

මුදලටය
අපේම නිර්මාණයේ විකුණුම් යන්ත්ර තිබේ. Raspberry Pi එක ඇතුලේ සහ වෙනම පුවරුවක වයරින් ටිකක්. කාසි භාර ගන්නෙකු, බිල්පත් පිළිගන්නා, බැංකු පර්යන්තයක් සම්බන්ධ වේ ... සියල්ල ස්වයං-ලිඛිත වැඩසටහනකින් පාලනය වේ. සම්පූර්ණ වැඩ ඉතිහාසය ෆ්ලෑෂ් ඩ්රයිව් එකක (MicroSD) ලොග් එකකට ලියා ඇත, එය පසුව අන්තර්ජාලය හරහා (USB මොඩමයක් භාවිතා කරමින්) සේවාදායකයට සම්ප්රේෂණය වේ, එය දත්ත ගබඩාවක ගබඩා කර ඇත. විකුණුම් තොරතුරු 1c වෙත පටවා ඇත, අධීක්ෂණය සඳහා සරල වෙබ් අතුරු මුහුණතක් ද ඇත.
එනම්, සඟරාව ඉතා වැදගත් වේ - ගිණුම්කරණය (ආදායම්, විකුණුම්, ආදිය), අධීක්ෂණය (සියලු ආකාරයේ අසාර්ථකත්වයන් සහ වෙනත් බලහත්කාර තත්වයන්); මෙම යන්ත්රය පිළිබඳ අප සතුව ඇති සියලුම තොරතුරු මෙය යැයි කෙනෙකුට පැවසිය හැකිය.
ප්රශ්නය
ෆ්ලෑෂ් ධාවකයන් ඉතා විශ්වාස කළ නොහැකි උපාංග ලෙස පෙන්වයි. ඔවුන් අපේක්ෂා කළ හැකි විධිමත්භාවයකින් අසමත් වේ. මෙය යන්ත්ර ක්රියා විරහිත වීම සහ (යම් හේතුවක් නිසා ලොගය මාර්ගගතව මාරු කළ නොහැකි නම්) දත්ත නැතිවීම යන දෙකටම මඟ පාදයි.
ෆ්ලෑෂ් ඩ්රයිව් භාවිතා කිරීමේ පළමු අත්දැකීම මෙය නොවේ, මීට පෙර උපාංග සියයකට වඩා වැඩි ප්රමාණයක් සහිත තවත් ව්යාපෘතියක් තිබුණි, එහිදී සඟරාව USB ෆ්ලෑෂ් ඩ්රයිව් වල ගබඩා කර ඇත, විශ්වසනීයත්වය පිළිබඳ ගැටළු ද ඇත, සමහර විට අසාර්ථක වූ සංඛ්යාව. මාසයක් දුසිම් ගණනකින් විය. අපි SLC මතකය සහිත වෙළඳනාම ඇතුළු විවිධ ෆ්ලෑෂ් ඩ්රයිව් උත්සාහ කළ අතර සමහර මාදිලි අනෙක් ඒවාට වඩා විශ්වාසදායක ය, නමුත් ෆ්ලෑෂ් ඩ්රයිව් ප්රතිස්ථාපනය කිරීමෙන් ගැටළුව රැඩිකල් ලෙස විසඳී නැත.
කරුණාකරලා! Longread! ඔබ "ඇයි" ගැන උනන්දුවක් නොදක්වන්නේ නම්, නමුත් "කෙසේද" පමණක් නම්, ඔබට කෙලින්ම යා හැකිය ලිපි.
තීරණය
මතකයට එන පළමු දෙය නම්: මයික්රෝ එස්ඩී අතහැර දමන්න, උදාහරණයක් ලෙස, එස්එස්ඩී එකක් ස්ථාපනය කර එයින් ආරම්භ කරන්න. න්යායාත්මකව හැකි, බොහෝ විට, නමුත් සාපේක්ෂව මිල අධික, සහ එතරම් විශ්වාසදායක නොවේ (USB-SATA ඇඩැප්ටරයක් එකතු කර ඇත; අයවැය SSD සඳහා අසාර්ථක සංඛ්යාලේඛන ද දිරිගන්වන සුළු නොවේ).
USB HDD ද විශේෂයෙන් ආකර්ෂණීය විසඳුමක් ලෙස නොපෙනේ.
එබැවින්, අපි මෙම විකල්පය වෙත පැමිණියෙමු: MicroSD වෙතින් ආරම්භ කිරීම අත්හැර, නමුත් ඒවා කියවීමට පමණක් භාවිතා කරන්න, සහ මෙහෙයුම් ලොගය (සහ විශේෂිත දෘඪාංග කැබැල්ලකට අනන්ය වූ අනෙකුත් තොරතුරු - අනුක්රමික අංකය, සංවේදක ක්රමාංකන ආදිය) වෙනත් ස්ථානයක ගබඩා කරන්න. .
රාස්ප්බෙරි සඳහා කියවීමට පමණක් FS යන මාතෘකාව දැනටමත් ඇතුළත සහ පිටත අධ්යයනය කර ඇත, මම මෙම ලිපියේ ක්රියාත්මක කිරීමේ විස්තර ගැන වාසය නොකරමි. (නමුත් උනන්දුවක් තිබේ නම්, සමහර විට මම මෙම මාතෘකාව පිළිබඳ කුඩා ලිපියක් ලියන්නෙමි). මම සටහන් කිරීමට කැමති එකම කරුණ නම් පුද්ගලික අත්දැකීම් වලින් සහ එය දැනටමත් ක්රියාත්මක කර ඇති අයගේ සමාලෝචන වලින්, විශ්වසනීයත්වයේ වාසියක් ඇති බවයි. ඔව්, බිඳවැටීම් සම්පූර්ණයෙන්ම ඉවත් කළ නොහැක, නමුත් ඒවායේ සංඛ්යාතය සැලකිය යුතු ලෙස අඩු කිරීම තරමක් හැකි ය. කාඩ්පත් ඒකාබද්ධ වෙමින් පවතින අතර එමඟින් සේවා පුද්ගලයින්ට ප්රතිස්ථාපනය වඩාත් පහසු වේ.
දෘඩාංග
මතක වර්ගය - NOR Flash තෝරා ගැනීම ගැන විශේෂ සැකයක් නොතිබුණි.
තර්ක:
- සරල සම්බන්ධතාවය (බොහෝ විට SPI බසය, ඔබ දැනටමත් භාවිතා කර අත්දැකීම් ඇති බැවින්, දෘඪාංග ගැටළු කිසිවක් අපේක්ෂා නොකෙරේ);
- හාස්යජනක මිල;
- සම්මත මෙහෙයුම් ප්රොටෝකෝලය (ක්රියාත්මක කිරීම දැනටමත් කර්නලයේ ඇත) Linux, ඔබට අවශ්ය නම්, ඔබට තෙවන පාර්ශවීය එකක් ගත හැකිය, ඒවා ද ඇත, නැතහොත් ඔබේම දෑ පවා ලිවිය හැකිය, වාසනාවකට මෙන්, සියල්ල සරලයි);
- විශ්වසනීයත්වය සහ සම්පත්:
සාමාන්ය දත්ත පත්රිකාවකින්: දත්ත වසර 20ක් ගබඩා කර ඇත, එක් එක් වාරණ සඳහා මකන චක්ර 100000;
තෙවන පාර්ශවීය මූලාශ්ර වලින්: අතිශයින් අඩු BER, දෝෂ නිවැරදි කිරීමේ කේත අවශ්ය නොවන බව උපකල්පනය කරයි (සමහර කෘතීන් NOR සඳහා ECC සලකනු ලැබේ, නමුත් සාමාන්යයෙන් ඒවා තවමත් MLC NOR අදහස් කරයි; මෙයද සිදු වේ).
පරිමාව සහ සම්පත් සඳහා අවශ්යතා තක්සේරු කරමු.
දින කිහිපයක් සඳහා දත්ත සුරැකීමට සහතික වීමට මම කැමතියි. කිසියම් සන්නිවේදන ගැටළු වලදී, විකුණුම් ඉතිහාසය අහිමි නොවන පරිදි මෙය අවශ්ය වේ. මෙම කාල සීමාව තුළ අපි දින 5 ක් කෙරෙහි අවධානය යොමු කරන්නෙමු (සති අන්ත සහ නිවාඩු දින පවා සැලකිල්ලට ගනිමින්) ගැටලුව විසඳා ගත හැකිය.
අපි දැනට දිනකට ලොග් 100kb (ඇතුල්වීම් 3-4 දහසක්) පමණ එකතු කරමු, නමුත් ක්රමයෙන් මෙම අගය වර්ධනය වෙමින් පවතී - විස්තර වැඩි වෙමින් පවතී, නව සිදුවීම් එකතු වේ. Plus, සමහර විට පිපිරීම් ඇත (සමහර සංවේදකය ව්යාජ ධනාත්මක සමග ස්පෑම් කිරීම ආරම්භ කරයි, උදාහරණයක් ලෙස). අපි වාර්තා 10 දහසක් සඳහා බයිට් 100 බැගින් ගණනය කරන්නෙමු - දිනකට මෙගාබයිට්.
සමස්තයක් වශයෙන්, 5MB පිරිසිදු (හොඳින් සම්පීඩිත) දත්ත පිටතට පැමිණේ. ඔවුන්ට තවත් (දල ඇස්තමේන්තුව) සේවා දත්ත 1MB.
එනම්, අපි සම්පීඩනය භාවිතා නොකරන්නේ නම් 8MB චිපයක් හෝ අප එය භාවිතා කරන්නේ නම් 4MB අවශ්ය වේ. මෙම වර්ගයේ මතකය සඳහා තරමක් යථාර්ථවාදී සංඛ්යා.
සම්පත සම්බන්ධයෙන් ගත් කල: සම්පූර්ණ මතකය සෑම දින 5 කට වරක් නොඅඩු ලෙස නැවත ලිවිය යුතු යැයි අපි සැලසුම් කරන්නේ නම්, වසර 10 කට වැඩි සේවා කාලයකදී අපට නැවත ලිවීමේ චක්ර දහසකට වඩා අඩුය.
නිෂ්පාදකයා ලක්ෂයක් පොරොන්දු වන බව මම ඔබට මතක් කරමි.
NOR vs NAND ගැන ටිකක්
අද, ඇත්ත වශයෙන්ම, NAND මතකය වඩාත් ජනප්රියයි, නමුත් මම එය මෙම ව්යාපෘතිය සඳහා භාවිතා නොකරමි: NAND, NOR මෙන් නොව, දෝෂ නිවැරදි කිරීමේ කේත, නරක කුට්ටි වගුවක් ආදිය භාවිතා කිරීම අවශ්ය වේ, සහ කකුල් NAND චිප්ස් සාමාන්යයෙන් ඊට වඩා වැඩිය.
NOR හි අවාසි වලට ඇතුළත් වන්නේ:
- කුඩා පරිමාව (සහ, ඒ අනුව, මෙගාබයිට් එකකට ඉහළ මිලක්);
- අඩු සන්නිවේදන වේගය (බොහෝ දුරට අනුක්රමික අතුරුමුහුණතක් භාවිතා කරන නිසා, සාමාන්යයෙන් SPI හෝ I2C);
- මන්දගාමී මකාදැමීම (බ්ලොක් ප්රමාණය අනුව, එය තත්පරයක කොටසක සිට තත්පර කිහිපයක් දක්වා ගත වේ).
අපට විවේචනාත්මක කිසිවක් නොමැති බව පෙනේ, එබැවින් අපි දිගටම කරගෙන යන්නෙමු.
විස්තර රසවත් නම්, ක්ෂුද්ර පරිපථය තෝරාගෙන ඇත (කෙසේ වෙතත්, මෙය නොවැදගත් ය, pinout සහ විධාන පද්ධතියට අනුකූල වන බොහෝ ප්රතිසමයන් වෙළඳපොලේ ඇත; අපට වෙනත් නිෂ්පාදකයෙකුගෙන් සහ / හෝ වෙනත් ප්රමාණයකින් ක්ෂුද්ර පරිපථයක් ස්ථාපනය කිරීමට අවශ්ය වුවද, සියල්ල වෙනස් නොකර ක්රියා කරයි. කේතය).
