


توهان کان اڳ ٻيهر شيون ڳولڻ جو ڪم آهي. ترجيح قابل قبول درستگي سان آپريشن جي رفتار آھي. توھان وٺو YOLOv3 فن تعمير ۽ ان کي وڌيڪ تربيت ڏيو. درستگي (mAp75) 0.95 کان وڌيڪ آھي. پر رن ريٽ اڃا گهٽ آهي. گندو.
اڄ اسان quantization کي نظرانداز ڪنداسين. ۽ ڪٽ جي هيٺان ڏسنداسين ماڊل ڇنڊڇاڻ - درستگي جي نقصان کان سواءِ انفرنس کي تيز ڪرڻ لاءِ نيٽ ورڪ جي بيڪار حصن کي ڪٽڻ. اهو واضح آهي ته ڪٿي، ڪيترو ۽ ڪيئن ڪٽيو. اچو ته اهو ڄاڻون ته اهو دستي طور ڪيئن ڪجي ۽ ڪٿي توهان ان کي خودڪار ڪري سگهو ٿا. آخر ۾ ڪراس تي هڪ مخزن آهي.
تعارف
منهنجي ڪم جي پوئين جاءِ تي، پرم ۾ ميڪروسڪوپ، مون هڪ عادت حاصل ڪئي - هميشه لاءِ الگورتھم جي عمل جي وقت جي نگراني ڪرڻ. ۽ هميشه چيڪ ڪريو نيٽ ورڪ رن ٽائم کي مناسب فلٽر ذريعي. عام طور تي پيداوار ۾ اسٽيٽ آف دي آرٽ هن فلٽر کي پاس نه ڪندو آهي، جنهن جي ڪري مون کي پرننگ ڪيو ويو.
ڇنڊڇاڻ هڪ پراڻو موضوع آهي جنهن تي بحث ڪيو ويو آهي 2017 ۾. بنيادي خيال مختلف نوڊس کي هٽائڻ جي درستگي کي وڃائڻ کان سواء تربيت يافته نيٽ ورڪ جي سائيز کي گهٽائڻ آهي. اهو ٿڌو آواز آهي، پر مان گهٽ ۾ گهٽ ان جي استعمال بابت ٻڌندو آهيان. شايد، اتي ڪافي عمل درآمد نه آھن، اتي ڪو روسي-ٻولي مضمون نه آھن، يا بس هرڪو اهو سمجهي ٿو ته ڪيئن ڄاڻو ۽ خاموش رهي.
پر اچو ته ان کي ڌار ڪريون
حياتيات ۾ هڪ جھلڪ
مون کي اهو پسند آهي جڏهن ڊيپ لرننگ انهن خيالن کي ڏسندي آهي جيڪي حياتيات مان ايندا آهن. اهي، ارتقاء وانگر، ڀروسو ڪري سگهجي ٿو (ڇا توهان کي خبر آهي ته ReLU تمام گهڻو ساڳيو آهي ?)
ماڊل پرننگ جو عمل به حياتيات جي ويجهو آهي. نيٽ ورڪ جو جواب هتي دماغ جي پلاسٽيٽيٽي سان مقابلو ڪري سگهجي ٿو. ڪتاب ۾ اهڙا ٻه دلچسپ مثال آهن. :
- هڪ عورت جو دماغ جيڪو صرف هڪ اڌ سان پيدا ٿيو هو پاڻ کي ٻيهر پروگرام ڪيو ويو آهي غائب اڌ جي ڪم کي انجام ڏيڻ لاء.
- ڇوڪرو پنهنجي دماغ جو حصو بند ڪري ڇڏيو جيڪو خواب لاء ذميوار هو. وقت سان گڏ، دماغ جي ٻين حصن کي انهن ڪمن تي قبضو ڪيو. (اسان ورجائڻ جي ڪوشش نه ڪري رهيا آهيون)
ساڳئي طرح، توهان پنهنجي ماڊل مان ڪجهه ضعيف سازشن کي ڪٽي سگهو ٿا. آخري حل جي طور تي، باقي بنڈل ڪٽي وارن کي تبديل ڪرڻ ۾ مدد ڪندو.
