


هي مضمون ڪيئن پڙهو: مان معافي وٺان ٿو ته متن ايترو ڊگهو ۽ افراتفري آهي. توھان جو وقت بچائڻ لاءِ، مان ھر باب کي ”ڇا مون سکيو“ جي تعارف سان شروع ڪريان ٿو، جيڪو باب جي خلاصي کي ھڪڙي يا ٻن جملن ۾ بيان ڪري ٿو.
"بس مون کي حل ڏيکاريو!" جيڪڏھن توھان رڳو اھو ڏسڻ چاھيو ٿا ته مان ڪٿان آيو آھيان، پوءِ باب ڏانھن وڃو “Becoming more inventive”، پر مان سمجھان ٿو ته ناڪاميءَ بابت پڙھڻ وڌيڪ دلچسپ ۽ مفيد آھي.
مون کي تازو ئي ڪم ڪيو ويو هو پروسيسنگ لاءِ هڪ پروسيس قائم ڪرڻ لاءِ هڪ وڏي مقدار جي خام ڊي اين اي ترتيبن (ٽيڪنيڪل طور تي هڪ SNP چپ). ضرورت ان ڳالهه جي هئي ته هڪ ڏنل جينياتي مقام (جنهن کي SNP سڏيو وڃي ٿو) بعد ۾ ماڊلنگ ۽ ٻين ڪمن لاءِ جلدي ڊيٽا حاصل ڪئي وڃي. R ۽ AWK استعمال ڪندي، مان ڊيٽا کي صاف ۽ منظم ڪرڻ جي قابل ٿي ويو قدرتي طريقي سان، تمام تيز رفتار سوال پروسيسنگ. اهو مون لاء آسان نه هو ۽ ڪيترن ئي ورهاڱي جي ضرورت هئي. اهو آرٽيڪل توهان جي مدد ڪندو منهنجي ڪجهه غلطين کان بچڻ ۽ توهان کي ڏيکاريو ته مان ڇا ختم ڪيو.
پهرين، ڪجهه تعارفي وضاحتون.
انگن اکرن
اسان جي يونيورسٽي جينياتي انفارميشن پروسيسنگ سينٽر اسان کي 25 TB TSV جي صورت ۾ ڊيٽا فراهم ڪئي. مون حاصل ڪيو انھن کي 5 پيڪيجز ۾ ورهايو ويو، Gzip پاران ٺھيل، جن مان ھر ھڪ بابت 240 چار گيگا بائيٽ فائلون شامل آھن. هر قطار ۾ هڪ فرد کان هڪ SNP لاءِ ڊيٽا شامل آهي. مجموعي طور تي، ~ 2,5 ملين SNPs ۽ ~ 60 هزار ماڻهن تي ڊيٽا منتقل ڪيا ويا. SNP معلومات کان علاوه، فائلن ۾ ڪيترائي ڪالمن شامل آهن انگن سان گڏ مختلف خاصيتن کي ظاهر ڪن ٿا، جهڙوڪ پڙهڻ جي شدت، مختلف ايليلز جي تعدد، وغيره. مجموعي طور تي اٽڪل 30 ڪالمن منفرد قدرن سان گڏ هئا.
گول
جيئن ڪنهن به ڊيٽا مينيجمينٽ پروجيڪٽ سان، سڀ کان اهم شيء اهو طئي ڪرڻ هو ته ڊيٽا ڪيئن استعمال ڪئي ويندي. هن معاملي ۾ اسان گهڻو ڪري SNP جي بنياد تي SNP لاءِ ماڊل ۽ ورڪ فلوز چونڊينداسين. اهو آهي، اسان کي هڪ وقت ۾ صرف هڪ SNP تي ڊيٽا جي ضرورت پوندي. مون کي سکڻو هو ته 2,5 ملين SNPs مان هڪ سان لاڳاپيل سڀئي رڪارڊ ڪيئن حاصل ڪجي جيترو آساني سان، جلدي ۽ سستي سان.
اهو ڪيئن نه ڪجي
هڪ مناسب ڪليچ کي نقل ڪرڻ لاء:
مان هڪ هزار ڀيرا ناڪام نه ٿيو آهيان، مون صرف هڪ هزار طريقا دريافت ڪيا آهن جن کان پاسو ڪرڻ کان بچڻ لاءِ ڊيٽا جي هڪ گروپ کي سوال-دوست فارميٽ ۾.
پهرين ڪوشش
مون ڇا سکيو آهي: هڪ وقت ۾ 25 ٽي بي کي پارس ڪرڻ جو ڪو سستو طريقو ناهي.
واندربلٽ يونيورسٽي ۾ ”بگ ڊيٽا پروسيسنگ لاءِ اعليٰ طريقا“ ڪورس وٺڻ کان پوءِ، مون کي پڪ هئي ته اها چال بيگ ۾ هئي. اهو شايد هڪ ڪلاڪ يا ٻه وٺي سگھي ٿو Hive سرور کي سيٽ ڪرڻ لاء سڀني ڊيٽا ذريعي هلائڻ ۽ نتيجو رپورٽ ڪرڻ لاء. جيئن ته اسان جي ڊيٽا AWS S3 ۾ ذخيرو ٿيل آهي، مون خدمت استعمال ڪئي ، جيڪو توهان کي S3 ڊيٽا تي Hive SQL سوالن کي لاڳو ڪرڻ جي اجازت ڏئي ٿو. توهان کي Hive ڪلستر قائم ڪرڻ/اٿڻ جي ضرورت ناهي، ۽ توهان صرف ان ڊيٽا لاءِ ادا ڪندا آهيو جنهن کي توهان ڳولي رهيا آهيو.
بعد ۾ مون ايٿينا کي منهنجي ڊيٽا ۽ ان جي شڪل ڏيکاري، مون هن طرح جي سوالن سان ڪجهه ٽيسٽ ورتا:
select * from intensityData limit 10;۽ جلدي حاصل ڪيل چڱي طرح منظم نتيجا. تيار.
جيستائين اسان پنهنجي ڪم ۾ ڊيٽا استعمال ڪرڻ جي ڪوشش ڪئي...
مون کي چيو ويو ته سڀني SNP معلومات کي ڪڍڻ لاء ماڊل کي جانچڻ لاء. مون سوال ڪيو:
select * from intensityData
where snp = 'rs123456';... ۽ انتظار ڪرڻ لڳو. اٺن منٽن کان پوءِ ۽ درخواست ڪيل ڊيٽا جي 4 TB کان وڌيڪ، مون نتيجو حاصل ڪيو. ايٿينا وصول ڪيل ڊيٽا جي مقدار جي حساب سان، $5 في ٽيرا بائيٽ. تنهن ڪري هن هڪ درخواست جي قيمت $20 ۽ انتظار جي اٺ منٽ. سموري ڊيٽا تي ماڊل کي هلائڻ لاءِ، اسان کي 38 سال انتظار ڪرڻو پيو ۽ 50 ملين ڊالر ادا ڪرڻا پيا، ظاهر آهي، اهو اسان لاءِ مناسب نه هو.
ان کي استعمال ڪرڻ ضروري هو Parquet ...
مون ڇا سکيو آهي: محتاط رھو پنھنجي پارڪ فائلن جي سائيز ۽ انھن جي تنظيم سان.
مون پهريون ڀيرو سڀني TSVs کي تبديل ڪندي صورتحال کي درست ڪرڻ جي ڪوشش ڪئي . اهي وڏي ڊيٽا سيٽن سان ڪم ڪرڻ لاءِ آسان آهن ڇاڪاڻ ته انهن ۾ معلومات ڪالمن جي شڪل ۾ محفوظ ڪئي ويندي آهي: هر ڪالم پنهنجي ميموري/ڊسڪ سيڪشن ۾ هوندو آهي، ٽيڪسٽ فائلن جي برعڪس، جنهن ۾ قطارون هر ڪالم جا عنصر هوندا آهن. ۽ جيڪڏهن توهان کي ڪجهه ڳولڻ جي ضرورت آهي، ته پوء صرف گهربل ڪالم پڙهو. اضافي طور تي، هر فائل هڪ ڪالمن ۾ قدرن جي حد کي محفوظ ڪري ٿو، تنهنڪري جيڪڏهن توهان ڳولي رهيا آهيو ته قيمت ڪالمن جي حد ۾ نه آهي، اسپارڪ پوري فائل کي اسڪين ڪرڻ ۾ وقت ضايع نه ڪندو.