මම කර්නලය තුළ ගොඩනගා ඇති එක භාවිතා කරමි. Linux ධාවකය, Raspberry මත, උපාංග ගස් උඩැතිරි සහායට ස්තූතියි, සියල්ල ඉතා සරලයි - ඔබ සම්පාදනය කරන ලද උඩැතිරිය /boot/overlays තුළට දමා /boot/config.txt තරමක් වෙනස් කළ යුතුය.
උදාහරණ dts ගොනුව
අවංකවම, එය දෝෂයකින් තොරව ලියා ඇති බව මට විශ්වාස නැත, නමුත් එය ක්රියා කරයි.
/*
* Device tree overlay for at25 at spi0.1
*/
/dts-v1/;
/plugin/;
/ {
compatible = "brcm,bcm2835", "brcm,bcm2836", "brcm,bcm2708", "brcm,bcm2709";
/* disable spi-dev for spi0.1 */
fragment@0 {
target = <&spi0>;
__overlay__ {
status = "okay";
spidev@1{
status = "disabled";
};
};
};
/* the spi config of the at25 */
fragment@1 {
target = <&spi0>;
__overlay__ {
#address-cells = <1>;
#size-cells = <0>;
flash: m25p80@1 {
compatible = "atmel,at25df321a";
reg = <1>;
spi-max-frequency = <50000000>;
/* default to false:
m25p,fast-read ;
*/
};
};
};
__overrides__ {
spimaxfrequency = <&flash>,"spi-max-frequency:0";
fastread = <&flash>,"m25p,fast-read?";
};
};සහ config.txt හි තවත් පේළියක්
dtoverlay=at25:spimaxfrequency=50000000Raspberry Pi වෙත චිපය සම්බන්ධ කිරීමේ විස්තරය මම මග හරිමි. එක් අතකින්, මම ඉලෙක්ට්රොනික විද්යාව පිළිබඳ විශේෂ expert යෙක් නොවේ, අනෙක් අතට, මෙහි ඇති සියල්ල මට පවා අශෝභන ය: ක්ෂුද්ර පරිපථයට ඇත්තේ කකුල් 8 ක් පමණි, එයින් අපට අවශ්ය වන්නේ භූමිය, බලය, SPI (CS, SI, SO, SCK) ); මට්ටම් Raspberry Pi හි මට්ටමට සමාන වේ, අමතර රැහැන් අවශ්ය නොවේ - සඳහන් කර ඇති අල්ෙපෙනති 6 සම්බන්ධ කරන්න.
ගැටලුව ප්රකාශ කිරීම
සුපුරුදු පරිදි, ගැටළු ප්රකාශය පුනරාවර්තන කිහිපයක් හරහා යන අතර, එය ඊළඟ එක සඳහා කාලය බව මට පෙනේ. ඒ නිසා අපි නවතිමු, දැනටමත් ලියා ඇති දේ එකට එකතු කර, සෙවනැල්ලේ ඉතිරිව ඇති විස්තර පැහැදිලි කරන්න.
එබැවින්, ලොගය SPI NOR Flash හි ගබඩා කිරීමට අපි තීරණය කර ඇත්තෙමු.
නොදන්නා අයට NOR Flash යනු කුමක්ද?
මෙය වාෂ්පශීලී නොවන මතකයක් වන අතර ඔබට මෙහෙයුම් තුනක් කළ හැකිය:
- කියවීම:
වඩාත් පොදු කියවීම: අපි ලිපිනය සම්ප්රේෂණය කර අපට අවශ්ය තරම් බයිට් කියවා; - වාර්තාව:
NOR ෆ්ලෑෂ් වෙත ලිවීම සාමාන්ය එකක් ලෙස පෙනේ, නමුත් එයට එක් විශේෂත්වයක් ඇත: ඔබට වෙනස් කළ හැක්කේ 1 සිට 0 දක්වා පමණි, නමුත් අනෙක් අතට නොවේ. උදාහරණයක් ලෙස, අපට මතක සෛලයක 0x55 තිබුනේ නම්, එයට 0x0f ලිවීමෙන් පසු, 0x05 දැනටමත් එහි ගබඩා වේ. (පහත වගුව බලන්න); - මකන්න:
ඇත්ත වශයෙන්ම, අපට ප්රතිවිරුද්ධ මෙහෙයුම කිරීමට හැකි විය යුතුය - 0 සිට 1 දක්වා වෙනස් කරන්න, මකා දැමීමේ මෙහෙයුම හරියටම මෙයයි. පළමු දෙක මෙන් නොව, එය බයිට් සමඟ නොව, බ්ලොක් සමඟ ක්රියා කරයි (තෝරාගත් චිපයේ අවම මකාදැමීම 4kb වේ). Erase මගින් සම්පූර්ණ බ්ලොක් එක විනාශ වන අතර 0 සිට 1 දක්වා වෙනස් කිරීමට ඇති එකම ක්රමය එයයි. එම නිසා ෆ්ලෑෂ් මතකය සමඟ වැඩ කිරීමේදී බොහෝ විට දත්ත ව්යුහයන් මකන බ්ලොක් මායිමට පෙළගස්වීමට සිදුවේ.
NOR Flash හි පටිගත කිරීම:
ද්විමය දත්ත
විය
01010101
පටිගත කර ඇත
00001111
බවට පත්ව ඇත
00000101
ලොගයම විචල්ය දිගේ වාර්තා අනුපිළිවෙලක් නියෝජනය කරයි. වාර්තාවක සාමාන්ය දිග බයිට් 30ක් පමණ වේ (කිලෝබයිට් කිහිපයක් දිග වාර්තා සමහර විට සිදු වුවද). මෙම අවස්ථාවේදී, අපි ඔවුන් සමඟ වැඩ කරන්නේ බයිට් කට්ටලයක් ලෙස, නමුත්, ඔබ කැමති නම්, CBOR වාර්තා තුළ භාවිතා වේ
ලොගයට අමතරව, අපට යාවත්කාලීන වූ සහ නැති “සැකසීම්” තොරතුරු කිහිපයක් ගබඩා කිරීමට අවශ්ය වේ: යම් උපාංග හැඳුනුම්පතක්, සංවේදක ක්රමාංකන, “උපාංගයක් තාවකාලිකව අක්රීය කර ඇත” ධජය යනාදිය.
මෙම තොරතුරු CBOR හි ගබඩා කර ඇති ප්රධාන වටිනාකම් වාර්තා සමූහයකි. අප සතුව මෙම තොරතුරු විශාල ප්රමාණයක් නොමැත (උපරිම වශයෙන් කිලෝබයිට් කිහිපයක්), එය කලාතුරකින් යාවත්කාලීන වේ.
ඊළඟට අපි එය සන්දර්භය ලෙස හඳුන්වමු.
මෙම ලිපිය ආරම්භ වූයේ කොතැනින්දැයි අපට මතක නම්, විශ්වාසදායක දත්ත ගබඩා කිරීම සහ, හැකි නම්, දෘඪාංග අසමත්වීම්/දත්ත දූෂණයකදී පවා අඛණ්ඩව ක්රියාත්මක වීම සහතික කිරීම ඉතා වැදගත් වේ.
සලකා බැලිය හැකි ගැටළු මූලාශ්ර මොනවාද?
- ලිවීමේ/මැකීමේ මෙහෙයුම් අතරතුර බලය අක්රියයි. මෙය "කකුළුවෙකුට එරෙහිව උපක්රමයක් නැත" යන ප්රවර්ගයෙනි.
වෙතින් තොරතුරු Stackexchange මත: ෆ්ලෑෂ් සමඟ වැඩ කරන අතරතුර බලය අක්රිය වූ විට, මකා දැමීම (1 ලෙස සකසා ඇත) සහ ලිවීම (0 ලෙස සකසා ඇත) යන දෙකම නිර්වචනය නොකළ හැසිරීම් වලට මග පාදයි: දත්ත ලිවිය හැකිය, අර්ධ වශයෙන් ලිවිය හැකිය (කියන්න, අපි බයිට් 10/බිට් 80 මාරු කළෙමු. , නමුත් තවම ලිවිය හැක්කේ බිටු 45ක් පමණක් නොවේ), සමහර බිටු "අතරමැදි" තත්වයක තිබිය හැකිය (කියවීම 0 සහ 1 යන දෙකම නිපදවිය හැක); - ෆ්ලෑෂ් මතකයේම දෝෂ.
BER, ඉතා අඩු වුවද, ශුන්යයට සමාන විය නොහැක; - බස් දෝෂ
SPI හරහා සම්ප්රේෂණය වන දත්ත කිසිඳු ආකාරයකින් ආරක්ෂා නොකෙරේ; තනි බිටු දෝෂ සහ සමමුහුර්ත කිරීමේ දෝෂ යන දෙකම සිදු විය හැක - බිටු නැතිවීම හෝ ඇතුල් කිරීම (දැවැන්ත දත්ත විකෘතියකට තුඩු දෙයි); - වෙනත් දෝෂ / දෝෂ
කේතයේ දෝෂ, රාස්ප්බෙරි දෝෂ, පිටසක්වල මැදිහත්වීම්...
මම අවශ්යතා සකස් කර ඇති අතර, ඒවා ඉටු කිරීම, මගේ මතය අනුව, විශ්වසනීයත්වය සහතික කිරීම සඳහා අවශ්ය වේ:
- වාර්තා වහාම ෆ්ලෑෂ් මතකයට යා යුතුය, ප්රමාද වූ ලිවීම් නොසැලකේ; - දෝෂයක් සිදුවුවහොත්, එය හැකි ඉක්මනින් හඳුනාගෙන සැකසිය යුතුය; - පද්ධතිය, හැකි නම්, දෝෂ වලින් යථා තත්ත්වයට පත් විය යුතුය.
(එය "එය නොවිය යුතු ආකාරය" ජීවිතයෙන් උදාහරණයක්, සෑම කෙනෙකුම මුහුණ දී ඇති බව මම සිතමි: හදිසි නැවත පණගැන්වීමෙන් පසු, ගොනු පද්ධතිය "කැඩී" ඇති අතර මෙහෙයුම් පද්ධතිය ආරම්භ නොවේ)
අදහස්, ප්රවේශයන්, පරාවර්තන
මම මෙම ගැටලුව ගැන සිතීමට පටන් ගත් විට, මගේ හිස හරහා බොහෝ අදහස් දැල්වීය, උදාහරණයක් ලෙස:
- දත්ත සම්පීඩනය භාවිතා කරන්න;
- දක්ෂ දත්ත ව්යුහයන් භාවිතා කරන්න, උදාහරණයක් ලෙස, වාර්තා වලින් වෙන් වෙන්ව වාර්තා ශීර්ෂ ගබඩා කිරීම, එවිට ඕනෑම වාර්තාවක දෝෂයක් තිබේ නම්, ඔබට කිසිදු ගැටළුවක් නොමැතිව ඉතිරිය කියවිය හැකිය;
- බලය අක්රිය වූ විට පටිගත කිරීම සම්පූර්ණ කිරීම පාලනය කිරීම සඳහා බිට් ක්ෂේත්ර භාවිතා කරන්න;
- සියල්ල සඳහා චෙක්සම් ගබඩා කරන්න;
- යම් ආකාරයක ශබ්ද-ප්රතිරෝධී කේතීකරණ භාවිතා කරන්න.
මෙම අදහස් සමහරක් භාවිතා කරන ලද අතර අනෙක් ඒවා අත්හැර දැමීමට තීරණය විය. අපි පිළිවෙලට යමු.
