڙو استعمال ڪجي.
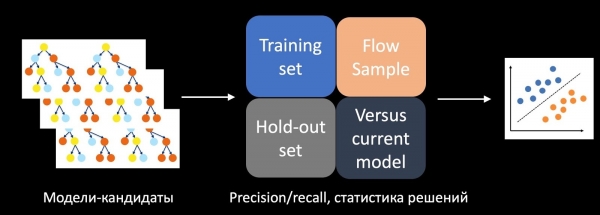
عمل درآمد جي وقت، هن طريقي سان اسان کي ڪامياب A/B ٽيسٽن جو تعداد ڪيترائي ڀيرا وڌائڻ جي اجازت ڏني.
چڪاس ۽ نگراني
جانچ ۽ نگراني، عجيب طور تي، اسان جي صحت کي نقصان نه پهچايو؛ بلڪه، ان جي برعڪس، اهي ان کي بهتر ڪن ٿا ۽ اسان کي غير ضروري دٻاء کان بچائين ٿا. جاچ توهان کي ناڪامي کي روڪڻ جي اجازت ڏئي ٿي، ۽ نگراني توهان کي وقت ۾ ان کي ڳولڻ جي اجازت ڏئي ٿي صارفين تي اثر کي گهٽائڻ لاء.
هتي اهو سمجهڻ ضروري آهي ته جلدي يا بعد ۾ توهان جو سسٽم هميشه غلطيون ڪندو - اهو ڪنهن به سافٽ ويئر جي ترقي جي چڪر جي سبب آهي. سسٽم ڊولپمينٽ جي شروعات ۾ هميشه تمام گهڻا ڪيڙا هوندا آهن جيستائين سڀ ڪجهه ٺهڪي اچي ۽ جدت جو بنيادي مرحلو مڪمل ٿئي. پر وقت گذرڻ سان گڏ، اينٽروپي پنهنجو اثر وٺي ٿي، ۽ غلطيون ٻيهر ظاهر ٿينديون آهن - چوڌاري اجزاء جي تباهي ۽ ڊيٽا ۾ تبديلين جي ڪري، جنهن بابت مون شروعات ۾ ڳالهايو.
هتي مان اهو نوٽ ڪرڻ چاهيان ٿو ته ڪنهن به مشين لرننگ سسٽم کي ان جي فائدي جي نقطي نظر کان غور ڪيو وڃي ته ان جي سڄي زندگي چڪر دوران. هيٺ ڏنل گراف هڪ مثال ڏيکاري ٿو ته سسٽم هڪ نادر قسم جي اسپام کي پڪڙڻ لاء ڪيئن ڪم ڪري ٿو (گراف ۾ لائن صفر جي ويجهو آهي). هڪ ڏينهن، غلط ڪيش ڪيل وصف جي ڪري، هوء چريو ٿي وئي. جيئن ته قسمت هجي ها، غير معمولي ٽرگرنگ لاءِ ڪا به نگراني نه هئي؛ نتيجي طور، سسٽم خطن کي وڏي مقدار ۾ محفوظ ڪرڻ شروع ڪيو ”اسپام“ فولڊر ۾ فيصلو ڪرڻ واري حد تي. نتيجن کي درست ڪرڻ جي باوجود، سسٽم اڳ ۾ ئي ڪيترائي ڀيرا غلطي ڪئي آهي ته اهو پنجن سالن ۾ به پاڻ کي ادا نه ڪندو. ۽ هن نموني جي زندگيء جي چڪر جي نقطي نظر کان هڪ مڪمل ناڪامي آهي.
