

“පෙනෙන සරල” PostgreSQL විමසුම්වල කාර්ය සාධනය වැඩි දියුණු කිරීම සඳහා එතරම් නොදන්නා ක්රම අධ්යයනය කිරීමට කැප වූ ලිපි මාලාව අපි දිගටම කරගෙන යන්නෙමු:
මම එකතු වෙන්න එච්චර කැමති නෑ කියලා හිතන්න එපා... :)
නමුත් බොහෝ විට එය නොමැතිව, ඉල්ලීම එය සමඟ වඩා සැලකිය යුතු ලෙස වඩා ඵලදායී බවට හැරේ. ඉතින් අද අපි උත්සාහ කරමු සම්පත්-දැඩි JOIN වලින් මිදෙන්න - ශබ්දකෝෂයක් භාවිතා කිරීම.

PostgreSQL 12 සමඟින් පටන් ගෙන, පහත විස්තර කර ඇති සමහර තත්වයන් නිසා තරමක් වෙනස් ලෙස ප්රතිනිෂ්පාදනය විය හැක . යතුර සඳහන් කිරීමෙන් මෙම හැසිරීම ප්රතිවර්තනය කළ හැක
MATERIALIZED.
සීමිත වචන මාලාවක "කරුණු" ගොඩක්
අපි ඉතා සැබෑ යෙදුම් කාර්යයක් ගනිමු - අපට ලැයිස්තුවක් පෙන්විය යුතුය හෝ යවන්නන් සමඟ සක්රිය කාර්යයන්:
25.01 | Иванов И.И. | Подготовить описание нового алгоритма.
22.01 | Иванов И.И. | Написать статью на Хабр: жизнь без JOIN.
20.01 | Петров П.П. | Помочь оптимизировать запрос.
18.01 | Иванов И.И. | Написать статью на Хабр: JOIN с учетом распределения данных.
16.01 | Петров П.П. | Помочь оптимизировать запрос.
වියුක්ත ලෝකයේ, කාර්ය කතුවරුන් අපගේ සංවිධානයේ සියලුම සේවකයින් අතර ඒකාකාරව බෙදා හැරිය යුතුය, නමුත් යථාර්ථයේ දී කාර්යයන් පැමිණෙන්නේ, රීතියක් ලෙස, තරමක් සීමිත පුද්ගලයින්ගෙන් ය - "කළමනාකරණයෙන්" ධූරාවලිය දක්වා හෝ "උප කොන්ත්රාත්කරුවන්ගෙන්" අසල්වැසි දෙපාර්තමේන්තු (විශ්ලේෂකයින්, නිර්මාණකරුවන්, අලෙවිකරණය, ...).
පුද්ගලයන් 1000 කින් සමන්විත අපගේ සංවිධානයේ, එක් එක් නිශ්චිත කාර්ය සාධනය සඳහා කාර්යයන් සකසා ඇත්තේ කතුවරුන් 20 දෙනෙකු (සාමාන්යයෙන් ඊටත් වඩා අඩු) පමණක් බව පිළිගනිමු. "සාම්ප්රදායික" විමසුම වේගවත් කිරීමට.
ස්ක්රිප්ට් උත්පාදක යන්ත්රය
-- сотрудники
CREATE TABLE person AS
SELECT
id
, repeat(chr(ascii('a') + (id % 26)), (id % 32) + 1) "name"
, '2000-01-01'::date - (random() * 1e4)::integer birth_date
FROM
generate_series(1, 1000) id;
ALTER TABLE person ADD PRIMARY KEY(id);
-- задачи с указанным распределением
CREATE TABLE task AS
WITH aid AS (
SELECT
id
, array_agg((random() * 999)::integer + 1) aids
FROM
generate_series(1, 1000) id
, generate_series(1, 20)
GROUP BY
1
)
SELECT
*
FROM
(
SELECT
id
, '2020-01-01'::date - (random() * 1e3)::integer task_date
, (random() * 999)::integer + 1 owner_id
FROM
generate_series(1, 100000) id
) T
, LATERAL(
SELECT
aids[(random() * (array_length(aids, 1) - 1))::integer + 1] author_id
FROM
aid
WHERE
id = T.owner_id
LIMIT 1
) a;
ALTER TABLE task ADD PRIMARY KEY(id);
CREATE INDEX ON task(owner_id, task_date);
CREATE INDEX ON task(author_id);
නිශ්චිත ක්රියාත්මක කරන්නෙකු සඳහා අවසාන කාර්යයන් 100 පෙන්වමු:
SELECT
task.*
, person.name
FROM
task
LEFT JOIN
person
ON person.id = task.author_id
WHERE
owner_id = 777
ORDER BY
task_date DESC
LIMIT 100; 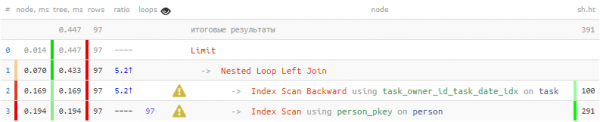
එය එවැන්නකි 1/3 මුළු කාලය සහ 3/4 කියවීම් සෑම ප්රතිදාන කාර්යයක් සඳහාම - කර්තෘ 100 වතාවක් සෙවීමට පමණක් දත්ත පිටු සාදන ලදී. නමුත් මේ සියගණනක් අතර බව අපි දනිමු වෙනස් 20 ක් පමණි - මෙම දැනුම භාවිතා කළ හැකිද?