දත්ත සම්පීඩනය
අපි සඟරාවේ වාර්තා කරන සිදුවීම් බොහෝ දුරට සමාන සහ පුනරාවර්තනය වේ ("රූබල් 5 කාසියක් විසි කළා", "වෙනස් කිරීම සඳහා බොත්තම ඔබන්න", ...). එබැවින්, සම්පීඩනය බෙහෙවින් ඵලදායී විය යුතුය.
සම්පීඩන උඩිස් ගණන නොවැදගත් ය (අපගේ ප්රොසෙසරය තරමක් බලවත් ය, පළමු Pi හි පවා 700 MHz සංඛ්යාතයක් සහිත එක් හරයක් තිබුණි, වත්මන් මාදිලිවල ගිගාහර්ට්ස් එකකට වඩා වැඩි සංඛ්යාතයක් සහිත මධ්ය කිහිපයක් ඇත), ගබඩාව සමඟ විනිමය අනුපාතය අඩුය (කිහිපයක් තත්පරයට මෙගාබයිට්), වාර්තා වල විශාලත්වය කුඩා වේ. සාමාන්යයෙන්, සම්පීඩනය කාර්ය සාධනය කෙරෙහි බලපෑමක් ඇති කරයි නම්, එය ධනාත්මක වනු ඇත. (සම්පූර්ණයෙන්ම විවේචනාත්මක නොවේ, ප්රකාශ කිරීම පමණි)ඊට අමතරව, අප සතුව සැබෑ එම්බඩඩ් එකක් නැත, නමුත් සාමාන්ය එකක්. Linux — එබැවින් ක්රියාත්මක කිරීම සඳහා වැඩි උත්සාහයක් අවශ්ය නොවිය යුතුය (පුස්තකාලය සම්බන්ධ කර එයින් කාර්යයන් කිහිපයක් භාවිතා කිරීම පමණක් ප්රමාණවත් වේ).
ලොග් කැබැල්ලක් ක්රියාකාරී උපාංගයකින් (1.7 MB, 70 දහසක් ඇතුළත් කිරීම්) ලබාගෙන පරිගණකයේ ඇති gzip, lz4, lzop, bzip2, xz, zstd භාවිතයෙන් සම්පීඩනය සඳහා පළමුව පරීක්ෂා කරන ලදී.
- gzip, xz, zstd සමාන ප්රතිඵල පෙන්වයි (40Kb).
විලාසිතාමය xz මෙහි gzip හෝ zstd මට්ටමින් පෙන්නුම් කිරීම ගැන මම පුදුමයට පත් විය; - පෙරනිමි සැකසුම් සමඟ lzip තරමක් නරක ප්රතිඵල ලබා දුන්නේය;
- lz4 සහ lzop ඉතා හොඳ ප්රතිඵල නොපෙන්වයි (150Kb);
- bzip2 පුදුම සහගත ලෙස හොඳ ප්රතිඵලයක් (18Kb) පෙන්නුම් කළේය.
එබැවින්, දත්ත ඉතා හොඳින් සම්පීඩිත වේ.
එබැවින් (අපි මාරාන්තික අඩුපාඩු සොයා නොගන්නේ නම්) සම්පීඩනය වනු ඇත! එකම ෆ්ලෑෂ් ඩ්රයිව් එකට වැඩි දත්ත ප්රමාණයක් ගැළපෙන නිසා.
අවාසි ගැන සිතමු.
පළමු ගැටළුව: සෑම වාර්තාවක්ම වහාම ෆ්ලෑෂ් වෙත යා යුතු බවට අපි දැනටමත් එකඟ වී ඇත. සාමාන්යයෙන්, ලේඛනාගාරය සති අන්තයේ ලිවීමට කාලය බව තීරණය කරන තෙක් ආදාන ප්රවාහයෙන් දත්ත රැස් කරයි. අපි වහාම සම්පීඩිත දත්ත බ්ලොක් එකක් ලබා ගත යුතු අතර එය වාෂ්පශීලී නොවන මතකයේ ගබඩා කළ යුතුය.
මම ආකාර තුනක් දකිමි:
- ඉහත සාකච්ඡා කර ඇති ඇල්ගොරිතම වෙනුවට ශබ්ද කෝෂ සම්පීඩනය භාවිතයෙන් සෑම වාර්තාවක්ම සම්පීඩනය කරන්න.
එය සම්පූර්ණයෙන්ම වැඩ කරන විකල්පයකි, නමුත් මම එයට කැමති නැත. වැඩි හෝ අඩු යහපත් මට්ටමේ සම්පීඩනයක් සහතික කිරීම සඳහා, ශබ්දකෝෂය නිශ්චිත දත්ත වලට "ගැලපෙන" විය යුතුය; ඕනෑම වෙනසක් සම්පීඩන මට්ටම ව්යසනකාරී ලෙස පහත වැටීමට හේතු වේ. ඔව්, ශබ්දකෝෂයේ නව අනුවාදයක් නිර්මාණය කිරීමෙන් ගැටළුව විසඳා ගත හැකිය, නමුත් මෙය හිසරදයකි - අපට ශබ්දකෝෂයේ සියලුම අනුවාද ගබඩා කිරීමට අවශ්ය වනු ඇත; සෑම ප්රවේශයකම එය සම්පීඩිත ශබ්දකෝෂයේ කුමන අනුවාදයෙන්ද යන්න සඳහන් කිරීමට අපට අවශ්ය වනු ඇත... - "සම්භාව්ය" ඇල්ගොරිතම භාවිතයෙන් සෑම වාර්තාවක්ම සම්පීඩනය කරන්න, නමුත් අනෙක් ඒවායින් ස්වාධීනව.
සලකා බලනු ලබන සම්පීඩන ඇල්ගොරිතම මෙම ප්රමාණයේ (බයිට් දස දහස් ගණනක) වාර්තා සමඟ වැඩ කිරීමට සැලසුම් කර නොමැත, සම්පීඩන අනුපාතය පැහැදිලිවම 1 ට වඩා අඩු වනු ඇත (එනම්, සම්පීඩනය වෙනුවට දත්ත පරිමාව වැඩි කිරීම); - එක් එක් පටිගත කිරීමෙන් පසු ෆ්ලෂ් කරන්න.
බොහෝ සම්පීඩන පුස්තකාලවල FluSH සඳහා සහය ඇත. මෙය විධානයක් (හෝ සම්පීඩන ක්රියා පටිපාටියට පරාමිතියකි), එය ලැබීමෙන් පසු ලේඛනාගාරය සම්පීඩිත ප්රවාහයක් සාදයි, එවිට එය ප්රතිසාධනය කිරීමට භාවිතා කළ හැකිය. සියල්ල දැනටමත් ලැබී ඇති සම්පීඩිත නොකළ දත්ත. එවැනි ප්රතිසමයක්syncගොනු පද්ධති තුළ හෝcommitවර්ග කි.මී.
වැදගත් වන්නේ පසුකාලීන සම්පීඩන මෙහෙයුම් සමුච්චිත ශබ්දකෝෂය භාවිතා කිරීමට හැකි වනු ඇති අතර සම්පීඩන අනුපාතය පෙර අනුවාදයේ තරම් දුක් විඳින්නේ නැත.
මම හිතන්නේ මම තුන්වන විකල්පය තෝරා ගත් බව පැහැදිලිය, අපි එය වඩාත් විස්තරාත්මකව බලමු.
හමු විය zlib වලින් FLUSH ගැන.
මම ලිපිය මත පදනම්ව දණහිස් පරීක්ෂණයක් කළා, පිටු ප්රමාණය 70Kb සමඟ සැබෑ උපාංගයකින් ලොග් සටහන් 60 ක් ලබා ගත්තෙමි. (අපි පසුව පිටු ප්රමාණයට එන්නෙමු) ලැබුණු:
මූලාශ්ර දත්ත
සම්පීඩනය gzip -9 (ෆ්ලෂ් නැත)
Z_PARTIAL_FLUSH සමඟ zlib
Z_SYNC_FLUSH සමඟ zlib
පරිමාව, KB
1692
40
352
604
මුලින්ම බැලූ බැල්මට, FLUSH විසින් දායක වූ මිල අධික ලෙස ඉහළ ය, නමුත් යථාර්ථයේ දී අපට කුඩා තේරීමක් ඇත - එක්කෝ කිසිසේත් සම්පීඩනය නොකිරීමට හෝ FLUSH සමඟ සම්පීඩනය කිරීමට (හා ඉතා ඵලදායී ලෙස). අප සතුව වාර්තා 70 දහසක් ඇති බව අප අමතක නොකළ යුතුය, Z_PARTIAL_FLUSH විසින් හඳුන්වා දුන් අතිරික්තය එක් වාර්තාවකට බයිට් 4-5 ක් පමණි. සම්පීඩන අනුපාතය 5: 1 ට ආසන්න විය, එය විශිෂ්ට ප්රතිඵලයකට වඩා වැඩි ය.
එය පුදුමයට කරුණක් විය හැක, නමුත් Z_SYNC_FLUSH ඇත්ත වශයෙන්ම FLUSH කිරීමට වඩාත් කාර්යක්ෂම ක්රමයකි.
Z_SYNC_FLUSH භාවිතා කරන විට, එක් එක් ප්රවේශයේ අවසාන බයිට් 4 සෑම විටම 0x00, 0x00, 0xff, 0xff වේ. අපි ඒවා දන්නේ නම්, අපට ඒවා ගබඩා කිරීමට අවශ්ය නැත, එබැවින් අවසාන ප්රමාණය 324Kb පමණි.
මා සම්බන්ධ කළ ලිපියේ පැහැදිලි කිරීමක් ඇත:
හිස් අන්තර්ගතයන් සහිත නව වර්ගයේ 0 බ්ලොක් එකක් එකතු කර ඇත.
හිස් අන්තර්ගතයන් සහිත 0 වර්ගයේ බ්ලොක් එකක් සමන්විත වන්නේ:
- බිටු තුනේ වාරණ ශීර්ෂය;
- බයිට් පෙළගැස්ම සාක්ෂාත් කර ගැනීම සඳහා බිටු 0 සිට 7 දක්වා ශුන්යයට සමාන වේ;
- බයිට් හතරේ අනුපිළිවෙල 00 00 FF FF.
ඔබට පහසුවෙන් පෙනෙන පරිදි, මෙම බයිට් 4 ට පෙර අවසාන බ්ලොක් එකේ බිටු 3 සිට 10 දක්වා ඇත. කෙසේ වෙතත්, ප්රායෝගිකව පෙන්නුම් කර ඇත්තේ ඇත්ත වශයෙන්ම අවම වශයෙන් බිටු 10 ක් වත් ඇති බවයි.
එවැනි කෙටි දත්ත බ්ලොක් සාමාන්යයෙන් (සැමවිටම?) කේතනය කර ඇත්තේ 1 වර්ගයේ (ස්ථාවර බ්ලොක්) බ්ලොක් එකක් භාවිතයෙන් බව පෙනේ, එය අනිවාර්යයෙන්ම ශුන්ය බිටු 7 කින් අවසන් වන අතර, සම්පූර්ණ සහතික බිටු 10-17 ක් ලබා දෙයි (සහ ඉතිරිය 50% ක පමණ සම්භාවිතාවකින් ශුන්ය විය යුතුය).
එබැවින්, පරීක්ෂණ දත්ත මත, 100% අවස්ථා වලදී 0x00, 0x00, 0xff, 0xff ට පෙර එක් ශුන්ය බයිටයක් ඇති අතර, අවස්ථා තුනෙන් එකකට වඩා ශුන්ය බයිට් දෙකක් ඇත. (සමහර විට කාරණය නම් මම ද්විමය CBOR භාවිතා කරන අතර, JSON පෙළ භාවිතා කරන විට, 2 වර්ගයේ - ගතික බ්ලොක් වඩාත් සුලභ වනු ඇත, පිළිවෙලින්, 0x00, 0x00, 0xff, 0xff ට පෙර අමතර ශුන්ය බයිට් නොමැති කුට්ටි හමුවනු ඇත).