ڇا توهان کي منتقلي جي سکيا پسند آهي يا توهان شروع کان سکيا آهيو؟
اختيار نمبر هڪ. توهان Yolov3 تي منتقلي سکيا استعمال ڪريو. ريٽنا، ماسڪ-RCNN يا U-Net. پر اڪثر وقت اسان کي 80 اعتراض ڪلاسن کي سڃاڻڻ جي ضرورت ناهي جيئن COCO ۾. منهنجي عمل ۾، سڀ ڪجهه گريڊ 1-2 تائين محدود آهي. ڪو سمجهي سگهي ٿو ته 80 طبقن لاءِ فن تعمير هتي بيڪار آهي. اهو مشورو ڏئي ٿو ته فن تعمير کي ننڍو بڻائڻ جي ضرورت آهي. ان کان علاوه، مان اهو ڪرڻ چاهيان ٿو بغير موجوده اڳوڻي تربيتي وزن کي وڃائڻ کان سواء.
آپشن نمبر ٻه. ٿي سگهي ٿو توهان وٽ تمام گهڻو ڊيٽا ۽ ڪمپيوٽنگ جا وسيلا آهن، يا صرف هڪ سپر ڪسٽم فن تعمير جي ضرورت آهي. ڪو مسئلو ناهي. پر توهان شروع کان نيٽ ورڪ سکي رهيا آهيو. عام طريقو اهو آهي ته ڊيٽا جي جوڙجڪ کي ڏسڻ لاء، هڪ فن تعمير کي چونڊيو جيڪو طاقت ۾ تمام گهڻو آهي، ۽ ٻيهر تربيت کان ٻاهر نڪرڻ کي ڌڪايو. مون ڏٺو 0.6 ڊراپ آئوٽ، ڪارل.
ٻنهي صورتن ۾، نيٽ ورڪ کي گهٽائي سگهجي ٿو. موهيندڙ. هاڻي اچو ته اهو سمجهون ته طواف ڪرڻ ڪهڙي قسم جو آهي
عام الگورتھم
اسان فيصلو ڪيو ته اسان بنڊلن کي هٽائي سگهون ٿا. اهو بلڪل سادو ڏسڻ ۾ اچي ٿو:
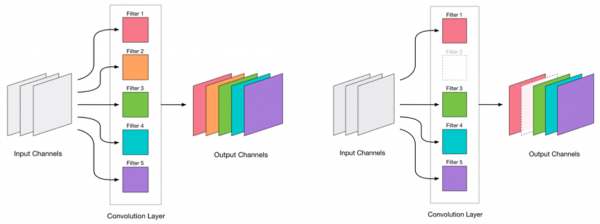
ڪنهن به ٺاهه کي هٽائڻ نيٽ ورڪ لاءِ دٻاءُ وارو آهي، جيڪو عام طور تي ڪجهه غلطين ۾ اضافو ڪري ٿو. هڪ پاسي، غلطي ۾ هي اضافو هڪ اشارو آهي ته اسان ڪئين صحيح طريقي سان هٽايو (مثال طور، هڪ وڏو اضافو اشارو ڪري ٿو ته اسان ڪجهه غلط ڪري رهيا آهيون). پر هڪ ننڍڙو اضافو ڪافي قابل قبول آهي ۽ اڪثر ڪري هڪ ننڍڙي LR سان گڏ ايندڙ روشني اضافي تربيت ذريعي ختم ڪيو ويندو آهي. اضافي تربيتي قدم شامل ڪريو:
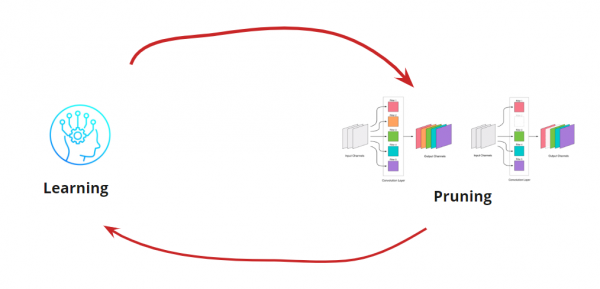
هاڻي اسان کي اهو سمجهڻو پوندو ته اسان پنهنجي سکيا کي بند ڪرڻ چاهيون ٿا<->پرننگ لوپ. هتي ڌاريا آپشن ٿي سگهن ٿا جڏهن اسان کي ضرورت آهي نيٽ ورڪ کي هڪ خاص سائيز ۽ رفتار تائين گھٽائڻ لاءِ (مثال طور، موبائل ڊوائيسز لاءِ). بهرحال، سڀ کان وڌيڪ عام اختيار اهو آهي ته چڪر جاري رکو جيستائين غلطي قابل قبول کان وڌيڪ نه ٿي وڃي. شرط شامل ڪريو:
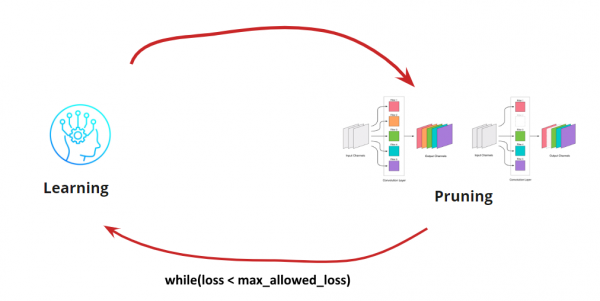
تنهن ڪري، الورورٿم واضح ٿئي ٿو. اهو معلوم ڪرڻ لاء رهي ٿو ته ڪيئن ختم ٿيل convolutions جو تعين ڪرڻ لاء.