hstore-ශබ්දකෝෂය
ප්රයෝජනය ගනිමු "ශබ්දකෝෂය" යතුරු-අගය ජනනය කිරීමට:
CREATE EXTENSION hstoreඅපට අවශ්ය වන්නේ කර්තෘගේ හැඳුනුම්පත සහ ඔහුගේ නම ශබ්දකෝෂයේ තැබීමට එවිට අපට මෙම යතුර භාවිතයෙන් උපුටා ගත හැකිය:
-- формируем целевую выборку
WITH T AS (
SELECT
*
FROM
task
WHERE
owner_id = 777
ORDER BY
task_date DESC
LIMIT 100
)
-- формируем словарь для уникальных значений
, dict AS (
SELECT
hstore( -- hstore(keys::text[], values::text[])
array_agg(id)::text[]
, array_agg(name)::text[]
)
FROM
person
WHERE
id = ANY(ARRAY(
SELECT DISTINCT
author_id
FROM
T
))
)
-- получаем связанные значения словаря
SELECT
*
, (TABLE dict) -> author_id::text -- hstore -> key
FROM
T; 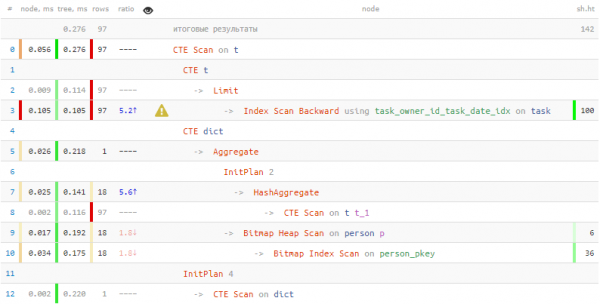
පුද්ගලයන් පිළිබඳ තොරතුරු ලබා ගැනීම සඳහා වියදම් කර ඇත 2 ගුණයකින් අඩු කාලයක් සහ 7 ගුණයකින් අඩු දත්ත කියවීම! "වචන මාලාවට" අමතරව, මෙම ප්රතිඵල අත්කර ගැනීමට අපට උපකාරවත් වූයේ ය තොග වාර්තා ලබා ගැනීම භාවිතා කරමින් තනි පාස් එකකින් මේසයෙන් = ANY(ARRAY(...)).
වගු ඇතුළත් කිරීම්: අනුක්රමිකකරණය සහ පරිවෘත්තීයකරණය
නමුත් අපට එක් පෙළ ක්ෂේත්රයක් පමණක් නොව ශබ්දකෝෂයේ සම්පූර්ණ ප්රවේශයක් සුරැකීමට අවශ්ය නම් කුමක් කළ යුතුද? මෙම අවස්ථාවේදී, PostgreSQL හි හැකියාව අපට උපකාර වනු ඇත වගු ඇතුළත් කිරීමක් තනි අගයක් ලෙස සලකන්න:
...
, dict AS (
SELECT
hstore(
array_agg(id)::text[]
, array_agg(p)::text[] -- магия #1
)
FROM
person p
WHERE
...
)
SELECT
*
, (((TABLE dict) -> author_id::text)::person).* -- магия #2
FROM
T;මෙහි සිදුවන්නේ කුමක්දැයි බලමු:
- අපි ගත්තා p පූර්ණ පුද්ගල වගු ප්රවේශයට අන්වර්ථයක් ලෙස සහ ඔවුන්ගෙන් අරාවක් එක්රැස් කළේය.