සමස්තයක් වශයෙන්, පවතින පරීක්ෂණ දත්ත භාවිතයෙන්, සම්පීඩිත දත්ත 250Kb ට වඩා අඩු ප්රමාණයකට ගැලපේ.
බිට් ජුගුල් කිරීමෙන් ඔබට තව ටිකක් ඉතිරි කර ගත හැක: දැනට අපි බ්ලොක් එකේ අවසානයේ බිටු කිහිපයක් තිබීම නොසලකා හරිමු, බ්ලොක් එකේ ආරම්භයේ බිටු කිහිපයක් ද වෙනස් නොවේ...
නමුත් පසුව මම නැවැත්වීමට දැඩි කැමැත්තෙන් තීරණයක් ගත්තෙමි, එසේ නොමැතිනම් මෙම අනුපාතයෙන් මට මගේම ලේඛනාගාරයක් සංවර්ධනය කළ හැකිය.
සමස්තයක් වශයෙන්, මගේ පරීක්ෂණ දත්ත වලින් මට ලිවීමකට බයිට් 3-4 ක් ලැබුණි, සම්පීඩන අනුපාතය 6: 1 ට වඩා වැඩි විය. මම අවංක වන්නෙමි: මම එවැනි ප්රතිඵලය අපේක්ෂා නොකළෙමි; මගේ මතය අනුව, 2: 1 ට වඩා හොඳ දෙයක් දැනටමත් සම්පීඩනය භාවිතා කිරීම සාධාරණීකරණය කරන ප්රතිඵලයකි.
සෑම දෙයක්ම හොඳයි, නමුත් zlib (deflate) තවමත් පැරණි, හොඳින් සුදුසු සහ තරමක් පැරණි තාලයේ සම්පීඩන ඇල්ගොරිතමයකි. සම්පීඩිත නොකළ දත්ත ප්රවාහයේ අවසාන 32Kb ශබ්ද කෝෂයක් ලෙස භාවිතා කිරීම අද අමුතු දෙයක් ලෙස පෙනේ (එනම්, සමහර දත්ත වාරණ 40Kb පෙර ආදාන ප්රවාහයේ තිබූ දෙයට බෙහෙවින් සමාන නම්, එය නැවත සංරක්ෂණය කිරීමට පටන් ගනී. සහ පෙර සිදුවීමකට යොමු නොවේ). විලාසිතාමය නවීන ලේඛනාගාරවල, ශබ්ද කෝෂ ප්රමාණය බොහෝ විට මනිනු ලබන්නේ කිලෝබයිට් වලට වඩා මෙගාබයිට් වලින්.
එබැවින් අපි ලේඛනාගාර පිළිබඳ අපගේ කුඩා අධ්යයනය දිගටම කරගෙන යන්නෙමු.
මීළඟට අපි bzip2 පරීක්ෂා කළෙමු (මතක තබා ගන්න, FLUSH නොමැතිව එය 100:1 තරම් වූ අපූරු සම්පීඩන අනුපාතයක් පෙන්නුම් කළේය). අවාසනාවකට මෙන්, එය FLUSH සමඟ ඉතා දුර්වල ලෙස ක්රියාත්මක විය; සම්පීඩිත දත්තවල ප්රමාණය සම්පීඩිත නොකළ දත්තවලට වඩා විශාල විය.
අසාර්ථක වීමට හේතු ගැන මගේ උපකල්පන
Libbz2 ඉදිරිපත් කරන්නේ එක් ෆ්ලෂ් විකල්පයක් පමණක් වන අතර, එය ශබ්දකෝෂය ඉවත් කරන බව පෙනේ (zlib හි Z_FULL_FLUSH ට සමාන); මෙයින් පසු කිසිදු ඵලදායී සම්පීඩනයක් ගැන කතා නොකරයි.
ඒවගේම අන්තිමට ටෙස්ට් කරපු එක zstd. පරාමිතීන් මත පදනම්ව, එය gzip මට්ටමින් සම්පීඩනය කරයි, නමුත් වඩා වේගවත් හෝ gzip වඩා හොඳය.
අහෝ, ෆ්ලෂ් සමඟ එය ඉතා හොඳින් ක්රියා කළේ නැත: සම්පීඩිත දත්තවල ප්රමාණය 700Kb පමණ විය.
Я ව්යාපෘතියේ github පිටුවෙන්, මට පිළිතුරක් ලැබුණි, ඔබ සම්පීඩිත දත්ත එක් එක් බ්ලොක් එකක් සඳහා සේවා දත්ත බයිට් 10ක් දක්වා ගණන් කළ යුතු බවට පිළිතුරක් ලැබුණි, එය ලබාගත් ප්රතිඵලවලට ආසන්නයි; deflate සමඟ අල්ලා ගැනීමට ක්රමයක් නැත.
ලේඛනාගාර සමඟ මගේ අත්හදා බැලීම් වලදී මම මෙම අවස්ථාවේදී නතර කිරීමට තීරණය කළෙමි (xz, lzip, lzo, lz4 FLUSH නොමැතිව පරීක්ෂණ අදියරේදී පවා නොපෙන්වන බව මම ඔබට මතක් කර දෙන්නෙමි, සහ මම වඩාත් විදේශීය සම්පීඩන ඇල්ගොරිතම සලකා බැලුවේ නැත).
සංරක්ෂිත ගැටළු වෙත ආපසු යමු.
දෙවන (ඔවුන් පවසන පරිදි, වටිනාකමින් නොව, පිළිවෙලට) ගැටළුව වන්නේ සම්පීඩිත දත්ත තනි ධාරාවක් වන අතර, එහි පෙර කොටස් වෙත නිරන්තරයෙන් යොමු වේ. මේ අනුව, සම්පීඩිත දත්ත කොටසකට හානි සිදුවුවහොත්, සම්පීඩිත දත්තවල සම්බන්ධිත බ්ලොක් පමණක් නොව, පසුව ඇති සියලුම ඒවා ද අපට අහිමි වේ.
මෙම ගැටළුව විසඳීම සඳහා ප්රවේශයක් තිබේ:
- ගැටළුව ඇතිවීම වලක්වන්න - සම්පීඩිත දත්ත වලට අතිරික්තය එකතු කරන්න, එමඟින් දෝෂ හඳුනා ගැනීමට සහ නිවැරදි කිරීමට ඔබට ඉඩ සලසයි; අපි මේ ගැන පසුව කතා කරමු;
- ගැටලුවක් ඇති වුවහොත් ප්රතිවිපාක අවම කරන්න
ඔබට එක් එක් දත්ත වාරණ ස්වාධීනව සම්පීඩනය කළ හැකි බව අපි කලින් පවසා ඇති අතර, ගැටළුව තනිවම පහව යනු ඇත (එක් බ්ලොක් එකක දත්ත වලට හානි වීම මෙම කොටස සඳහා පමණක් දත්ත නැති වීමට හේතු වේ). කෙසේ වෙතත්, මෙය දත්ත සම්පීඩනය අකාර්යක්ෂම වන ආන්තික අවස්ථාවකි. ප්රතිවිරුද්ධ අන්තය: අපගේ චිපයේ සියලුම 4MB තනි ලේඛනාගාරයක් ලෙස භාවිතා කරන්න, එය අපට විශිෂ්ට සම්පීඩනයක් ලබා දෙනු ඇත, නමුත් දත්ත දූෂණය වූ විට ව්යසනකාරී ප්රතිවිපාක.
ඔව්, විශ්වසනීයත්වය සම්බන්ධයෙන් සම්මුතියක් අවශ්ය වේ. නමුත් අපි මතක තබා ගත යුතු කරුණක් නම්, අපි අතිශයින් අඩු BER සහ වසර 20 ක ප්රකාශිත දත්ත ගබඩා කාලයක් සහිත වාෂ්පශීලී නොවන මතකය සඳහා දත්ත ගබඩා කිරීමේ ආකෘතියක් සංවර්ධනය කරන බවයි.
පරීක්ෂණ අතරතුර, සම්පීඩන මට්ටමේ වැඩි හෝ අඩු සැලකිය යුතු පාඩු ආරම්භ වන්නේ 10 KB ට වඩා අඩු සම්පීඩිත දත්ත කොටස් මත බව මම සොයා ගතිමි.
භාවිතා කරන මතකය පිටුගත කර ඇති බව කලින් සඳහන් කර ඇත; “එක් පිටුවක් - සම්පීඩිත දත්ත එක් කොටසක” ලිපි හුවමාරුව භාවිතා නොකළ යුතු බවට කිසිදු හේතුවක් මට නොපෙනේ.
එනම්, අවම සාධාරණ පිටු ප්රමාණය 16Kb (සේවා තොරතුරු සඳහා රක්ෂිතයක් සහිත) වේ. කෙසේ වෙතත්, එවැනි කුඩා පිටු ප්රමාණය උපරිම වාර්තා ප්රමාණයට සැලකිය යුතු සීමාවන් පනවා ඇත.
මම තවමත් සම්පීඩිත ආකාරයෙන් කිලෝබයිට් කිහිපයකට වඩා විශාල වාර්තා බලාපොරොත්තු නොවූවත්, මම 32Kb පිටු (චිපයකට පිටු 128ක් සඳහා) භාවිතා කිරීමට තීරණය කළෙමි.
සාරාංශය:
- අපි zlib (deflate) භාවිතයෙන් සම්පීඩිත දත්ත ගබඩා කරමු;
- සෑම ප්රවේශයක් සඳහාම අපි Z_SYNC_FLUSH සකසන්නෙමු;
- සෑම සම්පීඩිත වාර්තාවක් සඳහාම, අපි පසුපස බයිට් කප්පාදු කරමු (උදා: 0x00, 0x00, 0xff, 0xff); ශීර්ෂයේ අපි බයිට් කීයක් කපා දැමුවද;
- අපි 32Kb පිටු වල දත්ත ගබඩා කරමු; පිටුව තුළ සම්පීඩිත දත්ත එක් ප්රවාහයක් ඇත; සෑම පිටුවකම අපි නැවත සම්පීඩනය ආරම්භ කරමු.
තවද, සම්පීඩනය සමඟ අවසන් කිරීමට පෙර, අප සතුව ඇත්තේ එක් වාර්තාවකට සම්පීඩිත දත්ත බයිට් කිහිපයක් පමණක් බව ඔබේ අවධානයට යොමු කිරීමට කැමැත්තෙමි, එබැවින් සේවා තොරතුරු පුම්බා නොගැනීම අතිශයින්ම වැදගත්ය, සෑම බයිටයක්ම මෙහි ගණන් ගනී.
දත්ත ශීර්ෂ ගබඩා කිරීම
විචල්ය දිග පිළිබඳ වාර්තා අප සතුව ඇති බැවින්, අපි කෙසේ හෝ වාර්තාවල ස්ථානගත කිරීම්/සීමා තීරණය කළ යුතුය.
මම ප්රවේශ තුනක් දනිමි:
- සියලුම වාර්තා අඛණ්ඩ ප්රවාහයක ගබඩා කර ඇත, පළමුව දිග අඩංගු වාර්තා ශීර්ෂයක් ඇත, පසුව වාර්තාවම ඇත.
මෙම ප්රතිමූර්තිය තුළ, ශීර්ෂක සහ දත්ත යන දෙකම විචල්ය දිගකින් යුක්ත විය හැක.
අත්යවශ්යයෙන්ම, අපට සෑම විටම භාවිතා වන තනි සම්බන්ධිත ලැයිස්තුවක් ලැබේ; - ශීර්ෂයන් සහ වාර්තා වෙනම ප්රවාහවල ගබඩා කර ඇත.
නියත දිගකින් යුත් ශීර්ෂ භාවිතා කිරීමෙන්, එක් ශීර්ෂයකට වන හානිය අනෙක් ඒවාට බලපාන්නේ නැති බව අපි සහතික කරමු.