مون هڪ سادو ڪم ڪيو اسان جي TSVs کي Parquet ۾ تبديل ڪرڻ ۽ نئين فائلن کي ايٿينا ۾ اڇلائي ڇڏيو. اهو اٽڪل 5 ڪلاڪ ورتو. پر جڏهن مون درخواست ڏني، ان کي پورو ڪرڻ ۾ ساڳئي وقت ۽ ٿورڙي گهٽ رقم ورتي. حقيقت اها آهي ته اسپارڪ، ڪم کي بهتر ڪرڻ جي ڪوشش ڪري، صرف هڪ TSV ٿلهو انپيڪ ڪيو ۽ ان کي پنهنجي پارڪ جي ٽڪري ۾ وجهي ڇڏيو. ۽ ڇاڪاڻ ته هر ٽڪرو ڪافي وڏو هو ته جيئن ڪيترن ئي ماڻهن جا سمورا رڪارڊ شامل هجن، هر فائل ۾ سڀئي SNPs شامل هئا، تنهنڪري اسپارڪ کي گهربل معلومات ڪڍڻ لاءِ سڀني فائلن کي کولڻو پيو.
دلچسپ ڳالهه اها آهي ته، پارڪ جو ڊفالٽ (۽ تجويز ڪيل) ڪمپريشن جو قسم، تيز، ورهايل نه آهي. تنهن ڪري، هر عملدار مڪمل 3,5 GB ڊيٽا سيٽ کي پيڪنگ ۽ ڊائون لوڊ ڪرڻ جي ڪم تي بيٺو هو.
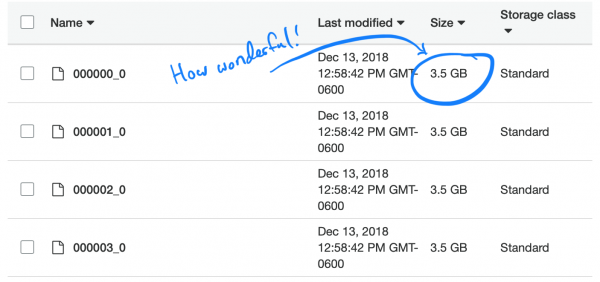
اچو ته مسئلي کي سمجھون
مون ڇا سکيو آهي: ترتيب ڏيڻ ڏکيو آهي، خاص طور تي جيڪڏهن ڊيٽا ورهايل هجي.
مون کي لڳي ٿو ته هاڻي مون کي مسئلي جي جوهر سمجهي. مون کي صرف ڊيٽا کي ترتيب ڏيڻ جي ضرورت آهي SNP ڪالمن طرفان، نه ماڻهن طرفان. پوءِ ڪيترائي SNPs هڪ الڳ ڊيٽا جي حصي ۾ محفوظ ڪيا ويندا، ۽ پوءِ Parquet جو ”سمارٽ“ فنڪشن ”اوپن صرف ان صورت ۾ جڏهن قيمت رينج ۾ هجي“ پنهنجو پاڻ کي پوري شان ۾ ڏيکاريندو. بدقسمتي سان، هڪ ڪلستر ۾ پکڙيل اربين قطارن کي ترتيب ڏيڻ هڪ ڏکيو ڪم ثابت ٿيو.
مون ڪاليج ۾ الگورٿم ڪلاس ورتو: ”اڙي، ڪنهن کي به پرواه ناهي ته انهن سڀني ترتيب ڏيڻ واري الگورتھم جي ڪمپيوٽيشنل پيچيدگي جي“
مان 20TB ۾ ڪالم تي ترتيب ڏيڻ جي ڪوشش ڪري رهيو آهيان ٽيبل: ”اهو ايترو وقت ڇو پيو وٺي؟ جدوجهد.
- نک اسٽرير (@ NicholasStrayer)
AWS يقيني طور تي "مان هڪ پريشان شاگرد آهيان" سبب جي ڪري واپسي جاري ڪرڻ نٿو چاهي. مون کي Amazon Glue تي ترتيب ڏيڻ کان پوء، اهو 2 ڏينهن تائين هليو ۽ تباهه ٿي ويو.
ورهاڱي بابت ڇا؟
مون ڇا سکيو آهي: اسپارڪ ۾ ورهاڱي کي متوازن هجڻ گهرجي.
ان کان پوء مون کي ڪروموزوم ۾ ڊيٽا جي ورهاڱي جو خيال آيو. انهن مان 23 آهن (۽ ٻيا ڪيترائي آهن جيڪڏهن توهان اڪائونٽ ۾ وٺو mitochondrial DNA ۽ unmapped علائقن).
هي توهان کي ڊيٽا کي ننڍن حصن ۾ ورهائڻ جي اجازت ڏيندو. جيڪڏهن توهان گلو اسڪرپٽ ۾ اسپارڪ ايڪسپورٽ فنڪشن ۾ صرف هڪ لڪير شامل ڪيو partition_by = "chr"، پوء ڊيٽا کي buckets ۾ ورهايو وڃي.
جينوم ڪيترن ئي ٽڪرن تي مشتمل آهي جنهن کي ڪروموزوم سڏيو ويندو آهي.
بدقسمتي سان، اهو ڪم نه ڪيو. ڪروموزوم مختلف سائيز آهن، جنهن جو مطلب آهي معلومات جي مختلف مقدار. هن جو مطلب اهو آهي ته ڪم جيڪي اسپارڪ ڪارڪنن ڏانهن موڪليا آهن متوازن نه هئا ۽ سست رفتاري سان مڪمل ڪيا ويا ڇاڪاڻ ته ڪجهه نوڊس جلدي ختم ٿي ويا ۽ بيڪار هئا. بهرحال، ڪم مڪمل ڪيا ويا. پر جڏهن هڪ SNP لاء پڇي، عدم توازن ٻيهر مسئلا پيدا ڪيو. وڏي ڪروموزومس تي پروسيسنگ SNPs جي قيمت (جيڪو اسان ڊيٽا حاصل ڪرڻ چاهيون ٿا) صرف 10 جي فيڪٽر کان گهٽجي ويو آهي. تمام گهڻو، پر ڪافي نه.
ڇا جيڪڏهن اسان ان کي ننڍڙن حصن ۾ ورهايون؟
مون ڇا سکيو آهي: ڪڏهن به ڪوشش نه ڪريو 2,5 ملين پارٽيشنون.
مون سڀ ٻاهر وڃڻ جو فيصلو ڪيو ۽ هر SNP کي ورهايو. انهي کي يقيني بڻايو ويو ته ورهاڱي برابر سائيز جا هئا. اهو هڪ خراب خيال هو. مون گلو استعمال ڪيو ۽ هڪ معصوم لائن شامل ڪئي partition_by = 'snp'. ڪم شروع ڪيو ۽ عمل ڪرڻ شروع ڪيو. هڪ ڏينهن بعد مون چيڪ ڪيو ۽ ڏٺو ته اڃا تائين S3 ڏانهن ڪجهه به نه لکيو ويو آهي، تنهنڪري مون ڪم کي ماري ڇڏيو. اهو ڏسڻ ۾ اچي ٿو ته گلو وچولي فائلون لکي رهيو هو S3 ۾ لڪيل جڳهه تي، تمام گهڻيون فائلون، شايد ٻه ملين. نتيجي طور، منهنجي غلطي هڪ هزار ڊالر کان وڌيڪ خرچ ڪئي ۽ منهنجي مرشد کي خوش نه ڪيو.