- මෙම පටිගත කිරීම් මාලාව නැවත සකස් කරන ලදී අගයන් අරාවක් ලෙස hstore ශබ්දකෝෂයේ තැබීමට පෙළ තන්තු මාලාවකට (පුද්ගල[]::text[]).
- අපට අදාළ වාර්තාවක් ලැබුණු විට, අපි යතුරෙන් ශබ්ද කෝෂයෙන් ඇද්දා පෙළ පෙළක් ලෙස.
- අපට පෙළ අවශ්යයි වගු ආකාරයේ අගයක් බවට පත් කරන්න පුද්ගලයා (එක් එක් වගුව සඳහා එකම නමේ වර්ගයක් ස්වයංක්රීයව සාදනු ලැබේ).
- භාවිතයෙන් ටයිප් කළ වාර්තාව තීරුවලට "පුළුල් කරන්න"
(...).*.
json ශබ්දකෝෂය
නමුත් "වාත්තු කිරීම" කිරීමට අනුරූප වගු වර්ගයක් නොමැති නම් අප ඉහත යෙදූ එවැනි උපක්රමයක් ක්රියා නොකරනු ඇත. හරියටම එම තත්ත්වය මතු වනු ඇත, සහ අපි භාවිතා කිරීමට උත්සාහ කළහොත් CTE පේළියක්, "සැබෑ" වගුවක් නොවේ.
මෙම අවස්ථාවේ දී, ඔවුන් අපට උපකාර කරනු ඇත :
...
, p AS ( -- это уже CTE
SELECT
*
FROM
person
WHERE
...
)
, dict AS (
SELECT
json_object( -- теперь это уже json
array_agg(id)::text[]
, array_agg(row_to_json(p))::text[] -- и внутри json для каждой строки
)
FROM
p
)
SELECT
*
FROM
T
, LATERAL(
SELECT
*
FROM
json_to_record(
((TABLE dict) ->> author_id::text)::json -- извлекли из словаря как json
) AS j(name text, birth_date date) -- заполнили нужную нам структуру
) j; ඉලක්ක ව්යුහය විස්තර කිරීමේදී, අපට ප්රභව තන්තුවේ සියලුම ක්ෂේත්ර ලැයිස්තුගත කළ නොහැකි නමුත් අපට සැබවින්ම අවශ්ය ඒවා පමණක් බව සටහන් කළ යුතුය. අපට "ස්වදේශීය" වගුවක් තිබේ නම්, කාර්යය භාවිතා කිරීම වඩා හොඳය json_populate_record.
අපි තවමත් එක් වරක් ශබ්ද කෝෂයට පිවිසෙමු, නමුත් json-[de]serialization පිරිවැය තරමක් ඉහළ ය, එබැවින්, "අවංක" CTE ස්කෑන් වඩාත් නරක අතට හැරෙන විට සමහර අවස්ථාවලදී පමණක් මෙම ක්රමය භාවිතා කිරීම සාධාරණ වේ.
කාර්ය සාධනය පරීක්ෂා කිරීම
ඉතින්, අපට ශබ්ද කෝෂයකට දත්ත අනුක්රමික කිරීමට ක්රම දෙකක් තිබේ - hstore/json_object. ඊට අමතරව, යතුරු අරා සහ අගයන් ද ක්රම දෙකකින් ජනනය කළ හැකිය, අභ්යන්තර හෝ බාහිර පෙළ බවට පරිවර්තනය කිරීම: array_agg(i::text) / array_agg(i)::text[].