සමාන ප්රවේශයක් භාවිතා කරයි, උදාහරණයක් ලෙස, බොහෝ ගොනු පද්ධතිවල; - වාර්තා අඛණ්ඩ ප්රවාහයක ගබඩා කර ඇත, වාර්තා මායිම නිශ්චිත සලකුණු කරුවෙකු විසින් තීරණය කරනු ලැබේ (දත්ත කොටස් තුළ තහනම් කර ඇති අක්ෂර අනුපිළිවෙලක්). වාර්තාවේ ඇතුළත සලකුණක් තිබේ නම්, අපි එය යම් අනුපිළිවෙලකින් ප්රතිස්ථාපනය කරමු (එය පැන යන්න).
උදාහරණයක් ලෙස, PPP ප්රොටෝකෝලය තුළ සමාන ප්රවේශයක් භාවිතා වේ.
මම නිදර්ශනය කරන්නම්.
විකල්ප 1:

මෙහි සෑම දෙයක්ම ඉතා සරලයි: වාර්තාවේ දිග දැන ගැනීමෙන්, ඊළඟ ශීර්ෂයේ ලිපිනය ගණනය කළ හැකිය. එබැවින් 0xff (නිදහස් ප්රදේශය) හෝ පිටුවේ අවසානය පිරී ඇති ප්රදේශයක් හමු වන තෙක් අපි ශීර්ෂයන් හරහා ගමන් කරමු.
විකල්ප 2:

විචල්ය වාර්තා දිග නිසා, අපට පිටුවකට කොපමණ වාර්තා (සහ ඒ නිසා ශීර්ෂයන්) අවශ්ය වේද යන්න කල්තියා පැවසිය නොහැක. ඔබට විවිධ පිටු හරහා ශීර්ෂයන් සහ දත්ත බෙදා හැරිය හැක, නමුත් මම වෙනස් ප්රවේශයකට කැමැත්තෙමි: අපි ශීර්ෂයන් සහ දත්ත දෙකම එක් පිටුවක තබමු, නමුත් ශීර්ෂයන් (ස්ථාවර ප්රමාණයෙන්) පැමිණෙන්නේ පිටුවේ ආරම්භයේ සිට, සහ දත්ත (විචල්ය දිග) පැමිණෙන්නේ අවසානයෙනි. ඔවුන් "හමු වූ" විගස (නව ප්රවේශයක් සඳහා ප්රමාණවත් නිදහස් ඉඩක් නොමැත), අපි මෙම පිටුව සම්පූර්ණ යැයි සලකමු.
විකල්ප 3:

ශීර්ෂයේ දත්ත පිහිටීම පිළිබඳ දිග හෝ වෙනත් තොරතුරු ගබඩා කිරීම අවශ්ය නොවේ; වාර්තා වල මායිම් දක්වන සලකුණු ප්රමාණවත් වේ. කෙසේ වෙතත්, ලිවීමේදී/කියවන විට දත්ත සැකසීමට සිදුවේ.
මම 0xff සලකුණක් ලෙස භාවිතා කරමි (එය මැකීමෙන් පසු පිටුව පුරවයි), එබැවින් නිදහස් ප්රදේශය නියත වශයෙන්ම දත්ත ලෙස නොසලකනු ඇත.
සංසන්දනාත්මක වගුව:
විකල්ප 1
විකල්ප 2
විකල්ප 3
දෝෂ ඉවසීම
-
+
+
සංයුක්ත බව
+
-
+
ක්රියාත්මක කිරීමේ සංකීර්ණත්වය
*
**
**
විකල්ප 1 හි මාරාන්තික දෝෂයක් ඇත: කිසියම් ශීර්ෂයකට හානි සිදුවුවහොත්, සම්පූර්ණ පසු දාමය විනාශ වේ. ඉතිරි විකල්ප ඔබට විශාල හානියක් සිදු වූ විට පවා සමහර දත්ත නැවත ලබා ගැනීමට ඉඩ සලසයි.
නමුත් මෙහිදී අපි දත්ත සම්පීඩිත ස්වරූපයෙන් ගබඩා කිරීමට තීරණය කළ බව මතක තබා ගැනීම සුදුසුය, එබැවින් “කැඩුණු” වාර්තාවකින් පසු පිටුවේ ඇති සියලුම දත්ත අපට අහිමි වේ, එබැවින් වගුවේ අඩුපාඩුවක් තිබුණද, අපි එසේ නොකරමු. එය සැලකිල්ලට ගන්න.
සංයුක්ත බව:
- පළමු විකල්පයේදී, අපි ශීර්ෂයේ දිග පමණක් ගබඩා කළ යුතුය; අපි විචල්ය-දිග පූර්ණ සංඛ්යා භාවිතා කරන්නේ නම්, බොහෝ අවස්ථාවලදී අපට එක් බයිටයකින් ලබා ගත හැකිය;
- දෙවන විකල්පය තුළ අපි ආරම්භක ලිපිනය සහ දිග ගබඩා කළ යුතුය; වාර්තාව නියත ප්රමාණය විය යුතුය, මම වාර්තාවකට බයිට් 4ක් ඇස්තමේන්තු කරමි (ඕෆ්සෙට් සඳහා බයිට් දෙකක් සහ දිග සඳහා බයිට් දෙකක්);
- තෙවන විකල්පයට පටිගත කිරීමේ ආරම්භය දැක්වීමට අවශ්ය වන්නේ එක් අක්ෂරයක් පමණක් වන අතර, පලිහක් හේතුවෙන් පටිගත කිරීම 1-2% කින් වැඩි වේ. සාමාන්යයෙන්, පළමු විකල්පය සමඟ ආසන්න වශයෙන් සමානාත්මතාවය.
මුලදී, මම දෙවන විකල්පය ප්රධාන එකක් ලෙස සැලකුවා (සහ ක්රියාත්මක කිරීම පවා ලිවීය). මම එය අත්හැරියේ අවසානයේ සම්පීඩනය භාවිතා කිරීමට තීරණය කළ විට පමණි.
සමහර විට කවදා හෝ මම තවමත් සමාන විකල්පයක් භාවිතා කරමි. නිදසුනක් වශයෙන්, පෘථිවිය සහ අඟහරු අතර ගමන් කරන නෞකාවක් සඳහා දත්ත ගබඩා කිරීම සමඟ කටයුතු කිරීමට මට සිදු වුවහොත්, විශ්වසනීයත්වය, කොස්මික් විකිරණ, ...
තෙවන විකල්පය සම්බන්ධයෙන් ගත් කල: ක්රියාත්මක කිරීමේ දුෂ්කරතාවය සඳහා මම එයට තරු දෙකක් ලබා දුන්නේ පලිහක් සමඟ පටලවා ගැනීමට, ක්රියාවලියේ දිග වෙනස් කිරීමට මා කැමති නැති බැවිනි. ඔව්, සමහර විට මම පක්ෂග්රාහීයි, නමුත් මට කේතය ලිවීමට සිදුවේ - ඔබ අකමැති දෙයක් කිරීමට ඔබට බල කරන්නේ ඇයි?
සාරාංශය: කාර්යක්ෂමතාව සහ ක්රියාත්මක කිරීමේ පහසුව හේතුවෙන් අපි “දිග සහිත ශීර්ෂකය - විචල්ය දිග දත්ත” දාම ආකාරයෙන් ගබඩා විකල්පය තෝරා ගනිමු.
ලිවීමේ මෙහෙයුම් වල සාර්ථකත්වය නිරීක්ෂණය කිරීමට Bit Fields භාවිතා කිරීම
මට අදහස ලැබුනේ කොහෙන්දැයි මට දැන් මතක නැත, නමුත් එය මේ වගේ දෙයක් පෙනේ:
සෑම ප්රවේශයක් සඳහාම, අපි කොඩි ගබඩා කිරීමට බිටු කිහිපයක් වෙන් කරමු.
අප කලින් කී පරිදි, මකා දැමීමෙන් පසු සියලුම බිටු 1s වලින් පුරවා ඇති අතර, අපට 1 සිට 0 දක්වා වෙනස් කළ හැකිය, නමුත් අනෙක් අතට නොවේ. එබැවින් "ධජය සකසා නැත" සඳහා අපි 1 භාවිතා කරමු, "කොඩිය සකසා ඇත" සඳහා අපි 0 භාවිතා කරමු.
විචල්ය-දිග වාර්තාවක් ෆ්ලෑෂ් වෙත තැබීම කෙබඳු විය හැකිද යන්න මෙන්න:
- "දිග පටිගත කිරීම ආරම්භ කර ඇත" ධජය සකසන්න;
- දිග සටහන් කරන්න;
- "දත්ත පටිගත කිරීම ආරම්භ කර ඇත" ධජය සකසන්න;
- අපි දත්ත සටහන් කරමු;
- "පටිගත කිරීම අවසන්" ධජය සකසන්න.
ඊට අමතරව, අපට "දෝෂයක් සිදු වූ" ධජයක් ඇත, මුළු 4 බිටු කොඩි සඳහා.
මෙම අවස්ථාවෙහිදී, අපට "1111" ස්ථාවර අවස්ථා දෙකක් ඇත - පටිගත කිරීම ආරම්භ කර නොමැති අතර "1000" - පටිගත කිරීම සාර්ථක විය; පටිගත කිරීමේ ක්රියාවලියේ අනපේක්ෂිත බාධාවකදී, අපට අතරමැදි තත්වයන් ලැබෙනු ඇත, එය අපට හඳුනාගෙන සැකසීමට හැකිය.
ප්රවේශය සිත්ගන්නා සුළුය, නමුත් එය හදිසි විදුලිය ඇනහිටීම් සහ ඒ හා සමාන අසමත්වීම් වලින් පමණක් ආරක්ෂා කරයි, එය ඇත්ත වශයෙන්ම වැදගත් වේ, නමුත් මෙය සිදුවිය හැකි අසාර්ථකත්වයන් සඳහා ඇති එකම (හෝ ප්රධාන) හේතුවට වඩා බොහෝ සෙයින් වෙනස් ය.
සාරාංශය: හොඳ විසඳුමක් සොයා අපි ඉදිරියට යමු.
චෙක්සම්
චෙක්සම් මඟින් අපි ලිවිය යුතු දේ හරියටම කියවන බව (සාධාරණ සම්භාවිතාවක් සහිතව) සහතික කර ගැනීමට හැකි වේ. තවද, ඉහත සාකච්ඡා කර ඇති බිට් ක්ෂේත්ර මෙන් නොව, ඒවා සැමවිටම ක්රියා කරයි.
අප ඉහත සාකච්ඡා කළ ගැටලු ඇති විය හැකි මූලාශ්ර ලැයිස්තුව සලකා බැලුවහොත්, එහි මූලාරම්භය නොසලකා දෝෂයක් හඳුනා ගැනීමට චෙක්සම්ට හැකි වේ. (සමහර විට, අනිෂ්ට පිටසක්වල ජීවීන් සඳහා හැර - ඔවුන්ට චෙක්සම් ව්යාජ ලෙස සකස් කළ හැකිය).
එබැවින් අපගේ ඉලක්කය දත්ත නොවෙනස්ව පවතින බව තහවුරු කිරීම නම්, චෙක්සම් ඉතා හොඳ අදහසකි.
චෙක්සම් ගණනය කිරීම සඳහා ඇල්ගොරිතම තේරීම කිසිදු ප්රශ්නයක් මතු නොකළේය - CRC. එක් අතකින්, ගණිතමය ගුණාංග මඟින් යම් යම් දෝෂ 100% ක් අල්ලා ගැනීමට හැකි වේ; අනෙක් අතට, අහඹු දත්ත මත, මෙම ඇල්ගොරිතම සාමාන්යයෙන් න්යායාත්මක සීමාවට වඩා වැඩි නොවන ගැටුම්වල සම්භාවිතාව පෙන්වයි.  . එය වේගවත්ම ඇල්ගොරිතම නොවිය හැකිය, ගැටුම් ගණන අනුව එය සැමවිටම අවම නොවේ, නමුත් එය ඉතා වැදගත් ගුණාංගයක් ඇත: මා මුහුණ දුන් පරීක්ෂණ වලදී, එය පැහැදිලිවම අසාර්ථක වූ රටා නොමැත. මෙම නඩුවේ ප්රධාන ගුණාංගය වන්නේ ස්ථාවරත්වයයි.