ورهاڱي + ترتيب ڏيڻ
مون ڇا سکيو آهي: ترتيب ڏيڻ اڃا به مشڪل آهي، جيئن اسپارڪ کي ترتيب ڏيڻ.
ورهاڱي جي منهنجي آخري ڪوشش ۾ ڪروموزوم کي ورهاڱي ڪرڻ ۽ پوءِ هر ورهاڱي کي ترتيب ڏيڻ شامل هو. نظريي ۾، هي هر سوال کي تيز ڪري ڇڏيندو ڇو ته گهربل SNP ڊيٽا کي ڏنل حد جي اندر ڪجهه پارڪ جي ٽڪرن ۾ هجڻ گهرجي. بدقسمتي سان، ورهاڱي واري ڊيٽا کي ترتيب ڏيڻ ڏکيو ڪم ٿي ويو. نتيجي طور، مون تبديل ڪيو EMR لاءِ ڪسٽم ڪلسٽر ۽ اٺ طاقتور مثال (C5.4xl) ۽ Sparklyr استعمال ڪيو وڌيڪ لچڪدار ڪم فلو ٺاهڻ لاءِ...
# Sparklyr snippet to partition by chr and sort w/in partition
# Join the raw data with the snp bins
raw_data
group_by(chr) %>%
arrange(Position) %>%
Spark_write_Parquet(
path = DUMP_LOC,
mode = 'overwrite',
partition_by = c('chr')
)... بهرحال، ڪم اڃا تائين مڪمل نه ڪيو ويو آهي. مون ان کي مختلف طريقن سان ترتيب ڏنو: هر سوال جي ايگزيڪيوٽر لاءِ ميموري مختص وڌائي، وڏي مقدار ۾ ميموري سان نوڊس استعمال ڪيا، براڊ ڪاسٽ ويريبل (براڊ ڪاسٽنگ ويريئبل) استعمال ڪيا، پر هر ڀيري اهي اڌ ماپون ثابت ٿيا، ۽ آهستي آهستي عمل ڪندڙ شروع ٿيا. ناڪام ٿيڻ تائين جيستائين هر شي بند ٿي وئي.
تازه ڪاري: تنهنڪري اهو شروع ٿئي ٿو.
- نک اسٽرير (@ NicholasStrayer)
مان وڌيڪ تخليقي ٿي رهيو آهيان
مون ڇا سکيو آهي: ڪڏهن ڪڏهن خاص ڊيٽا خاص حل جي ضرورت آهي.
هر SNP ۾ پوزيشن جي قيمت آهي. هي هڪ انگ آهي جيڪو ان جي ڪروموزوم جي بنيادن جي تعداد سان لاڳاپيل آهي. هي اسان جي ڊيٽا کي منظم ڪرڻ جو هڪ سٺو ۽ قدرتي طريقو آهي. شروعات ۾ مون کي هر ڪروموزوم جي علائقن طرفان ورهاڱي ڪرڻ چاهيو. مثال طور، پوزيشن 1 - 2000، 2001 - 4000، وغيره. پر مسئلو اهو آهي ته SNPs برابر طور تي ڪروموزوم ۾ ورهايل نه آهن، تنهنڪري گروپ جي سائيز تمام گهڻو مختلف هوندا.
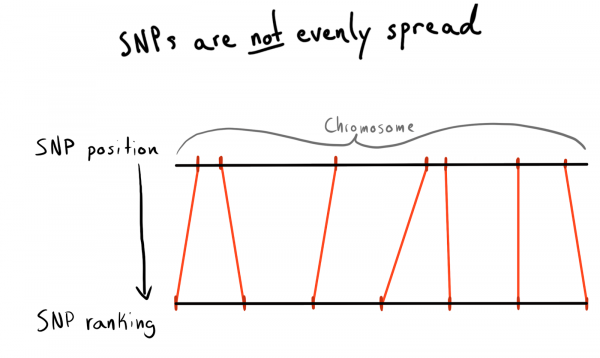
نتيجي طور، مون کي درجي (درجه بندي) ۾ پوزيشن جي ڀڃڪڙي ڪرڻ آيو. اڳ ۾ ئي ڊائون لوڊ ڪيل ڊيٽا کي استعمال ڪندي، مون هڪ درخواست ڪئي ته منفرد SNPs، انهن جي پوزيشن ۽ ڪروموزوم جي فهرست حاصل ڪرڻ لاء. ان کان پوء مون ڊيٽا کي هر ڪروموزوم جي اندر ترتيب ڏنو ۽ SNPs کي ڏنل سائيز جي گروپن (بن) ۾ گڏ ڪيو. اچو ته چوندا آهن 1000 SNPs هر هڪ. هن مون کي SNP-to-گروپ-في-ڪروموزوم تعلق ڏنو.
آخر ۾، مون 75 SNPs جا گروپ (بن) ڪيا، سبب ھيٺ بيان ڪيو ويندو.
snp_to_bin <- unique_snps %>%
group_by(chr) %>%
arrange(position) %>%
mutate(
rank = 1:n()
bin = floor(rank/snps_per_bin)
) %>%
ungroup()پهرين ڪوشش ڪريو Spark سان
مون ڇا سکيو آهي: اسپارڪ ايگريگيشن تيز آهي، پر ورهاڱي اڃا مهانگو آهي.
مان هن ننڍڙي (2,5 ملين قطار) ڊيٽا فريم کي اسپارڪ ۾ پڙهڻ چاهيان ٿو، ان کي خام ڊيٽا سان گڏ ڪرڻ، ۽ پوءِ ان کي نئين شامل ڪيل ڪالمن سان ورهائڻ چاهيان ٿو. bin.
# Join the raw data with the snp bins
data_w_bin <- raw_data %>%
left_join(sdf_broadcast(snp_to_bin), by ='snp_name') %>%
group_by(chr_bin) %>%
arrange(Position) %>%
Spark_write_Parquet(
path = DUMP_LOC,
mode = 'overwrite',
partition_by = c('chr_bin')
)
مون استعمال ڪيو sdf_broadcast()، تنهنڪري اسپار ڄاڻي ٿو ته اهو سڀني نوڊس ڏانهن ڊيٽا فريم موڪلڻ گهرجي. اهو مفيد آهي جيڪڏهن ڊيٽا سائيز ۾ ننڍو آهي ۽ سڀني ڪمن لاء گهربل آهي. ٻي صورت ۾، اسپارڪ سمارٽ ٿيڻ جي ڪوشش ڪري ٿو ۽ ضرورت مطابق ڊيٽا کي ورهائي ٿو، جيڪو سست ٿي سگهي ٿو.
۽ ٻيهر، منهنجو خيال ڪم نه ڪيو: ڪم ڪجهه وقت لاء ڪم ڪيو، يونين کي مڪمل ڪيو، ۽ پوء، ورهاڱي جي ذريعي شروع ڪيل عملدار وانگر، اهي ناڪام ٿيڻ لڳا.
AWK شامل ڪرڻ
مون ڇا سکيو آهي: ننڊ نه ڪريو جڏهن توهان کي بنيادي شيون سيکاريا وڃن. يقيناً ڪو توهان جو مسئلو حل ڪري چڪو آهي 1980ع واري ڏهاڪي ۾.
هن نقطي تائين، اسپارڪ سان منهنجي سڀني ناڪامين جو سبب ڪلستر ۾ ڊيٽا جو جهيڙو هو. ٿي سگهي ٿو ته صورتحال اڳ-علاج سان بهتر ٿي سگهي ٿي. مون خام ٽيڪسٽ ڊيٽا کي ڪروموزوم جي ڪالمن ۾ ورهائڻ جي ڪوشش ڪرڻ جو فيصلو ڪيو، تنهن ڪري مون کي اميد هئي ته اسپارڪ کي ”اڳ-پارٽيشن ٿيل“ ڊيٽا سان مهيا ڪيو وڃي.