ختم ٿيل بنڊلن جي ڳولا ڪريو
اسان کي ڪجهه convolutions کي ختم ڪرڻ جي ضرورت آهي. اڳتي وڌڻ ۽ ”شوٽنگ“ ڪنهن کي به خراب خيال آهي، جيتوڻيڪ اهو ڪم ڪندو. پر جيئن توهان وٽ هڪ سر آهي، توهان سوچڻ ۽ هٽائڻ لاء "ضعيف" سازشون چونڊڻ جي ڪوشش ڪري سگهو ٿا. اتي ڪيترائي اختيار آھن:
- . اهو خيال آهي ته ننڍن وزنن سان ٺهڪندڙ حتمي فيصلي ۾ ٿورو حصو وٺندا آهن
- سڀ کان ننڍو L1-پيماني مطلب ۽ معياري انحراف کي مدنظر رکندي. اسان تقسيم جي نوعيت جي جائزي سان گڏ ڪريون ٿا.
- . غير معمولي سازشن جو وڌيڪ صحيح عزم، پر تمام گهڻو وقت سازي ۽ وسيلن جي استعمال.
- ٻيا
اختيارن مان هر هڪ کي زندگي گذارڻ جو حق آهي ۽ ان جي پنهنجي عمل جي خاصيتون. هتي اسان سڀ کان ننڍي L1 ماپ سان اختيار تي غور ڪيو
YOLOv3 لاءِ دستي عمل
اصل فن تعمير ۾ بقايا بلاڪ شامل آهن. پر ڪابه ڳالهه نه آهي ته اهي گہرے نيٽ ورڪن لاءِ ڪيترا سٺا آهن، اهي اسان کي ڪجهه حد تائين روڪيندا. ڏکيائي اها آهي ته توهان انهن پرتن ۾ مختلف انڊيڪس سان ٺاهه کي ختم نٿا ڪري سگهو:
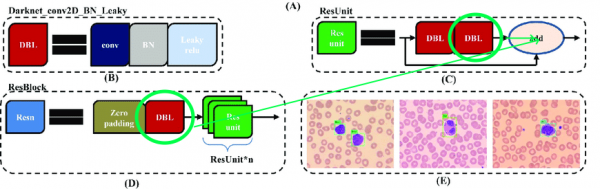
تنهن ڪري، اچو ته پرت چونڊيو جن مان اسان آزاديء سان مفاهمت کي ختم ڪري سگهون ٿا:

هاڻي اچو ته هڪ ڪم جي چڪر ٺاهيو:
- اپلوڊ ڪرڻ واريون سرگرميون
- اندازو لڳايو ته ڪيترو ڪٽيو وڃي
- ڪٽڻ
- LR = 10e-1 سان 4 epochs سکيا
- جاچڻ
انلوڊنگ ڪنووليشن اهو اندازو ڪرڻ لاءِ ڪارائتو آهي ته اسان ڪنهن خاص قدم تي ڪيترو حصو هٽائي سگهون ٿا. لوڊ ڪرڻ جا مثال:
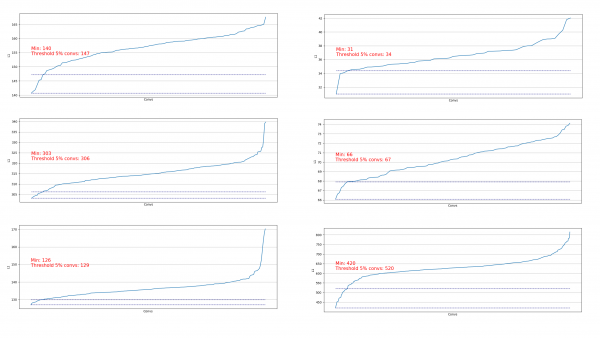
اسان ڏسون ٿا ته تقريباً هر هنڌ 5٪ convolutions ۾ تمام گهٽ L1-norm آهي ۽ اسان انهن کي ختم ڪري سگهون ٿا. هر قدم تي، هن لوڊشيڊنگ کي بار بار ڪيو ويو ۽ هڪ اندازو لڳايو ويو ته ڪهڙيون پرتون ۽ ڪيترا ڪٽي سگهجن ٿا.