. එය වේගවත්ම ඇල්ගොරිතම නොවිය හැකිය, ගැටුම් ගණන අනුව එය සැමවිටම අවම නොවේ, නමුත් එය ඉතා වැදගත් ගුණාංගයක් ඇත: මා මුහුණ දුන් පරීක්ෂණ වලදී, එය පැහැදිලිවම අසාර්ථක වූ රටා නොමැත. මෙම නඩුවේ ප්රධාන ගුණාංගය වන්නේ ස්ථාවරත්වයයි.
පරිමාමිතික අධ්යයනයක උදාහරණය: , (narod.ru වෙත සබැඳි, සමාවන්න).
කෙසේ වෙතත්, චෙක්සම් තෝරාගැනීමේ කාර්යය සම්පූර්ණ නැත; CRC යනු චෙක්සම් මුළු පවුලකි. ඔබ දිග තීරණය කළ යුතු අතර, පසුව බහුපදයක් තෝරන්න.
චෙක්සම් දිග තෝරාගැනීම මුලින්ම බැලූ බැල්මට පෙනෙන තරම් සරල ප්රශ්නයක් නොවේ.
මම නිදර්ශනය කරන්නම්:
එක් එක් බයිටය තුළ දෝෂයක් ඇතිවීමේ සම්භාවිතාව අපට ලබා දෙන්න  සහ පරමාදර්ශී චෙක්සම් එකක්, වාර්තා මිලියනයකට සාමාන්ය දෝෂ සංඛ්යාව ගණනය කරමු:
සහ පරමාදර්ශී චෙක්සම් එකක්, වාර්තා මිලියනයකට සාමාන්ය දෝෂ සංඛ්යාව ගණනය කරමු:
දත්ත, බයිට්
චෙක්සම්, බයිට්
හඳුනා නොගත් දෝෂ
වැරදි දෝෂ හඳුනාගැනීම්
සම්පූර්ණ බොරු ධනාත්මක
1
0
1000
0
1000
1
1
4
999
1003
1
2
≈0
1997
1997
1
4
≈0
3990
3990
10
0
9955
0
9955
10
1
39
990
1029
10
2
≈0
1979
1979
10
4
≈0
3954
3954
1000
0
632305
0
632305
1000
1
2470
368
2838
1000
2
10
735
745
1000
4
≈0
1469
1469
සෑම දෙයක්ම සරල බව පෙනේ - ආරක්ෂා කර ඇති දත්තවල දිග අනුව, අවම වැරදි ධනාත්මක අගයන් සහිත චෙක්සම් දිග තෝරන්න - සහ උපක්රමය මල්ලේ ඇත.
කෙසේ වෙතත්, කෙටි පිරික්සුම් සමඟ ගැටළුවක් පැන නගී: ඒවා තනි බිටු දෝෂ හඳුනා ගැනීමට දක්ෂ වුවද, තරමක් ඉහළ සම්භාවිතාවක් සහිතව සම්පූර්ණ අහඹු දත්ත නිවැරදි ලෙස පිළිගත හැකිය. Habré ගැන විස්තර කරන ලිපියක් දැනටමත් තිබුනා .
එබැවින්, අහඹු චෙක්සම් ගැලපීම පාහේ කළ නොහැකි දෙයක් බවට පත් කිරීම සඳහා, ඔබ බිටු 32 ක් හෝ ඊට වැඩි දිග චෙක්සම් භාවිතා කළ යුතුය. (බිට් 64 ට වැඩි දිග සඳහා, ගුප්ත ලේඛන හැෂ් ශ්රිත සාමාන්යයෙන් භාවිතා වේ).
සෑම ආකාරයකින්ම ඉඩ ඉතිරි කර ගත යුතු බව මා කලින් ලියා ඇතත්, අපි තවමත් 32-bit චෙක්සම් එකක් භාවිතා කරන්නෙමු (බිට් 16 ප්රමාණවත් නොවේ, ගැටීමේ සම්භාවිතාව 0.01% ට වඩා වැඩි ය; සහ බිට් 24, ඒවා ලෙස. කියන්න, මෙහි හෝ එහි නැත) .
මෙහිදී විරෝධයක් මතු විය හැක: දැන් අපි එකවර බයිට් 4ක් ලබා දීම සඳහා සම්පීඩනය තෝරාගැනීමේදී සෑම බයිටයක්ම සුරැකුවද? චෙක්සම් සම්පීඩනය හෝ එකතු නොකිරීමට වඩා හොඳ නොවේද? ඇත්ත වශයෙන්ම නැත, සම්පීඩනය නැත යන්නෙන් අදහස් නොවේ, අපට අඛණ්ඩතාව පරීක්ෂා කිරීම අවශ්ය නොවන බව.
බහුපදයක් තෝරාගැනීමේදී, අපි රෝදය නැවත සොයා නොගන්නෙමු, නමුත් දැන් ජනප්රිය CRC-32C ගන්නෙමු.
මෙම කේතය බයිට් 6 දක්වා පැකට් වල බිට් 22 දෝෂ (සමහර විට අපට වඩාත් පොදු අවස්ථාව), බයිට් 4 දක්වා පැකට් වල බිට් 655 දෝෂ (අපට ද පොදු අවස්ථාවකි), 2 හෝ පැකට් වල ඔත්තේ සංඛ්යා බිට් දෝෂ හඳුනා ගනී. ඕනෑම සාධාරණ දිගකින්.
කවුරුහරි කැමති නම් විස්තර
CRC ගැන.
මත - සමහරවිට ග්රහලෝකයේ ප්රමුඛතම CRC විශේෂඥයා.
В ය , එය අපට අදාළ පැකට් දිග සඳහා තරමක් හොඳ පරාමිතීන් සපයයි, නමුත් මම වෙනස සැලකිය යුතු ලෙස නොසලකන අතර සම්මත සහ හොඳින් පර්යේෂණ කළ එක වෙනුවට අභිරුචි කේතය තෝරා ගැනීමට තරම් මම දක්ෂ විය.
එසේම, අපගේ දත්ත සම්පීඩනය කර ඇති බැවින්, ප්රශ්නය පැනනගින්නේ: අපි සම්පීඩිත හෝ සම්පීඩිත දත්තවල චෙක්සම් ගණනය කළ යුතුද?
සම්පීඩිත නොකළ දත්තවල චෙක්සම් ගණනය කිරීමට පක්ෂව තර්ක:
- අපට අවසානයේ දත්ත ගබඩා කිරීමේ ආරක්ෂාව පරීක්ෂා කිරීමට අවශ්ය වේ - එබැවින් අපි එය කෙලින්ම පරීක්ෂා කරමු (ඒ සමඟම, සම්පීඩනය / විසංයෝජනය ක්රියාත්මක කිරීමේදී සිදුවිය හැකි දෝෂ, බිඳුණු මතකය නිසා ඇති වන හානිය ආදිය පරීක්ෂා කරනු ලැබේ);
- zlib හි deflate ඇල්ගොරිතමයට තරමක් පරිණත ක්රියාත්මක කිරීමක් ඇත නොකළ යුතුය “වංක” ආදාන දත්ත සමඟ වැටීම; එපමනක් නොව, එය බොහෝ විට ආදාන ප්රවාහයේ දෝෂ ස්වාධීනව හඳුනා ගැනීමට සමත් වන අතර, දෝෂයක් හඳුනා ගැනීමේ සමස්ත සම්භාවිතාව අඩු කරයි (කෙටි වාර්තාවක් තුළ තනි බිට් එකක් ප්රතිලෝම කිරීම සමඟ පරීක්ෂණයක් සිදු කරන ලදී, zlib දෝෂයක් අනාවරණය කළේය. නඩු වලින් තුනෙන් එකක් පමණ).
සම්පීඩිත නොකළ දත්තවල චෙක්සම් ගණනය කිරීමට එරෙහි තර්ක:
- CRC විශේෂයෙන් ෆ්ලෑෂ් මතකයේ ලක්ෂණ වන බිටු දෝෂ කිහිපයක් සඳහා "අනුගත" කර ඇත (සම්පීඩිත ප්රවාහයක බිට් දෝෂයක් ප්රතිදාන ප්රවාහයේ දැවැන්ත වෙනසක් ඇති කළ හැකිය, එය මත, සම්පූර්ණයෙන්ම න්යායාත්මකව, අපට ගැටුමක් "අල්ලා" ගත හැකිය);
- බිඳී යා හැකි දත්ත විසංයෝජනයට යැවීමේ අදහසට මම ඇත්තටම කැමති නැත, ඔහු ප්රතිචාර දක්වන ආකාරය.
මෙම ව්යාපෘතියේදී, සම්පීඩිත නොකළ දත්තවල චෙක්සම් ගබඩා කිරීමේ සාමාන්යයෙන් පිළිගත් පරිචයෙන් බැහැර වීමට මම තීරණය කළෙමි.
සාරාංශය: අපි CRC-32C භාවිතා කරමු, අපි ඒවා ෆ්ලෑෂ් කිරීමට ලියා ඇති පෝරමයේ දත්ත වලින් චෙක්සම් ගණනය කරමු (සම්පීඩනයෙන් පසු).
අතිරික්තය
අතිරික්ත කේතීකරණය භාවිතා කිරීම, ඇත්ත වශයෙන්ම, දත්ත නැතිවීම ඉවත් නොකරයි, කෙසේ වෙතත්, එය සැලකිය යුතු ලෙස (බොහෝ විට විශාලත්වයේ බොහෝ ඇණවුම් මගින්) ආපසු හැරවිය නොහැකි දත්ත අහිමි වීමේ සම්භාවිතාව අඩු කළ හැකිය.
දෝෂ නිවැරදි කිරීම සඳහා අපට විවිධ ආකාරයේ අතිරික්තයන් භාවිතා කළ හැකිය.
Hamming කේත මගින් තනි බිටු දෝෂ නිවැරදි කළ හැක, Reed-Solomon අක්ෂර කේත, චෙක්සම් සමඟ ඒකාබද්ධ වූ බහුවිධ දත්ත පිටපත්, හෝ RAID-6 වැනි කේතීකරණ දැවැන්ත දූෂණයකදී පවා දත්ත නැවත ලබා ගැනීමට උපකාරී වේ.
මුලදී, මම දෝෂ-ප්රතිරෝධී කේතීකරණය පුළුල් ලෙස භාවිතා කිරීමට කැපවී සිටියෙමි, නමුත් පසුව මට වැටහුණේ අපට අපව ආරක්ෂා කර ගැනීමට අවශ්ය දෝෂ මොනවාද යන්න පිළිබඳ අදහසක් පළමුව අපට තිබිය යුතු බවත් පසුව කේතීකරණය තෝරා ගත යුතු බවත්ය.
අපි කලිනුත් කිව්වා පුළුවන් තරම් ඉක්මනට වැරදි අල්ලන්න ඕන කියලා. අපට දෝෂ ඇතිවිය හැක්කේ කුමන අවස්ථා වලදීද?
- නිම නොකළ පටිගත කිරීම (යම් හේතුවක් නිසා පටිගත කරන අවස්ථාවේ විදුලිය විසන්ධි විය, රාස්ප්බෙරි කැටි විය, ...)
අහෝ, එවැනි දෝෂයක් ඇති වූ විට, ඉතිරිව ඇත්තේ වලංගු නොවන වාර්තා නොසලකා හැරීම සහ නැතිවූ දත්ත සලකා බැලීම පමණි; - ලිවීමේ දෝෂ (යම් හේතුවක් නිසා, ෆ්ලෑෂ් මතකයට ලියා ඇත්තේ ලියා ඇති දේ නොවේ)
පටිගත කළ වහාම පරීක්ෂණ කියවීමක් කළහොත් අපට එවැනි දෝෂ ක්ෂණිකව හඳුනාගත හැකිය; - ගබඩා කිරීමේදී මතකයේ දත්ත විකෘති කිරීම;
- කියවීමේ දෝෂ
එය නිවැරදි කිරීම සඳහා, චෙක්සම් නොගැලපේ නම්, කියවීම කිහිප වතාවක් නැවත නැවත කිරීමට ප්රමාණවත් වේ.