مون اسٽيڪ اوور فلو تي ڳولهيو ته ڪالمن جي قدرن سان ڪيئن ورهايو وڃي ۽ مليو AWK سان توهان هڪ ٽيڪسٽ فائل کي ڪالمن جي قدرن سان ورهائي سگهو ٿا ان کي اسڪرپٽ ۾ لکڻ بجاءِ نتيجن کي موڪلڻ بدران stdout.
مون ان کي آزمائڻ لاءِ بش اسڪرپٽ لکيو. پيڪيج ٿيل TSVs مان هڪ ڊائون لوڊ ڪيو، پوء ان کي استعمال ڪندي ان کي کوليو gzip ۽ ڏانهن موڪليو ويو awk.
gzip -dc path/to/chunk/file.gz |
awk -F 't'
'{print $1",..."$30">"chunked/"$chr"_chr"$15".csv"}'اهو ڪم ڪيو!
ڪور ڀرڻ
مون ڇا سکيو آهي: gnu parallel - اهو هڪ جادو شيء آهي، هرڪو ان کي استعمال ڪرڻ گهرجي.
جدائي ڪافي سست هئي ۽ جڏهن مون شروع ڪيو htopهڪ طاقتور (۽ قيمتي) EC2 مثال جي استعمال کي جانچڻ لاء، اهو ظاهر ٿيو ته مان صرف هڪ ڪور استعمال ڪري رهيو آهيان ۽ اٽڪل 200 MB ميموري. مسئلو حل ڪرڻ ۽ تمام گهڻو پئسو نه وڃائڻ لاء، اسان کي اهو معلوم ڪرڻو پوندو ته ڪم کي متوازي ڪيئن ڪجي. خوش قسمت، هڪ بلڪل شاندار ڪتاب ۾ مون کي هڪ باب مليو Jeron Janssens پاران متوازي ڪرڻ تي. ان مان مون کي معلوم ٿيو gnu parallelيونڪس ۾ ملٽي ٿريڊنگ کي لاڳو ڪرڻ لاءِ هڪ تمام لچڪدار طريقو.

جڏهن مون نئين عمل کي استعمال ڪندي ورهاڱي جي شروعات ڪئي، سڀ ڪجهه ٺيڪ هو، پر اڃا به هڪ رڪاوٽ هئي - ڊسڪ تي S3 شيون ڊائون لوڊ ڪرڻ تمام تيز نه هو ۽ مڪمل طور تي متوازي نه هو. هن کي درست ڪرڻ لاء، مون هن ڪيو:
- مون کي معلوم ٿيو ته اهو ممڪن آهي ته S3 ڊائون لوڊ اسٽيج کي سڌو سنئون پائپ لائن ۾، مڪمل طور تي ڊسڪ تي وچولي اسٽوريج کي ختم ڪرڻ. هن جو مطلب آهي ته مان ڊسڪ تي خام ڊيٽا لکڻ کان پاسو ڪري سگهان ٿو ۽ اڃا به ننڍا استعمال ڪريو، ۽ تنهن ڪري سستا، AWS تي اسٽوريج.
- ٽيم
aws configure set default.s3.max_concurrent_requests 50موضوعن جو تعداد تمام گھڻو وڌايو جيڪو AWS CLI استعمال ڪري ٿو (ڊفالٽ طور تي 10 آھن). - مون نيٽ ورڪ جي رفتار لاءِ بهتر ڪيل هڪ EC2 مثال ڏانهن تبديل ڪيو، نالي ۾ اکر n سان. مون ڏٺو آهي ته پروسيسنگ پاور جو نقصان جڏهن اين-مثال استعمال ڪندي لوڊشيڊنگ جي رفتار ۾ اضافو جي معاوضي کان وڌيڪ آهي. اڪثر ڪمن لاءِ مون استعمال ڪيو c5n.4xl.
- تبديل ٿيل
gzipتي ، هي هڪ gzip اوزار آهي جيڪو فائلن کي ڊمپپري ڪرڻ جي شروعاتي غير متوازي ڪم کي متوازي ڪرڻ لاءِ سٺيون شيون ڪري سگهي ٿو (هن گهٽ ۾ گهٽ مدد ڪئي).
# Let S3 use as many threads as it wants
aws configure set default.s3.max_concurrent_requests 50
for chunk_file in $(aws s3 ls $DATA_LOC | awk '{print $4}' | grep 'chr'$DESIRED_CHR'.csv') ; do
aws s3 cp s3://$batch_loc$chunk_file - |
pigz -dc |
parallel --block 100M --pipe
"awk -F 't' '{print $1",..."$30">"chunked/{#}_chr"$15".csv"}'"
# Combine all the parallel process chunks to single files
ls chunked/ |
cut -d '_' -f 2 |
sort -u |
parallel 'cat chunked/*_{} | sort -k5 -n -S 80% -t, | aws s3 cp - '$s3_dest'/batch_'$batch_num'_{}'
# Clean up intermediate data
rm chunked/*
doneاهي قدم هڪ ٻئي سان گڏ ڪيا ويا آهن ته جيئن هر شي کي تمام جلدي ڪم ڪري سگهجي. ڊائون لوڊ جي رفتار وڌائڻ ۽ ڊسڪ رائٽس کي ختم ڪرڻ سان، مان ھاڻي صرف چند ڪلاڪن ۾ 5 ٽيرا بائيٽ پيڪيج کي پروسيس ڪري سگھندس.
هتي سڀني ڪور کي ڏسڻ کان وڌيڪ مٺو ناهي جيڪو توهان ادا ڪري رهيا آهيو AWS استعمال ڪيو پيو وڃي. Gnu-parallel جي مهرباني مان هڪ 19gig csv کي ان زپ ۽ ورهائي سگهان ٿو جيترو جلدي مان ان کي ڊائون لوڊ ڪري سگهان ٿو. مان هن کي هلائڻ لاءِ چمڪ به حاصل ڪري نه سگهيس.
- نک اسٽرير (@ NicholasStrayer)
هن ٽوئيٽ ۾ 'TSV' جو ذڪر ڪرڻ گهرجي ها. افسوس.
نئين تجزياتي ڊيٽا استعمال ڪندي
مون ڇا سکيو آهي: اسپارڪ بي ترتيب ٿيل ڊيٽا کي پسند ڪري ٿو ۽ پارٽيشنن کي گڏ ڪرڻ پسند نٿو ڪري.
ھاڻي ڊيٽا S3 ۾ ھڪڙي غير ڀريل (پڙھيو: شيئر) ۽ نيم آرڊر ٿيل فارميٽ ۾ ھئي، ۽ مان وري اسپارڪ ڏانھن موٽي سگھيس. هڪ تعجب مون لاء انتظار ڪيو: مان ٻيهر حاصل ڪرڻ ۾ ناڪام ٿيس جيڪو مون چاهيو! اسپارڪ کي ٻڌائڻ ڏاڍو ڏکيو هو ته ڊيٽا ڪيئن ورهاڱي ڪئي وئي. ۽ جيتوڻيڪ جڏهن مون اهو ڪيو، اهو ظاهر ٿيو ته اتي تمام گهڻا ورهاڱي (95 هزار) هئا، ۽ جڏهن مون استعمال ڪيو coalesce انهن جي تعداد کي گهٽائي ڇڏيو مناسب حد تائين، هن منهنجي ورهاڱي کي تباهه ڪيو. مون کي پڪ آهي ته اهو طئي ٿي سگهي ٿو، پر ڪجهه ڏينهن جي ڳولا کان پوءِ مون کي ڪو حل نه ملي سگهيو. مون آخرڪار اسپارڪ ۾ سڀ ڪم ختم ڪيا، جيتوڻيڪ ان ۾ ڪجهه وقت لڳي ويو ۽ منهنجي ورهايل پارڪٽ فائلون تمام ننڍيون نه هيون (~ 200 KB). بهرحال، ڊيٽا هئي جتي اها ضرورت هئي.
تمام ننڍو ۽ اڻ برابر، شاندار!