سڄو عمل 4 مرحلن ۾ مڪمل ڪيو ويو (هتي نمبر ۽ هر جڳهه RTX 2060 سپر لاءِ):
| قدم | mAp75 | پيرا ميٽرن جو تعداد، مليون | نيٽ ورڪ سائيز، ايم بي | شروعاتي کان،٪ | هلائڻ وقت، ms | طواف ڪرڻ جي حالت |
|---|---|---|---|---|---|---|
| 0 | 0.9656 | 60 | 241 | 100 | 180 | - |
| 1 | 0.9622 | 55 | 218 | 91 | 175 | سڀني جو 5٪ |
| 2 | 0.9625 | 50 | 197 | 83 | 168 | سڀني جو 5٪ |
| 3 | 0.9633 | 39 | 155 | 64 | 155 | 15٪ 400 کان وڌيڪ ڪنوولوشن سان پرتن لاءِ |
| 4 | 0.9555 | 31 | 124 | 51 | 146 | 10٪ 100 کان وڌيڪ ڪنوولوشن سان پرتن لاءِ |
ھڪڙو مثبت اثر قدم 2 ۾ شامل ڪيو ويو - بيچ سائيز 4 ياداشت ۾ فٽ، جنھن اضافي تربيت جي عمل کي تيز ڪيو.
قدم 4 تي، عمل کي روڪيو ويو ڇاڪاڻ ته جيتوڻيڪ ڊگھي مدي واري اضافي تربيت به mAp75 کي پراڻي قدرن تائين نه وڌايو.
نتيجي طور، اسان ترتيب ڏيڻ جي رفتار کي تيز ڪرڻ ۾ مدد ڪئي 15٪، سائيز کي گھٽايو 35٪ ۽ بلڪل نه وڃايو.
آسان فن تعمير لاء خودڪار
آسان نيٽ ورڪ آرڪيٽيڪچرز لاءِ (بغير مشروط اضافو، گڏيل ۽ بقايا بلاڪن جي)، اهو تمام ممڪن آهي ته سڀني قاعدن جي پرت جي پروسيسنگ تي ڌيان ڏيڻ ۽ ڪنوولوشن کي ڪٽڻ جي عمل کي خودڪار ڪيو وڃي.
مون هن اختيار تي عمل ڪيو .
اهو سادو آهي: توهان کي صرف نقصان جي فنڪشن، هڪ اصلاح ڪندڙ ۽ بيچ جنريٽر جي ضرورت آهي:
import pruning
from keras.optimizers import Adam
from keras.utils import Sequence
train_batch_generator = BatchGenerator...
score_batch_generator = BatchGenerator...
opt = Adam(lr=1e-4)
pruner = pruning.Pruner("config.json", "categorical_crossentropy", opt)
pruner.prune(train_batch, valid_batch)جيڪڏھن ضروري ھجي، توھان config parameters کي تبديل ڪري سگھو ٿا:
{
"input_model_path": "model.h5",
"output_model_path": "model_pruned.h5",
"finetuning_epochs": 10, # the number of epochs for train between pruning steps
"stop_loss": 0.1, # loss for stopping process
"pruning_percent_step": 0.05, # part of convs for delete on every pruning step
"pruning_standart_deviation_part": 0.2 # shift for limit pruning part
}اضافي طور تي، معياري انحراف جي بنياد تي هڪ حد لاڳو ڪئي وئي آهي. مقصد اهو آهي ته هٽايو ويو حصو کي محدود ڪرڻ، اڳ ۾ ئي "ڪافي" L1 قدمن سان ٺهڪندڙ کان سواء.