එනම්, තුන්වන වර්ගයේ දෝෂ පමණක් (ගබඩා කිරීමේදී දත්ත ස්වයංසිද්ධව දූෂණය වීම) දෝෂ-ප්රතිරෝධී කේතීකරණයකින් තොරව නිවැරදි කළ නොහැක. එවැනි දෝෂ තවමත් අතිශයින් අඩු බව පෙනේ.
සාරාංශය: අතිරික්ත කේතීකරණය අත්හැරීමට තීරණය කරන ලදී, නමුත් මෙහෙයුම මෙම තීරණයේ දෝෂය පෙන්නුම් කරන්නේ නම්, ගැටළුව සලකා බැලීමට ආපසු යන්න (අසාර්ථකවීම් පිළිබඳ දැනටමත් සමුච්චිත සංඛ්යාලේඛන සමඟ, එමඟින් ප්රශස්ත කේතීකරණ වර්ගය තෝරා ගැනීමට ඉඩ සලසයි).
Прочее
ඇත්ත වශයෙන්ම, ලිපියේ ආකෘතිය අපට ආකෘතියේ සෑම බිට් එකක්ම සාධාරණීකරණය කිරීමට ඉඩ නොදේ (සහ මගේ ශක්තිය දැනටමත් අවසන් වී ඇත), ඒ නිසා මම කලින් ස්පර්ශ නොකළ කරුණු කිහිපයක් කෙටියෙන් කියන්නම්.
- සියලුම පිටු "සමාන" කිරීමට තීරණය විය
එනම්, පාර-දත්ත, වෙනම නූල් යනාදිය සහිත විශේෂ පිටු නොතිබෙනු ඇත, නමුත් ඒ වෙනුවට සියලුම පිටු නැවත ලියන තනි නූල් එකක්.
මෙය පිටු මත පවා ඇඳීම සහතික කරයි, අසාර්ථකත්වයේ එක් කරුණක් නැත, මම එයට කැමතියි; - ආකෘතියේ අනුවාදය සැපයීම අනිවාර්ය වේ.
ශීර්ෂයේ අනුවාද අංකයක් නොමැති ආකෘතියක් නරකයි!
පිටු ශීර්ෂයට නිශ්චිත මැජික් අංකයක් (අත්සන) සහිත ක්ෂේත්රයක් එක් කිරීමට ප්රමාණවත් වේ, එය භාවිතා කළ ආකෘතියේ අනුවාදය දක්වයි (ප්රායෝගිකව ඔවුන්ගෙන් දුසිමක්වත් සිටිනු ඇතැයි මම නොසිතමි); - වාර්තා සඳහා විචල්ය-දිග ශීර්ෂයක් භාවිතා කරන්න (ඒවායින් බොහොමයක් තිබේ), බොහෝ අවස්ථාවලදී එය බයිට 1ක් දිගු කිරීමට උත්සාහ කරන්න;
- ශීර්ෂයේ දිග සහ සම්පීඩිත වාර්තාවේ කැපූ කොටසේ දිග කේතනය කිරීමට, විචල්ය-දිග ද්විමය කේත භාවිතා කරන්න.
ගොඩක් උදව් කළා හෆ්මන් කේත. මිනිත්තු කිහිපයකින් අපට අවශ්ය විචල්ය දිග කේත තෝරා ගැනීමට හැකි විය.
දත්ත ගබඩා ආකෘතියේ විස්තරය
බයිට් ඇණවුම
එක් බයිටයකට වඩා විශාල ක්ෂේත්ර විශාල-එන්ඩියන් ආකෘතියෙන් (ජාල බයිට් අනුපිළිවෙල) ගබඩා කර ඇත, එනම් 0x1234 0x12, 0x34 ලෙස ලියා ඇත.
පේජිනේෂන්
සියලුම ෆ්ලෑෂ් මතකය සමාන ප්රමාණයේ පිටු වලට බෙදා ඇත.
පෙරනිමි පිටු ප්රමාණය 32Kb වේ, නමුත් මතක චිපයේ මුළු ප්රමාණයෙන් 1/4 කට වඩා වැඩි නොවේ (4MB චිපයක් සඳහා පිටු 128 ක් ලබා ගනී).
සෑම පිටුවක්ම අනෙක් ඒවායින් ස්වාධීනව දත්ත ගබඩා කරයි (එනම්, එක් පිටුවක දත්ත වෙනත් පිටුවක දත්ත යොමු නොකරයි).
සියලුම පිටු ස්වභාවික අනුපිළිවෙලින් අංකනය කර ඇත (ලිපිනවල ආරෝහණ අනුපිළිවෙලින්), අංක 0 න් ආරම්භ වේ (පිටුව බිංදුව 0 ලිපිනයෙන් ආරම්භ වේ, පළමු පිටුව 32Kb වලින් ආරම්භ වේ, දෙවන පිටුව 64Kb වලින් ආරම්භ වේ, ආදිය)
මතක චිපය චක්රීය බෆරයක් (ring buffer) ලෙස භාවිතා කරයි, එනම්, පළමුව ලිවීම පිටු අංක 0 ට, පසුව අංක 1, ..., අපි අවසාන පිටුව පුරවන විට, නව චක්රයක් ආරම්භ වන අතර පිටුව බිංදුවෙන් පටිගත කිරීම දිගටම සිදු වේ. .
පිටුව ඇතුළත

පිටුවේ ආරම්භයේ දී, 4-byte පිටු ශීර්ෂයක් ගබඩා කර ඇත, පසුව ශීර්ෂ චෙක්සම් (CRC-32C), පසුව වාර්තා "ශීර්ෂකය, දත්ත, චෙක්සම්" ආකෘතියෙන් ගබඩා කර ඇත.
පිටු මාතෘකාව (රූප සටහනේ අපිරිසිදු කොළ) සමන්විත වන්නේ:
- ද්වි-බයිට් මැජික් අංක ක්ෂේත්රය (ආකෘති අනුවාදයේ ලකුණක් ද)
ආකෘතියේ වත්මන් අනුවාදය සඳහා එය ගණනය කරනු ලැබේ0xed00 ⊕ номер страницы; - ද්වි-බයිට් කවුන්ටරය "පිටු අනුවාදය" (මතකය නැවත ලිවීමේ චක්ර අංකය).
පිටුවේ ඇතුළත් කිරීම් සම්පීඩිත ආකාරයෙන් ගබඩා කර ඇත (deflate ඇල්ගොරිතම භාවිතා වේ). එක් පිටුවක ඇති සියලුම වාර්තා එක් නූල් එකකින් සම්පීඩිත වේ (පොදු ශබ්දකෝෂයක් භාවිතා වේ), සහ සෑම නව පිටුවකම සම්පීඩනය අලුතින් ආරම්භ වේ. එනම්, ඕනෑම වාර්තාවක් විසංයෝජනය කිරීමට, මෙම පිටුවෙන් පෙර සියලුම වාර්තා (සහ මෙය පමණක්) අවශ්ය වේ.
සෑම වාර්තාවක්ම Z_SYNC_FLUSH ධජය සමඟ සම්පීඩිත වන අතර, සම්පීඩිත ප්රවාහය අවසානයේ බයිට් 4ක් 0x00, 0x00, 0xff, 0xff ඇත, සමහර විට තවත් ශුන්ය බයිට් එකක් හෝ දෙකකින් පෙර විය හැක.
ෆ්ලෑෂ් මතකයට ලියන විට අපි මෙම අනුපිළිවෙල (4, 5 හෝ 6 බයිට් දිග) ඉවතලන්නෙමු.
වාර්තා ශීර්ෂය බයිට් 1, 2 හෝ 3 ගබඩා කරයි:
- එක් බිට් (T) වාර්තා වර්ගය පෙන්නුම් කරයි: 0 - සන්දර්භය, 1 - ලොග්;
- විචල්ය දිග ක්ෂේත්රයක් (S) බිටු 1 සිට 7 දක්වා, විසංයෝජනය සඳහා වාර්තාවට එකතු කළ යුතු ශීර්ෂයේ දිග සහ "වලිගය" නිර්වචනය කිරීම;
- වාර්තාගත දිග (L).
S අගය වගුව:
S
ශීර්ෂයේ දිග, බයිට්
ලිවීම, බයිට් මත ඉවත දමන ලදී
0
1
5 (00 00 00 ff ff)
10
1
6 (00 00 00 00 ff ff)
110
2
4 (00 00 ff ff)
1110
2
5 (00 00 00 ff ff)
11110
2
6 (00 00 00 00 ff ff)
1111100
3
4 (00 00 ff ff)
1111101
3
5 (00 00 00 ff ff)
1111110
3
6 (00 00 00 00 ff ff)
මම නිදර්ශනය කිරීමට උත්සාහ කළෙමි, එය කෙතරම් පැහැදිලිව සිදුවී ඇත්දැයි මම නොදනිමි:
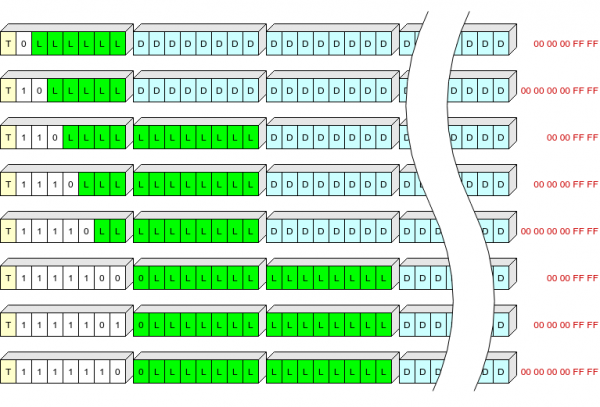
මෙහි කහ පැහැයෙන් දැක්වෙන්නේ T ක්ෂේත්රය, සුදු S ක්ෂේත්රය, කොළ L (සම්පීඩිත දත්තවල දිග බයිට් වලින්), නිල් පැහැයෙන් සම්පීඩිත දත්ත, ෆ්ලෑෂ් මතකයට ලියා නැති සම්පීඩිත දත්තවල අවසාන බයිට් රතු ය.
මේ අනුව, අපට වඩාත් පොදු දිග (සම්පීඩිත ආකාරයෙන් බයිට් 63+5 දක්වා) වාර්තාගත ශීර්ෂයන් එක් බයිටයකින් ලිවිය හැකිය.
එක් එක් වාර්තාවෙන් පසුව, CRC-32C චෙක්සම් එකක් ගබඩා කර ඇති අතර, එහි පෙර චෙක්සම් හි ප්රතිලෝම අගය ආරම්භක අගය (init) ලෙස භාවිතා කරයි.
CRC සතුව “කාලසීමාව” යන ගුණාංගය ඇත, පහත සූත්රය ක්රියා කරයි (ක්රියාවලියේදී ප්ලස් හෝ අඩු බිටු ප්රතිලෝම):  .
.
එනම්, ඇත්ත වශයෙන්ම, අපි මෙම පිටුවේ ශීර්ෂක සහ දත්තවල පෙර සියලුම බයිට් වල CRC ගණනය කරමු.
චෙක්සම් එක කෙලින්ම අනුගමනය කිරීම ඊළඟ වාර්තාවේ ශීර්ෂයයි.
ශීර්ෂකය නිර්මාණය කර ඇත්තේ එහි පළමු බයිටය සෑම විටම 0x00 සහ 0xff ට වඩා වෙනස් වන ආකාරයටය (ශීර්ෂකයේ පළමු බයිටය වෙනුවට 0xff අපට හමු වුවහොත්, මෙයින් අදහස් කරන්නේ මෙය භාවිතයට නොගත් ප්රදේශයක් බවයි; 0x00 දෝෂයක් සංඥා කරයි).