مقامي اسپارڪ سوالن جي جانچ ڪندي
مون ڇا سکيو آهي: سادو مسئلا حل ڪرڻ وقت اسپارڪ تمام گھڻو مٿي آھي.
هوشيار فارميٽ ۾ ڊيٽا کي ڊائون لوڊ ڪندي، مان رفتار کي جانچڻ جي قابل ٿي ويو. مقامي اسپارڪ سرور کي هلائڻ لاءِ آر اسڪرپٽ سيٽ اپ ڪريو، ۽ پوءِ مخصوص پارڪيٽ گروپ اسٽوريج (بن) مان اسپارڪ ڊيٽا فريم لوڊ ڪيو. مون تمام ڊيٽا لوڊ ڪرڻ جي ڪوشش ڪئي پر ورهاڱي کي سڃاڻڻ لاء اسپارڪلر حاصل نه ڪري سگهيو.
sc <- Spark_connect(master = "local")
desired_snp <- 'rs34771739'
# Start a timer
start_time <- Sys.time()
# Load the desired bin into Spark
intensity_data <- sc %>%
Spark_read_Parquet(
name = 'intensity_data',
path = get_snp_location(desired_snp),
memory = FALSE )
# Subset bin to snp and then collect to local
test_subset <- intensity_data %>%
filter(SNP_Name == desired_snp) %>%
collect()
print(Sys.time() - start_time)عملدرآمد 29,415 سيڪنڊن ۾ ورتو. گهڻو بهتر، پر ڪنهن به شيءِ جي ماس ٽيسٽ لاءِ تمام سٺو ناهي. اضافي طور تي، مان ڪيشنگ سان شين کي تيز نه ڪري سگهيس ڇاڪاڻ ته جڏهن مون ميموري ۾ ڊيٽا فريم کي ڪيش ڪرڻ جي ڪوشش ڪئي، اسپارڪ هميشه خراب ٿي ويو، ايستائين جڏهن مون 50 GB کان وڌيڪ ميموري کي ڊيٽا سيٽ لاء مختص ڪيو جنهن جو وزن 15 کان گهٽ هو.
AWK ڏانهن واپس وڃو
مون ڇا سکيو آهي: AWK ۾ تنظيمي صفون تمام ڪارائتيون آھن.
مون محسوس ڪيو ته مان تيز رفتار حاصل ڪري سگهان ٿو. مون کي اها ڳالهه عجيب انداز ۾ ياد آئي مون هڪ سٺي خصوصيت بابت پڙهيو جنهن کي "" لازمي طور تي، اهي اهم-قدر جوڙو آهن، جيڪي ڪجهه سببن لاء AWK ۾ مختلف طور تي سڏيا ويا آهن، ۽ تنهن ڪري مون انهن بابت گهڻو ڪجهه نه سوچيو. ياد ڪيو ويو ته اصطلاح "associative arrays" اصطلاح "key-value pair" کان گهڻو پراڻو آهي. جيتوڻيڪ تون ، توهان هن اصطلاح کي اتي نه ڏسندا، پر توهان ملندا ملن ٿا associative arrays! ان کان علاوه، "اهم-قدر جوڙو" اڪثر ڪري ڊيٽابيس سان لاڳاپيل هوندو آهي، تنهنڪري ان کي هيش ميپ سان مقابلو ڪرڻ گهڻو وڌيڪ احساس آهي. مون محسوس ڪيو ته مان پنھنجي SNPs کي اسپارڪ استعمال ڪرڻ کان سواءِ بِن ٽيبل ۽ خام ڊيٽا سان ڳنڍڻ لاءِ ھي ايسوسيئيٽو صفون استعمال ڪري سگھان ٿو.
هن کي ڪرڻ لاء، AWK اسڪرپٽ ۾ مون بلاڪ استعمال ڪيو BEGIN. هي ڪوڊ جو هڪ ٽڪرو آهي جيڪو عمل ڪيو ويو آهي ان کان اڳ جو ڊيٽا جي پهرين لائن کي اسڪرپٽ جي مکيه جسم ڏانهن منتقل ڪيو وڃي.
join_data.awk
BEGIN {
FS=",";
batch_num=substr(chunk,7,1);
chunk_id=substr(chunk,15,2);
while(getline < "snp_to_bin.csv") {bin[$1] = $2}
}
{
print $0 > "chunked/chr_"chr"_bin_"bin[$1]"_"batch_num"_"chunk_id".csv"
}
ٽيم while(getline...) CSV گروپ (بن) مان سڀئي قطارون لوڊ ڪيون، پھريون ڪالم (SNP نالو) سيٽ ڪريو associative array جي ڪنجي طور bin ۽ ٻي قدر (گروپ) قدر جي طور تي. پوء بلاڪ ۾ { }، جيڪو مکيه فائل جي سڀني لائينن تي عمل ڪيو ويندو آهي، هر لڪير کي ٻاڦ واري فائل ڏانهن موڪليو ويندو آهي، جيڪو هڪ منفرد نالو حاصل ڪري ٿو ان جي گروپ (بن): ..._bin_"bin[$1]"_....
مختلف batch_num и chunk_id پائپ لائن پاران مهيا ڪيل ڊيٽا سان ملائي، نسل جي حالت کان بچڻ، ۽ هر عمل جي سلسلي ۾ هلندڙ parallel، پنهنجي منفرد فائل ڏانهن لکيو.
جيئن ته مون AWK سان منهنجي پوئين تجربي مان بچيل ڪروموزوم تي فولڊرن ۾ سمورو خام ڊيٽا ورهائي ڇڏيو، هاڻي مان هڪ وقت ۾ هڪ ڪروموزوم کي پروسيس ڪرڻ لاءِ هڪ ٻي Bash اسڪرپٽ لکي سگهان ٿو ۽ S3 ڏانهن ڊيپ ورهاڱي واري ڊيٽا موڪلي سگهان ٿو.
DESIRED_CHR='13'
# Download chromosome data from s3 and split into bins
aws s3 ls $DATA_LOC |
awk '{print $4}' |
grep 'chr'$DESIRED_CHR'.csv' |
parallel "echo 'reading {}'; aws s3 cp "$DATA_LOC"{} - | awk -v chr=""$DESIRED_CHR"" -v chunk="{}" -f split_on_chr_bin.awk"
# Combine all the parallel process chunks to single files and upload to rds using R
ls chunked/ |
cut -d '_' -f 4 |
sort -u |
parallel "echo 'zipping bin {}'; cat chunked/*_bin_{}_*.csv | ./upload_as_rds.R '$S3_DEST'/chr_'$DESIRED_CHR'_bin_{}.rds"
rm chunked/*
رسم الخط جا ٻه ڀاڱا آهن parallel.
پهرين حصي ۾، ڊيٽا سڀني فائلن مان پڙهي ويندي آهي جنهن ۾ گهربل ڪروموزوم تي معلومات شامل هوندي آهي، پوء هي ڊيٽا انهن سلسلين ۾ ورهايو ويندو آهي، جيڪي فائلن کي مناسب گروپن (بن) ۾ ورهائيندا آهن. نسل جي حالتن کان بچڻ لاءِ جڏهن هڪ ئي فائل تي گھڻا موضوع لکن ٿا، AWK مختلف هنڌن تي ڊيٽا لکڻ لاءِ فائل جا نالا پاس ڪري ٿو، مثال طور. chr_10_bin_52_batch_2_aa.csv. نتيجي طور، ڪيتريون ئي ننڍيون فائلون ڊسڪ تي ٺاهيا ويا آهن (هن لاء مون استعمال ڪيو terabyte EBS حجم).
ٻئي حصي کان ڪنويئر parallel گروپن (بن) جي ذريعي وڃي ٿو ۽ انهن جي انفرادي فائلن کي عام CSV ۾ گڏ ڪري ٿو c cat۽ پوء انهن کي برآمد ڪرڻ لاء موڪلي ٿو.