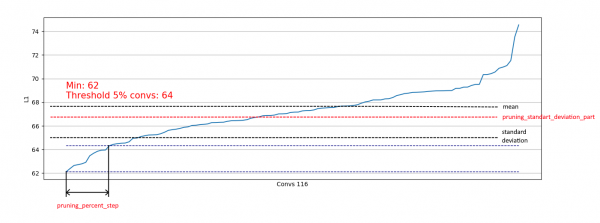
ان ڪري، اسان توهان کي اجازت ڏيون ٿا ته صرف ساڄي ورهاست مان صرف ڪمزور ڪنوولوشنز کي هٽايو وڃي ۽ نه ئي کاٻي سان ملندڙ تقسيم مان هٽائڻ تي اثر انداز ٿئي:

جڏهن تقسيم معمول تي اچي ٿي، pruning_standart_deviation_part coefficient هن مان چونڊيو وڃي ٿو:
مان سفارش ڪريان ٿو 2 سگما جو فرض. يا توھان ھن خصوصيت کي نظرانداز ڪري سگھو ٿا، قدر کي ڇڏي <1.0.
ٻاھر آھي ھڪڙي گراف آھي نيٽ ورڪ جي سائيز، نقصان، ۽ نيٽ ورڪ رن ٽائم پوري ٽيسٽ لاءِ، 1.0 تائين عام ڪيو ويو آھي. مثال طور، هتي نيٽ ورڪ جي سائيز تقريبن 2 ڀيرا گھٽجي وئي بغير معيار جي نقصان جي (ننڍو ڪنوولوشنل نيٽورڪ 100k وزن سان):
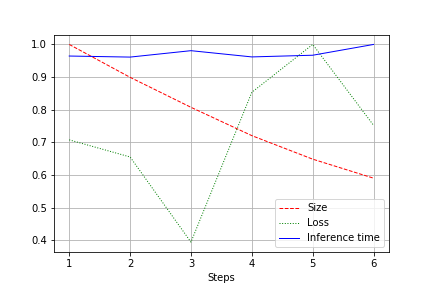
ھلندڙ رفتار عام fluctuations جي تابع آهي ۽ لڳ ڀڳ اڻڄاتل رهي ٿو. هن لاء هڪ وضاحت آهي:
- convolutions جو تعداد آسان (32, 64, 128) کان بدلجي ٿو وڊيو ڪارڊ لاء سڀ کان وڌيڪ آسان نه - 27, 51, وغيره. مان هتي غلط ٿي سگهي ٿو، پر گهڻو ڪري اهو اثر آهي.
- فن تعمير وسيع نه آهي، پر مسلسل. چوٿين کي گهٽائڻ سان، اسان کوٽائي تي اثر انداز نه ڪندا آهيون. اهڙيء طرح، اسان لوڊ کي گهٽايو، پر رفتار کي تبديل نه ڪندا آهيون.
تنهن ڪري، 20-30٪ جي هلائڻ دوران CUDA لوڊ ۾ گهٽتائي ۾ سڌارو ظاهر ڪيو ويو، پر رن ٽائيم ۾ گهٽتائي ۾ نه.
نتيجو
اچو ته فڪر ڪريون. اسان 2 اختيارن تي غور ڪيو پرننگ لاءِ - YOLOv3 لاءِ (جڏهن توهان کي پنهنجن هٿن سان ڪم ڪرڻو پوندو) ۽ آسان آرڪيٽيڪچر سان نيٽ ورڪن لاءِ. اهو ڏسي سگھجي ٿو ته ٻنهي صورتن ۾ اهو ممڪن آهي ته نيٽ ورڪ جي سائيز جي گھٽتائي ۽ رفتار حاصل ڪرڻ جي درستگي جي نقصان کان سواء. نتيجا:
- سائيز کي گھٽائڻ
- تيز رفتار ڊوڙ
- CUDA لوڊ گھٽائڻ
- نتيجي طور، ماحولياتي دوستي (اسان ڪمپيوٽنگ وسيلن جي مستقبل جي استعمال کي بهتر بڻايون ٿا. ڪٿي هڪ خوش آهي )
جر
- pruning قدم کان پوء، توهان مقدار شامل ڪري سگهو ٿا (مثال طور، TensorRT سان)
- Tensorflow لاء صلاحيتون مهيا ڪري ٿي . ڪم.
- مان ترقي ڪرڻ چاهيان ٿو ۽ مدد ڪرڻ ۾ خوش ٿيندو
جو ذريعو: www.habr.com