උදාහරණ ඇල්ගොරිතම
ෆ්ලෑෂ් මතකයෙන් කියවීම
ඕනෑම කියවීමක් චෙක්සම් චෙක්පතක් සමඟ පැමිණේ.
චෙක්සම් නොගැලපේ නම්, නිවැරදි දත්ත කියවීමේ බලාපොරොත්තුවෙන් කියවීම කිහිප වතාවක් පුනරාවර්තනය වේ.
(ඒක තේරුමක් තියෙනවා, Linux NOR Flash වෙතින් කියවීම් හැඹිලිගත නොකරයි, සත්යාපනය කර ඇත)
ෆ්ලෑෂ් මතකයට ලියන්න
අපි දත්ත සටහන් කරමු.
අපි ඒවා කියවමු.
කියවීමේ දත්ත ලිඛිත දත්ත සමඟ නොගැලපේ නම්, අපි ප්රදේශය ශුන්ය වලින් පුරවා දෝෂයක් සංඥා කරමු.
ක්රියාත්මක කිරීම සඳහා නව ක්ෂුද්ර පරිපථයක් සකස් කිරීම
ආරම්භ කිරීම සඳහා, 1 අනුවාදය සහිත ශීර්ෂයක් පළමු (හෝ ඒ වෙනුවට ශුන්ය) පිටුවට ලියා ඇත.
ඊට පසු, ආරම්භක සන්දර්භය මෙම පිටුවට ලියා ඇත (යන්ත්රයේ UUID සහ පෙරනිමි සැකසුම් අඩංගු වේ).
එච්චරයි, ෆ්ලෑෂ් මතකය භාවිතයට සූදානම්.
යන්ත්රය පැටවීම
පූරණය වන විට, සෑම පිටුවකම පළමු බයිට් 8 (ශීර්ෂකය + CRC) කියවනු ලැබේ, නොදන්නා මැජික් අංකයක් හෝ වැරදි CRC සහිත පිටු නොසලකා හරිනු ලැබේ.
"නිවැරදි" පිටු වලින්, උපරිම අනුවාදය සහිත පිටු තෝරාගෙන ඇති අතර, වැඩිම සංඛ්යාවක් සහිත පිටුව ඔවුන්ගෙන් ගනු ලැබේ.
පළමු වාර්තාව කියවනු ලැබේ, CRC හි නිවැරදිභාවය සහ "සන්දර්භය" ධජය තිබීම පරීක්ෂා කරනු ලැබේ. සෑම දෙයක්ම හොඳයි නම්, මෙම පිටුව වත්මන් ලෙස සැලකේ. එසේ නොවේ නම්, අපි "සජීවී" පිටුවක් සොයා ගන්නා තෙක් අපි පෙර එකට පෙරළන්නෙමු.
සහ සොයාගත් පිටුවේ අපි "සන්දර්භය" ධජය සමඟ භාවිතා කරන සියලුම වාර්තා කියවමු.
zlib ශබ්ද කෝෂය සුරකින්න (මෙම පිටුවට එක් කිරීමට එය අවශ්ය වනු ඇත).
එපමණයි, බාගත කිරීම සම්පූර්ණයි, සන්දර්භය ප්රතිෂ්ඨාපනය කර ඇත, ඔබට වැඩ කළ හැකිය.
ජර්නල සටහනක් එකතු කිරීම
අපි Z_SYNC_FLUSH සඳහන් කරමින් නිවැරදි ශබ්දකෝෂය සමඟ වාර්තාව සම්පීඩනය කරමු. සම්පීඩිත වාර්තාව වත්මන් පිටුවට ගැලපේදැයි අපි දකිමු.
එය නොගැලපේ නම් (හෝ පිටුවේ CRC දෝෂ තිබේ නම්), නව පිටුවක් ආරම්භ කරන්න (පහත බලන්න).
අපි වාර්තාව සහ CRC ලියන්නෙමු. දෝෂයක් සිදුවුවහොත්, නව පිටුවක් ආරම්භ කරන්න.
නව පිටුව
අපි අවම අංකයක් සහිත නොමිලේ පිටුවක් තෝරා ගනිමු (නිදහස් පිටුවක් ශීර්ෂයේ වැරදි චෙක්සම් සහිත පිටුවක් ලෙස හෝ වත්මන් එකට වඩා අඩු අනුවාදයක් ලෙස අපි සලකමු). එවැනි පිටු නොමැති නම්, වත්මන් එකට සමාන අනුවාදයක් ඇති ඒවායින් අවම අංකය සහිත පිටුව තෝරන්න.
අපි තෝරාගත් පිටුව මකා දමමු. අපි 0xff සමඟ අන්තර්ගතය පරීක්ෂා කරන්නෙමු. යමක් වැරදී ඇත්නම්, ඊළඟ නිදහස් පිටුව ආදිය ගන්න.
අපි මකා දැමූ පිටුවේ ශීර්ෂයක් ලියන්නෙමු, පළමු ප්රවේශය සන්දර්භයේ වත්මන් තත්වයයි, ඊළඟට නොලියූ ලොග් ප්රවේශයයි (එකක් තිබේ නම්).
ආකෘති අදාළත්වය
මගේ මතය අනුව, එය NOR Flash හි වැඩි හෝ අඩු සම්පීඩිත තොරතුරු ප්රවාහයක් (සරල පෙළ, JSON, MessagePack, CBOR, සමහරවිට protobuf) ගබඩා කිරීම සඳහා හොඳ ආකෘතියක් බවට පත් විය.
ඇත්ත වශයෙන්ම, ආකෘතිය SLC NOR Flash සඳහා "ගැලපෙන" වේ.
එය NAND හෝ MLC NOR වැනි ඉහළ BER මාධ්ය සමඟ භාවිතා නොකළ යුතුය (එවැනි මතකය විකිණීමට තිබේද? එය නිවැරදි කිරීමේ කේතවල කෘතිවල පමණක් සඳහන් කර ඇති බව මම දුටුවෙමි).
තවද, එය තමන්ගේම FTL ඇති උපාංග සමඟ භාවිතා නොකළ යුතුය: USB ෆ්ලෑෂ්, SD, MicroSD, ආදිය. (එවැනි මතකය සඳහා මම බයිට් 512 ක පිටු ප්රමාණයකින් යුත් ආකෘතියක් සෑදුවෙමි, එක් එක් පිටුවේ ආරම්භයේ අත්සනක් සහ අද්විතීය වාර්තා අංක - සමහර විට සරල අනුක්රමික කියවීමකින් “ගැටුණු” ෆ්ලෑෂ් ධාවකයකින් සියලුම දත්ත නැවත ලබා ගැනීමට හැකි විය).
කාර්යයන් මත පදනම්ව, 128Kbit (16Kb) සිට 1Gbit (128MB) දක්වා ෆ්ලෑෂ් ඩ්රයිව් වල වෙනස්කම් නොමැතිව ආකෘතිය භාවිතා කළ හැක. අවශ්ය නම්, ඔබට එය විශාල චිප්ස් මත භාවිතා කළ හැකිය, නමුත් ඔබට පිටු ප්රමාණය සකස් කිරීමට අවශ්ය වේ (නමුත් මෙහි ආර්ථික ශක්යතාව පිළිබඳ ප්රශ්නය දැනටමත් පැන නගී; විශාල පරිමාණ NOR Flash සඳහා මිල දිරිගන්වන සුළු නොවේ).
යමෙකුට ආකෘතිය සිත්ගන්නාසුළු වන අතර එය විවෘත ව්යාපෘතියක භාවිතා කිරීමට අවශ්ය නම්, ලියන්න, මම කාලය සොයා ගැනීමට උත්සාහ කරමි, කේතය ඔප දමා එය github මත පළ කරන්න.
නිගමනය
ඔබට පෙනෙන පරිදි, අවසානයේ ආකෘතිය සරල විය සහ පවා කම්මැලි.
ලිපියකින් මගේ දෘෂ්ටිකෝණයේ පරිණාමය පිළිබිඹු කිරීම දුෂ්කර ය, නමුත් මාව විශ්වාස කරන්න: මුලදී මට අවශ්ය වූයේ න්යෂ්ටික පිපිරීමකින් පවා නොනැසී පැවතිය හැකි නවීන, විනාශ කළ නොහැකි දෙයක් නිර්මාණය කිරීමට ය. කෙසේ වෙතත්, හේතුව (මම බලාපොරොත්තු වෙමි) තවමත් ජයග්රහණය කළ අතර ක්රමයෙන් ප්රමුඛතාවයන් සරල බව සහ සංයුක්තත්වය වෙත මාරු විය.
මම වැරදියි කියලා වෙන්න පුළුවන්ද? ඔව්, සහතිකයි. නිදසුනක් වශයෙන්, අපි අඩු ගුණාත්මක ක්ෂුද්ර පරිපථ සමූහයක් මිලදී ගත් බව පෙනේ. නැතහොත් වෙනත් හේතුවක් නිසා උපකරණවල විශ්වසනීයත්වය අපේක්ෂා නොකෙරේ.
මට මේ සඳහා සැලැස්මක් තිබේද? ලිපිය කියවීමෙන් පසු සැලැස්මක් ඇති බවට ඔබට සැකයක් නැතැයි මම සිතමි. ඒ වගේම තනියම නෙවෙයි.
තරමක් බරපතල සටහනක් මත, ආකෘතිය වැඩ කරන විකල්පයක් ලෙස සහ "අත්හදා බැලීමේ බැලූනයක්" ලෙස සංවර්ධනය කරන ලදී.
මේ මොහොතේ මේසයේ ඇති සියල්ල හොඳින් ක්රියාත්මක වේ, වචනාර්ථයෙන් අනෙක් දවසේ විසඳුම යොදවනු ලැබේ (ආසන්න වශයෙන්) උපාංග සිය ගණනක, "සටන්" මෙහෙයුමේදී සිදුවන්නේ කුමක්දැයි බලමු (වාසනාවකට මෙන්, අසාර්ථකත්වය විශ්වාසදායක ලෙස හඳුනා ගැනීමට ආකෘතිය ඔබට ඉඩ සලසයි; එබැවින් ඔබට සම්පූර්ණ සංඛ්යා ලේඛන එකතු කළ හැකිය). මාස කිහිපයකින් නිගමනවලට එළඹීමට හැකි වනු ඇත (සහ ඔබ අවාසනාවන්ත නම්, ඊටත් පෙර).
භාවිතයේ ප්රති results ල මත පදනම්ව, බරපතල ගැටළු සොයාගෙන වැඩිදියුණු කිරීම් අවශ්ය නම්, මම අනිවාර්යයෙන්ම ඒ ගැන ලියන්නෙමි.
සාහිත්යය
භාවිතා කළ කෘතීන් දිගු වෙහෙසකර ලැයිස්තුවක් සෑදීමට මට අවශ්ය නොවීය; සියල්ලට පසු, සෑම කෙනෙකුටම ගූගල් තිබේ.
මෙහිදී මට විශේෂයෙන් සිත්ගන්නාසුලු යැයි පෙනෙන සොයාගැනීම් ලැයිස්තුවක් තැබීමට මම තීරණය කළෙමි, නමුත් ක්රමයෙන් ඒවා කෙලින්ම ලිපියේ පෙළට සංක්රමණය වූ අතර එක් අයිතමයක් ලැයිස්තුවේ පැවතුනි:
- උපයෝගීතාව zlib කතුවරයාගෙන්. deflate/zlib/gzip ලේඛනාගාරයේ අන්තර්ගතය පැහැදිලිව පෙන්විය හැක. ඔබට deflate (හෝ gzip) ආකෘතියේ අභ්යන්තර ව්යුහය සමඟ කටයුතු කිරීමට සිදු වුවහොත්, මම එය බෙහෙවින් නිර්දේශ කරමි.
මූලාශ්රය: www.habr.com