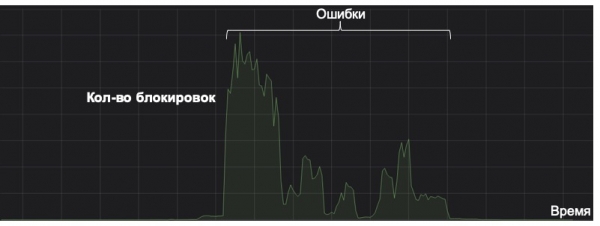
تنهن ڪري، اهڙي سادي شيء جيئن مانيٽرنگ هڪ ماڊل جي زندگيء ۾ اهم ٿي سگهي ٿو. معياري ۽ واضح ميٽرڪس جي اضافي ۾، اسان ماڊل جي جوابن ۽ سکور جي ورڇ تي غور ڪندا آهيون، انهي سان گڏ اهم خصوصيت جي قدرن جي ورڇ. KL divergence استعمال ڪندي، اسان موجوده ورڇ کي تاريخي هڪ سان يا A/B ٽيسٽ ۾ موجود قدرن کي باقي وهڪري سان ڀيٽي سگھون ٿا، جيڪو اسان کي اجازت ڏئي ٿو ته ماڊل ۾ بي ضابطگين کي نوٽيس ڪري ۽ بروقت تبديلين کي واپس آڻي سگهون.
اڪثر صورتن ۾، اسان اسان جي سسٽم جا پھريون ورجن لانچ ڪندا آھيون سادي ھيرسٽڪس يا ماڊل استعمال ڪندي جيڪي اسان مستقبل ۾ مانيٽرنگ طور استعمال ڪندا آھيون. مثال طور، اسان مخصوص آن لائن اسٽورن لاءِ باقاعده وارن جي مقابلي ۾ NER ماڊل جي نگراني ڪندا آهيون، ۽ جيڪڏهن درجه بندي ڪوريج انهن جي مقابلي ۾ گهٽجي ٿي، ته پوءِ اسان سببن کي سمجهون ٿا. heuristics جو ٻيو مفيد استعمال!
نتيجو
اچو ته مضمون جي اهم خيالن تي ٻيهر وڃو.
- فبڊيڪ. اسان هميشه صارف بابت سوچيو ٿا: هو اسان جي غلطين سان ڪيئن رهندو، ڪيئن هو انهن کي رپورٽ ڪرڻ جي قابل هوندو. اهو نه وساريو ته صارف ٽريننگ ماڊلز لاءِ خالص موٽ جو ذريعو نه آهن، ۽ ان کي مددگار ML سسٽم جي مدد سان صاف ڪرڻ جي ضرورت آهي. جيڪڏهن اهو ممڪن ناهي ته صارف کان سگنل گڏ ڪرڻ، پوء اسان متبادل ذريعن جي راء جي ڳولا ڪندا آهيون، مثال طور، ڳنڍيل سسٽم.
- اضافي تربيت. هتي بنيادي شيء تسلسل آهي، تنهنڪري اسان موجوده پيداوار جي ماڊل تي ڀروسو ڪندا آهيون. اسان نون ماڊلن کي تربيت ڏيون ٿا ته جيئن اهي هارمونڪ ريگولرائزيشن ۽ ساڳين چالن جي ڪري پوئين ماڊل کان گهڻو مختلف نه ٿين.
- مقرر ڪرڻ. ميٽرڪس جي بنياد تي خودڪار ترتيب ڏيڻ واري ماڊل کي لاڳو ڪرڻ لاء وقت گھٽائي ٿو. مانيٽرنگ انگ اکر ۽ فيصلا ڪرڻ جي تقسيم، صارفين کان زوال جو تعداد لازمي آهي توهان جي آرام واري ننڊ ۽ پيداواري هفتي جي آخر ۾.
خير، مون کي اميد آهي ته هي توهان جي ايم ايل سسٽم کي تيزيءَ سان بهتر ڪرڻ ۾، انهن کي تيزيءَ سان مارڪيٽ ۾ آڻڻ، ۽ انهن کي وڌيڪ قابل اعتماد ۽ گهٽ دٻاءُ وارو بنائڻ ۾ مدد ڪندو.
جو ذريعو: www.habr.com
