

منهنجي ڪم جي نوعيت جي ڪري، مون کي اهڙين حالتن سان منهن ڏيڻو پوندو آهي جڏهن هڪ ڊولپر درخواست لکي ٿو ۽ سوچي ٿو ته "بنياد هوشيار آهي، اهو سڀ ڪجهه پاڻ سنڀاليندو!«
ڪجهه حالتن ۾ (جزوي طور تي ڊيٽابيس جي صلاحيتن جي اڻڄاڻائي جي ڪري، جزوي طور تي وقت کان اڳ اصلاح جي ڪري)، هي طريقو "فرينڪنسٽائنز" جي ظهور جو سبب بڻجي ٿو.
پهرين، مون کي اهڙي درخواست جو هڪ مثال ڏيڻ ڏيو:
-- для каждой ключевой пары находим ассоциированные значения полей
WITH RECURSIVE cte_bind AS (
SELECT DISTINCT ON (key_a, key_b)
key_a a
, key_b b
, fld1 bind_fld1
, fld2 bind_fld2
FROM
tbl
)
-- находим min/max значений для каждого первого ключа
, cte_max AS (
SELECT
a
, max(bind_fld1) bind_fld1
, min(bind_fld2) bind_fld2
FROM
cte_bind
GROUP BY
a
)
-- связываем по первому ключу ключевые пары и min/max-значения
, cte_a_bind AS (
SELECT
cte_bind.a
, cte_bind.b
, cte_max.bind_fld1
, cte_max.bind_fld2
FROM
cte_bind
INNER JOIN
cte_max
ON cte_max.a = cte_bind.a
)
SELECT * FROM cte_a_bind;ڪنهن سوال جي معيار کي معروضي طور تي جانچڻ لاءِ، اچو ته هڪ بي ترتيب ڊيٽا سيٽ ٺاهيون:
CREATE TABLE tbl AS
SELECT
(random() * 1000)::integer key_a
, (random() * 1000)::integer key_b
, (random() * 10000)::integer fld1
, (random() * 10000)::integer fld2
FROM
generate_series(1, 10000);
CREATE INDEX ON tbl(key_a, key_b);
اهو ظاهر ٿيو ته اهو آهي ڊيٽا پڙهڻ ۾ ڪل وقت جو چوٿون حصو کان به گهٽ وقت لڳو. سوال جي عملدرآمد:
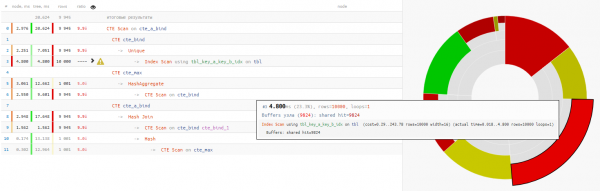
اچو ته ان کي ٽڪرا ٽڪرا ڪريون.
اچو ته درخواست تي هڪ ويجهي نظر وجهون ۽ حيران ٿي وڃون:
- جيڪڏهن ڪو به ريڪرسيو سي ٽي اي نه آهي ته هتي WITH RECURSIVE ڇو آهي؟
- جيڪڏهن اهي اڃا تائين اصل نموني سان ڳنڍيل آهن ته پوءِ گهٽ ۾ گهٽ/وڌ قدرن کي الڳ CTE ۾ ڇو گروپ ڪيو وڃي؟
+25٪ وقت - آخر ۾ غير مشروط 'SELECT * FROM' ذريعي پوئين CTE مان ٻيهر پڙهڻ ڇو استعمال ڪجي؟
+14٪ وقت
هن صورت ۾، اسان تمام خوش قسمت هئاسين ته ڪنيڪشن لاءِ هيش جوائن چونڊيو ويو، ۽ نيسٽڊ لوپ نه، ڇاڪاڻ ته پوءِ اسان کي هڪ به CTE اسڪين پاس نه، پر 10K ملي ها!
سي ٽي اي اسڪين بابت ٿوروهتي اسان کي ياد رکڻ گهرجي ته سي ٽي اي اسڪين، سيڪ اسڪين جو هڪ اينالاگ آهي. - يعني، ڪا به انڊيڪسنگ نه، پر صرف هڪ مڪمل ڳڻپ، جنهن جي ضرورت پوندي 10 ڪلو بائيٽ x 0.3 ايم ايس = 3000MS جڏهن cte_max ذريعي سائيڪل هلائيندي يا 1 ڪلو بائيٽ x 1.5 ايم ايس = 1500MS جڏهن cte_bind ذريعي لوپ ڪيو وڃي!
اصل ۾، توهان نتيجي ۾ ڇا حاصل ڪرڻ چاهيو ٿا؟ ها، اهو اهڙو سوال آهي جيڪو عام طور تي "ٽي منزله" سوالن جي تجزيي جي پنجين منٽ ۾ ڪٿي نه ڪٿي اڀري ايندو آهي.
اسان هر منفرد ڪي جوڙو لاءِ آئوٽ پُٽ ڏيڻ چاهيون ٿا key_a جي گروپ مان گھٽ ۾ گھٽ/وڌ.
تنهنڪري اچو ته ان کي هن لاءِ استعمال ڪريون. :
SELECT DISTINCT ON(key_a, key_b)
key_a a
, key_b b
, max(fld1) OVER(w) bind_fld1
, min(fld2) OVER(w) bind_fld2
FROM
tbl
WINDOW
w AS (PARTITION BY key_a); 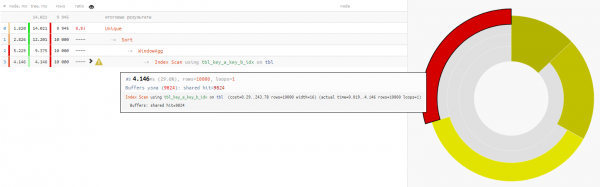
جيئن ته ٻنهي آپشنن ۾ ڊيٽا پڙهڻ ۾ ساڳيو وقت لڳندو آهي، تقريبن 4-5 ايم ايس، پوءِ اسان جو پورو وقت ۾ فائدو -32٪ - هي پنهنجي خالص ترين شڪل ۾ آهي سي پي يو بيس تان لوڊ هٽايو ويو، جيڪڏهن اهڙي درخواست تي بار بار عمل ڪيو وڃي.
عام طور تي، بنيادي ڳالهين کي "گول شيون پائڻ، چورس شيون رول ڪرڻ" تي مجبور ڪرڻ جي ڪا ضرورت ناهي.
جو ذريعو: www.habr.com