آر ۾ نشريات؟
مون ڇا سکيو آهي: توهان رابطو ڪري سگهو ٿا stdin и stdout آر اسڪرپٽ مان، ۽ تنهن ڪري ان کي پائپ لائن ۾ استعمال ڪريو.
توھان شايد ھن لائن کي پنھنجي بش اسڪرپٽ ۾ محسوس ڪيو آھي: ...cat chunked/*_bin_{}_*.csv | ./upload_as_rds.R.... اهو هيٺ ڏنل آر اسڪرپٽ ۾ سڀني گڏيل گروپ فائلن (بن) کي ترجمو ڪري ٿو. {} هڪ خاص ٽيڪنڪ آهي parallel، جيڪو ڪنهن به ڊيٽا کي داخل ڪري ٿو جيڪو مخصوص وهڪرو ڏانهن موڪلي ٿو سڌو سنئون حڪم ۾. اختيار {#} هڪ منفرد موضوع جي سڃاڻپ مهيا ڪري ٿي، ۽ {%} نوڪري جي سلاٽ نمبر جي نمائندگي ڪري ٿو (بار بار، پر ڪڏهن به گڏ نه). سڀني اختيارن جي ھڪڙي فهرست ڳولي سگھجي ٿو
#!/usr/bin/env Rscript
library(readr)
library(aws.s3)
# Read first command line argument
data_destination <- commandArgs(trailingOnly = TRUE)[1]
data_cols <- list(SNP_Name = 'c', ...)
s3saveRDS(
read_csv(
file("stdin"),
col_names = names(data_cols),
col_types = data_cols
),
object = data_destination
)
جڏهن ته هڪ variable file("stdin") ڏانهن منتقل ڪيو ويو readr::read_csv، آر اسڪرپٽ ۾ ترجمو ڪيل ڊيٽا کي فريم ۾ لوڊ ڪيو ويندو آهي، جيڪو پوءِ فارم ۾ هوندو آهي .rds- فائل استعمال ڪندي aws.s3 سڌو سنئون S3 ڏانهن لکيل آهي.
آر ڊي ايس پارڪٽ جي جونيئر ورزن وانگر ڪجهه آهي، اسپيڪر اسٽوريج جي فريل کان سواء.
بش اسڪرپٽ ختم ڪرڻ کان پوءِ مون کي هڪ بنڊل مليو .rds- فائلون S3 ۾ واقع آهن، جن کي مون کي موثر ڪمپريشن استعمال ڪرڻ جي اجازت ڏني وئي ۽ تعمير ٿيل قسمون.
بريڪن آر جي استعمال جي باوجود، هر شيء تمام جلدي ڪم ڪيو. تعجب جي ڳالهه ناهي، آر جا حصا جيڪي ڊيٽا پڙهي ۽ لکندا آهن انتهائي بهتر آهن. ھڪڙي وچولي سائيز ڪروموزوم تي جانچ ڪرڻ کان پوء، ڪم تقريبا ٻن ڪلاڪن ۾ C5n.4xl مثال تي مڪمل ڪيو ويو.
S3 حدون
مون ڇا سکيو آهي: سمارٽ رستي تي عمل ڪرڻ جي مهرباني، S3 ڪيترن ئي فائلن کي سنڀالي سگھي ٿو.
مون کي انديشو هو ته ڇا S3 ڪيترن ئي فائلن کي سنڀالڻ جي قابل هوندو جيڪي ان ڏانهن منتقل ڪيا ويا آهن. مان فائل جا نالا سمجهه ۾ آڻي سگهان ٿو، پر S3 انهن کي ڪيئن ڳولي سگهندو؟

S3 ۾ فولڊر صرف ڏيکارڻ لاء آهن، حقيقت ۾ سسٽم علامت ۾ دلچسپي نه آهي /.
اهو ظاهر ٿئي ٿو ته S3 هڪ خاص فائل ڏانهن رستو ڏيکاري ٿو هڪ سادي ڪيچ جي طور تي هيش ٽيبل يا دستاويزن تي ٻڌل ڊيٽابيس ۾. هڪ بالٽ کي ٽيبل جي طور تي سمجهي سگهجي ٿو، ۽ فائلن کي ان ٽيبل ۾ رڪارڊ سمجهي سگهجي ٿو.
جيئن ته رفتار ۽ ڪارڪردگي Amazon تي نفعو ڪمائڻ لاءِ اهم آهن، ان ۾ ڪا به تعجب جي ڳالهه ناهي ته هي ڪيئي-اي-فائيل-پاٿ سسٽم بيحد بهتر آهي. مون هڪ بيلنس ڳولڻ جي ڪوشش ڪئي: انهي ڪري ته مون کي گهڻيون درخواستون حاصل ڪرڻ جي ضرورت نه هئي، پر اهو ته درخواستون جلدي تي عمل ڪيو ويو. اهو ظاهر ٿيو ته اهو بهترين آهي اٽڪل 20 هزار بن فائلون ٺاهڻ. منهنجو خيال آهي ته جيڪڏهن اسان بهتر ڪرڻ جاري رکون ٿا، اسان رفتار ۾ اضافو حاصل ڪري سگهون ٿا (مثال طور، صرف ڊيٽا لاء هڪ خاص بالٽ ٺاهڻ، اهڙي طرح ڏسڻ واري ٽيبل جي سائيز کي گھٽائڻ). پر وڌيڪ تجربن لاء وقت يا پئسا نه هو.
ڪراس مطابقت بابت ڇا؟
مون ڇا سکيو: وقت جي ضايع ٿيڻ جو نمبر هڪ سبب توهان جي اسٽوريج جي طريقي کي وقت کان اڳ بهتر ڪرڻ آهي.
هن موقعي تي، اهو پنهنجي پاڻ کان پڇڻ تمام ضروري آهي: "ڇو هڪ ملڪيت واري فائيل فارميٽ استعمال ڪريو؟" سبب لوڊشيڊنگ جي رفتار ۾ آهي (gzipped CSV فائلون لوڊ ٿيڻ ۾ 7 ڀيرا وڌيڪ وقت لڳيون) ۽ اسان جي ڪم جي فلوز سان مطابقت. مان ٻيهر غور ڪري سگھان ٿو ته ڇا R آساني سان Parquet (يا Arrow) فائلن کي اسپارڪ لوڊ کان سواءِ لوڊ ڪري سگھي ٿو. اسان جي ليب ۾ هرڪو استعمال ڪري ٿو R، ۽ جيڪڏهن مون کي ڊيٽا کي ڪنهن ٻئي فارميٽ ۾ تبديل ڪرڻ جي ضرورت آهي، مون وٽ اڃا تائين اصل ٽيڪسٽ ڊيٽا آهي، تنهنڪري مان صرف پائپ لائن کي ٻيهر هلائي سگهان ٿو.
ڪم جي تقسيم
مون ڇا سکيو آهي: دستي طور نوڪريون بهتر ڪرڻ جي ڪوشش نه ڪريو، ڪمپيوٽر کي ڪرڻ ڏيو.
مون ھڪڙي ڪروموزوم تي ڪم فلو ڊيبگ ڪيو آھي، ھاڻي مون کي ٻين سڀني ڊيٽا کي پروسيس ڪرڻ جي ضرورت آھي.
مون تبادلي جي لاءِ ڪيترائي EC2 مثال وڌائڻ چاهيو، پر ساڳئي وقت مون کي مختلف پروسيسنگ نوڪرين ۾ تمام گهڻو غير متوازن لوڊ حاصل ڪرڻ کان ڊپ هو (جيئن اسپارڪ غير متوازن ورهاڱي جو شڪار ٿيو). ان کان علاوه، مون کي هر ڪروموزوم ۾ هڪ مثال وڌائڻ ۾ دلچسپي نه هئي، ڇاڪاڻ ته AWS اڪائونٽن لاءِ 10 مثالن جي ڊفالٽ حد آهي.
پوءِ مون فيصلو ڪيو ته آر ۾ اسڪرپٽ لکڻ لاءِ پروسيسنگ نوڪريون بهتر ڪرڻ لاءِ.