තනිකරම කෘත්රිම උදාහරණයක් භාවිතා කරමින් විවිධ වර්ගවල අනුක්රමිකකරණයේ සඵලතාවය පරීක්ෂා කරමු - විවිධ යතුරු සංඛ්යා අනුක්රමික කරන්න:
WITH dict AS (
SELECT
hstore(
array_agg(i::text)
, array_agg(i::text)
)
FROM
generate_series(1, ...) i
)
TABLE dict;ඇගයීම් පිටපත: අනුක්රමිකකරණය
WITH T AS (
SELECT
*
, (
SELECT
regexp_replace(ea[array_length(ea, 1)], '^Execution Time: (d+.d+) ms$', '1')::real et
FROM
(
SELECT
array_agg(el) ea
FROM
dblink('port= ' || current_setting('port') || ' dbname=' || current_database(), $$
explain analyze
WITH dict AS (
SELECT
hstore(
array_agg(i::text)
, array_agg(i::text)
)
FROM
generate_series(1, $$ || (1 << v) || $$) i
)
TABLE dict
$$) T(el text)
) T
) et
FROM
generate_series(0, 19) v
, LATERAL generate_series(1, 7) i
ORDER BY
1, 2
)
SELECT
v
, avg(et)::numeric(32,3)
FROM
T
GROUP BY
1
ORDER BY
1; 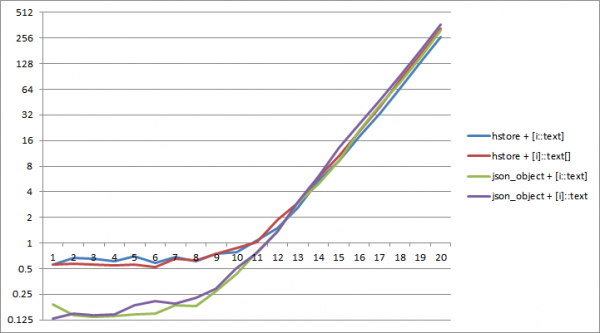
PostgreSQL 11 මත, ආසන්න වශයෙන් 2^12 යතුරු වල ශබ්ද කෝෂ ප්රමාණය දක්වා json වෙත ශ්රේණිගත කිරීම අඩු කාලයක් ගතවේ. මෙම අවස්ථාවෙහිදී, වඩාත් ඵලදායී වන්නේ json_object සහ "අභ්යන්තර" ආකාරයේ පරිවර්තනයේ සංයෝජනයයි array_agg(i::text).
දැන් අපි එක් එක් යතුරේ අගය 8 වතාවක් කියවීමට උත්සාහ කරමු - සියල්ලට පසු, ඔබ ශබ්ද කෝෂයට ප්රවේශ නොවන්නේ නම්, එය අවශ්ය වන්නේ ඇයි?
ඇගයීම් පිටපත: ශබ්දකෝෂයකින් කියවීම
WITH T AS (
SELECT
*
, (
SELECT
regexp_replace(ea[array_length(ea, 1)], '^Execution Time: (d+.d+) ms$', '1')::real et
FROM
(
SELECT
array_agg(el) ea
FROM
dblink('port= ' || current_setting('port') || ' dbname=' || current_database(), $$
explain analyze
WITH dict AS (
SELECT
json_object(
array_agg(i::text)
, array_agg(i::text)
)
FROM
generate_series(1, $$ || (1 << v) || $$) i
)
SELECT
(TABLE dict) -> (i % ($$ || (1 << v) || $$) + 1)::text
FROM
generate_series(1, $$ || (1 << (v + 3)) || $$) i
$$) T(el text)
) T
) et
FROM
generate_series(0, 19) v
, LATERAL generate_series(1, 7) i
ORDER BY
1, 2
)
SELECT
v
, avg(et)::numeric(32,3)
FROM
T
GROUP BY
1
ORDER BY
1; 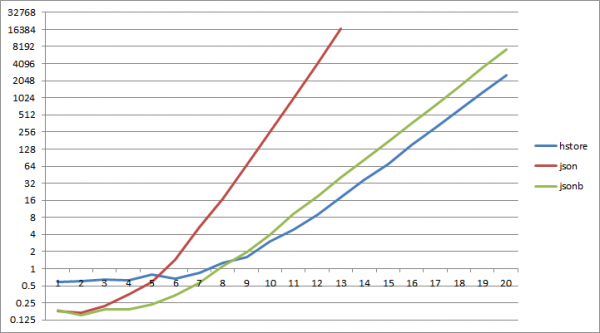
සහ ... දැනටමත් ආසන්න වශයෙන් 2^6 යතුරු සමඟ, json ශබ්දකෝෂයකින් කියවීම කිහිප වතාවක් අහිමි වීමට පටන් ගනී hstore වෙතින් කියවීම, jsonb සඳහා 2^9 ට එයම සිදුවේ.
අවසාන නිගමන:
- ඔබට එය කිරීමට අවශ්ය නම් බහු පුනරාවර්තන වාර්තා සමඟ එක්වන්න - මේසයේ "ශබ්දකෝෂය" භාවිතා කිරීම වඩා හොඳය
- ඔබේ ශබ්දකෝෂය අපේක්ෂා කරන්නේ නම් කුඩා වන අතර ඔබ එයින් බොහෝ දේ කියවන්නේ නැත - ඔබට json [b] භාවිතා කළ හැකිය
- අනෙකුත් සියලුම අවස්ථා වලදී hstore + array_agg(i::text) වඩාත් ඵලදායී වනු ඇත
මූලාශ්රය: www.habr.com