پهرين، مون S3 کي حساب ڏيڻ لاءِ چيو ته هر ڪروموزوم ڪيتري اسٽوريج جاءِ تي قبضو ڪيو آهي.
library(aws.s3)
library(tidyverse)
chr_sizes <- get_bucket_df(
bucket = '...', prefix = '...', max = Inf
) %>%
mutate(Size = as.numeric(Size)) %>%
filter(Size != 0) %>%
mutate(
# Extract chromosome from the file name
chr = str_extract(Key, 'chr.{1,4}.csv') %>%
str_remove_all('chr|.csv')
) %>%
group_by(chr) %>%
summarise(total_size = sum(Size)/1e+9) # Divide to get value in GB
# A tibble: 27 x 2
chr total_size
<chr> <dbl>
1 0 163.
2 1 967.
3 10 541.
4 11 611.
5 12 542.
6 13 364.
7 14 375.
8 15 372.
9 16 434.
10 17 443.
# … with 17 more rows
ان کان پوء مون هڪ فنڪشن لکيو جيڪو ڪل سائيز وٺي ٿو، ڪروموزوم جي ترتيب کي ڦيرايو، انهن کي گروپن ۾ ورهائي ٿو. num_jobs ۽ توهان کي ٻڌائي ٿو ته سڀني پروسيسنگ نوڪرين جا سائز مختلف آهن.
num_jobs <- 7
# How big would each job be if perfectly split?
job_size <- sum(chr_sizes$total_size)/7
shuffle_job <- function(i){
chr_sizes %>%
sample_frac() %>%
mutate(
cum_size = cumsum(total_size),
job_num = ceiling(cum_size/job_size)
) %>%
group_by(job_num) %>%
summarise(
job_chrs = paste(chr, collapse = ','),
total_job_size = sum(total_size)
) %>%
mutate(sd = sd(total_job_size)) %>%
nest(-sd)
}
shuffle_job(1)
# A tibble: 1 x 2
sd data
<dbl> <list>
1 153. <tibble [7 × 3]>ان کان پوء مون purrr استعمال ڪندي هڪ هزار شفلز ذريعي ڀڄي ويا ۽ بهترين چونڊيو.
1:1000 %>%
map_df(shuffle_job) %>%
filter(sd == min(sd)) %>%
pull(data) %>%
pluck(1)
تنهن ڪري مون ڪمن جي هڪ سيٽ سان ختم ڪيو جيڪي سائيز ۾ تمام ملندڙ هئا. پوءِ اهو سڀ ڪجهه رهجي ويو هو ته منهنجي پوئين بش اسڪرپٽ کي وڏي لوپ ۾ لپيٽڻ لاءِ for. ھن اصلاح کي لکڻ ۾ اٽڪل 10 منٽ لڳا. ۽ اهو ان کان گهڻو گهٽ آهي جو آئون دستي طور تي ڪم ٺاهڻ تي خرچ ڪندس جيڪڏهن اهي غير متوازن هئا. تنهن ڪري، مان سمجهان ٿو ته آئون هن ابتدائي اصلاح سان صحيح هو.
for DESIRED_CHR in "16" "9" "7" "21" "MT"
do
# Code for processing a single chromosome
fiآخر ۾ مان شامل ڪريان ٿو shutdown حڪم:
sudo shutdown -h now
... ۽ سڀ ڪجهه ڪم ڪيو! AWS CLI استعمال ڪندي، مون اختيار کي استعمال ڪندي مثالن کي وڌايو user_data انهن کي پروسيسنگ لاءِ انهن جي ڪمن جا بش اسڪرپٽ ڏنا. اهي ڀڄي ويا ۽ خودڪار طور تي بند ٿي ويا، تنهنڪري مان اضافي پروسيسنگ پاور لاء ادا نه ڪيو ويو.
aws ec2 run-instances ...
--tag-specifications "ResourceType=instance,Tags=[{Key=Name,Value=<<job_name>>}]"
--user-data file://<<job_script_loc>>اچو ته پيڪ ڪريون!
مون ڇا سکيو آهي: استعمال جي آسانيءَ ۽ لچڪداريءَ خاطر API سادو هجڻ گھرجي.
آخرڪار مون ڊيٽا کي صحيح جڳهه ۽ فارم ۾ حاصل ڪيو. اهو سڀ ڪجهه رهي ٿو ڊيٽا کي استعمال ڪرڻ جي عمل کي آسان ڪرڻ لاءِ جيترو ٿي سگهي منهنجي ساٿين لاءِ آسان بڻائي. مان درخواستون ٺاهڻ لاءِ هڪ سادي API ٺاهڻ چاهيان ٿو. جيڪڏهن مستقبل ۾ مان سوئچ ڪرڻ جو فيصلو ڪريان ٿو .rds Parquet فائلن ڏانهن، پوء اهو مون لاء هڪ مسئلو هجڻ گهرجي، نه منهنجي ساٿين لاء. ان لاءِ مون هڪ اندروني آر پيڪيج ٺاهڻ جو فيصلو ڪيو.
هڪ تمام سادو پيڪيج ٺاهيو ۽ دستاويز ڪريو جنهن ۾ صرف چند ڊيٽا جي رسائي افعال شامل آهن هڪ فنڪشن جي چوڌاري منظم get_snp. مون پنهنجي ساٿين لاءِ هڪ ويب سائيٽ پڻ ٺاهي آهي ، تنهن ڪري اهي آساني سان مثال ۽ دستاويز ڏسي سگهن ٿا.
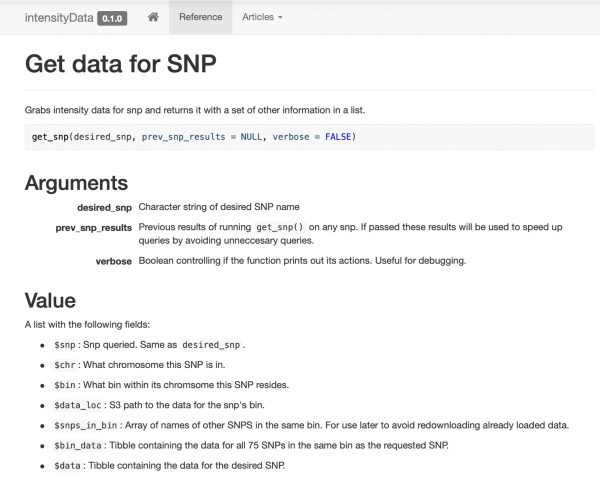
سمارٽ ڪيشنگ
مون ڇا سکيو آهي: جيڪڏهن توهان جي ڊيٽا چڱي طرح تيار آهي، ڪيشنگ آسان ٿي ويندي!
جيئن ته هڪ مکيه ورڪ فلوز ساڳئي تجزياتي ماڊل کي SNP پيڪيج تي لاڳو ڪيو، مون پنهنجي فائدي لاء بائننگ استعمال ڪرڻ جو فيصلو ڪيو. SNP ذريعي ڊيٽا کي منتقل ڪرڻ وقت، گروپ جي سڀني معلومات (بن) واپسي اعتراض سان ڳنڍيل آهي. اھو آھي، پراڻا سوال (نظريي ۾) نوان سوالن جي پروسيسنگ کي تيز ڪري سگھن ٿا.
# Part of get_snp()
...
# Test if our current snp data has the desired snp.
already_have_snp <- desired_snp %in% prev_snp_results$snps_in_bin
if(!already_have_snp){
# Grab info on the bin of the desired snp
snp_results <- get_snp_bin(desired_snp)
# Download the snp's bin data
snp_results$bin_data <- aws.s3::s3readRDS(object = snp_results$data_loc)
} else {
# The previous snp data contained the right bin so just use it
snp_results <- prev_snp_results
}
...
جڏهن پيڪيج ٺاهي، مون مختلف طريقن کي استعمال ڪندي رفتار جي مقابلي لاء ڪيترن ئي معيارن کي هلائي ڇڏيو. مان هن کي نظرانداز نه ڪرڻ جي صلاح ڏيان ٿو، ڇاڪاڻ ته ڪڏهن ڪڏهن نتيجا غير متوقع آهن. مثال طور، dplyr::filter انڊيڪسنگ جي بنياد تي فلٽرنگ استعمال ڪندي قطارن کي پڪڙڻ کان گھڻو تيز ھو، ۽ فلٽر ٿيل ڊيٽا فريم مان ھڪڙي ڪالمن کي حاصل ڪرڻ انڊيڪسنگ نحو استعمال ڪرڻ کان گھڻو تيز ھو.
مهرباني ڪري نوٽ ڪريو ته اعتراض prev_snp_results چاٻي تي مشتمل آهي snps_in_bin. هي هڪ گروپ (بن) ۾ سڀني منفرد SNPs جو هڪ صف آهي، توهان کي جلدي چيڪ ڪرڻ جي اجازت ڏئي ٿي ته توهان وٽ اڳ ۾ ئي اڳئين سوال جي ڊيٽا آهي. اهو پڻ آسان بڻائي ٿو سڀني SNPs ذريعي هڪ گروپ (بن) ۾ هن ڪوڊ سان:
# Get bin-mates
snps_in_bin <- my_snp_results$snps_in_bin
for(current_snp in snps_in_bin){
my_snp_results <- get_snp(current_snp, my_snp_results)
# Do something with results
}نتيجا
ھاڻي اسان ڪري سگھون ٿا (۽ سنجيدگيءَ سان شروع ڪري چڪا آھيون) ماڊل ۽ منظرنامو جيڪي اڳي اسان لاءِ دستياب نه ھئا. بهترين ڳالهه اها آهي ته منهنجي ليب جي ساٿين کي ڪنهن به پيچيدگي بابت سوچڻ جي ضرورت ناهي. انهن وٽ صرف هڪ فنڪشن آهي جيڪو ڪم ڪري ٿو.
۽ جيتوڻيڪ پيڪيج انهن کي تفصيلن کان بچائيندو آهي، مون ڪوشش ڪئي ته ڊيٽا فارميٽ کي ڪافي سادو ٺاهيو ته اهي اهو معلوم ڪري سگھن ٿا ته جيڪڏهن آئون اوچتو سڀاڻي غائب ٿي وڃان ...
رفتار واضح طور تي وڌي وئي آهي. اسان عام طور تي فنڪشنل طور تي اهم جينوم ٽڪرا اسڪين ڪندا آهيون. اڳي، اسان اهو نه ڪري سگهياسين (اهو تمام گهڻو مهانگو ٿي ويو)، پر هاڻي، گروپ (بن) جي جوڙجڪ ۽ ڪيشنگ جي مهرباني، هڪ SNP لاءِ درخواست سراسري طور 0,1 سيڪنڊن کان گهٽ لڳندي آهي، ۽ ڊيٽا جو استعمال تمام گهٽ آهي. ته S3 جي قيمت مونگ پھلي آهي.
تازو مون پنهنجي ليبارٽري لاءِ خام جينو ٽائپنگ ڊيٽا جي 25+ ٽي بي جي تڪرار جي تبديلي ۾ رکيو آهي. جڏهن مون شروع ڪيو، اسپارڪ استعمال ڪرڻ 8 منٽ ورتو ۽ قيمت $20 هڪ SNP پڇڻ لاءِ. AWK + استعمال ڪرڻ کان پوء پروسيس ڪرڻ لاء، اهو هاڻي هڪ سيڪنڊ جي 10th کان گهٽ وٺندو آهي ۽ قيمت $0.00001. منهنجو ذاتي کٽڻ.
- نک اسٽرير (@ NicholasStrayer)
ٿڪل
هي مضمون هرگز هڪ گائيڊ ناهي. حل انفرادي ٿي ويو، ۽ تقريبن يقيني طور تي بهتر ناهي. بلڪه، اهو هڪ سفرنامو آهي. مان چاهيان ٿو ته ٻيا به اهو سمجهن ته اهڙا فيصلا سر ۾ پوري طرح ٺهيل نظر نه ٿا اچن، اهي آزمائش ۽ غلطي جو نتيجو آهن. انهي سان گڏ، جيڪڏهن توهان ڳولي رهيا آهيو هڪ ڊيٽا سائنسدان، ذهن ۾ رکون ٿا ته انهن اوزارن کي مؤثر طريقي سان استعمال ڪرڻ لاء تجربو جي ضرورت آهي، ۽ تجربو پئسا خرچ ڪري ٿو. مان خوش آهيان ته مون وٽ ادا ڪرڻ جو وسيلو هو، پر ٻيا ڪيترائي جيڪي مون کان بهتر ڪم ڪري سگهن ٿا، انهن کي ڪڏهن به موقعو نه ملندو ته پئسن جي کوٽ سبب ڪوشش ڪرڻ جو.
وڏي ڊيٽا جا اوزار versatile آهن. جيڪڏهن توهان وٽ وقت آهي، توهان تقريبا يقيني طور تي لکي سگهو ٿا هڪ تيز حل استعمال ڪندي سمارٽ ڊيٽا جي صفائي، اسٽوريج، ۽ ڪڍڻ واري ٽيڪنالاجي. آخرڪار اهو اچي ٿو قيمت جي فائدي جي تجزيو تي.
مون ڇا سکيو:
- هڪ وقت ۾ 25 ٽي بي کي پارس ڪرڻ جو ڪو به سستو طريقو ناهي.
- توهان جي پارڪ فائلن ۽ انهن جي تنظيم جي سائيز سان محتاط رکو؛
- Spark ۾ ورهاڱي کي متوازن هجڻ گهرجي؛
- عام طور تي، 2,5 ملين پارٽيشن ٺاهڻ جي ڪوشش نه ڪريو؛
- ترتيب ڏيڻ اڃا به ڏکيو آهي، جيئن اسپارڪ کي ترتيب ڏيڻ؛
- ڪڏهن ڪڏهن خاص ڊيٽا خاص حل جي ضرورت آهي؛
- اسپارڪ ايگريگيشن تيز آهي، پر ورهاڱي اڃا مهانگو آهي.
- ننڊ نه ڪريو جڏهن اهي توهان کي بنيادي شيون سيکاريندا آهن، ڪنهن شايد اڳ ۾ ئي توهان جو مسئلو 1980 جي ڏهاڪي ۾ حل ڪيو؛
gnu parallel- هي هڪ جادو شيء آهي، هرڪو ان کي استعمال ڪرڻ گهرجي؛- اسپارڪ اڻ سڌريل ڊيٽا کي پسند ڪندو آهي ۽ پارٽيشنن کي گڏ ڪرڻ پسند نٿو ڪري.
- سادي مسئلن کي حل ڪرڻ دوران اسپارڪ تمام گهڻو مٿي آهي.
- AWK جي ساٿي صفون تمام ڪارائتو آهن؛
- توهان رابطو ڪري سگهو ٿا
stdinиstdoutآر اسڪرپٽ مان، ۽ تنهن ڪري ان کي پائپ لائن ۾ استعمال ڪريو؛ - سمارٽ رستي تي عمل ڪرڻ جي مهرباني، S3 ڪيترن ئي فائلن تي عمل ڪري سگهي ٿو؛
- وقت ضايع ڪرڻ جو بنيادي سبب وقت کان اڳ توهان جي اسٽوريج جي طريقي کي بهتر ڪرڻ آهي.
- دستي طور تي ڪم کي بهتر ڪرڻ جي ڪوشش نه ڪريو، ڪمپيوٽر کي اهو ڪرڻ ڏيو؛
- استعمال جي آساني ۽ لچڪ جي خاطر API کي سادو هجڻ گهرجي؛
- جيڪڏهن توهان جي ڊيٽا چڱي طرح تيار ڪئي وئي آهي، ڪيشنگ آسان ٿي ويندي!
جو ذريعو: www.habr.com
